







1 实验介绍
1.1 数据集介绍
本次实验使用百度与林业大学合作开发的林业病虫害防治项目中的昆虫数据集,AI识虫数据集结构如下:
- 提供了2183张图片,其中训练集1693张,验证集245,测试集245张。
- 包含7种昆虫,分别是Boerner、Leconte、Linnaeus、acuminatus、armandi、coleoptera和linnaeus。
- 包含了图片和标注,请读者先将数据解压,并存放在insects目录下。
将数据解压之后,可以看到insects目录下的结构如下所示。
insects
|---train
| |---annotations
| | |---xmls
| | |---100.xml
| | |---101.xml
| | |---...
| |
| |---images
| |---100.jpeg
| |---101.jpeg
| |---...
|
|---val
| |---annotations
| | |---xmls
| | |---1221.xml
| | |---1277.xml
| | |---...
| |
| |---images
| |---1221.jpeg
| |---1277.jpeg
| |---...
|
|---test
|---images
|---1833.jpeg
|---1838.jpeg
|---...
insects包含train、val和test三个文件夹。train/annotations/xmls目录下存放着图片的标注。每个xml文件是对一张图片的说明,包括图片尺寸、包含的昆虫名称、在图片上出现的位置等信息。
<annotation>
<folder>刘霏霏</folder>
<filename>100.jpeg</filename>
<path>/home/fion/桌面/刘霏霏/100.jpeg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1336</width>
<height>1336</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Boerner</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>500</xmin>
<ymin>893</ymin>
<xmax>656</xmax>
<ymax>966</ymax>
</bndbox>
</object>
<object>
<name>Leconte</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>622</xmin>
<ymin>490</ymin>
<xmax>756</xmax>
<ymax>610</ymax>
</bndbox>
</object>
<object>
<name>armandi</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>432</xmin>
<ymin>663</ymin>
<xmax>517</xmax>
<ymax>729</ymax>
</bndbox>
</object>
<object>
<name>coleoptera</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>624</xmin>
<ymin>685</ymin>
<xmax>697</xmax>
<ymax>771</ymax>
</bndbox>
</object>
<object>
<name>linnaeus</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>783</xmin>
<ymin>700</ymin>
<xmax>856</xmax>
<ymax>802</ymax>
</bndbox>
</object>
</annotation>
上面列出的xml文件中的主要参数说明如下:
- size:图片尺寸。
- object:图片中包含的物体,一张图片可能中包含多个物体。
- name:昆虫名称;
- bndbox:物体真实框;
- difficult:识别是否困难。
1.2 yolov3介绍
YOLOv3算法的基本思想可以分成两部分:
- 按一定规则在图片上产生一系列的候选区域,然后根据这些候选区域与图片上物体真实框之间的位置关系对候选区域进行标注。跟真实框足够接近的那些候选区域会被标注为正样本,同时将真实框的位置作为正样本的位置目标。偏离真实框较大的那些候选区域则会被标注为负样本,负样本不需要预测位置或者类别。
- 使用卷积神经网络提取图片特征并对候选区域的位置和类别进行预测。这样每个预测框就可以看成是一个样本,根据真实框相对它的位置和类别进行了标注而获得标签值,通过网络模型预测其位置和类别,将网络预测值和标签值进行比较,就可以建立起损失函数。
YOLOv3算法训练过程的流程图如 图1 所示:

图1:YOLOv3算法训练流程图
- **图1 左边是输入图片,上半部分所示的过程是使用卷积神经网络对图片提取特征,随着网络不断向前传播,特征图的尺寸越来越小,每个像素点会代表更加抽象的特征模式,直到输出特征图,其尺寸减小为原图的132321。
- **图1 下半部分描述了生成候选区域的过程,首先将原图划分成多个小方块,每个小方块的大小是32×3232×32,然后以每个小方块为中心分别生成一系列锚框,整张图片都会被锚框覆盖到。在每个锚框的基础上产生一个与之对应的预测框,根据锚框和预测框与图片上物体真实框之间的位置关系,对这些预测框进行标注。
- 将上方支路中输出的特征图与下方支路中产生的预测框标签建立关联,创建损失函数,开启端到端的训练过程。
2 实验过程
2.1 使用PaddlePaddle框架实现AI识虫
