






1画时序图
library(forecast)
library(TSA)
data(co2)
plot(co2,xlab="时间",ylab="co2",type="o",col=4)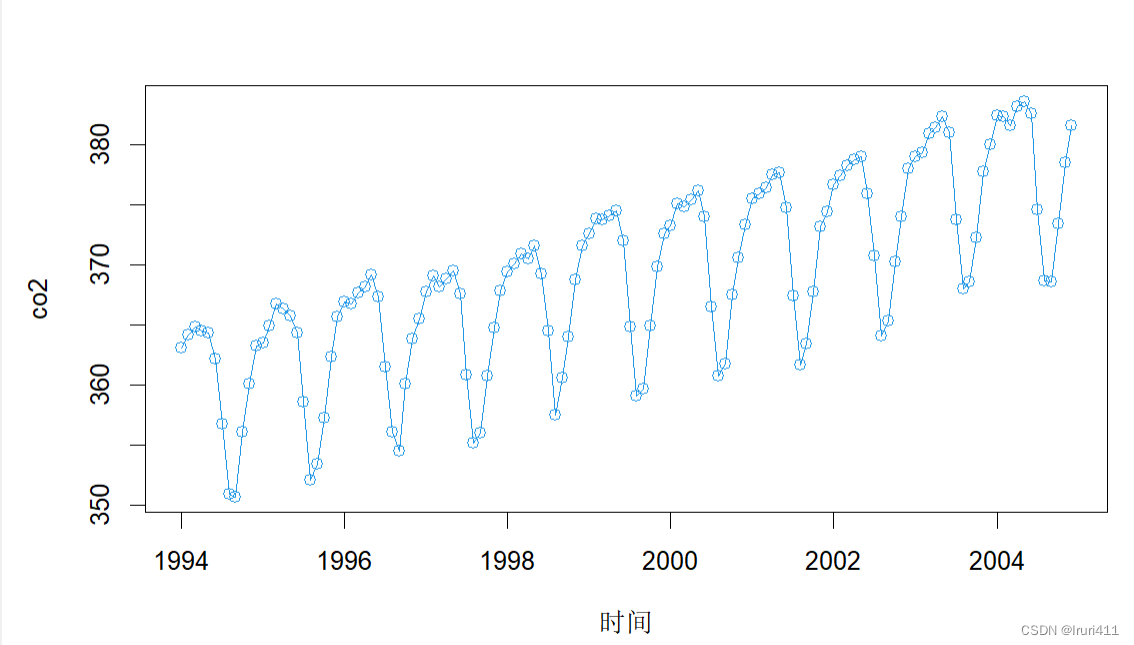
由时序图可以看出,加拿大阿勒特地区月度二氧化碳数据具有明显的趋势性和周期性,需要通过常规差分和季节差分消除趋势性和季节性。
1.1确定常规差分和季节差分的阶数
nsdiffs(co2) #确定季节性差分的阶数
ndiffs(co2) #确定常规差分的阶数结果显示,常规差分的阶数为d=1,季节差分的阶数D=1
2.单位根检验
检验差分之后序列的平稳性(ADF检验)
a=diff(diff(co2),lag=12) #差分后的数据
library(aTSA)
adf.test(a)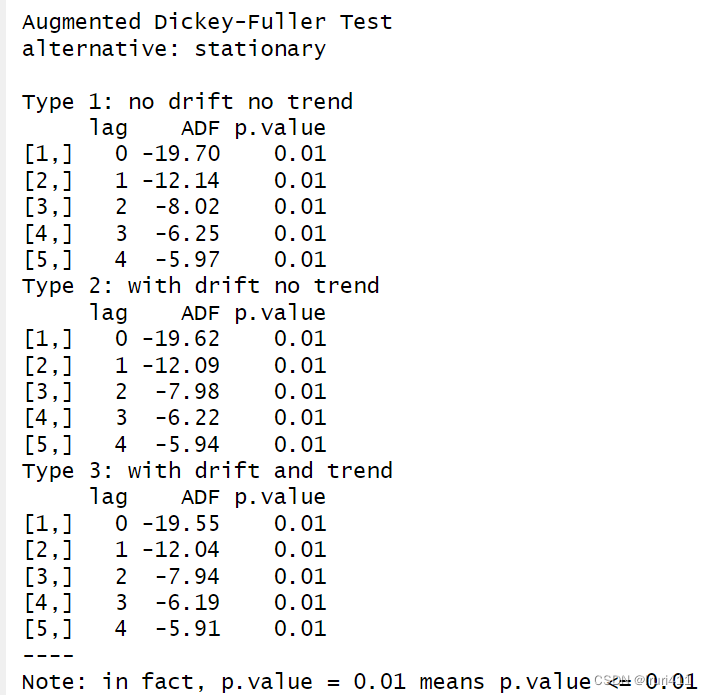
