







1 实验介绍
近年来,世界各国对于海洋鱼类资源的重视程度与日俱增。海洋鱼类资源不仅具有⼀定的食用价值,同时也具有较高的药用价值。在鱼类资源的开发利用中,需要对鱼类进行识别,但由于海洋鱼种类繁多,外形相似,且海底拍摄环境亮度低、场景模糊,导致人工进行鱼类资源识别较为困难。
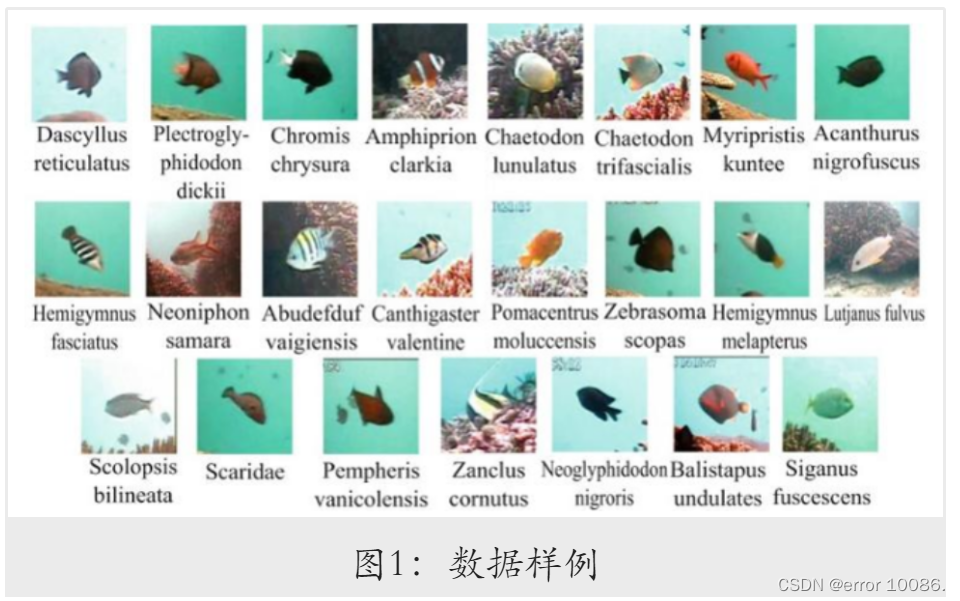
针对上述问题,本实验利用卷积神经网络构建深度学习模型进行高质量特征的自动提取,以提高海洋鱼类识别的准确率。实验所用数据集是由台湾电力公司、台湾海洋研究所和垦丁国家公园在2010年10月1日至2013年9月30日期间,于台湾南湾海峡、兰屿岛和胡比湖的⽔下观景台收集的鱼类图像数据集,包含23类鱼种,共有27370张鱼的图像。
本实验所构建的模型在测试数据集上的Top-1准确率达到了99.27% ,模型对海洋鱼类的识别准确率超过⼈眼,已初步具备实用价值。
2 数据准备
2.1 解压数据
将数据集压缩⽂件解压到实验数据对应的⽂件夹下,同时创建类别字典,将⻥类标签与类别名相对应。
SRC_PATH = "./data/data14492/fish_image23.zip" # 压缩包路径
DST_PATH = "./data" # 解压路径
DATA_PATH = DST_PATH + "/fish_image" # 实验数据集路径
INFER_LIST = [("./work/pm.jpg", "Pomacentrus moluccensis"),
("./work/ac.jpg", "Amphiprion clarkii"),
("./work/a.jpg", "Myripristis kuntee"),
("./work/b.jpg", "Amphiprion clarkii")] # 预测数据
MODEL_PATH = "GoogLeNet.pdparams" # 模型参数保存路径
save_dir="./save"LAB_DICT = {'fish_1': 'Dascyllus reticulatus', 'fish_2': 'Plectroglyphidodon dickii',
'fish_3': 'Chromis chrysura', 'fish_4': 'Amphiprion clarkii',
'fish_5': 'Chaetodon lunulatus', 'fish_6': 'Chaetodon trifascialis',
'fish_7': 'Myripristis kuntee', 'fish_8': 'Acanthurus nigrofuscus',
'fish_9': 'Hemigymnus fasciatus', 'fish_10': 'Neoniphon sammara',
'fish_11': 'Abudefduf vaigiensis', 'fish_12': 'Canthigaster valentini',
'fish_13': 'Pomacentrus moluccensis', 'fish_14': 'Zebrasoma scopas',
'fish_15': 'Hemigymnus melapterus', 'fish_16': 'Lutjanus fulvus',
'fish_17': 'Scolopsis bilineata', 'fish_18': 'Scaridae',
'fish_19': 'Pempheris vanicolensis', 'fish_20': 'Zanclus cornutus',
'fish_21': 'Neoglyphidodon nigroris', 'fish_22': 'Balistapus undulatus',
'fish_23': 'Siganus fuscescens'} # 用于将文件名和标签相对应
if not os.path.isdir(DATA_PATH):
z = zipfile.ZipFile(SRC_PATH, "r") # 打开压缩文件,创建zip对象
z.extractall(path=DST_PATH) # 解压zip文件至目标路径
z.close()
print("数据集解压完成!")
2.2 划分训练集和测试集
将原始数据集按9:1的⽐例划分为训练集和测试集,其中训练集用于训练模型参数,训练完指定的轮数后,使用测试集检验模型的泛化能力。
type_num, lab_dict = 0, {} # 方便动物类别在字符型和整型之间转换
train_list, test_list = [], [] # 存放数据的路径及标签的映射关系
file_folders = os.listdir(DATA_PATH) # 统计数据集下的文件夹
