






一、问题背景
在爬取拼多多商品页数据时,发现价格/销量等关键数据使用字体加密技术,网页中显示的""等Unicode字符无法直接转换为真实数字。本文通过Python实现了一套完整的解密方案。
二、解决思路
- 下载字体文件:从网页源码中提取字体文件URL
- 解析字体映射:使用fontTools解析字形关系
- 建立字符映射:通过Unicode码位与真实数字的对应关系
- 文本替换解密:根据映射表还原加密文本
我们看一下PDD的商家后台 上图
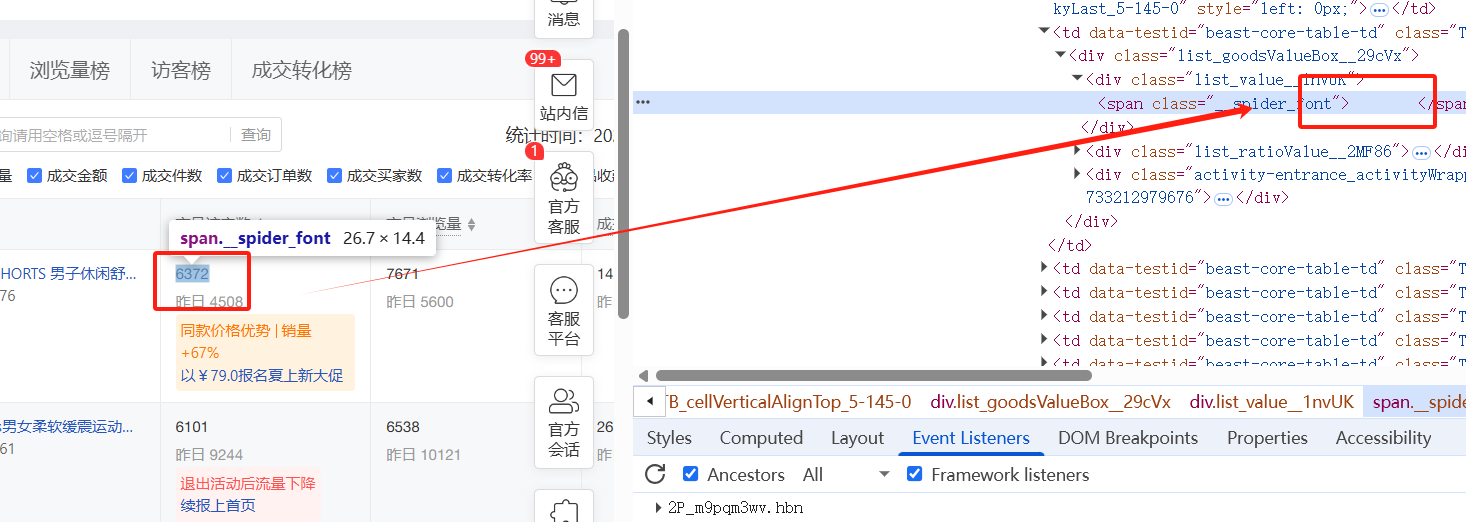
爬出来是这样的
爬取或者复制粘贴出来发现数字不是6372,而是这样的一个东西 ""从上图我们可以看出数字是一行的空白,后面被浏览器渲染后才展现的数字
我们发现每个加密的数字都有一个属性class="__spider_font"

我们搜索这个属性我们可以看到第一个这样的属性有一个URL,这个就是解密的字体包
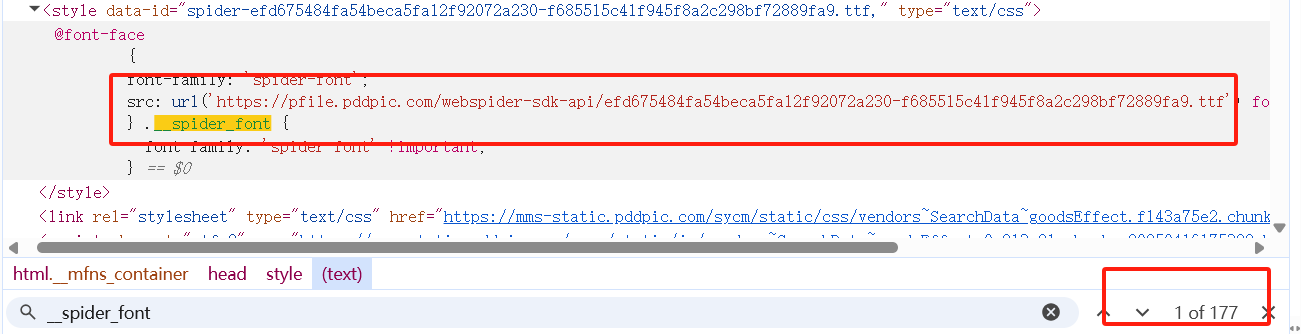
我们请求这个链接获取他的信息
三、关键代码解析
这个字典是使用 TTFont 解析字体文件,获取 Unicode 码位到字形名称的映射:
font_url = "https://pfile.pddpic.com/webspider-sdk-api/efd675484fa54beca5fa12f92072a230-f685515c41f945f8a2c298bf72889fa9.ttf" # 替换为实际URL
response = requests.get(font_url)
with open("encrypted_font.woff", "wb") as f:
f.write(response.content)
font = TTFont("encrypted_font.woff")
cmap = font.getBestCmap() # 获取 Unicode 到字形名称的映射
print("字符编码到字形的映射:", cmap)我们看一下这个结果其中当使用 font.getBestCmap() 获取字体映射时,得到的 cmap 字典结构如下:
#运行结果
字符编码到字形的映射:
{46: 'period',
58203: 'uniE35B',
58222: 'uniE36E',
