






C++11
面向对象特点
面向对象的三个基本特征是:封装、继承、多态。
封装
封装最好理解了。封装是面向对象的特征之一,是对象和类概念的主要特性。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为“基类”、“父类”或“超类”。
继承的过程,就是从一般到特殊的过程。
多态
多态是允许不同类的对象使用相同的接口名字,但具有不同实现的特性。
在 C++ 中,多态主要通过虚函数(Virtual Function)和抽象基类(Abstract Base Class)来实现。
虚函数允许在派生类中重写基类的方法,而抽象基类包含至少一个纯虚函数(Pure Virtual Function),不能被实例化,只能作为其他派生类的基类。
多态、虚函数表和纯虚函数
多态
C++中的多态是指同一个函数或者操作在不同的对象上有不同的表现形式。
多态是允许不同类的对象使用相同的接口名字,但具有不同实现的特性。
在 C++ 中,多态主要通过虚函数(Virtual Function)和抽象基类(Abstract Base Class)来实现。
虚函数允许在派生类中重写基类的方法,而抽象基类包含至少一个纯虚函数(Pure Virtual Function),不能被实例化,只能作为其他派生类的基类。
虚函数实现多态的底层原理
子类的虚函数表中用子类重写的函数地址去取代父类的函数地址。
必须满足两个条件:
-
必须通过基类的指针或者引用调用虚函数
-
被调用的函数是虚函数,且必须完成对基类虚函数的重写
虚函数表
每一个含有虚函数(无论是其本身的,还是继承而来的)的类都至少有一个与之对应的虚函数表,其中存放着该类所有的虚函数对应的函数指针。
纯虚函数
纯虚函数是一种在基类中声明但没有实现的虚函数。
它的作用是定义了一种接口,这个接口需要由派生类来实现。(PS: C++ 中没有接口,纯虚函数可以提供类似的功能
包含纯虚函数的类称为抽象类(Abstract Class)。
抽象类仅仅提供了一些接口,但是没有实现具体的功能。
作用就是制定各种接口,通过派生类来实现不同的功能,从而实现代码的复用和可扩展性。
另外,抽象类无法实例化,也就是无法创建对象。
原因很简单,纯虚函数没有函数体,不是完整的函数,无法调用,也无法为其分配内存空间。
重载、重写和隐藏
重载
重载是指相同作用域(比如命名空间或者同一个类)内拥有相同的方法名,但具有不同的参数类型或参数数量的方法。 重载允许根据所提供的参数不同来调用不同的函数。它主要在以下情况下使用:
-
方法具有相同的名称。
-
方法具有不同的参数类型或参数数量。
-
返回类型可以相同或不同。
-
同一作用域,比如都是一个类的成员函数,或者都是全局函数

重写
重写是指在派生类中重新定义基类中的方法。
当派生类需要改变或扩展基类方法的功能时,就需要用到重写。
重写的条件包括:
-
方法具有相同的名称。
-
方法具有相同的参数类型和数量。
-
方法具有相同的返回类型。
-
重写的基类中被重写的函数必须有virtual修饰。
-
重写主要在继承关系的类之间发生。


隐藏
隐藏是指派生类的函数屏蔽了与其同名的基类函数。注意只要同名函数,不管参数列表是否相同,基类函数都会被隐藏。

重载和重写的区别
范围区别:重写和被重写的函数在不同的类中,重载和被重载的函数在同一类中(同一作用域)。 参数区别:重写与被重写的函数参数列表一定相同,重载和被重载的函数参数列表一定不同。 virtual的区别:重写的基类必须要有virtual修饰,重载函数和被重载函数可以被virtual修饰,也可以没有。
隐藏和重写,重载的区别
与重载范围不同:隐藏函数和被隐藏函数在不同类中。 参数的区别:隐藏函数和被隐藏函数参数列表可以相同,也可以不同,但函数名一定同;当参数不同时,无论基类中的函数是否被virtual修饰,基类函数都是被隐藏,而不是被重写。
virtual
-
virtual可以修饰普通成员函数和析构函数;
-
不可以修饰构造函数,友元函数,static静态函数;
-
virtual具有继承性:父类中定义为virtual的函数在子类中重写的函数也自动成为虚函数。
-
如果一个基类中的函数是虚函数,其派生类不声明该函数为虚函数,那么该函数在派生类中仍然是一个虚函数。
深拷贝和浅拷贝
1、浅拷贝:
浅拷贝仅复制对象的基本类型成员和指针成员的值,而不复制指针所指向的内存。
这可能导致两个对象共享相同的资源,从而引发潜在的问题,如内存泄漏、意外修改共享资源等。
一般来说编译器默认帮我们实现的拷贝构造函数就是一种浅拷贝。
2、深拷贝:
深拷贝不仅复制对象的基本类型成员和指针成员的值,还复制指针所指向的内存。
因此,两个对象不会共享相同的资源,避免了潜在问题。
深拷贝通常需要显式实现拷贝构造函数和赋值运算符重载。
什么时候使用深拷贝?
1.一个对象以值传递的方式传入函数体
2.一个对象以值传递的方式从函数体返回
3.一个对象需要通过另一个对象进行初始化
拷贝构造函数和移动构造函数
拷贝构造函数:是一种特殊的构造函数,它用于根据同类型的另一个对象来初始化新对象的成员。拷贝构造函数通常接受一个对源对象的引用作为参数,并且这个引用通常是常量引用,以确保源对象不会被修改。
C++内存分区

堆栈
堆与栈的区别有:栈内存存储的是局部变量而堆内存是实体,栈内存的更新速度高于堆内存,栈内存的生命周期一结束就会被释放而堆内存会被垃圾回收机制不定时回收
栈中存放的是对象的引用及对象方法中的局部变量的值(参数的值)
堆中存放的是实例对象及成员变量的值(属性的值)
栈内存
栈内存首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
堆内存
存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
new和malloc
1,new是操作符,malloc是函数;malloc只分配内存,而new会分配内存并且调用对象的构造函数来初始化对象。
2,new开辟内存失败抛出异常,malloc申请内存失败返回NULL;
3,new开辟的内存大小不需要指定,malloc需要指定;
4,new开辟的内存的类型会自动推导,不需要强转,malloc需要强转;
5,返回值不同:malloc返回一个 void 指针,需要自己强制类型转换,而new返回一个指向对象类型的指针。
实现原理:
new会先调用operator new函数,申请足够的内存(通常底层使用malloc实现)。然后调用类型的构造函数,初始化成员变量,最后返回自定义类型指针。delete先调用析构函数,然后调用operator delete函数释放内存(通常底层使用free实现)。
malloc申请内存
malloc() 分配的是虚拟内存
-
方式一:通过 brk() 系统调用从堆分配内存
-
方式二:通过 mmap() 系统调用在文件映射区域分配内存;
方式一
过 brk() 函数将「堆顶」指针向高地址移动,获得新的内存空间。
缺点:会是堆内存出现类似分段储存的内存碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。

方式二
通过 mmap() 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷”了一块内存。
缺点:频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
free释放内存
-
malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
-
malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放

free() 函数只传入一个内存地址,为什么能知道要释放多大的内存?
malloc()分配内存时,会多返回16个字节来储存内存块信息
内存泄漏
(1)堆内存泄露:程序中通过malloc、new等从堆中分配的内存没有释放
(2)系统资源泄露:系统分配的资源没有使用相应的函数释放(如Bitmap、handle、socket等)
(3)没有将基类的析构函数定义为虚函数:当基类指针指向的派生类对象时,若基类的析构函数不是virtual,则子类的析构函数不会被调用
(4)释放对象数组是没有使用 delete[ ] 而是 delete
(5)缺少拷贝构造函数:无拷贝构造函数时,则会调用默认构造函数,即浅拷贝
如何检测
手动检查代码:
使用调试器和工具:
-
Valgrind(仅限于Linux和macOS):Valgrind是一个功能强大的内存管理分析工具,可以检测内存泄露、未初始化的内存访问、数组越界等问题。使用Valgrind分析程序时,只需在命令行中输入
valgrind --leak-check=yes your_program即可。 -
Visual Studio中的CRT(C Runtime)调试功能:Visual Studio提供了一些用于检测内存泄露的C Runtime库调试功能。
-
AddressSanitizer:AddressSanitizer是一个用于检测内存错误的编译器插件,适用于GCC和Clang。要启用AddressSanitizer,只需在编译时添加-fsanitize=address选项。
野指针和空悬指针
野指针是一个未被初始化或已被释放的指针。
所以它的值是不确定的,可能指向任意内存地址。
空悬指针是指向已经被释放(如删除、回收)的内存的指针。
这种指针仍然具有以前分配的内存地址,但是这块内存可能已经被其他对象或数据占用。
为了避免野指针和空悬指针引发的问题,我们应该:
在使用指针前对其进行初始化,如将其初始化为nullptr。 在释放指针指向的内存后,将指针设为nullptr,避免误访问已释放的内存。 在使用指针前检查其有效性,确保指针指向合法内存。
智能指针
1、unique_ptr:
(1)两个指针不能指向同一资源
(2)无法进行左值复制构造和左值复制赋值,但可以临时右值构造和复制(使用std::move())
(3)当他本身离开作用域是会自动释放指向他的对象
2、share_ptr:
多个 shared_ptr 可以同时指向并拥有同一个对象。(通过引用计数实现)
当最后一个拥有该对象的 shared_ptr 被销毁或者释放该对象的所有权时,对象会自动被删除。
(1)当复制或拷贝时,引用数+1,析构时引用数-1,引用数为0则释放
(2)初始化:使用make_shared或构造函数
(3)交换:swap
(4)要避免对象交叉使用智能指针,否则会形成死锁