for folder in file_folders:
lab_dict[str(type_num)] = LAB_DICT[folder] # 记录标签和数字代号的对应关系
imgs = os.listdir(os.path.join(DATA_PATH, folder))
for idx, img in enumerate(imgs):
path = os.path.join(DATA_PATH, folder, img)
if idx % 10 == 0: # 按照1:9的比例划分数据集
test_list.append([path, type_num])
else:
train_list.append([path, type_num])
type_num += 1
2.3 定义数据读取与处理方式
通过继承 paddle.io.Dataset 类自定义数据集类 MyDataset ,对传⼊的数据列表进行随机打乱,使用 ToTensor 接口对数据进行转换,以匹配数据馈送格式,并对图像的三通道分别进⾏标准化。在 data_mapper 中进行了图像的缩放、转换为 numpy 数组、转置和归一化等操作。确保这些处理与模型的期望输入一致,否则可能会导致训练问题,完整类定义如下:
class MyDataset(Dataset):
''' 自定义的数据集类 '''
def __init__(self, label_list, transform):
'''
* `label_list`: 标签与文件路径的映射列表
* `transform`: 数据处理函数
'''
super(MyDataset, self).__init__()
random.shuffle(label_list) # 打乱映射列表
self.label_list = label_list
self.transform = transform
def __getitem__(self, index):
''' 根据位序获取对应数据 '''
img_path, label = self.label_list[index]
img = self.transform(img_path)
return img, int(label)
def __len__(self):
''' 获取数据集样本总数 '''
return len(self.label_list)
def _load_img(self, path):
"""
从磁盘读取图片
"""
img = Image.open(path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.ANTIALIAS)
return img
def data_mapper(img_path, show=False):
''' 图像处理函数 '''
img = Image.open(img_path)
if show: # 展示图像
display(img)
# 将其缩放为224*224的高质量图像:
img = img.resize((224, 224), Image.ANTIALIAS)
# 把图像变成一个numpy数组以匹配数据馈送格式:
img = np.array(img).astype("float32")
# 将图像矩阵由“rgb,rgb,rbg...”转置为“rr...,gg...,bb...”:
img = img.transpose((2, 0, 1))
# 将图像数据归一化,并转换成Tensor格式:
img = paddle.to_tensor(img / 255.0)
return img
3 实验过程
3.1 模型选择
本次实验识别的对象为彩色图,尺⼨为224x224 ,相对于其他简单的神经网络模型,本实验选择使用效果更好、结构更为复杂的AlexNet与GoogLeNet模型完成分类任务。
3.1.1 AlexNet
AlexNet 由 Alex Krizhevsky 等 人 于 2012 年 在 论 文 ImageNet Classification with Deep Convolutional Neural Networks中提出。与LeNet相比,AlexNet具有更深的网络结构,同时采用了数据增广、Dropout与ReLU激活函数三种方式改进模型的训练过程。其基础结构如图2所⽰。

定义AlexNet⽹络结构如下:
class AlexNet(nn.Layer):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
# 卷积层
self.conv1 = nn.Conv2D(in_channels=3,
