






1、正则是什么
正则就是对一大段文本中提取数想要的数据的方法
2、正则的优点
1、效率高,速度快
2、准确
3、语法
用字符进行排列组合,用一句话从大字符串提取想要的内容
3.1 常用的元字符串(加粗为常用重要)
| 字符 | 含义 |
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母 或数字 或 下划线 |
| \s | 匹配任意的空白符(空格 换行 回车) |
| \d | 匹配数字 |
| \n | 匹配换行符 |
| \t | 一个只制表符 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| \W | 匹配非字母非数字或非下划线 |
| \D | 匹配非数字 |
| \S | 匹配非空白符 |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| [] | 匹配字符组中的字符如[a-zA-Z0-9] |
| [^] | 匹配除了字符组中的所有字符 |
3.2 量词
| 字符 | 含义 |
| * | 重复0次或更多次(尽可能多的去匹配) |
| + | 重复一个或更多次 |
| ? | 重复0次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
3.3 贪婪匹配和惰性匹配
| 字符 | 含义 |
| .* | 贪婪匹配(尽可能多的匹配能容) |
| .*? | 尽可能少的匹配内容 |
4、正则测试与练习
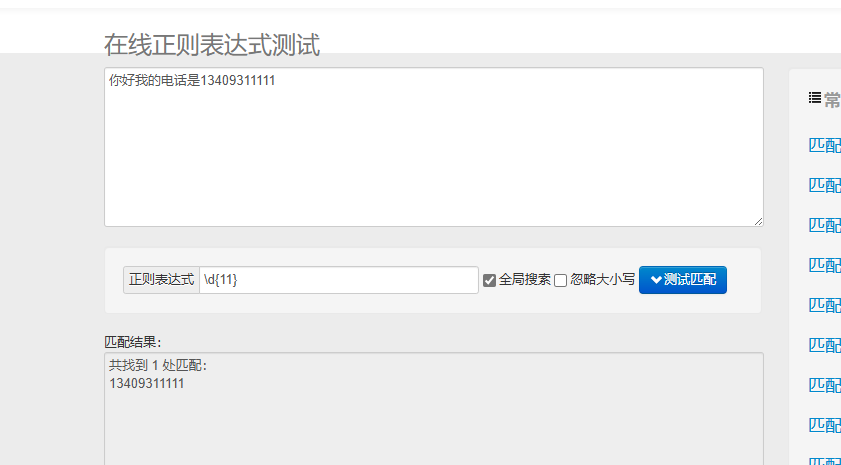
https://tool.oschina.net/regex#
5、python应用 re模块
5.1 findall
re.findall(pattern,string)
pattern:正则表达式
string:要匹配的东西 正则前面加一个r
例如:
lis=re.findall(r"\d+","我的电话是10086")
输出 ['10086']
返回的是list.,匹配字符串中所有符合正则的内容
findall 用的少,因为列表的效率不高
5.2 finditer
re.serch(pattern,string)
返回的是迭代器,match对象迭代器中拿出东西需要 遍历然后.grop()
怎么用
import re
pattern=r"\d+"
string="我的电话是10086"
iter=re.finditer(pattern,string)
for i in iter:
print(i.group())
#输出 100865.3 re.serch
re.serch(pattern,string)
seach 返回的结果是match对象,从match中拿东西需要 .grop()
与 finditer基本相似, 不同的是,serch找到一个就返回,finditer返回全部结果,
| 特性 | re.search() | re.finditer() |
|---|---|---|
| 返回值 | 单个 re.Match 对象(或 None) | 迭代器(生成 re.Match 对象) |
| 匹配行为 | 找到第一个匹配后立即返回 | 返回所有非重叠匹配 |
| 内存效率 | 低(只存储一个匹配) | 高(惰性计算,不一次性存储所有结果) |
| 适用场景 | 只需第一个匹配(如验证格式) | 需要所有匹配(如提取数据) |
serch可以证明存在过
import re
text = "电话:10086,备用:1008611"
match = re.search(r"\d+", text)
print(match.group()) if match else print("无匹配") # 输出: 100865.4 re.match
re.match(pattern,string)
从头开始匹配,不是全文匹配
5.5 re.compile
预加载正则表达式,可以反复使用,
import re
string="我的电话是10086"
re.compile(r"\d+")
obj=re.compile(r"\d+")
ret=obj.finditer(string)
for i in ret:
print(i.group())
#输出10086
5.6 重点用法 分组用法
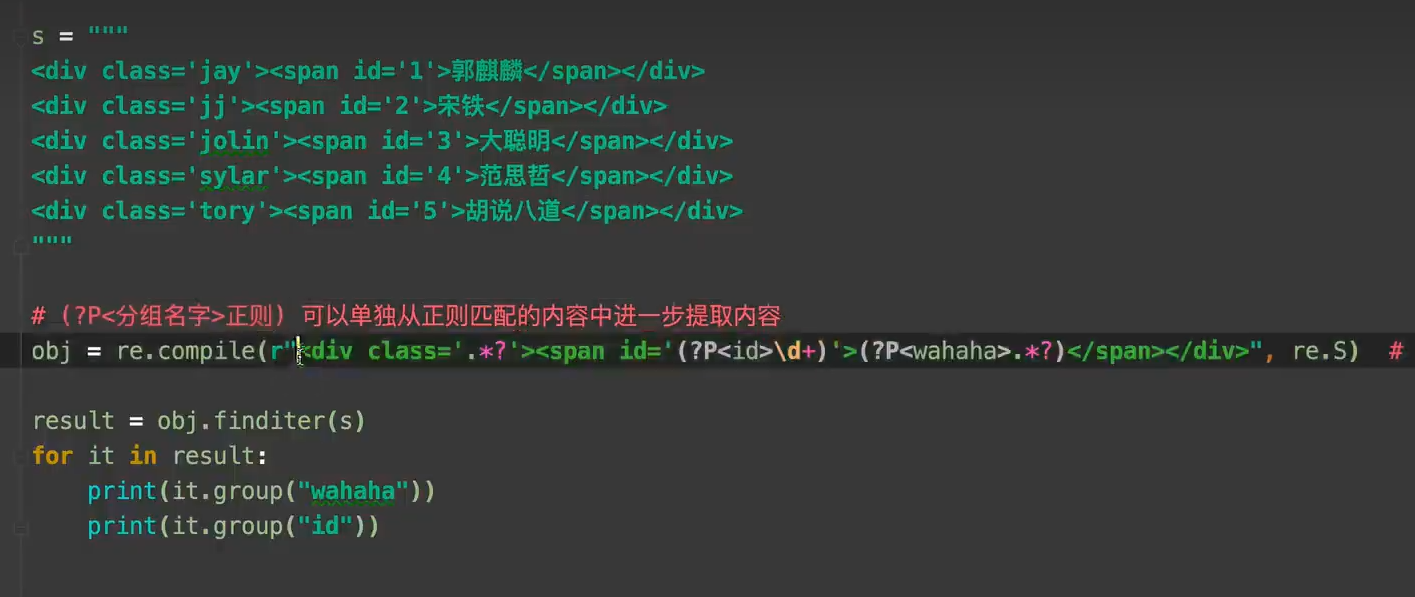
注意
最后加上 re.S 表示让.什么都能匹配到换行符也可以匹配到,防止断掉
想要看某块的东西就要把这个正则括起来 (.*?)
然后加上 P<组名> 如(?P<组名>.*?)
循环遍历迭代器 for i in 组名:
print(i.group("组名"))

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









