






爬取国家科技图书文献中心的论文信息 ,并存储到Excel中。(全部源码在最后展示)
以爬取 ‘2022年’ ‘中国科学院大学’ 的论文信息为例(也可不设置筛选条件)

筛选后进入详情页进行观察,所要的数据的在哪个包中(是在HTML还是在josn中)
找到数据后,不难发现每篇论文的数据包是通过id号来唯一标识的。找到了一个存储此页面内所有论文id的数据包
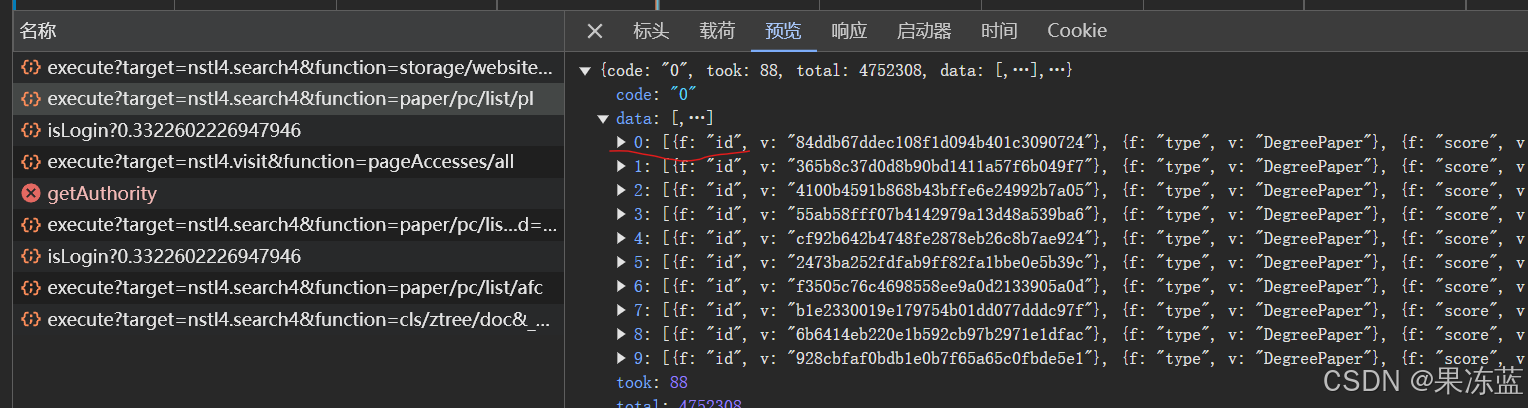
开始爬取每篇论文的id号
获取到id号即可以对所对应的id论文进行访问,例如:https://www.nstl.gov.cn/paper_detail.html?id=84ddb67ddec108f1d094b401c3090724
以上的网址就可以通过链接直接在浏览器中访问到论文,即获取到id号后通过改变id即可访问到不同的论文(对此链接称为:论文访问链接)
#对存在id号的数据包发送请求
def spider(pagenum):
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/list/pl'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
}
data = {
'query': '{"c":10,"st":"0","f":[],"p":"","q":[{"k":"uni_s","a":1,"o":"","f":1,"v":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"k":"yea","a":1,"o":"","f":1,"v":"2022"}],"op":"AND","s":["nstl","haveAbsAuK:desc","yea:desc","score"],"t":["DegreePaper"]}',
'webDisplayId': '11',
'sl': '1',
'searchWordId': 'e380808e48fd873dd19c006d7a8501a3',
'searchId': 'ca4b4bb73d24187981ce7e06b18a472d',
'facetRelation': '[{"id":"a7e9bfe0358d69e152389c5c412eecc3","sequence":3,"field":"uni_s","name":"\u9662\u6821","value":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"id":"c5612153a3c2a990483a48e5573f2c6e","sequence":2,"field":"yea","name":"\u5E74\u4EFD","value":"2022"}]',
'pageSize': '10',
#对于pageNumber的参数没有给定是因为后面要执行翻页爬取。(此参数可以标识页面数)
'pageNumber': f'{pagenum}'
}
response = requests.post(url,headers=headers,data = data).json()
#将数据包的数据信息传递给数据处理函数(parse_response)
parse_response(response)
#因为此网站有反爬机制,频繁的访问会被禁止访问,需要有时间间隔
time.sleep(5)
#获取到数据包的信息后对数据包的信息进行id号的提取
def parse_response(response):
data_list = response['data']
for i in data_list:
id = i[0]['v']
id_url(id)
time.sleep(5)
拿到id数据后,对论文的详情页数据进行抓取
在浏览器中访问到论文的详情页,在浏览器中检查所需的数据的在哪个包中,找到数据包后拿到数据包的链接对数据包进行请求。(id号会传递给data中来标识请求哪个论文的数据包)
def id_url(id):
#此链接是论文的数据包的链接而不是文论的访问链接
#论文访问链接是在浏览器进行直接的访问,浏览器会将各数据包中的数据渲染后呈现出来
#所以发送请求时,要对数据包进行请求,再到数据包中去提取数据
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/detail'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'https://www.nstl.gov.cn',
'Pragma': 'no-cache',
'Referer': 'https://www.nstl.gov.cn/paper_detail.html?id=49eca30cf784e72e5dd259fc789bc898',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
data = {
#从parse_response函数中传递来的id号
