






重点题目:Leetcode 144,94,145
重点记忆的我觉得只有以下10个代码:
1.递归3个
2.代码随想录前序遍历,后序遍历(这两个一样),中序和统一迭代//用于和层序遍历比较
这个代码没有想象的复杂,值得记一下。
3.黑马程序员前序遍历,中序遍历(这两个一样),后序和统一迭代//这个似乎更好理解
一、递归三部曲(代码随想录)
List: 代表一个有序的集合,它可以包含重复的元素。例如,ArrayList和LinkedList都实现了List接口。Deque(Double Ended Queue): 代表一个双端队列,允许我们在队列的两端进行元素的添加和移除。LinkedList同样实现了Deque接口。ArrayList不是Deque的实现类。
这里帮助大家确定下来递归算法的三个要素。每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法!
-
确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
-
确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
-
确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
代码随想录提供的代码:
// 前序遍历·递归·LC144_二叉树的前序遍历
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<Integer>();
preorder(root, result);
return result;
}
public void preorder(TreeNode root, List<Integer> result) {
if (root == null) {
return;
}
result.add(root.val);
preorder(root.left, result);
preorder(root.right, result);
}
}
// 中序遍历·递归·LC94_二叉树的中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
inorder(root, res);
return res;
}
void inorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
inorder(root.left, list);
list.add(root.val); // 注意这一句
inorder(root.right, list);
}
}
// 后序遍历·递归·LC145_二叉树的后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root, res);
return res;
}
void postorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val); // 注意这一句
}
}
二、递归法前中后序遍历:
在写代码之前,有几个好的视频可以看一下。
1.黑马程序员P147画图可以看一看。
2.虽然记录数据有先后,但是遍历走过的路径都是一样的(在迭代法中会更好的用到这句话)
1.前序遍历
public class Blog {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
