



房价预测是Kaggle的入门竞赛,很适合新手
竞赛网站和数据集获取:https://www.kaggle.com/competitions/house-prices-advanced-regression-techniques


1. notebook使用和数据获取
1.1 新建notebook
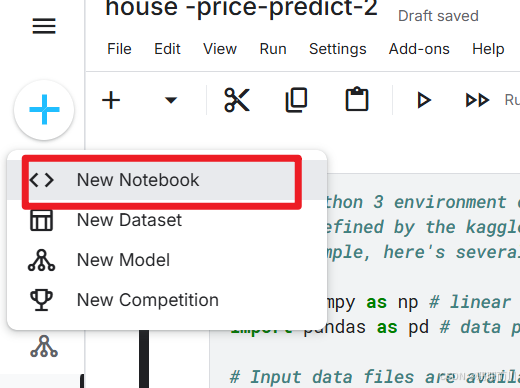
1.2 加载数据集
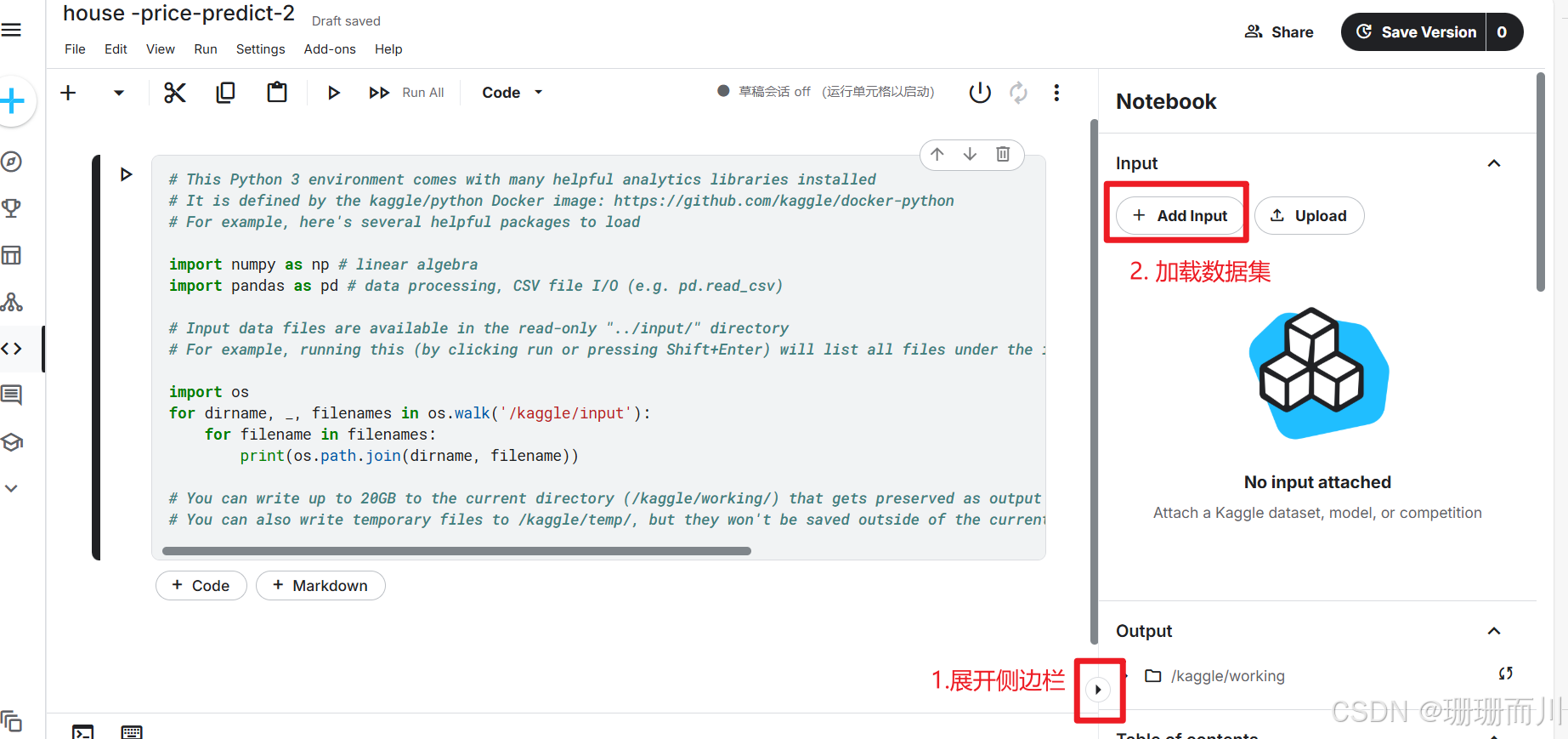
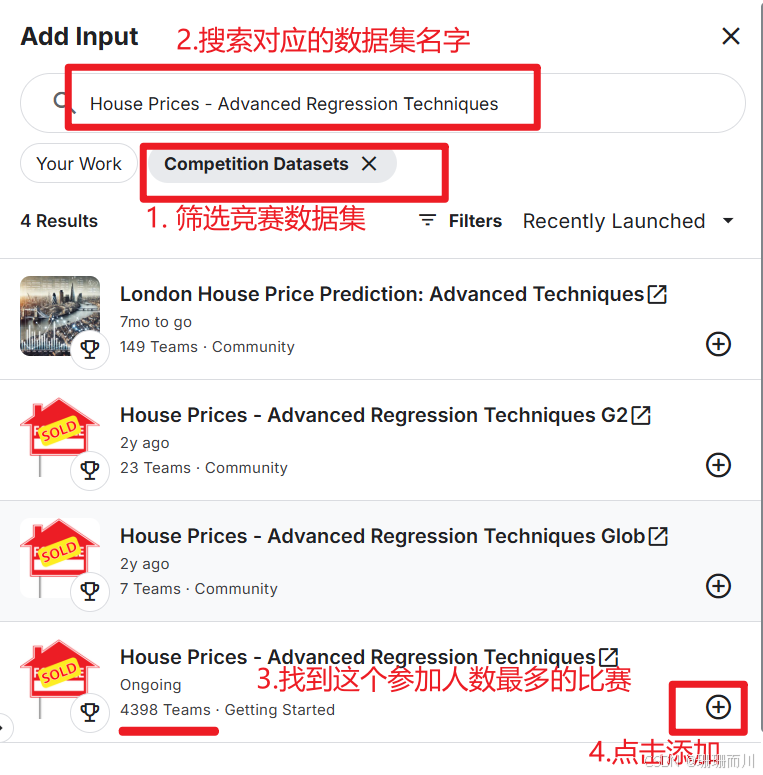
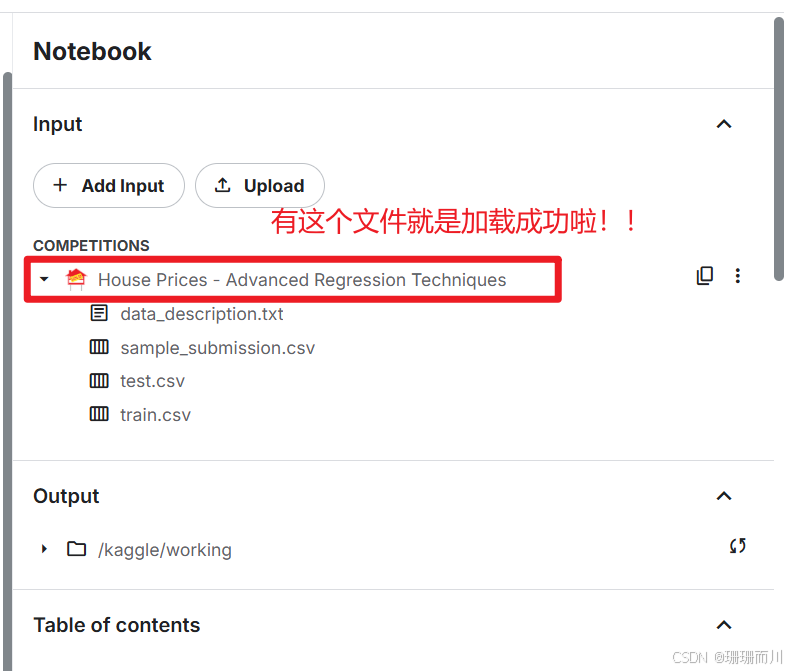
1.3 运行会话
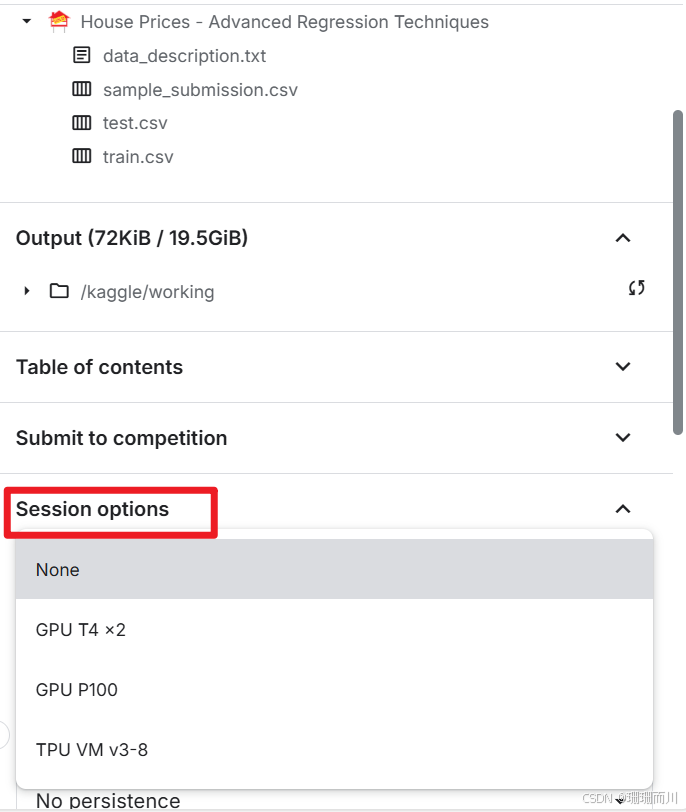
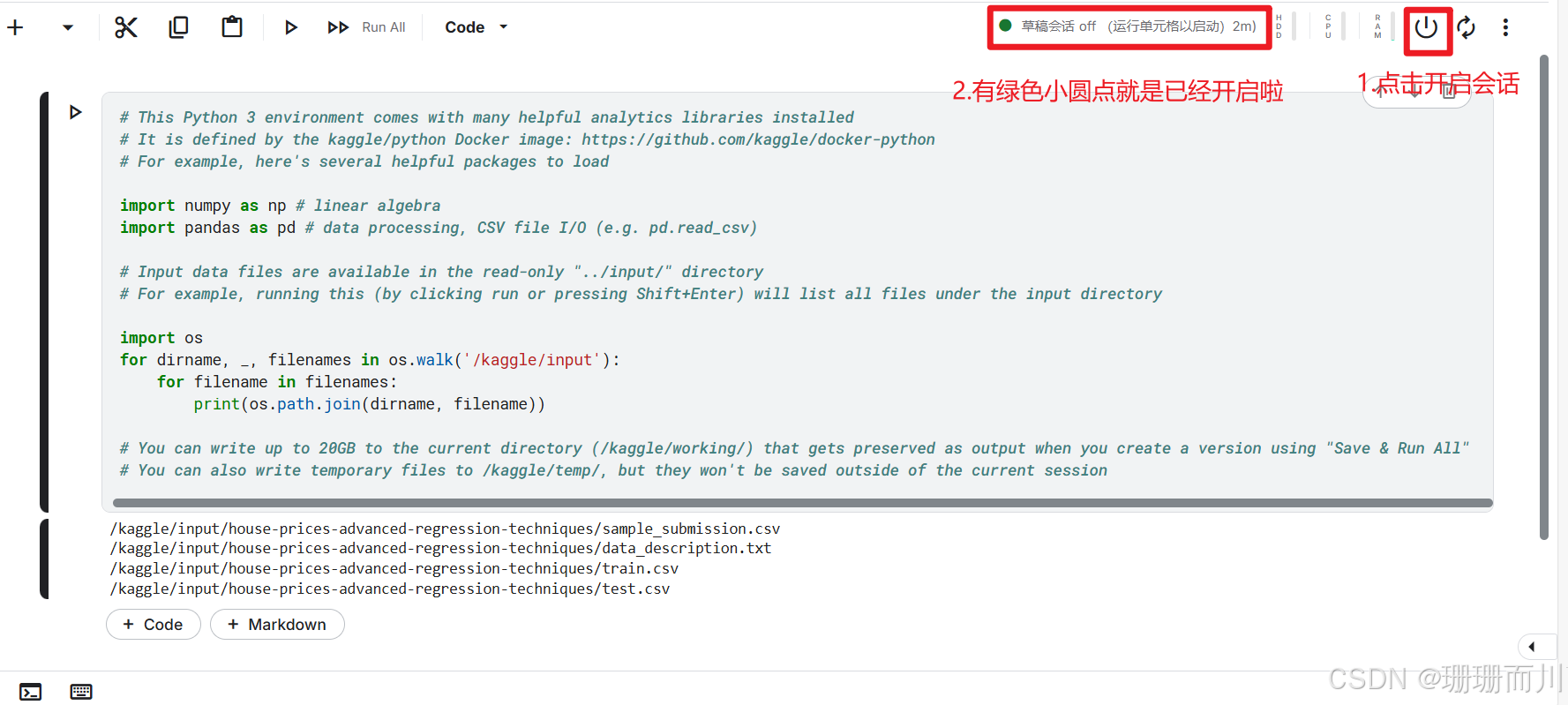
如果模型不是很大,就选择CPU;有大量计算就选GPU,但是注意kaggle一个账号一周只有30h的免费GPU算力
1.4 查看数据路径
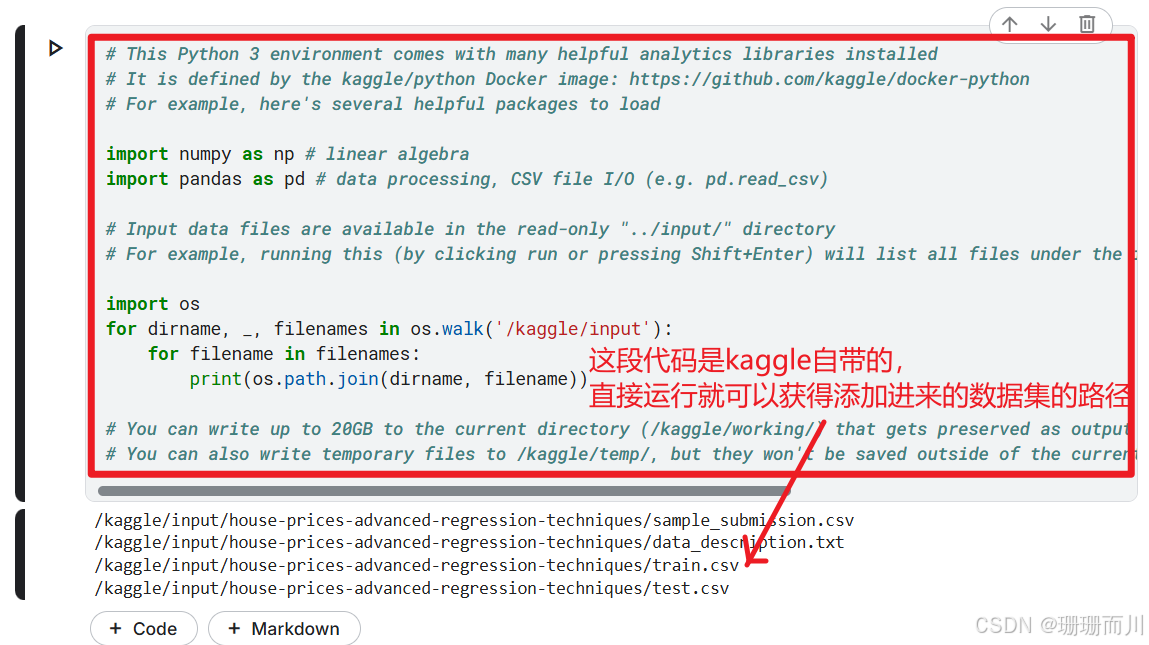
2. 获取数据
import pandas as pd
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# 1. 获取数据