#通过id的改变的访问不同的论文
'id': f'{id}',
'webDisplayId': '1001',
'searchWordId': '5aaae7f21e66d420b6ca2aef49221ed4',
'searchId': '6be74044bf3ec7d5fba04edb1639e3d8',
'searchSequence': '1'
}
response = requests.post(url,headers=headers,data=data).json()
#将论文的数据包的数据传递给数据处理函数(info_collect)
info_collect(response)
拿到论文的信息包后,将对论文的信息进行提取
例如提取以下信息:【论文的标题,作者:机构:院校:专业:学位:授予机构:导师:语种:提交日期:论文答辩日期:分类号:关键词:摘要:】
每条信息的提取都要对照着浏览器中的预览进行处理,对照着数据的结构提取数据(此过程没有标准,只能根据提取数据的数据结构进行书写代码)
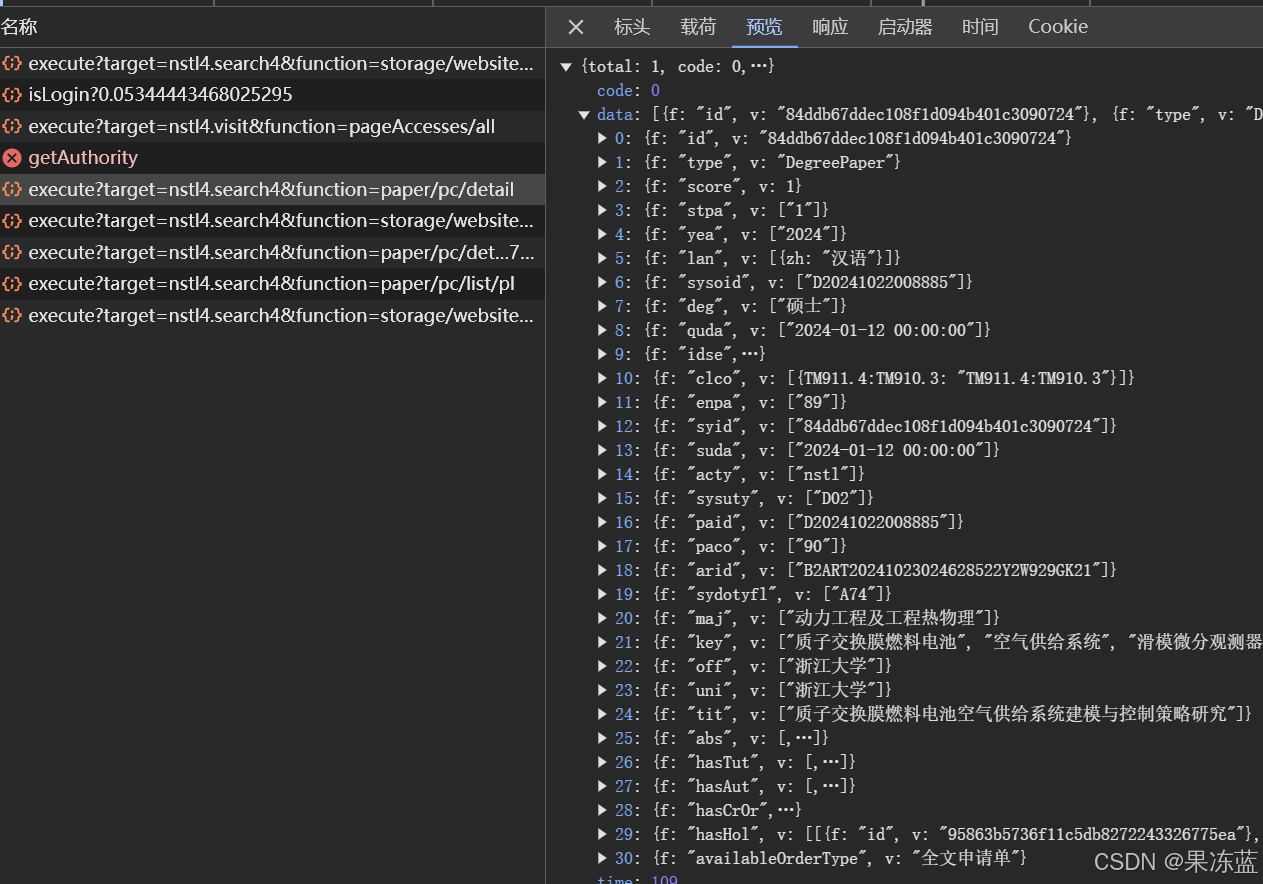
对数据进行提取
# 论文的标题,作者:机构:院校:专业:学位:授予机构:导师:语种:提交日期:分类号:关键词:摘要:
# 限定为 中国科学院大学
def info_collect(response):
#论文标题
title = None
#作者
zz_name = None
#机构
jg_name = None
#院校
yx_name = None
#专业
zy_name = None
#学位
xw = None
#授予机构
syjg_name = None
#提交日期
tjrq = None
#关键字
key = None
#摘要
zy = None
#导师
ds = None
#语种 使用list类型是基于数据包中的数据结构
yz_list =[]
#分类号
flh_list = []
data = response['data']
for i in data:
value_list = list(i.values())
if 'hasAut' in value_list:
zz_name=value_list[1][0][-1]['v']
zz_name=''.join(zz_name)
elif 'off' in value_list:
jg_name = value_list[1]
jg_name =''.join(jg_name)
syjg_name =jg_name
elif 'uni' in value_list:
yx_name=value_list[1]
yx_name=''.join(yx_name)
elif 'maj' in value_list:
zy_name = value_list[1]
zy_name =''.join(zy_name)
elif 'dag' in value_list:
xw = value_list[1]
xw =''.join(xw)
elif 'lan' in value_list:
data_list =value_list[1]
for i in data_list:
yz= list(i.values())
yz=''.join(yz)
yz_list.append(yz)
elif 'clco' in value_list:
data_list = value_list[1]
for i in data_list:
flh = list(i.values())
flh =''.join(flh)
flh_list.append(flh)
elif 'suda' in value_list:
tjrq = value_list[1]
tjrq = ''.join(tjrq).split(' ')[0]
elif 'hasTut' in value_list:
data_list = value_list[1][0]
for i in data_list:
ds_list = list(i.values())
if 'nam' in ds_list:
ds = ds_list[1]
ds = ''.join(ds)
elif 'key' in value_list:
key_list = value_list[1]
key = '|'.join(key_list)
elif 'tit' in value_list:
title = value_list[1]
title = ''.join(title)
elif 'abs' in value_list:
zy = value_list[1]
zy = ''.join(zy).replace(' ','').replace('\n','')
以上是对单页的论文进行提取,要想实现翻页的效果通过一下代码实现
def all_spider():
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/list/pl'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
}
data = {
