







| 标题 | Strengthening Evolution-Based Differential Evolution with Prediction Strategy for Multimodal Optimization and Its Application in Multi-Robot Task Allocation |
|---|---|
| 作者 | Hong Zhao; Ling Tang; JiaRui Li; Jing Liu |
| 机构 | Xidian University |
| 邮箱 | damtle@163.com |
| 论文 | https://www.sciencedirect.com/science/article/pii/S1568494623002363 |
摘要
许多现实世界中的问题可以被认为是多模态优化问题(MMOP),这需要定位尽可能多的全局最优解,并尽可能提高所找到的最优解的精度。然而,现有的MMOP求解算法存在一些问题。例如,现有的大多数方法都采用贪婪选择策略来选择后代,这可能会导致一些个体陷入局部最优,而对这些局部最优的重复评估将耗尽许多适应度评估(FE)。此外,许多MMOP的评估往往很昂贵,在数量有限的FE中,合理分配评估资源以更好地处理MMOP是一个关键挑战。如何在整个进化过程中合理地分配FE,以及如何避免个体陷入局部最优是解决MMOP的两个关键问题。因此,本文提出了一种基于增强进化的差分进化预测策略(SEDE-PS)来求解MMOPs,并验证了它在多机器人任务分配(MRTA)问题中的性能,它有以下三个贡献。首先,提出了一种基于邻居的进化预测(NEP)策略,通过尽可能多地利用个体的历史信息来预测个体在下一代中的位置。其次,将基于预测的变异(PM)策略与NEP策略相结合,以加速收敛。第三,提出了一种强化进化(SE)策略,选择较差的个体对其进行多次无条件进化,使其接近全局最优或跳出局部最优。我们在广泛使用的CEC’2013基准上,将SEDE-PS与最先进的多模态优化算法进行了比较。实验结果表明,SEDE-PS的性能等于或优于这些比较算法。此外,将SEDE-PS应用于真实世界的多机器人任务分配问题,结果进一步验证了SEDE-PS的有效性。
算法简介
SEDE-PS的流程图如图1所示。实线表示标准差分进化算法(DE)的过程,虚线表示SEDE-PS中提出的新策略。NEP策略与PM和SE策略结合,以增强后者的搜索能力。在执行选择策略之后,根据结果更新预测以提高预测过程的准确性。
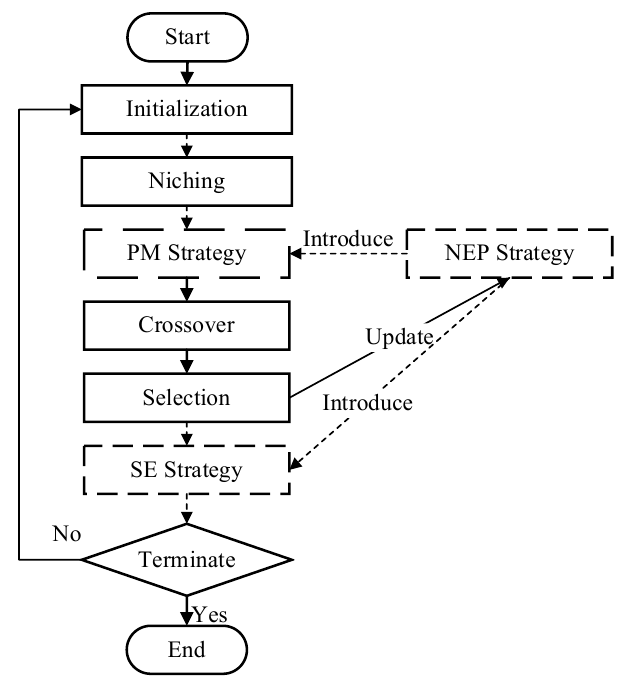
具体来说,SEDE-PS主要包括以下三个贡献点:
1)NEP策略利用前几代个体的进化特征来预测他们的下一个进化方向。与传统的预测方法相比,该策略是从一些邻域个体中提取个体的历史进化信息,这有助于这些个体减少盲目进化的可能,加速收敛。
2)提出了PM策略,通过在变异过程中引入预测方法来引导变异方向,加快收敛速度。在进化的早期阶段,PM策略利用NEP策略生成新的个体,扩大搜索范围。在进化的后期,NEP策略的比重降低,以提高算法的精确搜索能力。
3)SE策略合理地将更多的FE分配给较差的个体,通过扩大搜索范围来平衡种群的平均进化速度。此外,SE策略采用无条件进化方法,使劣化个体在没有评估的情况下多次进化,有效地减少了FE的消耗,使劣性个体能够跳出局部最优。
多模态问题定义

SEDE-PS
NEP
预测方法利用进化过程的历史信息来预测个体的未来位置。一种广泛使用的预测方法预测一个平移向量,然后将该向量与先前的位置相加:

根据预测方法,个体的历史进化趋势由每个个体的历史信息变化决定,可以用来预测个体在下一代将如何变化。然而,在非动态问题中,预测方法很少被提及,因为仅仅依靠一个个体的历史进化信息无法反映真实的进化方向,而且是偶然的。如图2所示,三角形代表一个全局峰值,个体的适应度与到峰值的距离呈线性正相关。
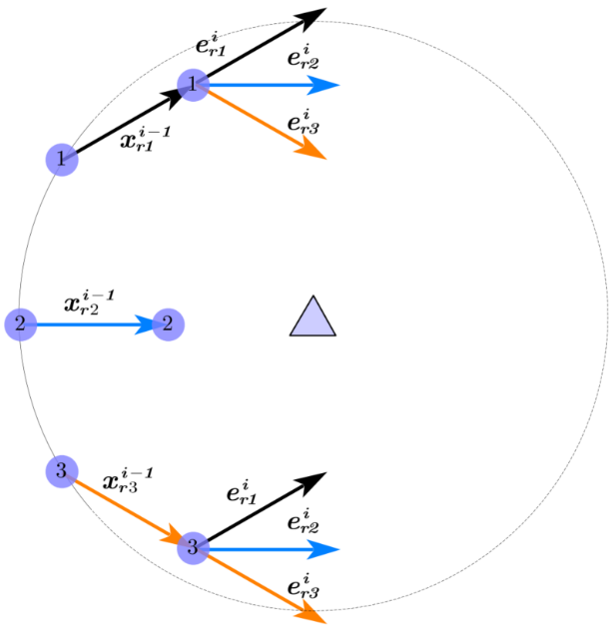

