








只有当你开始相信自己时,你才拥有真正的人生。——《洛奇》
前言:
大家好,我是爱打拳的程序猿。今天给大家展示是数据处理函数的用法,分为单行处理函数和分组函数。数据处理函数主要是为了更方便解决数据的各种问题。文章以代码和还原窗口的方式展现给大家,一起来看看吧。
目录
1、单行处理函数
数据处理函数是什么?
数据处理函数是用来更方便的计算表中某一字段数据。它分为单行处理函数和多行处理函数。单行处理函数的特点是一个输入对应一个输出。多行处理函数是多个输入对应一个输出。
1.1创建一个薪资表
首先,我们创建一个简易的薪资表,往后的所有函数也是通过这张表来讲解。
mysql> create table Pay(
-> id int,
-> name varchar(10),
-> salary decimal(10,3),
-> bonus decimal(10,3),
-> holiday int
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> insert into Pay (id,name,salary,bonus,holiday) values
-> (1001,'Bob',2345.435,800,5),
-> (1002,'Tom',3454.534,500.435,2),
-> (1003,'Mimi',5534.565,900,10),
-> (1004,'Boss',10000,888.666,20);
-> (1005,'Ggg',2454,300,null);
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from Pay;
+------+------+-----------+---------+---------+
| id | name | salary | bonus | holiday |
+------+------+-----------+---------+---------+
| 1001 | Bob | 2345.435 | 800.000 | 5 |
| 1002 | Tom | 3454.534 | 500.435 | 2 |
| 1003 | Mimi | 5534.565 | 900.000 | 10 |
| 1004 | Boss | 10000.000 | 888.666 | 20 |
| 1005 | Ggg | 2454.000 | 300.000 | NULL |
+------+------+-----------+---------+---------+
5 rows in set (0.00 sec)窗口显示:
单行处理函处理有这些:
| 函数名 | 描述 |
|---|---|
| LOWER | 转换小写 |
| UPPER | 转换大写 |
| SUBSTER | 字符串长度 |
| LENGTH | 取长度 |
| TRIM | 去空格 |
| STR_TO_DATE | 将字符串转换为日期 |
| DATE_FROMAT | 格式化日期 |
| FORMAT | 设置千分位 |
| ROUND | 四舍五入 |
| RAND() | 生成随机数 |
| IFNULL() | 可以将NULL转换成一个具体值 |
| CONCAT | 函数进行字符串的拼接 |
1.2LOWER和UPPER函数
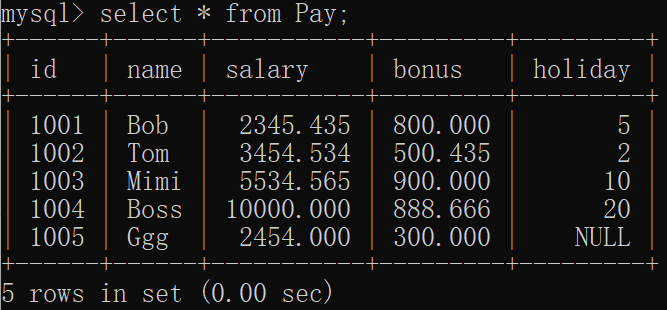
