







前提须知
1、Python的相关知识:
①Python的程序由包(package)、模块(module)和函数等组成。包是由一系列模块组成的集合,模块是处理某一类问题的函数和类的集合。(包就是一个完成特定任务的工具箱,Python提供了许多有用的工具包,如字符串处理、图形用户接口等。这些自带的工具包和模块安装在Python的安装目录下的Lib子目录中。)Python中还有库,它可能包含多个模块和包。库、包和模块都是Python编程中用于组织和管理代码的方式。它们之间的关系是:模块是最基本的单位,包是多个模块的集合,而库则是多个模块和包的集合。
在Python中,对于不是自带的模块、包和库,我们需要使用其中的函数等工具时,我们就需要使用import关键字来将其导入。以下是几种常见的导入模块的方法:
1.导入整个模块:
import module_name使用这种方法,你需要使用module_name.function_name的方式来调用模块中的函数或变量。
2. 导入模块并赋予别名:
import module_name as alias_name通过给模块取别名,可以简化调用模块中的函数或变量的方式。
3. 从模块中导入特定的项:
from module_name import item_name使用这种方法,你可以直接使用item_name来访问模块中的特定函数或变量,无需通过模块名。
请注意,module_name是你想要导入的模块的名称,item_name是模块中特定的函数、变量等的名称,而alias_name是你自己给模块取的别名。
导入包导入库基本语法同上。
②导入模块、包的目的是表明代码需要用的导入包、模块中的函数等工具,但是在代码运行前,我们还需要再配置环境中安装包。
例如:如果你没有安装requests库但在Python代码中尝试使用它,那么运行代码时会出现:

为了解决这个问题,你需要在运行代码之前先安装requests库。你可以使用pip(Python的包管理器)来安装它。在命令行(快捷键:Win+R键打开运行窗口,然后输入cmd并按回车键)中运行以下命令:
pip install requests或者,如果你使用的是Python 3(版本),可能需要(上面那种方法安装不成功就用这种)使用pip3:
pip3 install requests安装完成后,你就可以在代码中正常使用requests库了。
③Python的for循环:
在Python中,for循环是一种用于遍历可迭代对象(如列表、元组、字符串等)的循环结构。它允许我们按照一定的顺序逐个访问可迭代对象中的每个元素,并执行相应的操作。
下面是一个简单的示例,展示了如何使用for循环打印列表中的所有元素:
fruits = ["苹果", "香蕉", "橙子"]
for fruit in fruits:
print(fruit)
上述代码会依次打印出列表中的每个水果名称。在每次循环迭代时,变量fruit会依次取得列表中的一个元素,然后执行相应的操作,这里是打印元素的名称。
输出结果:
苹果
香蕉
橙子
除了列表,你还可以在for循环中使用其他可迭代对象,比如字符串、元组等。
2、爬虫:从别人的源代码中获取我们需要的数据
如何从网页中爬取省级行政区的全称?