使用PaddlePaddle框架进行数据读取与预处理,以及YOLOv3模型的实现。使用到的数据增强操作包括:
- 随机改变图片亮度、对比度和颜色
- 随机填充
- 随机裁剪
- 随机缩放
- 随机翻转
- 随机打乱真实框排列顺序
YOLOv3的模型整体定义如下:
class YoloDetectionBlock(paddle.nn.Layer):
# define YOLOv3 detection head
# 使用多层卷积和BN提取特征
def __init__(self,ch_in,ch_out,is_test=True):
super(YoloDetectionBlock, self).__init__()
assert ch_out % 2 == 0, \
"channel {} cannot be divided by 2".format(ch_out)
self.conv0 = ConvBNLayer(
ch_in=ch_in,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.conv1 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
self.conv2 = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.conv3 = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
self.route = ConvBNLayer(
ch_in=ch_out*2,
ch_out=ch_out,
kernel_size=1,
stride=1,
padding=0)
self.tip = ConvBNLayer(
ch_in=ch_out,
ch_out=ch_out*2,
kernel_size=3,
stride=1,
padding=1)
def forward(self, inputs):
out = self.conv0(inputs)
out = self.conv1(out)
out = self.conv2(out)
out = self.conv3(out)
route = self.route(out)
tip = self.tip(route)
return route, tip
# 定义YOLOv3模型
class YOLOv3(paddle.nn.Layer):
def __init__(self, num_classes=7):
super(YOLOv3,self).__init__()
self.num_classes = num_classes
# 提取图像特征的骨干代码
self.block = DarkNet53_conv_body()
self.block_outputs = []
self.yolo_blocks = []
self.route_blocks_2 = []
# 生成3个层级的特征图P0, P1, P2
for i in range(3):
# 添加从ci生成ri和ti的模块
yolo_block = self.add_sublayer(
"yolo_detecton_block_%d" % (i),
YoloDetectionBlock(
ch_in=512//(2**i)*2 if i==0 else 512//(2**i)*2 + 512//(2**i),
ch_out = 512//(2**i)))
self.yolo_blocks.append(yolo_block)
num_filters = 3 * (self.num_classes + 5)
# 添加从ti生成pi的模块,这是一个Conv2D操作,输出通道数为3 * (num_classes + 5)
block_out = self.add_sublayer(
"block_out_%d" % (i),
paddle.nn.Conv2D(in_channels=512//(2**i)*2,
out_channels=num_filters,
kernel_size=1,
stride=1,
padding=0,
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(0., 0.02)),
bias_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Constant(0.0),
regularizer=paddle.regularizer.L2Decay(0.))))
self.block_outputs.append(block_out)
if i < 2:
# 对ri进行卷积
route = self.add_sublayer("route2_%d"%i,
ConvBNLayer(ch_in=512//(2**i),
ch_out=256//(2**i),
kernel_size=1,
stride=1,
padding=0))
self.route_blocks_2.append(route)
开启训练,查看训练过程日志。
![[Pasted image 20240115143248.png]]
之后进行模型评估,可分为两步:
- 通过网络输出计算预测框位置和所属类别的得分
- 使用非极大抑制来消除重叠较大的预测框
测试程序:
# 计算IoU,矩形框的坐标形式为xyxy,这个函数会被保存在box_utils.py文件中
def box_iou_xyxy(box1, box2):
# 获取box1左上角和右下角的坐标
x1min, y1min, x1max, y1max = box1[0], box1[1], box1[2], box1[3]
# 计算box1的面积
s1 = (y1max - y1min + 1.) * (x1max - x1min + 1.)
