







select语句部分练习
1、显示所有职工的基本信息。
2、查询所有职工所属部门的部门号,不显示重复的部门号
3、求出所有职工的人数。
4、列出最高工和最低工资。
5、列出职工的平均工资和总工资。
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
7、列出所有姓刘的职工的职工号、姓名和出生日期。
8、列出1960年以前出生的职工的姓名、参加工作日期。
9、列出工资在3500一4800之间的所有职工姓名。
10、列出所有王姓和李姓的职工姓名。
11、列出所有部门号为2和3且为党员的职工号、姓名,政治面貌。
12、将职工表worker中的职工按出生的先后顺序排序。
13、显示工资最高的前3名职工的职工号和姓名。
14、求出各部门党员的人数。
15、统计各部门的工资和平均工资
16、列出总人数大于4的部门号和总人数。
前言:
- SELECT查询是SQL语言中最常用的命令之一。它用于从数据库表中检索数据,并根据指定的条件进行筛选和排序。以下是SELECT查询的总结:
- - 选择列: 使用SELECT子句后跟要检索的列名,可以选择一列或多列。例如: SELECT 列1, 列2 FROM 表名;
- - 检索所有列: 使用通配符 * 可以选择表中的所有列。例如: SELECT * FROM 表名;
- - 指定条件: 使用WHERE子句来添加条件,筛选符合条件的记录。例如: SELECT 列1, 列2 FROM 表名 WHERE 条件;
- - 排序数据: 使用ORDER BY子句按照指定的列对结果进行排序,默认是升序。可以使用DESC关键字进行降序排序。例如: SELECT 列1, 列2 FROM 表名 ORDER BY 列1 DESC;
- - 消除重复数据: 使用DISTINCT关键字可以去除结果中的重复记录。例如: SELECT DISTINCT 列 FROM 表名;
- - 计算列: 使用计算表达式可以在查询的结果中计算新的列。例如: SELECT 列1, 列2, 列1 + 列2 AS 新列 FROM 表名;
- - 使用聚合函数: 使用聚合函数如SUM、AVG、COUNT等对一列或多列进行计算。例如: SELECT SUM(列1) FROM 表名;
- - 连接表: 使用JOIN子句可以将多个表连接起来,并根据指定的条件进行匹配。例如: SELECT 列1, 列2 FROM 表1 JOIN 表2 ON 表1.列 = 表2.列;
- 以上是一些SELECT查询的常见用法,根据具体需求可以灵活组合和扩展。
- 以下例题是对部分select语句进行练习
- 前提须知 建成后该表如图呈现
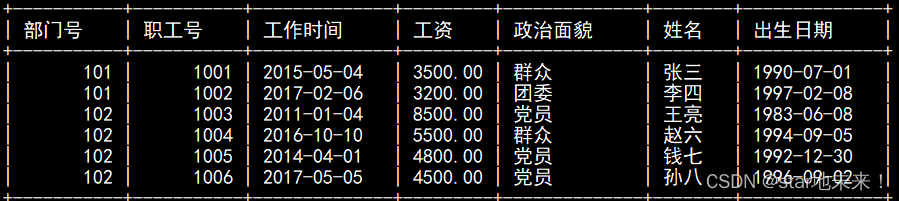
习题精炼:
1、显示所有职工的基本信息。
使用select查询表内所有数据(*是匹配每一个字段) ,对表格数据进行呈现。
select *from worker; 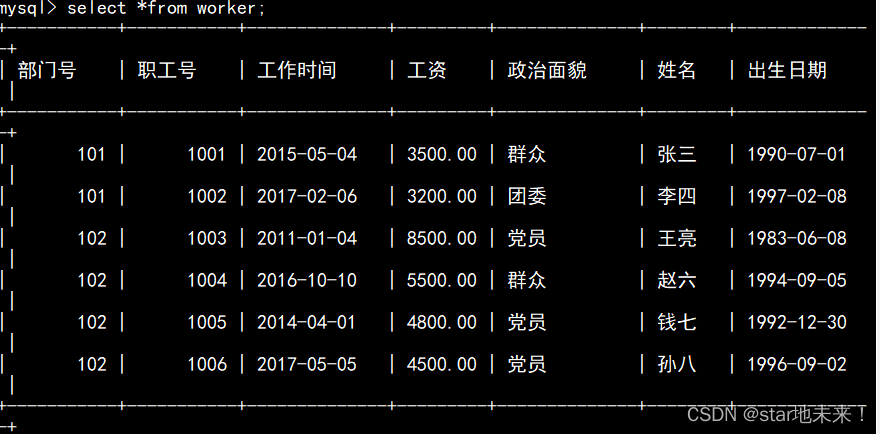
2、查询所有职工所属部门的部门号,不显示重复的部门号
使用select查询以部门号分组,将所有名字根据部门号字段全部展示出来。
select `部门号`,group_concat(`姓名`) from worker group by `部门号`;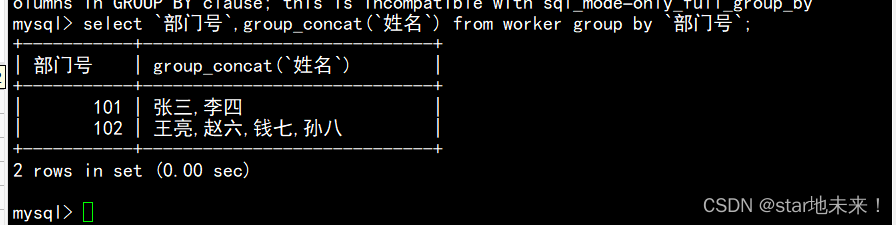
3、求出所有职工的人数。
使用count对姓名进行计数,从而达到对表内的数据进行计数,进而得出员工人数(as起到起别名作用)
