







基于BERT 的情感分类
主要论文:
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(双向Transformer 的预训练)
核心技术:
Embedding 、Attention --> Transformer
任务简介、拟解决问题、网络结构、LOSS设定、实验结果、案例分析等
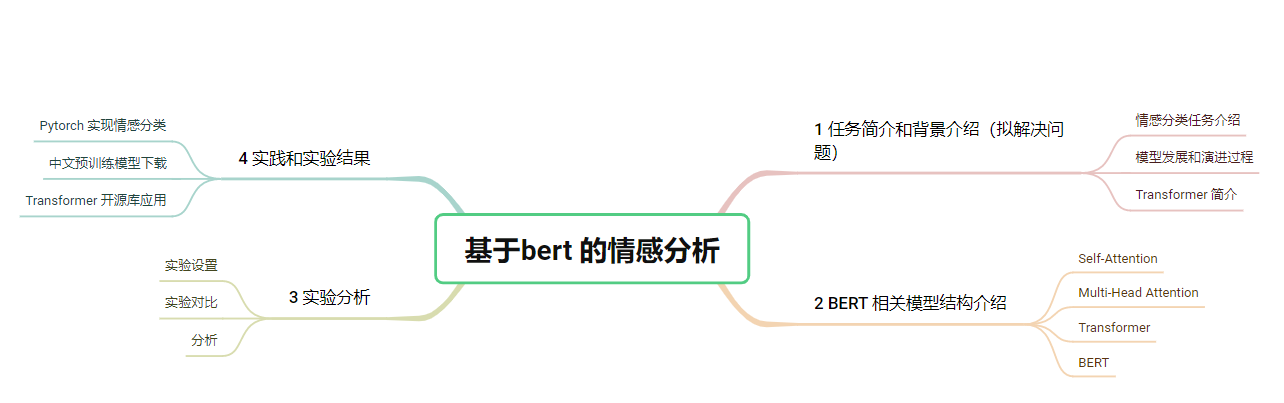
关于使用Pytorch 的简单说明
论文研究背景、成果及意义
情感极性分析 - 由粗到细
粗粒度的情感分析 (面向文档或者整个句子)
SemEval - 2014 的比赛的第四个子任务中基于 Aspect 的情感分类
- Aspect 提取 (aspect term extraction):识别句子中的方面或属性。
- 判断 Aspect 的情感倾向 (aspect term polarity):确定提取出的方面的情感是正面的还是负面的。
- 检测 Aspect 所属的类别 (aspect category detection):判断提取的方面属于哪一个预定义的类别。
- 判断 Aspect category 上的情感倾向 (aspect category polarity) ;例如:

state-of-the-art
