







1.配置环境
创建环境:conda create -n sfd2 python==3.7
然后激活环境:conda activate sfd2
随后cd到代码文件夹内部:cd /home/liutao/桌面/demo/sfd2-dev
pip install -r requirements.txt
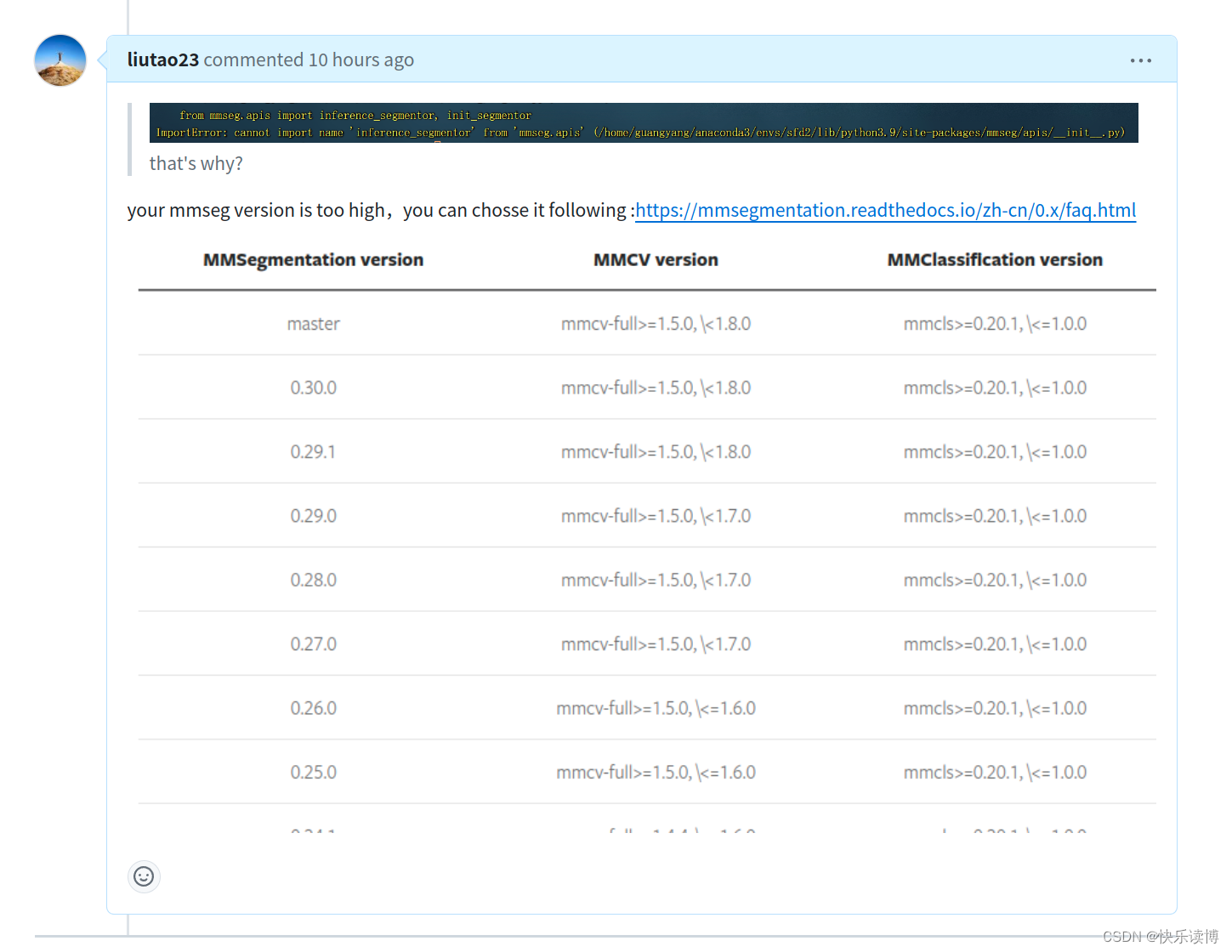
需要注意:安装mvcc时一定要注意版本1.5.0,另外安装与之对应的mmseg版本也应该对应,我今天随机在github上面回答了一个小伙伴的问题
问题如下:
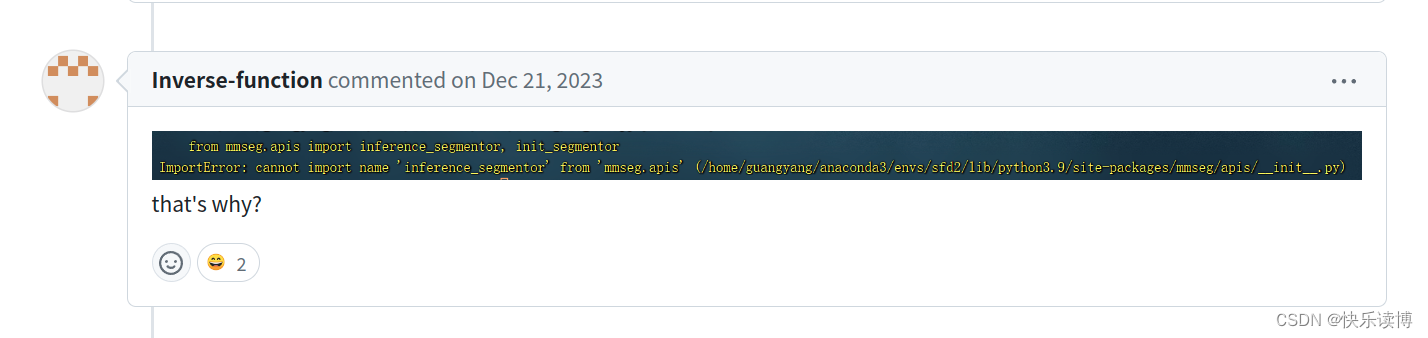
我的回答:
2.下载数据集和训练权重
根据readme,我们去寻找下载数据集的网址,发现论文中所用:
数据集来自R2D2:(按照R2D2的数据集架构组织就可以)
GitHub - naver/r2d2Contribute to naver/r2d2 development by creating an account on GitHub. https://github.com/naver/r2d2很遗憾,其中R2D2给出的download_traindata.sh文件中的下载revisitop数据集网址不知道是什么原因,连接失败,本人费了一番功夫在kaggle上面找到了:R2D2 Training Data | KaggleNatural Images for UnSupervised taskshttps://www.kaggle.com/datasets/javidtheimmortal/naturalimages?resource=download
https://github.com/naver/r2d2很遗憾,其中R2D2给出的download_traindata.sh文件中的下载revisitop数据集网址不知道是什么原因,连接失败,本人费了一番功夫在kaggle上面找到了:R2D2 Training Data | KaggleNatural Images for UnSupervised taskshttps://www.kaggle.com/datasets/javidtheimmortal/naturalimages?resource=download
语义分割模型来源于:ConvXt:(为训练阶段的稳定性学习提供语义标签和语义感知特征)
GitHub - facebookresearch/ConvNeXt: Code release for ConvNeXt modelCode release for ConvNeXt model. Contribute to facebookresearch/ConvNeXt development by creating an account on GitHub.https://github.com/facebookresearch/ConvNeXt 局部特征提取模型来自SuperPoint:(为训练阶段提供局部稳定性)