out_channels=96,
kernel_size=11,
stride=4,
padding=5)
self.max_pool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = nn.Conv2D(in_channels=96,
out_channels=256,
kernel_size=5,
padding=2)
self.max_pool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.conv3 = nn.Conv2D(in_channels=256,
out_channels=384,
kernel_size=3,
padding=1)
self.conv4 = nn.Conv2D(in_channels=384,
out_channels=384,
kernel_size=3,
padding=1)
self.conv5 = nn.Conv2D(in_channels=384,
out_channels=256,
kernel_size=3,
padding=1)
self.max_pool5 = nn.MaxPool2D(kernel_size=2, stride=2)
# 全连接层
self.fc1 = nn.Linear(in_features=12544, out_features=4096)
self.drop_ratio1 = 0.5
self.drop1 = nn.Dropout(self.drop_ratio1)
self.fc2 = nn.Linear(in_features=4096, out_features=4096)
self.drop_ratio2 = 0.5
self.drop2 = nn.Dropout(self.drop_ratio2)
self.fc3 = nn.Linear(in_features=4096, out_features=num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = self.conv3(x)
x = F.relu(x)
x = self.conv4(x)
x = F.relu(x)
x = self.conv5(x)
x = F.relu(x)
x = self.max_pool5(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = F.relu(x)
# 在全连接之后使用dropout抑制过拟合
x = self.drop1(x)
x = self.fc2(x)
x = F.relu(x)
# 在全连接之后使用dropout抑制过拟合
x = self.drop2(x)
x = self.fc3(x)
return x
将模型与输⼊数据的形状作为参数传⼊ paddle.summary 函数,得到网络基础结构与参数信息如下:
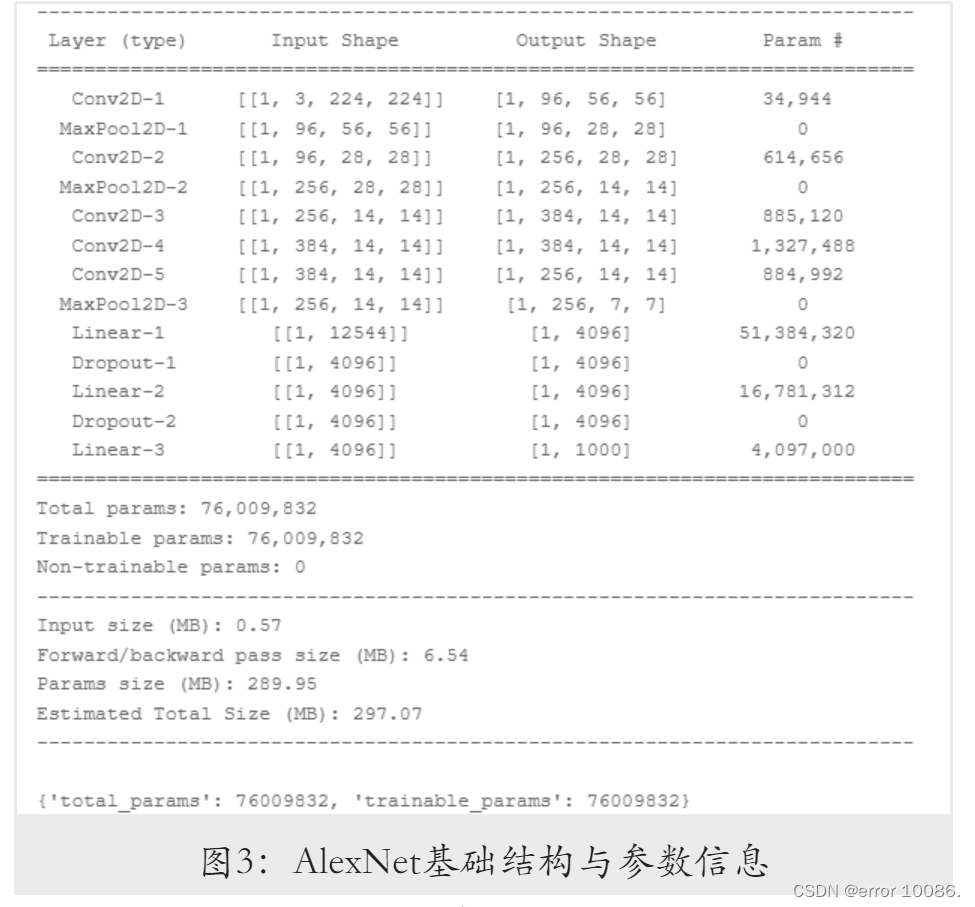
可以看到,模型的参数量达到了千万级别,且绝⼤部分参数都由全连接层产生。参数量过多势必会对训练速度造成影响,同时也会增⼤模型的存储开销,因而后续将对模型进行进一步的优化。
3.1.2 GoogLeNet
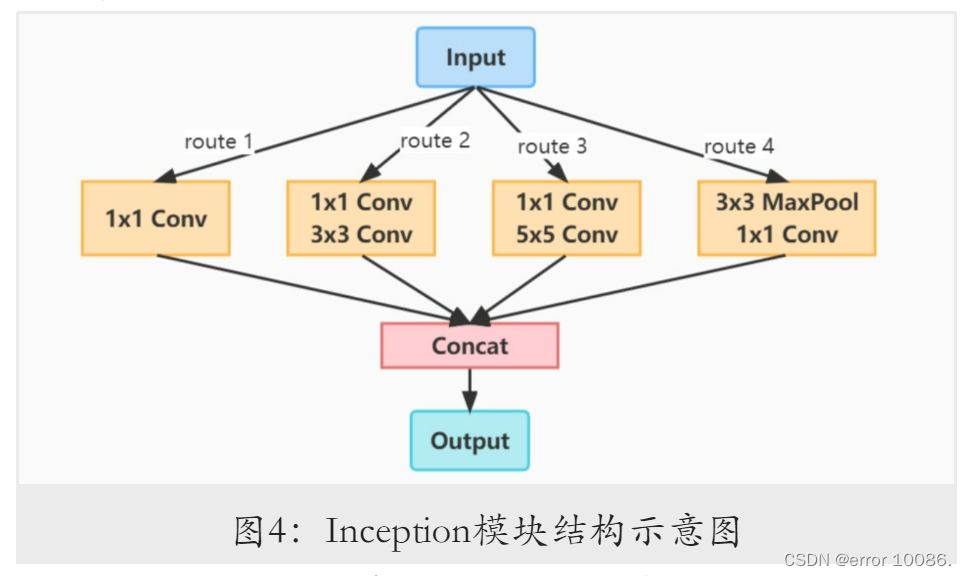
GoogLeNet由Google团队在论文Going deeper with convolutions中提出,该模型获得了2014年ImageNet挑战赛冠军。GoogLeNet创新性地采用了Inception模块,通过使用3个不同大小的卷积核来提取图像特征,并增加1 × 1的卷积层减小输出通道数。Inception模块结构如图4所⽰。
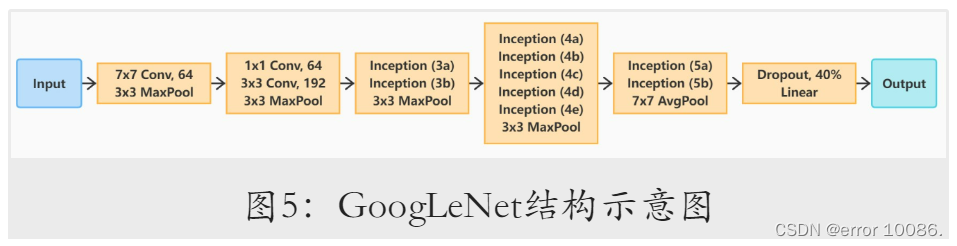
GoogLeNet主体则由多个模块串联而成。其整体结构如图5所⽰。
构建模型时,⾸先定义卷积块类,包含卷积层、BatchNorm层及ReLU激活函数。其中,批归⼀化方法(Batch Normalization)能够通过对神经元的数值进行归⼀化,使神经网络中间层的输出变得更加稳定,并能在⼀定程度上抑制过拟合。
卷积块类定义如下:
class ConvBN(nn.Layer):def __init__(self, in_channels: int, out_channels: int,
kernel_size: int, stride=1, padding=0):
'''
* `in_channels`: 输入通道数
* `out_channels`: 输出通道数
* `kernel_size`: 卷积核大小
