







这里的相关性分析主要是线性相关性分析,当然其他的形状的相关性分析可以通过变换转换为线性相关性分析。但是,线性相关性分析始终是相关性分析的基础。线性相关分析的构建主要分为以下几种:
直接绘制散点图
通过把点标出来主观上看是否是线性相关。
绘制散点图矩阵
绘制散点图矩阵是直接绘制散点图的一种,适用于多元线性回归的描述。如果用直接绘制散点图的方法,将每次取多个元中的两个进行绘画,但是这样很没有逻辑。所以我们可以将这n个元的具体情况用柱状图表示出来,放在正方形的对角线上,这样每一个变量与每一个变量之间都绘制了一个散点图,做到了不重复不遗漏。

计算相关系数
之前的两种方法偏向于定性分析,如果要定量分析,那么就要使用相关系数。在二元变量的相关分析中,比较常用的Pearson相关系数、Spearman秩相关系数、判定系数。
Pearson相关系数
适用条件:分析两个连续性变量的相关关系(不太理解为什么说Pearson线性相关系数要求连续变量的取值服从正态分布)
公式:

判断条件:(其本身的条件决定r的取值为[-1,1])
是正相关还是负相关:看r的正负,如果是正则是正相关,如果是负则是负相关
判断线性关系的强弱:
看r的绝对值:
绝对值=0:不存在线性关系
绝对值<=0.3:极弱线性相关或不存在线性相关
0.3<绝对值<=0.8:低度线性相关
0.5<绝对值<=0.8:显著线性相关
绝对值>0.8:高度线性相关
绝对值=1:完全线性相关
Spearman秩相关系数
适用条件:不服从正态分布的变量、分类或等级变量之间的关联性分析可以使用Spearman秩相关系数,注意是可以使用,说明正太分布的也可以用Spearman秩相关系数。
公式:(Spearman秩相关系数是统计学的知识,需要对二元的数据的两种数据进行排序,用标号对每个排序数据进行标记,然后对同一个事物的两种排序的标号之差进行运算)
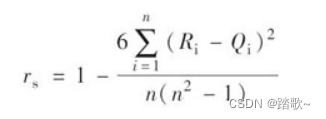
对两个变量成对的取值分别按照从小到大(或者从大到大小)顺序编秩,R i 代表x i 的秩次,Q i 代表y i 的秩次,R i -Q i 为x i 、y i 的秩次之差。
(举个例子)
来自于b站:
 https://www.bilibili.com/video/BV1oE411G7Za/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd
https://www.bilibili.com/video/BV1oE411G7Za/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd
判断Spearman相关的强弱:

对于两个相关系数的建立,都要经过假设检验,一般使用t检验方法进行假设检验。研究表明,在正态分布的假定下,Spearman秩相关系数与Pearson相关系数在效率上是等价的,而对于连续测量数据,更适合于Pearson相关系数来分析。
判定系数
判定系数是相关系数的平方,用来衡量回归方程对y的解释程度。
代码实现:以上两种相关系数都可以通过corr()函数实现,具体的形式如下。
具体代码如下:
# 代码3-9 餐饮销量数据相关性分析
# 餐饮销量数据相关性分析
from __future__ import print_function
import pandas as pd
catering_sale = 'D:\DataMiningCode\chapter3\demo\data\catering_sale_all.xls' # 餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = '日期') # 读取数据,指定“日期”列为索引列
print(data.corr()) # 相关系数矩阵,即给出了任意两款菜式之间的相关系数,这里的corr方法是默认首先使用Pearson相关系数
print(data.corr()['百合酱蒸凤爪']) # 只显示“百合酱蒸凤爪”与其他菜式的相关系数
print(data['百合酱蒸凤爪'].corr(data['翡翠蒸香茜饺']))# 计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数运行结果如下:
















 17万+
17万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











