






•2.1 概述
•2.1.1 Hadoop简介
•2.1.2 Hadoop发展简史


•2.1.3 Hadoop的特性
Hadoop 的主要特性包括:
-
分布式存储:Hadoop 使用 Hadoop 分布式文件系统(HDFS)来存储数据,将数据分散存储在多台计算机上,提高了数据的可靠性和容错性。
-
分布式计算:Hadoop 使用 MapReduce 编程模型,可以在大规模的数据集上执行并行计算任务。MapReduce 将计算任务分为映射(Map)和归约(Reduce)两个阶段,使大规模数据的处理变得更容易。
-
扩展性:Hadoop 具有高度的可扩展性,可以轻松地增加计算节点以应对不断增长的数据量。
-
容错性:Hadoop 具有内置的容错机制,可以处理硬件故障,确保计算不会因节点故障而中断。
-
生态系统:Hadoop 生态系统包括许多附加组件,如 Apache Hive、Apache Pig、Apache HBase 等,这些组件扩展了 Hadoop 的功能,使其更适合各种大数据处理需求。
Hadoop 已经成为处理大数据的重要工具,广泛用于企业和研究机构,用于存储、处理和分析大规模数据集。它在云计算、商业智能、日志分析等领域都有广泛的应用。
•2.1.4 Hadoop的应用现状