* `stride`: 卷积运算的步长
* `padding`: 卷积填充的大小
'''
super(ConvBN, self).__init__()
self.net = nn.Sequential(
nn.Conv2D(in_channels, out_channels, kernel_size, stride, padding),
nn.BatchNorm2D(out_channels),
nn.ReLU()
)
def forward(self, x):
return self.net(x)
定义Inception类如下:
class Inception(nn.Layer):
''' Inception v1 in GoogLeNet '''
def __init__(self, in_channels: int, c1: int,
c2: tuple, c3: tuple, c4: int):
'''
* `in_channels`: 输入通道数
* `c1`: 第1路卷积层的通道参数
* `c2`: 第2路卷积层的通道参数
* `c3`: 第3路卷积层的通道参数
* `c4`: 第4路卷积层的通道参数
'''
super(Inception, self).__init__()
self.conv1 = nn.Sequential(
ConvBN(in_channels, c1, 1, 1, 0),
nn.ReLU()
)
self.conv2 = nn.Sequential(
ConvBN(in_channels, c2[0], 1, 1, 0),
nn.ReLU(),
ConvBN(c2[0], c2[1], 3, 1, 1),
nn.ReLU()
)
self.conv3 = nn.Sequential(
ConvBN(in_channels, c3[0], 1, 1, 0),
nn.ReLU(),
ConvBN(c3[0], c3[1], 5, 1, 2),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.MaxPool2D(3, 1, 1),
ConvBN(in_channels, c4, 1, 1, 0),
nn.ReLU()
)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
y3 = self.conv3(x)
y4 = self.conv4(x)
y = paddle.concat([y1, y2, y3, y4], axis=1) # Depth Concat
return y
最后,定义完整的GoogLeNet网络结构如下:
class GoogLeNet(nn.Layer):
def __init__(self, in_channels=3, n_classes=2):
'''
* `in_channels`: 输入的通道数
* `n_classes`: 输出分类数量
'''
super(GoogLeNet, self).__init__()
# Conv2D(输入通道数,输出通道数,卷积核大小,卷积步长,填充长度)
# MaxPool2D(池化核大小,池化步长,填充长度)
self.block1 = nn.Sequential(
ConvBN(in_channels, 64, 7, 2, 3), # 64*112*112
nn.ReLU(),
nn.MaxPool2D(3, 2, 1), # 64*56*56
)
self.block2 = nn.Sequential(
ConvBN(64, 64, 1, 1, 0), # 64*56*56
nn.ReLU(),
ConvBN(64, 192, 3, 1, 1), # 192*56*56
nn.ReLU(),
nn.MaxPool2D(3, 2, 1), # 192*28*28
)
self.block3 = nn.Sequential(
Inception(192, 64, (96, 128), (16, 32), 32), # 3a:256*28*28
Inception(256, 128, (128, 192), (32, 96), 64), # 3b:480*28*28
nn.MaxPool2D(3, 2, 1), # 480*14*14
)
self.block4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64), # 4a:512*14*14
Inception(512, 160, (112, 224), (24, 64), 64), # 4b:512*14*14