shared_ptr 的 double free 问题
double free 问题就是一块内存空间或者资源被释放两次。
那么为什么会释放两次呢?
double free 可能是下面这些原因造成的:
(1)直接使用原始指针创建多个 shared_ptr,而没有使用 shared_ptr 的 make_shared 工厂函数,从而导致多个独立的引用计数。
(2)循环引用,即两个或多个 shared_ptr 互相引用,导致引用计数永远无法降为零,从而无法释放内存。
解决 shared_ptr double free 问题的方法:
使用 make_shared 函数创建 shared_ptr 实例,而不是直接使用原始指针。这样可以确保所有 shared_ptr 实例共享相同的引用计数。
对于可能产生循环引用的情况,使用 weak_ptr。weak_ptr 是一种不控制对象生命周期的智能指针,它只观察对象,而不增加引用计数。这可以避免循环引用导致的内存泄漏问题。
引用计数
-
什么是引用计数 引用计数(reference count)的核心思想是使用一个计数器来标识当前指针指向的对象被多少类的对象所使用(即记录指针指向对象被引用的次数)。它允许有多个相同值的对象共享这个值的实现。引用计数的使用常有两个目的:
-
简化跟踪堆中(也即C++中new出来的)的对象的过程。一旦一个对象通过调用new被分配出来,记录谁拥有这个对象是很重要的,因为其所有者要负责对它进行delete。但是对象所有者可以有多个,且所有权能够被传递,这就使得内存跟踪变得困难。引用计数可以跟踪对象所有权,并能够自动销毁对象。可以说引用计数是个简单的垃圾回收体系。
-
节省内存,提高程序运行效率。如果很多对象有相同的值,为这多个相同的值存储多个副本是很浪费空间的,所以最好做法是让左右对象都共享同一个值的实现。C++标准库中string类采取一种称为”写时复制“的技术,使得只有当字符串被修改的时候才创建各自的拷贝,否则可能(标准库允许使用但没强制要求)采用引用计数技术来管理共享对象的多个对象。
-
引用计数的实现 使用引用计数实现智能指针的关键是,引用计数应该存在哪里。引用计数应该是某个类对象和其复制对象共享的, 而指针成员恰好有这样的特性, 故可以在类中多声明一个size_t* 的成员,用来表示引用计数。
构造函数中创建类的新对象时,初始化引用计数为1; 拷贝构造函数复制指针,并使相应的引用计数增加1; 赋值操作减少左操作数所指对象的引用计数,增加右操作数所指对象的引用计数; 析构函数使引用计数减少1,并且当引用计数为1时,释放指针所指向的对象;
shared_ptr 常用 API
shared_ptr<T> 构造函数:创建一个空的 shared_ptr,不指向任何对象。
make_shared<T>(args...):创建一个 shared_ptr,并在单次内存分配中同时创建对象和控制块。这比直接使用 shared_ptr 的构造函数要高效。
reset():释放当前 shared_ptr 的所有权,将其设置为 nullptr。如果当前 shared_ptr 是最后一个拥有对象所有权的智能指针,则会删除对象。
get():返回指向的对象的裸指针。注意,这个裸指针的生命周期由 shared_ptr 管理,你不应该使用它来创建另一个智能指针。
weak_ptr
weak_ptr是C++11引入的一种智能指针,主要与shared_ptr配合使用。
它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。 同时weak_ptr 没有重载*和->但可以使用 lock 获得一个可用的 shared_ptr 对象。
它的主要作用是解决循环引用问题、观察shared_ptr对象而不影响引用计数,以及在需要时提供对底层资源的访问。
循环引用问题
struct ListNode
{
int _data;
shared_ptr<ListNode> prev;
shared_ptr<ListNode> next;
~ListNode(){ cout << "~ListNode()" << endl; }
};
int main()
{
shared_ptr<ListNode> node1(new ListNode);
shared_ptr<ListNode> node2(new ListNode);
node1->next = node2;
node2->prev = node1;
return 0;
}
现在来进一步分析:当main函数调用完,node2会先析构,但是此时引用计数是2。所以不会释放空间而是将计数变为1.然后node1再析构,同上,它的引用计数也减为一,但是这两份空间并不会释放,因为要node2的prev释放后,node1的空间才会释放,那node2的prev什么时候释放?答案是node2这份空间释放了才会释放prev,那么node2这份空间什么时候释放?答案是node1的next释放了它才释放,这就形成了一个死循环,我等你释放了我才能释放,对方也在等我释放了对方才能释放,这就是"循环引用问题"
解决循环引用问题:当两个或多个shared_ptr对象互相引用时,会导致循环引用。这种情况下,这些对象的引用计数永远不会变为0,从而导致内存泄漏。 weak_ptr可以打破这种循环引用,因为它不会增加引用计数。只需要将其中一个对象的std::shared_ptr替换为std::weak_ptr,即可解决循环引用问题。
观察shared_ptr对象:weak_ptr可以用作观察者,监视shared_ptr对象的生命周期。它不会增加引用计数,因此不会影响资源的释放。
相对于shared_ptr,它对于引用的对象是“弱引用”的关系。简单来说,它并不“拥有”对象本身。
std::weak_ptr并不拥有对象,在另外一个shared_ptr想要拥有对象的时候,它并不能做决定,需要转化到一个shared_ptr后才能使用对象。所以weak_ptr只是一个“引路人”而已。
expired函数的用法
expired:判断当前weak_ptr智能指针是否还有托管的对象,有则返回false,无则返回true
RAII
RAII即资源获取即初始化,它将在使用前获取(分配的堆内存、执行线程、打开的套接字、打开的文件、锁定的互斥量、磁盘空间、数据库连接等有限资源)的资源的生命周期与某个对象的生命周期绑定在一起。
确保在控制对象的生命周期结束时,按照资源获取的相反顺序释放所有资源。
同样,如果资源获取失败(构造函数退出并带有异常),则按照初始化的相反顺序释放所有已完全构造的成员和基类子对象所获取的资源。
RAII的核心思想就是:
利用栈上局部变量的自动析构来保证资源一定会被释放。
因为我们平常 C++ 编程过程中,经常会忘了释放资源,比如申请的堆内存忘了手动释放,那么就会导致内存泄露。
还有一些常见是程序遇到了异常,提前终止了,我们的资源也来不及释放。
但是变量的析构函数的调用是由编译器保证的一定会被执行,所以如果资源的获取和释放与对象的构造和析构绑定在一起,就不会有各种资源泄露问题。
RAII 类实现步骤
-
设计一个类封装资源,资源可以是内存、文件、socket、锁等等一切
-
在构造函数中执行资源的初始化,比如申请内存、打开文件、申请锁
-
在析构函数中执行销毁操作,比如释放内存、关闭文件、释放锁
-
使用时声明一个该对象的类,一般在你希望的作用域声明即可,比如在函数开始,或者作为类的成员变量
指针和引用
| 指针 | 引用 |
|---|---|
| 内存地址,是变量 | 已有变量别名,不会开辟新内存 |
| 具有指针的效率,又有变量使用的方便性和直观性(传值传参和传值返回都不产生拷贝,引用可以减少拷贝) | |
| 必须初始化 | |
| 可以被重新赋值,指向不同的变量 | 初始化后不能更改,始终指向同一个变量 |
| 可以为 nullptr,表示不指向任何变量 | 不能为 nullptr |
| 需要对其进行解引用以获取或修改其指向的变量的值 | 可以直接使用,无需解引用 |
| 只能引用一个实体 | |
| 显式解引用 | 编译器处理 |
值传递和引用传递的区别
值传递
调用时,将实参的值传递对应的形参,即为值传递。由于形参有自己独立的存储空间,又作为函数的局部变量使用,因此在函数中对任何形参值得修改都不会改变实参变量的值。
引用传递
引用传递是一种特殊的变量,它被认为是一个变量的别名。当定义一个引用时,其实是为目标变量起一个别名,引用并不分配独立的内存空间,它与目标变量公用其内存空间,当定义一个引用时,如果该引用不是用作函数的参数或者返回值,则必须提供该引用的初始值(即必须提供引用的目标变量名)
左值引用以及右值引用
左值和右值
区分左值和右值,终究还是要看能否取地址。右值对象不能取地址
左值引用和右值引用
左值引用
int& ra = a;
int*& rp = p;
int& r = *p;
const int& rb = b;右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);注意
右值引用引用右值,会使右值被存储到特定的位置。 也就是说,右值引用变量其实是左值,可以对它取地址和赋值(const右值引用变量可以取地址但不可以赋值,因为 const 在起作用)。 当然,取地址是指取变量空间的地址(右值是不能取地址的)。
比如:
double&& rr2 = x + y;
&rr2;
rr2 = 9.4;右值引用 rr2 引用右值 x + y 后,该表达式的返回值被存储到特定的位置,不能取表达式返回值 x + y 的地址,但是可以取 rr2 的地址,也可以修改 rr2 。
const double&& rr4 = x + y;
&rr4;可以对 rr4 取地址,但不能修改 rr4,即写成rr4 = 5.3;会编译报错
左值引用的短板
当对象出了函数作用域以后仍然存在时,可以使用左值引用返回,这是没问题的。
string& operator+=(char ch)
{
push_back(ch);
return *this;
}但当对象(对象是函数内的局部对象)出了函数作用域以后不存在时,就不可以使用左值引用返回了。
string operator+(const string& s, char ch)
{
string ret(s);
ret.push_back(ch);
return ret;
}
// 拿现在这个函数来举例:ret是函数内的局部对象,出了函数作用域后会被析构,即被销毁了
// 若此时再返回它的别名(左值引用),也就是再拿这个对象来用,就会出问题于是,对于第二种情形,左值引用也无能为力,只能传值返回。
右值引用
于是,为了解决上述传值返回的拷贝问题,C++11标准就增加了右值引用和移动语义。
1.移动语义(Move semantics)
将一个对象中的资源移动到另一个对象(资源控制权的转移)。
vector list map:
(1)Vector是一个动态数组。Vector中的元素可以按顺序存储,并且可以根据索引位置进行访问和修改。允许存储重复的元素。
优点:支持随机访问,即下标访问和迭代器访问,所以查询效率高。
缺点:往头部或中部插入或删除元素时,为了保持原本的相对次序,插入或删除之后的所有元素都必须移动,所以插入效率比较低。
适用场景:适用于对象简单,变化较小,并且频繁随机访问的场景。
(2)List: list 封装了链表,是有序的。 不过在内存中不是连续的内存存储。
优点:
-
不使用连续的内存进行存储,存储空间无限(只要内存够)。可以在任意位置插入或删除且效率高。
-
在内部插入、删除很快(不需要进行内存拷贝或者移动,只需要进行指针的更改)
缺点:1. 随机查找太慢
-
相比vector 占用内存比较大
Map: 由红黑树实现,其元素都是“键值/实值”,所形成的一个对祖(key/value paris)。每个元素都有一个键,是排序准则的基础。每个键只能出现一次,不允许重复。Map内部自建一棵红黑树,这棵树具有对数据自动排序的功能,所以在map内部所有的数据都是有序的。
红黑树
特性:
-
节点是红色或黑色
-
根是黑色
-
叶子节点(外部节点,空节点)都是黑色,这里的叶子节点指的是最底层的空节点(外部节点),下图中的那些null节点才是叶子节点,null节点的父节点在红黑树里不将其看作叶子节点
-
红色节点的子节点都是黑色
-
红色节点的父节点都是黑色
-
从根节点到叶子节点的所有路径上不能有 2 个连续的红色节点
-
-
从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
时间复杂度: O(logN)
为什么需要红黑树?
对于二叉搜索树,如果插入的数据是随机的,那么它就是接近平衡的二叉树,平衡的二叉树,它的操作效率(查询,插入,删除)效率较高,时间复杂度是O(logN)。但是可能会出现一种极端的情况,那就是插入的数据是有序的(递增或者递减),那么所有的节点都会在根节点的右侧或左侧,此时,二叉搜索树就变为了一个链表,它的操作效率就降低了,时间复杂度为O(N),所以可以认为二叉搜索树的时间复杂度介于O(logN)和O(N)之间,视情况而定。那么为了应对这种极端情况,红黑树就出现了,它是具备了某些特性的二叉搜索树,能解决非平衡树问题,红黑树是一种接近平衡的二叉树(说它是接近平衡因为它并没有像AVL树的平衡因子的概念,它只是靠着满足红黑节点的5条性质来维持一种接近平衡的结构,进而提升整体的性能,并没有严格的卡定某个平衡因子来维持绝对平衡)。
const
1. 修饰变量
当 const 修饰变量时,该变量将被视为只读变量,即不能被修改。
对于确定不会被修改的变量,应该加上 const,这样可以保证变量的值不会被无意中修改,也可以使编译器在代码优化时更加智能。
例如:
const int a = 10;
a = 20; // 编译错误,a 是只读变量,不能被修改但是!!!请注意!!!
这里的变量只读,其实只是编译器层面的保证,实际上可以通过指针在运行时去间接修改这个变量的值,当然这个方法比较trick。
2. 修饰函数参数,表示函数不会修改参数
当 const 修饰函数参数时,表示函数内部不会修改该参数的值。这样做可以使代码更加安全,避免在函数内部无意中修改传入的参数值。
尤其是 引用 作为参数时,如果确定不会修改引用,那么一定要使用 const 引用。
例如:
void func(const int a) {
// 编译错误,不能修改 a 的值
a = 10;
}3. 修饰函数返回值
当 const 修饰函数返回值时,表示函数的返回值为只读,不能被修改。这样做可以使函数返回的值更加安全,避免被误修改。
例如:
const int func() {
int a = 10;
return a;
}
int main() {
const int b = func(); // b 的值为 10,不能被修改
b = 20; // 编译错误,b 是只读变量,不能被修改
return 0;
}`4. 修饰指针或引用
在 C/C++ 中,const 关键字可以用来修饰指针,用于声明指针本身为只读变量或者指向只读变量的指针。
根据 const 关键字的位置和类型,可以将 const 指针分为以下三种情况:
4.1. 指向只读变量的指针
这种情况下,const 关键字修饰的是指针所指向的变量,而不是指针本身。
因此,指针本身可以被修改(意思是指针可以指向新的变量),但是不能通过指针修改所指向的变量。
const int* p; // 声明一个指向只读变量的指针,可以指向 int 类型的只读变量
int a = 10;
const int b = 20;
p = &a; // 合法,指针可以指向普通变量
p = &b; // 合法,指针可以指向只读变量
*p = 30; // 非法,无法通过指针修改只读变量的值我们可以将指针指向普通变量或者只读变量,但是无法通过指针修改只读变量的值。
4.2 只读指针
这种情况下,const 关键字修饰的是指针本身,使得指针本身成为只读变量。
因此,指针本身不能被修改(即指针一旦初始化就不能指向其它变量),但是可以通过指针修改所指向的变量。
int a = 10;
int b = 20;
int* const p = &a; // 声明一个只读指针,指向 a
*p = 30; // 合法,可以通过指针修改 a 的值
p = &b; // 非法,无法修改只读指针的值我们可以通过指针修改 a 的值,但是无法修改指针的值。
4.3 只读指针指向只读变量
这种情况下,const 关键字同时修饰了指针本身和指针所指向的变量,使得指针本身和所指向的变量都成为只读变量。
因此,指针本身不能被修改,也不能通过指针修改所指向的变量。
const int a = 10;
const int* const p = &a; // 声明一个只读指针,指向只读变量 a
*p = 20; // 非法,无法通过指针修改只读变量的值
p = nullptr; // 非法,无法修改只读指针的值4.4 常量引用
常量引用是指引用一个只读变量的引用,因此不能通过常量引用修改变量的值。
const int a = 10;
const int& b = a; // 声明一个常量引用,引用常量 a
b = 20; // 非法,无法通过常量引用修改常量 a 的值5. 修饰成员函数
当 const 修饰成员函数时,表示该函数不会修改对象的状态(就是不会修改成员变量)。
这样有个好处是,const 的对象就可以调用这些成员方法了,因为 const 对象不允许调用非 const 的成员方法。
也很好理解,既然对象是 const 的,那我怎么保证调用完这个成员方法,你不会修改我的对象成员变量呢?那就只能你自己把方法声明未 const 的呢~
例如:
class A {
public:
int func() const {
// 编译错误,不能修改成员变量的值
m_value = 10;
return m_value;
}
private:
int m_value;
};这里还要注意,const 的成员函数不能调用非 const 的成员函数,原因在于 const 的成员函数保证了不修改对象状态,但是如果调用了非 const 成员函数,那么这个保证可能会被破坏。
static
1. static 修饰全局变量
static 修饰全局变量可以将变量的作用域限定在当前文件中,使得其他文件无法访问该变量。
2. static 修饰局部变量
static 修饰局部变量可以使得变量在函数调用结束后不会被销毁,而是一直存在于内存中,下次调用该函数时可以继续使用。
同时,由于 static 修饰的局部变量的作用域仅限于函数内部,所以其他函数无法访问该变量。
3. static 修饰函数 static 修饰函数可以将函数的作用域限定在当前文件中,使得其他文件无法访问该函数。
同时,由于 static 修饰的函数只能在当前文件中被调用,因此可以避免命名冲突和代码重复定义。
4. static 修饰类成员变量和函数 static 修饰类成员变量和函数可以使得它们在所有类对象中共享,且不需要创建对象就可以直接访问。
在C语言中的作用:
1)全局量被静态关键字修饰只在本文件中有效,仍存储在静态区,生命周期没变。
2)函数被静态关键字修饰只在本文件中有效
3)在函数中局部变量用静态关键字定义,生命周期存在于整个程序中,但变量只能在函数中访问,且此只能创建初始化一份
4)static 修饰变量还有一特点,当变量未初始化时,默认初始化为 0。这是因为在静态存储区,所有内存都被默认置为 0,有时这一特点可减少工作量。
explicit
explicit 通常用于构造函数的声明中,用于防止隐式转换。 当将一个参数传递给构造函数时,如果构造函数声明中使用了 explicit 关键字,则只能使用显式转换进行转换,而不能进行隐式转换。
隐式转换:
int a = 0;
long b = a + 1; // int 转换为 long类和结构体区别
class 中类中的成员默认都是 private 属性的。
而在 struct 中结构体中的成员默认都是 public 属性的。
class 继承默认是 private 继承,而 struct 继承默认是 public 继承。
class 可以用于定义模板参数,struct 不能用于定义模板参数。
c和c++区别
我们都知道C语言是面向过程语言,而C++是面向对象语言,说C和C++的区别,也就是在比较面向过程和面向对象的区别。C与C++的最大区别:在于它们的用于解决问题的思想方法不一样。
参数列表 在C语言中,函数没有指定参数列表时,默认可以接收任意多个参数;但在C++中,因为严格的参数类型检测,没有参数列表的函数,默认为 void,不接收任何参数。
函数重载 函数重载:函数重载是函数的一种特殊情况,指在同一作用域中,声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数、类型、顺序)必须不同,返回值类型可以相同也可以不同,常用来处理实现功能类似数据类型不同的问题。(C语言没有函数重载,C++支持函数重载)。
this指针
-
this 是一个指向当前对象的指针
-
在类的成员函数中访问类的成员变量或调用成员函数时,编译器会隐式地将当前对象的地址作为 this 指针传递给成员函数。
-
<!--this--> 指针可以用来访问类的成员变量和成员函数,以及在成员函数中引用当前对象。
Hash冲突的解决方式
哈希冲突
哈希冲突即不同key值产生相同的地址,即发生了hash冲突。
开放寻址法
原理是当发生hash冲突时,会以当前地址为基准,然后根据寻址方法(探查寻址),去寻找下一次地址。若依旧发生冲突,则继续寻址,直到找到一个空的位置为止。
线性探查
顺序查找表的下一个单元,直到找到一个空单元或查遍全表。
即当hash值为3冲突时(假设此时hash表长度为11),利用线性探查的过程为:
H1 = (3+1)%11 = 4,此时若4依旧冲突,则再hash,即
H2 = (3+2)%11 = 5 … 通过这种线性增长增量系列,直到找到空的位置为止。
二次探查
这种方法的特点是,当哈希冲突时,在表的左右进行跳跃探测,比较灵活。
此时di = 1^2, -1^2, 2^2, -2^2 …
假设当hash值为3冲突时(假设此时hash表长度为11),利用二次探查的过程为:
H1 = (3+1^2)%11 = 4,此时若4依旧冲突,则再hash,即
H2 = (3+(-1)^2)%11 = 2 …
通过该方法直到找到空位置为止。
伪随机探测
这种方法即是产生一些随机系列值,并给定随机数作为起点。
假设当hash值为3冲突时(假设此时hash表长度为11),利用伪随机探测的过程为:
假设产生的随机系列为2,5,9 …,则
H1 = (3+2)%11 = 5
H2 = (3+5)%11 = 8
通过该方法直到找到空位置为止。
链地址法(拉链法)
HashMap,HashSet其实都是采用的拉链法来解决哈希冲突的,就是在每个位桶实现的时候,我们采用链表的数据结构来去存取发生哈希冲突的输入域的关键字(也就是被哈希函数映射到同一个位桶上的关键字)。
-
插入操作:在发生哈希冲突的时候,我们输入域的关键字去映射到位桶(实际上是实现位桶的这个数据结构,链表或者红黑树)中去的时候,我们先检查带插入元素x是否出现在表中,很明显,这个查找所用的次数不会超过装载因子(n/m : n为输入域的关键字个数,m为位桶的数目),它是个常数,所以插入操作的最坏时间复杂度为O(1)的。
-
查询操作:和插入操作一样,在发生哈希冲突的时候,我们去检索的时间复杂度不会超过装载因子,也就是检索数据的时间复杂度也是O(1)的
-
删除操作:如果在拉链法中我们想要使用链表这种数据结构来实现位桶,在删除一个元素x的时候,需要更改x的前驱元素的next指针的属性,把x从链表中删除。这个操作的时间复杂度也是O(1)的。