select count(`姓名`) as '职工人数'from worker; 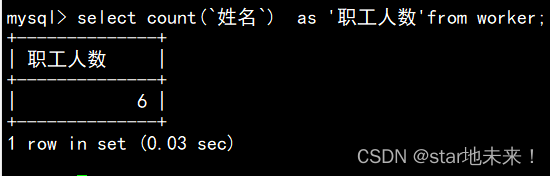
4、列出最高工和最低工资。
使用聚合函数对select查出的语句进行处理,as起到起别名的效果,用max,min取出最高与最低工资。
select max(`工资`) as '最高工资',min(`工资`) as '最低工资'from worker; 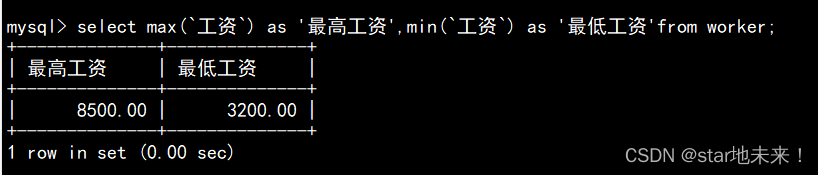
5、列出职工的平均工资和总工资。
使用聚合函数对select查出的语句进行处理,求出他的总工资和平均工资。
select avg(`工资`) as '平均工资',sum(`工资`) as '总工资' from worker; 
6、创建一个只有职工号、姓名和参加工作的新表,名为工作日期表。
创建一个新表,新表的数据来自于select从旧表中查处的数据。
create table `工作日期表` select `职工号`,`姓名`,`工作时间` from worker; 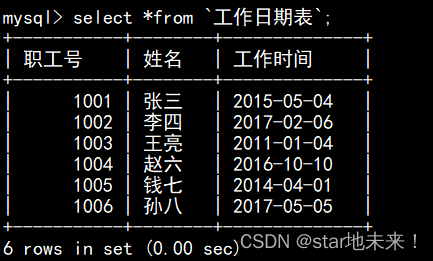
7、列出所有姓刘的职工的职工号、姓名和出生日期。
对题目进行操作得出该表中没有刘姓员工,所以该结果为空。
select `职工号`,`姓名`,`出生日期` from worker where `姓名` like '刘%'; 
8、列出1960年以前出生的职工的姓名、参加工作日期。
先查出字段结果,在用where进行判断,拿出条件相符的结果。
select `姓名`,`工作时间` as '参加工作时间' from worker where '出生日期' < '1960-1-1'; 
9、列出工资在3500一4800之间的所有职工姓名
在该表中应该拿出工资在3500-4800之间的员工姓名
select `姓名` from worker where `工资` >= 3500 and `工资` <= 4800; 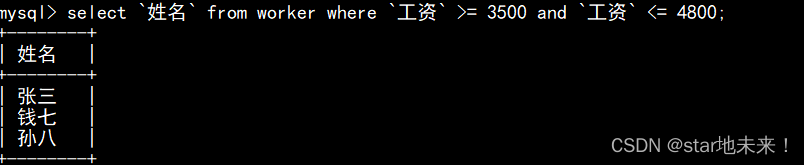
10、列出所有王姓和李姓的职工姓名。
对题目进行分析,和该表比较应该拿出所有李姓和王姓的员工,并使用like进行模糊查询,如果查询名字中包含王的话则用(%王%)
select `姓名` from worker where `姓名` like '李%' or `姓名` like '王%'; 
11、列出所有部门号为2和3且为党员的职工号、姓名,政治面貌。
和上述查询方法一样,在where后用条件判断。
select `姓名`,`职工号`,`政治面貌` from worker where( `部门号` = 103 or `部门号` = 102) and `政治面貌` = '党员'; 
12、将职工表worker中的职工按出生的先后顺序排序。
select `职工号`, `姓名` from worker order by `出生日期` desc;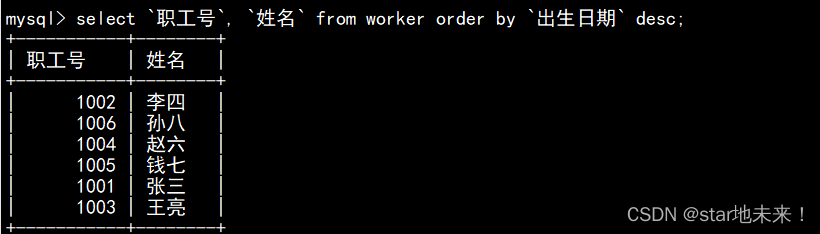
13、显示工资最高的前3名职工的职工号和姓名。
该语句用上了 order by + desc 进行了排序,并且最后在limit后将数据分成了两部分,从0开始,每次取三个数据。
select `职工号`, `姓名` from worker order by `工资` desc limit 0 ,3; 
14、求出各部门党员的人数。
