









一、基础原理
时序任务很难或者无法用DNN来进行预测,就像DNN对于图像特征提取任务很差,我们需要使用CNN,对于完成时序任务来说,我们就需要用到RNN,RNN(Recurrent Neural Network,循环神经网络),在时序任务中的广泛应用,包括文本生成、语音识别、时间序列预测、机器翻译等领域。

对于文本而言,它有如下特点:
1. 时序性:文本通常是有序的,每个字符或单词都依赖于前面的字符或单词。这种时序性是文本生成任务的关键特点,因为要生成连贯和有意义的文本,模型需要考虑上下文。
2. 长期依赖:文本中的依赖关系可能跨越较长的文本段落。例如,为了理解一个句子的含义,可能需要考虑整个段落或文章中的信息。
3. 离散性:文本数据通常是离散的,每个字符或单词属于有限的词汇表。这与连续数据(如图像像素)不同。RNN在处理离散数据时非常有效,因为它们可以处理不同词汇表中的不同单词或字符。
4. 可变长度:文本段落的长度可以变化,不同句子、段落或文档的长度可能不同。
二、RNN模型结构
2.1、模型结构
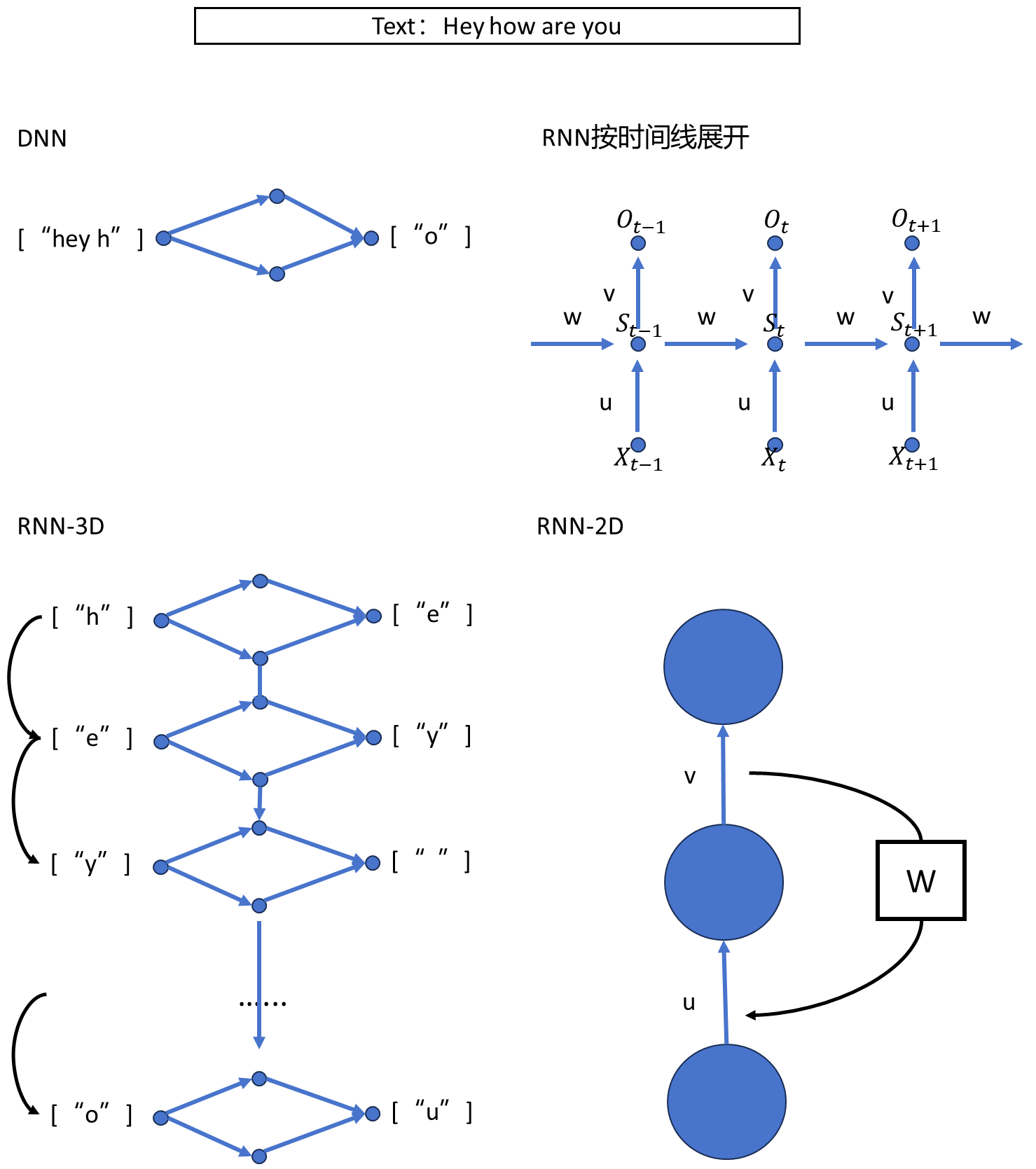
1.RNN在每个时间步使用相同的权重和偏置,并且时间步之间的权重和偏置也是共享的,这种参数共享使得模型具有一定的泛化能力,能够处理不同时间步的相似性质。
2. 并且RNN由于输入是一个字母,输出一个字母,意味着RNN可以处理可变长度的时间序列,因为它的结构可以根据输入的序列长度动态展开。
所以,这个结构非常适合做生成任务,如文本生成、语音合成等。由于它的内部状态和上下文捕获能力,RNN可以生成连贯和有意义的序列。
实际上,在搭建真实的网络时,并不会真的去搭建N个DNN,然后去连接起来,这样网络得非常之大,是不合理的。所以,RNN具有内部隐藏状态(hidden state),反映了模型的"记忆"。
隐藏状态在RNN中起到关键作用,因为它允许网络捕获并传递有关过去观察的信息,以便在序列中处理时间依赖关系。
也就是说,RNN专门有一个东西去存储时间步之间的“记忆”,具体来说,RNN的隐藏状态可以被看作是网络对之前时间步的输入数据和隐藏状态的函数,通常表示为h(t),其中"t"表示时间步。

隐藏状态的计算通过将当前时间步的输入与前一个时间步的隐藏状态相结合,从而使网络能够捕获时间序列中的信息传递和依赖关系。隐藏状态在每个时间步都会更新,因此它随着时间的推移反映了网络对先前时间步的观察和处理。
隐藏状态在RNN中有多种应用,包括:
作为输出,用于进行预测,如文本生成或时间序列预测。
作为网络内部状态,维护和传递信息,以捕获时间依赖关系。
用于初始化或提供上下文信息,例如在机器翻译任务中,初始隐藏状态可以包含源语言句子的信息,然后通过解码器生成目标语言句子
2.2、数据集划分

2.3、数据编码
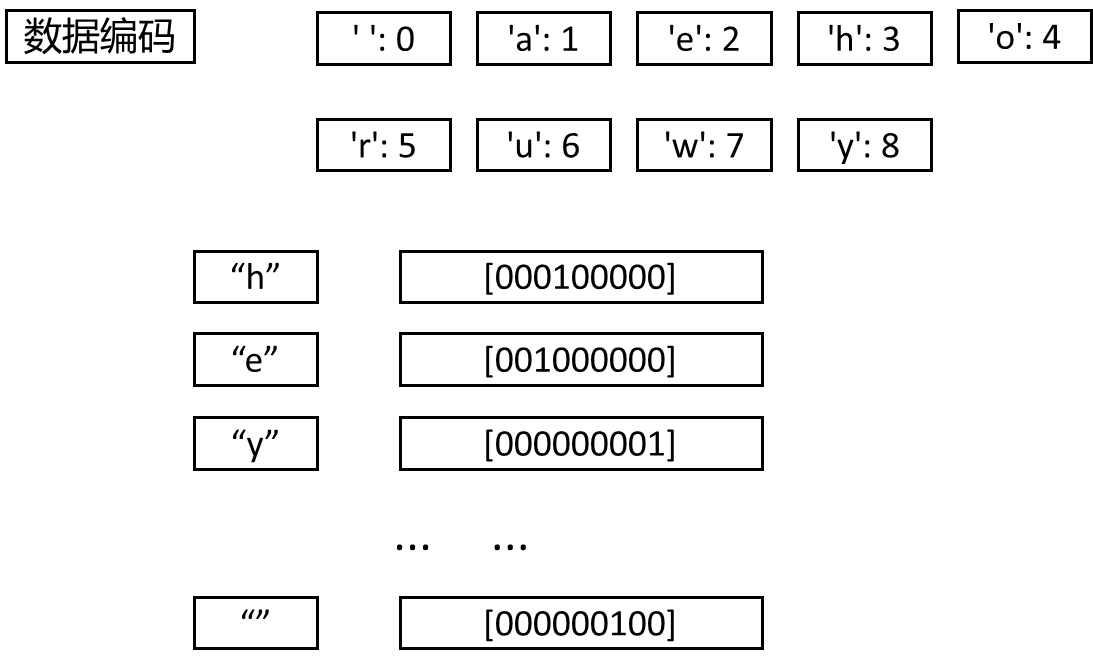
1. 字母去重(hey how are you -> ['h', 'r', 'e', 'a', 'y', ' ', 'w', 'o', 'u'])
2. 字母按照ASCII码排序(['h', 'r', 'e', 'a', 'y', ' ', 'w', 'o', 'u'] -> [' ', 'a', 'e', 'h', 'o', 'r', 'u', 'w', 'y'])
3. 按照ASCII的顺序进行从0开始编号({' ': 0, 'a': 1, 'e': 2, 'h': 3, 'o': 4, 'r': 5, 'u': 6, 'w': 7, 'y': 8})
4. 将每一个数字进行one-hot编码:['h']对应着:[0, 0, 0, 1, 0, 0, 0, 0, 0]
2.4、 循环神经网络
torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True,batch_first=False, dropout=0.0, bidirectional=False, device=None, dtype=None)| 参数 | 描述 |
|---|---|
| input_size | 输入 x 中预期特征的数量 |
| hidden_size | 处于隐藏状态 h 的特征数量 |
| num_layers | 循环层数。例如,设置意味着将两个 RNN 堆叠在一起以形成一个堆叠的 RNN, 第二个 RNN 接收第一个 RNN 的输出,并且 计算最终结果。默认值:1num_layers=2 |