preOrder(root,ans);
return ans;
}
private void preOrder(TreeNode root,List<Integer> ans){
if(root==null){
return;
}
ans.add(root.val);
preOrder(root.left,ans);
preOrder(root.right,ans);
}
}2.中序遍历
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
preOrder(root,ans);
return ans;
}
private void preOrder(TreeNode root,List<Integer> ans){
if(root==null){
return;
}
preOrder(root.left,ans);
ans.add(root.val);
preOrder(root.right,ans);
}
}3.后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
preOrder(root,ans);
return ans;
}
private void preOrder(TreeNode root,List<Integer> ans){
if(root==null){
return;
}
preOrder(root.left,ans);
preOrder(root.right,ans);
ans.add(root.val);
}
}前中后序遍历迭代法
1.前序遍历
思路:
前序遍历顺序:中左右,入栈顺序中右左,出栈顺序中左右
1.一个整数列表用于存放结果
2.节点为空返回空列表
3.用双端对列模拟栈用于遍历节点
4.总体思路是,首先押入根节点,然后弹出一个节点就押入它的右左节点,这样每次先弹出自己,然后弹出左,左节点弹出完了,栈不为空然后依次弹出右节点。
public class Blog {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();//一个整数列表存放结果
if(root==null){
return ans;//是一个空列表但不是null
}
Deque<TreeNode> stack = new ArrayDeque<>();//一个双端对列模拟栈存放节点用于遍历
stack.push(root);
while(!stack.isEmpty()){
TreeNode pop = stack.pop();//当队列使用时用poll,当栈使用时用pop,使代码可观
ans.add(pop.val); //pop写成tempNode可能会好理解一些
if(pop.right!=null){
stack.push(pop.right);//栈先进后出
}
if(pop.left!=null){
stack.push(pop.left);
}
}
return ans;
}
}2.后序遍历
后序遍历顺序:左右中,入栈顺序:中左右,出栈顺序中右左,最后反转顺序。
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
while (!stack.isEmpty()){
TreeNode pop = stack.pop();
ans.add(pop.val);
if(pop.left!=null){
stack.push(pop.left);
}
if(pop.right!=null){
