








安装requests库
要安装requests库,请按照以下步骤操作:
- 打开命令提示符(Windows)或终端(Mac/Linux)。
- 输入以下命令并按回车键执行:
pip install requests
- 等待安装过程完成。安装成功后,就可以在Python代码中导入requests库并使用了:
import requests
response = requests.get('https://www.example.com')
print(response.text)
requests.get()方法使用
requests.get()方法用于发送HTTP GET请求。以下是详细步骤和相关代码:
- 首先,确保已经安装了
requests库。如果没有安装,可以使用以下命令安装:
pip install requests
- 在Python代码中,导入
requests库:
import requests
- 使用
requests.get()方法发送GET请求。例如,要获取百度首页的HTML内容,可以使用以下代码:
response = requests.get('https://www.baidu.com')
- 检查响应状态码,以确保请求成功。状态码为200表示请求成功:
print(response.status_code)
- 获取响应的文本内容:
print(response.text)
将以上代码整合在一起:
import requests
response = requests.get('https://www.baidu.com')
print(response.status_code)
print(response.text)
运行这段代码,你将看到百度首页的HTML内容。
客户端渲染
客户端渲染(Client-Side Rendering,简称CSR)是一种网页开发技术,指的是在用户的浏览器中生成和显示网页内容。这种技术通常使用JavaScript来实现,当用户访问一个网站时,服务器会发送一个包含JavaScript代码的HTML文件,然后浏览器执行这些代码,从服务器获取数据,并根据这些数据动态生成和更新网页内容。
当打开网页并检查网络请求时,可能会发现有些数据(如图片或其他信息)并不在预览中。这可能是因为这些数据是通过客户端渲染技术动态加载的。在这种情况下,无法直接从预览中获取这些数据,因为它们是在浏览器端生成的,而不是直接从服务器获取的静态内容。
实战演示
检查数据
检查需要的数据是否在链接中
1.数据不在链接中
打开网页,右键点击检查,然后点击网络,刷新,接着选择第一个文档,点击预览,这个时候我们发现,左边的照片或者其他信息不在预览里面,这个时候我们就无法获得想要的数据了。这种数据就属于客户端渲染 。
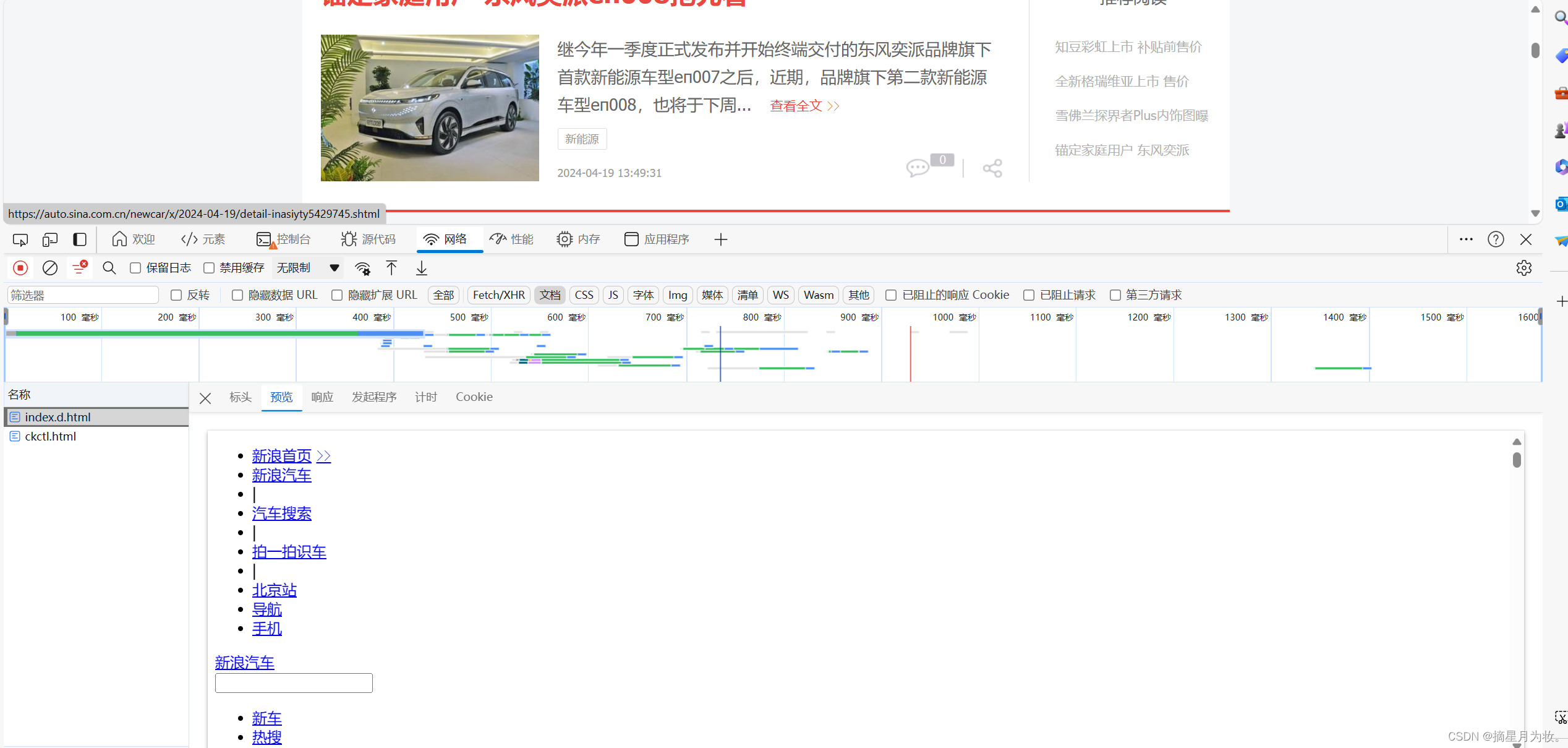
2.数据在链接中
打开网页,点击右键,点击检查,然后点击左上角的小箭头,移动到左边我们需要的数据上面,如果右边代码中出现相应的代码,就说明数据就在代码中,接着我们就开始后面的操作,方便获取我们需要的数据。
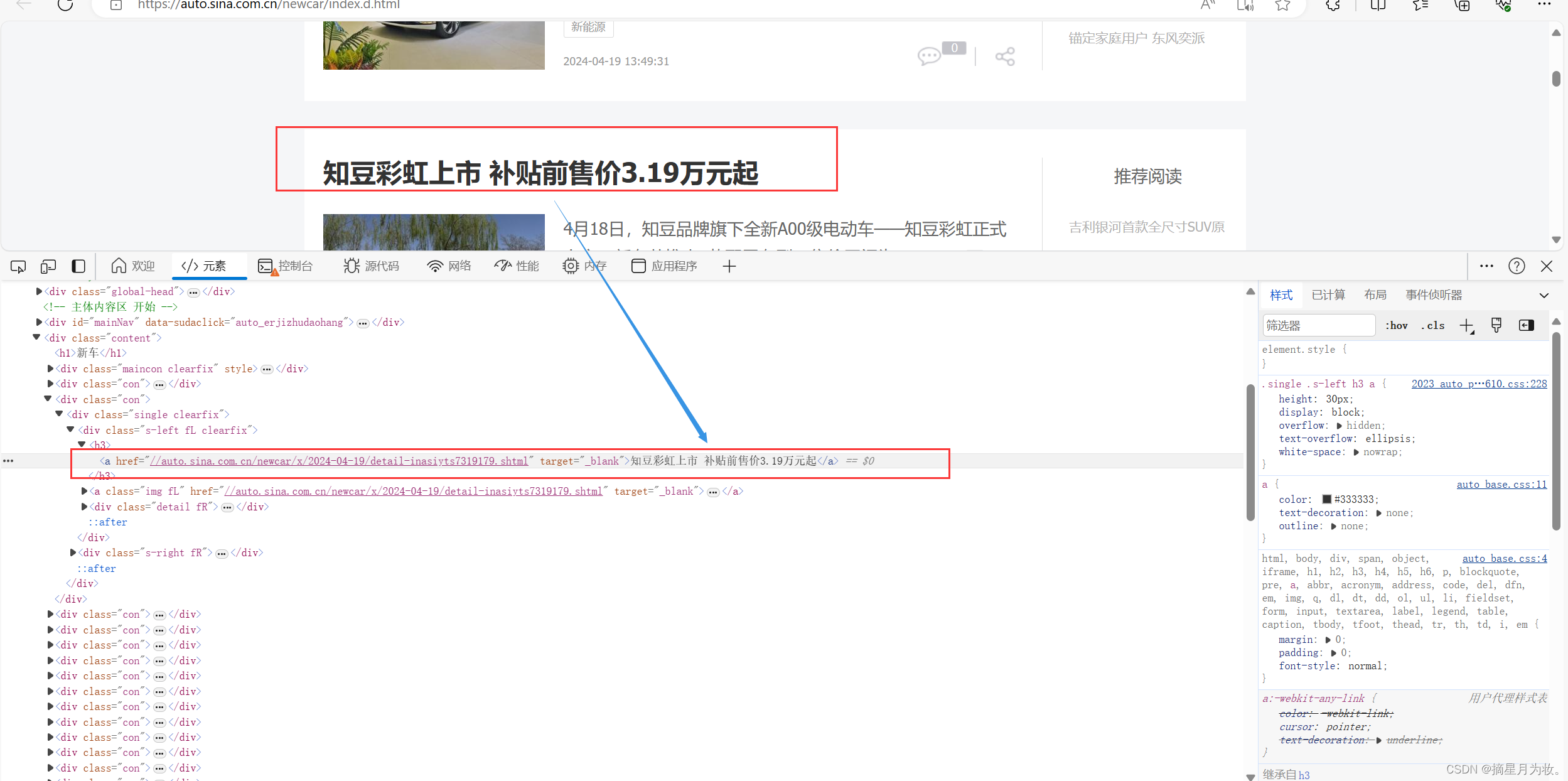
请求数据
浏览器页面的网址一定是qet请求
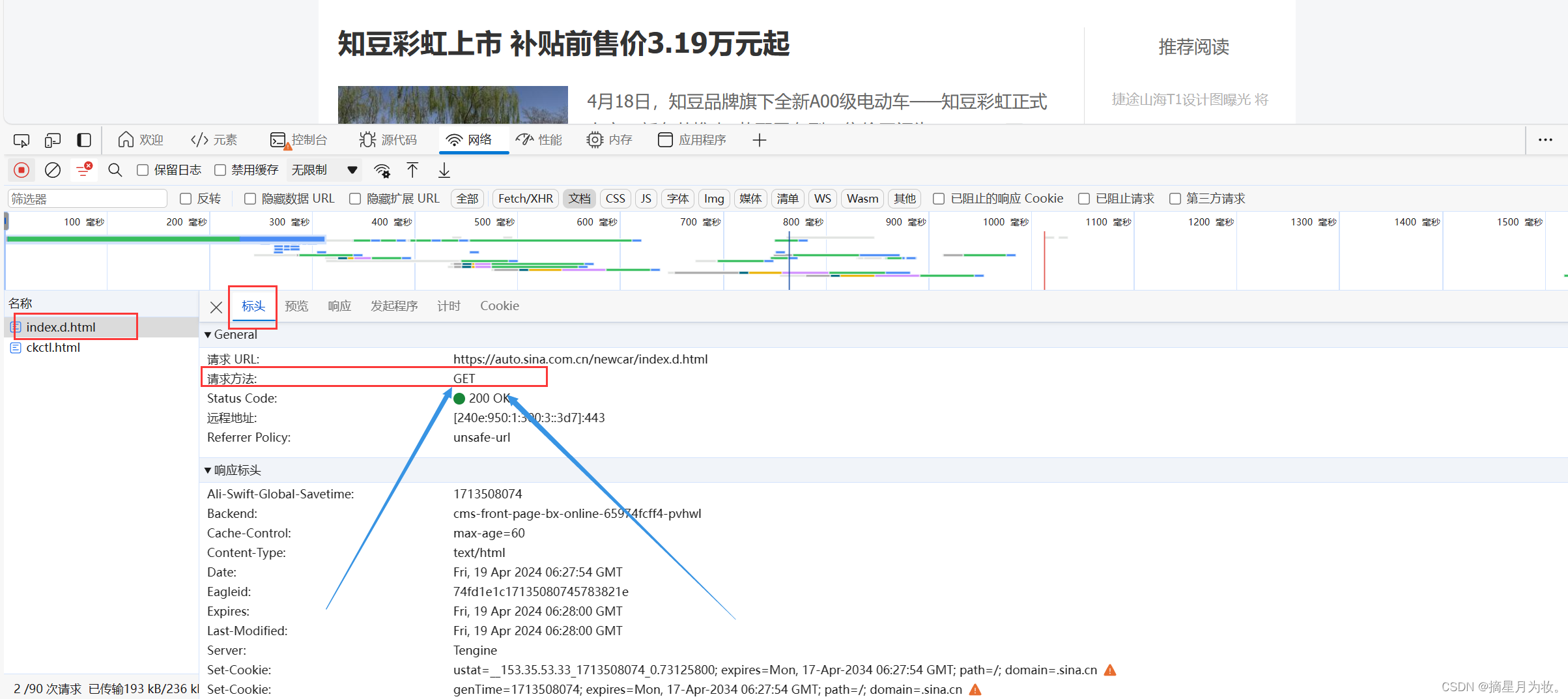
现在我们知道数据在链接中,我们就要通过链接去获取他:
import requests