由上述结果可以看出p值均小于0.05,所以拒绝原假设,可以认为差分后的序列平稳。
3.模型拟合
自相关函数和偏自相关函数
acf(a,lag=36)
pacf(a,lag=36)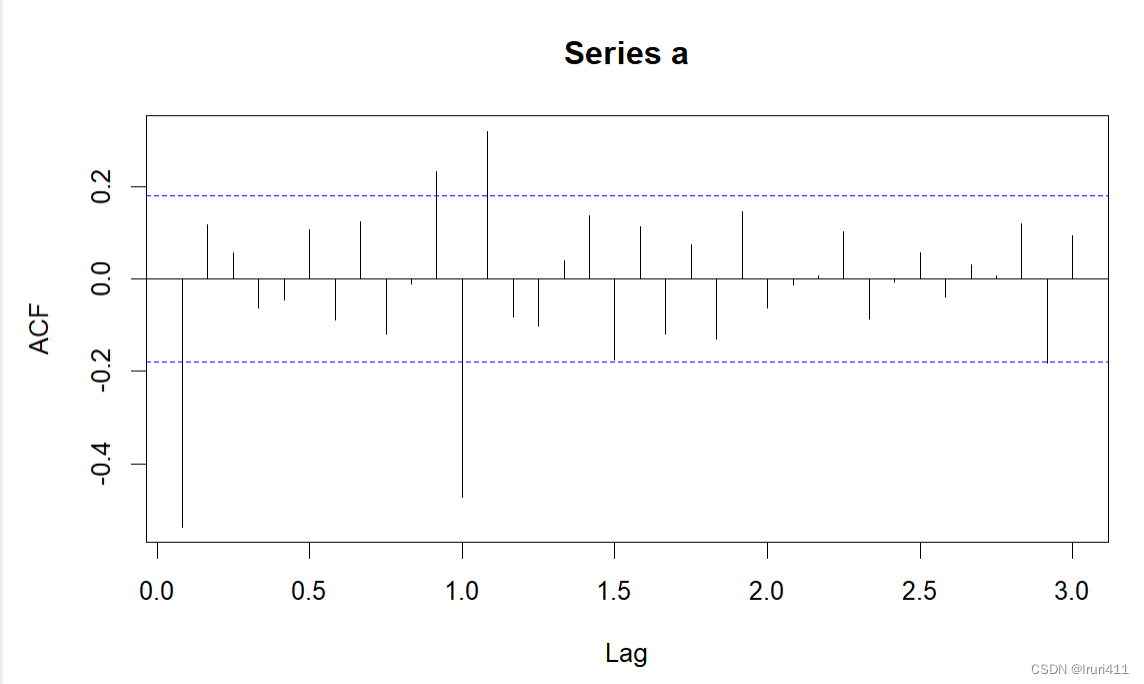
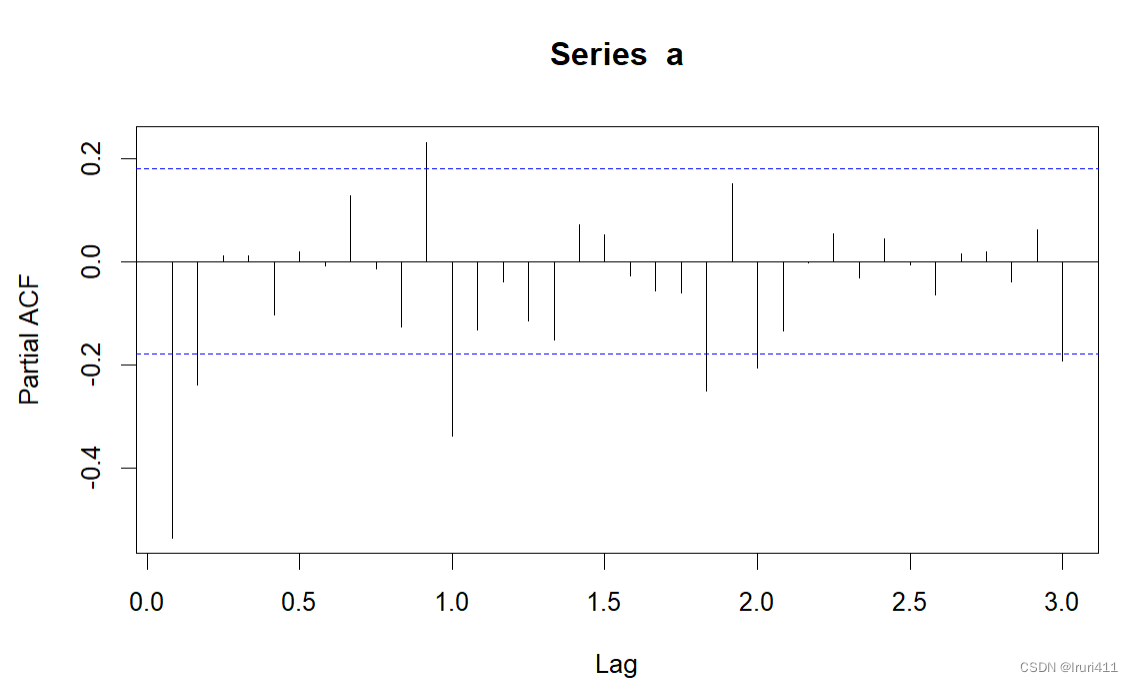
运行结果如上述所示,我们将根据差分序列12阶以内的自相关函数和偏自相关函数的特征确定短期相关模型.该图显示前12期以内的自相关函数和偏自相关函数均均不截尾,所以尝试使用ARMA(1,1)模型提取差分后序列的短期相关信息;根据延迟周期长度整数倍上的自相关函数和偏自相关函数的特征确定季节模型.该图显示,延迟12阶的自相关系数显著非零,但延迟24期和36期自相关系数落入2倍标准差之内;偏自相关函数延迟12期、24期和36期均显