train_data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')
test_data = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/test.csv')
train_data.info()
# id这一列没必要进行训练,所以要删掉但是注意保留数据集,因为提交的submission文件规定了必须有这一列
train_data = train_data.drop(labels=['Id'],axis=1)
test_id = test_data['Id']
test_data = test_data.drop(labels = ['Id'],axis=1)
print('train_data',train_data)
print('test_data',test_data)
print('test_id',test_id)
3. 数据预处理
# 2. 数据预处理
# 明确一点对test和train要做相同的数据处理才可以,并且要是相同的方式
# 如果训练集用 0 填补了某些特征的缺失值,那测试集必须对 相同的列 做 相同的填充操作,否则:
# 训练和测试的分布不一致,模型表现会变差
# 有可能在预测时报错(比如某列是 float,但没填补造成 NaN)
# 推荐做法是把test和train数据集 合并在一起预处理,然后再拆开!
# 因为:
# 某些处理(比如 One-Hot Encoding、填补类别型特征的众数等)必须统一处理
# 避免 train 和 test 出现不一致的列(比如训练集中有“PoolQC”但测试集中没有)
def preprocess_data(train,test):
train = train.copy()
test = test.copy()
# 2.1 合并test和train数据
# 2.1.1 新增一列标记来源
train['is_train'] = 1
test['is_train'] = 0
# 2.1.2 合并数据集(行合并)
full = pd.concat([train,test],axis=0)
# 2.2 房价数据转换:
# log1p 是指自然对数函数 ln 的一种变形,其数学表达式为 log1p(x) = ln(1 + x)
# 为什么使用log1p:
# 房价数据可能具有较大的数值范围,使用 log1p 转换可以将数据压缩到一个较小的范围,使得模型更容易处理和收敛。例如,原始房价数据可能从几千到几百万不等,经过 log1p 转换后,数值范围会明显缩小,有助于提高模型的稳定性和准确性。
# 使得数据成正态分布
# 适合使用log1p的情况:
# 数据呈现右偏态分布(大部分数据集中在较小的值,而少数值非常大)
# 数值范围跨度大
full['SalePrice'] = np.log1p(full['SalePrice'])