与开放定址法相比,拉链法有如下几个优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。
拉链法的缺点
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
再哈希法
fi=(f(key)+i*g(key)) % m (i=1,2,……,m-1)
其中,f(key) 和 g(key) 是两个不同的哈希函数,m为哈希表的长度
步骤:
双哈希函数探测法,先用第一个函数 f(key) 对关键码计算哈希地址,一旦产生地址冲突,再用第二个函数 g(key) 确定移动的步长因子,最后通过步长因子序列由探测函数寻找空的哈希地址。
比如,f(key)=a 时产生地址冲突,就计算g(key)=b,则探测的地址序列为 f1=(a+b) mod m,f2=(a+2b) mod m,……,fm-1=(a+(m-1)b) % m。
缺点:
每次冲突都要重新散列,计算时间增加。
公共溢出区法
即设立两个表:基础表和溢出表。将所有关键字通过哈希函数计算出相应的地址。然后将未发生冲突的关键字放入相应的基础表中,一旦发生冲突,就将其依次放入溢出表中即可。
在查找时,先用给定值通过哈希函数计算出相应的散列地址后,首先与基本表的相应位置进行比较,如果不相等,再到溢出表中顺序查找。
map和set底层实现和区别
set
set称为集合,是一个内部自动有序且不含重复元素的容器。他只有key值,不是键值对类型的。底层实现是依靠红黑树实现。插入和删除元素时间复杂度为O(logN)。set最重要的作用就是自动去重和按照升序排序
map
map是由一对键值对组成(key----value),map是有序的,里面的元素排序是根据key的大小按升序排列,底层实现和set一样都是红黑树。
区别
-
map中的元素是key-value (键值)对;Set与之相对就是关键字的简单集合
-
set的迭代器是const的。不允许修改元素的值; map允许修改value,但不允许修改key。
-
map支持下标操作,set不支持下标操作。
vector容器中resize()和reserve()的区别
①size 容器中的现有元素个数 ②capacity 容器最大容量
resize()
-
resize()函数实质是改变vector中的元素个数;
-
resize()含有两个参数,resize(n, m); 参数n表示vector中元素个数n,参数 m表示初始化,其中参数m可省略。
使用: vector v 1、参数n < v.size()时,结果是容器v的size减小到n,删除n之后的元素; 2、v.size() < 参数n < v.capacity(),结果是容器v的size增加到n,增加的元素值初始化为m,m省略时,增加元素值为缺省值,即默认值; 3、v.capacity() < 参数n,结果是先增大容量capacity至n,然后初始化值,初始化方法与情况2相同,此时v中的size与capacity均发生改变。
resize()常用情形 1、需要对容器中现有元素进行操作时; 2、容器初始化之后,使用容器时。
reserve()
-
reserve()函数实质是改变vector的容量,即总空间的大小;
-
reserve(n),只含有一个参数,表示总空间的大小。
使用: vector v; v.reserve(100); 1、参数n < v.capacity()时,size与capacity均不发生改变; 2、参数n > v.capacity()时,此时会重新分配一块空间,使得capacity扩容至n,size不发生改变。
reserve()常用情形 常用来容器初始化,预留容器空间,以免之后多次动态改变容器空间。 也可以在程序中间调用以扩大容器的空间. 注意: reserve只能扩大容器的空间,并不能减小容器的空间
总结:
-
resize更改容器的大小并调整元素数量,会分配/释放内存和复制/删除元素。 -
reserve只会改变容器的容量,不改变元素数量,可以提前预留内存空间以减少内存重新分配的开销。
序列化和反序列化
序列化:把对象转化为可传输的字节序列过程称为序列化。
反序列化:把字节序列还原为对象的过程称为反序列化。
序列化 (Serialization) 是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
目的
-
以某种存储形式使自定义对象持久化。
-
将对象从一个地方传递到另一个地方(网络传输)。
-
进程间传递对象。
其实序列化最终的目的是为了对象可以跨平台存储,和进行网络传输。而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组。
数据库
索引
1、索引的概念
索引是通过额外的数据结构,针对表里的数据进行重新组织,加快查询速度。
索引的作用是在不读取整个表的情况下,使得数据库应用程序可以更快地查找数据,用户无法看到索引,只能被用来加速检索或查询。
2、索引的特点
(1)加快查询的速度;
(2)索引自身也是一种数据结构,会占据存储空间;
(3)当对表进行增、删、改时,对应的索引也要进行修改。
3、索引使用场景
索引适用于表查询的频率高,但是增删改的频率低。
4、索引实现原理
数据库索引采用的数据结构是B+树,它的前身是B树。
索引失效

B树和B+树
B树
①概念
B树是一个n叉搜索树
例如:

②特点
B树中所有结点的孩子个数的最大值称为B树的阶,通常用m表示。一棵m阶B树要么是空树,要么满足以下性质:
-
每个结点,至多 有m棵子树,即至多含m-1个关键字
-
若根结点非终端结点,则至少有两棵子树
-
除根结点外,所有非叶子结点至少有⌈m/2⌉,即至少含有⌈m/2⌉-1个关键字
-
所有叶子结点都出现在同一层次上,并不带信息(即NULL)。即绝对平衡
B树的插入
针对m阶高度h的B树,插入一个元素时,首先在B树中是否存在,如果不存在,则在终端结点中插入该新的元素。
若该节点元素个数小于m-1,直接插入; 若该节点元素个数等于m-1,引起节点分裂;以该节点中间元素为分界,取中间元素(偶数个数,中 - 间两个随机选取)插入到父节点中; 重复上面动作,直到所有节点符合B树的规则;最坏的情况一直分裂到根节点,生成新的根节点,高度增加1;
删除
-
删除的是非终端结点
将用该结点的直接前驱或直接后继代替其位置,因此对于非终端结点的删除最后还是转化到了对终端结点的删除。
-
删除的是终端结点
-
删除后结点的关键字个数未低于下限 直接删除即可
2. 删除后结点的关键字个数低于下限
(1) 右兄弟有足够的关键字
有足够关键字的意思就是借给自己一个关键字后还能够保证B树的性质,即关键字个数大于⌈m/2⌉-1个。 此时右兄弟的最左关键字上浮到父亲结点,而原来的父亲元素则下沉到被删除关键字的结点中。如下图所示

(2) 右兄弟没有足够的关键字,左兄弟有足够的关键字 此时左兄弟的最右关键字上浮到父亲结点,而原来的父亲元素则下沉到被删除关键字的结点中。如下图所示

(3) 左右兄弟都没有足够关键字 此时由于左右兄弟的结点都只有⌈m/2⌉-1个,因此,当关键字删除后,该结点与任意兄弟结点的关键字个数的总和必然不大于一个结 点所能容纳的上限。

B+树
①概念
B树的查找效率虽然非常优秀,但是它也有一个自身的缺陷。我们都知道,数据库中的数据都是按照记录存放的,每条记录都是由多个数据项组成。因此我们的每条数据记录通常也不会太短,甚至可能非常之长。同样,如果将这些数据记录按照我们的B树进行组织,那么每个结点将存储的内容就是记录本身,B树是将记录本身作为单位存放的。 因此我们引入了B+树,B+树的特殊之处在于它将我们的记录的内容放在了叶子结点上,其他分支节点和终端结点只存放关键字。同时所有的结点的关键字都会再次出现在该关键字对应的子结点上即所有的关键字都会出现在终端结点上,这样保证了每个叶子结点上的数据记录都能够有一个关键字于其对应。在这样的调整下我们每个结点只需要存放记录对应关键字,由此相较于B树,在同样大小的结点约束下,我们的B+树的每个结点可以存放更多的关键字,从而大幅降低我们的树高,提升检索速度。
且在B树的基础上将从m个关键字对应m+1个分支变成了m个关键字对应m个分支,即B+树的结点最大关键字数与B+数的阶相同。

②特点
-
每个分支结点最多有m棵树和m个关键字
-
根结点至少两棵子树,其他每个分支结点至少有⌈m/2⌉棵子树
-
结点的子树个数与关键字个数相等
-
每个关键字都应该出现在其对应子结点中,且每个结点都按照从小到大的顺序排列
-
所有终端结点包含全部关键字及指向相应记录的指针。同时终端结点将关键字从小到大顺序排列,并且相终端结点按大小顺序相互链接起来。
-
同样是是绝对平衡的
数据库选择B+树的原因
-
B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快;
-
B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定;
-
B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
-
B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
事务
事务的四大特性
1.原子性(Atomicity):事务是最小的执行单位,不允许分割,要么全部执行,要么全部不执行。
2.一致性(Consistency):执行事务前后,数据保持一致,多个事务读取的结果是相同的。比如两个人进行转账,两个的总金额是1000,不过他们进行了多少次转账(事务),两个人的总额1000是不变的,这就是一致性状态。
3.隔离性(Isolation):并发访问数据时,一个用户事务不会被其他事务所干扰。比如有两个线程A和B对同一数据S进行事务执行,线程A在获取数据S时,线程B的事务要么已经提交结束,要么还未执行。
4.持久性(Durability):事务完成以后,该事务对数据库所做的更改便持久的保存在数据库之中,并不会被回滚。
在InnoDB 引擎中
-
持久性是通过 redo log (重做日志)来保证的;
-
原子性是通过 undo log(回滚日志) 来保证的;
-
隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
-
一致性则是通过持久性+原子性+隔离性来保证;
并行事务会出现什么问题?
在同时处理多个事务的时候,就可能出现脏读、不可重复读、幻读的问题。
脏读
如果一个事务「读到」了另一个「未提交事务修改过的数据」,就意味着发生了「脏读」现象。
不可重复读
在一个事务内多次读取同一个数据,如果出现前后两次读到的数据不一样的情况
幻读
在一个事务内多次查询某个符合查询条件的「记录数量」,如果出现前后两次查询到的记录数量不一样的情况
事务的隔离级别

SQL 标准提出了四种隔离级别来规避这些现象,隔离级别越高,性能效率就越低,这四个隔离级别如下:
-
读未提交(read uncommitted),指一个事务还没提交时,它做的变更就能被其他事务看到;
-
读提交(read committed),指一个事务提交之后,它做的变更才能被其他事务看到;
-
可重复读(repeatable read),指一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,MySQLInnoDB 引擎的默认隔离级别
-
串行化(serializable ):会对记录加上读写锁,在多个事务对这条记录进行读写操作时,如果发生了读写冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行:
按隔离水平高低排序如下:

针对不同的隔离级别,并发事务时可能发生的现象也会不同

操作系统(Linux)
一、进程和线程
进程和线程的区别
| 进程 | 线程 | |
|---|---|---|
| 资源(如内存、文件等)分配的单位 | CPU调度的单位 | |
| 拥有一个完整的资源平台 | 只独享必不可少的资源,如寄存器等 | |
| 具有就绪、阻塞、执行三种基本状态 | 具有就绪、阻塞、执行三种基本状态 | |
| 能减少并发执行的时间和空间开销 | ||
| 属于进程,是程序的实际执行者。一个进程至少包含一个主线程 | ||
| 有独立的地址空间,一个进程崩溃不影响其它进程 | 多个线程共享该进程的地址空间,一个线程的非法操作会使整个进程崩溃。 |
进程的状态