url = 'https://auto.sina.com.cn/' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
这段代码使用了Python第三方库requests,发送了一个HTTP
GET请求,并获取了HTTP响应的正文和状态码,并根据状态码判断请求是否成功。其中,url是一个字符串类型的参数,表示要发送HTTP请求的URL地址。
使用requests.get()函数发送HTTP GET请求,并将HTTP响应对象赋值给变量html。
使用text属性获取HTTP响应正文,并将其打印出来。此外,使用status_code属性获取HTTP响应状态码,并将其打印出来。
根据HTTP响应状态码判断请求是否成功,如果状态码为200,则表示请求成功,否则表示请求失败。(状态码详情可查阅第二节,html页面组成)
结果如下:

import requests
url = 'https://auto.sina.com.cn' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
print(html.url) # 访问的网址
print(html.request.headers) # 输出请求头信息
使用url属性获取HTTP请求的URL地址,并将其打印出来。
然后,使用request.headers属性获取HTTP请求的请求头信息,并将其打印出来。request属性是HTTP响应对象的一个属性,表示该HTTP响应对象对应的HTTP请求对象。因此,html.request.headers表示HTTP请求的请求头信息。
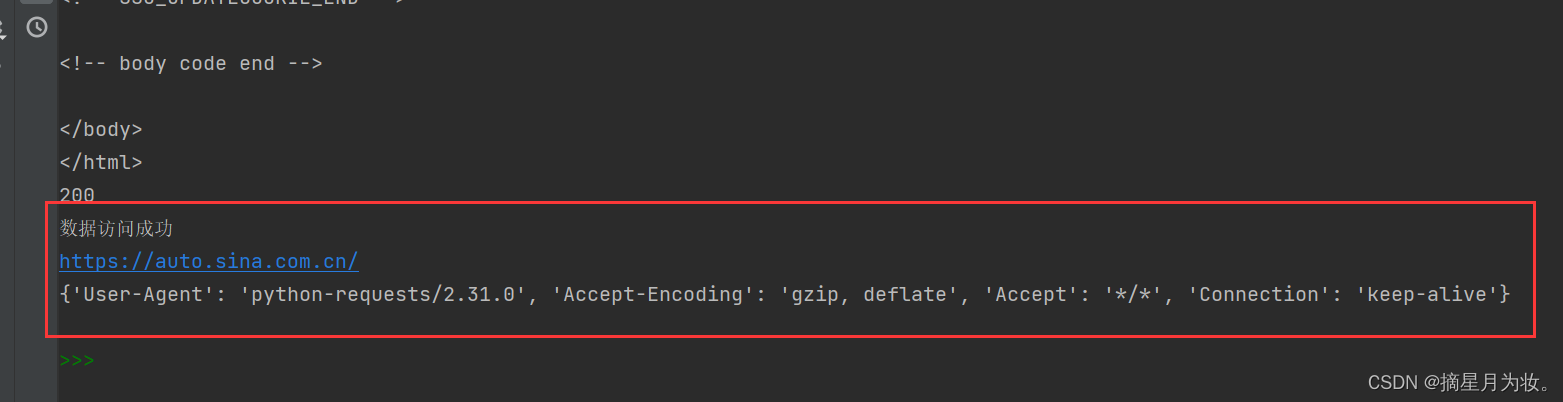
请求头的作用
请求头在HTTP协议中扮演着至关重要的角色,它的主要作用是传递关于请求的额外信息。以下是请求头的一些关键作用:
- 传递客户端信息:请求头可以包含浏览器的类型、版本、语言等信息,这些信息对于服务器来说有助于提供定制化的内容或进行统计分析。
- 指导服务器如何处理请求:例如,
Accept头部字段告诉服务器客户端希望接收的数据格式,如application/json表示客户端期望接收JSON格式的数据。这有助于服务器根据客户端的需求发送正确的数据类型。 - 异步请求识别:
X-Requested-With头部字段通常用于指示请求是否为异步请求,这对于服务器处理AJAX请求特别重要。 - 安全性:请求头还可以包含安全相关的信息,如
Referer(指示请求来源)和User-Agent(指示用户代理信息),这些信息有助于服务器验证请求的合法性。 - 条件请求:通过
If-Modified-Since和If-None-Match等头部字段,客户端可以询问服务器自上次请求以来资源是否有变化,这有助于减少不必要的数据传输。 - 缓存控制:
Cache-Control头部字段可以指示服务器如何缓存响应,以及客户端是否可以缓存响应。 - 内容协商:
Accept-Encoding和Accept-Language等头部字段允许客户端表达对特定编码或语言的偏好,服务器可以根据这些偏好返回最合适的内容。 - 认证:如
Authorization头部字段可用于携带访问令牌或其他认证信息,以便服务器验证用户身份。
保存数据
import requests
import chardet
url = '
https://dbs.auto.sina.cn/api/auto/getBrandBaseCondition?brandLogoSize=250&serialSellStatus=1,2'
headers = {
'User-Agent': 'python-requests/2.28.2',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'
}
html = requests.get(url, headers=headers).content
encoding = chardet.detect(html)['encoding']
html = html.decode(encoding)
print(html)
# 将网页内容写入文件中
with open('example.html', 'w', encoding='utf-8') as f:
f.write(html)
- 这段代码可以将 html 变量中的网页内容写入到名为 example.html 的文件中。具体来说,open() 函数用于打开文件,‘w’
参数表示以写入模式打开文件,encoding=‘utf-8’ 参数表示指定编码格式为 UTF-8。然后使用 write()
方法将网页内容写入文件中。with 语句用于自动关闭文件。 - 需要注意的是,如果该文件不存在,则会自动创建该文件;如果该文件已经存在,则会覆盖原文件中的内容。如果要在已经存在的文件中追加内容,可以将
‘w’ 参数改为 ‘a’。















 1874
1874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