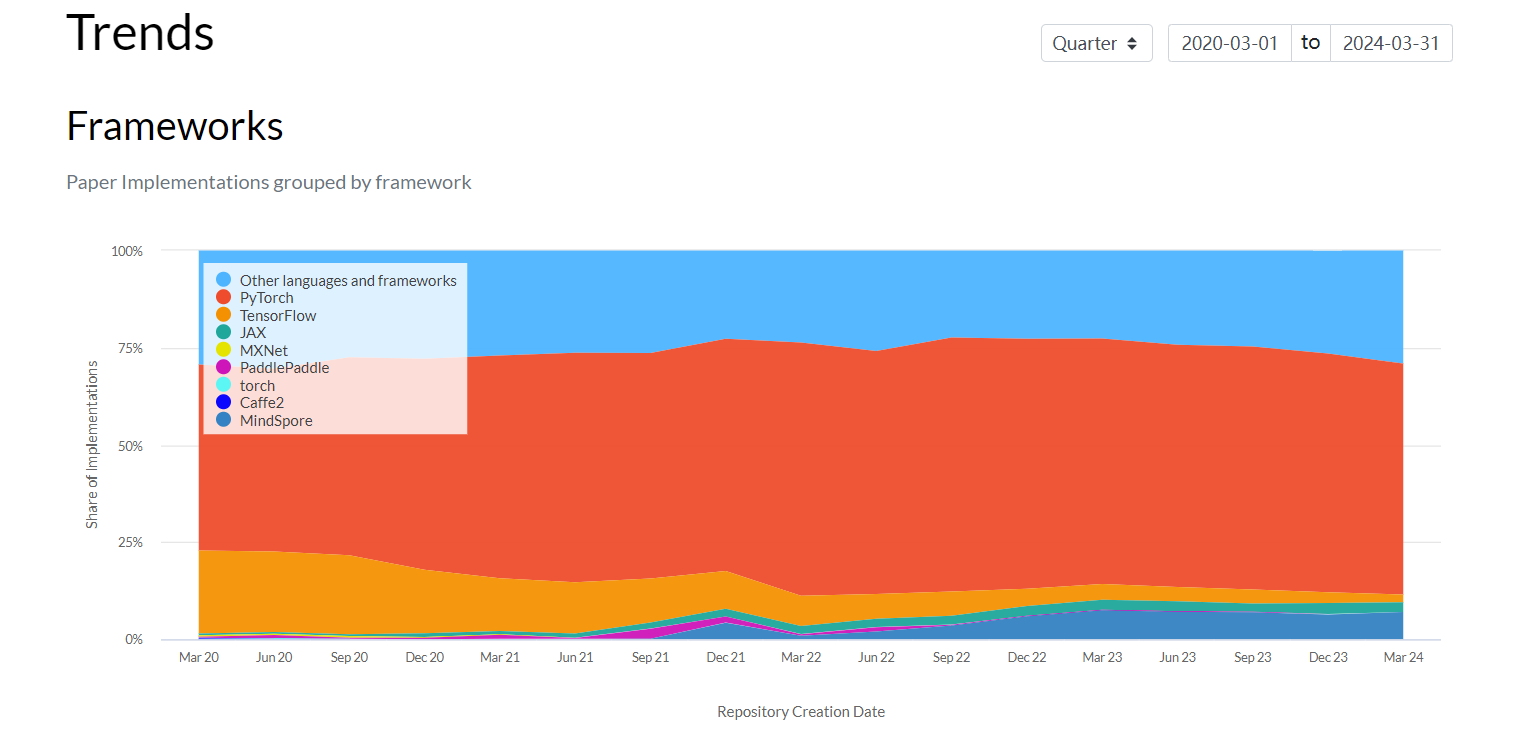
这里可以看到情感分类的最新论文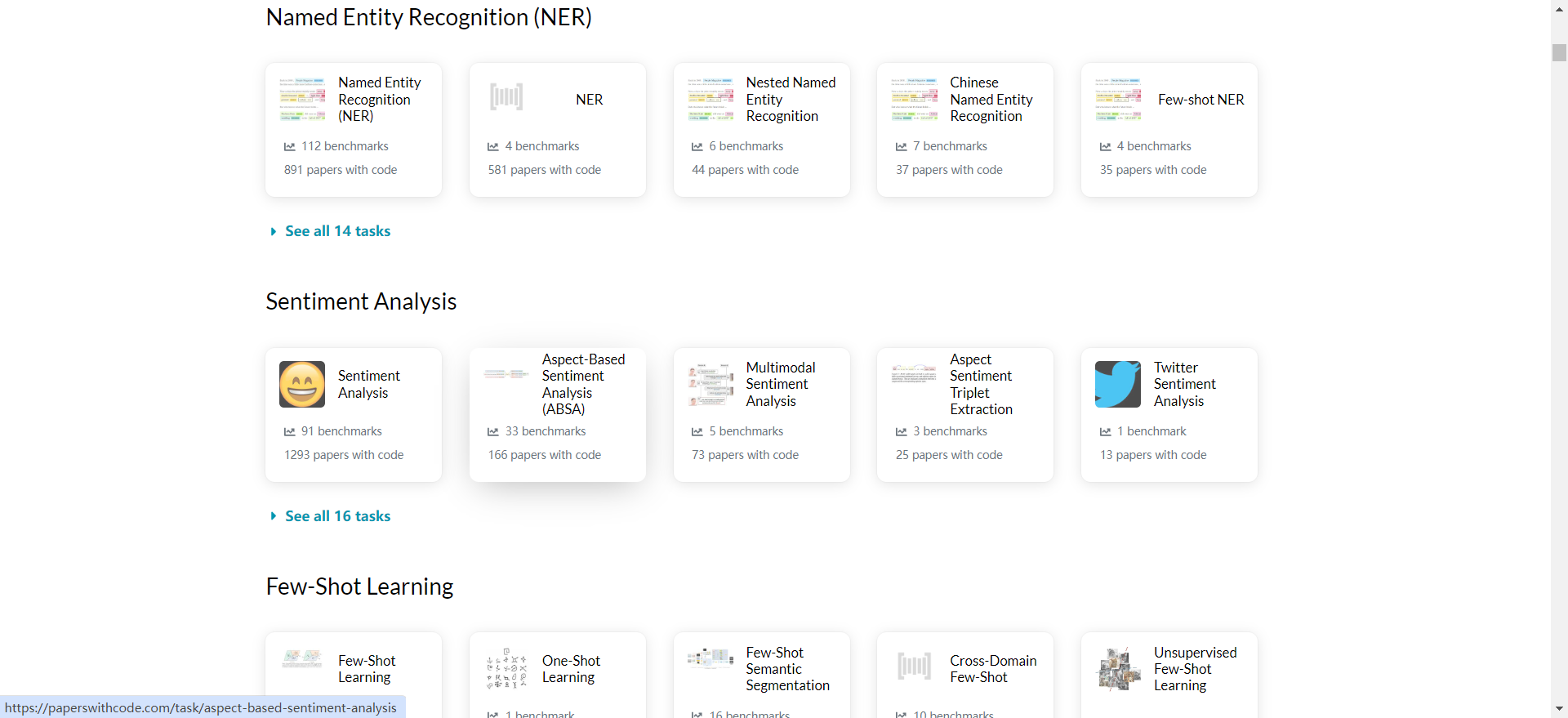
算力提升 – GPU 的发展
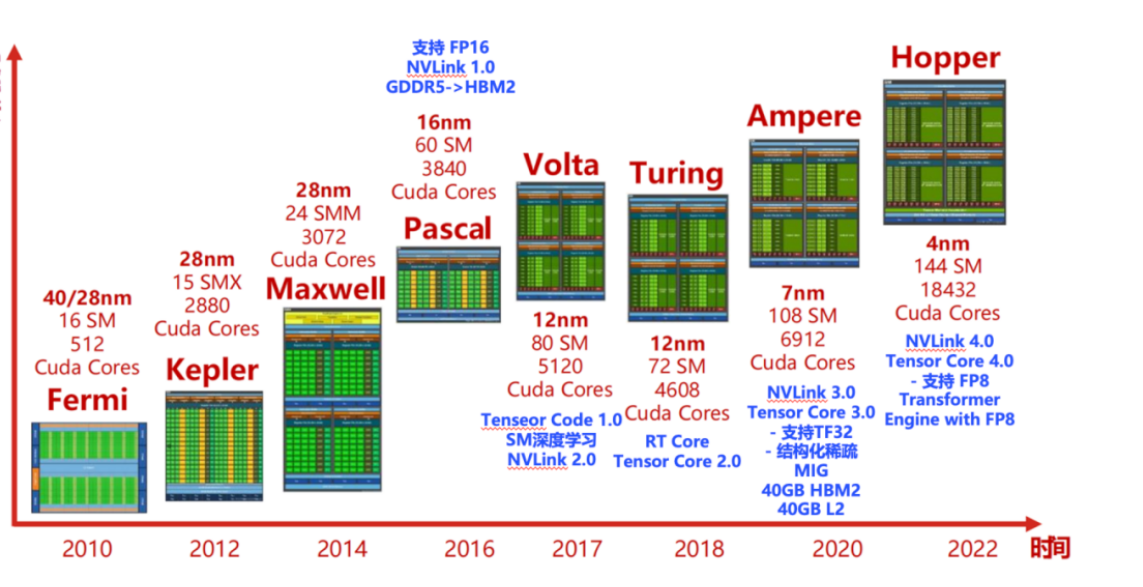
带来了 多任务深度学习 – 并行计算 (BERT – 2019)
大一统模型 – BERT
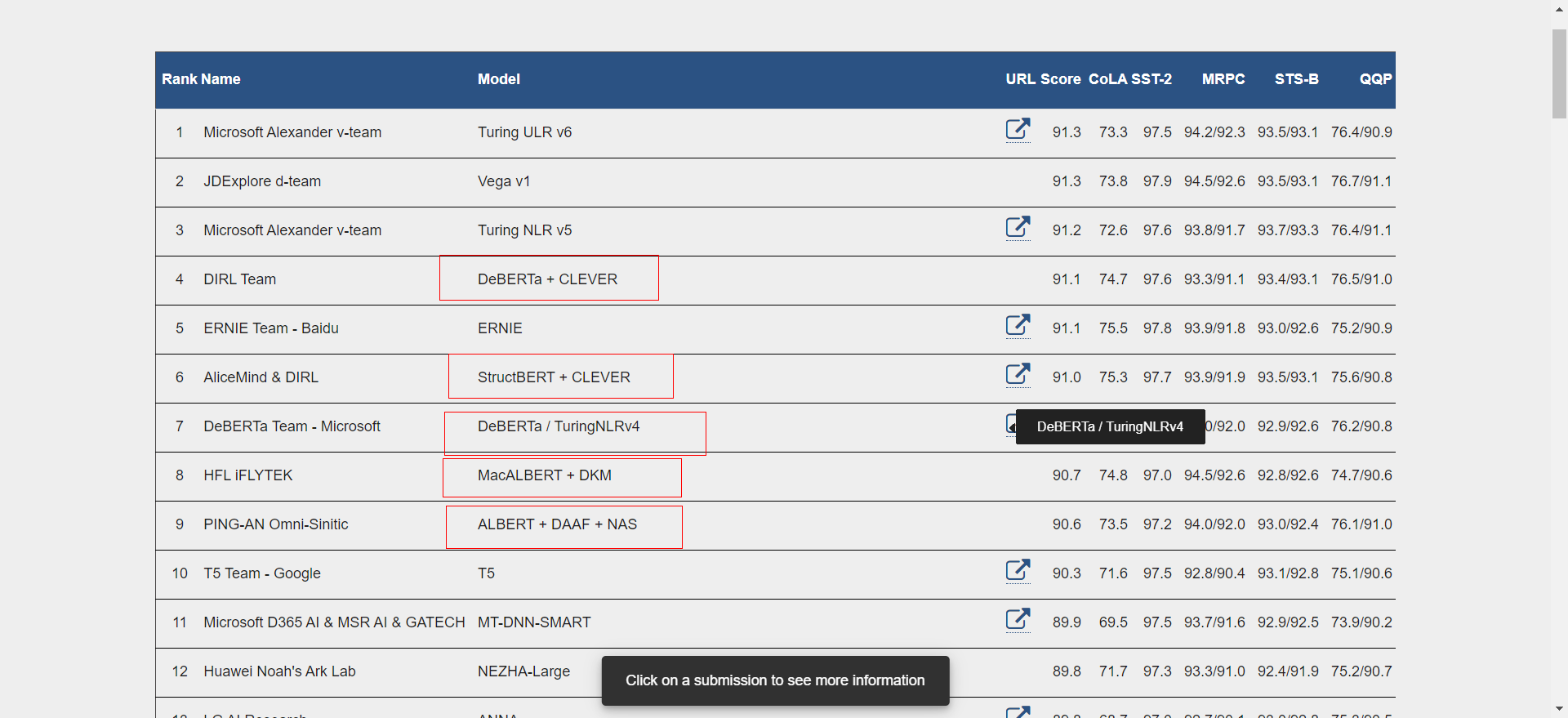
Benchmarks - BERT 的主流影响力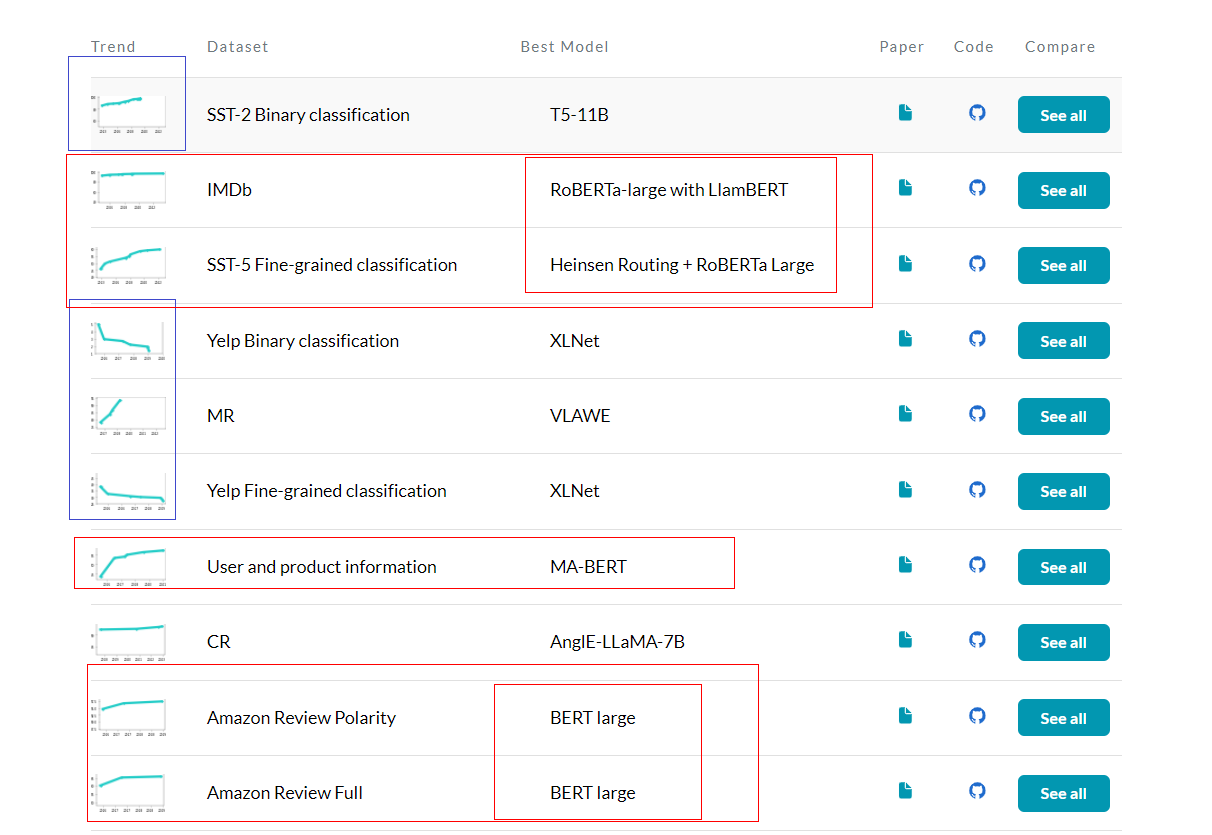
LlamBERT: Large-scale low-cost data annotation in NLP
23 Mar 2024 · Bálint Csanády, Lajos Muzsai, Péter Vedres, Zoltán Nádasdy, András Lukács · Edit social preview
Large Language Models (LLMs), such as GPT-4 and Llama 2, show remarkable proficiency in a wide range of natural