58519: 'uniE497',
58573: 'uniE4CD',
58925: 'uniE62D',
58954: 'uniE64A',
60501: 'uniEC55',
60666: 'uniECFA',
60934: 'uniEE06',
61022: 'uniEE5E'}📌 键(Key):十进制的 Unicode 码位
- 含义:表示字符在 Unicode 标准中的唯一标识值。
- 获取方式:Python 中通过
ord(字符)获得。 - 示例:
字符对应的十进制码位为58222
📌 值(Value):字形的名称
🌰 举个栗子
假设你在网页上看到一个显示为 2 的字符,背后发生的故事:
| 步骤 | 数据来源 | 示例值 | 说明 |
|---|---|---|---|
| 1 | 网页HTML源码 |  | HTML实体,对应十六进制 E36E |
| 2 | cmap 字典 | 58222: 'uniE36E' | 十进制码位 → 字形名称 |
| 3 | 字体文件图形数据 | uniE36E 对应图形 2 | 实际显示的符号 |
- 命名规则:通常以
uni开头,后面跟着该字符的 十六进制 Unicode 码位(大写)。 - 示例:
uniE36E中的E36E对应十六进制值,转换后为十进制: -
🔍 值(字形名称) ≠ 直接复制的方块符号!
📌 关键结论
-
cmap中的值(如uniE35B)是字体内部的字形名称,不是你在网页上看到的方块符号。 - 复制的乱码方块符号(如
)本质是 Unicode 字符,其显示效果依赖字体文件。 - 字形名称和显示符号的关联:
- 通过
cmap的键(十进制码位)链接到字形名称 - 通过字体文件的图形数据链接到实际显示符号
- 通过
然后我们要建立映射关系,根据观察结果手动创建映射字典:
我们需要用到一个网站
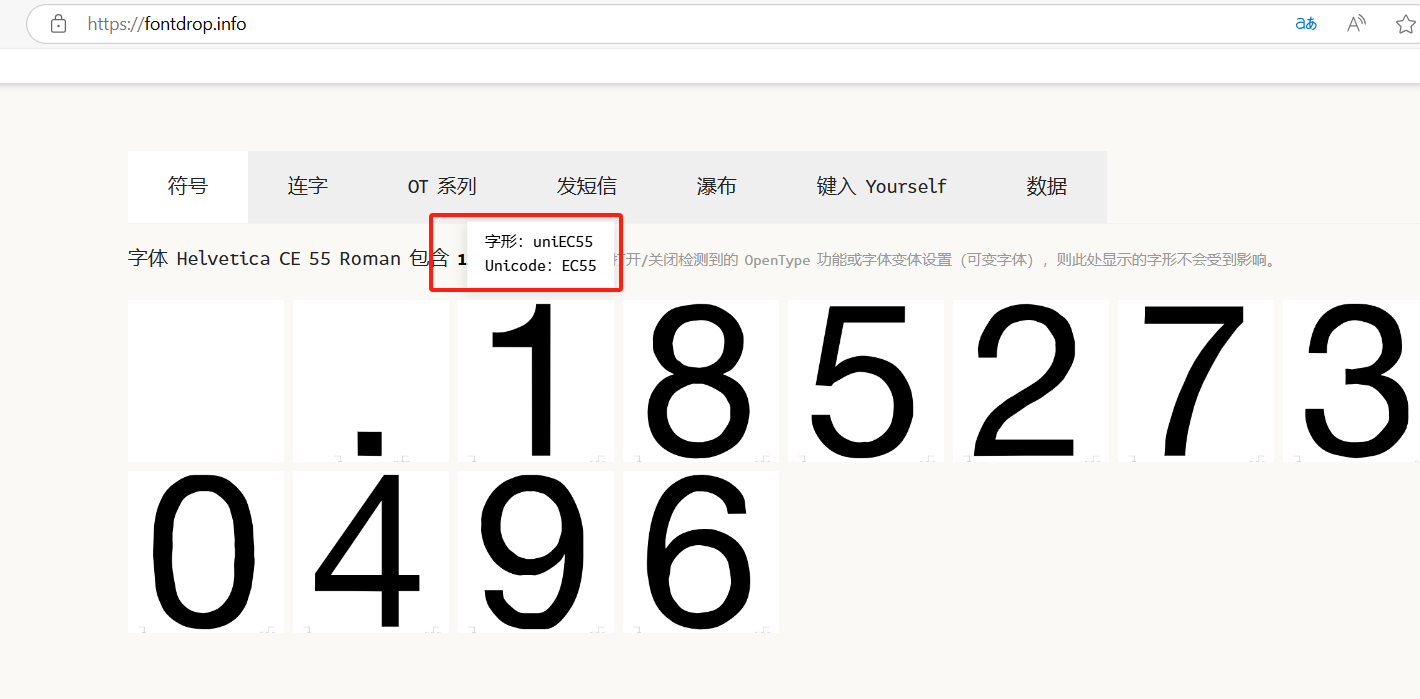
我们看到有一个Unicode编码,
uni 后的 EC55 是该字符的 Unicode 码位(十六进制)
我们可以用这个代码查看十六位进制对应的十进制,为什么要看十进制呢?因为我们要构造一个十进制数字对应的字典,ord()函数返回的是十进制的Unicode码位,而字体文件中的字符映射关系(cmap)也是以十进制存储的。用十进制键能直接匹配,无需转换!
