







目录:
1:字典树介绍:
字典树介绍:
字典树又称前缀树(trie),主要用于字符串的存储与查询,与哈希表相比有近乎相同的时间效率和空间效率,而且两者差异很大,其能完成一些用哈希很难解决又有较高时间要求的问题。
字典树是由树节点构成,我们来看每个树的节点该如何定义:
typedef struct TreeNode
{
int val;
struct TreeNode* next[26];
}node;我们利用val来记录当前字母有几个公共前缀,用26个树节点指针来记录,这里我们根据英文的26个字母(假设记录的都是英语),根节点不记录任何数据。
//新建节点
node* NewNode()
{
node* root = (node*)malloc(sizeof(node));
int i = 0;
for (i = 0; i < 26; i++)
{
root->next[i] = NULL;
}
root->val = 0;
return root;
}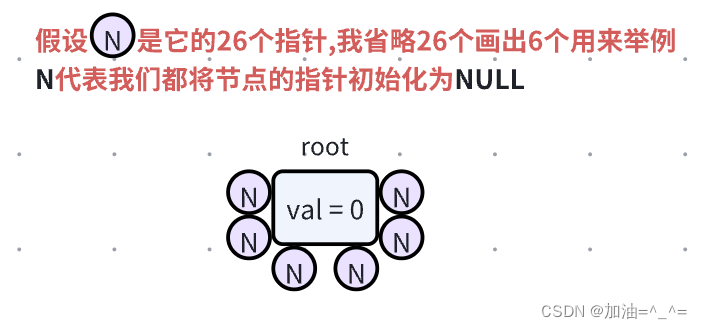 此时我们往里面插入数据,比如插入一个“brad”字符串。
此时我们往里面插入数据,比如插入一个“brad”字符串。
//插入节点
void Insert(node* root, char* s)
{
int i = 0;
for (i = 0; s[i] != '\0'; i++)
{
if (root->next[s[i] - 'a'] == NULL)
{
root->next[s[i] - 'a'] = NewNode();
}
//根节点的值为0
root = root->next[s[i] - 'a']; //先迭代后赋值
root->val++;
}
} 我们在遍历字符串的同时,去访问它是否有该位置的的指针,如果没有,就去创建;有则把节点val值增加1,标记其字母增加了1次。
 此时我们再向字典树中插入单词“bread”,它会在原来的基础上,存在则迭代根节点继续向下寻找,并把标记增加1;否则就开辟新的节点。
此时我们再向字典树中插入单词“bread”,它会在原来的基础上,存在则迭代根节点继续向下寻找,并把标记增加1;否则就开辟新的节点。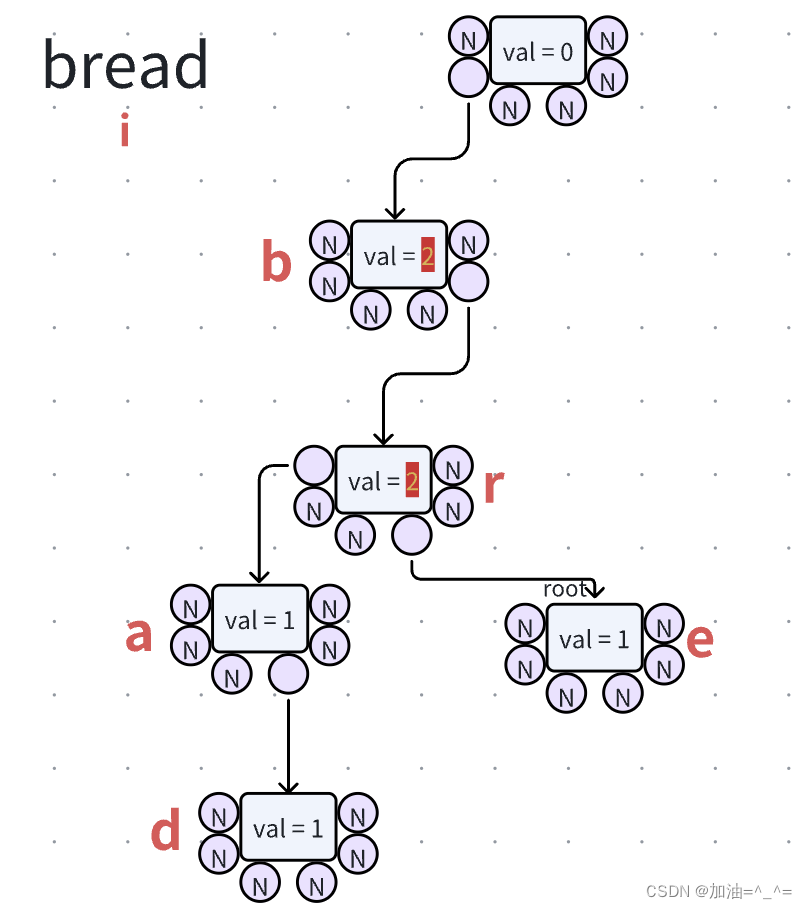
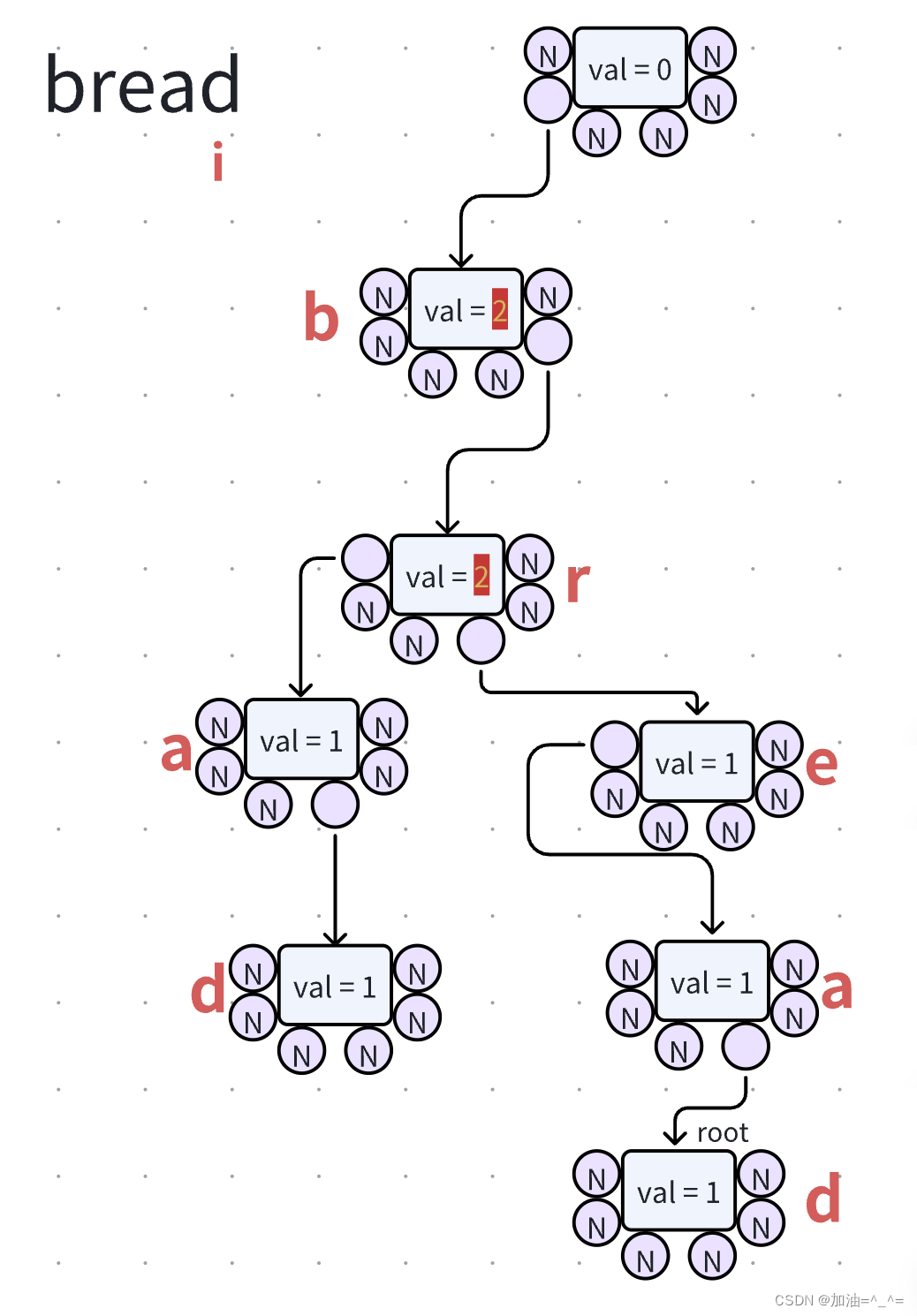 此时我们可以看到,字典树中有多少共同前缀,都一一记录清楚,比如我们再向其中插入“bed”,并直接给出结果:
此时我们可以看到,字典树中有多少共同前缀,都一一记录清楚,比如我们再向其中插入“bed”,并直接给出结果: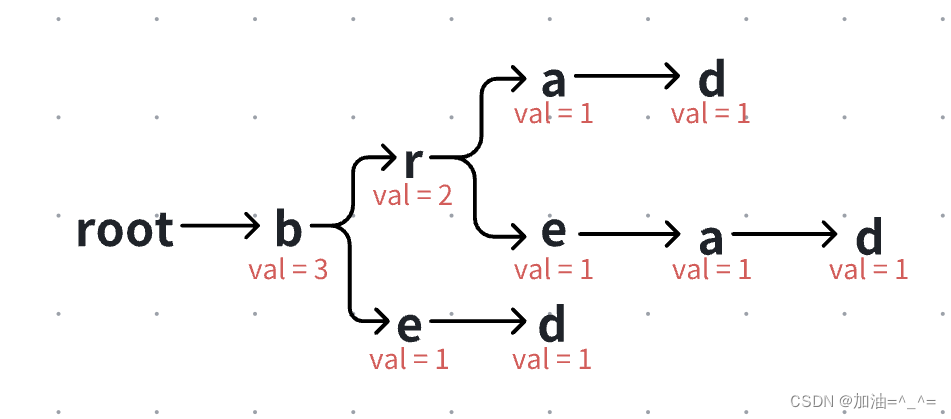 此时我们可以查阅一个字符串有多少个共同前缀:
此时我们可以查阅一个字符串有多少个共同前缀:
//搜索,返回标记即可
int Search(node* root, char* s)
{
int i = 0;
for (i = 0; s[i] != '\0'; i++)
{
if (root->next[s[i] - 'a'] == NULL)
{
return 0;
}
else
{
root = root->next[s[i] - 'a'];
}
}
return root->val;
} 比如我们当前搜索字符串“b”,应当返回“b”节点的val = 3;查询“bed”应当返回val = 1。 最后我们要释放节点,则利用递归逐个释放:
最后我们要释放节点,则利用递归逐个释放:
//释放
void Realse(node* root)
{
//递归销毁
int i = 0;
for (i = 0; i < 26; i++)
{
if (root->next[i] != NULL)
{
Realse(root->next[i]);
}
}
free(root);
}这里我们给出全部字典树相关代码:
#include<stdio.h>
#include<stdlib.h>
typedef struct TreeNode
{
int val;
struct TreeNode* next[26];
}node;
//新建节点
node* NewNode()
{
node* root = (node*)malloc(sizeof(node));
int i = 0;
for (i = 0; i < 26; i++)
{
root->next[i] = NULL;
}
root->val = 0;
return root;
}
//插入节点
void Insert(node* root, char* s)
{
int i = 0;
for (i = 0; s[i] != '\0'; i++)
{
if (root->next[s[i] - 'a'] == NULL)
{
root->next[s[i] - 'a'] = NewNode();
}
//根节点的值为0
root = root->next[s[i] - 'a']; //先迭代后赋值
root->val++;
}
}
//搜索,返回标记即可
int Search(node* root, char* s)
{
int i = 0;
for (i = 0; s[i] != '\0'; i++)
{
if (root->next[s[i] - 'a'] == NULL)
{
return 0;
}
else
{
root = root->next[s[i] - 'a'];
}
}
return root->val;
}
//释放
void Realse(node* root)
{