language processing (NLP) tasks. Despite their effectiveness, the high costs associated with their use pose a challenge. We present LlamBERT, a hybrid approach that leverages LLMs to annotate a small subset of large, unlabeled databases and uses the results for fine-tuning transformer encoders like BERT and RoBERTa. This strategy is evaluated on two diverse datasets: the IMDb review dataset and the UMLS Meta-Thesaurus. Our results indicate that the LlamBERT approach slightly compromises on accuracy while offering much greater cost-effectiveness.
两个含义:
1 基于BERT 和RoBERTa 的微调
2 准确率有所下降(降低了成本)
模型发展历程
RNN
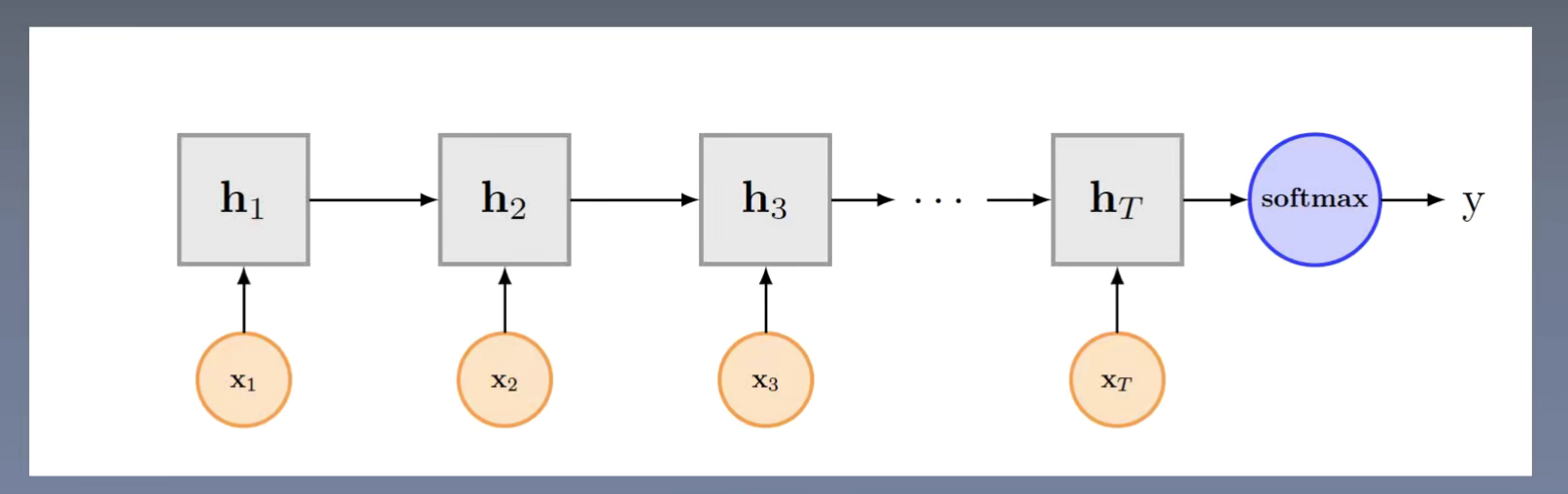
梯度爆炸 和梯度消失的问题
LSTM
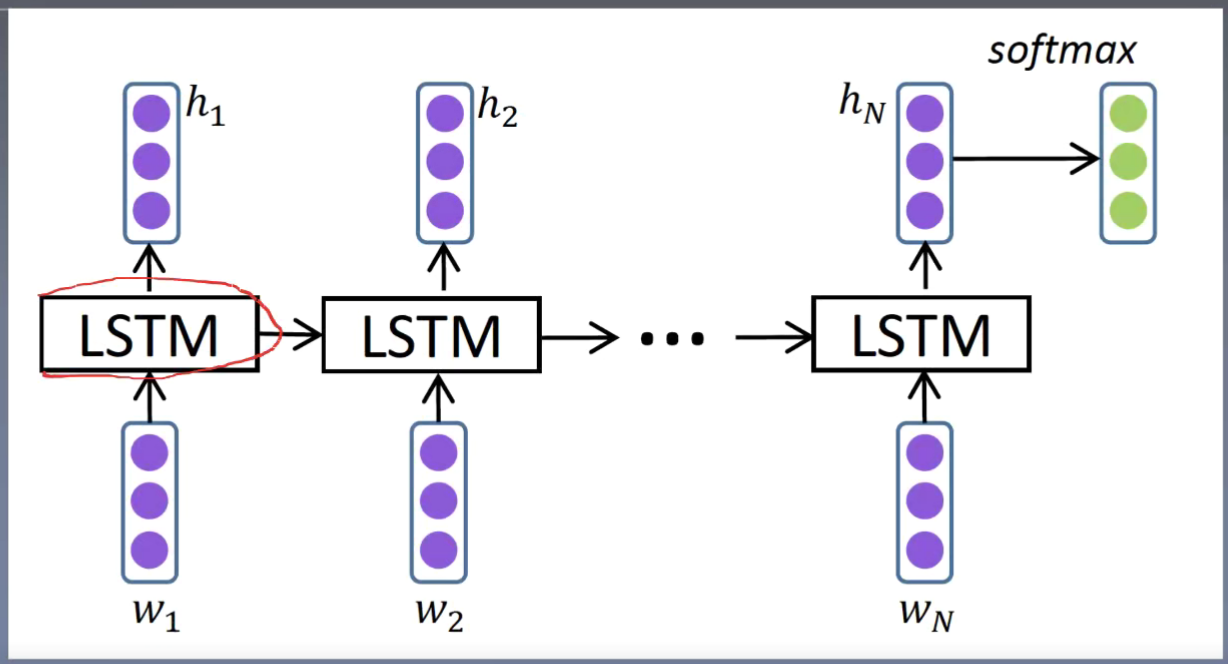
LSTM 引入门控单元 一定程度上减少了 梯度消失(累乘 – > 乘(记忆细胞的累加)); 但是不能解决梯度爆炸
Bi - LSTM(双向LSTM 从算法or 结构进行改进)
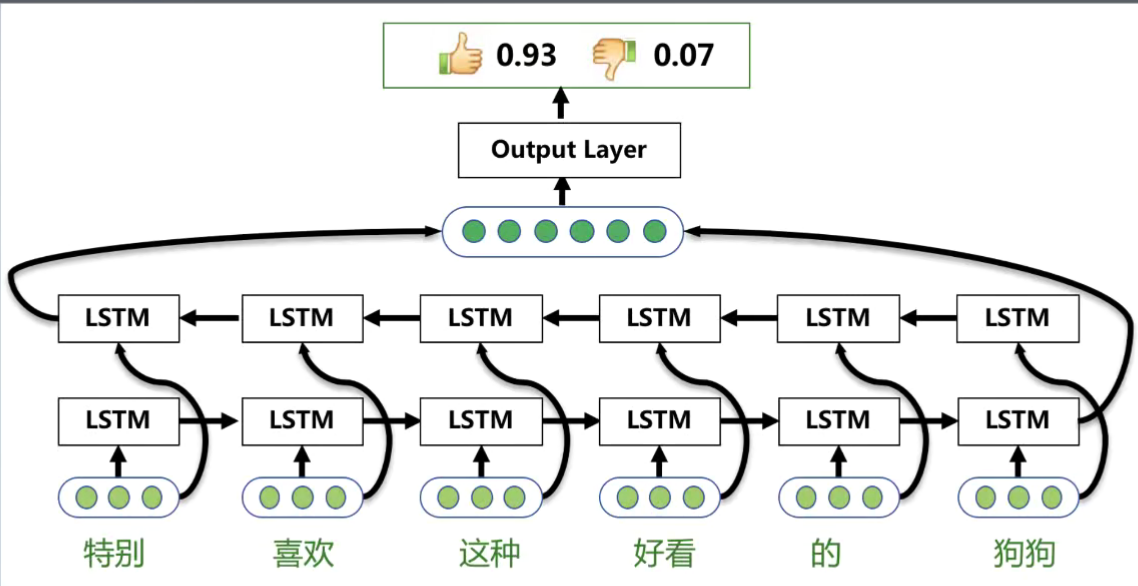
Attention
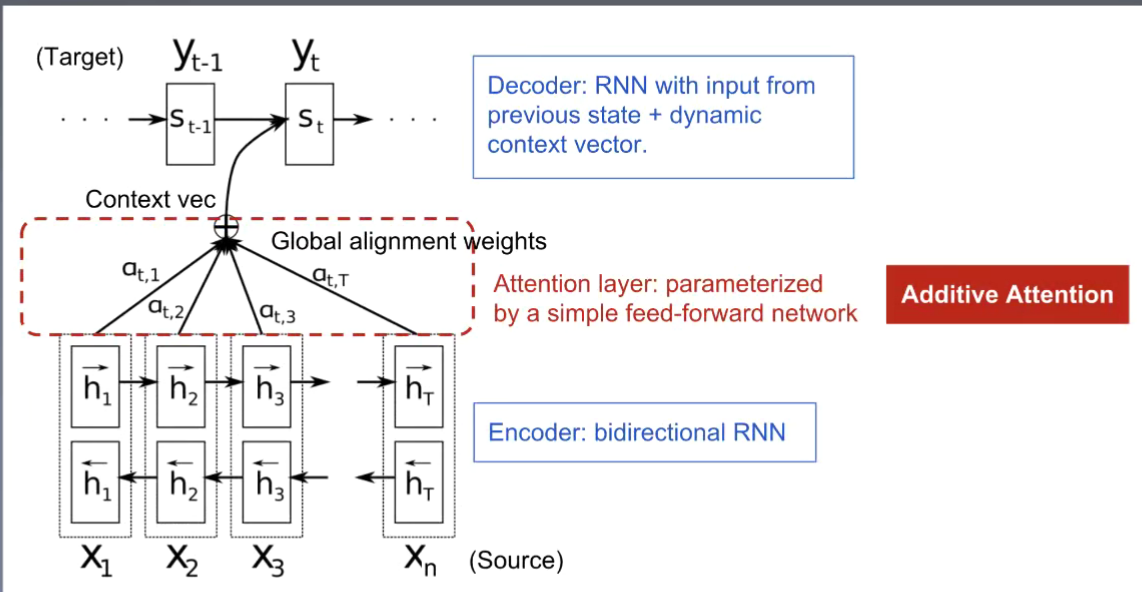
QKW 得到得分矩阵 ;
SEQ2 SEQ
Transformer
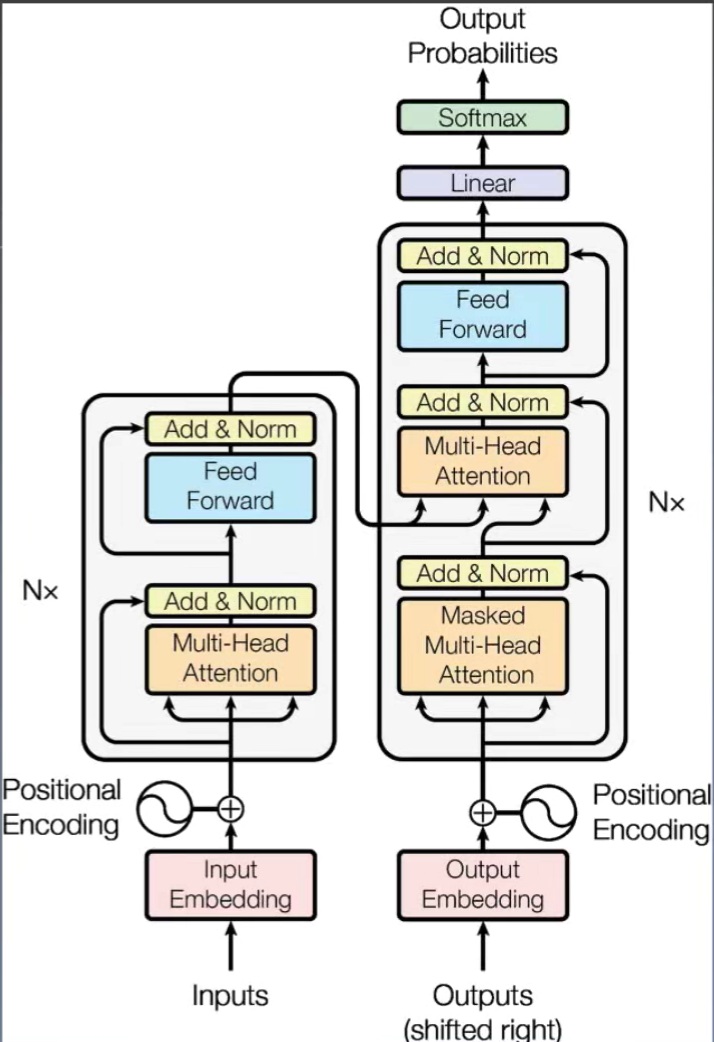
可并行的跨时代意义: 抽离了位置信息;
Bi - Transformer
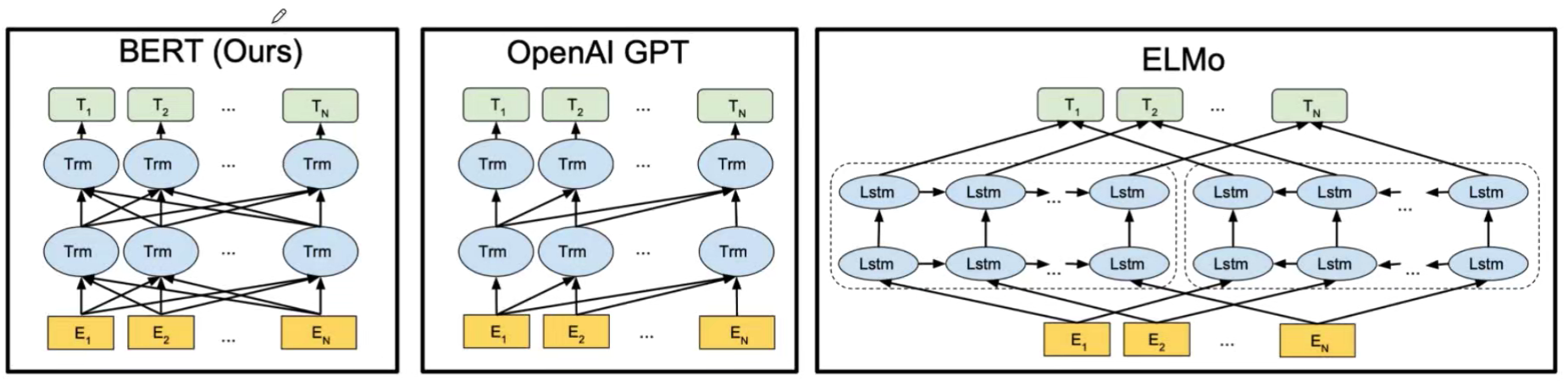
论文泛读
论文结构总览
- 摘要:介绍了研究主题是BERT模型的概述。
- 引言:论述了研究的重要性和必要性。
- 模型:探讨了BERT模型的基本结构和关键特点。
- 架构:详细介绍了采用Transformer技术的架构细节。