# 获取box2左上角和右下角的坐标
x2min, y2min, x2max, y2max = box2[0], box2[1], box2[2], box2[3]
# 计算box2的面积
s2 = (y2max - y2min + 1.) * (x2max - x2min + 1.)
# 计算相交矩形框的坐标
xmin = np.maximum(x1min, x2min)
ymin = np.maximum(y1min, y2min)
xmax = np.minimum(x1max, x2max)
ymax = np.minimum(y1max, y2max)
# 计算相交矩形行的高度、宽度、面积
inter_h = np.maximum(ymax - ymin + 1., 0.)
inter_w = np.maximum(xmax - xmin + 1., 0.)
intersection = inter_h * inter_w
# 计算相并面积
union = s1 + s2 - intersection
# 计算交并比
iou = intersection / union
return iou
import json
import os
ANCHORS = [10, 13, 16, 30, 33, 23, 30, 61, 62, 45, 59, 119, 116, 90, 156, 198, 373, 326]
ANCHOR_MASKS = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
VALID_THRESH = 0.01
NMS_TOPK = 400
NMS_POSK = 100
NMS_THRESH = 0.45
NUM_CLASSES = 7
if __name__ == '__main__':
TRAINDIR = '/home/aistudio/work/insects/train/images'
TESTDIR = '/home/aistudio/work/insects/test/images'
VALIDDIR = '/home/aistudio/work/insects/val'
model = YOLOv3(num_classes=NUM_CLASSES)
params_file_path = '/home/aistudio/yolo_epoch0'
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
total_results = []
test_loader = test_data_loader(TESTDIR, batch_size= 1, mode='test')
for i, data in enumerate(test_loader()):
img_name, img_data, img_scale_data = data
img = paddle.to_tensor(img_data)
img_scale = paddle.to_tensor(img_scale_data)
outputs = model.forward(img)
bboxes, scores = model.get_pred(outputs,
im_shape=img_scale,
anchors=ANCHORS,
anchor_masks=ANCHOR_MASKS,
valid_thresh = VALID_THRESH)
bboxes_data = bboxes.numpy()
scores_data = scores.numpy()
result = multiclass_nms(bboxes_data, scores_data,
score_thresh=VALID_THRESH,
nms_thresh=NMS_THRESH,
pre_nms_topk=NMS_TOPK,
pos_nms_topk=NMS_POSK)
for j in range(len(result)):
result_j = result[j]
img_name_j = img_name[j]
total_results.append([img_name_j, result_j.tolist()])
