







自己记录一下学习过程,会比较琐碎。。。
在看文件搞明白数据集的意义后开始导入。
原始文件:
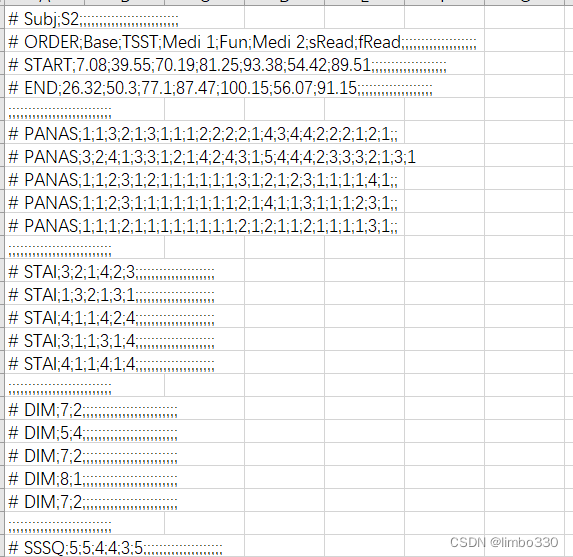
先尝试用python的pandas包进行导入,由于是.csv文件用read_csv方法导入
import pandas as pd
fpath="/content/drive/MyDrive/projects/data/S2_quest.csv"
qn=pd.read_csv(fpath)
print(qn.shape)
qn.head(10)结果:
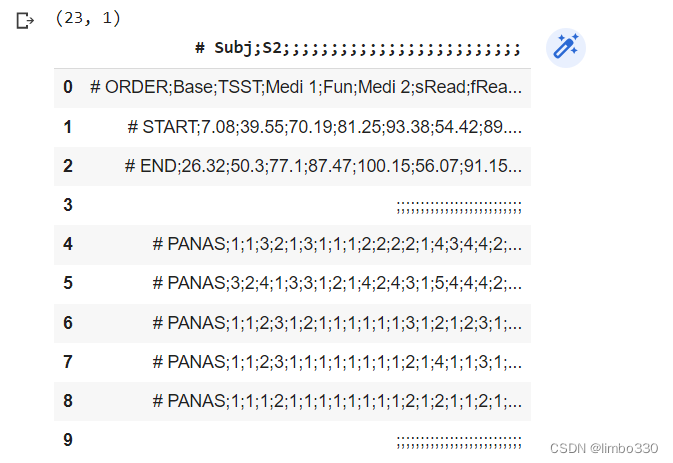
发现pandas在行内只能将逗号分开,所以无法成功导入
当数据如下时(.csv实际上为文本文件,在windows里默认excel打开方式),则可以成功导入:
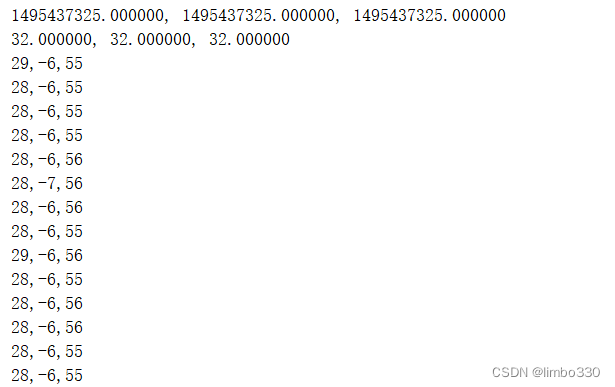
因为文本用“,”分开,在excel和pandas里都可以自动分割。
同组的朋友给了个github导入进来试了一下
去查了一下
dataFrame:dataFrame
statistics:statistics
这个地方原本是报错的,原因是np.vstack必须要数组长度相同,于是手动用append函数把它补齐,但感觉不是很优雅,应该有更简洁的函数,暂时没搜到。
这段说没有'labels'