stack.push(pop.right);
}
}
Collections.reverse(ans);
return ans;
}
}3.由中序遍历推出统一迭代
代码随想录和黑马给出了两种解法,核心思想就是让中间节点待在栈里不被一开始弹出
1.代码随想录:用空节点标记
思路是遇到空节点才彻底弹出。第一次经过一个节点时,不能直接弹出它本身,因为中序遍历要先弹出它的左节点,这时候就应该先弹出然后在压入右节点之后再将其本身再次压入,然后压入左节点,第二次经过的时候再彻底弹出。(模拟一下树)直到找到最左边的节点的操作是,弹出最左节点再压入其本身再压入dummy。然后发现是dummy。这意味着找到了最左边的点,意味着所有该弹出的节点已经被dummy标记。
否则就是先弹出再在压入右左节点后重新压入并压入空节点做标记。在左子树遇到右边孩子为空的节点在算法里的处理方式为先弹出再压入再压入空节点。
ChatGPT:这个算法的关键是利用栈的特性,以及用 null 作为标记。当你首次访问一个节点时,它的孩子节点会被推入栈,然后该节点自己再次被推入栈,但这次是带有 null 标记的,这样当你再次遇到这个节点时,你知道它是你已经遍历过的,接下来应该处理它(加入到结果链表中)。(ChatGPT真强啊)
重新用标号理一下思路:
1.建立一个链表储存答案
2.判断根节点是否为空
3.建立一个双端对列用于模拟栈对节点进行遍历
4.定义一个dummy节点,放在第一次经过的节点之后(如果是stack可以直接压入null)。用于判断该节点是不是被处理过了。
5.循环条件是栈是否为空,这意味着是不是所有的节点都被处理了。
6.看一下栈最上面的节点是否为dummy,并将其弹出。
7.如果不是说明是第一次遍历,则按照相应的遍历顺序将其压回,由以下三部分构成:1.left是否为null2.right是否为null3.本身和一个dummy。根据需要调整顺序。
8.当是dummy的时候才要处理当前节点,在这个else里写上处理节点的代码
中序遍历:
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode dummy= new TreeNode(-1);
stack.push(root);
while (!stack.isEmpty()){
TreeNode peek = stack.peek();
if(peek!=dummy){ //Arraydeque里不能push null;
stack.pop();
if(peek.right!=null){
stack.push(peek.right);
}
stack.push(peek);
stack.push(dummy);
if (peek.left!=null){
stack.push(peek.left);
}
}else {
stack.pop();
peek = stack.pop();//或许用cur更容易理解,这里就是省事用了一下。可以写成两句peek = stack.peek();stack.pop();
ans.add(peek.val);
}
}
return ans;
}
}还可以将代码简化
思路是:先弹出来看看是不是dummy(标记),不是的话说明是第一次遍历,再把它压回去。是的话说明接着弹出它的下一个实体节点
中序遍历:
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode dummy= new TreeNode(-1);
stack.push(root);