print('processed {} pictures'.format(len(total_results)))
print('')
json.dump(total_results, open('pred_results.json', 'w'))
初步尝试后,发现结果不够理想,检查原始代码发现,训练过程中的 MAX_EPOCH 参数被设置为1,模型实际上只训练了一轮。将该参数修改为10后再次开启训练,并进行评估,训练耗时约90分钟,结果如下图所示。可以看到,训练结果仍不够理想,且最终预测时未输出任何预测框,因此选择将 MAX_EPOCH 参数改回1,重新进行练和预测。
![[Pasted image 20240115143750.png|300]]
为直观展示模型效果,选择读取单张图片并绘制模型在其上产生的预测框,以对模型的效果进行可视化展示。

可见效果并不是很好
2.2 使用PaddleX框架实现AI识虫
2.2.1 安装paddlx库
!pip install paddlex
!pip install --user --upgrade pyarrow==11.0.0
2.2.2 数据预处理
- MixupImage:
mixup_epoch=-1:应用 Mixup 数据增强,这是一种通过混合两个图像来生成新的训练样本的技术。mixup_epoch=-1表示在所有训练周期中都应用 Mixup。
- RandomDistort:
- 随机扭曲图像,增加训练数据的多样性。
- RandomExpand:
- 随机扩展图像,通过填充值
[123.675, 116.28, 103.53]进行填充。有助于增加模型对输入图像边界的鲁棒性。
- 随机扩展图像,通过填充值
- RandomCrop:
- 随机裁剪图像,增加训练数据的多样性。
- RandomHorizontalFlip:
- 随机水平翻转图像,增加训练数据的多样性。
- BatchRandomResize:
- 随机调整图像尺寸,可选择多个目标尺寸
[320, 352, 384, 416, 448, 480, 512, 544, 576, 608],并使用随机的插值方法。
- 随机调整图像尺寸,可选择多个目标尺寸
- Normalize:
- 将图像进行标准化,使用均值
[0.485, 0.456, 0.406]和标准差[0.229, 0.224, 0.225]进行归一化。
定义数据处理流程,其中训练集和验证集需分别定义,训练过程包括了部分测试过程中不需要的数据增强操作,如在本示例中,训练过程使用了MixupImage、RandomDistort、RandomExpand、RandomCrop和RandomHorizontalFlip共5种数据增强方式。
- 将图像进行标准化,使用均值
import paddlex as pdx
from paddlex import transforms as T
train_transforms = T.Compose([
T.MixupImage(mixup_epoch=250), T.RandomDistort(),
T.RandomExpand(im_padding_value=[123.675, 116.28, 103.53]), T.RandomCrop(),
T.RandomHorizontalFlip(), T.BatchRandomResize(
target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608],
interp='RANDOM'), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
eval_transforms = T.Compose([
T.Resize(
608, interp='CUBIC'), T.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
2.2.3 定义数据集Dataset
目标检测可使用VOCDetection格式和COCODetection两种数据集,此处由于数据集为VOC格式,因此采用pdx.datasets.VOCDetection来加载数据集。
train_dataset = pdx.datasets.VOCDetection(
data_dir='insects/train',
