






数据预处理的主要内容包括数据清洗、数据集成、数据变换和数据规约。
一、数据清洗
数据清洗主要进行删除一些数据,处理一些异常数据等到工作。主要分为缺失值处理和异常值处理两种。
(1)缺失值处理
缺失值处理的方法可以分为三类:删除记录、不处理、数据插补三中。其中删除记录和不处理两种技术含量较低,下面主要介绍一下数据插补的一些方法。
插补方法1:用一大坨数据的均值或中位数或众数进行缺失值的插补。
插补方法2:使用固定的一个值进行插补。
插补方法3:用这个缺失的值最近的那个值进行插补。
插补方法4:回归方法。用不缺的数据建立回归模型进行预测这个值是什么。
插补方法5:插值法。也是相当于建立一个函数进行缺失值的预测。就是利用已知点建立合适的插值函数,未知值由对应点求出的函数值近似代替。
以下主要介绍两种插值法。拉格朗日插值法和牛顿插值法。两者都关系是拉格朗日插值法是一种比较基础的插值法,平常使用的时候SciPy库中的拉格朗日函数即可。而牛顿插值法比较好运算,但是代码实现的话还是要自己编写。


以下是具体的代码实现:###################################################
我遇到的问题:
不了解pandas库中的notnull'函数
不了解list函数的具体用法
解决办法:
具体代码展现:
import pandas as pd # 导入数据分析库Pandas
from scipy.interpolate import lagrange # 导入拉格朗日插值函数
inputfile = 'D:\DataMiningCode\chapter4\demo\data\catering_sale.xls' # 销量数据路径
outputfile = 'D:\DataMiningCode\chapter4\demo\tmp\sales.xls' # 输出数据路径
data = pd.read_excel(inputfile) # 读入数据,并用data标记已读的数据
data['销量'][(data['销量'] < 400) | (data['销量'] > 5000)] = None # 过滤异常值,将其变为空值
#竖线表示或,data['销量']表示访问销量这一列,后面的是数据的筛选条件,把这些异常值的属性设置为None
#我不太懂啊,这个代码段是啥意思啊!
# 自定义列向量插值函数
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] # 取数
y = y[y.notnull()] # 剔除空值
return lagrange(y.index, list(y))(n) # 插值并返回插值结果
# 逐个元素判断是否需要插值
for i in data.columns:#遍历每一列
for j in range(len(data)):#求文件的长度如何求?
if (data[i].isnull())[j]: # 如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile) # 输出结果,写入文件(代码)
(2)异常值处理
异常值的处理可以分为以下几种:
直接删除含有异常值的记录
将异常值视为缺失值,按照缺失值的处理办法处理
用这个异常值前后两个观测值的平均值修正该异常值
不处理
二、数据集成
数据集成的意思就是将多个数据源合并存放在一个一致的数据存储位置。主要分为实体识别、冗余属性识别、数据变换、属性构造小波变换等步骤。
(1)实体识别
所谓实体识别就是将电脑中的名称与它在现实生活中的实体相对应。通常在数据集成的过程中常出现以下三种问题:同名异义、异名同义、单位不同意。
(2)冗余属性识别
在数据集成的过程中,肯定会出现数据中表示相同意义的数据。这样同种实体的数据被存储了多次,占用了太多的空间。
对于冗余属性识别可以使用相关分析检测。根据数据集的属性值,利用相关系数度量一个属性多大程度上蕴含另一个属性。
(3)数据变换
可以这样理解数据变换,一大坨数据好比一大坨衣服,我们要把它们都叠规整之后才能把它们放入衣柜。这样叠规整的过程就是数据变换,它将凌乱的衣服造型整理为规整的一个个小方块。以下主要介绍集中数据变换的方法。
a、简单函数变换
简单函数变换的目的一般是将不具有正态分布的数据变换成具有正态分布的数据。对于时间序列分析这类特殊的问题来说,有时简单的对数变换或者差分运算就可以将非平稳序列转换成平稳序列。再如,对一个很大的区间,对这个区间进行对数化就可以对整个区间进行压缩。
常见的简单函数有以下几个:
平方、开方、取对数、差分运算
其中差分运算是时间序列分析当中的知识,目前这里的差分运算是一阶差分运算。具体的差分运算请见b站视频:
 https://www.bilibili.com/video/BV1jD4y1B7ew/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd
https://www.bilibili.com/video/BV1jD4y1B7ew/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd规范化的主要是把大范围的数据集转换成小范围的数据集,干的是把数据集区域缩小的事情。就是将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。下面主要介绍三种规范化方法:
1、最小-最大规范化方法(离差标准化方法)
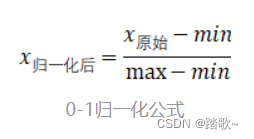
2、零-均值规范化方法
经过这种处理的数据均值为0,标准差为1。