while (!stack.isEmpty()){
TreeNode peek = stack.peek();
stack.pop();
if(peek!=dummy){ //ArrayDeque里不能push null;
if(peek.right!=null){
stack.push(peek.right);
}
stack.push(peek);
stack.push(dummy);
if (peek.left!=null){
stack.push(peek.left);
}
}else {
peek = stack.peek();
stack.pop();
ans.add(peek.val);
}
}
return ans;
}
}根据中序遍历的代码,推导出前序遍历和后续遍历的代码以及统一代码。
前序遍历代码,把那中间两行放在后面。代码运行的时候是每次都能先遇到标记所以会把中节点打出来,然后左节点作为下一个中节点也被打出来。一直打完最后一个左节点开始打右节点。
前序遍历:(这样写好像空间复杂度更好)
public class Leetcode144suixianglu {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
TreeNode dummy = new TreeNode(-1);
while (!stack.isEmpty()){
TreeNode peek = stack.peek();
stack.pop();//把栈顶的数弹出来看一下是不是要处理的数
if(peek!= dummy){
if(peek.right!=null){
stack.push(peek.right);
}
if (peek.left!=null){
stack.push(peek.left);
}
stack.push(peek);
stack.push(dummy);//如果不是dummy说明现在不要处理这个数,和dummy一起压进去
}else {
peek = stack.peek();//如果是,现在栈顶的元素需要被处理,处理即可然后将其弹出(注意此时dummy已经被弹出了)
stack.pop();
ans.add(peek.val);
}
}
return ans;
}
}前序遍历一些书写上的小改动算是自己玩一下吧,以后也按照这个写了。(空间复杂度好像很差)又提交了一次,不差。。。
lass Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
stack.push(root);
TreeNode dummy = new TreeNode(-1);
while (!stack.isEmpty()){
TreeNode pop = stack.pop();
if(pop!= dummy){
if(pop.right!=null){
stack.push(pop.right);
}
if (pop.left!=null){
stack.push(pop.left);
}
stack.push(pop); //如果不是dummy,就说明现在不要处理这个数,和dummy一起压进去
stack.push(dummy);
}else {
pop = stack.pop();//如果是dummy,就再弹出来一个(要处理的节点本身)
ans.add(pop.val);
}
}
return ans;
}
}后序遍历