Inception(512, 128, (128, 256), (24, 64), 64), # 4c:512*14*14
Inception(512, 112, (144, 288), (32, 64), 64), # 4d:528*14*14
Inception(528, 256, (160, 320), (32, 128), 128), # 4e:832*14*14
nn.MaxPool2D(3, 2, 1), # 832*7*7
)
self.block5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128), # 5a:832*7*7
Inception(832, 384, (192, 384), (48, 128), 128), # 5b:1024*7*7
nn.AdaptiveAvgPool2D(1), # 1024*1*1
)
self.block6 = nn.Sequential(
nn.Flatten(1, -1), # 1024
nn.Dropout(p=0.4),
nn.Linear(1024, n_classes), # n_classes
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
y = self.block6(x)
return y
将模型与输⼊数据的形状作为参数传⼊ paddle.summary 函数,查看⽹络基础结构与参数信息。由于GoogLeNet层数较多,其⽹络结构在此仅作部分展⽰。模型的部分模型结构和参数信息如图6和图7所⽰。
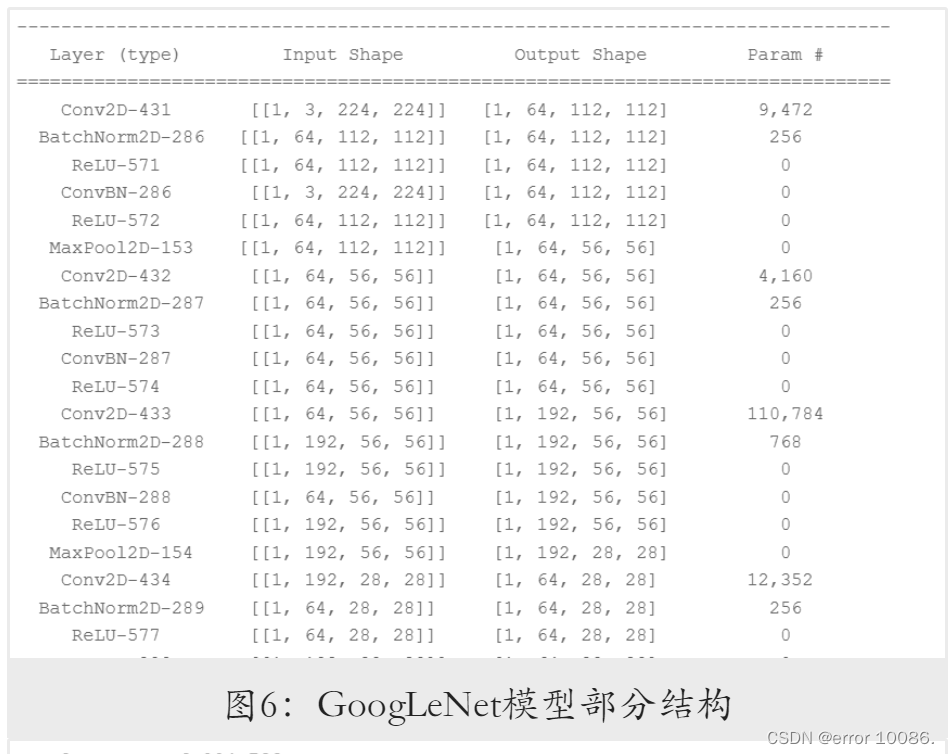

3.2 模型训练
初始化参数设置:
| 初始化参数设置 |
|---|
| BATCH_SIZE = 64 # 每批次的样本数 |
| EPOCHS = 10 # 训练轮数 |
| LOG_GAP = 200 # 输出训练信息的间隔 |
| weight_decay=0.0005 # 权重衰减 |
| INIT_LR = 0.001 # 初始学习率 |
| LR_DECAY = 0.9 # 学习率衰减率 |
| step_size=50 # 衰减步长 |
| patience=3 # 早停 |
| 训练集的准备: |
| 将训练集数据进行打乱,定义相关参数。 |
train_loader = DataLoader(train_dataset, # 训练数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=True, # 打乱训练数据集
drop_last=False) # 丢弃不完整的样本
test_loader = DataLoader(test_dataset, # 测试数据集
batch_size=BATCH_SIZE, # 每批读取的样本数
num_workers=0, # 加载数据的子进程个数
shuffle=False, # 不打乱测试数据集
drop_last=False) # 不丢弃不完整的样本
3.2.1 AlexNet模型的训练
构建好模型后,进⾏训练过程的配置,基本思路与⼿写数字识别实验⼤致相同,涉及学习率衰减,以及设置回调函数实现早停与训练过程可视化。在此基础上,由于分类问题通常以Top-1准确率和Top-5准确率作为衡量指标,在查阅官⽅⽂档后,我修改了传入paddle.metric.Accuracy 接口中的 topk 参数,使得模型训练过程中能同时打印Top-1准确率和Top-5准确率。相应地,也需要修改EarlyStopping 中的 monitor参数,否则会导致早停策略失效。在本实验中,我将监测对象设置为模型的Top-1准确率。完整训练代码如下(以AlexNet为例):
# 封装模型
model = paddle.Model(AlexNet(num_classes=type_num))
# 设置学习率衰减及优化策略
from paddle.optimizer.lr import StepDecay
learning_rate_decay = StepDecay(learning_rate=INIT_LR,
step_size=step_size,
gamma=LR_DECAY)
optim = paddle.optimizer.AdamW(learning_rate=learning_rate_decay,
weight_decay=weight_decay,
parameters=model.parameters())
# 设置可视化回调、停止训练回调及学习率回调
visualDL = paddle.callbacks.VisualDL(log_dir=save_dir+'/visualDL')