-
NULL -> 创建状态:一个新进程被创建时的第一个状态;
-
创建状态 -> 就绪状态:当进程被创建完成并初始化后,一切就绪准备运行时,变为就绪状态,这个过程是很快的;
-
就绪态 -> 运行状态:处于就绪状态的进程被操作系统的进程调度器选中后,就分配给 CPU 正式运行该进程;
-
运行状态 -> 结束状态:当进程已经运行完成或出错时,会被操作系统作结束状态处理;
-
运行状态 -> 就绪状态:处于运行状态的进程在运行过程中,由于分配给它的运行时间片用完,操作系统会把该进程变为就绪态,接着从就绪态选中另外一个进程运行;
-
运行状态 -> 阻塞状态:当进程请求某个事件且必须等待时,例如请求 I/O 事件;
-
阻塞状态 -> 就绪状态:当进程要等待的事件完成时,它从阻塞状态变到就绪状态;
进程的控制结构(PCB)
进程描述信息:
-
进程标识符:标识各个进程,每个进程都有一个并且唯一的标识符;
-
用户标识符:进程归属的用户,用户标识符主要为共享和保护服务;
进程控制和管理信息:
-
进程当前状态,如 new、ready、running、waiting 或 blocked 等;
-
进程优先级:进程抢占 CPU 时的优先级;
资源分配清单:
-
有关内存地址空间或虚拟地址空间的信息,所打开文件的列表和所使用的 I/O 设备信息。
CPU 相关信息:
-
CPU 中各个寄存器的值,当进程被切换时,CPU 的状态信息都会被保存在相应的 PCB 中,以便进程重新执行时,能从断点处继续执行。
进程的控制
01 创建进程
操作系统允许一个进程创建另一个进程,而且允许子进程继承父进程所拥有的资源。
创建进程的过程如下:
-
申请一个空白的 PCB,并向 PCB 中填写一些控制和管理进程的信息,比如进程的唯一标识等;
-
为该进程分配运行时所必需的资源,比如内存资源;
-
将 PCB 插入到就绪队列,等待被调度运行;
02 终止进程
进程可以有 3 种终止方式:正常结束、异常结束以及外界干预(信号 kill 掉)。
当子进程被终止时,其在父进程处继承的资源应当还给父进程。而当父进程被终止时,该父进程的子进程就变为孤儿进程,会被 1 号进程收养,并由 1 号进程对它们完成状态收集工作。
终止进程的过程如下:
-
查找需要终止的进程的 PCB;
-
如果处于执行状态,则立即终止该进程的执行,然后将 CPU 资源分配给其他进程;
-
如果其还有子进程,则应将该进程的子进程交给 1 号进程接管;
-
将该进程所拥有的全部资源都归还给操作系统;
-
将其从 PCB 所在队列中删除;
03 阻塞进程
当进程需要等待某一事件完成时,它可以调用阻塞语句把自己阻塞等待。而一旦被阻塞等待,它只能由另一个进程唤醒。
阻塞进程的过程如下:
-
找到将要被阻塞进程标识号对应的 PCB;
-
如果该进程为运行状态,则保护其现场,将其状态转为阻塞状态,停止运行;
-
将该 PCB 插入到阻塞队列中去;
04 唤醒进程
进程由「运行」转变为「阻塞」状态是由于进程必须等待某一事件的完成,所以处于阻塞状态的进程是绝对不可能叫醒自己的。
如果某进程正在等待 I/O 事件,需由别的进程发消息给它,则只有当该进程所期待的事件出现时,才由发现者进程用唤醒语句叫醒它。
唤醒进程的过程如下:
-
在该事件的阻塞队列中找到相应进程的 PCB;
-
将其从阻塞队列中移出,并置其状态为就绪状态;
-
把该 PCB 插入到就绪队列中,等待调度程序调度;
进程的阻塞和唤醒是一对功能相反的语句,如果某个进程调用了阻塞语句,则必有一个与之对应的唤醒语句。
进程的上下文切换
各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执行,那么这个一个进程切换到另一个进程运行,称为进程的上下文切换。
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中
发生进程上下文切换有哪些场景
-
时间片耗尽,系统从就绪队列选择另外一个进程运行;
-
系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行;
-
当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度;
-
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
-
发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;
线程的上下文切换
-
当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
-
当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
线程的实现
主要有三种线程的实现方式:
用户线程(User Thread)
在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;
用户线程是基于用户态的线程管理库来实现的,那么线程控制块(TCB) 也是在库里面来实现的,对于操作系统而言是看不到这个 TCB 的,它只能看到整个进程的 PCB。
所以,用户线程的整个线程管理和调度,操作系统是不直接参与的,而是由用户级线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
用户线程的优点:
-
每个进程都需要有它私有的线程控制块(TCB)列表,用来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB 由用户级线程库函数来维护,可用于不支持线程技术的操作系统;
-
用户线程的切换也是由线程库函数来完成的,无需用户态与内核态的切换,所以速度特别快;
用户线程的缺点:
-
由于操作系统不参与线程的调度,如果一个线程发起了系统调用而阻塞,那进程所包含的用户线程都不能执行了。
-
当一个线程开始运行后,除非它主动地交出 CPU 的使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行中的线程,它没有这个特权,只有操作系统才有,但是用户线程不是由操作系统管理的。
-
由于时间片分配给进程,故与其他进程比,在多线程执行时,每个线程得到的时间片较少,执行会比较慢;
内核线程(Kernel Thread)
内核线程是由操作系统管理的,线程对应的 TCB 自然是放在操作系统里的,这样线程的创建、终止和管理都是由操作系统负责。
内核线程的优点:
-
在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行;
-
分配给线程,多线程的进程获得更多的 CPU 运行时间;
内核线程的缺点:
-
在支持内核线程的操作系统中,由内核来维护进程和线程的上下文信息,如 PCB 和 TCB;
-
线程的创建、终止和切换都是通过系统调用的方式来进行,因此对于系统来说,系统开销比较大;
轻量级进程(LightWeight Process)
内核支持的用户线程,一个进程可有一个或多个 LWP,每个 LWP 是跟内核线程一对一映射的,也就是 LWP 都是由一个内核线程支持,而且 LWP 是由内核管理并像普通进程一样被调度。
协程
协程是用户视角的一种抽象,操作系统并没有协程的概念。
协程运行在线程之上,协程的主要思想是在用户态实现调度算法,用少量线程完成大量任务的调度。
协程与线程进行区别
| 线程 | 协程 |
|---|---|
| 一个线程可以多个协程 | 一个进程也可以单独拥有多个协程 |
| 进程和线程都是同步方式 | 异步 |
| 能保留上一次调用时的状态 | |
| 抢占式 | 非抢占式,同一时间其实只有一个协程拥有运行权 |
| 线程是协程的资源 |
二、进程调度算法、通信方法
调度:当想要访问资源的进程的数量大于资源的数量时,就需要通过某种算法决定进程访问资源的顺序这种就称为调度。
进程调度算法
1.先来先服务(FCFS)调度算法
2. 优先级调度算法
3. 时间片轮转调度算法:在使用完一个时间片后,即使进程还没有完成其运行,它也必须让出(被剥夺)处理机给下一个就绪的进程。
4. 短进程优先(SPF)调度算法
5. 最短剩余时间优先调度算法
6. 最高响应比优先调度算法:优先数=(等待时间+要求的服务时间)/要求的服务时间
进程间通信
1. 管道通信:
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
2. 信息队列
消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
一个消息队列可以被多个进程所共享(IPC((Inter-Process Communication,进程间通信))就是在这个基础上进行的);如果一个进程消息太多,一个消息队列放不下,也可以用多于一个的消息队列(不管管理可能会比较复杂)。
3. 信息量
信号和信号量是不同的,它们虽然都可以用来同步和互斥,但是信号是使用信号处理器来进行的,信号量是使用P,V操作来实现的。
信号量(semaphore),它是一个计数器。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4. 共享内存通信
共享内存(Shared Memory),指两个或多个进程共享一个给定的存储区。共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
5. 套接字( socket )
套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信
五种通讯方式总结
Linux 内核提供了不少进程间通信的方式,其中最简单的方式就是管道,管道分为「匿名管道」和「命名管道」。
匿名管道顾名思义,它没有名字标识,匿名管道是特殊文件只存在于内存,没有存在于文件系统中,shell 命令中的「|」竖线就是匿名管道,通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。
命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
线程间通信
同个进程下的线程之间都是共享进程的资源,只要是共享变量都可以做到线程间通信,比如全局变量,所以对于线程间关注的不是通信方式,而是关注多线程竞争共享资源的问题,信号量也同样可以在线程间实现互斥与同步:
-
互斥的方式,可保证任意时刻只有一个线程访问共享资源;
-
同步的方式,可保证线程 A 应在线程 B 之前执行;
三、死锁
死锁就是两个或两个以上线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。
死锁产生的原因
①互斥条件:
互斥条件是指多个线程不能同时使用同一个资源,一个资源只能被一个线程占有,当这个资源被占用后其他线程就只能等待。
②不可剥夺条件:
当一个线程不主动释放资源时,此资源一直被拥有线程占有。
③持有并等待条件:
当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
④环路等待条件:
在死锁发生的时候,两个线程获取资源的顺序构成了环形链。
如何避免死锁
资源有序分配法:。
线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
加锁顺序:
线程按照一定的顺序加锁
加锁时限:
线程尝试获取锁的时候加上一定的时限,超过时限则放弃对该锁的请求,并释放自己占有的锁
死锁检测
在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题
四、介绍几种锁,具体使用
互斥锁与自旋锁
-
互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
-
自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。
读写锁
读写锁的工作原理是:
-
当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
-
但是,一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
乐观锁和悲观锁
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
五、线程池
什么是线程池
线程池其实就是一种多线程处理形式,处理过程中可以将任务添加到队列中,然后在创建线程后自动启动这些任务。这里的线程就是我们前面学过的线程,这里的任务就是我们前面学过的实现了Runnable或Callable接口的实例对象;
为什么使用线程池
使用线程池最大的原因就是可以根据系统的需求和硬件环境灵活的控制线程的数量,且可以对所有线程进行统一的管理和控制,从而提高系统的运行效率,降低系统运行运行压力;当然了,使用线程池的原因不仅仅只有这些,我们可以从线程池自身的优点上来进一步了解线程池的好处;
使用线程池有哪些优势
线程和任务分离,提升线程重用性; 控制线程并发数量,降低服务器压力,统一管理所有线程; 提升系统响应速度,假如创建线程用的时间为T1,执行任务用的时间为T2,销毁线程用的时间为T3,那么使用线程池就免去了T1和T3的时间;
六、select/poll/epoll区别
七、线程之间的同步
八、段页
九、Linux常用指令
-
查进程 `
ps aux | grep <程序名称>
`
-
查日志
tail
-
查看文件倒数第四行
tail -n 4 <文件名>
-
显示磁盘剩余空间
df -h
-
显示目录下的文件大小
du -h [目录名]
-
查看/配置计算机当前的网卡配置信息
ifconfig
-
查看线程占用
top -H
十、同步和异步
同步(Synchronous):
同步I/O操作是指在执行I/O操作时,程序必须等待操作完成才能继续执行。在同步操作中,程序提交一个I/O请求后,操作系统会阻塞该程序,直到请求操作完成。此时,程序才能继续执行后续的代码。因此,同步操作会导致程序执行流程暂停,直至I/O操作完成。 同步I/O的例子:read(), write(), recv(), send() 等。 异步(Asynchronous):
异步I/O操作是指程序在发起I/O请求后,无需等待操作完成,可以继续执行其他任务。当异步I/O操作完成时,程序会通过某种方式(如回调函数、事件通知、信号等)得到通知。因此,异步操作使程序执行流程得以继续,而不必等待I/O操作完成。 异步I/O的例子:Linux中的aio_read(), aio_write() 等。
十一、虚拟内存
操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
于是,这里就引出了两种地址的概念:
-
我们程序所使用的内存地址叫做虚拟内存地址
-
实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)。
操作系统引入了虚拟内存,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存

操作系统是如何管理虚拟地址与物理地址之间的关系?
主要有两种方式:内存分段和内存分页
内存分段
虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址
缺点:
-
第一个就是内存碎片的问题。
-
第二个就是内存交换的效率低的问题。
内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。在 Linux 下,每一页的大小为 4KB。
如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(Swap In)。
更进一步地,分我们完全可以只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
在分页机制下,虚拟地址分为两部分,页号和页内偏移。
根据页号在页表中索引,再加上偏移量,就得到物理内存地址
简单的分页的缺陷
有空间上的缺陷。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
解决方法:
-
多级页表:(占用空间不是更大了吗?)如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表
-
TLB:CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。
进程间能否共享内存,通过什么技术实现进程之间的内存无法访问?
通常情况下一个进程是无法直接访问另一个进程的内存的。每个进程在运行时都会被分配独立的内存空间,这样可以确保进程之间的数据不会相互干扰,也增强了系统的安全性和稳定性。
操作系统使用来实现进程间内存隔离:
-
虚拟内存:操作系统为每个进程提供了一个虚拟地址空间,这使得每个进程都认为自己拥有连续且私有的内存空间。实际上,这些虚拟地址会被映射到物理内存中的不同位置,这样可以确保一个进程无法直接访问其他进程的内存。
-
内存保护:操作系统通过硬件机制(如内存管理单元)实施内存保护,防止一个进程越界访问另一个进程的内存空间。当一个进程尝试访问未分配给自己的内存区域时,操作系统会捕获这个错误并终止进程。
-
进程隔离:每个进程在操作系统中都被单独管理,有自己的内存空间和权限控制。操作系统确保进程之间无法直接互相访问内存,除非它们明确使用IPC机制进行通信。
-
权限控制:操作系统会根据每个进程的权限设置来控制对内存的访问。进程只能访问其被授权的内存区域,而不能越权访问其他进程的内存。
十三、Linux内存布局

十四、内存分配
应用程序通过 malloc 函数申请虚拟内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作

内存回收
回收的方式主要是两种:直接内存回收和后台内存回收。
-
后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
-
直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了 ——触发 OOM (Out of Memory)机制。
OOM Killer 机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM Killer 会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
主要有两类内存可以被回收,而且它们的回收方式也不同。
-
文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
-
匿名页(Anonymous Page):这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如堆、栈数据等。这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
文件页和匿名页的回收都是基于 LRU 算法
OOM
在 Linux 内核里有一个 oom_badness() 函数,它会把系统中可以被杀掉的进程扫描一遍,并对每个进程打分,得分最高的进程就会被首先杀掉。
进程得分的结果受下面这两个方面影响:
-
第一,进程已经使用的物理内存页面数。
-
第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过
/proc/[pid]/oom_score_adj来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
用「系统总的可用页面数」乘以 「OOM 校准值 oom_score_adj」再除以 1000,最后再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
每个进程的 oom_score_adj 默认值都为 0,所以最终得分跟进程自身消耗的内存有关,消耗的内存越大越容易被杀掉。我们可以通过调整 oom_score_adj 的数值,来改成进程的得分结果:
-
如果你不想某个进程被首先杀掉,那你可以调整该进程的 oom_score_adj,从而改变这个进程的得分结果,降低该进程被 OOM 杀死的概率。
-
如果你想某个进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。
我们最好将一些很重要的系统服务的 oom_score_adj 配置为 -1000,比如 sshd,因为这些系统服务一旦被杀掉,我们就很难再登陆进系统了。
但是,不建议将我们自己的业务程序的 oom_score_adj 设置为 -1000,因为业务程序一旦发生了内存泄漏,而它又不能被杀掉,这就会导致随着它的内存开销变大,OOM killer 不停地被唤醒,从而把其他进程一个个给杀掉。
十五、I/O多路复用
Socket模型
服务端首先调用 socket()函数,创建网络协议为 IPv4,以及传输协议为 TCP 的 Socket ,接着调用bind() 函数,给这个 Socket 绑定一个 IP 地址和端口
绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到我们的应用程序,然后把数据传递给我们。
绑定 IP 地址的目的:一台机器是可以有多个网卡的,每个网卡都有对应的IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发
给我们;
绑定完 IP 地址和端口后,就可以调用 listen()函数进行监听,此时对应 TCP 状态图中的 listen ,如果我们要判定服务器中一个网络程序
有没有启动,可以通过netstat命令查看对应的端口号是否有被监听
accept()函数,来从内核获取客户端的连接,如果没有客户端连服务端进入了监听状态后,通过调用接,则会阻塞等待客户端连接的到来
客户端发起连接:客户端在创建好 Socket 后,调用 connect()函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后就是三次握手
在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
-
一个是「还没完全建立」连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于 syn_rcvd 的状态;
-
一个是「已经建立」连接的队列,称为TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于established 状态;
当 TCP 全连接队列不为空后,服务端的 accept()函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程
序,后续数据传输都用这个 Socket。