- 训练:描述了模型的训练方法,包括数据准备和训练过程。
- 数据集:解释了用于训练和测试模型的数据集特性。
- 定性评估:通过实际案例和应用来评估模型的表现。
- 讨论:分析了模型的限制和未来的研究方向。
摘要:
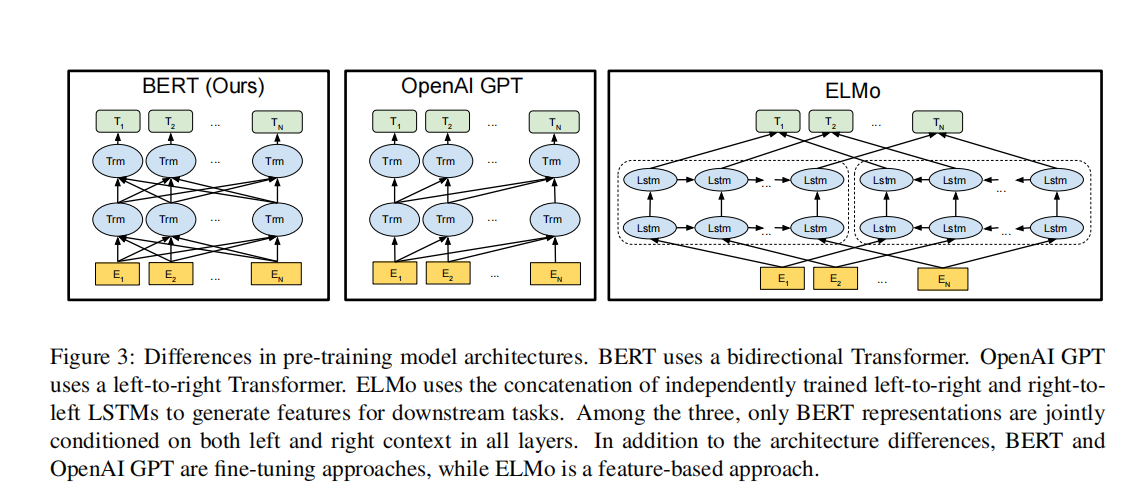
BERT(Bidirectional Encoder Representations from Transformers.)是一种新型的语言表示模型。与其他近期的语言表示模型(如 Peters et al., 2018a; Radford et al., 2018)不同,BERT 的设计目标是通过在所有层上同时考虑左右上下文,从未标注的文本中预训练深层的双向表示。因此,只需在预训练的 BERT 模型上增加一个输出层,就可以针对广泛的任务(如问题回答和语言推理)进行微调,而无需大幅修改特定任务的架构。
BERT 在概念上简单,实证上有效。它在十一个自然语言处理任务上取得了新的最佳效果,包括:
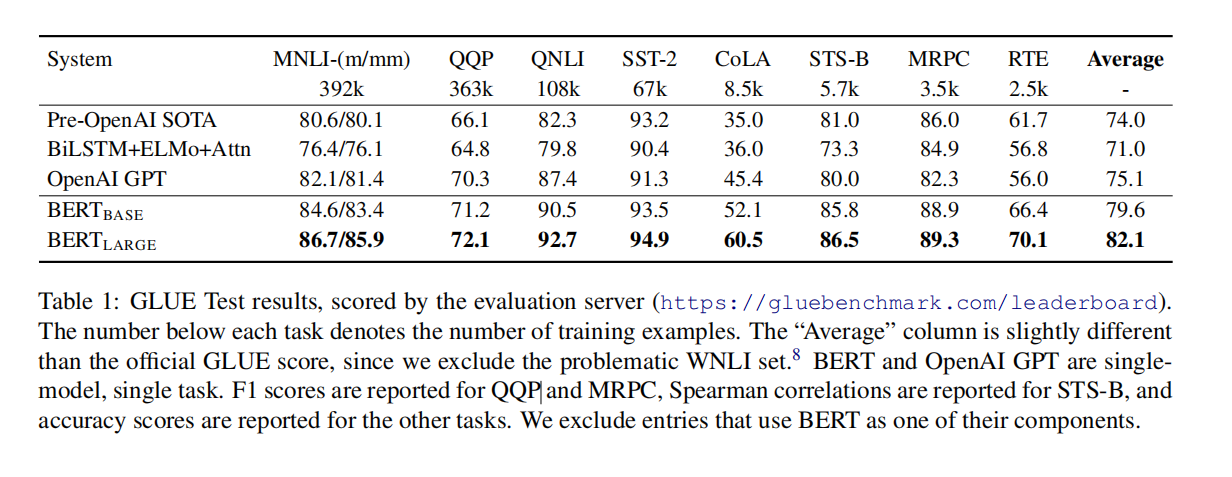
- 将 GLUE 得分提升到 80.5%(绝对提高了 7.7 个百分点)
- MultiNLI 准确率提升到 86.7%(绝对提高了 4.6 个百分点)
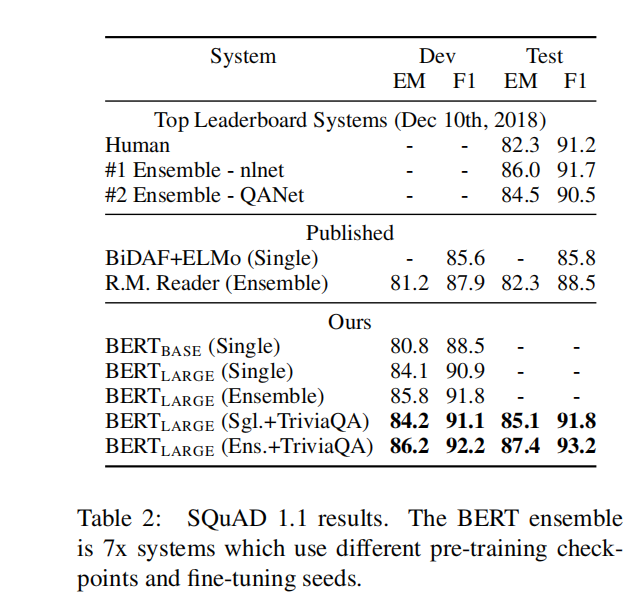