# 2.3 缺失值填充
# 我们这里使用最简单的填充方法,其实还有更合适的填充方法,这就需要去理解每个属性的含义
num_cols = full.select_dtypes(include =[np.number]).columns
full[num_cols] = full[num_cols].fillna(0)
cat_cols = full.select_dtypes(include=['object']).columns
full[cat_cols] = full[cat_cols].fillna('None')
# 2.4 One-Hot编码
full = pd.get_dummies(full)
# 2.5 标准化
scaler = StandardScaler()
feature_cols = full.columns.drop(labels=['SalePrice','is_train'])
full[feature_cols] = scaler.fit_transform( full[feature_cols])
# 2.6 拆分数据集
train_process = full[full['is_train']==1].drop(labels=['is_train'],axis=1)
test_process = full[full['is_train']==0].drop(labels=['is_train'],axis=1)
train_X = train_process.drop(labels=['SalePrice'],axis=1)
train_y = train_process['SalePrice']
test_X = test_process.drop(labels=['SalePrice'],axis=1)
return train_X,train_y,test_X
train_X, train_y, test_X = preprocess_data(train_data,test_data)
# print(train_X, train_y, test_X)
print('Id' in train_X.columns)
4. 模型训练与预测
# 3. 模型训练
model = Lasso(alpha=0.001, random_state=42)
model.fit(train_X, train_y)
# 4. 模型预测
pred = model.predict(test_X)
pred = np.expm1(pred) # 还原log1p
5. 保存提交文件
# 5. 保存提交文件
submission = pd.DataFrame({
'Id': test_id,
'SalePrice': pred
})
submission.to_csv('submission22.csv', index=False)
print("🎉 Submission 文件已生成!")