'query': '{"c":10,"st":"0","f":[],"p":"","q":[{"k":"uni_s","a":1,"o":"","f":1,"v":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"k":"yea","a":1,"o":"","f":1,"v":"2022"}],"op":"AND","s":["nstl","haveAbsAuK:desc","yea:desc","score"],"t":["DegreePaper"]}',
'webDisplayId': '11',
'sl': '1',
'searchWordId': 'e380808e48fd873dd19c006d7a8501a3',
'searchId': 'ca4b4bb73d24187981ce7e06b18a472d',
'facetRelation': '[{"id":"a7e9bfe0358d69e152389c5c412eecc3","sequence":3,"field":"uni_s","name":"\u9662\u6821","value":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"id":"c5612153a3c2a990483a48e5573f2c6e","sequence":2,"field":"yea","name":"\u5E74\u4EFD","value":"2022"}]',
'pageSize': '10',
'pageNumber': '1'
}
response = requests.post(url, headers=headers, data=data).json()
num = int(response['total'])
pagenum = math.ceil(num/10)
for i in range(1,pagenum+1):
spider(i)
time.sleep(5)
#因为数据量较多,通过一下代码只爬取两页数据(可以不执行)
if i ==2:
print('已经访问了2页文件')
break
源代码实现
import requests
import time
import math
import os
def all_spider():
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/list/pl'
headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control': 'no-cache',
# 'Connection': 'keep-alive',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
# 'Origin': 'https://www.nstl.gov.cn',
# 'Pragma': 'no-cache',
# 'Referer': 'https://www.nstl.gov.cn/resources_search.html?t=DegreePaper',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
# 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
# 'sec-ch-ua-mobile': '?0',
# 'sec-ch-ua-platform': '"Windows"',
}
data = {
'query': '{"c":10,"st":"0","f":[],"p":"","q":[{"k":"uni_s","a":1,"o":"","f":1,"v":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"k":"yea","a":1,"o":"","f":1,"v":"2022"}],"op":"AND","s":["nstl","haveAbsAuK:desc","yea:desc","score"],"t":["DegreePaper"]}',
'webDisplayId': '11',
'sl': '1',
'searchWordId': 'e380808e48fd873dd19c006d7a8501a3',
'searchId': 'ca4b4bb73d24187981ce7e06b18a472d',
'facetRelation': '[{"id":"a7e9bfe0358d69e152389c5c412eecc3","sequence":3,"field":"uni_s","name":"\u9662\u6821","value":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"id":"c5612153a3c2a990483a48e5573f2c6e","sequence":2,"field":"yea","name":"\u5E74\u4EFD","value":"2022"}]',
