







 本文介绍了使用Python的requests和正则库爬取斗破苍穹小说前10章标题和内容的过程,包括网页元素分析,数据提取,并将结果保存至txt文件中。
本文介绍了使用Python的requests和正则库爬取斗破苍穹小说前10章标题和内容的过程,包括网页元素分析,数据提取,并将结果保存至txt文件中。
主要目标
1:利用requests库和正则库爬取斗破苍穹小说的前十章标题和内容
2:将屏幕输出结果并存入txt文件中
主要的模块:requests、time、re
思路分析:
1 首先打开需要分析得网页,查看网页元素信息,找到需要爬取得标题和内容。
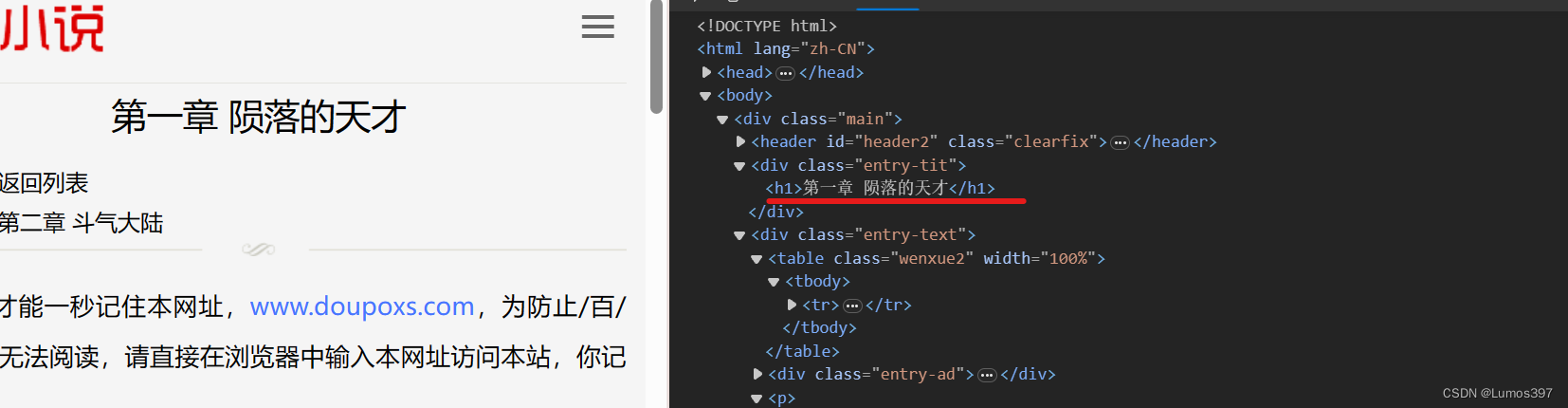
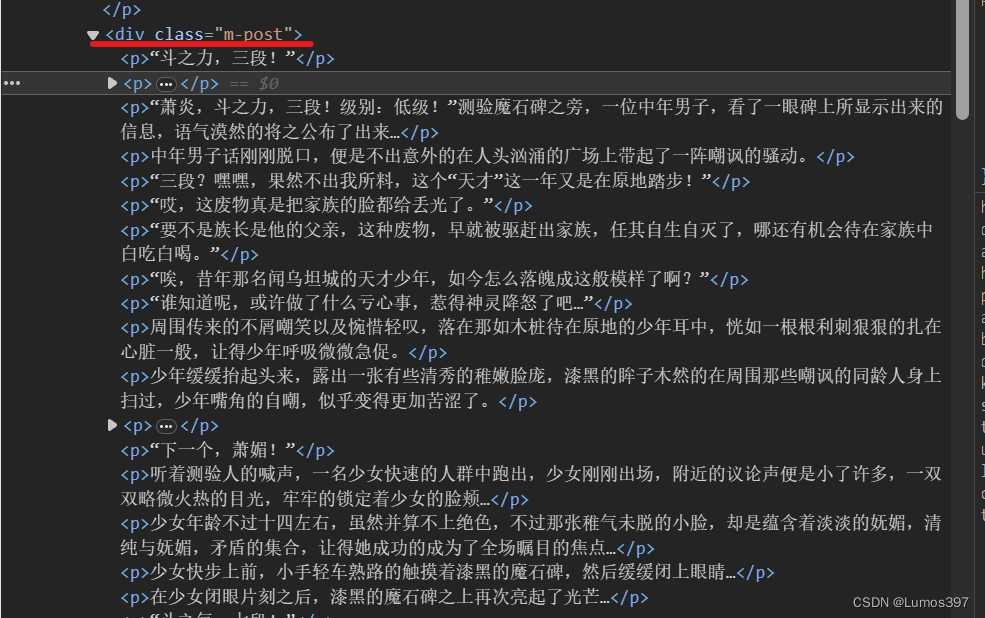
在上面网页元素中可以确定标题在<div class="entry-text">下面的h1标签里 ,正文内容在<div class="m-post">下面的所有p标签里。
# 标题
title = re.findall('<h1>(.*?)</h1>', div)[0]
print(title)
# 正文内容
div = re.findall('<div class="m-post">(.*?)</div>', res.text, re.S)[0].strip()
contents = re.findall('<p>(.*?)</p>', div, re.S)
for i in contents:
print(i)
2. 把结果输出保存到txt文本中(过程可以想象把大象装在冰箱里)
①扒开冰箱门
f = open('xiaoshuo.txt','a+',encoding='utf-8')②把大象装进去
contents = re.findall('<p>(.*?)</p>', div, re.S)
for i in contents:
print(i)
f.write(i+'\n')③关闭冰箱门
f.close()完整代码如下
import requests
import re
import time
hd = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69'
} #加入请求头
# url="http://www.doupoxs.com/doupocangqiong/1.html"
f = open('xiaoshuo.txt','a+',encoding='utf-8') # 新建文本,以追加的方式打开
def get_info(url):
res = requests.get(url, headers=hd)
res.encoding = 'utf-8' # 设置编码格式
title = re.findall('<h1>(.*?)</h1>', div)[0] #标题
print(title)
f.write(title)
div = re.findall('<div class="m-post">(.*?)</div>', res.text, re.S)[0].strip() #包含所有文本的div
contents = re.findall('<p>(.*?)</p>', div, re.S) # 包含文本的p标签
for i in contents:
print(i)
f.write(i+'\n') # 循环遍历写入
for i in range(1, 11):
url = 'https://www.doupoxs.com/doupocangqiong/{}.html'.format(i) #构造多页url
get_info(url) # 调用函数
time.sleep(1)
print("爬取完毕!")
f.close()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









