









一、双链表
单链表无法逆向检索,想找到单链表前驱结点会很麻烦,采用可进可退的双链表,存储密度相比单链表低一些。
1.代码定义双链表
typedef struct DNode //定义双链表结点类型
{
ElemType data; //数据域
struct DNode* prior, * next; //前驱和后继指针
}DNode,*DLinkList;双链表结构中包含两个指针域:前驱指针*prior和后继指针*next。
2.初始化双链表
bool InitDLinkList(DLinkList& L)
{
L = (DNode*)malloc(sizeof(DNode));
if (L == NULL)
return false;
L->prior = NULL; //头结点的prior永远指向NULL
L->next = NULL; //头结点之后暂时还没有结点
return true;
}初始化双链表需要把头结点的prior和next都指向NULL,如上代码段。
3.双链表判空
判断双链表头结点是否指向NULL即可,如下:
bool Empty(DLinkList L)
{
if (L->next == NULL)
return true;
else
return false;
}4.双链表的后插操作
①InsertNextDNode(DNode *p,DNode *s):在p结点之后插入s结点。
②代码实现:
bool InsertNextDNode(DNode* p, DNode* s)
{
if (p == NULL || s == NULL) //非法参数
return false;
s->next = p->next;
if (p->next != NULL) //如果p有后继结点
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}③补充解释:
(1)先判断p和s的合法性,如果p是NULL,也就意味着不能在空指针后插入;如果s是NULL,也不能说插入一个空的结点;
(2)把s指向p的后继结点,也就是断连p和p本身的后继结点;
(3)判断p的后继结点是否为NULL:如果为NULL,即p是表尾结点,那么上一句的执行就是将s的后继指针指向了NULL,此时直接跳过if语句,执行s.prior=p和后续语句,先将s的前驱指针指向p,再将p的后继指针指向s即可;如果p的后继结点不是NULL,即p不是表尾结点,执行if语句,将p的后继结点的前驱指针指向s,再把p和s连上即可。
④双链表的前插以及按位插入等操作都可以用遍历加后插来实现。
5.双链表的遍历
①后向遍历
while (p != NULL) //双链表的表尾结点后继为空
{
p = p->next;
}②前向遍历(没有跳过头结点)
while (p != NULL) //双链表头结点前驱为空
{
p = p->prior;
}③前向遍历(跳过头结点)
while (p->prior != NULL)
{
p = p->prior;
}6.双链表的删除
①DeleteNextDNode(DNode *p):删除p结点的后继结点。
②代码实现:
bool DeleteNextDNode(DNode* p)
{
if (p == NULL)
return false;
DNode* q = p->next; //找到p的后继结点q
if (q == NULL)
return false; //p没有后继结点
p->next = q->next;
if (q->next != NULL) //q结点不是最后一个结点
q->next->prior = p;
free(q); //释放q
return true;
}③如果我们想销毁某一个双链表,我们可以依次删除头结点的后继结点,如下:
void DestroyDNodeList(DLinkList& L)
{
while (L->next != NULL)
DeleteNextDNode(L);
free(L); //释放头结点
L = NULL; //头指针指向NULL
}二、循环链表
1.循环单链表
①普通的单链表最后一个结点指向NULL,循环单链表最后一个结点指回头结点。
typedef struct LNode
{
int data;
struct LNode* next;
}LNode,*LinkList;②初始化一个循环单链表,让头结点的后继指针再指向头结点即可,如下:
bool InitList(LinkList& L)
{
L = (LNode*)malloc(sizeof(LNode));
if (L == NULL)
return false;
L->next = L; //头结点next指向头结点
return true;
}③循环单链表判空,即判断头结点的后继指针是否指向自身,如下:
bool Empty(LinkList& L)
{
if (L->next == L)
return true;
else
return false;
}④判断结点p是否为循环单链表的表尾结点,如果p是表尾结点,那么p的后继指针应该指向头结点,如下:
bool isTail(LinkList L,LNode* p)
{
if (p->next == L)
return true;
else
return false;
}⑤相关说明:
(1)普通单链表从一个结点出发只能找到后续结点,而循环单链表从一个结点出发可以找到其他任何一个结点。