file_list='insects/train/train_list.txt',
label_list='insects/train/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='insects/train',
file_list='insects/train/val_list.txt',
label_list='insects/train/labels.txt',
transforms=eval_transforms,
shuffle=False)
2.2.4 yolov3实验过程
1模型选择
使用YOLOv3模型,DarkNet53网络
num_classes = len(train_dataset.labels)
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
2 YOLO检测模型的预置anchor生成
anchors = train_dataset.cluster_yolo_anchor(num_anchors=9, image_size=480)
anchor_masks = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
3 模型训练
![![[Pasted image 20240115221431.png]]](https://i-blog.csdnimg.cn/blog_migrate/fcabfbb6e656c8fb5d1658140b67792f.png)
num_classes = len(train_dataset.labels)
model = pdx.det.YOLOv3(
num_classes=num_classes,
backbone='DarkNet53',
anchors=anchors.tolist() if isinstance(anchors, np.ndarray) else anchors,
anchor_masks=[[6, 7, 8], [3, 4, 5], [0, 1, 2]],
label_smooth=True,
ignore_threshold=0.6)
model.train(
num_epochs=10, # 训练轮次
train_dataset=train_dataset, # 训练数据
eval_dataset=eval_dataset, # 验证数据
train_batch_size=16, # 批大小
pretrain_weights='COCO', # 预训练权重,刚开始训练的时候取消该注释,注释resume_checkpoint
learning_rate=0.005 / 12, # 学习率
warmup_steps=500, # 预热步数
warmup_start_lr=0.0, # 预热起始学习率
save_interval_epochs=5, # 每5个轮次保存一次,有验证数据时,自动评估
lr_decay_epochs=[85, 135], # step学习率衰减
save_dir='output/yolov3_darknet53', # 保存路径
#resume_checkpoint='output/yolov3_darknet53', # 断点继续训练
use_vdl=True) # 其用visuadl进行可视化训练记录
训练过程:
![![[Pasted image 20240115233042.png]]](https://i-blog.csdnimg.cn/blog_migrate/370ab6eab0dc3f1aae0905a1a8c5c9f2.png)
验证集训练结果:
![![[Pasted image 20240115231258.png]]](https://i-blog.csdnimg.cn/blog_migrate/3f1674601573a3b04b6dcd9ae5cf7a5a.png)
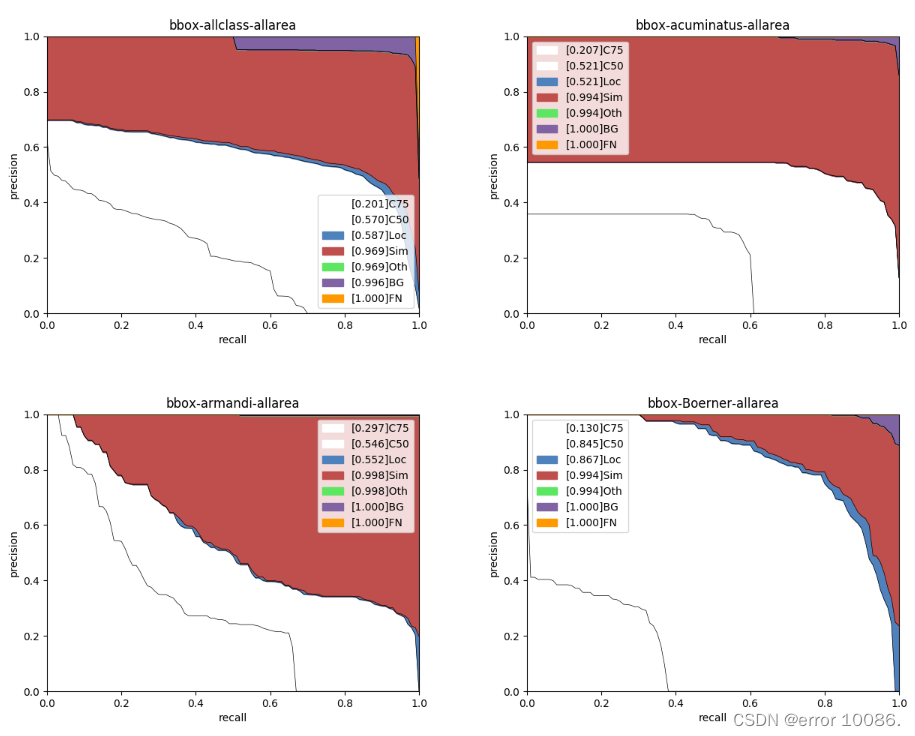
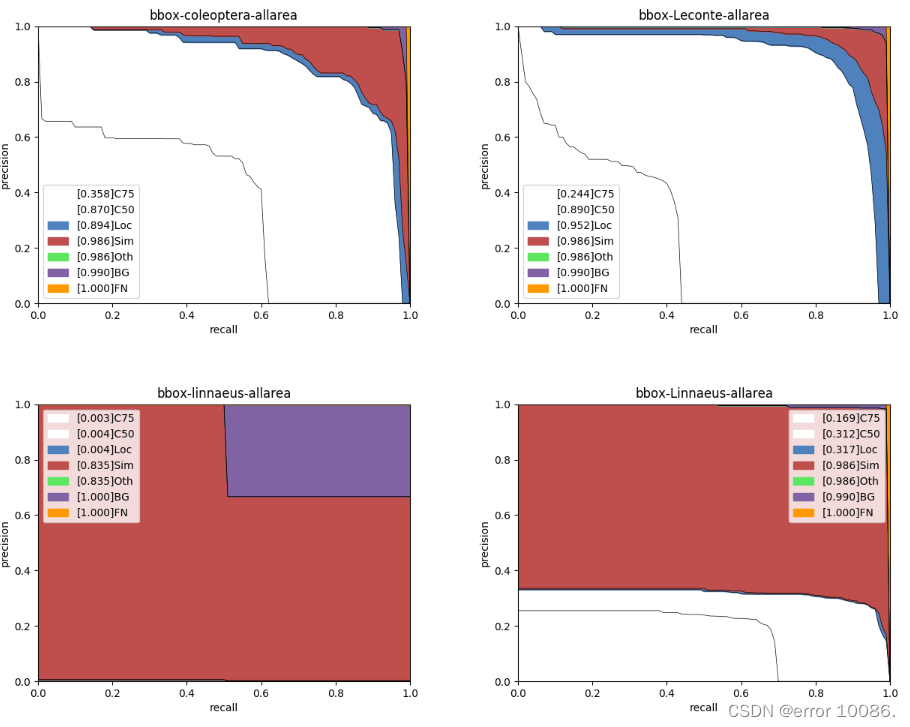
分析图表展示了7条Precision-Recall(PR)曲线,每一条曲线表示的Average Precision (AP)比它左边那条高,原因是逐步放宽了评估要求。以Leconte类为例,各条PR曲线的评估要求解释如下:
- C75: 在IoU设置为0.75时的PR曲线, AP为0.244。
- C50: 在IoU设置为0.5时的PR曲线,AP为0.890。C50与C75之间的白色区域面积代表将IoU从0.75放宽至0.5带来的AP增益。
- Loc: 在IoU设置为0.1时的PR曲线,AP为0.952。Loc与C50之间的蓝色区域面积代表将IoU从0.5放宽至0.1带来的AP增益。蓝色区域面积越大,表示越多的检测框位置不够精准。
- Sim: 在Loc的基础上,如果检测框与真值框的类别不相同,但两者同属于一个亚类,则不认为该检测框是错误的,在这种评估要求下的PR曲线, AP为0.986。Sim与Loc之间的红色区域面积越大,表示子类间的混淆程度越高。VOC格式的数据集所有的类别都属于同一个亚类。
- Oth: 在Sim的基础上,如果检测框与真值框的亚类不相同,则不认为该检测框是错误的,在这种评估要求下的PR曲线,AP为0.986。Oth与Sim之间的绿色区域面积越大,表示亚类间的混淆程度越高。VOC格式的数据集中所有的类别都属于同一个亚类,故不存在亚类间的混淆。
- BG: 在Oth的基础上,背景区域上的检测框不认为是错误的,在这种评估要求下的PR曲线,AP为0.990。BG与Oth之间的紫色区域面积越大,表示背景区域被误检的数量越多。
- FN: 在BG的基础上,漏检的真值框不认为是错误的,在这种评估要求下的PR曲线,AP为1.00。FN与BG之间的橙色区域面积越大,表示漏检的真值框数量越多。
**从上述结果可以看出训练集中除了Leconate外的六类均有很高的混淆程度,并且在数据集的标签中出现了linnaeus和Linnaeus两种类别的虫子,我并不清楚这两种类别的虫子有什么区别,我怀疑是数据集名字存在问题,并且可以看到linnaeus这一类的AP基本为0,说明这一类的数据集是有问题的。**在验证集中表现程度相对较好的是Boerner、coleoptera、Leconte,这三类的AP分别达到了0.845、0.870、0.890.
4 模型预测
import paddlex as pdx
model = pdx.load_model('output/yolov3_darknet53/best_model')
image_name = '/home/aistudio/insects/val/JPEGImages/1221.jpeg'
result = model.predict(image_name)
print(result)
pdx.det.visualize(image_name, result, threshold=0.3, save_dir='./output/yolov3_darknet53/predict')
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(cv2.imread("/home/aistudio/output/yolov3_darknet53/predict/visualize_1221.jpeg"))
![![[visualize_1221.jpeg|500]]](https://i-blog.csdnimg.cn/blog_migrate/496555dbf397e9e48002f15c4f0206a3.png)
2.3 使用yolov5训练模型
!pip install paddlex -i https://mirror.baidu.com/pypi/simple
!unzip /home/aistudio/PaddleYOLO-develop.zip -d /home/aistudio
!pip install --user --upgrade pyarrow==11.0.0
!unzip -oq /home/aistudio/data/data257193/insects.zip -d /home/aistudio
%cd PaddleYOLO-develop/
!pip install -r requirements.txt --user
#改名字用的函数,paddlex需要文件名是Annotations和JPEGIamges,但是这个数据集里是annotations和images