1、在网上找到有省级行政区的全称的页面
以下页面为例:
2、爬取页面中省级行政区的全称
1:检查页面,获得详情页和源代码页
(操作:详情页面空白处鼠标右键——检查,即会出现一半页面是详情页,一半页面是源代码页。)其中源代码页中,左上角的第一个工具,可以在详情页指定具体内容,在源代码页会显示出其对应的源代码。这个工具将会帮助我们更快的完成第二个步骤。
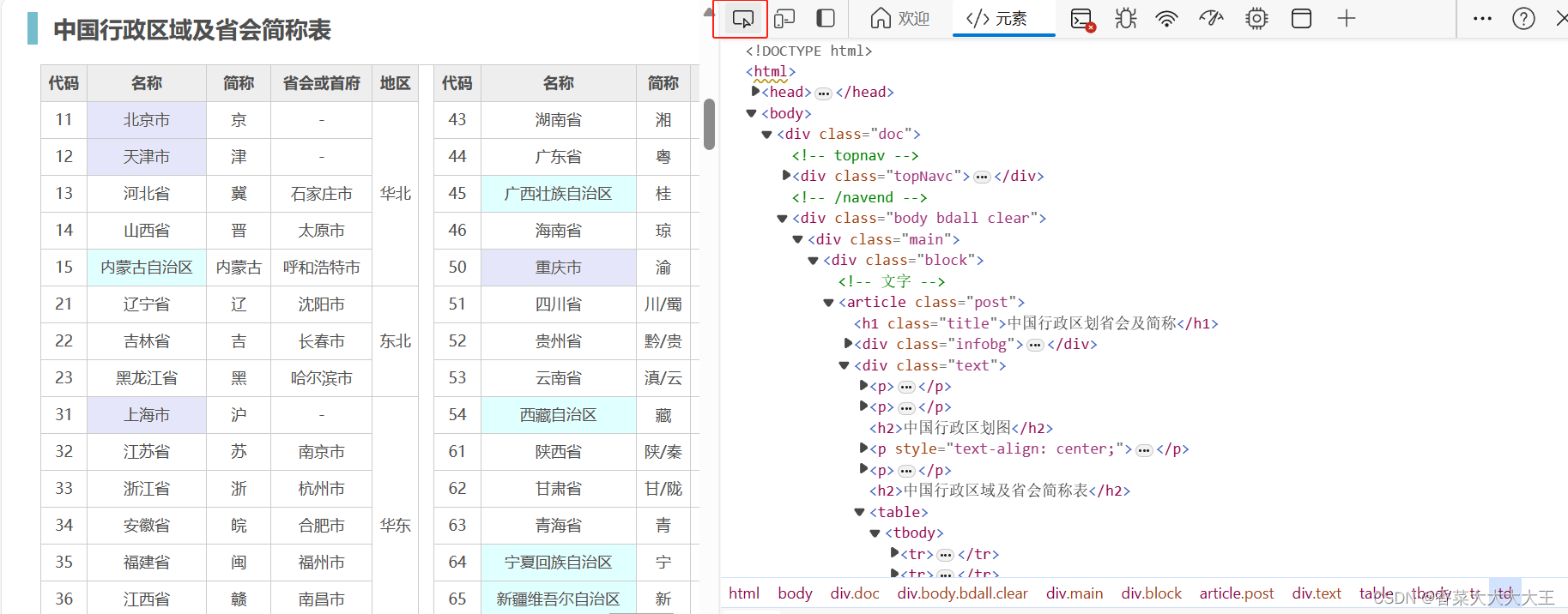
2:对比分析,在源代码页面中找到我们需要的省行政区的全称对应的源代码所在位置的规律
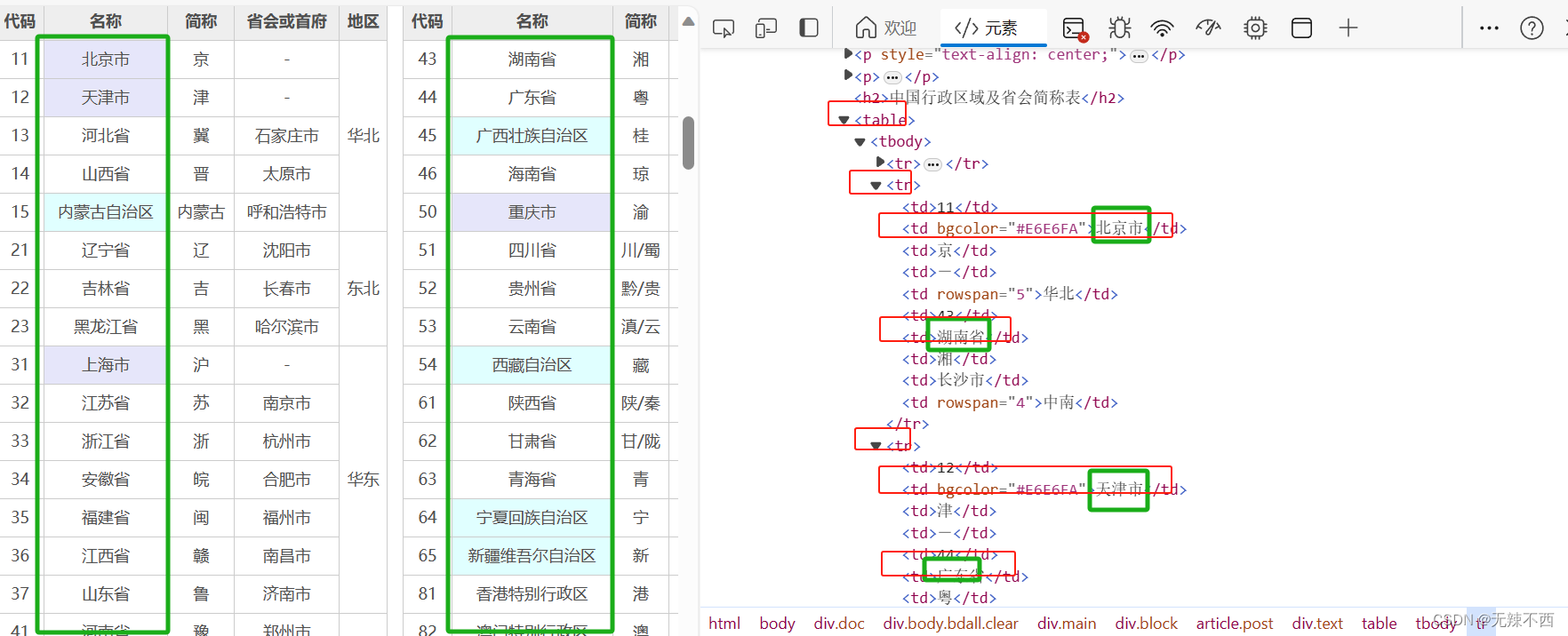 对比之后,在源代码页中可以看出,我们所需要的省行政区的全称均在table标签中从第2个tr开始的td标签内(table标签中的第一个tr里没有我们需要的信息)。在仔细观察可以发现,在tr中的第二个td中必有我们需要的全称,然后要么在第六个中有我们需要的全称,要么在第七个td中有我们需要的全称。
对比之后,在源代码页中可以看出,我们所需要的省行政区的全称均在table标签中从第2个tr开始的td标签内(table标签中的第一个tr里没有我们需要的信息)。在仔细观察可以发现,在tr中的第二个td中必有我们需要的全称,然后要么在第六个中有我们需要的全称,要么在第七个td中有我们需要的全称。
思考为什么有时全称会在第六个td中,有时又是在第七个td中呢?
查看源代码发现是第五个td中的rowspan标签(用于合并单元格)造成的,则tr中的第五个td中,如果出现了rowspan属性,那么第七个td中有我们需要的全称,否则则是第六个td中有我们需要的全称。
综合可得规律是:我们所需要的省行政区的全称都在table标签中从第二个tr开始的td标签内,其中如果tr中的第五个td出现了rowspan属性,那么我们需要的全称则是在tr的第二个td和第七个td中,否则则是在第二个td和第六个td中。