多进程模型

服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接Socket」,这时就通过 fork()函
数创建一个子进程,实际上就把父进程所有相关的东西都复制一份包括文件描述符、内存地址空间、程序计数器、执行的代码等。
这两个进程根据返回值来区分是父进程还是子进程,如果返回值是0,则是子进程;如果返回值是其他的整数,就是父进程。
子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进
程不需要关心「已连接 Socket」,只需要关心「监听 Socket]
多线程模型

当服务器与客户端 TCP 完成连接后,通过 pthread_create()函数创建线程,然后将「已连接 Socket]的文件描述符传递给线程函数,接
着在线程里和客户端进行通信,从而达到并发处理的目的。
如果每来一个连接就创建一个线程,线程运行完后,还得操作系统还得销毁线程,虽说线程切换的上写文开销不大,但是如果频繁创建和
销毁线程,系统开销也是不小的。
那么,我们可以使用线程池的方式来避免线程的频繁创建和销毁,所谓的线程池,就是提前创建若干个线程,这样当由新连接建立时,将
这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出「已连接 Socket|进行处理。
I/O多路复用
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select和poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核
里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此
Socket 标记为可读或可写,接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的
Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行2次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里,而且还会发生2次「拷
贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在Linux 系统中,由内核中的
FD_SETSIZE 限制,默认最大值为 1024 ,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了select 的文件描述符个数限制,当
然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到
可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的
损耗会呈指数级增长。
epoll
epoll的用法:如下代码中,先用epoll_create创建一个epoll对象epfd,再通过epoll_ctl将需要监视的socket添加到epfd中,最后调用epoll_wait等待数据
int s = socket(AF_INET , SOCK_STREAM , 0);
bind(s , ...);
listen(s , ...);
int epfd = epoll_create(...);
epoll_ctl(epfd , ...);
while(1){
int n = epoll_wait(...);
for(接收到数据的socket){
//处理
}
}epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过epoll_ctl() 函数加入内核中的红黑
树里,红黑树是个高效的数据结构,增删改一般时间复杂度是O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测
的 socket 的数据结构,所以select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待
检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点,epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个socket 有事件发生时,通过回调函数内核会将其加
入到这个就绪事件列表中,当用户调用 epoll_wait()函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询
扫描整个 socket 集合,大大提高了检测的效率。

边缘出发和水平触发
epoll 支持两种事件触发模式,分别是边缘触发(ET)和水平触发(LT)
使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用
read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证次性将内核缓冲区的数据读取完;
使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函
数读完才结束,目的是告诉我们有数据需要读取;
这就是两者的区别,水平触发的意思是只要满足事件的条件,比如内核中有数据需要读,就一直不断地把这个事件传递给用户;而边缘触
发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到知
后,没必要一次执行尽可能多的读写操作。
如果使用边缘触发模式,I/O事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,
以免错失读写的机会。所以,边缘触发模式一般和非阻塞I/O 搭配使用,程序会一直执行I/O 操作,直到系统调用(如 read 和 write)
返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
十六、Reactor和Proactor
单 Reactor 单进程 / 线程

-
Reactor 对象的作用是监听和分发事件;
-
Acceptor 对象的作用是获取连接;
-
Handler 对象的作用是处理业务;
-
「单 Reactor 单进程」 Reactor 对象通过 select(10 多路复用接口)监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
-
如果是连接建立的事件,则交出 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
-
如果不是连接建立事件,则交由当前连接对应的 Handler 对象来进行响应
-
·Handler 对象通过 read ->业务处理 ->send 的流程来完成完整的业务流程
但是,这种方案存在 2 个缺点:
第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能,.
第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,!如果业务处理耗时比较长,那么就造成响应的延迟
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
Redis 是由C 语言实现的,在 Redis 6.0 版本之前采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,
操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
单 Reactor 多线程 / 多进程

-
Reactor 对象通过 select( I/O多路复用接口)监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
-
如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
-
如果不是连接建立事件,则交由当前连接对应的 Handler 对象来进行响应,
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
-
Handler对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
-
子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由Handler 通过 send 方法将响应结果发送给 client;
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。
例如,子线程完成业务处理后,要把结果传递给主线程的 Handler 进行发送,这里涉及共享数据的竞争。要避免多线程由于竞争共享资
源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁,以保证任意时间里只有一个线程在操作共享资源,待该线程操作完释放
互斥锁后,其他线程才有机会操作共享数据。
「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方
多 Reactor 多进程 / 线程

-
主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的accept 获取连接,将新的连接分配给某个子线程:
-
子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个Handler 用于处理连接的响应事件。
-
如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
-
Handler 对象通过 read ->业务处理 ->send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
-
主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
-
主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客
户端。
Proactor
Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
阻塞、非阻塞、同步、异步 I/O
阻塞 I/O
当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。

非阻塞 I/O
非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。
这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程.

异步 I/O
「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。

Reactor 和 Proactor 的区别
-
Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
-
Proactor 是异步网络模式,感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。

互斥锁的使用场景
互斥锁
在多任务操作系统中,同时运行的多个任务可能都需要使用同一种资源。在线程里也有这么一把锁——互斥锁(mutex),互斥锁是一种简单的加锁的方法来控制对共享资源的访问,互斥锁只有两种状态,即上锁( lock )和解锁( unlock )。
【互斥锁的特点】:
-
原子性:把一个互斥量锁定为一个原子操作,这意味着操作系统(或pthread函数库)保证了如果一个线程锁定了一个互斥量,没有其他线程在同一时间可以成功锁定这个互斥量;
-
唯一性:如果一个线程锁定了一个互斥量,在它解除锁定之前,没有其他线程可以锁定这个互斥量;
-
非繁忙等待:如果一个线程已经锁定了一个互斥量,第二个线程又试图去锁定这个互斥量,则第二个线程将被挂起(不占用任何cpu资源),直到第一个线程解除对这个互斥量的锁定为止,第二个线程则被唤醒并继续执行,同时锁定这个互斥量。
互斥锁的操作流程:
-
在访问共享资源后临界区域前,对互斥锁进行加锁;
-
在访问完成后释放互斥锁导上的锁。在访问完成后释放互斥锁导上的锁;
-
对互斥锁进行加锁后,任何其他试图再次对互斥锁加锁的线程将会被阻塞,直到锁被释放。对互斥锁进行加锁后,任何其他试图再次对互斥锁加锁的线程将会被阻塞,直到锁被释放。
计算机网络
TCP
TCP头部格式

UDP头部格式

TCP和UDP
TCP协议的特点:
1.面向连接
面向连接,是指发送数据之前必须在两端建立连接。建立连接的方法是“三次握手”,这样能建立可靠的连接。建立连接,是为数据的可靠传输打下了基础。
2.仅支持单播传输
每条TCP传输连接只能有两个端点,只能进行点对点的数据传输,不支持多播和广播传输方式。
3.面向字节流
TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
4.可靠传输
对于可靠传输,判断丢包,误码靠的是TCP的段编号以及确认号。TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
5.提供拥塞控制
当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞
UDP特点:
1. 面向无连接
首先 UDP 是不需要和 TCP一样在发送数据前进行三次握手建立连接的,想发数据就可以开始发送了。并且也只是数据报文的搬运工,不会对数据报文进行任何拆分和拼接操作。
具体来说就是:
在发送端,应用层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加一个 UDP 头标识下是 UDP 协议,然后就传递给网络层了
在接收端,网络层将数据传递给传输层,UDP 只去除 IP 报文头就传递给应用层,不会任何拼接操作
2. 有单播,多播,广播的功能
UDP 不止支持一对一的传输方式,同样支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能。
3. UDP是面向报文的
发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
4. 不可靠性
首先不可靠性体现在无连接上,通信都不需要建立连接,想发就发,这样的情况肯定不可靠。
并且收到什么数据就传递什么数据,并且也不会备份数据,发送数据也不会关心对方是否已经正确接收到数据了。
再者网络环境时好时坏,但是 UDP 因为没有拥塞控制,一直会以恒定的速度发送数据。即使网络条件不好,也不会对发送速率进行调整。这样实现的弊端就是在网络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP。
5. 头部开销小,传输数据报文时是很高效的。
确定唯一 TCP 连接
TCP 四元组可以唯一的确定一个连接,四元组包括如下:
-
源地址
-
源端口
-
目的地址
-
目的端口
TCP最大连接数
最大连接数 = 客户端IP数 × 客户端口数
三次握手
三次握手过程

第三次握手是可以携带数据的,前两次握手是不可以携带数据的
-
若是数据包比第三次应答包提前到达服务端,会被服务端当做重复的包而忽略
-
客户端发送完第三个握手后,是不是不管服务器有没有收到,直接就发送数据?
你可以从理论上来猜测一下,如果上面这个问题的答案是否定的话,也就是说客户端还得要确认服务器收到自己的第三次握手包以后才能发送数据。那怎么确认呢?是不是服务端还得回复自己一下:我收到了你的第三次握手包了,你可以发送数据了。
但如果这样一来,那是不是就变成了四次握手,而不是三次握手了呢?
为什么是三次握手?
-
阻止重复历史连接的初始化(主要原因)

-
同步双方的初始序列号
-
避免资源浪费
若只有两次握手
如果第二次syn包正常达到且与server端建立了tcp连接, server端维护了一个连接, 一次貌似OK, 但别忘了, 第一次那个syn包可能就在此时达到server端了, 于是server端又要维护一个连接, 而这个连接是无效的, 可以认为是死连接。 而一个进程打开的socket是有限度的, 维护这些死连接非常耗费资源。
握手丢失
第一次握手丢失
触发超时重传机制,重传 SYN 报文。
第二次握手丢失
客户端就觉得可能自己的 SYN 报文(第一次握手)丢失了,于是客户端就会触发超时重传机制,重传 SYN 报文。
服务端就收不到第三次握手,于是服务端这边会触发超时重传机制,重传 SYN-ACK 报文。
第三次握手丢失
服务端重传 SYN-ACK 报文,直到收到第三次握手,或者达到最大重传次数。
ACK 报文是不会有重传的,当 ACK 丢失了,就由对方重传对应的报文。
SNY攻击
四次挥手
四次挥手过程

-
中断连接端可以是客户端,也可以是服务器端。
-
第一次挥手:客户端发送一个FIN=M,用来关闭客户端到服务器端的数据传送,客户端进入FIN_WAIT_1状态。意思是说"我客户端没有数据要发给你了",但是如果你服务器端还有数据没有发送完成,则不必急着关闭连接,可以继续发送数据。
-
第二次挥手:服务器端收到FIN后,先发送ack=M+1,告诉客户端,你的请求我收到了,但是我还没准备好,请继续你等我的消息。这个时候客户端就进入FIN_WAIT_2 状态,继续等待服务器端的FIN报文。
-
第三次挥手:当服务器端确定数据已发送完成,则向客户端发送FIN=N报文,告诉客户端,好了,我这边数据发完了,准备好关闭连接了。服务器端进入LAST_ACK状态。
-
第四次挥手:客户端收到FIN=N报文后,就知道可以关闭连接了,但是他还是不相信网络,怕服务器端不知道要关闭,所以发送ack=N+1后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。服务器端收到ACK后,就知道可以断开连接了。客户端等待了2MSL后依然没有收到回复,则证明服务器端已正常关闭,那好,我客户端也可以关闭连接了。最终完成了四次握手。
挥手丢失
第一次挥手丢失
客户端迟迟收不到被动方的 ACK 的话,也就会触发超时重传机制,重传 FIN 报文。
已达到最大重传次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),若还是没收到第二次挥手,则断开连接
第二次挥手丢失
ACK 报文是不会重传的,客户端就会触发超时重传机制,重传 FIN 报文,类似于第一次挥手丢失
第三次挥手丢失
-
当服务端重传第三次挥手报文的次数达到了 3 次后,由于 tcp_orphan_retries 为 3,达到了重传最大次数,于是再等待一段时间(时间为上一次超时时间的 2 倍),如果还是没能收到客户端的第四次挥手(ACK报文),那么服务端就会断开连接。
-
客户端因为是通过 close 函数关闭连接的,处于 FIN_WAIT_2 状态是有时长限制的,如果tcp_fin_timeout 时间内还是没能收到服务端的第三次挥手(FIN 报文),那么客户端就会断开连接。
第四次挥手丢失

TIME_WAIT
-
防止历史连接中的数据,被后面相同四元组的连接错误的接收;
-
保证「被动关闭连接」的一方,能被正确的关闭;
TIME_WAIT 过多有什么危害?
-
第一是占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等;
-
第二是占用端口资源,端口资源也是有限的
为什么TIME_WAIT等待时间的2MSL?
网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
三次挥手
当被动关闭方(上图的服务端)在 TCP 挥手过程中,「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
什么是 TCP 延迟确认机制?
当发送没有携带数据的 ACK,它的网络效率也是很低的,因为它也有 40 个字节的 IP 头 和 TCP 头,但却没有携带数据报文。为了解决 ACK 传输效率低问题,所以就衍生出了 TCP 延迟确认。TCP 延迟确认的策略:
-
当有响应数据要发送时,ACK 会随着响应数据一起立刻发送给对方
-
当没有响应数据要发送时,ACK 将会延迟一段时间,以等待是否有响应数据可以一起发送
-
如果在延迟等待发送 ACK 期间,对方的第二个数据报文又到达了,这时就会立刻发送 ACK
两种关闭
-
close 函数,同时 socket 关闭发送方向和读取方向,也就是 socket 不再有发送和接收数据的能力。如果有多进程/多线程共享同一个 socket,如果有一个进程调用了 close 关闭只是让 socket 引用计数 -1并不会导致 socket 不可用,同时也不会发出 FIN 报文,其他进程还是可以正常读写该 socket,直到引用计数变为 0,才会发出 FIN 报文。
-
shutdown 函数,可以指定 socket 只关闭发送方向而不关闭读取方向,也就是 socket 不再有发送数据的能力,但是还是具有接收数据的能力。如果有多进程/多线程共享同一个socket,shutdown 则不管引用计数,直接使得该 socket 不可用,然后发出 FIN 报文,如果有别的进程企图使用该 socket,将会受到影响。
重传、滑动窗口、流向控制、拥塞控制
重传
-
超时重传
-
数据包丢失
-
确认应答丢失
超时重传时间 RTO 的值应该略大于报文往返 RTT 的值。
-
快速重传

