






一、网络结构
1、经典的全连接神经网络
其包含四层网络:输入层、两个隐含层和输出层。
- 输入层:将数据输入给神经网络。在该任务中,输入层的尺度为28×28的像素值。
- 隐含层:增加网络深度和复杂度,隐含层的节点数是可以调整的,节点数越多,神经网络表示能力越强,参数量也会增加。在该任务中,中间的两个隐含层为10×10的结构,通常隐含层会比输入层的尺寸小,以便对关键信息做抽象,激活函数使用常见的Sigmoid函数。
- 输出层:输出网络计算结果,输出层的节点数是固定的。如果是回归问题,节点数量为需要回归的数字数量。如果是分类问题,则是分类标签的数量。在该任务中,模型的输出是回归一个数字,输出层的尺寸为1。
手写数字识别任务的全连接神经网络:
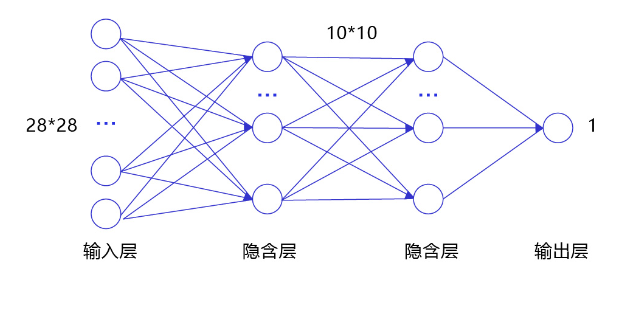
说明:隐含层引入非线性激活函数Sigmoid是为了增加神经网络的非线性能力。(Sigmoid是早期神经网络模型中常见的非线性变换函数 )
缺点:使用经典的全连接神经网络可以提升一定的准确率,但其输入数据的形式导致丢失了图像像素间的空间信息,这影响了网络对图像内容的理解
2.、卷积神经网络(善于处于图像的网络)
网络结构优化,可以直接处理原始形式的图像数据,保留像素间的空间信息,因此更适合处理视觉问题。
卷积神经网络由多个卷积层和池化层组成
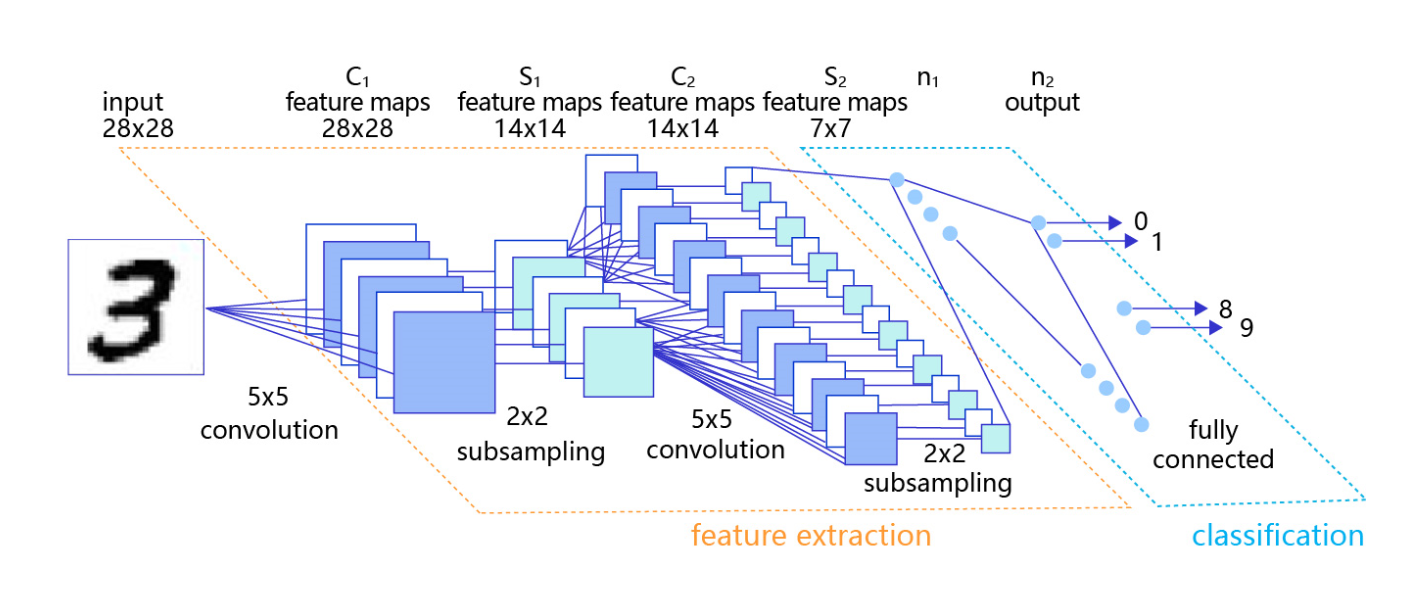
- 卷积层负责对输入进行扫描以生成更抽象的特征表示。
- 池化层对这些特征表示进行过滤,保留最关键的特征信息。