import os
import shutil
def rename_folder(original_folder_path, new_folder_name):
new_folder_path = os.path.join(os.path.dirname(original_folder_path), new_folder_name)
# 创建新的目标文件夹
os.mkdir(new_folder_path)
# 移动文件夹中的文件到新的目标文件夹
file_list = os.listdir(original_folder_path)
for file_name in file_list:
file_path = os.path.join(original_folder_path, file_name)
shutil.move(file_path, new_folder_path)
# 删除原始文件夹
os.rmdir(original_folder_path)
import os
import shutil
old_name = '/home/aistudio/insects/train/annotations'
new_name = 'Annotations'
rename_folder(old_name,new_name)
old_name = '/home/aistudio/insects/train/images'
new_name = 'JPEGImages'
rename_folder(old_name,new_name)
old_name = '/home/aistudio/insects/val/annotations'
new_name = 'Annotations'
rename_folder(old_name,new_name)
old_name = '/home/aistudio/insects/val/images'
new_name = 'JPEGImages'
rename_folder(old_name,new_name)
#voc转coco,下面那个cell一样的效果作用在测试集上
!paddlex --split_dataset --format VOC --dataset_dir /home/aistudio/insects/train --val_value 0.001
!python /home/aistudio/PaddleYOLO-develop/tools/x2coco.py\
--dataset_type voc\
--voc_anno_dir /home/aistudio/insects/train\
--voc_anno_list /home/aistudio/insects/train/train_list.txt\
--voc_label_list /home/aistudio/insects/train/labels.txt\
--voc_out_name /home/aistudio/insects/train/coco.json
#1.训练(单卡/多卡),加 --eval 表示边训边评估,加 --amp 表示混合精度训练
!python /home/aistudio/PaddleYOLO-develop/tools/train.py -c /home/aistudio/PaddleYOLO-develop/configs/yolov5/yolov5_s_300e_coco.yml --use_vdl=True --vdl_log_dir=/home/aistudio/work --eval
训练过程:
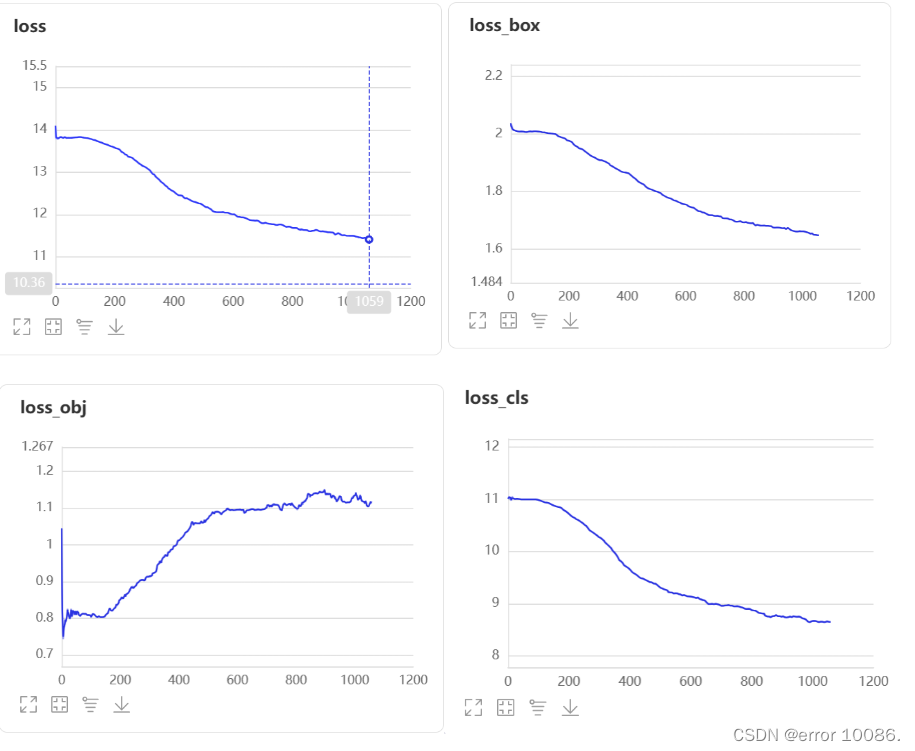
yolov5最终的AP仅有35.5,效果不是很好,可能是学习率选择不好。
3 模型优化
3.1 基线模型选择
相较于二阶段检测模型,单阶段检测模型的精度略低但是速度更快。考虑到是部署到GPU端,本案例选择单阶段检测模型YOLOV3作为基线模型,其骨干网络选择DarkNet53。训练完成后,模型在验证集上的精度如下:
| 模型 | 推理时间 (ms/image) | map(Iou-0.5) |
|---|---|---|
| baseline: YOLOv3 + DarkNet53 + cluster_yolo_anchor + img_size(480) | 50.34 | 57.0 |