著非零,所以认为季节自相关函数截尾,偏自相关函数拖尾,因此考虑以12为周期的$SARMA(0,1)_{12}$提取差分后序列的季节相关信息
4.参数估计
fit1=Arima(co2,order=c(1,1,1),seasonal=list(order=c(0,1,1),period=12))
fit1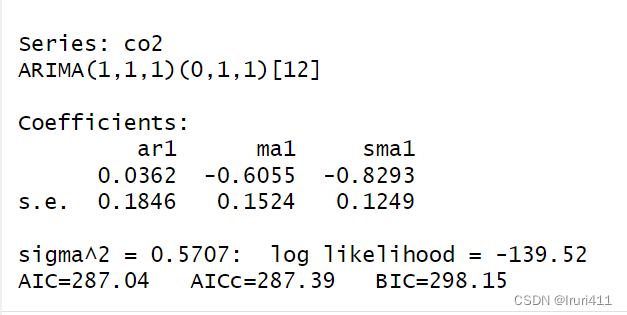
4.1参数显著性检验
t=abs(fit1$coef)/sqrt(diag(fit1$var.coef))
pt(t,length(a)-length(fit1$coef),lower.tail=F)
由结果显示Φ1Φ1对应的p值大于0.05,在0.05的显著性水平下不显著,应该予以剔除,因此我们重新拟合模型.事实上,由差分后的自相关函数只在滞后1阶和11期、12期、13期处有明显的突出,所以我们可以识别出
模型.