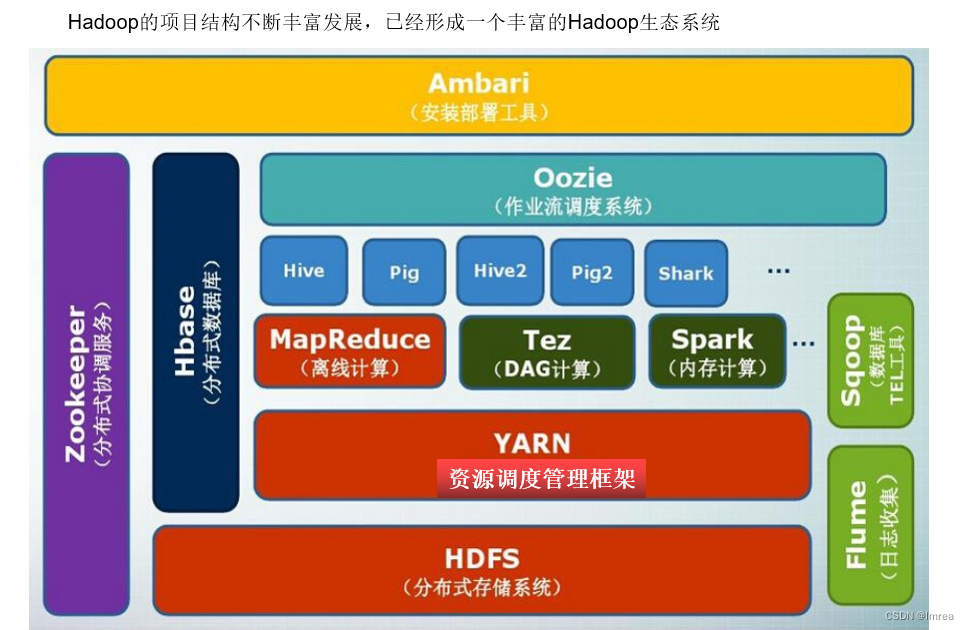
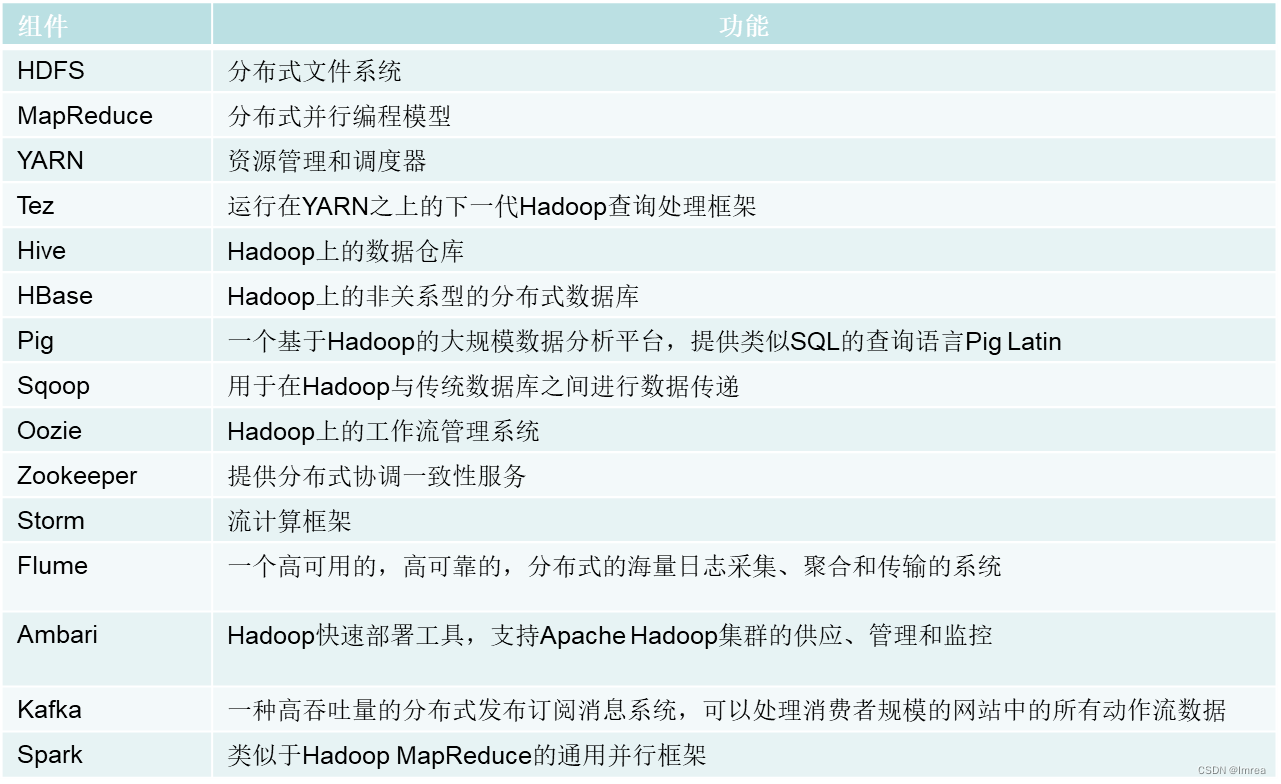
•2.2 Hadoop项目结构
•2.3 Hadoop的安装与使用
•2.3.1 Hadoop安装之前的预备知识
(1)选择哪个Linux发行版?
(2)选择32位还是64位?
关于Linux的一些基础知识
Hadoop安装方式
安装 Hadoop 时,你可以选择不同的模式,包括单机模式、伪分布式模式和分布式模式。以下是这三种模式的详细说明和安装步骤:
-
单机模式:
- 单机模式是最简单的 Hadoop 部署模式,通常用于开发和测试目的。它在一台机器上运行 Hadoop,不使用分布式文件系统(HDFS)。
- 下面是在单机模式下安装和配置 Hadoop 的一般步骤:
- 下载 Hadoop 安装包,并解压到本地文件夹。
- 配置 Hadoop 环境变量,如
HADOOP_HOME和JAVA_HOME。 - 配置 Hadoop 的核心配置文件,如
core-site.xml和hdfs-site.xml,以指定本地文件系统路径。 - 创建 HDFS 数据存储目录。
- 启动 Hadoop 服务并运行 MapReduce 任务。
-
伪分布式模式:
- 伪分布式模式允许在一台机器上模拟分布式环境,使用 HDFS 存储数据,但是 HDFS 的名称节点和数据节点都在同一台机器上。
- 安装伪分布式模式的一般步骤如下:
- 下载 Hadoop 安装包,并解压到本地文件夹。
- 配置 Hadoop 环境变量,如
HADOOP_HOME和JAVA_HOME。 - 配置 Hadoop 的核心配置文件,如
core-site.xml和hdfs-site.xml,以指定 HDFS 的数据存储路径。 - 启动 HDFS 和 YARN(资源管理器)守护进程。
- 创建 HDFS 数据存储目录。