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode dummy = new TreeNode(-1);
stack.push(root);
while (!stack.isEmpty()){
TreeNode peek = stack.peek();
stack.pop();
if(peek!=dummy){
stack.push(peek);
stack.push(dummy);
if(peek.right!=null){
stack.push(peek.right);
}
if (peek.left!=null){
stack.push(peek.left);
}
}else{
peek=stack.peek();
stack.pop();
ans.add(peek.val);
}
}
return ans;
}
}那么把这些代码融合在一起
自己总结出来的通用代码,有点成就感:
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode dummy= new TreeNode(-1);
stack.push(root);
while (!stack.isEmpty()){
TreeNode peek = stack.peek();
stack.pop();
if(peek!=dummy){ //Arraydeque里不能push null;
stack.push(peek);//后序遍历
stack.push(dummy);//后序遍历
if(peek.right!=null){
stack.push(peek.right);
}
stack.push(peek);//中序遍历(先pop出来然后右边节点压进去但是不压dummy,中间节点压进去的时候却压了dummy,再压入左节点,然后从左节点开始经历相同的过程)
stack.push(dummy);//中序遍历
if (peek.left!=null){
stack.push(peek.left);
}
stack.push(peek);//前序遍历
stack.push(dummy);//前序遍历
}else {
peek = stack.peek();
stack.pop();
ans.add(peek.val);
}
}
return ans;
}
}又提交了一次没有区别,还是用这个,思路就是if里是入栈,else里是出栈。
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> ans = new ArrayList<>();
if(root==null){
return ans;
}
Deque<TreeNode> stack = new ArrayDeque<>();
TreeNode dummy= new TreeNode(-1);
stack.push(root);
while (!stack.isEmpty()){
TreeNode pop = stack.pop();
if(pop!=dummy){ //Arraydeque里不能push null;
stack.push(pop);//后序遍历
stack.push(dummy);//后序遍历
if(pop.right!=null){
stack.push(pop.right);
}
stack.push(pop);//中序遍历
stack.push(dummy);//中序遍历
if (pop.left!=null){
stack.push(pop.left);
}