- SQuAD v1.1 问题回答测试 F1 分数提升到 93.2(绝对提高了 1.5 个百分点)
- SQuAD v2.0 测试 F1 分数提升到 83.1(绝对提高了 5.1 个百分点)。
论文结构:

论文精读
- 论文算法模型总览
- 论文算法模型的细节
- 论文算法模型细节2
- 实验设置及结果分析
- 论文总结
论文的算法总览
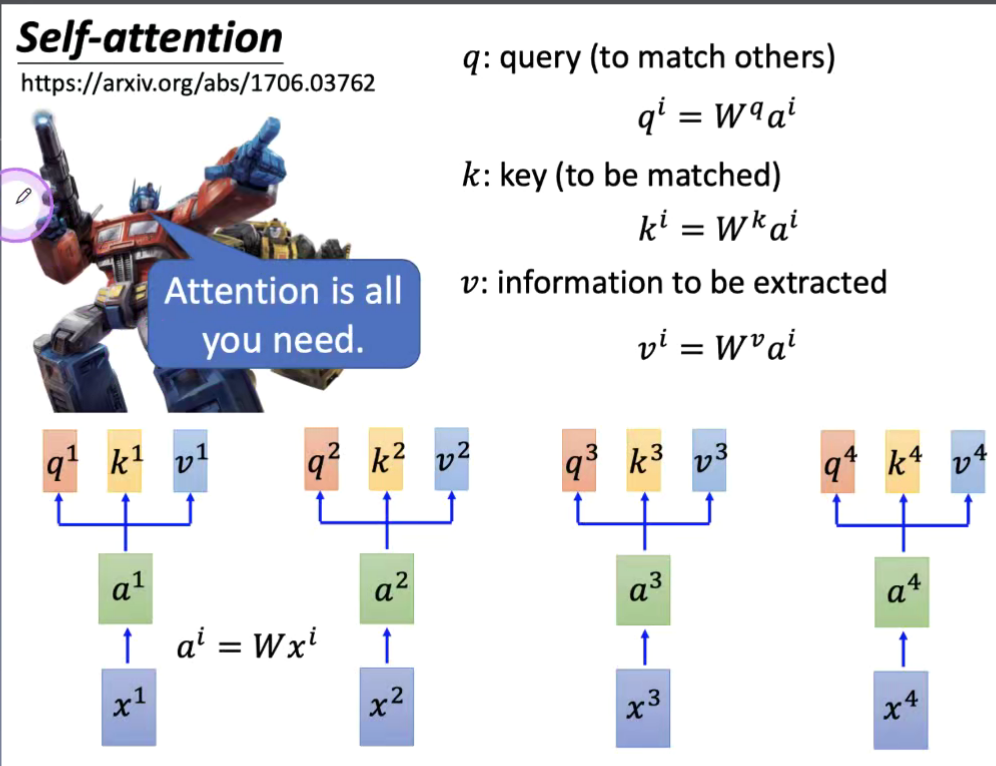
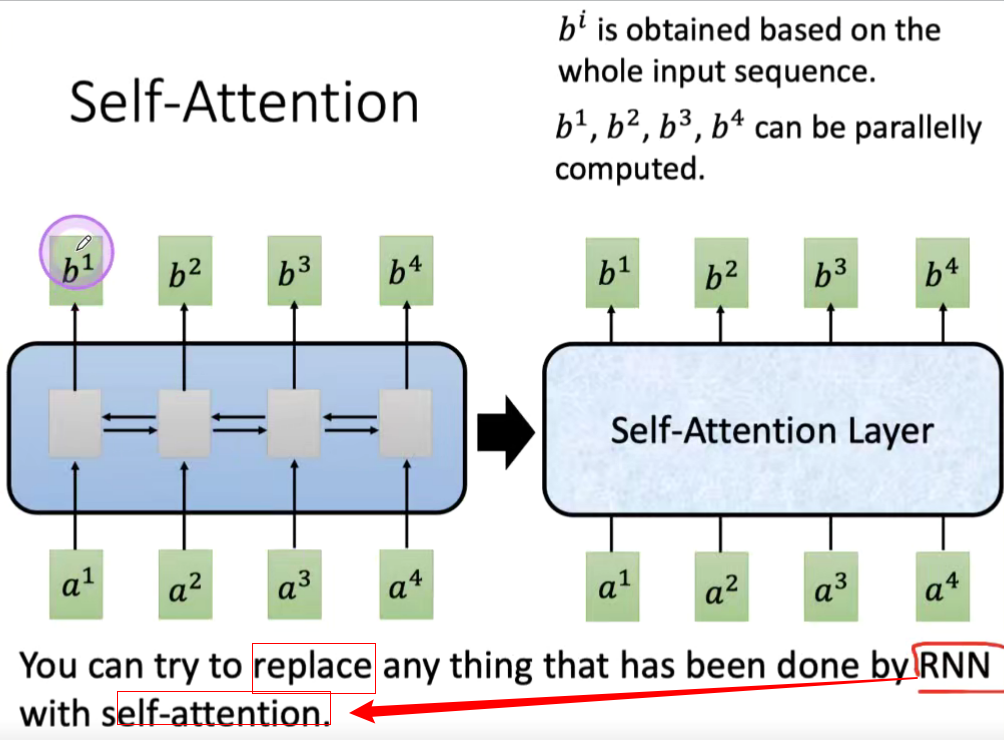
Attention+ Self- Attention +Transformer
论文算法模型的细节
Attention and more
得到X 1 到X n 的每一个word 的weight;主要运用到机器翻译的模型
多头自注意力
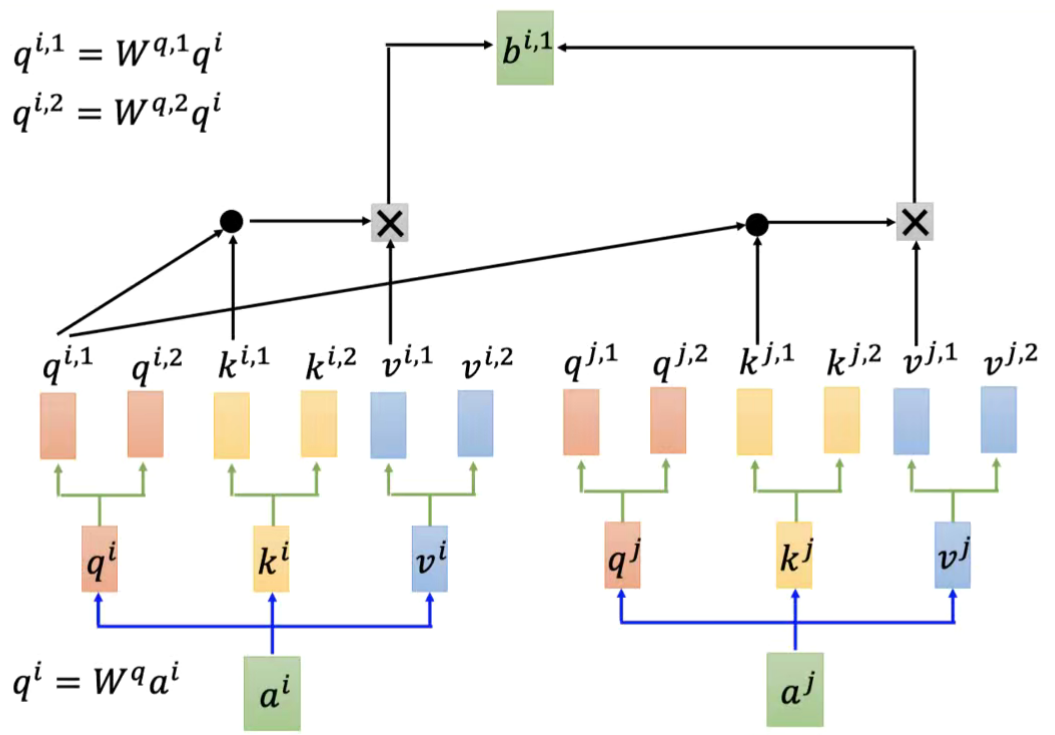
头越多 提取的特征越多 语义表达效果越强;这里可以类比一下TextCNN;不同角度的特征提取,侧重不同,相当于一句话我们通过不同的角度去理解
Transformer
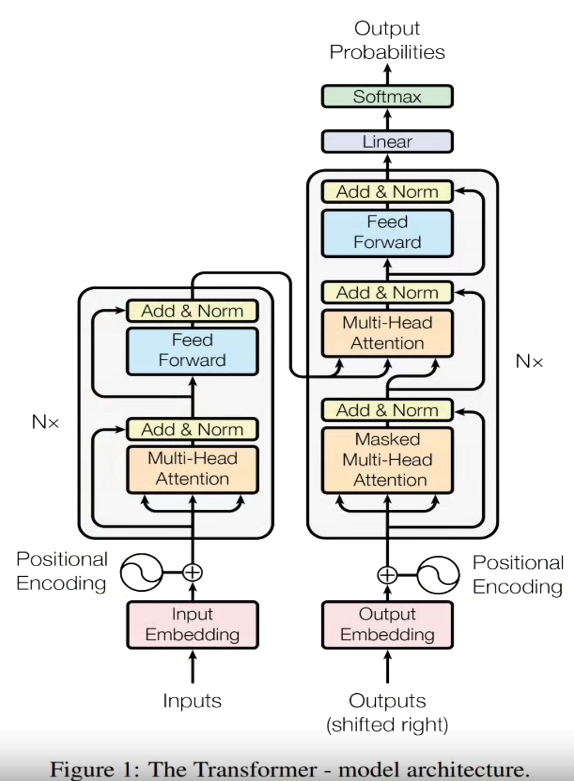
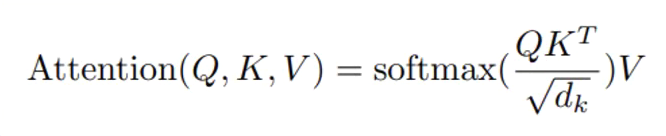