| nonlinearity | 要使用的非线性。可以是 或 。否则:'tanh''relu''tanh' |
| bias | 如果 ,则层不使用 b_ih 和 b_hh 的偏差权重。否则 :FalseTrue |
| batch_first | 如果 ,则提供输入和输出张量 作为 (batch, seq, feature) 而不是 (seq, batch, feature)。 请注意,这不适用于隐藏状态或单元格状态。请参阅 Inputs/Outputs 部分了解详细信息。否则:True False |
| dropout | 如果为非零,则在每个 RNN 层(最后一层除外),其 dropout 概率等于 。默认值:0dropout |
| bidirectional | 如果 ,则变为双向 RNN。否则:True False |
| output | 形状的张量(L,D∗Hout)(长、深∗高out)对于未批处理的输入,(L,N,D∗Hout)(长、北、深∗高out)when 或batch_first=False(N,L,D∗Hout)(北、长、深∗高out)当包含 RNN 最后一层的输出特征 (h_t) 时,对于每个 t。如果已将 a 作为输入,则输出 也将是一个打包序列。batch_first=True |
| h_n | 形状的张量(D∗num_layers,Hout)(D∗num_layers,Hout)对于未批处理的输入,或(D∗num_layers,N,Hout)(D∗num_layers,N,Hout)包含最终的 Hidden 状态 对于批处理中的每个元素。 |
三、设计思路
输入的特征个数->隐藏层->输出层特征个数。
1. 输入的特征个数是9,即[0, 0, 0, 1, 0, 0, 0, 0, 0]的长度。
2. 采用一层的隐藏层,其节点个数是可选的。
3. 输出层特征个数和输入特征个数是一样的,也是9。
3.1、数据输入
import torch
import numpy as np
from torch import nn
# 1. 字符输入
text = "hey how are you" # 定义输入的文本序列
# 3. 数据集划分
# 将原始文本序列划分为输入序列和输出序列
# 输入序列是原始文本的除了最后一个字符的部分
input_seq = [text[:-1]]
# 输出序列是原始文本的除了第一个字符的部分,作为模型的目标输出
output_seq = [text[1:]]
print("input_seq:", input_seq)
# print("output_seq:", output_seq)
# 4. 数据编码:one-hot
# 获取文本中所有不重复的字符
chars = set(text)
# 对字符进行排序,确保编码的一致性
chars = sorted(chars)
# print("chars:", chars)
# 创建字符到整数的映射字典
char2int = {char: ind for ind, char in enumerate(chars)}
# print("char2int:", char2int)
# 创建整数到字符的映射字典
int2char = dict(enumerate(chars))
# 将字符序列转换为数字编码序列
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
# print("input_seq:", input_seq)
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
# one-hot 编码函数,用于将数字编码转换为 one-hot 张量,以适应 PyTorch RNN的输入格式
def one_hot_encode(seq, bs, seq_len, size):
# 创建一个形状为 (batch_size, sequence_length, vocabulary_size) 的全零张量
features = np.zeros((bs, seq_len, size), dtype=np.float32)
# 遍历批次中的每个序列
for i in range(bs):
# 遍历序列中的每个时间步
for u in range(seq_len):