lower函数的用法就是将一串字符种的大写转换成小写,如果字符本身就是小写则不管。语法为:select lower(字段) from 表名;
我要将薪资表的name中大写都改为小写:
mysql> select lower(name) from Pay;
+-------------+
| lower(name) |
+-------------+
| bob |
| tom |
| mimi |
| boss |
| ggg |
+-------------+
5 rows in set (0.00 sec)窗口显示:
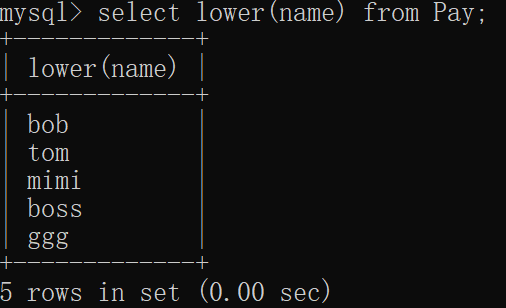
upper函数的用法就是将一串字符种的小写转换成大写,如果字符本身就是大写则不管。语法为:select upper(字段) from 表名;
我要将薪资表的name中小写都改为大写:
mysql> select upper(name) from Pay;
+-------------+
| upper(name) |
+-------------+
| BOB |
| TOM |
| MIMI |
| BOSS |
| GGG |
+-------------+
5 rows in set (0.00 sec)窗口显示:
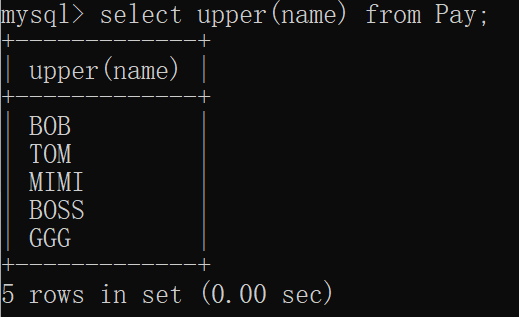
1.3SUBSTER函数
substr是截取字符串从某一下标到另一下标的字段,起始下标为1终止下标根据你的需求来定。格式为:select substr(字段,前下标,后下标) from 表名;
比如我要找到薪资表name的第一个字符,也就是员工的姓:
mysql> select substr(name,1,1) name from Pay;
+------+
| name |
+------+
| B |
| T |
| M |
| B |
| G |
+------+
5 rows in set (0.00 sec)窗口显示:
如果我们要找姓名为B的人,怎么查找呢。有两种方法:
1.使用模糊查询like
mysql> select name from Pay where name like'B%';
+------+
| name |
+------+
| Bob |
| Boss |
+------+
2 rows in set (0.00 sec)2.使用substr查询
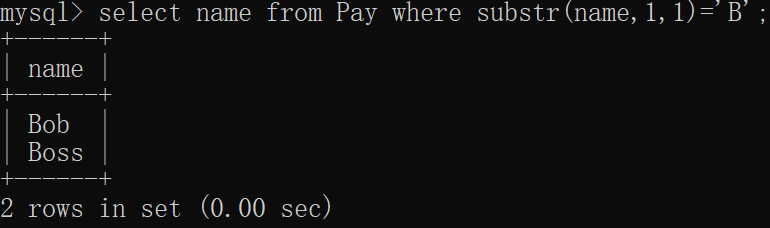
mysql> select name from Pay where substr(name,1,1)='B';
+------+
| name |
+------+
| Bob |
| Boss |
+------+
2 rows in set (0.00 sec)两种方式窗口显示都一样:
1.4LENGTH函数
length跟java的length一样都是求长度,语法为select length(字段) from 表名;
求薪资表中所有name的长度:
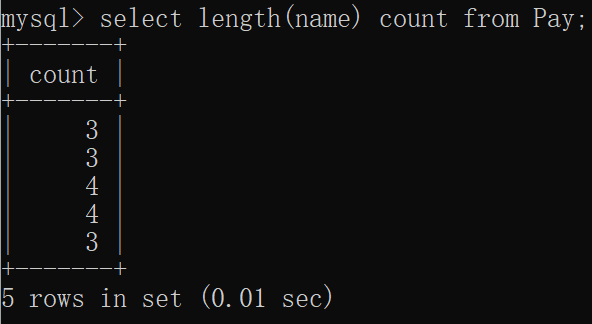
mysql> select length(name) count from Pay;
+-------+
| count |
+-------+
| 3 |
| 3 |
| 4 |
| 4 |
| 3 |
+-------+