二、损失函数
损失函数的三步:
- 先根据输入数据正向计算预测输出。
- 再根据预测值和真实值计算损失。
- 最后根据损失反向传播梯度并更新参数。
Softmax函数:
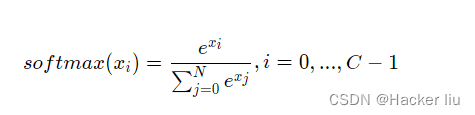
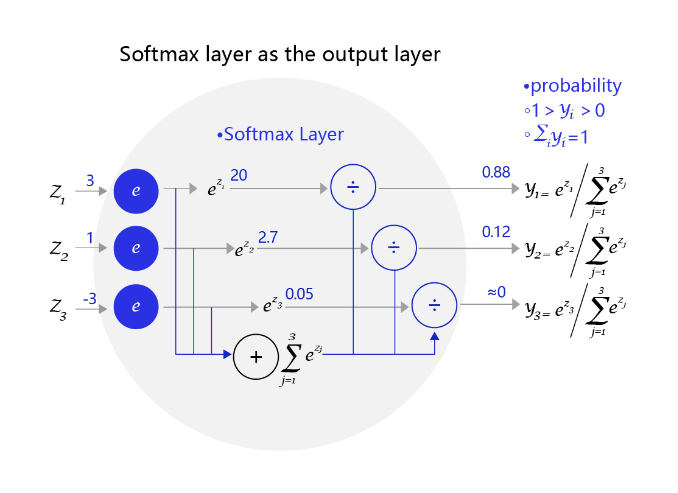
图3:网络输出层改为softmax函数

交叉熵:(主要用于度量两个概率分布间的差异性信息)
在模型输出为分类标签的概率时,直接以标签和概率做比较也不够合理,人们更习惯使用交叉熵误差作为分类问题的损失衡量。
交叉熵损失函数的设计是基于最大似然思想:最大概率得到观察结果的假设是真的。
三、优化算法
学习率:
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。(当学习率最优时,模型的有效容量最大,最终能达到的效果最好。)
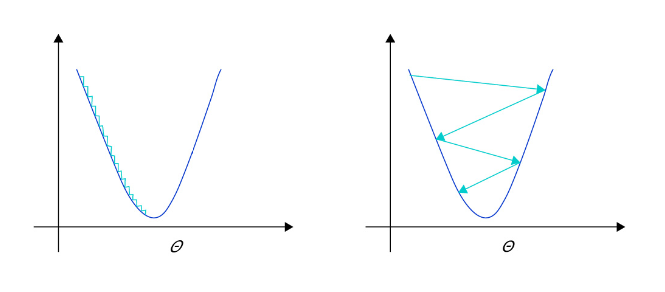
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如右图所示。
四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam
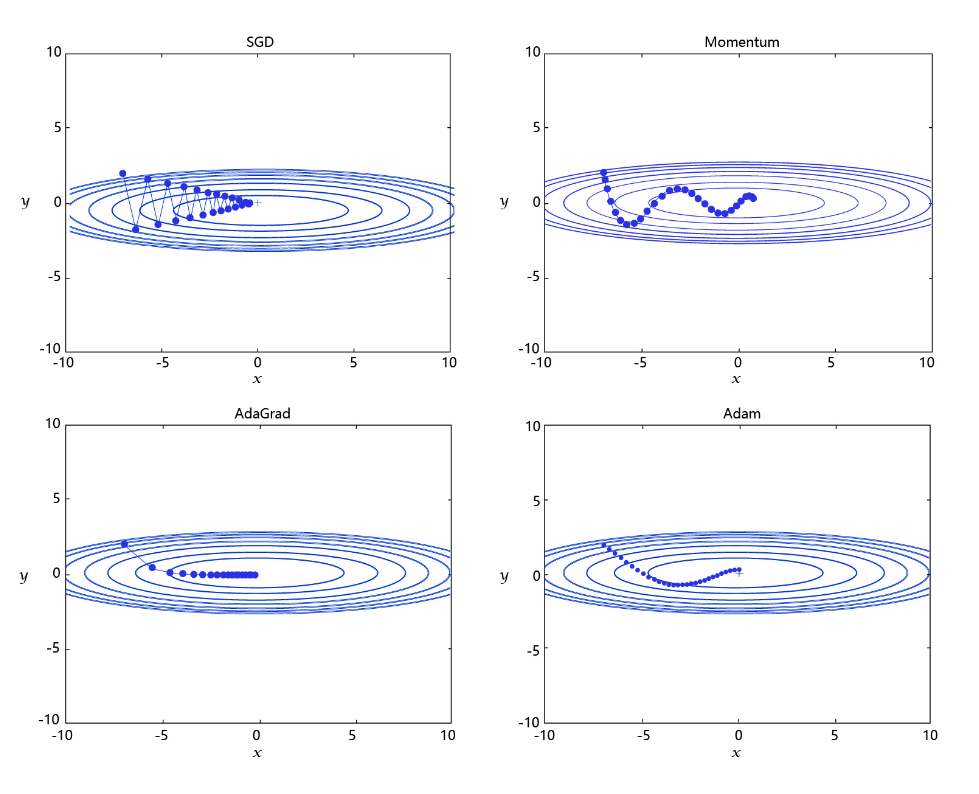
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