//递归销毁
int i = 0;
for (i = 0; i < 26; i++)
{
if (root->next[i] != NULL)
{
Realse(root->next[i]);
}
}
free(root);
}
int main()
{
node* root = NewNode();
Insert(root, "brad");
Insert(root, "bread");
Insert(root, "bed");
int ret = Search(root, "bed");
printf("ret = %d\n", ret);
ret = Search(root, "b");
printf("ret = %d\n", ret);
//释放节点
Realse(root);
return 0;
}字典树应用场景及相关例题:
最后我们来看一道关于利用字典树来解决的一题:求数组中两个数的最大异或值。
其实这一题很简答,我们可以直接使用暴力方法双重遍历去寻找两个数异或的最大值,得出结果即可。
如果这题是简单题,暴力肯定随便过,但是!这是力扣的中等题,各位不要想着暴力了,会超时的。所以我们只能使用其他方法,此时我们就可以使用字典树,这里确实很难想到我大致说一下方法:假设数组中有 i 个元素,我们把数组中的 i - 1 个元素放入字典树,把第 i 个元素与字典树中的元素异或。因为异或的性质就是相同出零,相异出一,此时得出最大值则是异或最大。
不多说,上图:
定义一个返回值x。因为题目给出都是正整数,并且不会超过2^31,所以最多有31个bit位,所以最多左移30位,所以我们每次判断最高位。
- 判断当前位如果为1,则去字典树左边寻找(因为左边就是0),如果存在,则将 x = x * 2 +1(因为二进制位每次多一个1,十进制就 * 2 + 1);左边如果不存在,就只能去右边,则将 x = x * 2 (二进制位每多一个0,十进制 * 2)。
- 判断当前位如果为0,则去字典树右边寻找(因为右边就是1),如果存在,则将 x = x * 2 + 1(因为二进制位每次多一个1,十进制就 * 2 + 1);右边如果不存在,就只能去左边,则将 x = x * 2 (二进制位每多一个0,十进制 * 2)。
此时不再做过多解释,上代码!
//其实基本思路就是将i-1(一共i个元素)个元素放在字典树中
//之后用最后一个元素nums[i] 与字典树比较得出最大值
//只有左右节点, 左节点表示0, 右节点表示1
typedef struct Node
{
struct Node* left;
struct Node* right;
}Trie;
//初始化
Trie* newNode()
{
Trie* root = (Trie*)malloc(sizeof(Trie));
root->left = NULL;