-
第一份 Seq1 先送到了,于是就 Ack 回 2;
-
结果 Seq2 因为某些原因没收到,Seq3 到达了,于是还是 Ack 回 2;
-
后面的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;
-
后面的 Seq4 和 Seq5 都到了,但还是 Ack 回 2,因为 Seq2 还是没有收到;
-
发送端收到了三个 Ack = 2 的确认,知道了 Seq2 还没有收到,就会在定时器过期之前,重传丢失的 Seq2。
-
最后,收到了 Seq2,此时因为 Seq3,Seq4,Seq5 都收到了,于是 Ack 回 6
-
SACK
选择性确认。
可以将已收到的数据的信息发送给「发送方」
-
D-SACK
使用了 SACK 来告诉「发送方」有哪些数据被重复接收了。
滑动窗口
引入窗口概念的原因
TCP 是每发送一个数据,都要进行一次确认应答。当上一个数据包收到了应答了, 再发送下一个。
这样的传输方式有一个缺点:数据包的往返时间越长,通信的效率就越低。
所以引入窗口概念
那么有了窗口,就可以指定窗口大小,窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。
窗口大小
通常窗口的大小是由接收方的窗口大小来决定的。
TCP 头里有一个字段叫 Window,也就是窗口大小。这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
流量控制
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
窗口关闭

为了解决这个问题,TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。
糊涂窗口综合征
糊涂窗口综合症的现象是可以发生在发送方和接收方:
-
接收方可以通告一个小的窗口
-
而发送方可以发送小数据
要解决糊涂窗口综合症,就要同时解决上面两个问题就可以了:
-
让接收方不通告小窗口给发送方
-
让发送方避免发送小数据
拥塞控制
-
慢启动
当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
慢启动算法,发包的个数是指数性的增长。
-
当
cwnd<ssthresh时,使用慢启动算法。 -
当
cwnd>=ssthresh时,就会使用「拥塞避免算法」。
-
拥塞避免
每当收到一个 ACK 时,cwnd 增加 1/cwnd。
-
拥塞发生
超时重传:
-
ssthresh设为cwnd/2, -
cwnd重置为1(是恢复为 cwnd 初始化值,我这里假定 cwnd 初始化值 1)
快速重传:
-
cwnd = cwnd/2,也就是设置为原来的一半; -
ssthresh = cwnd; -
进入快速恢复算法
-
快速恢复
-
拥塞窗口
cwnd = ssthresh + 3( 3 的意思是确认有 3 个数据包被收到了); -
重传丢失的数据包;
-
如果再收到重复的 ACK,那么 cwnd 增加 1;
-
如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
HTTP
HTTP 的名字「超文本协议传输」,它可以拆成三个部分:
-
超文本
-
传输
-
协议
HTTP 是基于 TCP 传输协议进行通信的
HTTP状态码

| 状态码 | 英文名称 | 描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Conten | 服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 使用代理。所请求的资源必须通过代理访问 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
-
301适合永久重定向:
常见场景是使用域名跳转。浏览器发出原始请求后重定向到新地址,浏览器会缓存这个请求,等下次再次访问原始地址时会直接请求到新地址去。
-
302适合临时跳转:
可用于临时的、动态的地址跳转,每次请求原地址都会重新重定向到目标地址。应用场景:页面单点登录。
HTTP常见字段
-
Host:www.A.com
-
Content-Length:1000 (表明本次回应的数据长度)
HTTP 协议通过设置回车符、换行符作为 HTTP header 的边界,通过 Content-Length 字段作为 HTTP body 的边界,这两个方式都是为了解决“粘包”的问题。
-
Connection:常用于客户端要求服务器使用「HTTP 长连接」机制,以便其他请求复用。指定客户端和服务器之间的连接类型,如 keep-alive、close 等。
HTTP 长连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
-
Content-Type: 用于服务器回应时,告诉客户端,本次数据是什么格式。
-
Content-Encoding : 明数据的压缩方法。表示服务器返回的数据使用了什么压缩格式
-
User-Agent:标识浏览器的详细信息,包括名称、版本、操作系统等。
-
Accept:指定客户端接受的数据类型,可以是文本、HTML、XML、JSON 等等。
-
Cache-Control:指定客户端的缓存策略,如 no-cache、max-age 等。
-
Cookie:用于客户端和服务器之间传递会话信息,如用户登录状态等。
-
Referer:指定请求来源网页的 URL。
-
User-Agent:标识浏览器的详细信息,包括名称、版本、操作系统等。
HTTP特性
HTTP/1.1的优点
简单
灵活和易于扩展
HTTP 协议里的各类请求方法、URI/URL、状态码、头字段等每个组成要求都没有被固定死,都允许开发人员自定义和扩充。、
同时 HTTP 由于是工作在应用层( OSI 第七层),则它下层可以随意变化,比如:
-
HTTPS 就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层;
-
HTTP/1.1 和 HTTP/2.0 传输协议使用的是 TCP 协议,而到了 HTTP/3.0 传输协议改用了 UDP 协议。
应用广泛和跨平台
HTTP/1.1的缺点
无状态(双刃剑)
好处,因为服务器不会去记忆 HTTP 的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担
坏处,既然服务器没有记忆能力,它在完成有关联性的操作时会非常麻烦。
对于无状态的问题,可以用cookie解决,在客户端第一次请求后,服务器会下发一个装有客户信息的「小贴纸」,后续客户端请求服务器的时候,带上「小贴纸」,服务器就能认得了了
明文传输(双刃剑)
好处方便阅读
坏处不安全
不安全
-
通信使用明文(不加密),内容可能会被窃听。
-
不验证通信方的身份,因此有可能遭遇伪装。
-
无法证明报文的完整性,所以有可能已遭篡改。
HTTP/1.1性能
长连接
特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
管道网络传输
即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。但是服务器必须按照接收请求的顺序发送对这些管道化请求的响应。
队头阻塞
当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一同被阻塞了
HTTP缓存技术
强制缓存
强缓存指的是只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存
实现:
-
当浏览器第一次请求访问服务器资源时,服务器会在返回这个资源的同时,在 Response 头部加上 Cache-Control,Cache-Control 中设置了过期时间大小;
-
浏览器再次请求访问服务器中的该资源时,会先通过请求资源的时间与 Cache-Control 中设置的过期 时间大小,来计算出该资源是否过期,如果没有,则使用该缓存,否则重新请求服务器;
-
服务器再次收到请求后,会再次更新 Response 头部的 Cache-Control。
协商缓存
协商缓存就是与服务端协商之后,通过协商结果来判断是否使用本地缓存。
实现:

http请求方式
1、get请求:
get:可以理解 为 取 的意思,对应select操作 用来获取数据的,只是用来查询数据,不对服务器的数据做任何的修改,新增,删除等操作。 说明: get请求会把请求的参数附加在URL后面,这样是不安全的,在处理敏感数据时不用,或者参数做加密处理。 get请求其实本身HTTP协议并没有限制它的URL大小,但是不同的浏览器对其有不同的大小长度限制
2、post请求:
post 可以理解 为 贴 的意思 数据发送到服务器以创建或更新资源,侧重于更新数据,对应update操作 说明:
3、put请求:
put:可以理解为 放 的意思 数据发送到服务器以创建或更新资源,侧重于创建数据,对应insert操作
4、delete请求:
delete:字面意思删除,即删除数据,对应delete操作 用来删除指定的资源,它会删除URI给出的目标资源的所有当前内容
5、options请求:
用来描述了目标资源的通信选项,返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性!
6、head请求:
HEAD方法与GET方法相同,但没有响应体,仅传输状态行和标题部分。这对于恢复相应头部编写的元数据非常有用,而无需传输整个内容。
7、connect请求
HTTP和HTTPS
HTTP和HTTPS的区别
-
HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
-
HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
-
两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
-
HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS 解决了 HTTP 的哪些问题?
HTTP 由于是明文传输,所以安全上存在以下三个风险:
-
窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
-
篡改风险,比如强制植入垃圾广告,视觉污染,用户眼容易瞎。
-
冒充风险,比如冒充淘宝网站,用户钱容易没。
HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议,可以很好的解决了上述的风险
-
信息加密:交互信息无法被窃取,但你的号会因为「自身忘记」账号而没。
-
校验机制:无法篡改通信内容,篡改了就不能正常显示,但百度「竞价排名」依然可以搜索垃圾广告。
-
身份证书:证明淘宝是真的淘宝网,但你的钱还是会因为「剁手」而没。
HTTPS 是如何解决上面的三个风险的?
-
混合加密的方式实现信息的机密性,解决了窃听的风险
-
摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决了篡改的风险。
-
将服务器公钥放入到数字证书中,解决了冒充的风险。
HTTP1.1优化
三个优化思路:
-
尽量避免发送 HTTP 请求;
-
在需要发送 HTTP 请求时,考虑如何减少请求次数;
-
减少服务器的 HTTP 响应的数据大小;
避免发送HTTP请求
缓存技术
客户端会把第一次请求以及响应的数据保存在本地磁盘上,其中将请求的 URL 作为 key,而响应作为 value,两者形成映射关系。
这样当后续发起相同的请求时,就可以先在本地磁盘上通过 key 查到对应的 value,也就是响应,如果找到了,就直接从本地读取该响应。