3.2 基线模型效果分析与优化
使用PaddleX提供的paddlex.det.coco_error_analysis接口对模型在验证集上预测错误的原因进行分析,分析结果以图表的形式展示如下:
数据增强选择
| 训练预处理1(a1) | 验证预处理 |
|---|---|
| MixupImage(mixup_epoch=-1) | Resize(target_size=480, interp=‘CUBIC’) |
| RandomDistort() | Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) |
| RandomExpand(im_padding_value=[123.675, 116.28, 103.53]) | |
| RandomCrop() | |
| RandomHorizontalFlip() | |
| BatchRandomResize(target_sizes=[320, 352, 384, 416, 448, 480, 512, 544, 576, 608],interp=‘RANDOM’) | |
| Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) | |
考虑到定位问题,通过尝试放大图片,不同的网络结构以及定位的优化策略: 利用cluster_yolo_anchor生成聚类的anchor或开启iou_aware。最终得到上线模型PPYOLOV2的精度如下: |
| 模型 | 推理时间 (ms/image) | map(Iou-0.5) |
|---|---|---|
| PPYOLOV2 + ResNet50_vd_dcn + img_size(608) | 81.52 | 59.3 |
| baseline: YOLOv3 + DarkNet53 + cluster_yolo_anchor + img_size(480) | 50.34 | 57.0 |
| baseline: YOLOv3 +MobileNetV1 + cluster_yolo_anchor + img_size(480) | 72.3 | 57.4 |
| baseline: YOLOv3 + MobileNetV3 + cluster_yolo_anchor + img_size(480) | 75.3 | 58.1 |
在加入了RandomHorizontalFlip、RandomDistort、RandomCrop、RandomExpand、BatchRandomResize、MixupImage这几种数据增强方法后,对模型的优化是有一定的积极作用了,在取消这些预处理后,模型性能会有一定的下降。
4 模型评估
- 1.通过选择更好的backbone作为特征提取的骨干网络可以提高识别率、降低漏检率。
- 2.通过选择更好的检测架构可以提高检测的mmap值——即Neck,Head部分的优化可以提高ap。
- 3.缩放适当的图像大小可以提高模型的识别率,但是存在一定的阈值——当图像大小到某一个阈值时会导致精度下降。
- 一般图像大小选择(YOLO系列):320,480, 608。
- 一般图像如果较大,物体也比较大,可以较为放心的缩小图像大小再进行相关的训练和预测。
- 物体较小,不易缩小,可以适当的裁剪划分原图或放大,并处理对应的标注数据,再进行训练。
- 4.通过cluster_yolo_anchor生成当前网络输入图像大小下拟合数据集的预置anchors,利用新生成的anchors替换原来的默认anchor,使得模型预测定位上框选位置更准确。
5 实验总结
- 本次实验尝试使用YOLOv3模型完成目标检测任务,相对于分类任务,目标检测任务的难度较高,需要同时进行分类与预测框生成,老师提供的样例十分详细,在逐段阅读并运行项目的过程中,我也对目标检测任务的基本思想与总体流程有了较为清晰的认知。
- 为简化开发流程,我尝试引入PaddleX框架进行实验。可以看到,通过使用现有的框架,个人的工作量大大降低,项目代码量也大幅度减少。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