4.2模型修正
fit1=Arima(co2,order=c(0,1,1),seasonal=list(order=c(0,1,1),period=12))
fit1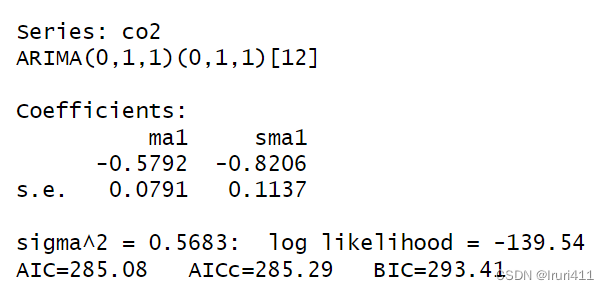
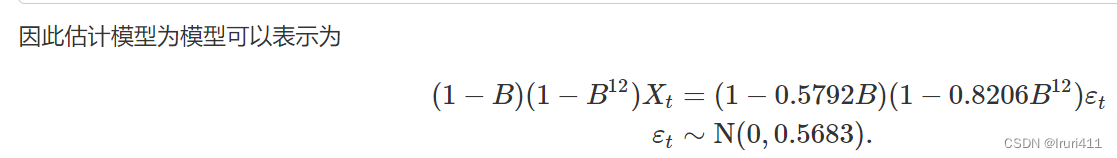
4.3修正后的模型参数显著性检验
t=abs(fit1$coef)/sqrt(diag(fit1$var.coef))
pt(t,length(a)-length(fit1$coef),lower.tail=F)两个参数上的p值均小于0.05,说明这两个参数在显著性水平α=0.05下显著.
5.残差检验
tsdiag(fit1,gof.lag=20)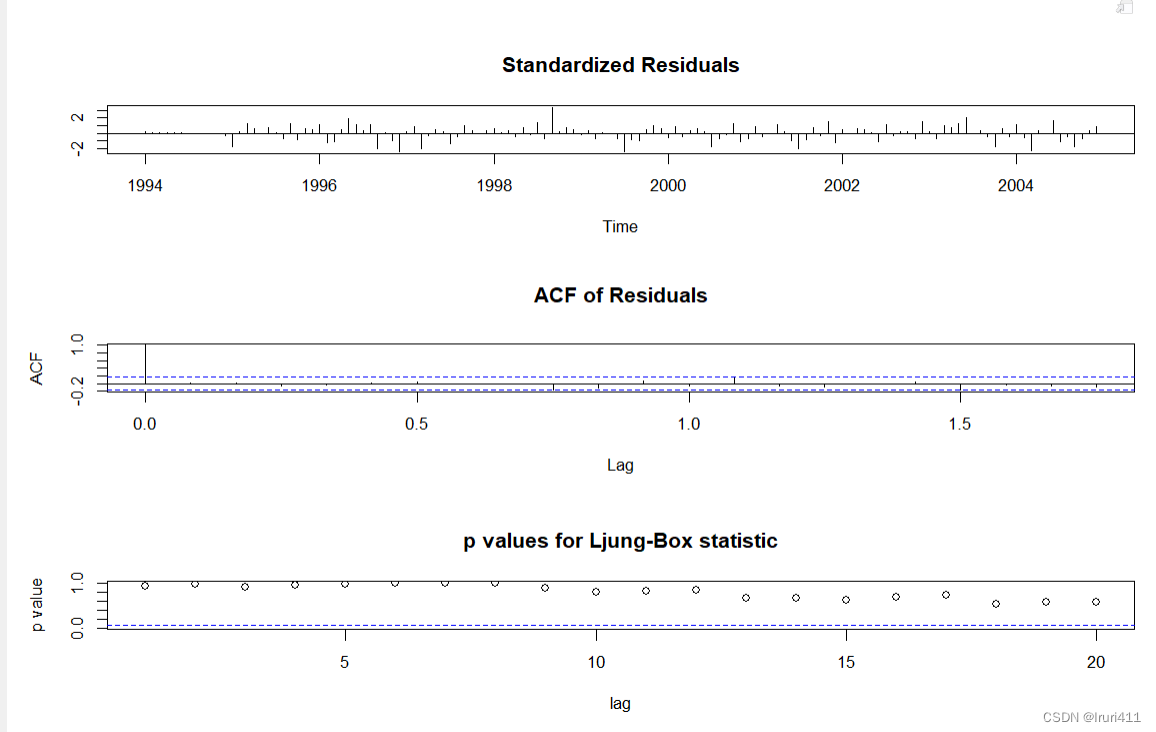