'pageSize': '10',
'pageNumber': '1'
}
response = requests.post(url, headers=headers, data=data).json()
num = int(response['total'])
pagenum = math.ceil(num/10)
for i in range(1,pagenum+1):
spider(i)
time.sleep(5)
if i ==2:
print('已经访问了2页文件')
break
def spider(pagenum):
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/list/pl'
headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control': 'no-cache',
# 'Connection': 'keep-alive',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
# 'Origin': 'https://www.nstl.gov.cn',
# 'Pragma': 'no-cache',
# 'Referer': 'https://www.nstl.gov.cn/resources_search.html?t=DegreePaper',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
# 'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
# 'sec-ch-ua-mobile': '?0',
# 'sec-ch-ua-platform': '"Windows"',
}
data = {
'query': '{"c":10,"st":"0","f":[],"p":"","q":[{"k":"uni_s","a":1,"o":"","f":1,"v":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"k":"yea","a":1,"o":"","f":1,"v":"2022"}],"op":"AND","s":["nstl","haveAbsAuK:desc","yea:desc","score"],"t":["DegreePaper"]}',
'webDisplayId': '11',
'sl': '1',
'searchWordId': 'e380808e48fd873dd19c006d7a8501a3',
'searchId': 'ca4b4bb73d24187981ce7e06b18a472d',
'facetRelation': '[{"id":"a7e9bfe0358d69e152389c5c412eecc3","sequence":3,"field":"uni_s","name":"\u9662\u6821","value":"\u4E2D\u56FD\u79D1\u5B66\u9662\u5927\u5B66"},{"id":"c5612153a3c2a990483a48e5573f2c6e","sequence":2,"field":"yea","name":"\u5E74\u4EFD","value":"2022"}]',
'pageSize': '10',
'pageNumber': f'{pagenum}'
}
response = requests.post(url,headers=headers,data = data).json()
parse_response(response)
time.sleep(5)
def parse_response(response):
data_list = response['data']
for i in data_list:
id = i[0]['v']
id_url(id)
time.sleep(5)
def id_url(id):
url = 'https://www.nstl.gov.cn/api/service/nstl/web/execute?target=nstl4.search4&function=paper/pc/detail'
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Origin': 'https://www.nstl.gov.cn',
'Pragma': 'no-cache',
'Referer': 'https://www.nstl.gov.cn/paper_detail.html?id=49eca30cf784e72e5dd259fc789bc898',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="130", "Google Chrome";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