stack.push(pop);//前序遍历
stack.push(dummy);//前序遍历
}else {
pop = stack.pop();
ans.add(pop.val);
}
}
return ans;
}
}然后再看看黑马程序员的代码,好像理解起来更为简单。
public class Leetcode144heima {
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Deque<TreeNode> stack = new LinkedList<>();
TreeNode cur = root;
while (cur != null || !stack.isEmpty()){//防止左边走到头为null了却不进入循环;而在pop出root节点的时候(中序遍历)则又通过cur != null进入循环
if (cur != null){
//result.add(cur.val);前序遍历
stack.push(cur);//为了记住回来的路
cur = cur.left;
}else{
TreeNode pop = stack.pop();
result.add(pop.val);//中序遍历
cur = pop.right;
}
}
return result;
}
}对于后序遍历先看一个例子,以后就用这个推
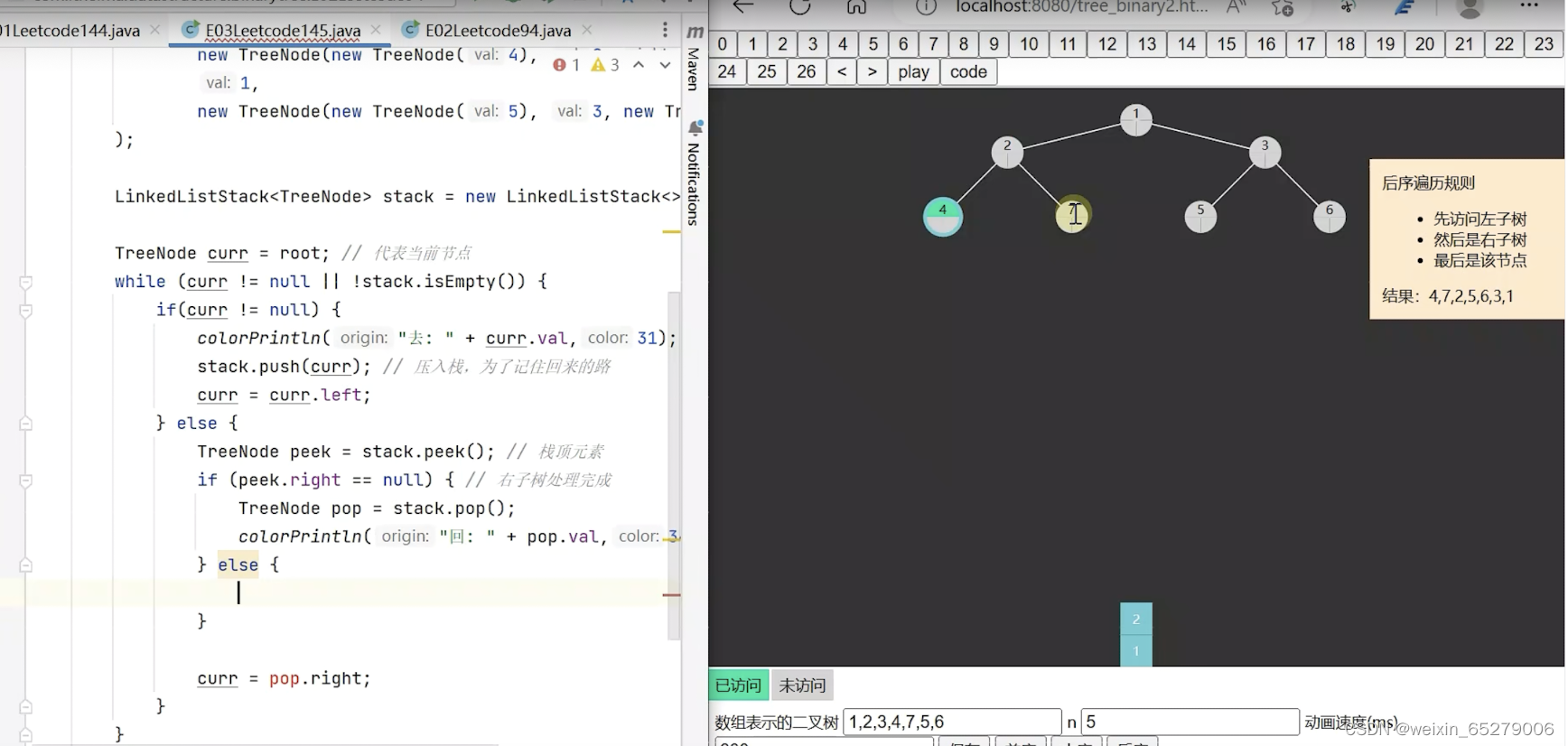
在这个例子之前,对于中序遍历的叙述和我自己想的一样,可以看下面这张图。就是2这个节点已经被POP出去了所以右子树不用入栈,处理完右子树直接就继续处理1就可以了。
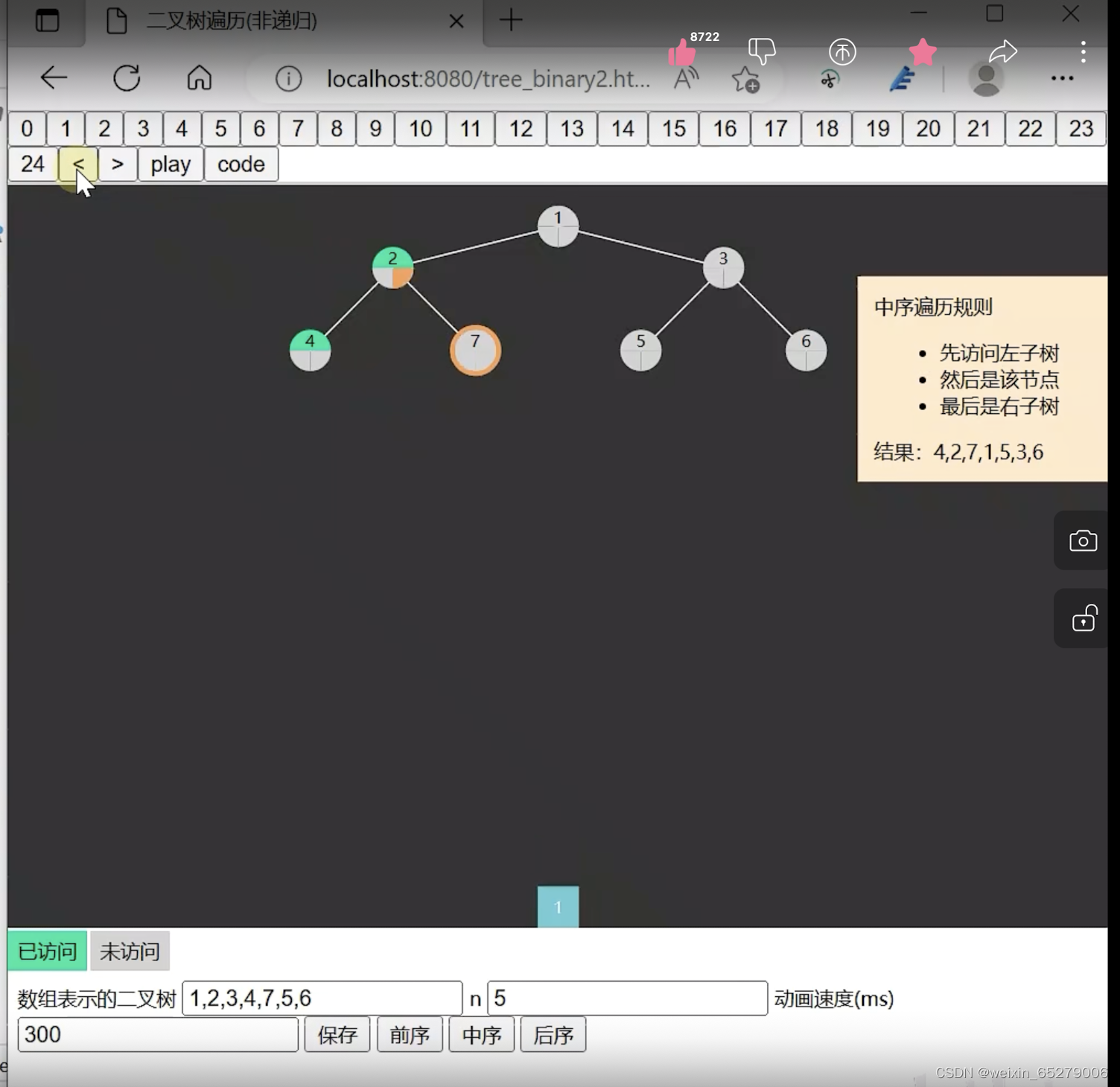
所以与中序遍历不一样的是,后序遍历需要判断一个节点的左右子树是不是都处理完了。
关键之处就在于右子树的代码部分。前面说了前序中序遍历之所以不用右子树入栈,就是因为右子树处理完就相当于一个节点全部处理完了。而本来根结底和左子树就应该在右子树前面处理。所以前面pop就pop就好了。但是到了后序遍历,就不能这样随意pop了。要判断右子树是不是处理过了。那么既看到栈顶元素,又暂时不会弹出的代码就是peek了。其实走到else这一步左子树都已经处理完成了,要判断的就是右子树。
1.此时就要加入一个pop来记录下右子树,以便于判断右子树是不是处理过了。
不能用cur来代替pop,因为cur是null的时候才会去一直处理右子树。(推导一下就知道了)
2.后序遍历右子树是有压栈操作的,只不过压进去就弹出来了。
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Deque<TreeNode> stack = new LinkedList<>();
TreeNode cur = root;
TreeNode pop=null;//最近一次弹栈元素
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
cur = cur.left;
}else{
TreeNode peek = stack.peek();//对栈顶元素进行检查,右子树处理完成了执行if,未完成让cur过去进行处理。
if(peek.right==null||peek.right==pop){//该节点的右孩子为null或者右孩子为上一次弹出的值。进行这一步说明右子树处理完成了
pop = stack.pop();//pop相对于判断而言就是上一次弹出的值