3、小数定标规范化方法

进行这种规范化后,所有的数落到[-1,1]这个区间内。
(代码)
c、连续属性离散化
连续属性离散化方法主要是为了让数据能够服务于一些需要自变量以离散型出现的算法。例如ID3算法、Apriori算法等。
离散化的过程可以分为两步:在数据的取值范围内设定若干个离散的划分点,将所有的区间值通过离散化的办法映射到这些分类值中。
常用的离散化办法有三种:
1、等宽法
直接将自变量轴分为几个等宽的区间,划分点可以设置为等宽区间的左点。
2、等频法
将出现频率相同的记录放入每个区间,区间代表的划分点可以自己定。
3、基于聚类分析的办法
一般使用一维聚类办法:首先用聚类算法进行聚类,得到一个个簇之后将一个簇中的属性值进行同一个标号。这个簇的个数一般需要人为指定。
(代码)
(4)属性构造
为了更好的贴近数据挖掘的目的,有时候我们会通过已有的属性构造一个新的属性,从而使这个新的属性更加适合挖掘目的。
(代码)
(5)小波变换
小波变换是一种是近些年来一种新的数据分析工具。它是主要用于信号处理、图像处理、语音处理、模式识别、量子物理等领域。它提供了一种从粗到细的视角维度,这种视角在小波变换过程中叫做小波信号特征。通常我们想要得到的结论隐藏在众多视角当中的一个,因此选取合适的视角非常重要。以下将从应用步骤介绍小波变换。
1、基于小波变换的特征提取方法
主要有四种:(了解)基于小波变换的多尺度空间能量分布特征提取方法、基于小波变换的多尺度空间中模极大值特征提取方法、基于小波包变换的特征提取方法、基于适应性小波神经网络的特征提取方法。
2、设定小波基函数
(图片)
3、对小波函数进行小波变换
小波变换包括伸缩和平移。这两种变换可以用一种公式来统一。这里涉及到傅里叶变换的相关知识。
(图片)
4、基于小波变换的多尺度空间能量分布特征提取方法
对于一个信号,我们可以将这个信号分为一个大的近似信号和一大坨细节信号。依据这两种信号,我们可以构造这个信号的特征向量。这个特征向量能够有近似信号的特征和一切特征信号的特征。这就完成了从一个具体的信号到一个抽象的向量。对于一大坨细节信号,我们可以用层来对它们分类。
(代码)
三、数据归约
数据归约是在尽量保持数据原貌的特征下,尽可能的精简数据量(完成该任务的必要前提是理解挖掘任务和熟悉数据本身内容)。
主要分为属性归约和数值归约。
(一)属性归约
属性归约可以通过合并创建新属性、删除与挖掘无关的属性的方法来进行。主要的属性归约方法有以下五种。
合并属性:将旧属性合并为新属性
(例子)
逐步向前选择:先选一类最优的,再选一个次优的,再选一个次次优的……直到无法选出最优的或满足一定阈值约束等
(例子)
逐步向后删除:一开始面对所有的属性,删除一个最差的,再删除一个次差的,再删除一个次次差的……直到无法选出最差属性或满足一定阈值约束。
决策树归纳:利用决策树的归纳方法对初始数据进行分类归纳学习,从而获得一个初始决策树。没有出现在决策树上的数据就被删除。值只考虑出现在决策树上的数据。
主成分分析:主成分分析(Principal Component Analysis,PCA), 是一种统计方法。通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。主成分分析主要实现了一个数据降维的效果,其通过数据坐标系的转换、数据的拉伸变换等方式实现了数据的降维。
简单来说,在一大坨数据中找到一些数,使其他数的属性能够用这些数来表示,有点类似于线性代数中找基底的意思。
从数学的角度可以参考以下b站视频:
 https://www.bilibili.com/video/BV1E5411E71z/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd
https://www.bilibili.com/video/BV1E5411E71z/?spm_id_from=333.337.search-card.all.click&vd_source=a50afd4fb17bb7c0aa0f024bc613a5bd在python中,主成分分析的函数位于scikit-learn库下,其使用格式如下:
sklearn.decomposition.PCA(n_components=None,copy=True,whiten=False)
n_components表示进行降维后想要保持的特征个数,也是想要的主成分个数;如果令n_components='mle',则自动选取特征个数n,使满足所求的方差百分比。
copy表示是否先将训练数据复制一份再进行运算。
whiten表示白化,是每个特征具有相同的方差,默认为False。
(二)数值归约
数值归约可以分为有参数方法的数值归约和无参数方法的数值归约两种。有参数方法的数值归约就是回归分析,利用最小二乘法拟合出最优的曲线。无参数方法的数值归约其实就是整理数据,把一大坨数据归成几类罢了。
无参数的数值归约主要有直方图、聚类、抽样。
有参数的数值归约就是回归分析。
直方图:用于数值归约的直方图的每个柱所对应的取值区间可以自行改变,但要包括样本的所有值的取值区间。
聚类:通过特定的聚类方法,把所有的数字样本按照聚类方法给分好类,形成一个个簇。
抽样:抽样最常用来估计聚集查询结果。通常的抽样方法有无放回的简单抽样、有放回的简单抽样、聚类抽样、分层抽样。
参数回归:可以参考数据模拟与决策当中的线性回归,由线性回归进行变换的多种回归方法。值得注意的是,对数化的回归方式可以将大化小,经常用作于维归纳和数据光滑。















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