data = {
'id': f'{id}',
'webDisplayId': '1001',
'searchWordId': '5aaae7f21e66d420b6ca2aef49221ed4',
'searchId': '6be74044bf3ec7d5fba04edb1639e3d8',
'searchSequence': '1'
}
response = requests.post(url,headers=headers,data=data).json()
info_collect(response)
# 论文的标题,作者:机构:院校:专业:学位:授予机构:导师:语种:提交日期:论文答辩日期:分类号:关键词:摘要:
# 限定为 中国科学院大学
def info_collect(response):
title = None
zz_name = None
jg_name = None
yx_name = None
zy_name = None
xw = None
syjg_name = None
tjrq = None
key = None
zy = None
ds = None
yz_list =[]
flh_list = []
data = response['data']
for i in data:
value_list = list(i.values())
if 'hasAut' in value_list:
zz_name=value_list[1][0][-1]['v']
zz_name=''.join(zz_name)
elif 'off' in value_list:
jg_name = value_list[1]
jg_name =''.join(jg_name)
syjg_name =jg_name
elif 'uni' in value_list:
yx_name=value_list[1]
yx_name=''.join(yx_name)
elif 'maj' in value_list:
zy_name = value_list[1]
zy_name =''.join(zy_name)
elif 'dag' in value_list:
xw = value_list[1]
xw =''.join(xw)
elif 'lan' in value_list:
data_list =value_list[1]
for i in data_list:
yz= list(i.values())
yz=''.join(yz)
yz_list.append(yz)
elif 'clco' in value_list:
data_list = value_list[1]
for i in data_list:
flh = list(i.values())
flh =''.join(flh)
flh_list.append(flh)
elif 'suda' in value_list:
tjrq = value_list[1]
tjrq = ''.join(tjrq).split(' ')[0]
elif 'hasTut' in value_list:
data_list = value_list[1][0]
for i in data_list:
ds_list = list(i.values())
if 'nam' in ds_list:
ds = ds_list[1]
ds = ''.join(ds)
elif 'key' in value_list:
key_list = value_list[1]
key = '|'.join(key_list)
elif 'tit' in value_list:
title = value_list[1]
title = ''.join(title)
elif 'abs' in value_list:
zy = value_list[1]
zy = ''.join(zy).replace(' ','').replace('\n','')
if not os.path.exists('论文.csv'):
with open('论文.csv','w',encoding='UTF-8') as f:
f.write('文的标题,作者,机构,院校,专业,学位,授予机构,导师,语种,提交日期,分类号,关键词,摘要'+'\n')
with open('论文.csv','a+',encoding='UTF-8') as f:
f.write(f'{title},{zz_name},{jg_name},{yx_name},{zy_name},{xw},{syjg_name},{ds},{yz_list},{tjrq},{flh_list},{key},{zy}'+'\n')
print(f'{title}---写入完成')
if __name__ == '__main__':
all_spider()
# spider()

















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