(2)对于“需要频繁对表头表尾结点进行操作”的情况下,我们可以把循环单链表的头地址指向表尾结点,而不是指向头结点。这样做的好处是,按照常规我们在单链表找头尾的方法,只能从L.next开始依次从头结点扫描到表尾结点,其时间复杂度为O(n);而如果把L指向表尾结点,由于是循环单链表,我们从尾找到头只需要1步即可,此时时间复杂度为O(1),但这时插入或删除操作可能需要修改L的值。
2.循环双链表
①相关概念:
(1)普通双链表的头结点prior指向NULL,表尾结点的next指向NULL;
(2)循环双链表的头结点prior指向表尾结点,表尾结点的next指向头结点;
(3)所有的prior和next指针都形成了一个闭环。
②初始化一个循环双链表;使头结点的前驱和后继指针都指向自身,如下:
bool InitDLinkList(DLinkList& L)
{
L = (DNode*)malloc(sizeof(DNode));
if (L == NULL) //内存不足,分配失败
return false;
L->prior = L; //头结点的prior指向头结点
L->next = L; //头结点的next指向头结点
return true;
}③循环双链表判空;判断头结点的后继指针是否指向自身,如下:
bool Empty(DLinkList L)
{
if (L->next == L)
return true;
else
return false;
}④判断结点p是否为循环双链表的表尾结点;如果p是表尾结点,那么它的后继指针就指向头结点,判断如下:
bool isTail(DLinkList L, DNode* p)
{
if (p->next == L)
return true;
else
return false;
}⑤循环双链表的插入;InsertNextDNode(DNode*p,DNode*s):在p结点后插入s结点。
bool InsertNextDNode(DNode* p, DNode* s)
{
s->next = p->next;
p->next->prior = s;
s->prior = p;
p->next = s;
}上述代码段和普通双链表的后插操作类似,不同的是这里不用判断p是否为表尾结点,因为循环双链表表尾结点不指向NULL。
⑥循环双链表的删除;DeleteDNode(DNode* q):删除结点q。
bool DeleteDNode(DNode* q)
{
DNode* q = p->next;
p->next = q->next;
q->next->prior = p;
free(q);
}通过定义q指向p的后继结点,把p的后继指针指向q的后继结点,改变q后继结点的前驱指针指向p,使pq断连,最后释放p即可。
三、静态链表
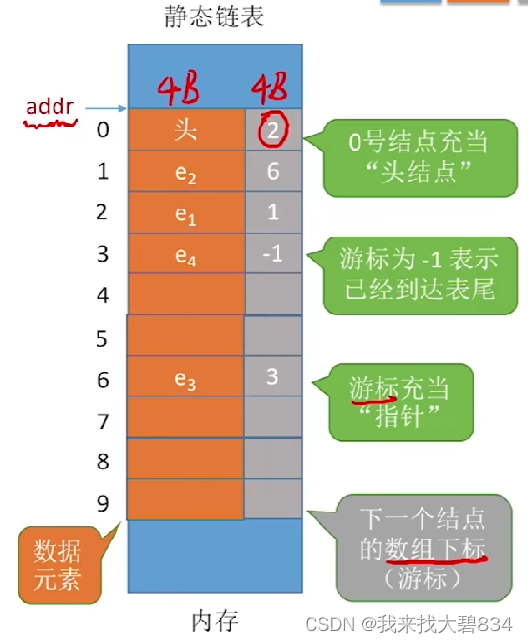
1.相关基本概念:
①如上图所示,静态数组分配一整片连续的内存空间,各个结点集中安置;
②每个结点包括一个数据元素(4B)和下一个结点的数组游标(4B)(每个结点共8B),起始地址为addr;
③游标充当指针:在静态数组中,数组下标为0的这个结点充当了“头结点”的角色,头结点的游标指向了下一个结点的数组下标;
④如果某一个结点的游标为-1,即代表这个结点为该静态数组的表尾结点(类似于指向NULL的结点);
⑤指针指向的是某一个具体的地址,而游标指向的是下一个结点的数组下标;
⑥表中某一个结点的存放地址为 addr+8*数组下标。
2.代码定义静态链表
①第一种定义方式:
#define MaxSize 10 //静态链表的最大长度
struct Node { //静态链表结构类型的定义
int data; //存储数据元素
int next; //下一个元素的数组下标
};
void testSLinkList()
{
struct Node a[MaxSize]; //数组a作为静态链表
}
②第二种定义方式:
#define MaxSize 10
typedef struct {
int data;
int next;
}SLinkList[MaxSize]; //等价于 typedef struct Node SLinkList[MaxSize];③上面的两种定义方式的区别还是在于使用环境不同,实际效果是一样的:
struct Node a[MaxSize];重点强调a是一个Node型数组;SLinkList a;重点强调a是一个静态链表。
3.简述静态链表的操作
①初始化:把a[0]的next设为-1;
②查找:从头结点出发往后挨个遍历结点 O(n);
③插入位序为i的结点:
(1)找到一个空的结点,存入数据元素(判断空结点时,我们在初始化时可以把这些空闲结点的next设置为某一个特殊值比如-2,那我只需要判断这个结点的游标是不是-2就可以判断这个结点是不是空结点了);
(2)从头结点出发找到位序为i-1的结点;
(3)修改新结点的next;
(4)修改i-1号结点的next;
④删除某个结点:
(1)从头结点出发找到前驱结点;
(2)修改前驱结点的游标;
(3)被删除结点的next设为-2。
4.静态链表优缺点:
①静态链表优点:增删操作不需要大量地移动元素;
②静态链表缺点:不能随机存取,只能从头结点开始依次往后查找,容量固定不可变;
③静态链表使用场景:①不支持指针的低级语言;②数据元素数量固定不变的场景(如操作系统的文件分配表FAT)。















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