由上述结果的第二个图可以看出残差的ACF均在两倍的标准误差上下限内,同时第三个图显示不同m值对应的Ljung-Box统计量的p值均大于0.05,说明可以认为残差序列是一个白噪声序列,即模型拟合数据比较充分.
6.运用自动识别模型再次拟合模型
fit2=auto.arima(co2)
fit2
所以估计模型如下:
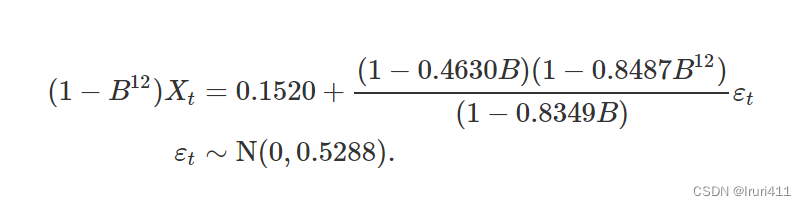
7.模型诊断
7.1参数的显著性检验
t=abs(fit2$coef)/sqrt(diag(fit2$var.coef))
pt(t,length(a)-length(fit2$coef),lower.tail=F) 结果显示,四个参数所对应的p值均小于0.05,同样可以说明这些参数在0.05显著性水平下均显著
结果显示,四个参数所对应的p值均小于0.05,同样可以说明这些参数在0.05显著性水平下均显著
7.2残差检验
library(tseries)
tsdiag(fit2,gof.lag=20)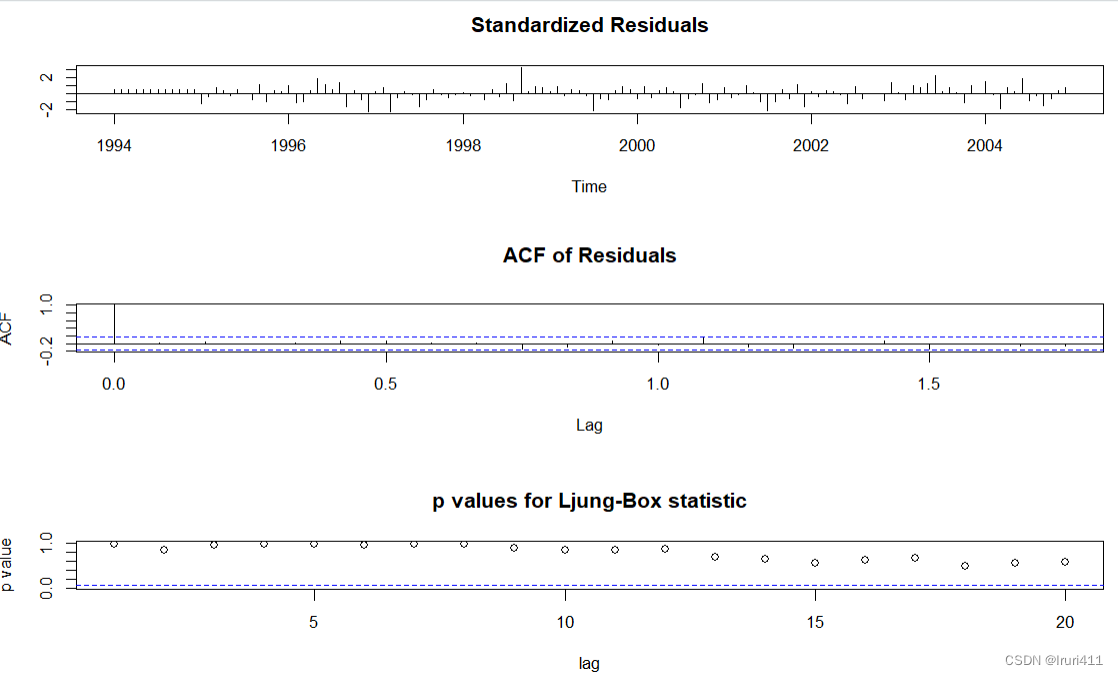