root->right = NULL;
return root;
}
//添加数字
void add(Trie* root, int n)
{
//因为最多 31 位, 所以最多右移 30 位
for (int count = 30; count >= 0; count--)
{
int bit = (n >> count) & 1;
if (bit == 0)
{
//向左
if (!root->left)
{
root->left = newNode();
}
root = root->left;
}
else
{
//向右
if (!root->right)
{
root->right = newNode();
}
root = root->right;
}
}
}
//与字典树所有元素比较求异或最大
int check(Trie* root, int n)
{
int x = 0;
for (int k = 30; k >= 0; k--)
{
int bit = (n >> k) & 1;
if (bit == 0)
{
//此时要去找 1 这样才能使结果最大
//如果右边有, 则去右边
if (root->right)
{
root = root->right;
//如果一个数每次二进制位上加1
//那么其实就是 * 2 + 1
x = x * 2 + 1;
}
else
{//没有右节点,没有不同比特位,只能找0
root = root->left;
x = x * 2;
}
}
else
{
//此时找到1
//去左边找0
if (root->left)
{
root = root->left;
x = x * 2 + 1;
}
else
{
root = root->right;
x = x * 2;
}
}
}
return x;
}
int findMaximumXOR(int* nums, int numsSize){
//先建树
Trie* root = newNode();
int x = 0;
for (int i = 1; i < numsSize; i++)
{
add(root, nums[i - 1]);
//将 nums[i - 1] 放入字典树,此时nums[0 .. i - 1] 都在字典树中
//之后 nums[i] 与 字典树中所有元素对比, 得出最大值
x = fmax(x, check(root, nums[i]));
}
return x;
}如果能耐心看完这篇文章,我相信对你肯定有所帮助,水滴石穿。当然,有什么不足请在请在评论区指出,感谢各位!














 241
241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