3:利用通义灵码、ChatGPT等,得到与规律相关的python代码。
以使用通义灵码为例:

通义灵码给出的代码:
import requests
from bs4 import BeautifulSoup
# 发送请求获取页面内容
url = "网页的URL地址"
response = requests.get(url)
content = response.content
# 解析页面内容
soup = BeautifulSoup(content, 'html.parser')
table = soup.find('table')
# 获取table中的数据
data = []
for tr in table.find_all('tr')[1:]:
td = tr.find_all('td')
if td[5].get('rowspan'):
row = [td[2].text, td[7].text]
else:
row = [td[2].text, td[6].text]
data.append(row)
# 打印获取到的数据
for row in data:
print(row)4.粗略的读懂代码并进行必有部分的修改然后运行代码。
通义灵码给的代码,不能直接使用,要进行适当的修改。例如上图的代码,我们应该就其中“网页的URL地址”改为我们具体网页地址。然后利用代码中的一些注释大致看看代码是否是我们想要的代码。因为有时如果我们表述的不明确,得到的代码不是我们想要的代码,就需要重新获取新的代码。最后运行代码,也可通过运行结果来判断代码的正误。
粗略的看代码:整体上:代码共分为了五段,第一段用于导入代码中所需要的模块、包和库。第二部分调用模块、包和库中的方法、函数之类的获取整个页面的内容。第三个部分是解析页面的内容。第四部分也是最重要的部分,筛选出我们所需要的东西。第五部分是输出我们需要的内容。整体上看,方向正确。下面就是要重点第四部分,是怎么筛选代码的。它是先把从第二个开始的tr筛选出来,然后判断第五个td的属性,然后再选择性输出td的值。这个思路是没有问题的。但是我们发现我们要求的是第五个td中有属性rowspan的,要第二个td和第七个td的值,这个[ ]符号表明是数组,而数组是从0开始的。第五个应该是[5-1=4]=[4],其余同理,所以这里需要改。
