






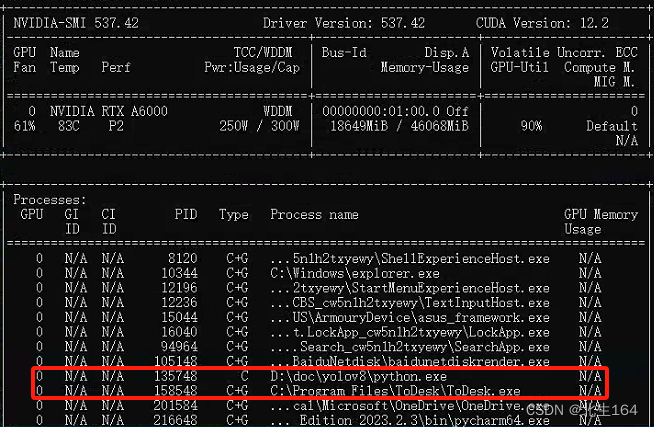
在使用nvidia-smi工具监控NVIDIA GPU状态时,我们可能会看到当前运行的进程使用的GPU类型被标记为'C'、'G'或'C+G'三种状态。这些状态表示进程使用GPU的不同方式:
-
C (Compute):C状态表示进程主要使用GPU的计算能力(CUDA核心)。表示进程正在进行计算密集型任务,如深度学习训练、科学计算等。
-
G (Graphics):G状态表示进程主要使用GPU的图形渲染能力。这在进行图形渲染、视频游戏或任何需要GPU加速的图形界面渲染任务时很常见。
-
C+G (Compute + Graphics):这个标记表示进程同时使用GPU的计算和图形渲染能力。在某些深度学习应用中,比如使用GPU进行数据可视化或者同时运行计算和图形渲染任务的情况下,可能拥有C+G状态。这意味着GPU被综合利用,既参与计算任务也参与图形渲染任务。
通常,深度学习和其他科学计算任务主要使用'C'状态,因为这些任务通常重计算而轻渲染。然而,在开发和测试阶段,或者在某些特殊的应用场景中,可能会看到'G'或'C+G'状态,尤其是在需要图形输出(例如,使用GPU加速的可视化工具)时。了解这些状态可以帮助我们更好地监控和优化GPU资源的使用。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