该语句用count(*)对政治面貌 为党员的进行了一个计数,求出党员人数,和所在部门号
select `部门号` ,count(*) from worker where `政治面貌`='党员'group by `部门号` having count(*)>1; 
15、统计各部门的工资和平均工资
用聚合函数对数据进行处理,并展现出来,并且用求和和取平均值将需要的结果展现出来。
select sum(`工资`),avg(`工资`) from worker group by `部门号`; 
16、列出总人数大于4的部门号和总人数。
用count对姓名进行计数,用来统计人数,并且以部门号进行分组,在此之前先求出来满足人数大于4人的条件。
select `部门号` as '部门' ,count(`姓名`) as '人数' from worker group by `部门号` havingg count(`姓名`) >= 4 ; 
总结,以下是对select用法的一些简单总结
- 当使用SELECT语句时,可以使用多个关键字和子句来实现不同的功能。以下是SELECT语句的常见用法总结:
- 1. 选择列: 使用SELECT子句后跟要检索的列名,可以选择一列或多列。例如: SELECT 列1, 列2 FROM 表名;
- 2. 检索所有列: 使用通配符 * 可以选择表中的所有列。例如: SELECT * FROM 表名;
- 3. 指定条件: 使用WHERE子句来添加条件,筛选符合条件的记录。例如: SELECT 列1, 列2 FROM 表名 WHERE 条件;
- 4. 排序数据: 使用ORDER BY子句按照指定的列对结果进行排序,默认是升序。可以使用DESC关键字进行降序排序。例如: SELECT 列1, 列2 FROM 表名 ORDER BY 列1 DESC;
- 5. 消除重复数据: 使用DISTINCT关键字可以去除结果中的重复记录。例如: SELECT DISTINCT 列 FROM 表名;
- 6. 计算列: 使用计算表达式可以在查询的结果中计算新的列。例如: SELECT 列1, 列2, 列1 + 列2 AS 新列 FROM 表名;
- 7. 使用聚合函数: 使用聚合函数如SUM、AVG、COUNT等对一列或多列进行计算。例如: SELECT SUM(列1) FROM 表名;
- 8. 连接表: 使用JOIN子句可以将多个表连接起来,并根据指定的条件进行匹配。例如: SELECT 列1, 列2 FROM 表1 JOIN 表2 ON 表1.列 = 表2.列;
- 9. 分组数据: 使用GROUP BY子句可以对结果进行分组,并对每个组应用聚合函数。例如: SELECT 列1, SUM(列2) FROM 表名 GROUP BY 列1;
- 10. 过滤分组: 使用HAVING子句对分组的结果进行条件过滤,类似于WHERE子句。例如: SELECT 列1, SUM(列2) FROM 表名 GROUP BY 列1 HAVING SUM(列2) > 100;
- 11. 子查询: SELECT语句可以嵌套在另一个SELECT语句中,作为子查询使用。例如: SELECT 列1, (SELECT 列2 FROM 表2 WHERE 条件) FROM 表1;
- 这些是SELECT语句的常见用法,可以根据具体需求进行灵活组合和扩展。















 109
109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