总的来说,NEP策略可以减少单一个体预测的偶然性所造成的演化误差,充分利用种群邻域内的历史信息,有效引导个体的进化过程,加速种群收敛。
PM
在标准DE的基础上,将NEP引入突变策略。由于后期预测向量过大,可能会阻碍物种的顺利进化,因此预测向量的比例应随着进化代数的增加而降低。即使预测向量使个体的进化过程暂时接近停滞,它也会在不断更新的过程中自适应调整:

SE
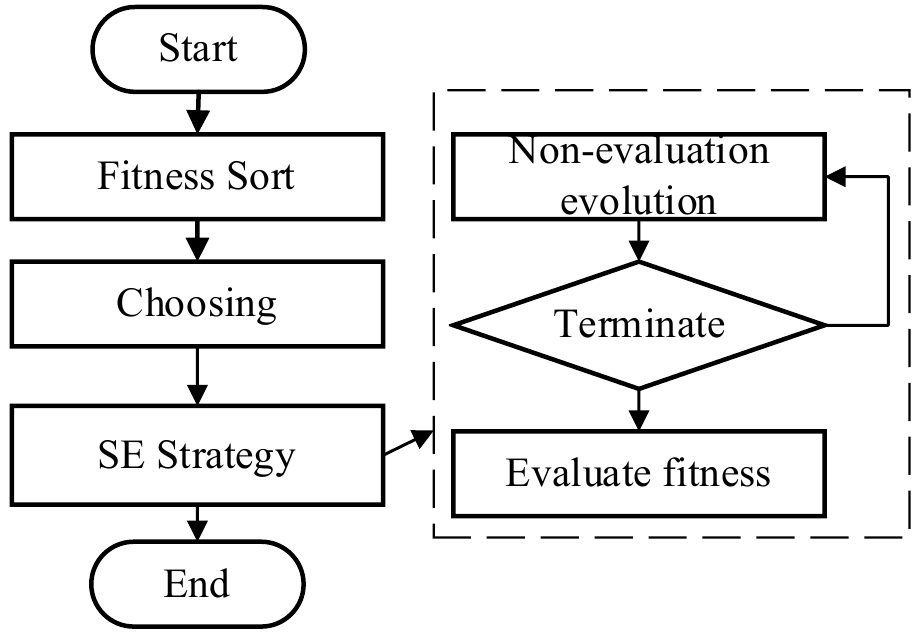
在每一代结束之前,整个种群中的劣势个体在SE的引导下没有评估的进行多次进化,即一旦产生了一个新的个体,我们就直接选择这个新的个体进入下一代。SE策略是在新个体的生成完成时执行的,这可以减少由局部最优引起的FE的浪费。SE策略的流程图如图所示。

实验结果
经典算法对比
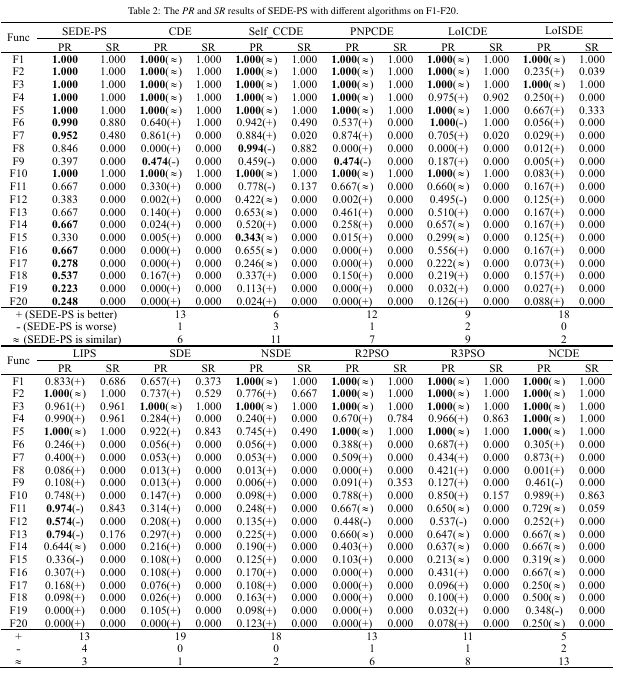
不同精度下与新近算法对比
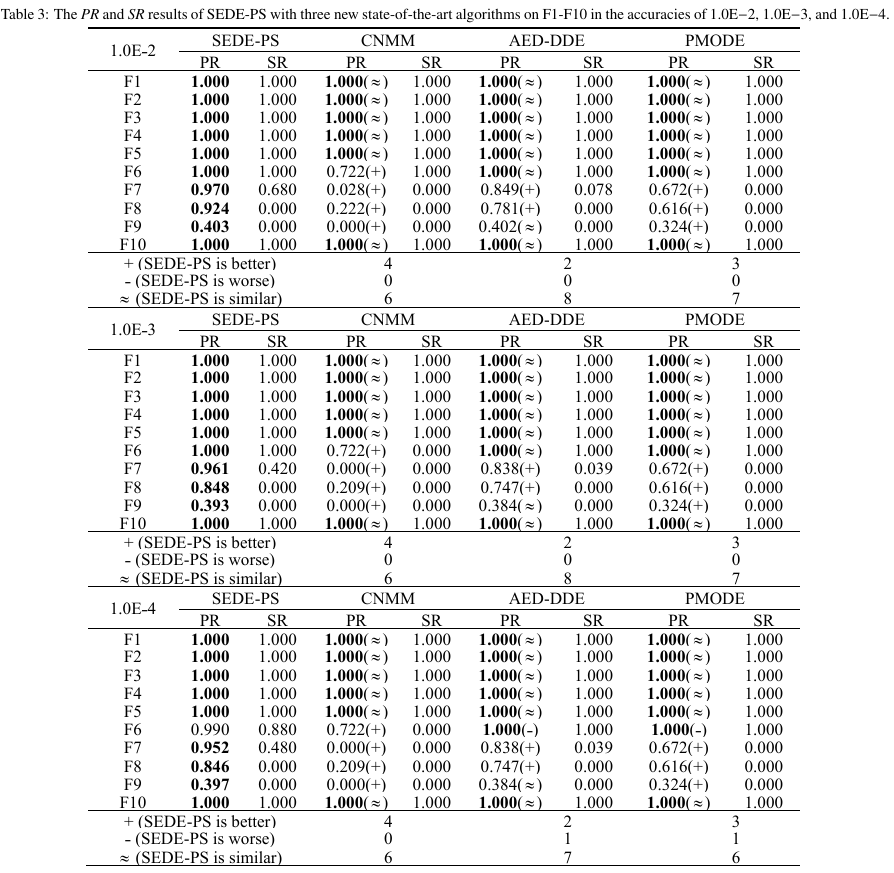
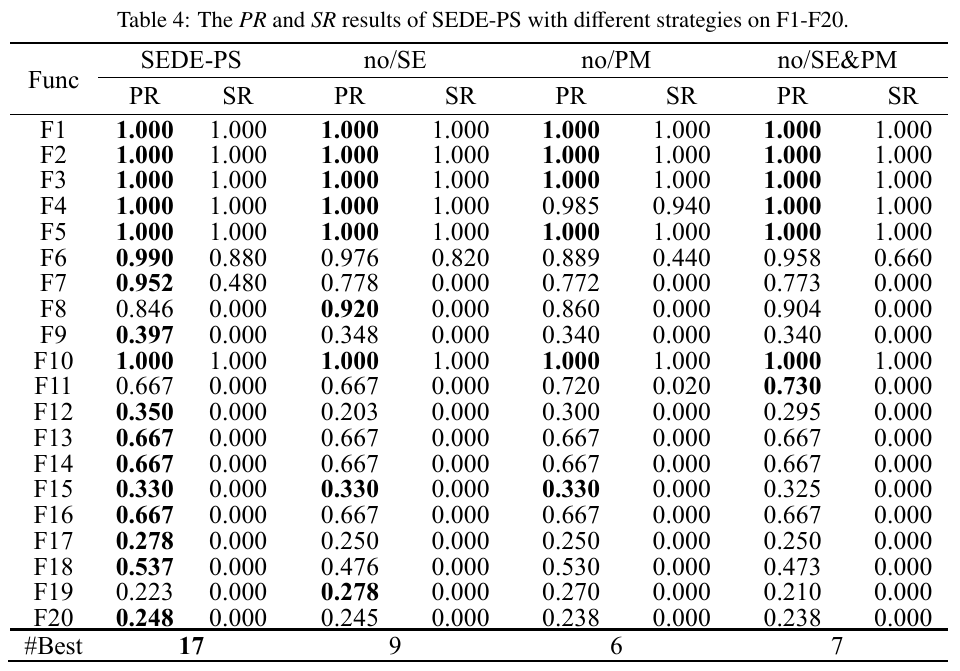
策略消融实验
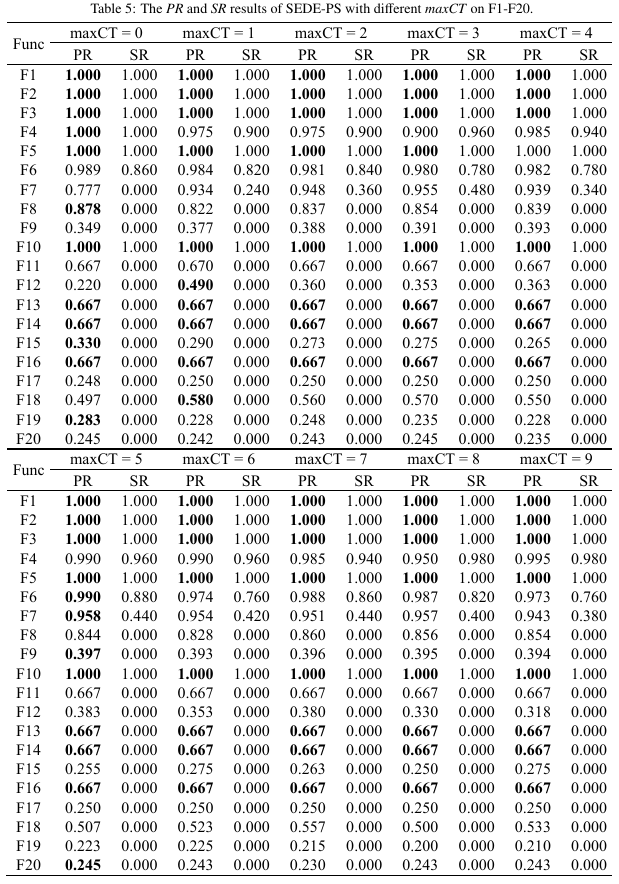
参数分析
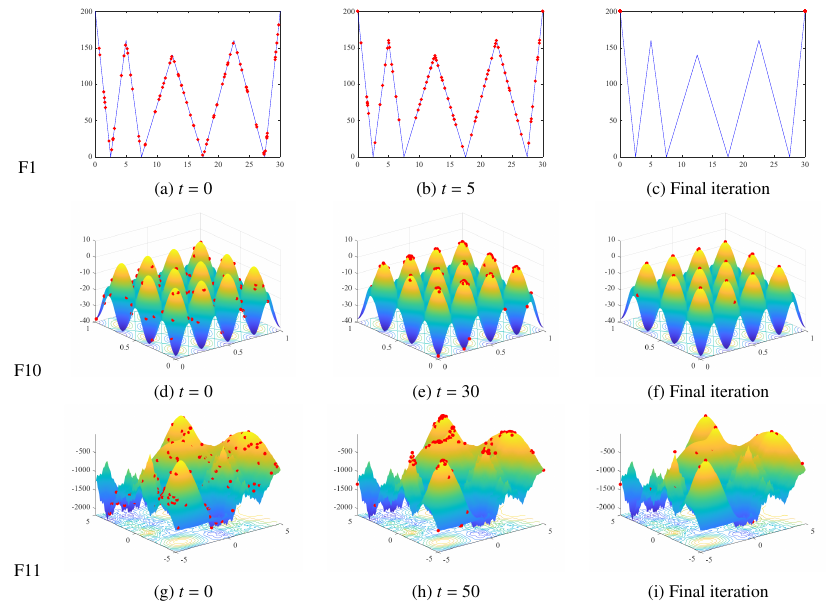