5 rows in set (0.01 sec)窗口显示:
1.5CONCAT函数
concat函数的用法就是合并两个字符串,语法:select concat(字段1,字段2) from 表名;
将薪资表中的id和salary连接起来:
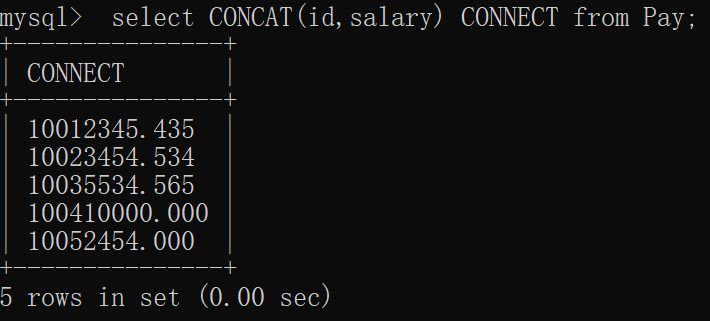
mysql> select concat(id,salary) connect from Pay;
+---------------+
| connect |
+---------------+
| 10012345.435 |
| 10023454.534 |
| 10035534.565 |
| 100410000.000 |
| 10052454.000 |
+---------------+
5 rows in set (0.00 sec)窗口显示:
1.6TRIM函数
trim是去掉一个字符串前后的括号,比如我不小心在一个字段前后打上了几个空格trim函数会自动去掉这些空格:
mysql> select * from Pay where name=trim(' Boss ');
+------+------+-----------+---------+---------+
| id | name | salary | bonus | holiday |
+------+------+-----------+---------+---------+
| 1004 | Boss | 10000.000 | 888.666 | 20 |
+------+------+-----------+---------+---------+
1 row in set (0.00 sec)窗口显示:

1.7ROUND函数
round函数是用来做四舍五入操作的,当然你可以规定保留几位小数。语法为:select 字段 round(字段,保留位数) from 表名;
比如我要使工资保留一位小数并且四舍五入:
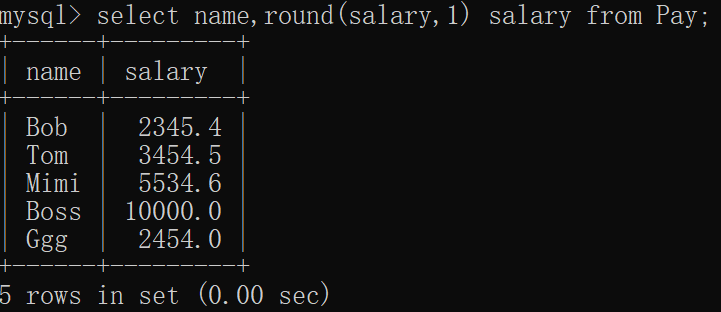
mysql> select name,round(salary,1) salary from Pay;
+------+---------+
| name | salary |
+------+---------+
| Bob | 2345.4 |
| Tom | 3454.5 |
| Mimi | 5534.6 |
| Boss | 10000.0 |
| Ggg | 2454.0 |
+------+---------+
5 rows in set (0.00 sec)窗口显示:
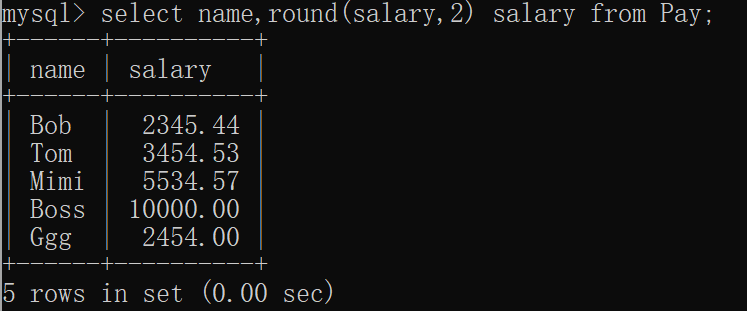
保留多位小数,他只会对最后一位小数位进行四舍五入,最后一位前的小数不进行四舍五入。如我要保留两位小数:
mysql> select name,round(salary,2) salary from Pay;
+------+----------+
| name | salary |
+------+----------+
| Bob | 2345.44 |
| Tom | 3454.53 |
| Mimi | 5534.57 |
| Boss | 10000.00 |
| Ggg | 2454.00 |
+------+----------+
5 rows in set (0.00 sec)窗口显示:
2、分组函数
