






import math
def create_tree(data, attributes, max_depth=float('inf'), min_samples=1, depth=0):
if len(data) == 0:
return None
if all_same(data):
return data[0][-1]
if len(attributes) == 1 or depth >= max_depth:
return majority_class(data)
best_attribute = choose_best_attribute(data, attributes)
tree = {best_attribute: {}}
attribute_values = get_attribute_values(data, best_attribute)
for value in attribute_values:
sub_data = get_sub_data(data, best_attribute, value)
if len(sub_data) < min_samples:
tree[best_attribute][value] = majority_class(sub_data)
else:
sub_attributes = attributes[:]
sub_attributes.remove(best_attribute)
tree[best_attribute][value] = create_tree(sub_data, sub_attributes, max_depth, min_samples, depth + 1)
return tree
def all_same(data):
label = data[0][-1]
for sample in data:
if sample[-1] != label:
return False
return True
def majority_class(data):
label_count = {}
for sample in data:
label = sample[-1]
if label in label_count:
label_count[label] += 1
else:
label_count[label] = 1
return max(label_count, key=label_count.get)
def choose_best_attribute(data, attributes):
best_gain = 0
best_attribute = None
for attribute in attributes:
gain = calculate_gain(data, attribute)
if gain > best_gain:
best_gain = gain
best_attribute = attribute
return best_attribute
def calculate_gain(data, attribute):
gain = calculate_entropy(data)
attribute_values = get_attribute_values(data, attribute)
for value in attribute_values:
sub_data = get_sub_data(data, attribute, value)
prob = len(sub_data) / len(data)
gain -= prob * calculate_entropy(sub_data)
return gain
def calculate_entropy(data):
label_count = {}
for sample in data:
label = sample[-1]
if label in label_count:
label_count[label] += 1
else:
label_count[label] = 1
entropy = 0
for count in label_count.values():
prob = count / len(data)
entropy -= prob * math.log(prob, 2)
return entropy
def get_attribute_values(data, attribute):
values = []
for sample in data:
value = sample[attribute]
if value not in values:
values.append(value)
return values
def get_sub_data(data, attribute, value):
sub_data = []
for sample in data:
if sample[attribute] == value:
sub_data.append(sample)
return sub_data
def classify(tree, sample):
if isinstance(tree, str):
return tree
root = list(tree.keys())[0]
value = sample[root]
subtree = tree[root][value]
return classify(subtree, sample)
def accuracy(tree, data):
correct_count = 0
for sample in data:
if classify(tree, sample) == sample[-1]:
correct_count += 1
return correct_count / len(data)
data1 = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
data2 = [
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜']
]
attributes = [0, 1, 2, 3, 4, 5]
max_depth = 4
min_samples = 3
tree = create_tree(data1, attributes, max_depth, min_samples)
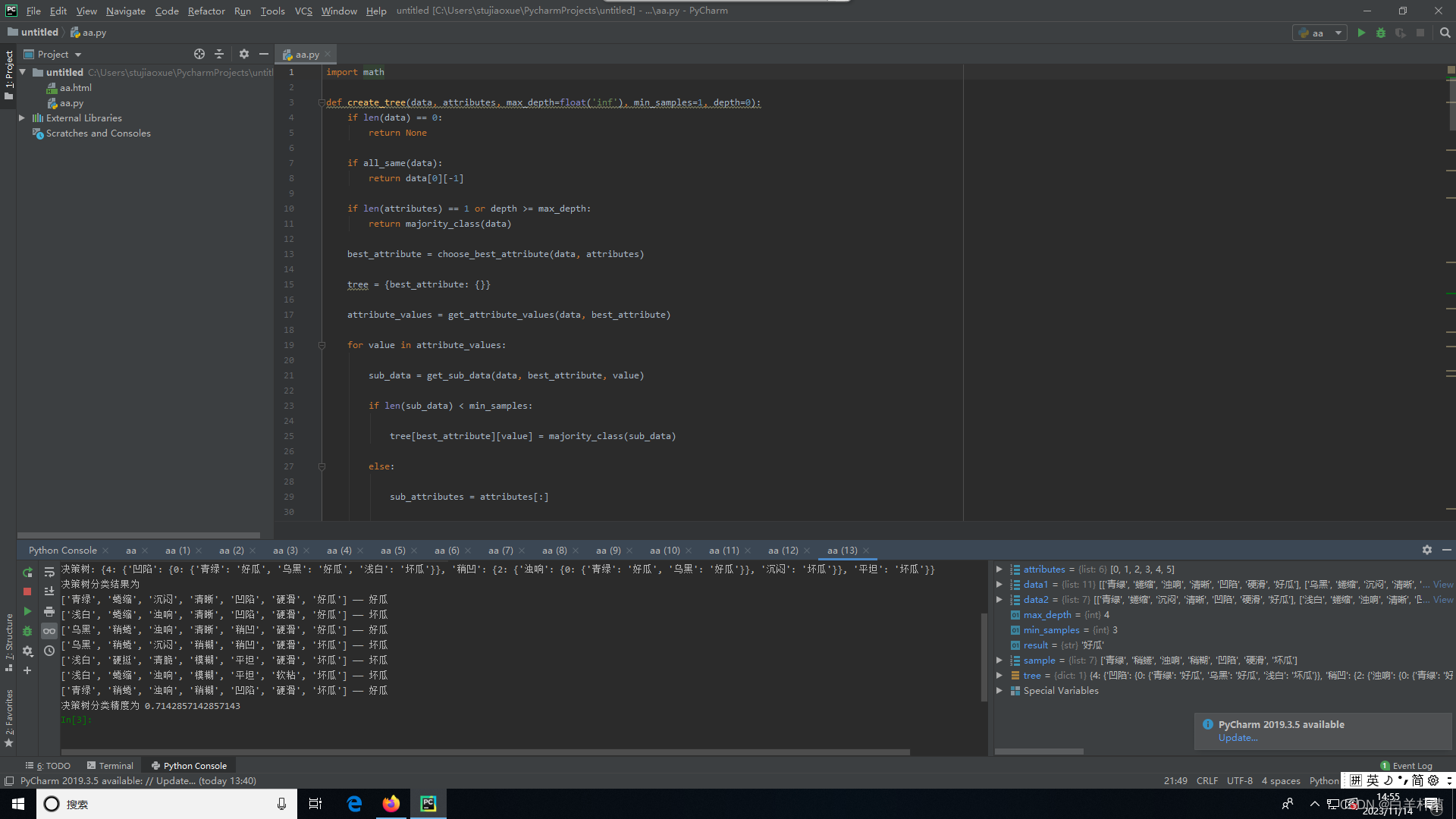
print("决策树:", tree)
print("决策树分类结果为")
for sample in data2:
result = classify(tree, sample)
print(sample, "——", result)
print("决策树分类精度为", accuracy(tree, data2))决策树: {4: {'凹陷': {0: {'青绿': '好瓜', '乌黑': '好瓜', '浅白': '坏瓜'}}, '稍凹': {2: {'浊响': {0: {'青绿': '好瓜', '乌黑': '好瓜'}}, '沉闷': '坏瓜'}}, '平坦': '坏瓜'}}
决策树分类结果为
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'] —— 好瓜
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'] —— 坏瓜
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'] —— 好瓜
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'] —— 坏瓜
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'] —— 坏瓜
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'] —— 坏瓜
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'] —— 好瓜
决策树分类精度为 0.7142857142857143















 2532
2532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