收敛景观图
ST-SR-IA

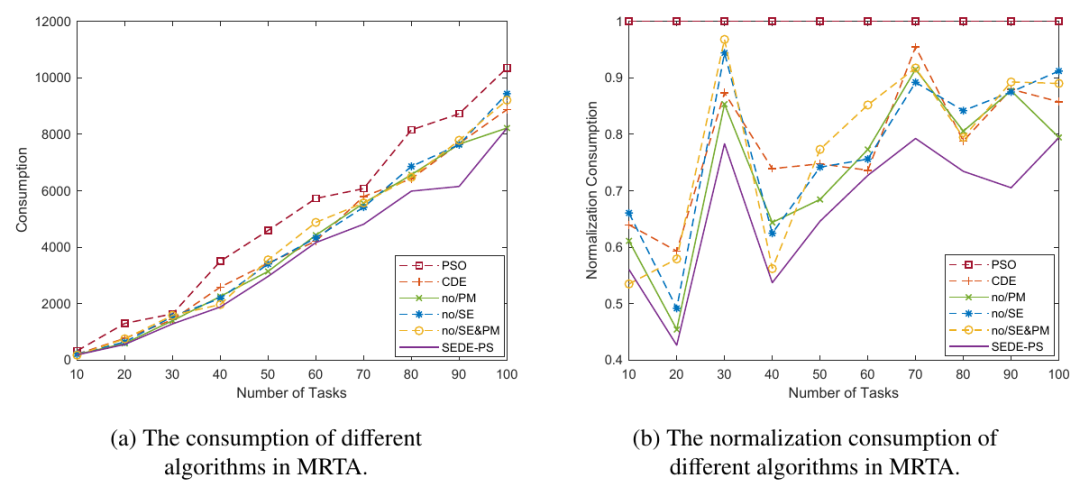
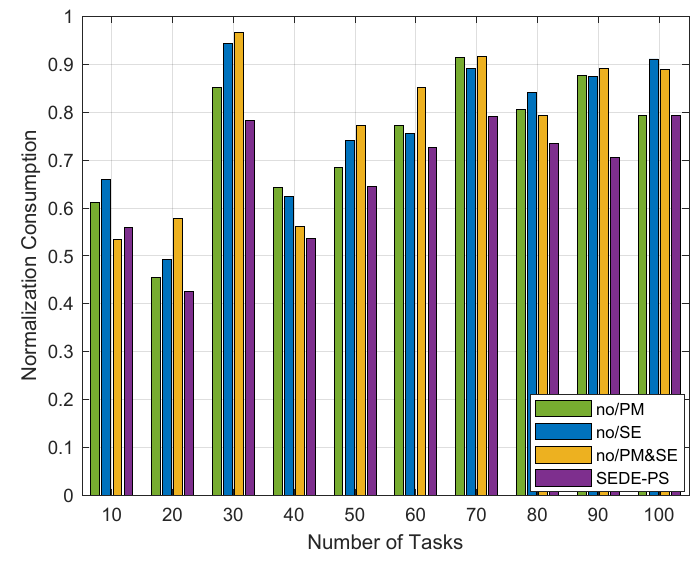
实验结果表面,提出的SEDE-PS在算法对比和消融实验上均取得了很好的效果。
ST-SR-TA

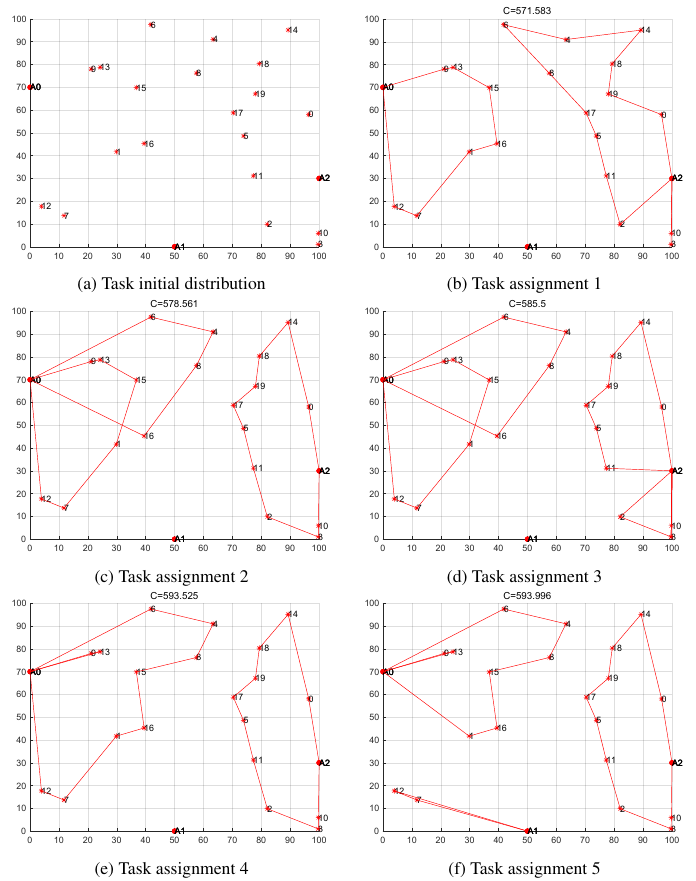
图中,(a)表示任务和机器人的初始分布,(b)-(f)显示了五种不同的分配方案,它们是SEDE-PS获得的分配方案中最优的五种资源消耗方案。在五种分配方案中,机器人的具体实现方式和相应的任务不同,这表明SEDE-PS能够适应各种不利情况,并合理地解决现实世界中的问题。例如,与方案3相比,方案4选择了大部分长路径,而方案3更均匀地分配路径。因此,当机器人的剩余功率较低,并且无法实现平均路径消耗下的任务时,我们选择方案4,使功率较大的机器人完成大部分任务,而功率较小的机器人可以完成需要较少资源消耗的任务。尽管方案4的资源消耗高于方案3,但与机器人无法完成任务相比,这种消耗是可以接受的。