我们可以用这个代码查看十六进制对应的十进制、
print(int("002E",16))然后我们构造一个这样的映射字典 key就是对应的十进制,后面的值就是对应的数字
custom_map = {
60501: '1', # 注意:Unicode码位需转换为十进制
58222: '2',
58519: '3',
58203: '4',
60666: '5',
60934: '6',
58925: '7',
58573: '8',
61022: '9',
58954: '0',
46:'.'
# 继续添加其他字符...
}然后我们需要封装一个函数,将加密文字和映射字典传入,返回解密后的数字
def decrypt_text(text, mapping):
"""将加密文本根据映射字典解密"""
decrypted = []
for char in text:
# 获取字符的 Unicode 码位(十进制)
unicode_code = ord(char)
# 从映射字典中查找对应的真实字符,找不到则保留原字符
decrypted_char = mapping.get(unicode_code, char)
decrypted.append(decrypted_char)
return ''.join(decrypted)最后我们测试一下
encrypted_text="" #5505的加密字符
decrypted = decrypt_text(encrypted_text, custom_map)
print(decrypted) # 预期输出: "5005"看一下运行结果

完美
下面是完整代码我是在影刀中写的,其他编译器前四个包大家可以不用导
# 使用提醒:
# 1. xbot包提供软件自动化、数据表格、Excel、日志、AI等功能
# 2. package包提供访问当前应用数据的功能,如获取元素、访问全局变量、获取资源文件等功能
# 3. 当此模块作为流程独立运行时执行main函数
# 4. 可视化流程中可以通过"调用模块"的指令使用此模块
import xbot
from xbot import print, sleep
from .import package
from .package import variables as glv
import requests
from fontTools.ttLib import TTFont
def decrypt_text(text, mapping):
"""将加密文本根据映射字典解密"""
decrypted = []
for char in text:
# 获取字符的 Unicode 码位(十进制)
unicode_code = ord(char)
# 从映射字典中查找对应的真实字符,找不到则保留原字符
decrypted_char = mapping.get(unicode_code, char)
decrypted.append(decrypted_char)
return ''.join(decrypted)
def main(args):
font_url = "https://pfile.pddpic.com/webspider-sdk-api/efd675484fa54beca5fa12f92072a230-f685515c41f945f8a2c298bf72889fa9.ttf" # 替换为实际URL
response = requests.get(font_url)
with open("encrypted_font.woff", "wb") as f:
f.write(response.content)
font = TTFont("encrypted_font.woff")
cmap = font.getBestCmap() # 获取 Unicode 到字形名称的映射
print("字符编码到字形的映射:", cmap)
'''
{46: 'period',
58203: 'uniE35B', 4
58222: 'uniE36E', 2
58519: 'uniE497', 3
58573: 'uniE4CD', 8
58925: 'uniE62D', 7
58954: 'uniE64A', 0
60501: 'uniEC55', 1
60666: 'uniECFA', 5
60934: 'uniEE06', 6
61022: 'uniEE5E'9
002E:"."}
'''
print(int("002E",16))
custom_map = {
60501: '1', # 注意:Unicode码位需转换为十进制
58222: '2',
58519: '3',
58203: '4',
60666: '5',
60934: '6',
58925: '7',
58573: '8',
61022: '9',
58954: '0',
46:'.'
# 继续添加其他字符...
}
# 假设加密文本是Unicode字符 "\ue901\ue902"
#encrypted_text = "" #24053
#encrypted_text="" #17278
encrypted_text="" #5505
decrypted = decrypt_text(encrypted_text, custom_map)
print(decrypted) # 预期输出: "5005"
pass

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