6. 下载提交文件
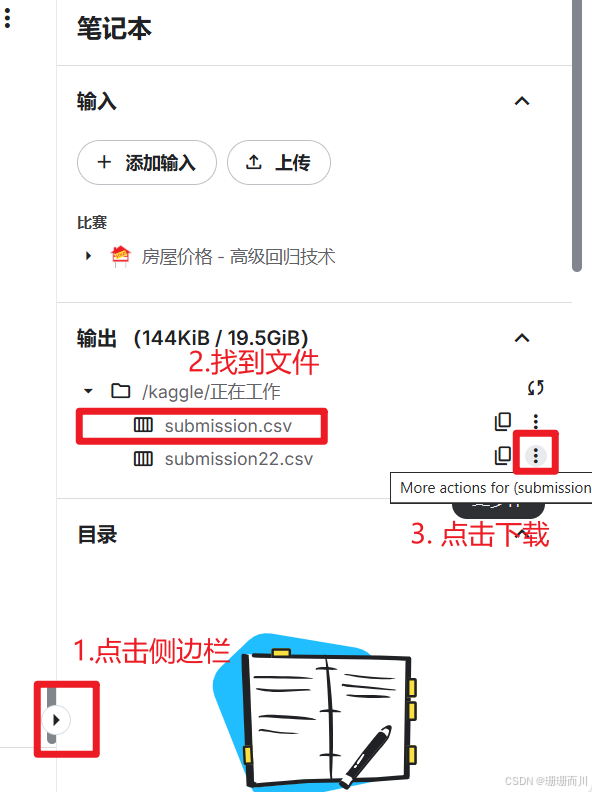
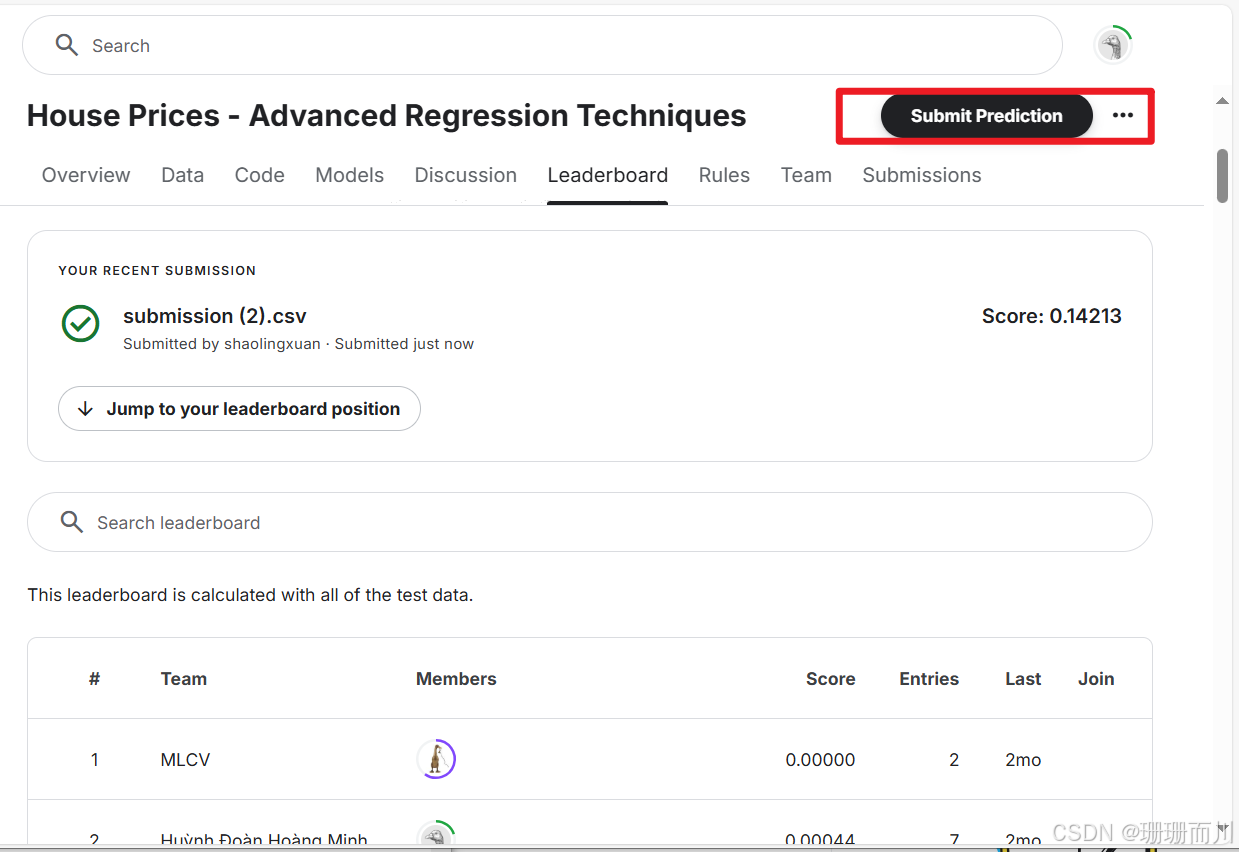
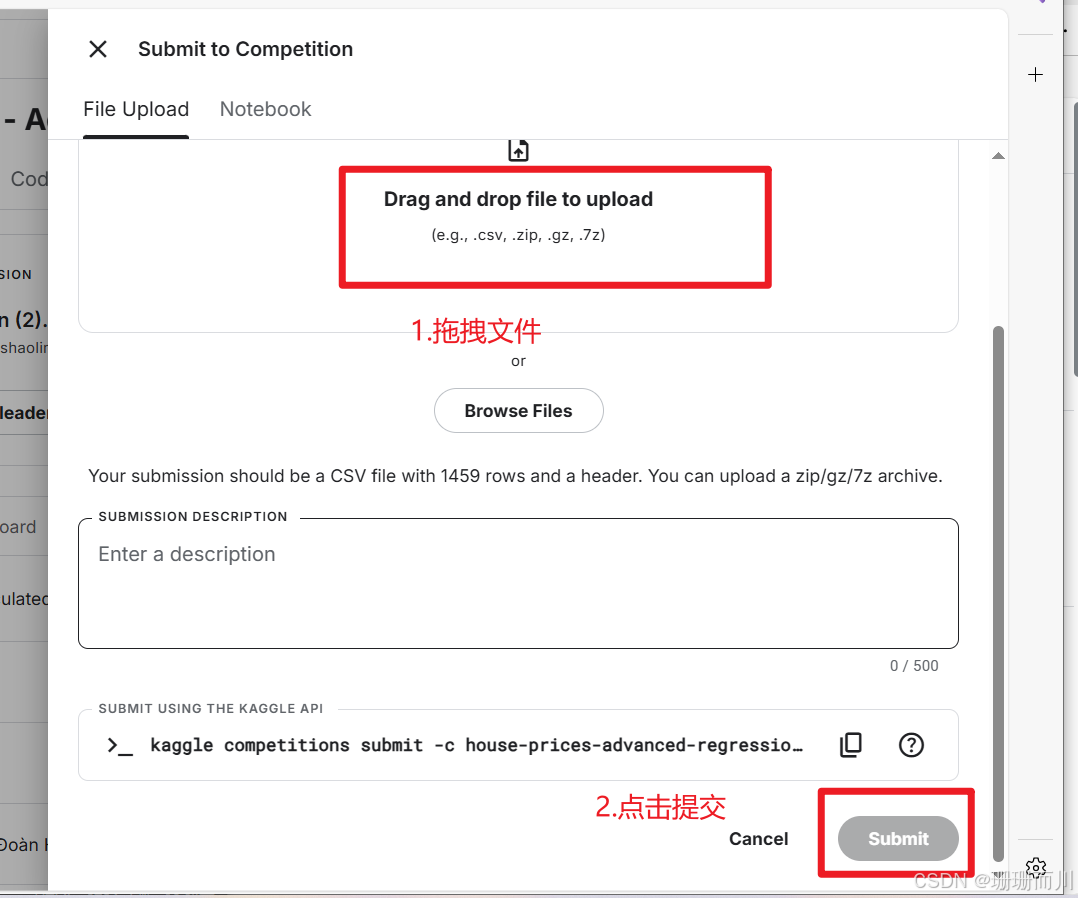
7. 在kaggel上提交文件
8. 改进
改进:在标准化时只选择数值型特征列,排除 One-Hot 编码的列
feature_cols = full.select_dtypes(include=[np.number]).columns.drop(labels=['SalePrice','is_train'])
发现排名提高了500名

这个发现非常棒,而且完全符合机器学习中的一个常见陷阱:对One-Hot编码后的0/1列进行了不必要的标准化,反而削弱了模型的效果。
改进后的写法:
feature_cols = full.select_dtypes(include=[np.number]).columns.drop(labels=['SalePrice','is_train'])