修改后的代码:
import requests
from bs4 import BeautifulSoup
# 发送请求获取页面内容
url = "http://www.lupipi.com/wiki/Chinashenghui.html"
response = requests.get(url)
content = response.content
# 解析页面内容
soup = BeautifulSoup(content, 'html.parser')
table = soup.find('table')
# 获取table中的数据
data = []
for tr in table.find_all('tr')[1:]:
td = tr.find_all('td')
if td[4].get('rowspan'):
row = [td[1].text, td[6].text]
else:
row = [td[1].text, td[5].text]
data.append(row)
# 打印获取到的数据
for row in data:
print(row)运行结果:
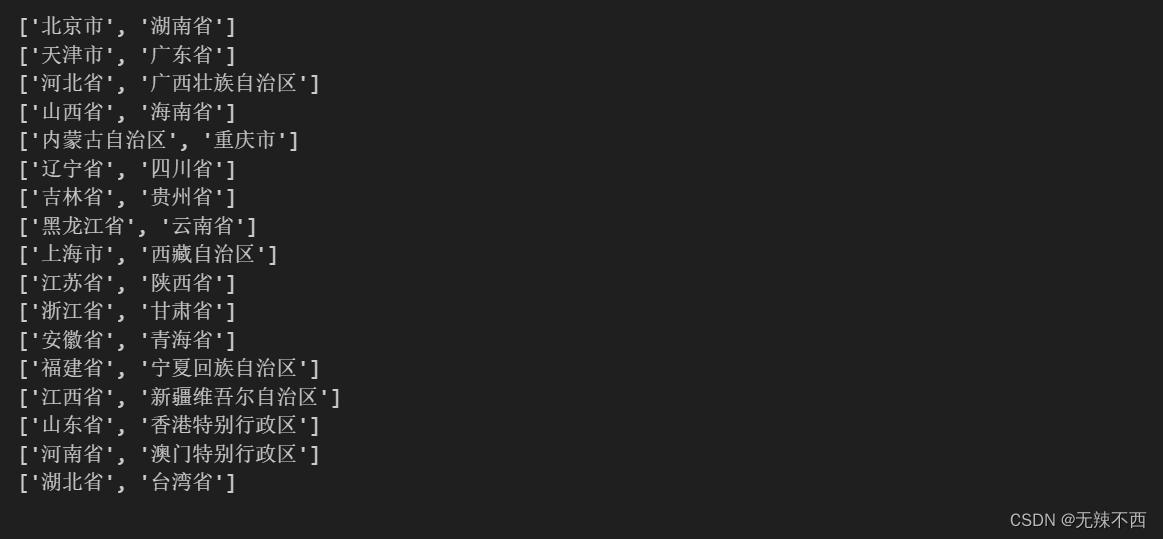
运行结果得到了我们想要的信息,这就是爬虫的整个过程了。可以看出其中最难的部分就是找规律。找规律需要仔细,不然很容易遗漏某些细节从而得到错误的结果。不过,可以通过代码运行的结果帮助我们判断找的规律正不正确!!!
大家可以使用其他页面尝试一下,不理解的地方可以私信我哦~















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