earlyStop = paddle.callbacks.EarlyStopping(monitor='acc_top1',
patience=patience)
callbacks = [visualDL, earlyStop]
# 配置模型
model.prepare(optim,
nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1, 5)))
# 训练并保存模型
model.fit(train_dataset,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
save_dir=save_dir+'/model',
verbose=1,
shuffle=True,
num_workers=0,
callbacks=callbacks)
训练过程:

训练过程可视化:
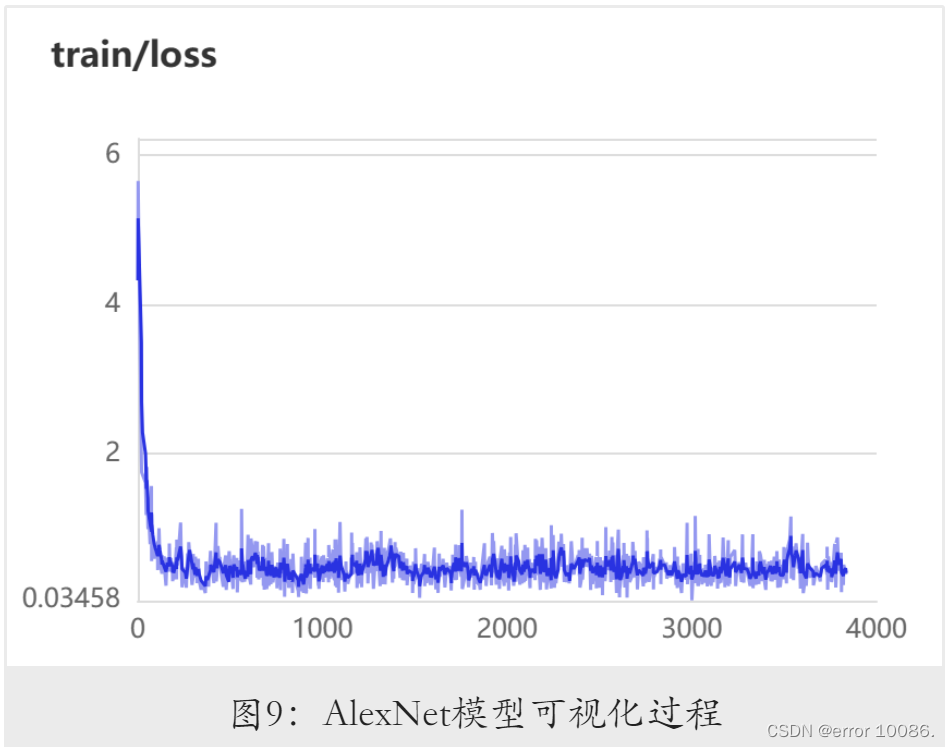
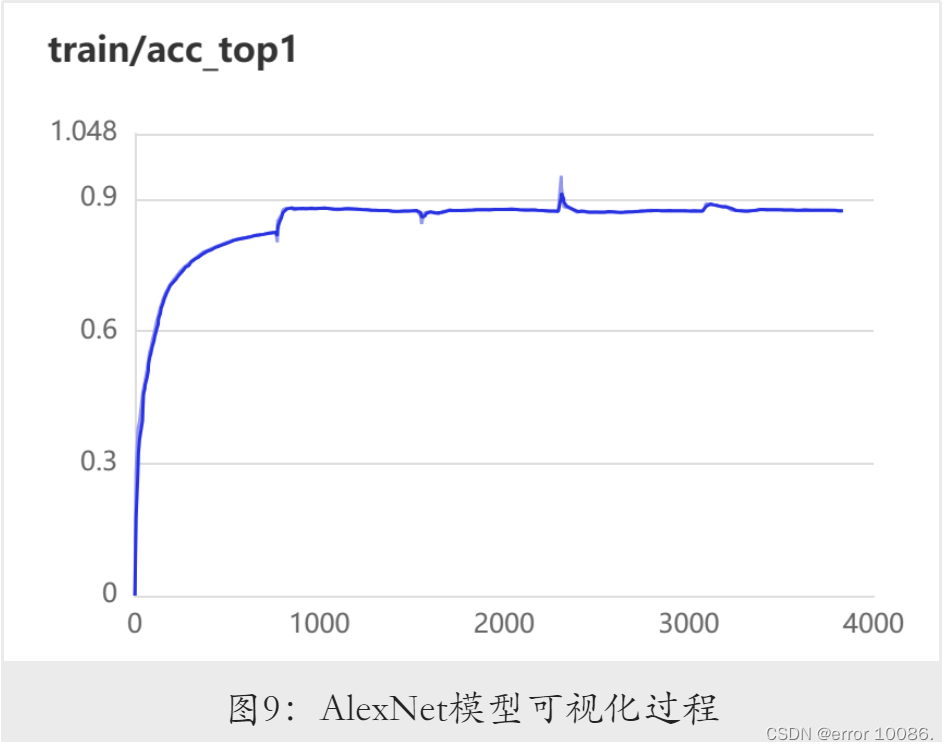
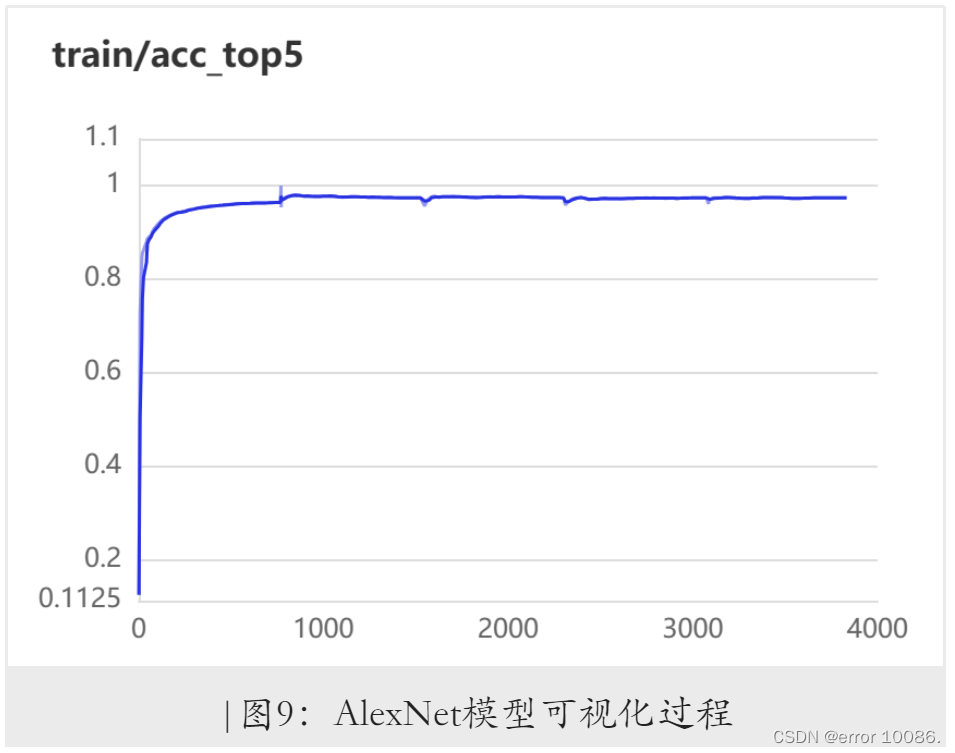
AlexNet在初始参数的训练结果:
| Model | Top-1 Acc | Top-5 Acc |
|---|---|---|
| AlexNet | 0.86 | 0.97 |
3.2.2 GoogleNet模型的训练
model.train() # 开启训练模式
scheduler = NaturalExpDecay(
learning_rate=INIT_LR,
gamma=LR_DECAY
) # 定义学习率衰减器
optimizer = Adam(
learning_rate=scheduler,
parameters=model.parameters()
) # 定义Adam优化器
loss_arr, acc_arr = [], [] # 用于可视化
for ep in range(EPOCHS):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
y_data =y_data.reshape((-1,1)) # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
if batch_id % LOG_GAP == 0: # 定期输出训练结果
print("Epoch:%d,Batch:%3d,Loss:%.5f,Acc:%.5f"\
% (ep, batch_id, loss, acc))
acc_arr.append(acc.numpy()[0])
loss_arr.append(loss.numpy()[0])
optimizer.clear_grad()
loss.backward()
optimizer.step()
scheduler.step() # 每轮衰减一次学习率
paddle.save(model.state_dict(), MODEL_PATH) # 保存训练好的模型
训练过程:

训练过程可视化:
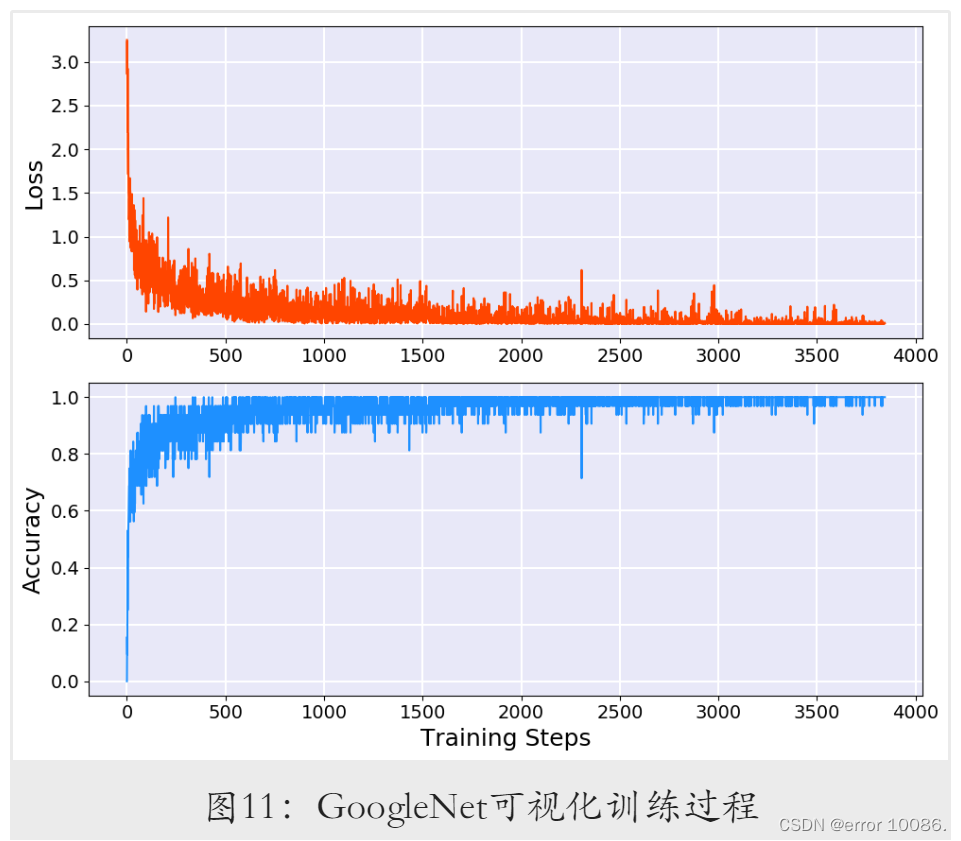
GoogleNet在初始参数的训练结果:
| Model | Top-1 Acc | Top-5 Acc |
|---|---|---|
| AlexNet | 0.99 | 1.00 |
3.3 模型评估
model.eval() # 开启评估模式
test_costs, test_accs = [], []
for batch_id, data in enumerate(test_loader()):
x_data, y_data = data
#y_data = y_data[:, np.newaxis] # 增加一维维度
y_data =y_data.reshape((-1,1)) # 增加一维维度
y_pred = model(x_data) # 预测结果
acc = M.accuracy(y_pred, y_data) # 计算准确率
loss = F.cross_entropy(y_pred, y_data) # 计算交叉熵
test_accs.append(acc.numpy()[0])
test_costs.append(loss.numpy()[0])
test_loss = np.mean(test_costs) # 每轮测试的平均误差
test_acc = np.mean(test_accs) # 每轮测试的平均准确率