由上述结果的第二个图可以看出残差的ACF均在两倍的标准误差上下限内,同时第三个图显示不同m值对应的Ljung-Box统计量的p值均大于0.05,说明可以认为残差序列是一个白噪声序列,即模型拟合数据比较充分.
8模型优化及预测
library(forecast)
fc1=forecast::forecast(fit1,h=12,level=95)
fc2=forecast::forecast(fit2,h=12,level=95)
par(mfrow=c(2,1))
plot(fc1)
plot(fc2)
par(mfrow=c(1,1))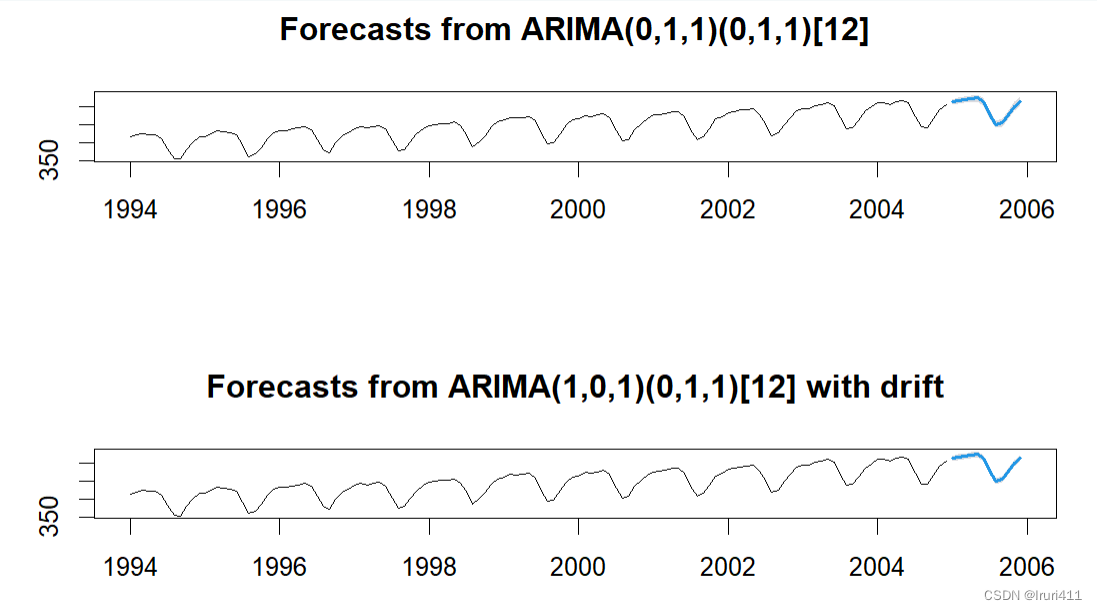















 2489
2489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