分组函数/聚合函数/多行处理函数
| 函数名 | 描述 |
|---|---|
| COUNT | 计数 |
| SUM | 求和 |
| AVG | 平均值 |
| MAX | 最大值 |
| MIN | 最小值 |
分组函数在使用时必须先分组再使用,如果是对整张表使用则默认这张表为一组。多行处理函数是多个输入对应一个输出。因为分组查询比较简单,我就直接讲解语法,然后实例演示。
2.1COUNT函数
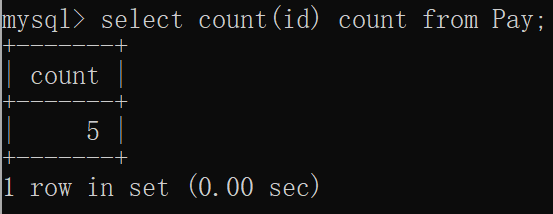
count函数是用来计数的,统计某一个字段出现的次数,语法:select count(字段) from 表名;
求薪资表中员工的个数:
mysql> select count(id) count from Pay;
+-------+
| count |
+-------+
| 5 |
+-------+
1 row in set (0.00 sec)窗口显示:
2.2SUM函数
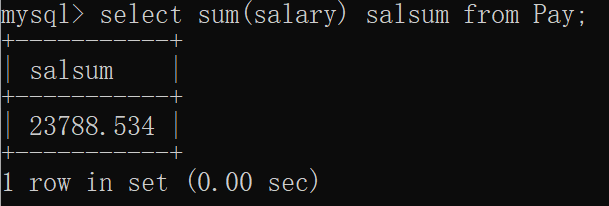
sum函数是用来求和的,计算某一字段数据的总和,语法:select sum(字段) from 表名;
求薪资表中所有员工工资总和:
mysql> select sum(salary) salsum from Pay;
+-----------+
| salsum |
+-----------+
| 23788.534 |
+-----------+
1 row in set (0.00 sec)窗口显示:
2.3AVG函数
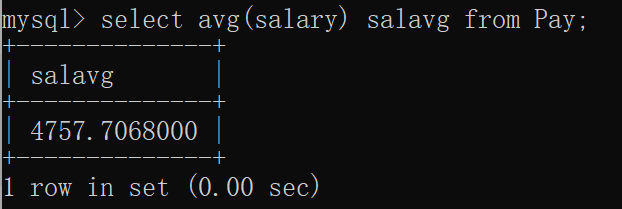
avg函数是求某一字段内数据的平均值,语法:select avg(字段) from 表名;
求薪资表中员工平均工资:
mysql> select avg(salary) salavg from Pay;
+--------------+
| salavg |
+--------------+
| 4757.7068000 |
+--------------+
1 row in set (0.00 sec)窗口显示:
2.4MAX函数
max函数是求某一字段内数据的最大值。语法:select max(字段) from 表名;
求薪资表中工资最高为多少:
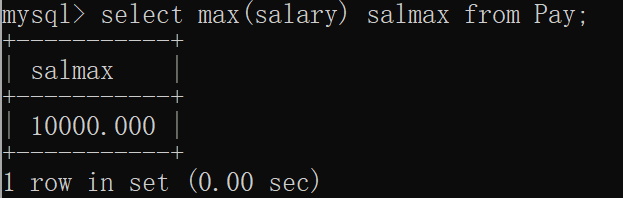
mysql> select max(salary) salmax from Pay;
+-----------+
| salmax |
+-----------+
| 10000.000 |
+-----------+
1 row in set (0.00 sec)窗口显示:
2.5MIN函数
min函数是求某一字段内数据的最小值。语法:select min(字段) from 表名;
求薪资表中工资最低为多少:
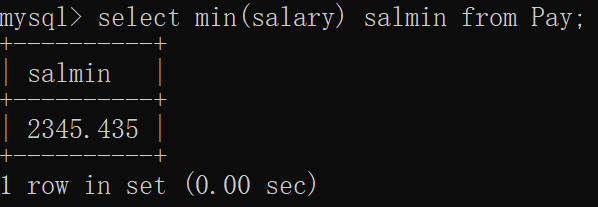
mysql> select min(salary) salmin from Pay;
+----------+
| salmin |
+----------+
| 2345.435 |
+----------+
1 row in set (0.00 sec)窗口显示:
3、分组函数注意事项
3.1注意1
在mysql数据库中,在运算时如果某一数据为NULL。则最后的结果一定是空,但在分组函数进行运算时会自动忽略NULL。