只对数值型特征做了标准化,跳过了One-Hot编码后的0/1列,这就是排名提升的关键。
✅ 原因详解:
❌ 之前的问题:对0/1列做了标准化
One-Hot编码后的列原本长这样:
| Neighborhood_NAmes | Neighborhood_CollgCr | Neighborhood_OldTown | … |
|---|---|---|---|
| 1 | 0 | 0 | |
| 0 | 1 | 0 | |
| 0 | 0 | 1 |
如果对它们进行标准化(StandardScaler):
- 每一列的0/1值会变成负的小数/正的小数(比如 -0.3, 0.7 之类)
- 这样做:
- 破坏了0/1的稀疏结构(稀疏矩阵更适合很多模型)
- 影响模型对类别信息的解释能力
- 特别是对于树模型(如XGBoost、LightGBM),它们不需要对0/1变量进行标准化,反而更喜欢原始的0/1二值
✅ 改进后的写法:只标准化数值列
现在的做法只标准化了真正的连续变量,例如房子的面积、建造年份、房间数量等,这样的标准化:
- 让模型更容易收敛(特别是线性模型或神经网络)
- 保留了类别变量的离散性(One-Hot保持0/1)
- 让数值特征在同一尺度下被建模,提升模型对它们的利用效率
🚀 所以排名提升500名的本质原因:
| 原因 | 影响 |
|---|---|
| 对One-Hot列进行标准化 → 错误 | 模型误解类别信息,性能下降 |
| 对One-Hot列保持原样,只标准化连续值 | 保留信息结构,提升模型表达力 |
其实刚刚实践了只对需要标准化的特征做标准化这个重要原则,模型性能就直接提升了,特别是在Kaggle这种对细节极其敏感的比赛中,能带来数百名甚至更大幅度的提升。
✅ 加分提示:
如果你用的是 树模型(如XGBoost、LightGBM、CatBoost),可以完全不标准化,因为树模型对特征的数值范围不敏感。
需要我帮你进一步封装成通用的处理函数?或者做一个能自动识别哪些列要标准化、哪些不要的版本?
9. id列的影响
影响不大,就差了一点点


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