result.add(pop.val);
}else{//这里就是既不是null也不是pop的情况,然后来处理这个节点
cur = peek.right;//发现这个节点右子树还没有处理,cur便走到右子树去处理它,cur不能像之前一样等于cur.right。
}
}
}
return result;
}
}统一迭代以后序遍历为模版,前序中序遍历因为处理右子节点之前弹走了值,所以其实少走了几步路。后序遍历走的是最全的。
由于中序遍历的缘故,后序遍历的代码要拆开:
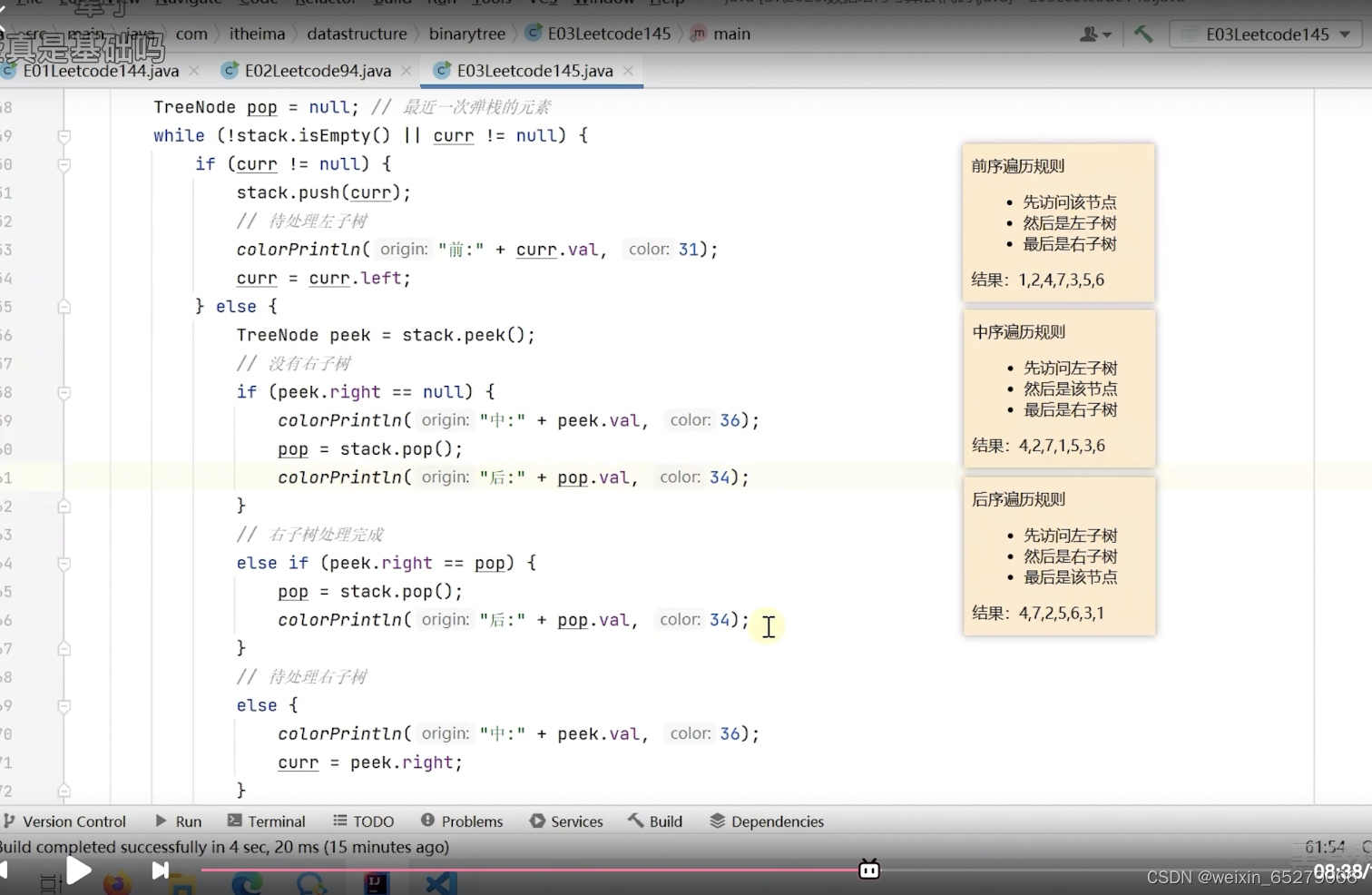
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<>();
if (root == null){
return result;
}
Deque<TreeNode> stack = new LinkedList<>();
TreeNode cur = root;
TreeNode pop=null;//最近一次弹栈元素
while (cur != null || !stack.isEmpty()){
if (cur != null){
stack.push(cur);
//result.add(cur.val);//前序遍历
//待处理左子树
cur = cur.left;
}else{
TreeNode peek = stack.peek();//对栈顶元素进行检查,右子树处理完成了执行if,未完成让cur过去进行处理。
if(peek.right==null){//该节点的右孩子为null或者右孩子为上一次弹出的值。进行这一步说明右子树处理完成了
//result.add(peek.val);//中序遍历
pop = stack.pop();
result.add(pop.val);//后序遍历
} else if (peek.right==pop) {
pop = stack.pop();
result.add(pop.val);//后序遍历
}
//待处理右子树
else{
//result.add(peek.val);//中序遍历,这种情况就是peek.right既不是null也不是pop,就是要在还不是pop的这个时候就把值给记录下来。
cur = peek.right;//发现这个节点右子树还没有处理,cur便走到右子树去处理它,cur不能像之前一样等于cur.right。
}
}
}
return result;
}
}但其实会发现这个代码里的一个可以说是漏洞,让人不好理解。就是队友右子节点是null的情况下,中序遍历和后序遍历写成一样的就可以,先POP后add和先add后pop其实没有差别。因为右孩子为空的时候,对于后序遍历和中序遍历都可以直接处理本节点。
对于中序遍历可以这样理解,当中序遍历发现右边节点pop了之后,说明这个节点本身已经在之前就记录过了,那么直接pop掉就好不用进行任何操作。
那么在中序遍历中,节点本身,比如2是什么时候被pop和记录的呢。当然是在else里,意味着右节点不是null,右节点也没有被处理过,要在左节点被处理了,右节点被处理之前就处理它。自然是在else里。
中序遍历和后序遍历的区别就在于:
在意味着右节点没有处理过的else里记录就是中序遍历。在意味着右节点已经处理过了的else-if里记录就是后序遍历















 818
818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