dk 全连接层数的超参, Google给的解释是使模型更快的收敛;
PositionEncoding;
输入和输出一起放入模型进行训练;预测的时候需要输入一个占位符
TF 的叠加
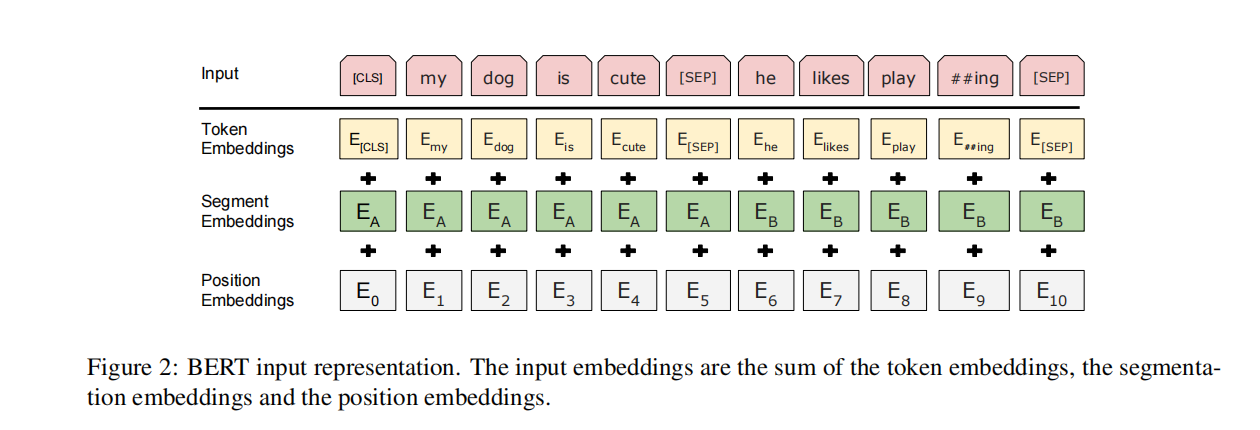
Pre-training and Fine Tuning
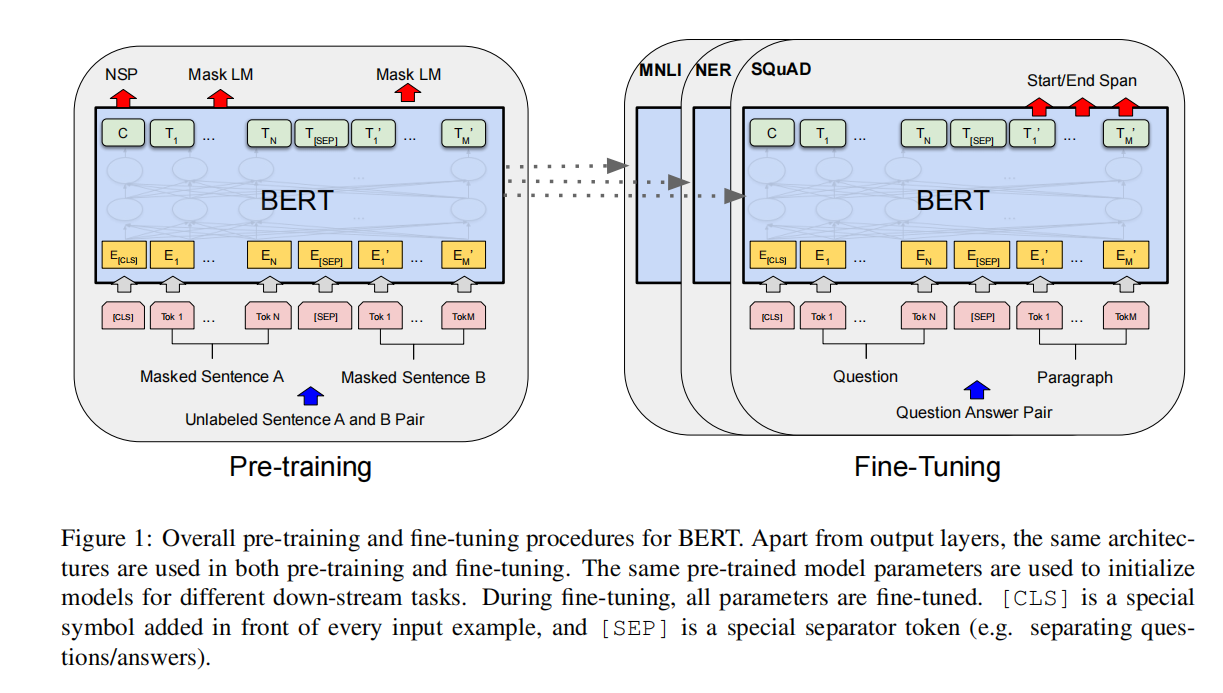
Pre
Masked LM
80% of the time: Replace the word with the [MASK] token, e.g., my dog is hairy →
my dog is [MASK]
• 10% of the time: Replace the word with a random word, e.g., my dog is hairy → my
dog is apple
• 10% of the time: Keep the word unchanged, e.g., my dog is hairy → my dog is hairy. The purpose of this is to bias the
representation towards the actual observed
word.