减少 HTTP 请求次数
-
减少重定向请求次数:
-
合并请求;
-
延迟发送请求;
减少重定向请求
重定向请求:
服务器上的一个资源可能由于迁移、维护等原因从 ur1 移至 ur2 后,而客户端不知情,它还是继续请求ur1,这时服务器不能粗暴地返回错误,而是通过 302 响应码和 Location 头部,告诉客户端该资源已经迁移至 ur2 了,于是客户端需要再发送 ur2 请求以获得服务器的资源。
重定向的工作交由代理服务器完成,就能减少 HTTP 请求次数了
合并请求
合并请求的方式就是合并资源,以一个大资源的请求替换多个小资源的请求。
延迟发送请求
不要一口气吃成大胖子,一般 HTML 里会含有很多 HTTP 的 URL,当前不需要的资源,我们没必要也获取过来,于是可以通过「按需获取」的方式,来减少第一时间的 HTTP 请求次数。
减少 HTTP 响应的数据大小
-
无损压缩;
-
有损压缩;
HTTP1.0、HTTP1.1和HTTP2.0
HTTP1.0
-
请求与响应支持 HTTP 头,响应含状态行,增加了状态码,
-
支持 HEAD,POST 方法
-
支持传输 HTML 文件以外其他类型的内容
HTTP1.0 使用的是非持久连接,主要缺点是客户端必须为每一个待请求的对象建立并维护一个新的连接,即每请求一个文档就要有两倍RTT 的开销。因为同一个页面可能存在多个对象,所以非持久连接可能使一个页面的下载变得十分缓慢,而且这种 短连接增加了网络传输的负担。
HTTP1.1
-
支持长连接。
-
在HTTP1.0的基础上引入了更多的缓存控制策略。
-
引入了请求范围设置,优化了带宽。
-
在错误通知管理中新增了错误状态响应码。
-
增加了Host头处理,可以传递主机名(hostname)。
缺点: 传输内容是明文,不够安全
HTTP2.0
-
和HTTP 1.x使用的header压缩方法不同。
-
HTTP2.0 基于二进制格式进行解析,而HTTP 1.x基于文本格式进行解析。
-
多路复用,HTTP1.1是多个请求串行化单线程处理,HTTP 2.0是并行执行,一个请求超时并不会影响其他请求。
-
HTTP2.0的多路复用提升了网页性能:
-
在 HTTP1 中浏览器限制了同一个域名下的请求数量(Chrome下一般是六个),当在请求很多资源的时候,由于队头阻塞,当浏览器达到最大请求数量时,剩余的资源需等待当前的六个请求完成后才能发起请求。
-
HTTP2 中引入了多路复用的技术,这个技术可以只通过一个 TCP连接就可以传输所有的请求数据。多路复用可以绕过浏览器限制同一个域名下的请求数量的问题,进而提高了网页的性能。
HTTP 3.0 (QUIC)
QUIC (Quick UDP Internet Connections), 快速 UDP 互联网连接。 QUIC是基于UDP协议的。
HTTPS RSA 握手
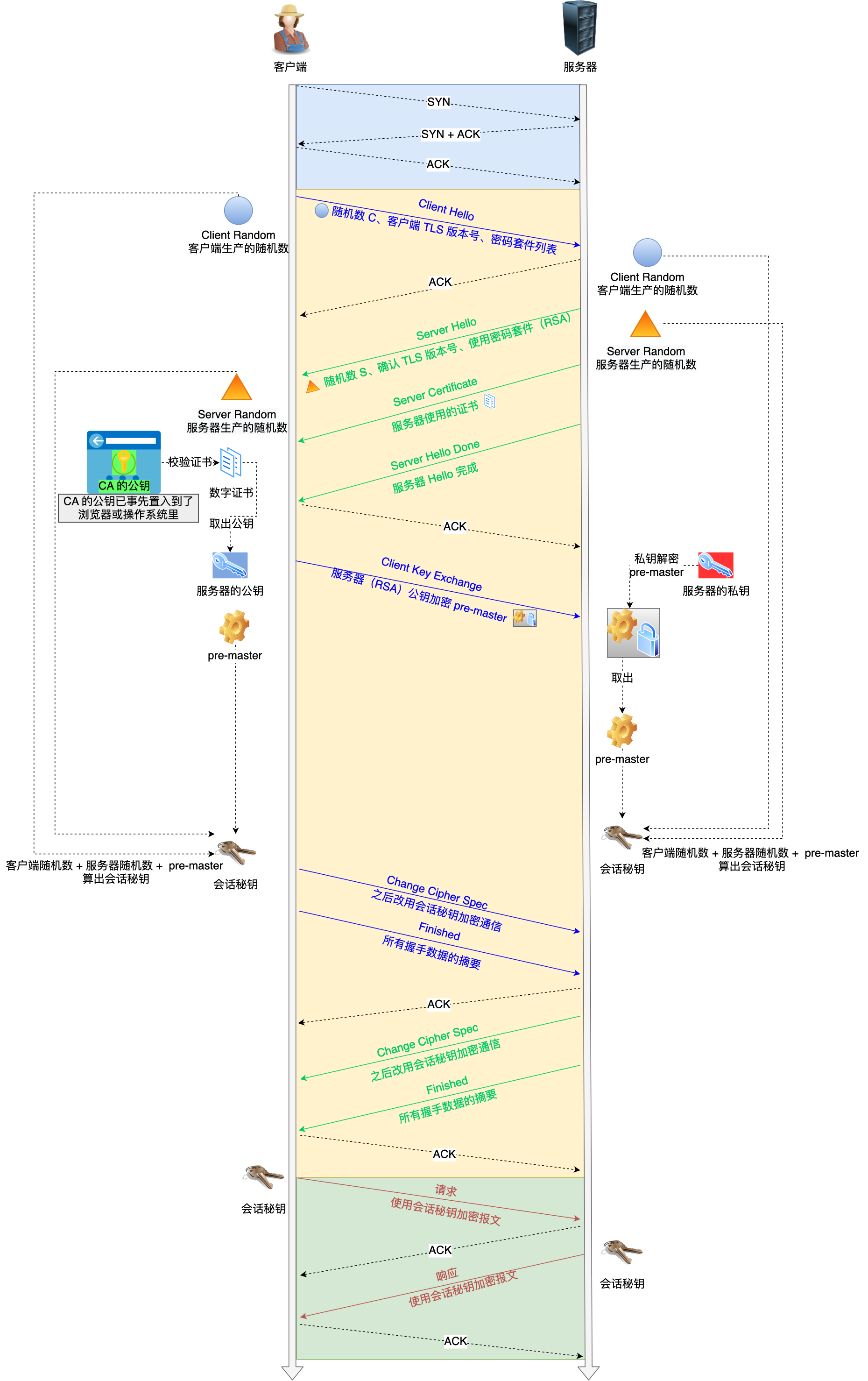
第一次握手
客户端首先会发一个「Client Hello」消息,消息里面有客户端使用的 TLS 版本号、支持的密码套件列表,以及生成的随机数。
第二次握手
-
当服务端收到客户端的「Client Hello」消息后,会确认 TLS 版本号是否支持,和从密码套件列表中选择一个密码套件,以及生成随机数。
-
接着,返回「Server Hello」消息,消息里面有服务器确认的 TLS 版本号,也给出了随机数
-
服务端为了证明自己的身份,会发送「Server Certificate」给客户端
-
服务端发了「Server Hello Done」消息,目的是告诉客户端,我已经把该给你的东西都给你了
第三次握手
-
客户端就会生成一个新的随机数 (pre-master),用服务器的 RSA 公钥加密该随机数,通过「Client Key Exchange」消息传给服务端。
-
客户端和服务端双方都共享了三个随机数,分别是 Client Random、Server Random、pre-master。
-
双方根据已经得到的三个随机数,生成会话密钥(Master Secret)
-
然后客户端发一个「Change Cipher Spec」,告诉服务端开始使用加密方式发送消息。
第四次握手
服务器也是同样的操作,发「Change Cipher Spec」和「Encrypted Handshake Message」消息。
post和get的区别
GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。
POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。
TCP就像汽车,我们用TCP来运输数据。为了避免这种情况发生,交通规则HTTP诞生了。HTTP给汽车运输设定了好几个服务类别,有GET, POST, PUT, DELETE等等,HTTP规定,当执行GET请求的时候,要给汽车贴上GET的标签(设置method为GET),而且要求把传送的数据放在车顶上(url中)以方便记录。如果是POST请求,就要在车上贴上POST的标签,并把货物放在车厢里。当然,你也可以在GET的时候往车厢内偷偷藏点货物,但是这是很不光彩;也可以在POST的时候在车顶上也放一些数据,让人觉得傻乎乎的。HTTP只是个行为准则,而TCP才是GET和POST怎么实现的基本。
不同的浏览器(发起http请求)和服务器(接受http请求)就是不同的运输公司。 虽然理论上,你可以在车顶上无限的堆货物(url中无限加参数)。但是运输公司可不傻,装货和卸货也是有很大成本的,他们会限制单次运输量来控制风险,数据量太大对浏览器和服务器都是很大负担。业界不成文的规定是,(大多数)浏览器通常都会限制url长度在2K个字节,而(大多数)服务器最多处理64K大小的url。超过的部分,恕不处理。如果你用GET服务,在request body偷偷藏了数据,不同服务器的处理方式也是不同的,有些服务器会帮你卸货,读出数据,有些服务器直接忽略,所以,虽然GET可以带request body,也不能保证一定能被接收到哦。
GET和POST还有一个重大区别,简单的说:
GET产生一个TCP数据包;POST产生两个TCP数据包。
长的说:
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
也就是说,GET只需要汽车跑一趟就把货送到了,而POST得跑两趟,第一趟,先去和服务器打个招呼“嗨,我等下要送一批货来,你们打开门迎接我”,然后再回头把货送过去。
因为POST需要两步,时间上消耗的要多一点,看起来GET比POST更有效。
网络7层、4层模型,区别,功能,有什么协议
1、物理层(Physical Layer)
该层为上层协议提供了一个传输数据的可靠的物理媒体。简单的说,物理层确保原始的数据可在各种物理媒体上传输。物理层记住两个重要的设备名称,中继器(Repeater,也叫放大器)和集线器。
2、数据链路层
如何将数据组合成数据块,在数据链路层中称这种数据块为帧(frame),帧是数据链路层的传送单位;如何控制帧在物理信道上的传输,包括如何处理传输差错,如何调节发送速率以使与接收方相匹配;以及在两个网络实体之间提供数据链路通路的建立、维持和释放的管理。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。
有关数据链路层的重要知识点:
1> 数据链路层为网络层提供可靠的数据传输;
2> 基本数据单位为帧;
3> 主要的协议:以太网协议;
4> 两个重要设备名称:网桥和交换机。
3、网络层(Network Layer)
网络层的目的是实现两个端系统之间的数据透明传送,具体功能包括寻址和路由选择、连接的建立、保持和终止等。它提供的服务使传输层不需要了解网络中的数据传输和交换技术。
有关网络层的重点为:
1> 网络层负责对子网间的数据包进行路由选择。此外,网络层还可以实现拥塞控制、网际互连等功能;
2> 基本数据单位为IP数据报;
3> 包含的主要协议:
IP协议(Internet Protocol,因特网互联协议):
IP协议的主要功能有:无连接数据报传输、数据报路由选择和差错控制。与IP协议配套使用实现其功能的还有地址解析协议ARP、逆地址解析协议RARP、因特网报文协议ICMP、因特网组管理协议IGMP。
ICMP协议(Internet Control Message Protocol,因特网控制报文协议);
ARP协议(Address Resolution Protocol,地址解析协议);
RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)。
4> 重要的设备:路由器。
4、传输层
第一个端到端,即主机到主机的层次。有关网络层的重点:
1> 传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输以及端到端的差错控制和流量控制问题;
2> 包含的主要协议:TCP协议(Transmission Control Protocol,传输控制协议)、UDP协议(User Datagram Protocol,用户数据报协议);
3> 重要设备:网关。
5、会话层
会话层管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。会话层还利用在数据中插入校验点来实现数据的同步。
6.表示层
表示层对上层数据或信息进行变换以保证一个主机应用层信息可以被另一个主机的应用程序理解。表示层的数据转换包括数据的加密、压缩、格式转换等。
7、应用层
1> 数据传输基本单位为报文;
2> 包含的主要协议:FTP(文件传送协议)、Telnet(远程登录协议)、DNS(域名解析协议)、SMTP(邮件传送协议),POP3协议(邮局协议),HTTP协议(Hyper Text Transfer Protocol)。
封装格式

TCP 的 Keepalive 和 HTTP 的 Keep-Alive
-
HTTP 的 Keep-Alive,是由应用层(用户态) 实现的,称为 HTTP 长连接;
-
TCP 的 Keepalive,是由 TCP 层(内核态) 实现的,称为 TCP 保活机制;
如果对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
如果对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送 FIN 报文,而主机宕机则是无法感知的,所以需要 TCP 保活机制来探测对方是不是发生了主机宕机),或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
IP
IP的分类

最大主机数
看主机号的位数,如 C 类地址的主机号占 8 位,那么 C 类地址的最大主机个数:8² - 2
减2是因为有两个特殊的主机号:
-
主机号全为 1 指定某个网络下的所有主机,用于广播
-
主机号全为 0 指定某个网络
D、E类地址没有主机号,不可用于主机 IP,D 类常被用于多播,E 类是预留的分类
-
广播地址用于在同一个链路中相互连接的主机之间发送数据包。
-
多播用于将包发送给特定组内的所有主机。
IPV6
优点
-
IPv6 可自动配置,即使没有 DHCP 服务器也可以实现自动分配IP地址,真是便捷到即插即用啊。
-
IPv6 包头包首部长度采用固定的值 48字节,去掉了包头校验和,简化了首部结构,减轻了路由器负荷,大大提高了传输的性能。
-
IPv6 有应对伪造 IP 地址的网络安全功能以及防止线路窃听的功能,大大提升了安全性
IPV6与IPV4

-
取消了首部校验和字段。 因为在数据链路层和传输层都会校验,因此 IPv6 直接取消了 IP 的校验。
-
取消了分片/重新组装相关字段。 分片与重组是耗时的过程,IPv6 不允许在中间路由器进行分片与重组,这种操作只能在源与目标主机,这将大大提高了路由器转发的速度。
-
取消选项字段。 选项字段不再是标准IP 首部的一部分了,但它并没有消失,而是可能出现在 IPv6 首部中的[下一个首部」指出的位置上。删除该选项字段使的 IPv6 的首部成为固定长度的 48 字节,
ping的工作原理
ICMP
ping 是基于 ICMP 协议工作的,ICMP的主要功能:确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。

ICMP头部格式

ping的过程
ping 命令执行的时候,源主机首先会构建一个 ICMP 回送请求消息数据包。
ICMP 数据包内包含多个字段,最重要的是两个:
-
第一个是类型,对于回送请求消息而言该字段为
8; -
另外一个是序号,主要用于区分连续 ping 的时候发出的多个数据包。
主机 B 收到这个数据帧后,先检查它的目的 MAC 地址,并和本机的 MAC 地址对比,如符合,则接收,否则就丢弃。
主机 B 会构建一个 ICMP 回送响应消息数据包,回送响应数据包的类型字段为 0,序号为接收到的请求数据包中的序号,然后再发送出去给主机 A。
七、ARP协议
ARP协议可以将IPv4地址(一种逻辑地址)转换为各种网络所需的硬件地址(一种物理地址)。换句话说,所谓的地址解析的目标就是发现逻辑地址与物理地址的映射关系。
有人可能觉得,直接用物理地址替代IP地址不就行了么?
如果完全依赖物理地址,那么路由表就需要对每个物理地址建立一个项,那样没有一个路由器能够负担如此庞大的表项。
而IP地址提供了更高层次的抽象,将不同的物理地址抽象为统一的逻辑地址。
ARP工作原理
ARP协议主要依赖ARP高速缓存(ARP cache)。ARP高速缓存就是一个映射表,它记录了IP地址和物理地址的映射关系。
当键入网址后,到网页显示,其间发生了什么
HTTP
首先浏览器做的第一步工作就是要对 URL 进行解析,从而生成发送给 Web 服务器的请求信息。
对 URL 进行解析之后,浏览器确定了 Web 服务器和文件名,接下来就是根据这些信息来生成 HTTP 请求消息了。

DNS
查询服务器域名对应的 IP 地址
有一种服务器就专门保存了 Web 服务器域名与 IP 的对应关系,它就是 DNS 服务器。
域名的层级关系类似一个树状结构:
-
根 DNS 服务器(.)
-
顶级域 DNS 服务器(.com)
-
权威 DNS 服务器(server.com)
域名解析的工作流程:

客户端-->本地DNS -->缓存
-->根域 --> 顶级域 --> 权威
协议栈
通过 DNS 获取到 IP 后,就可以把 HTTP 的传输工作交给操作系统中的协议栈。

TCP
生成TCP头部,TCP 模块在执行连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成网络包发送给通信对象。