# 将对应字符的索引位置设置为 1.0,完成 one-hot 编码
features[i, u, seq[i][u]] = 1.0
# 将 numpy 数组转换为 PyTorch 张量
return torch.tensor(features, dtype=torch.float32)
# 对输入序列进行 one-hot 编码
input_seq = one_hot_encode(input_seq, 1, len(text) - 1, len(chars))
# 将输出序列转换为 PyTorch 长整型张量,并调整形状为 (sequence_length),以适应 CrossEntropyLoss
output_seq = torch.tensor(output_seq, dtype=torch.long).view(-1)
print("output_seq:", output_seq)3.2、定义模型
# 5. 定义前向模型
class Model(nn.Module):
def __init__(self, input_size, hidden_size, out_size):
super(Model, self).__init__()
self.hidden_size = hidden_size
# 定义一个单层 RNN 网络,输入维度为 input_size,隐藏层维度为 hidden_size,batch_first=True 表示输入张量的第一个维度是 batch size
self.rnn1 = nn.RNN(input_size, hidden_size, num_layers=1, batch_first=True)
# 定义一个全连接层,将 RNN 的输出映射到词汇表大小
self.fc1 = nn.Linear(hidden_size, out_size)
def forward(self, x):
# 通过 RNN 层,out 包含每个时间步的隐藏状态,hidden 是最后一个时间步的隐藏状态
out, hidden = self.rnn1(x)
# 将 RNN 的输出形状从 (batch_size, sequence_length, hidden_size) 调整为 (batch_size * sequence_length, hidden_size),以便输入到全连接层
x = out.view(-1, self.hidden_size)
# 通过全连接层得到模型的预测输出
x = self.fc1(x)
return x, hidden
# 实例化模型,输入大小为词汇表大小,隐藏层大小为 32,输出大小也为词汇表大小
model = Model(len(chars), 32, len(chars))3.3、损失函数优化器
# 6. 定义损失函数和优化器
# 使用交叉熵损失函数,常用于多分类问题
cri = nn.CrossEntropyLoss()
# 使用 Adam 优化器,学习率为 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)3.4、训练模型
epochs = 1000
for epoch in range(1, epochs + 1):
# 前向传播,获取模型的输出和隐藏状态
output, hidden = model(input_seq)
# 计算损失
loss = cri(output, output_seq)
# 梯度清零
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 8. 显示频率设置
if epoch == 0 or epoch % 50 == 0:
print(f"Epoch [{epoch}/{epochs}], Loss {loss:.4f}")3.5、验证模型
# 预测下面几个字符
input_text = "hey" # 设置初始输入文本
to_be_pre_len = 12 # 设置要预测的字符个数
# 循环进行预测
for i in range(to_be_pre_len):
# 将当前输入文本转换为字符列表
chars = [char for char in input_text]
# print(chars)
# 将字符列表转换为数字编码的 numpy 数组
character = np.array([[char2int[c] for c in chars]])