GitHub - magicleap/SuperPointPretrainedNetwork: PyTorch pre-trained model for real-time interest point detection, description, and sparse tracking (https://arxiv.org/abs/1712.07629)PyTorch pre-trained model for real-time interest point detection, description, and sparse tracking (https://arxiv.org/abs/1712.07629) - magicleap/SuperPointPretrainedNetworkhttps://github.com/magicleap/SuperPointPretrainedNetwork 预训练模型来源于:谷歌硬盘(需要变成魔法师才能下载,我已经下载好,有需要可以关注私信我)
https://drive.google.com/drive/folders/1bM5lmMFMbsnDe_AdQ6SSs-t2OMIuys_j?usp=sharinghttps://drive.google.com/drive/folders/1bM5lmMFMbsnDe_AdQ6SSs-t2OMIuys_j?usp=sharing 这包含了CnovXt和SuperPoint的权重。
评估数据集来源于:visualization benchmark
Benchmarking Long-term Visual Localizationhttps://www.visuallocalization.net/
3.阅读代码了解代码框架
暂无(PS:因为本人电脑显卡问题,无法进行代码结果复现,后续可能在云服务器上面进行训练的展示,其他显卡大于3090Ti的小伙伴,可以私信我,我可以给你们一些建议)
本人已经完成了代码的调试,并且按照readme文件找到了其训练数据集,但是介于本人显卡显存不够,无法实施训练,所以是否结果真如作者论文中所说那么优秀,尚不可证明 。作者论文中给出的硬件是NVIDIA-3090Ti,如果有感兴趣的小伙伴,欢迎留言,请我喝杯奶茶,我或许可以和你说一些配置训练环境以及修改代码的细节,然后让我们共同探索这篇2023年CVPR的论文是否效果真的很棒。另外,后续有时间我租用云服务器跑一下这个代码。接下来本人探讨的方向仍然放在语义视觉定位方面。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