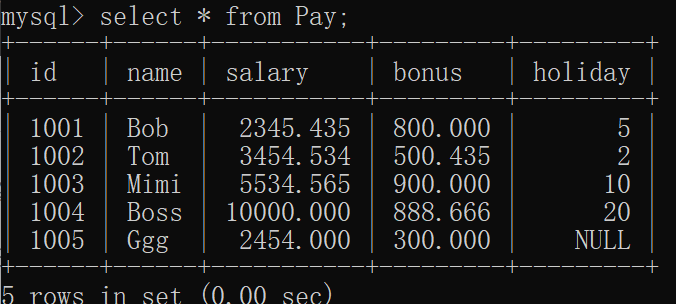
我们可以看到Pay表中假期(holiday)字段有一空,那么我对它进行求和会不会造成结果为空呢?
mysql> select sum(holiday) test from Pay;
+------+
| test |
+------+
| 37 |
+------+
1 row in set (0.00 sec)窗口显示:
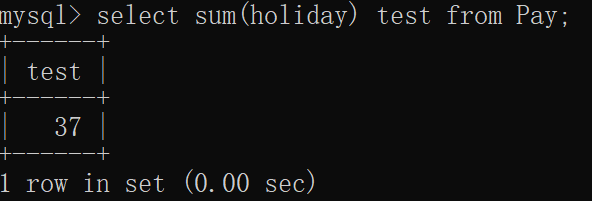
我们发现并没有结果为NULL,证实了上面那句话,分组函数运算时忽略NULL。
3.2注意2
分组函数中的count(*)和count(某字段)有什么区别?
count(*)是统计该字段所有数据的计数包括NULL,而count(字段)是统计除NULL以外数据的计数。
mysql> select count(*) from Pay;
+----------+
| count(*) |
+----------+
| 5 |
+----------+
1 row in set (0.00 sec)
mysql> select count(holiday) from Pay;
+----------------+
| count(holiday) |
+----------------+
| 4 |
+----------------+
1 row in set (0.00 sec)窗口显示:
因此,count(*)是通常是用来统计行数的,count(字段)是用来计数某一字段除NULL以外的数据。
3.3注意3
分组函数不得直接使用在where子句中!会提示使用了无效的分组函数 。
如用条件查询找工资最大值:
mysql> select name,salary salmax from Pay where salary>min(salary);
ERROR 1111 (HY000): Invalid use of group function窗口显示:

3.4注意4
分组函数可以联合使用,比如我要将员工薪资的最小值,最大值,平均值,总和,员工个数显示出来:
mysql> select min(salary) salmin,max(salary) salmax,avg(salary) salavg,sum(salary) salsum,count(*) salcou from Pay;
+----------+-----------+--------------+-----------+--------+
| salmin | salmax | salavg | salsum | salcou |
+----------+-----------+--------------+-----------+--------+
| 2345.435 | 10000.000 | 4757.7068000 | 23788.534 | 5 |
+----------+-----------+--------------+-----------+--------+
1 row in set (0.00 sec)窗口显示:

本期博客到这里就结束了,码文不易还请三连一波,感谢你的阅读。

Never Give Up















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











