






在神经网络的训练过程中,性能优化是至关重要的环节。本文将总结常用的优化技巧,包括模型初始化、数据划分、正则化方法以及优化算法等,帮助读者提升模型训练效率和性能。
一、常用技巧
1. 模型初始化
良好的初始化能够加速模型收敛并提高性能。常见的初始化方法包括:
简单初始化:权值在[-1, 1]区间内按均值或高斯分布初始化。
Xavier初始化:通过均匀分布确保每一层输出的方差尽量相等,公式如下:
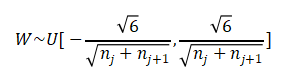
其中和
分别是当前层和下一层的神经元数量。
2. 数据划分
合理划分数据集是避免过拟合和欠拟合的关键:
训练集、验证集、测试集:通常比例为70%:15%:15%或60%:20%:20%。数据量大时可适当减少训练和验证数据的比例。
K折交叉验证:将原始训练数据分为K个子集,每次用K-1个子集训练,剩余1个子集验证,最终取K次结果的平均值。
3. 欠拟合与过拟合
欠拟合:模型在训练集和测试集上误差均较大,通常由于模型复杂度不足或训练不充分导致。
过拟合:模型在训练集上误差小,但在测试集上误差大,通常由于模型复杂度过高或训练数据不足导致。
4. 正则化方法
权重衰减(L2正则化):通过约束权值大小防止过拟合,目标函数为:
![]()
梯度下降时,权值更新公式为:
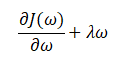
Dropout:在训练过程中随机将部分神经元置零,减少神经元间的依赖性,增强模型的泛化能力。
二、优化算法
1. 动量法
动量法通过引入速度变量,模拟物理中的动量效应,减少训练过程中的震荡,加速收敛。更新公式如下:
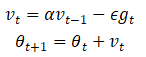
其中,为动量参数,
为学习率,
为当前梯度。
优点:能够有效穿越病态曲率区域,避免陷入局部极小值。
2. 自适应梯度算法
(1) AdaGrad
AdaGrad根据参数的历史梯度自适应调整学习率,适合稀疏数据。更新公式为:
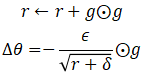
缺点:学习率单调递减,可能导致后期训练困难。
(2) RMSProp
RMSProp通过指数衰减平均解决AdaGrad学习率过度衰减的问题。更新公式为:
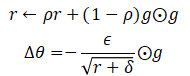
其中,ρ为衰减速率超参数。
(3) Adam
Adam结合了动量法和RMSProp的优点,通过一阶矩和二阶矩的指数衰减平均调整学习率。更新步骤如下:
1. 计算梯度g
2. 更新一阶矩估计:
![]()
3. 更新二阶矩估计:
![]()
4. 修正偏差:
![]()
5. 更新参数:
![]()
优点:适应性强,适合大多数场景。
三、总结
1. 常用技巧:合理初始化、数据划分、正则化方法(如权重衰减和Dropout)能够有效提升模型性能。
2. 优化算法:动量法加速收敛,自适应梯度算法(如AdaGrad、RMSProp、Adam)能够动态调整学习率,适应不同场景。
3. 实践建议:根据具体任务选择合适的优化方法,并结合交叉验证和正则化技术避免过拟合。
通过掌握这些优化技巧,读者可以显著提升神经网络的训练效率和模型性能。希望本文对大家有所帮助!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