此外,我们发现在A1站分配给机器人的任务很少。原因是该场景中的任务分布与A1不太相关。将任务分配给其他工作站的成本比将任务分配到A1的成本小得多。因此,将任务分配给它会浪费资源。这也表明,SEDE-PS展示了根据实际消耗将任务分配给机器人的优势,而不是仅仅因为有机器人站就将任务分配到机器人站。此外,车站的机器人最终充电时间更长,这使它们能够完成后续任务。
总结
本文提出了一种基于加强进化和预测策略的差分进化算法来更好地处理MMOPs和现实世界中的MRTA问题,其三个关键技术是NEP策略、PM策略和SE策略。首先,引入了NEP策略,以减少传统单一个体预测方法的不利影响。其次,PM策略利用当前个体的历史信息来引导进化方向,加速种群的收敛。第三,SE策略有助于合理分配FE,并为陷入局部最优的个体提供了跳出局部最优的可能。与几种最先进的多模态优化算法相比,所提出的SEDE-PS在CEC’2013基准测试中表现出更好的性能。对于MRTA问题,传统方法的实施需要几个耗时的步骤(例如,收集数据、构建模型、评估解决方案)。这个过程消耗了相当多的时间,因此可能会延迟任务的完成。使用SEDE-PS,可以预先获得一组覆盖机器人站中不同协作模式和执行路径的策略。无论可用于决策的机器人数量如何变化,这种组合策略都可以轻松选择合理且低资源消耗的解决方案。















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