np.asarray:http://t.csdn.cn/aLYqK
真看不懂丢进gpt
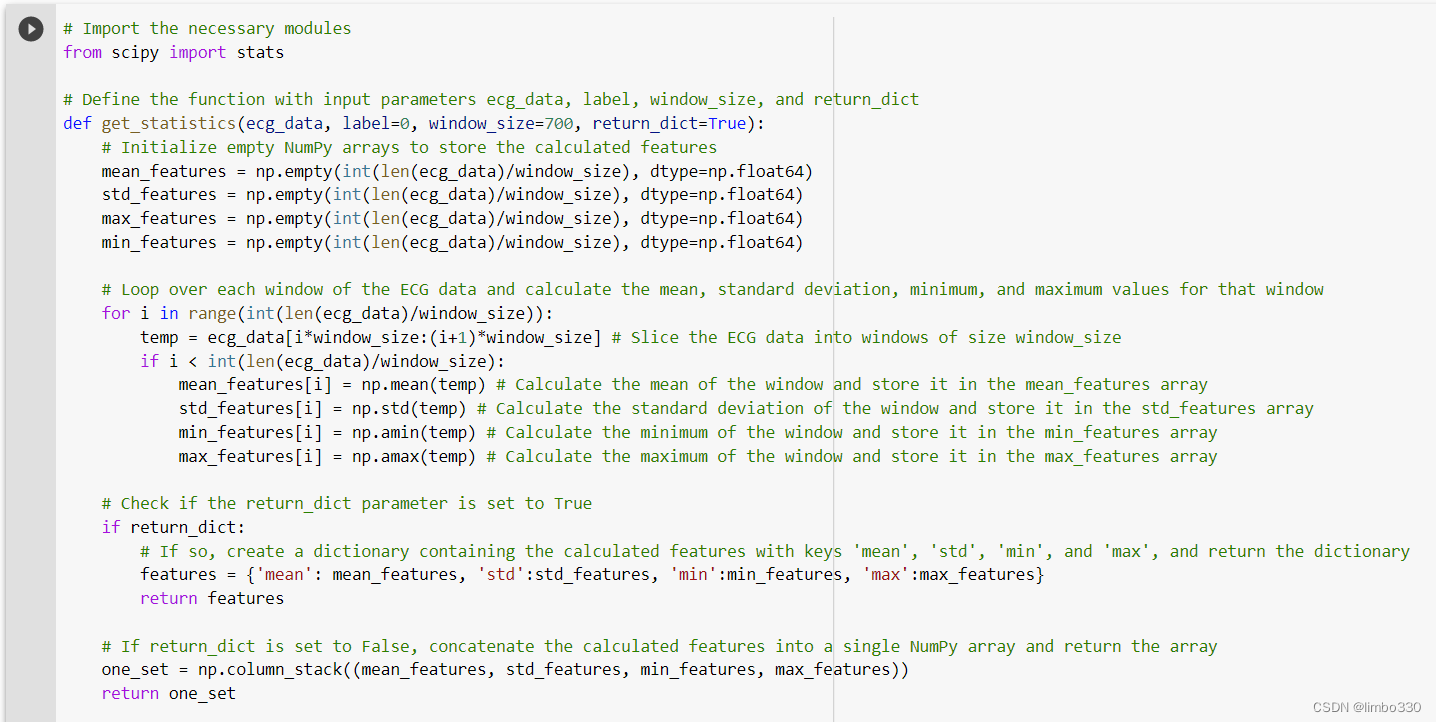
基本把checkpoints文件搞定,主要是提取信号的一些统计特征,并以1秒为间隔的时序储存显示。
开始feature_extraction:
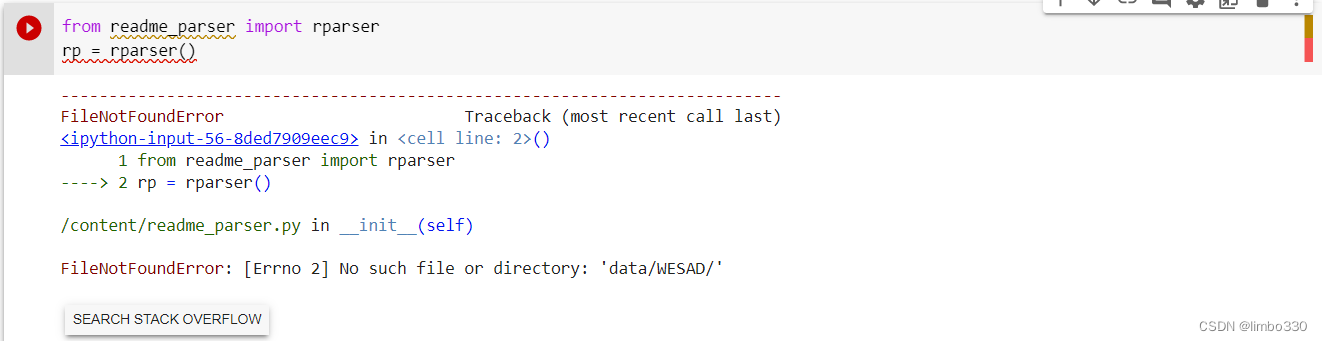
遇到这个报错,在read_parser中已经修改,暂时不知道如何解决,需要学习一下如何导入自定义包http://t.csdn.cn/ge2m0















 5524
5524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