- 启动 Hadoop 服务,并运行 MapReduce 任务。
-
分布式模式:
- 分布式模式是用于生产环境的 Hadoop 部署,它使用真正的分布式文件系统(HDFS),并将 HDFS 的名称节点和数据节点分布在不同的机器上。
- 安装分布式模式需要更多的硬件和网络配置,以确保节点之间的通信和容错性。
- 安装分布式模式的一般步骤如下:
- 配置多台计算机,为每台计算机分配特定的角色,如名称节点、数据节点、资源管理器、任务跟踪器等。
- 安装 Hadoop 安装包并在所有节点上配置 Hadoop 环境变量和配置文件。
- 启动 HDFS 和 YARN 守护进程。
- 创建 HDFS 数据存储目录。
- 启动 Hadoop 服务,确保节点之间的通信正常。
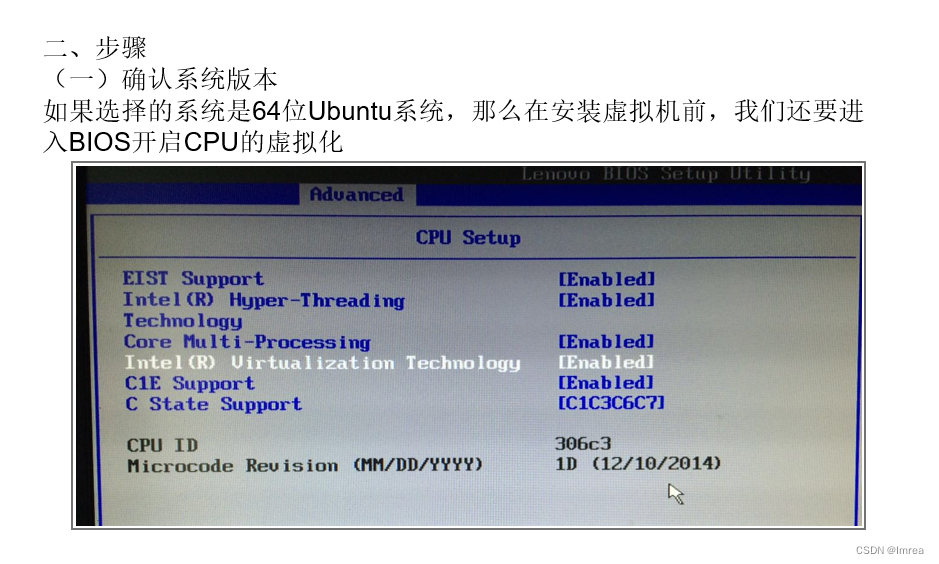
•2.3.2 安装Linux虚拟机
1、下载VirtualBox虚拟机软件
https://download.virtualbox.org/virtualbox/6.1.4/VirtualBox-6.1.4-136177-Win.exe
2. 下载Ubuntu LTS 16.04(或18.04) ISO映像文件
Ubuntu LTS 16.04下载:https://www.ubuntu.org.cn/download/ubuntu-kylin
Ubuntu LTS 18.04下载:https://ubuntu.com/download/desktop
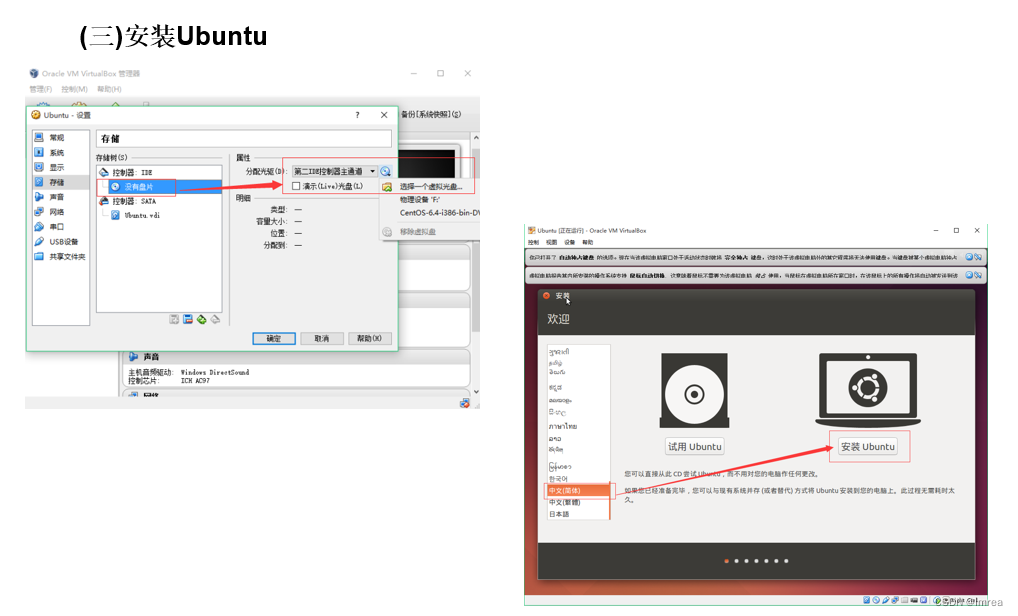
•2.3.3 安装双操作系统

•2.3.4 详解Hadoop的安装与使用


















 6700
6700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