print("Eval \t Loss:%.5f,Acc:%.5f" % (test_loss, test_acc))
AlexNet测试集结果:
| Loss | top1-ACC |
|---|---|
| 0.59149 | 0.86100 |
| GooleNet测试集结果: |
| Loss | top1-ACC |
|---|---|
| 0.04530 | 0.99237 |
3.4 模型预测
model.eval() # 开启评估模式
model.set_state_dict(
paddle.load(MODEL_PATH)
) # 载入预训练模型参数
for idx, (img_path, truth_lab) in enumerate(INFER_LIST):
image = data_mapper(img_path, show=True) # 获取预测图片
#result = model(image[np.newaxis, :, :, :])
result = model(image.reshape((1, 3, 224, 224)))
infer_lab = lab_dict[str(np.argmax(result))] # 获取推理结果
print("图%d的真实标签:%s,预测结果:%s" % (idx+1, truth_lab, infer_lab))

上图为两张从网络上下载的图片,清晰度较高,根据结果可知模型对其的预测完全正确,可见模型的泛化能力很好,达到了使用标准。
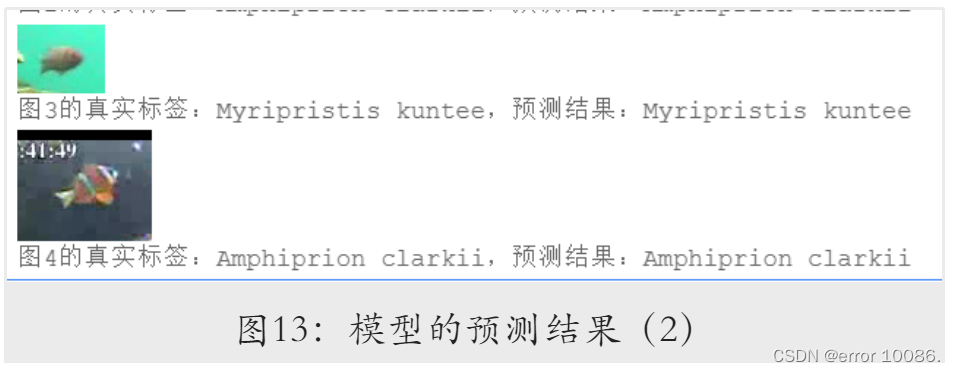
上图为测试集中随机抽取的两个图片,可见模型对其的预测也是完全正确的。
4 模型优化
4.1 优化AlexNet网络结构
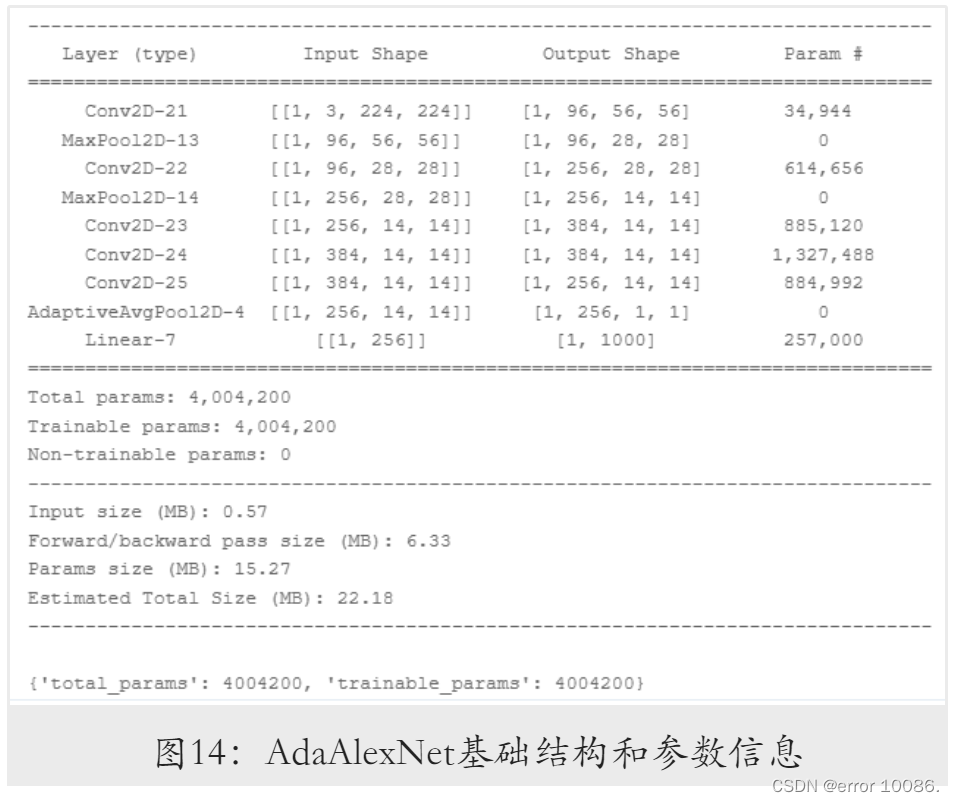
4.1.1AdaAlexNet模型
原始AlexNet模型中,绝大部分参数来自全连接层。为减少模型的参数量,受GoogLeNet
启发,选择将卷积层后的全连接层替换为全局平均池化层,同时舍弃原有的Dropout层,
构建出AdaAlexNet模型,其结构与参数信息如下:
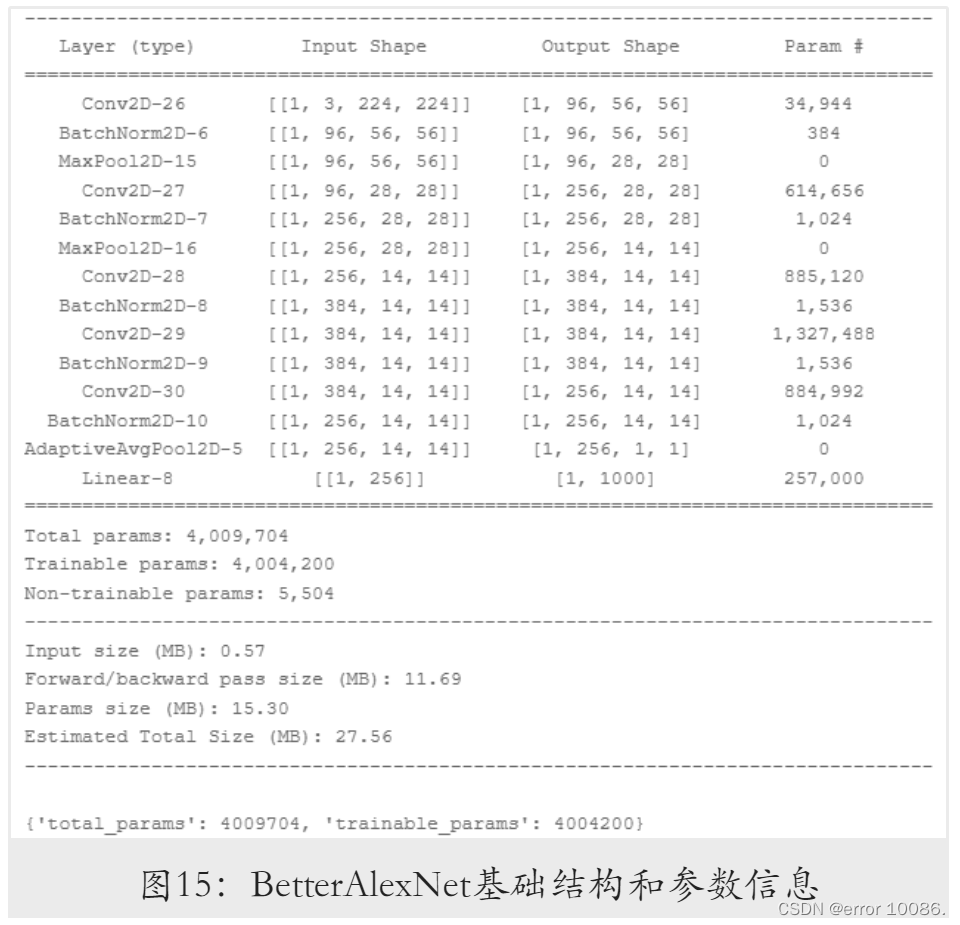
4.1.2BetterAlexNet模型
使用全局平均池化层代替全连接层后,模型参数量仅为原来的1/20左右,存储开销大幅
降低。由于AdaAlexNet舍弃了Dropout层,为降低模型的过拟合程度,选择在其基础上
进⼀步增加BatchNorm层,构建出BetterAlexNet模型,其结构与参数信息如下:
调整初始化参数:
| 初始化参数设置 |
|---|
| BATCH_SIZE = 64 # 每批次的样本数 |
| EPOCHS = 10 # 训练轮数 |
| LOG_GAP = 200 # 输出训练信息的间隔 |
| weight_decay=0.0005 # 权重衰减 |
| INIT_LR = 3e-4 # 初始学习率 |
| LR_DECAY = 0.5 # 学习率衰减率 |
| step_size=50 # 衰减步长 |
| patience=3 # 早停 |
三个模型的训练结果如下:
| model | Loss | top1-Acc | top5-Acc |
|---|---|---|---|
| AlexNet | 0.2680 | 0.9795 | 0.9974 |
| AdaAlexNet | 0.2693 | 0.9606 | 0.9956 |
| BetterAlexNet | 0.1683 | 0.9810 | 0.9985 |
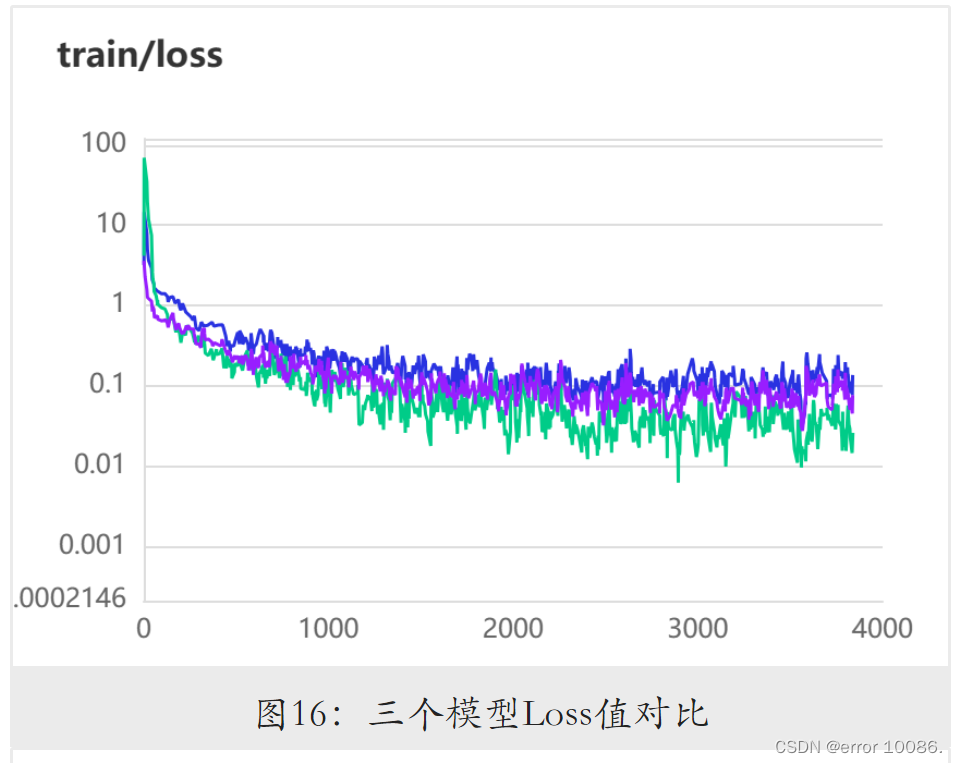
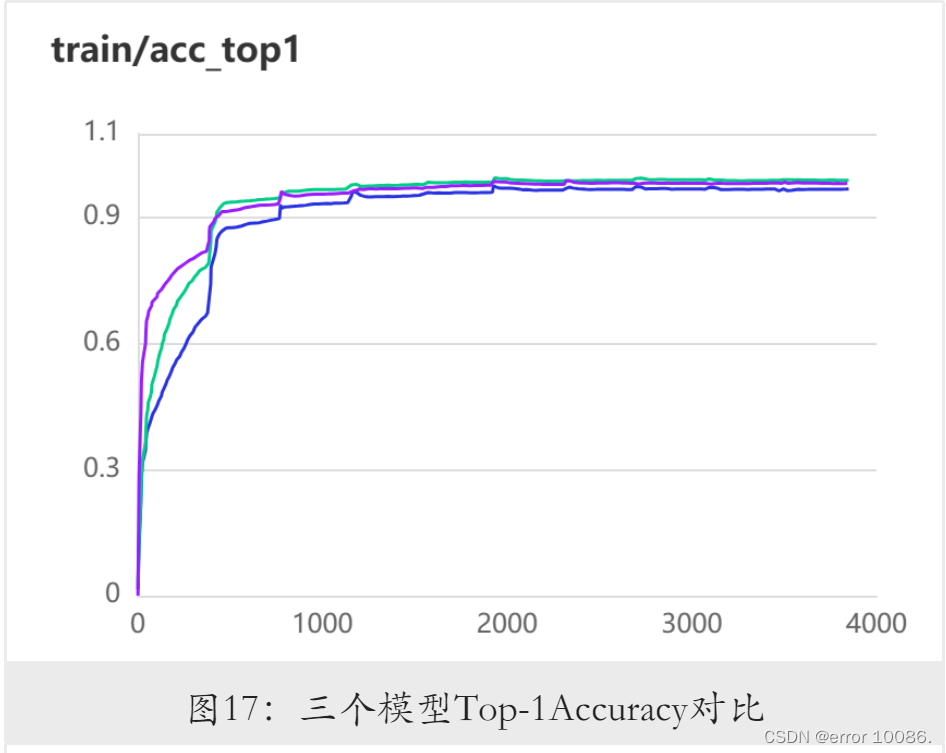

紫线:BetterAlexNet
蓝线:AdaAlexNet
绿线:AlexNet
可以看到,改用全局平均池化层后,模型准确率降低,损失基本不变,AdaAlexNet在减少大量的模型参数下损失基本不变且准确率下降度极少的情况下,使得模型的效率更高。加入BatchNorm层后,模型取得了最高的准确率与最低的损失值。需要注意的是,不同模型的准确率结果在多次重复试验中稍有区别,但BetterAlexNet所取得的损失总是最小,因此以该模型作为这三者中的最优方案。
4.2 对GoogLeNet改进学习率衰减策略
通过查阅官方文档发现,在使用 Model.fit 方式对模型进行训练时,可以通过paddle.callbacks ⽬录下的 LRScheduler 指定学习率在训练的哪⼀阶段进行更新。将学习率设置为在每⼀个 结束时才进行更新后,我重新选择学习率衰减策略。在实验过程中,我先后在GoogLeNet上尝试了三种不同的学习率衰减策略CosineAnnealingDecay、PiecewiseDacay以及NaturalExpDecay。
