






前置知识
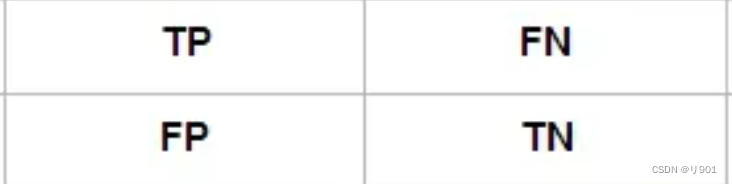
混淆矩阵
True:代表预测正确 Positive:代表预测类别为正样本
True Positive(TP):将正类预测为正类; True Negative(TN):将负类预测为负类
False Positive(FP):将负类预测为正类→误报;False Negative(FN):将正类预测为负类→漏报
实现:
from sklearn.metrics import confusion_matrix
def compute_confusion_matrix(labels,pred_labels_list,gt_labels_list):
pred_labels_list = np.asarray(pred_labels_list)
gt_labels_list = np.assarray(gt_labels_list)
matrix = confusion_matrix(gt_labels_list,
pred_label_list,
labels=labels)
return matrix
1)准确率=(TP+TN)/(TP+TN+FP+FN)
2)召回率(Recall)=TP/(TP+FN) 在所有正样本中,被正确预测的正样本所占的比例
3)精确率(Precision)=TP/(TP+TN) 在预测正确的结果中,被正确预测的正样本所占的比例
当P和R矛盾时,使用4)F-Score(Precision和Recall加权调和平均):
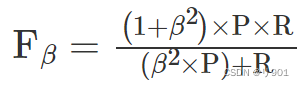
-
当 β > 1 时,更偏好召回(Recall)
-
当 β < 1 时,更偏好精准(Precision)
-
当 β = 1 时,平衡精准和召回,即为 F1

5)PR曲线
横轴召回率,纵轴精确率。P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。
6)置信度
在目标检测中,我们通常需要将边界框内物体划分为正样本和负样本。我们使用置信度这个指标来进行划分,当小于置信度设置的阈值判定为负样本(背景),大于置信度设置的阈值判定为正样本。
7)IOU
交并比,就是把 预测框 与 真实框 的相交的面积除以相并的面积。常用于目标检测任务和语义分割任务。后续因其缺陷衍生出来GIOU、DIOU、CIOU。
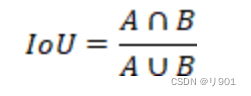
8)Average Precision AP
PR曲线所包含的面积,当我们取不同的置信度,可以获得不同的P和R,PR曲线下面所包含的面积就是模型检测某个类的AP值。















 3668
3668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