# 对数字编码进行 one-hot 编码
character = one_hot_encode(character, 1, character.shape[1], 9)
# 将 numpy 数组转换为 PyTorch 张量
character = torch.tensor(character, dtype=torch.float32)
# 将 one-hot 编码的输入传递给模型,获取输出和隐藏状态
out, hidden = model(character)
# 获取最后一个时间步输出中概率最大的字符的索引
char_index = torch.argmax(out[-1]).item()
# 将预测的字符添加到输入文本中,用于下一次的预测
input_text += int2char[char_index]
print("预测到的:", input_text)3.6、完整代码
import torch
import numpy as np
from torch import nn
# 1. 字符输入
text = "hey how are you" # 定义输入的文本序列
# 3. 数据集划分
# 将原始文本序列划分为输入序列和输出序列
# 输入序列是原始文本的除了最后一个字符的部分
input_seq = [text[:-1]]
# 输出序列是原始文本的除了第一个字符的部分,作为模型的目标输出
output_seq = [text[1:]]
print("input_seq:", input_seq)
# print("output_seq:", output_seq)
# 4. 数据编码:one-hot
# 获取文本中所有不重复的字符
chars = set(text)
# 对字符进行排序,确保编码的一致性
chars = sorted(chars)
# print("chars:", chars)
# 创建字符到整数的映射字典
char2int = {char: ind for ind, char in enumerate(chars)}
# print("char2int:", char2int)
# 创建整数到字符的映射字典
int2char = dict(enumerate(chars))
# 将字符序列转换为数字编码序列
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
# print("input_seq:", input_seq)
output_seq = [[char2int[char] for char in seq] for seq in output_seq]
# one-hot 编码函数,用于将数字编码转换为 one-hot 张量,以适应 PyTorch RNN的输入格式
def one_hot_encode(seq, bs, seq_len, size):
# 创建一个形状为 (batch_size, sequence_length, vocabulary_size) 的全零张量
features = np.zeros((bs, seq_len, size), dtype=np.float32)
# 遍历批次中的每个序列
for i in range(bs):
# 遍历序列中的每个时间步
for u in range(seq_len):
# 将对应字符的索引位置设置为 1.0,完成 one-hot 编码
features[i, u, seq[i][u]] = 1.0
# 将 numpy 数组转换为 PyTorch 张量
return torch.tensor(features, dtype=torch.float32)
# 对输入序列进行 one-hot 编码
input_seq = one_hot_encode(input_seq, 1, len(text) - 1, len(chars))
# 将输出序列转换为 PyTorch 长整型张量,并调整形状为 (sequence_length),以适应 CrossEntropyLoss
output_seq = torch.tensor(output_seq, dtype=torch.long).view(-1)
print("output_seq:", output_seq)
# 5. 定义前向模型
class Model(nn.Module):