CosineAnnealingDecay余弦退火学习率衰减出自论文SGDR: STOCHASTIC GRADIENT DESCENT WITH WARM RESTARTS,主要思想是通过余弦函数来降低学习率,使其先缓慢下降,而后加速下降,最后再缓慢下降。此外,由于余弦函数具有周期性,因而该策略能够实现在训练过程中突然提高学习率以跳出局部最小值的效果。在应用该策略时,我将T_max参数设置为与epoch相等。
PiecewiseDacay分段常数学习率衰减与StepDecay核心思想一直,都是对学习率进行分段设置的策略,在epoch为10的条件下,我将学习率调整侧率设置为:
n
e
w
_
l
e
a
r
n
i
n
g
_
r
a
t
e
=
{
0.0003
,
0
⩽
e
p
o
c
h
<
3
0.00003
,
3
⩽
e
p
o
c
h
<
6
0.000003
,
6
⩽
e
p
o
c
h
new\_learning\_rate = \begin{cases}0.0003,0 \leqslant epoch<3\\0.00003, 3 \leqslant epoch<6\\0.000003, 6\leqslant epoch\end{cases}
new_learning_rate=⎩
⎨
⎧0.0003,0⩽epoch<30.00003,3⩽epoch<60.000003,6⩽epoch
NaturalExpDecay自然指数学习率衰减能够使学习率按自然指数衰减,其计算方式如下:
n
e
w
_
l
e
a
r
n
i
n
g
_
r
a
t
e
=
l
e
a
r
n
i
n
g
_
r
a
t
e
×
e
−
γ
×
e
p
o
c
h
new\_learning\_rate = learning\_rate × e ^{−γ×epoch}
new_learning_rate=learning_rate×e−γ×epoch
在GoogLeNet模型上训练的初始参数如下:
| 初始化参数设置 |
|---|
| BATCH_SIZE = 64 # 每批次的样本数 |
| EPOCHS = 10 # 训练轮数 |
| LOG_GAP = 200 # 输出训练信息的间隔 |
| weight_decay=0.00005 # 权重衰减 |
| INIT_LR = 0.0003 # 初始学习率 |
| LR_DECAY = 0.5 # 学习率衰减率 |
| step_size=50 # 衰减步长 |
| patience=3 # 早停 |
根据以上初始化参数,分别应用三种策略进行训练,结果如下:
| LR-Decay | Loss | top1-Acc |
|---|---|---|
| CosineAnnealingDecay | 0.0417 | 0.9923 |
| PiecewiseDecay | 0.0394 | 0.9927 |
| NaturalExpDecay | 0.0404 | 0.9922 |
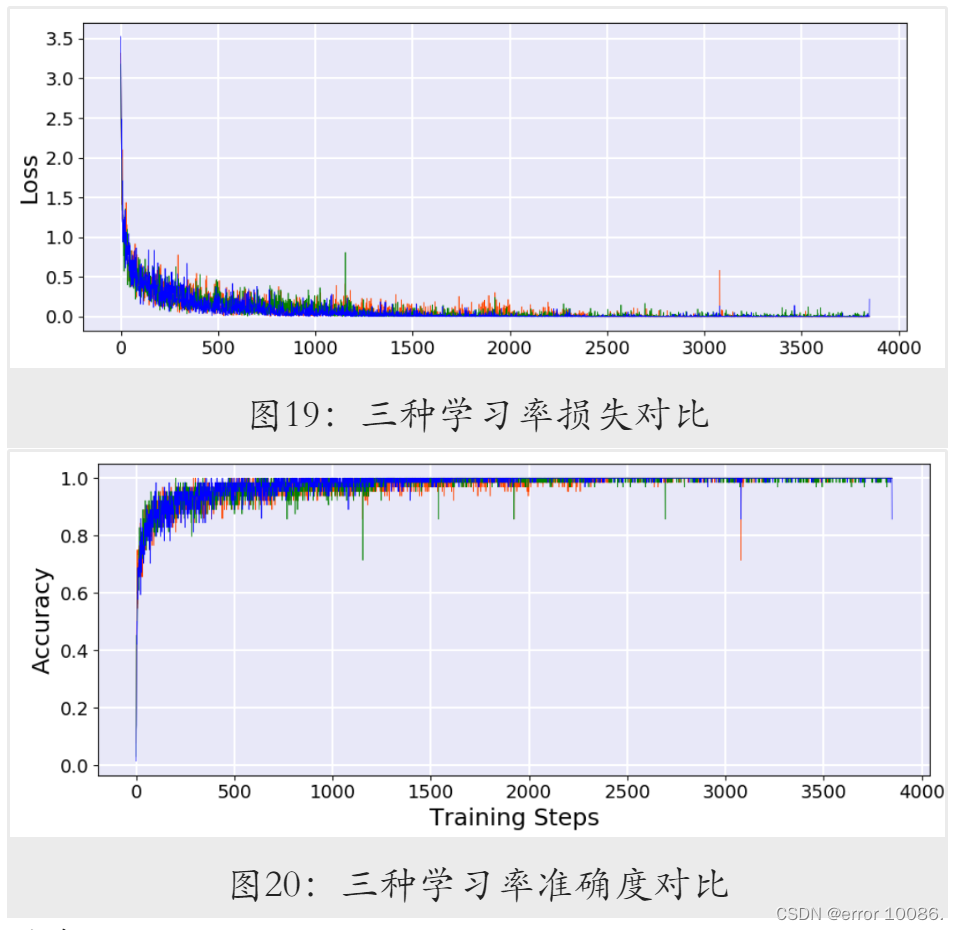
蓝色:NaturalExpDecay
绿色:PiecewiseDecay
橙色:CosineAnnealingDecay
根据表中结果,最佳准确率由PiecewiseDecay取得,三个模型训练过程的可视化结果如图19和图20所示。
4.3 最终模型评估
在优化后最终的模型评估结果为:
| Model | Loss | top1-Acc | top1-Acc |
|---|---|---|---|
| BetterAlexNet | 0.1683 | 0.9810 | 0.9985 |
| GoogleNet | 0.0394 | 0.9927 | 0.9992 |
5 实验总结
本次实验在应用新的模型进行训练的同时,还尝试了自己改进模型以及选择学习率衰减
策略,最终使用GoogLeNet在测试集上获得了99.27%的Top-1准确率与99.92%的Top-5准
确率,BetterAlexNet上获得了98.10%的Top-1准确率与99.85%的Top-5准确率。在实验过程中,我不断遇到各种问题,⼜不断通过查阅官⽅⽂档去解决问题,以这种方式加深了我对深度学习框架的理解。然而,实验仍存在许多可以优化的部分,在后续的实验中,我也将尽力去解决这些遗留问题,并尝试应用⼀些更为先进的模型进⾏训练。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