IP
生成了 IP 头部之后,接下来网络包还需要在 IP 头部的前面加上 MAC 头部。

MAC
发送方的 MAC 地址获取就比较简单了,MAC 地址是在网卡生产时写入到 ROM 里的,只要将这个值读取出来写入到 MAC 头部就可以了。
接收方的 MAC 地址就有点复杂了,只要告诉以太网对方的 MAC 的地址,以太网就会帮我们把包发送过去,那么很显然这里应该填写对方的 MAC 地址。
所以先得搞清楚应该把包发给谁,这个只要查一下路由表就知道了。在路由表中找到相匹配的条目,然后把包发给 Gateway 列中的 IP 地址就可以了。
此时就需要 ARP 协议帮我们找到路由器的 MAC 地址。
ARP 协议会在以太网中以广播的形式,对以太网所有的设备喊出:“这个 IP 地址是谁的?请把你的 MAC 地址告诉我”。
网卡
网络包只是存放在内存中的一串二进制数字信息,没有办法直接发送给对方。因此,我们需要将数字信息转换为电信号,才能在网线上传输,也就是说,这才是真正的数据发送过程。
负责执行这一操作的是网卡,要控制网卡还需要靠网卡驱动程序。
网卡驱动获取网络包之后,会将其复制到网卡内的缓存区中,接着会在其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。
交换机
交换机将电信号转换为数字信号。
计算机的网卡本身具有 MAC 地址,并通过核对收到的包的接收方 MAC 地址判断是不是发给自己的,如果不是发给自己的则丢弃;相对地,交换机的端口不核对接收方 MAC 地址,而是直接接收所有的包并存放到缓冲区中。因此,和网卡不同,交换机的端口不具有 MAC 地址。
将包存入缓冲区后,接下来需要查询一下这个包的接收方 MAC 地址是否已经在 MAC 地址表中有记录了。
交换机的 MAC 地址表主要包含两个信息:
-
一个是设备的 MAC 地址,
-
另一个是该设备连接在交换机的哪个端口上。
路由器
网络包经过交换机之后,现在到达了路由器,并在此被转发到下一个路由器或目标设备。
这一步转发的工作原理和交换机类似,也是通过查表判断包转发的目标。
不过在具体的操作过程上,路由器和交换机是有区别的。
-
而交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有 MAC 地址。
-
因为路由器是基于 IP 设计的,俗称三层网络设备,路由器的各个端口都具有 MAC 地址和 IP 地址;
路由器基本原理
路由器的端口具有 MAC 地址,因此它就能够成为以太网的发送方和接收方;同时还具有 IP 地址,从这个意义上来说,它和计算机的网卡是一样的。
当转发包时,首先路由器端口会接收发给自己的以太网包,然后路由表查询转发目标,再由相应的端口作为发送方将以太网包发送出去。
包的接收操作
首先,电信号到达网线接口部分,路由器中的模块会将电信号转成数字信号,然后通过包末尾的 FCS 进行错误校验。
如果没问题则检查 MAC 头部中的接收方 MAC 地址,看看是不是发给自己的包,如果是就放到接收缓冲区中,否则就丢弃这个包。
路由器的发送操作
包的发送操作
首先,我们需要根据路由表的网关列判断对方的地址。
-
如果网关是一个 IP 地址,则这个IP 地址就是我们要转发到的目标地址,还未抵达终点,还需继续需要路由器转发。
-
如果网关为空,则 IP 头部中的接收方 IP 地址就是要转发到的目标地址,也是就终于找到 IP 包头里的目标地址了,说明已抵达终点。
Linux系统收发网络包
Linux网络协议栈
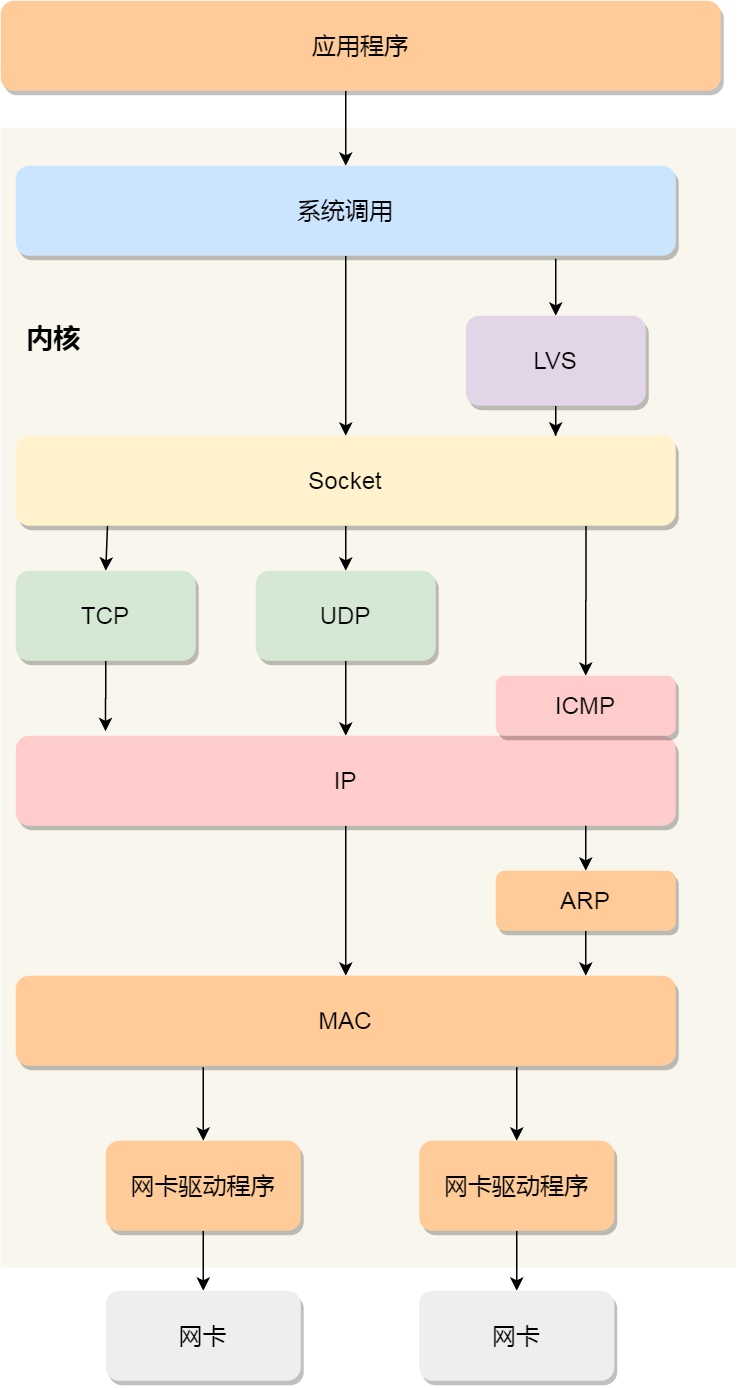
Linux 接收网络包的流程
网卡是计算机里的一个硬件,专门负责接收和发送网络包,当网卡接收到一个网络包后,会通过 DMA 技术,将网络包写入到指定的内存地址,也就是写入到 Ring Buffer 。
每当网卡收到一个网络包,就触发一个中断告诉操作系统网络包已经到达。
但是在高性能网络场景下,网络包的数量会非常多,那么就会触发非常多的中断,频繁地触发中断,导致其他任务可能无法继续前进,从
而影响系统的整体效率,所以为了解决频繁中断带来的性能开销,Linux 内核在 2.6 版本中引入了 NAPI 机制,它是混合中断和轮询的方式来接收网络包,它的核心概念就是不采用中断的方式读取数据,而是首先采用中断唤醒数据接收的服务程序,然后poll的方法来轮询数据。
因此,当有网络包到达时,会通过 DMA 技术,将网络包写入到指定的内存地址,接着网卡向 CPU 发起硬件中断,当 CPU 收到硬件中断
请求后,根据中断表,调用已经注册的中断处理函数。
硬件中断
-
需要先「暂时屏蔽中断」,表示已经知道内存中有数据了,告诉网卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提高效率,避免 CPU 不停的被中断。
-
接着,发起「软中断」,然后恢复刚才屏蔽的中断。
软中断
-
内核中的 ksoftirgd 线程专门负责软中断的处理,当 ksoftirqd 内核线程收到软中断后,就会来轮询处理数据。
-
ksoftirgd 线程会从 Ring Buffer 中获取一个数据帧,用 sk buff 表示,从而可以作为一个网络包交给网络协议栈进行逐层处理。
Linux 发送网络包的流程
首先,应用程序会调用 Socket 发送数据包的接口,由于这个是系统调用,所以会从用户态陷入到内核态中的 Socket 层,内核会申请一个
内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加入到发送缓冲区。
接下来,网络协议栈从 Socket 发送缓冲区中取出 sk_buff,并按照 TCP/IP 协议栈从上到下逐层处理。
如果使用的是 TCP 传输协议发送数据,那么先拷贝一个新的 sk_buff 副本 ,这是因为 sk_buff 后续在调用网络层,最后到达网卡发送完
成的时候,这个 sk buf 会被释放掉。而 TCP 协议是支持丢失重传的,在收到对方的 ACK 之前,这个 sk buff 不能被删除。所以内核的做
法就是每次调用网卡发送的时候,实际上传递出去的是 sk buff 的一个拷贝,等收到 ACK 再真正删除。
接着,对 sk_buff 填充 TCP 头。这里提一下,sk_buff 可以表示各个层的数据包,在应用层数据包,叫data,在 TCP 层我们称为
segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
为什么全部数据包只用一个结构体来描述呢?
协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在
层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用sk_buf 一个结构体来描述所有的网络包,通过调整 sk_buff 中 data 的指针,比如:
-
当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
-
当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
发送网络数据的时候,涉及几次内存拷贝操作?
第一次,调用发送数据的系统调用的时候,内核会申请一个内核态的 sk_buff 内存,将用户待发送的数据拷贝到 sk_buff 内存,并将其加
入到发送缓冲区。
第二次,在使用 TCP 传输协议的情况下,从传输层进入网络层的时候,每一个 sk_buff 都会被克隆一个新的副本出来。副本 sk_buff 会被
送往网络层,等它发送完的时候就会释放掉,然后原始的 sk_buff 还保留在传输层,目的是为了实现 TCP 的可靠传输,等收到这个数据包
的 ACK 时,才会释放原始的 sk_buff
第三次,当IP 层发现 sk_buf 大于 MTU 时才需要进行。会再申请额外的 sk_buff,并将原来的 sk_buff 拷贝为多个小的 sk_buff。
Redis
简介
Redis 是一种基于内存的数据库,对数据的读写操作都是在内存中完成,因此读写速度非常快,常用于缓存,消息队列、分布式锁等场景
Redis 提供了多种数据类型来支持不同的业务场景,比如 String(字符串)、Hash(哈希)、 List (列表)、Set(集合)、Zset(有序集合)、Bitmaps(位图)、HyperLogLog(基数统计)、GEO(地理信息)、Stream(流),并且对数据类型的操作都是原子性的,因为执行命令由单线程负责的,不存在并发竞争的问题。 除此之外,Redis 还支持事务 、持久化、Lua 脚本、多种集群方案(主从复制模式、哨兵模式、切片机群模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等。
Redis 和 Memcached 的区别
共同点:
-
都是基于内存的数据库,一般都用来当做缓存使用。
-
都有过期策略。
-
两者的性能都非常高。
区别:
-
Redis 支持的数据类型更丰富(String、Hash、List、Set、ZSet),而 Memcached 只支持最简单的key-value 数据类型:
-
Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memcached 没有持久化功能,数据全部存在内存之中,Memcached 重启或者挂掉后,数据就没了;
-
Redis 原生支持集群模式,Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;
-
Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持,
Redis数据结构
String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)、BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO、Stream(5.0 版新增)
-
String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等·
-
List 类型的应用场景:消息队列(但是有两个问题:1.生产者需要自行实现全局唯- ID;2.不能以消费组形式消费数据)等。
-
Hash 类型:缓存对象、购物车等。
-
Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等·
-
Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
-
BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等
-
HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等:
-
GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
-
Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
Redis 线程模型
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的,但Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程
关闭文件、AOF 刷盘、释放内存

Redis持久化
Redis 共有三种数据持久化的方式:
-
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里
-
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
-
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点
Redis为什么快?
-
基于内存实现
-
使用I/O多路复用模型
-
采用单线程模型
-
高效的数据结构
-
合理的数据编码
设计模式
单例模式
定义
单例模式是指在内存中只会创建且仅创建一次对象的设计模式。在程序中多次使用同一个对象且作用相同时,为了防止频繁地创建对象使得内存飙升,单例模式可以让程序仅在内存中创建一个对象,让所有需要调用的地方都共享这一单例对象。

类型
-
懒汉式:在真正需要使用对象时才去创建该单例类对象
懒汉式创建对象的方法是在程序使用对象前,先判断该对象是否已经实例化(判空),若已实例化直接返回该类对象。,否则则先执行实例化操作。

-
饿汉式:在类加载时已经创建好该单例对象,等待被程序使用
饿汉式在类加载时已经创建好该对象,在程序调用时直接返回该单例对象即可,即我们在编码时就已经指明了要马上创建这个对象,不需要等到被调用时再去创建。

总结
(1)单例模式常见的写法有两种:懒汉式、饿汉式
(2)懒汉式:在需要用到对象时才实例化对象,正确的实现方式是:Double Check + Lock,解决了并发安全和性能低下问题
(3)饿汉式:在类加载时已经创建好该单例对象,在获取单例对象时直接返回对象即可,不会存在并发安全和性能问题。
(4)在开发中如果对内存要求非常高,那么使用懒汉式写法,可以在特定时候才创建该对象;
(5)如果对内存要求不高使用饿汉式写法,因为简单不易出错,且没有任何并发安全和性能问题
(6)为了防止多线程环境下,因为指令重排序导致变量报NPE,需要在单例对象上添加volatile关键字防止指令重排序
(7)最优雅的实现方式是使用枚举,其代码精简,没有线程安全问题,且 Enum 类内部防止反射和反序列化时破坏单例。
简单工厂模式
定义
简单工厂模式(Simple Factroy Pattern):定义一个工厂类,它可以根据参数的不同返回不同的实例,被创建的实例通常都具有共同的父类。因为在简单工厂模式中用于创建实例的方法是静态方法,因此简单工厂模式又被称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。
1.要点
当你需要什么,只需要传入一个正确的参数,就可以获取所需要的对象,而无需知道创建细节。简单工厂的结构模式比较简单,其核心是工厂类的设计。如图:

2.各个角色
-
Factory (工厂角色):工厂角色即工厂类,它是简单工厂模式的核心,负责实现创建所有产品实例的内部逻辑;工厂类可以被外界直接调用,创建所需的产品对象; 在工厂类中提供了静态的工厂方法factoryMethod(),它的返回类型为抽象产品类型Product。
-
Product(抽象产品角色):它是工厂类所创建的所有对象的父类,封装了各种产品对象的公有方法,它的引入将提高系统的灵活性,使得在工厂类中只需定义一个通用的工厂方法,因为所有创建的具体产品对象都是其子类对象。
-
ConcreteProduct(具体产品角色):它是简单工厂模式的创建目标,所有被创建的对象都充当这个角色的某个具体类的实例。每一个具体产品角色都继承了抽象产品角色,需要实现在抽象产品中声明的抽象方法。
流程
-
将需要创建的各种不同对象(例如各种不同的Chart对象)的相关代码给封装到不同的类中,这些类称为具体产品类。
-
将他们公共的代码进行抽象和提取后封装在一个抽象产品类中,每一个具体产品类都是抽象产品类的子类。
-
提供一个工厂类用于创建各种产品,在工厂类中提供一个创建产品的工厂方法,该方法可以根据所传入的参数不同创建不同的具体产品对象。
-
客户端只需要调用工厂类的工厂方法并传入相应的参数即可得到一个产品对象。
抽象工厂模式
简介
抽象工厂模式(Abstract Factory Pattern)也是一种创建型设计模式,它提供了一种创建一系列相关或者相依赖对象的工厂接口(超级工厂),不同类型的工厂再去实现这个抽象工厂,最后还可提供一个工厂创造者类,通过传入工厂类型参数来创建具体工厂。它是对工厂方法模式的扩展,核心思想是将工厂本身也抽象化,其主旨是围绕一个超级工厂或中心工厂去创建其他工厂,这个超级工厂又称为其他工厂的工厂。
特点
优点
-
将产品的创建和使用分离开来,使得客户端代码更加简洁,并且向客户端隐藏产品的创建细节。
-
将一系列相关的产品对象的创建工作统一到一个抽象工厂中,客户端只需要访问抽象工厂即可,具体的产品工厂可以灵活替换。
-
当一个族中的多个对象被设计成一起工作时, 它能够保证客户端始终只使用同一个族中的对象。
缺点
-
一个产品族下增加新的产品等级非常困难,甚至需要修改抽象层代码和其下所有的实现, 严重违背了“开闭原则”。
-
增加了代码的复杂性,增加了系统的抽象性,增加了理解难度。
使用场景
-
系统需要一系列相关或相互依赖的产品对象,并且这些产品对象的实现可能会随着时间的推移而发生变化。
-
系统需要在运行时动态地选择产品族中的一种,而不是一种单一的产品。
-
系统需要保证一组产品对象被设计成一起使用,而不是单独使用。
-
系统需要对一个产品族下不同产品提供统一的访问接口,而不关心产品的具体实现。
观察者模式
定义
观察者模式通常由两个对象组成:观察者和被观察者。当被观察者状态发生改变时,它会通知所有的观察者对象,使他们能够及时做出响应,所以也被称作“发布-订阅模式”。
特点
优点:
-
被观察者和观察者对象之间不需要知道对方的具体实现,只需要知道对方的接口,避免了紧耦合的关系。
-
由于被观察者对象并不关心具体的观察者是谁,所以在程序运行的过程中,可以动态地增加或者删除观察者对象,增加了灵活性。
-
符合开闭原则,当需要添加新的观察者时,只需要添加一个实现观察者接口的类,而不需要修改被观察者对象的代码。
缺点:
-
当观察者没有被正确移除时,可能会导致内存泄漏的问题。
-
实现观察者模式,需要定义多个接口和类,增加了程序的复杂度。
-
在某些情况下,被观察者和观察者对象之间可能出现循环依赖的问题。
应用场景
-
当一个对象的状态发生改变时,需要通知多个对象做出相应的响应。例如,王者荣耀更新前,会通知所有用户要更新的时间。
-
当很多对象同时对某一个主题感兴趣时,可以采用观察者模式实现发布-订阅模式。例如,生产者发送消息到消息队列中,并通知所有订阅此队列的消费者进行消费。
-
数据库开发中,当数据库表中的数据发生变化时,需要通知相关的模块进行更新或其他操作。例如,当用户更新了数据库中的某个记录时,就可以通过观察者模式通知所有注册的监听器进行响应。

















 9045
9045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