def __init__(self, input_size, hidden_size, out_size):
super(Model, self).__init__()
self.hidden_size = hidden_size
# 定义一个单层 RNN 网络,输入维度为 input_size,隐藏层维度为 hidden_size,batch_first=True 表示输入张量的第一个维度是 batch size
self.rnn1 = nn.RNN(input_size, hidden_size, num_layers=1, batch_first=True)
# 定义一个全连接层,将 RNN 的输出映射到词汇表大小
self.fc1 = nn.Linear(hidden_size, out_size)
def forward(self, x):
# 通过 RNN 层,out 包含每个时间步的隐藏状态,hidden 是最后一个时间步的隐藏状态
out, hidden = self.rnn1(x)
# 将 RNN 的输出形状从 (batch_size, sequence_length, hidden_size) 调整为 (batch_size * sequence_length, hidden_size),以便输入到全连接层
x = out.view(-1, self.hidden_size)
# 通过全连接层得到模型的预测输出
x = self.fc1(x)
return x, hidden
# 实例化模型,输入大小为词汇表大小,隐藏层大小为 32,输出大小也为词汇表大小
model = Model(len(chars), 32, len(chars))
# 6. 定义损失函数和优化器
# 使用交叉熵损失函数,常用于多分类问题
cri = nn.CrossEntropyLoss()
# 使用 Adam 优化器,学习率为 0.01
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 7. 开始迭代训练
epochs = 1000
for epoch in range(1, epochs + 1):
# 前向传播,获取模型的输出和隐藏状态
output, hidden = model(input_seq)
# 计算损失
loss = cri(output, output_seq)
# 梯度清零
optimizer.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 8. 显示频率设置
if epoch == 0 or epoch % 50 == 0:
print(f"Epoch [{epoch}/{epochs}], Loss {loss:.4f}")
# 预测下面几个字符
input_text = "hey" # 设置初始输入文本
to_be_pre_len = 12 # 设置要预测的字符个数
# 循环进行预测
for i in range(to_be_pre_len):
# 将当前输入文本转换为字符列表
chars = [char for char in input_text]
# print(chars)
# 将字符列表转换为数字编码的 numpy 数组
character = np.array([[char2int[c] for c in chars]])
# 对数字编码进行 one-hot 编码
character = one_hot_encode(character, 1, character.shape[1], 9)
# 将 numpy 数组转换为 PyTorch 张量
character = torch.tensor(character, dtype=torch.float32)
# 将 one-hot 编码的输入传递给模型,获取输出和隐藏状态
out, hidden = model(character)
# 获取最后一个时间步输出中概率最大的字符的索引
char_index = torch.argmax(out[-1]).item()
# 将预测的字符添加到输入文本中,用于下一次的预测
input_text += int2char[char_index]
print("预测到的:", input_text)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