注意在中文中需要进行一定的本土化改进, 例如针对词组进行 mask (WWM 全词)
Next Sentence

Fine-Tuning
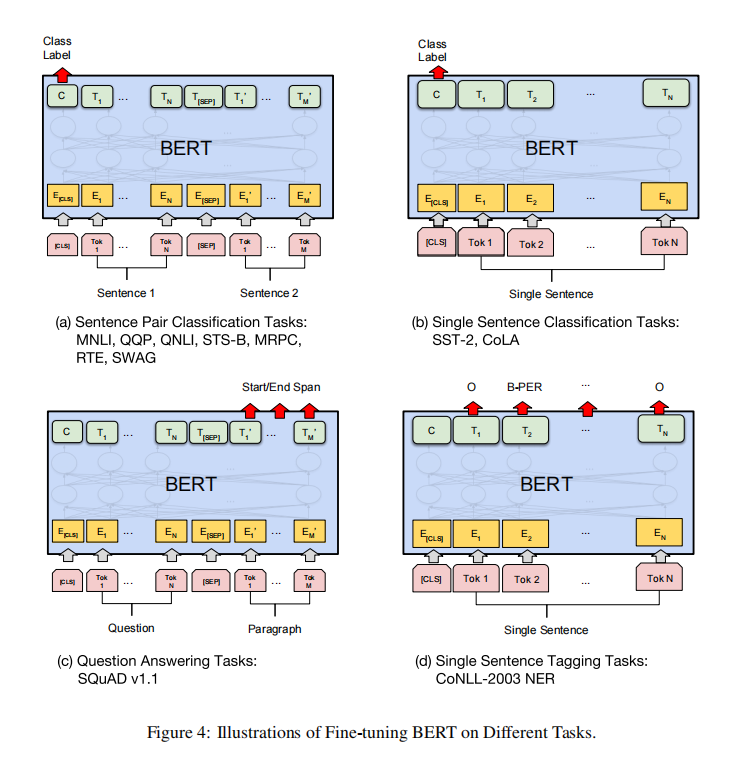
• Batch size: 16, 32
• Learning rate (Adam): 5e-5, 3e-5, 2e-5
• Number of epochs: 2, 3, 4
为什么需要进行微调? 怎么进行微调?
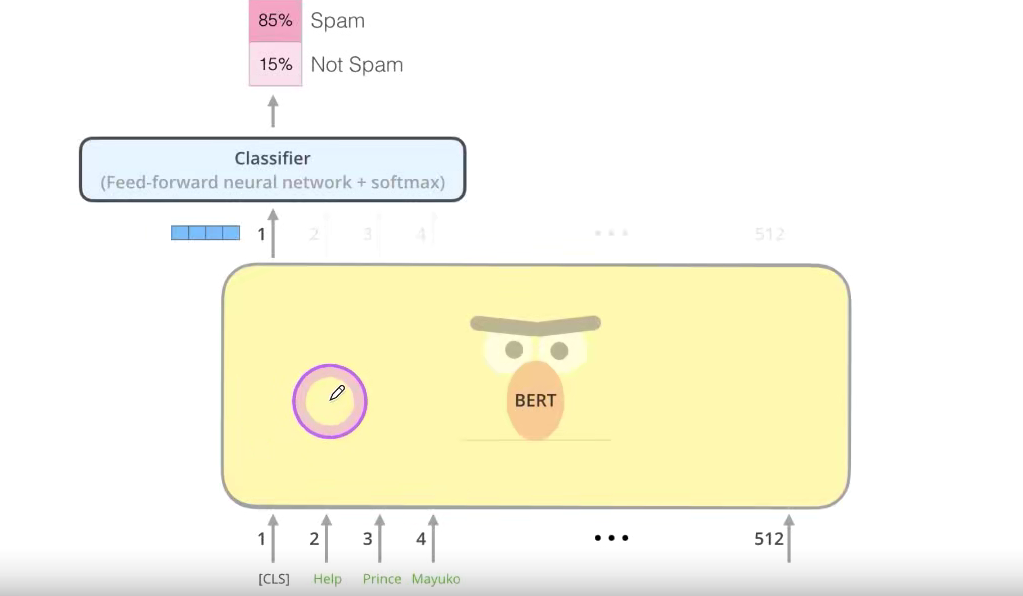
预训练模型权重有可能与我的任务不匹配;调整输入数据和全连接层
实验设置
实验数据
SST- 2 二分类情感分析
SQuAD 斯坦福大学给出的阅读理解数据集
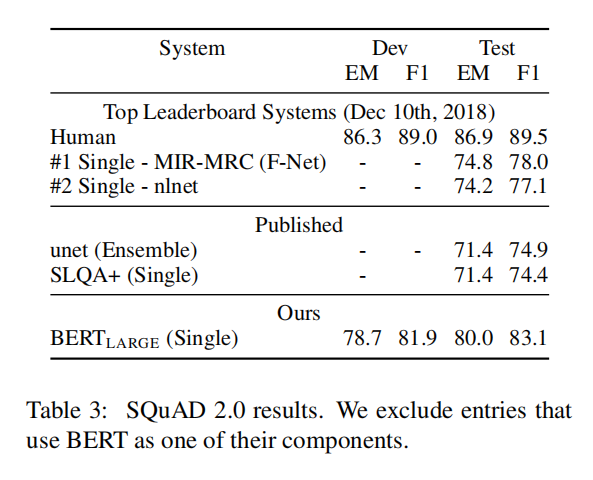
模型大小
it is also perhaps surprising that we are able to achieve such significant improvements on top of models which are already quite large relative to the existing literature. For example, the largest Transformer explored in Vaswani et al. (2017) is (L=6, H=1024, A=16)with 100M parameters for the encoder, and the largest Transformer we have found in the literatureis (L=64, H=512, A=2) with 235M parameters(Al-Rfou et al., 2018). By contrast, BERTBASE contains 110M parameters and BERTLARGE contains 340M parameters.
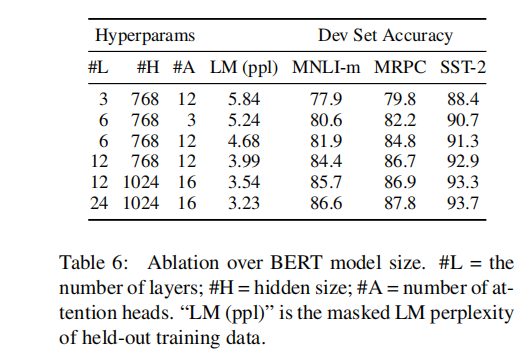
we hypothesize that when the model is fine-tuned directly on the downstream tasks and uses only a very small number of randomly initialized additional parameters, the task specific models can benefit from the larger, more expressive pre-trained representations even when downstream task data is very small.
论文总结
A 关键点
- 自注意力
- 多头自注意力
- Transformer (双向)
B 创新点(启发)
- 双向预训练 + Fine Tuning (可以针对数据较少的任务进行)
- 深度学习就是特征学习
- 规模
Results are presented in Table 7. BERTLARGE performs competitively with state-of-the-art methods. The best performing method concatenates the token representations from the top four hidden layers of the pre-trained Transformer, which is only 0.3 F1 behind fine-tuning the entire model. This demonstrates that BERT is effective for both fine tuning and feature-based approaches.
代码实现
下面的代码实现均展示Bert 结构的核心思路,并非全部可直接run 的码子;
完整代码见GitHub: https://github.com/boots-coder/ABSA-PyTorch
how to Get Started With the Model
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
预训练模型下载
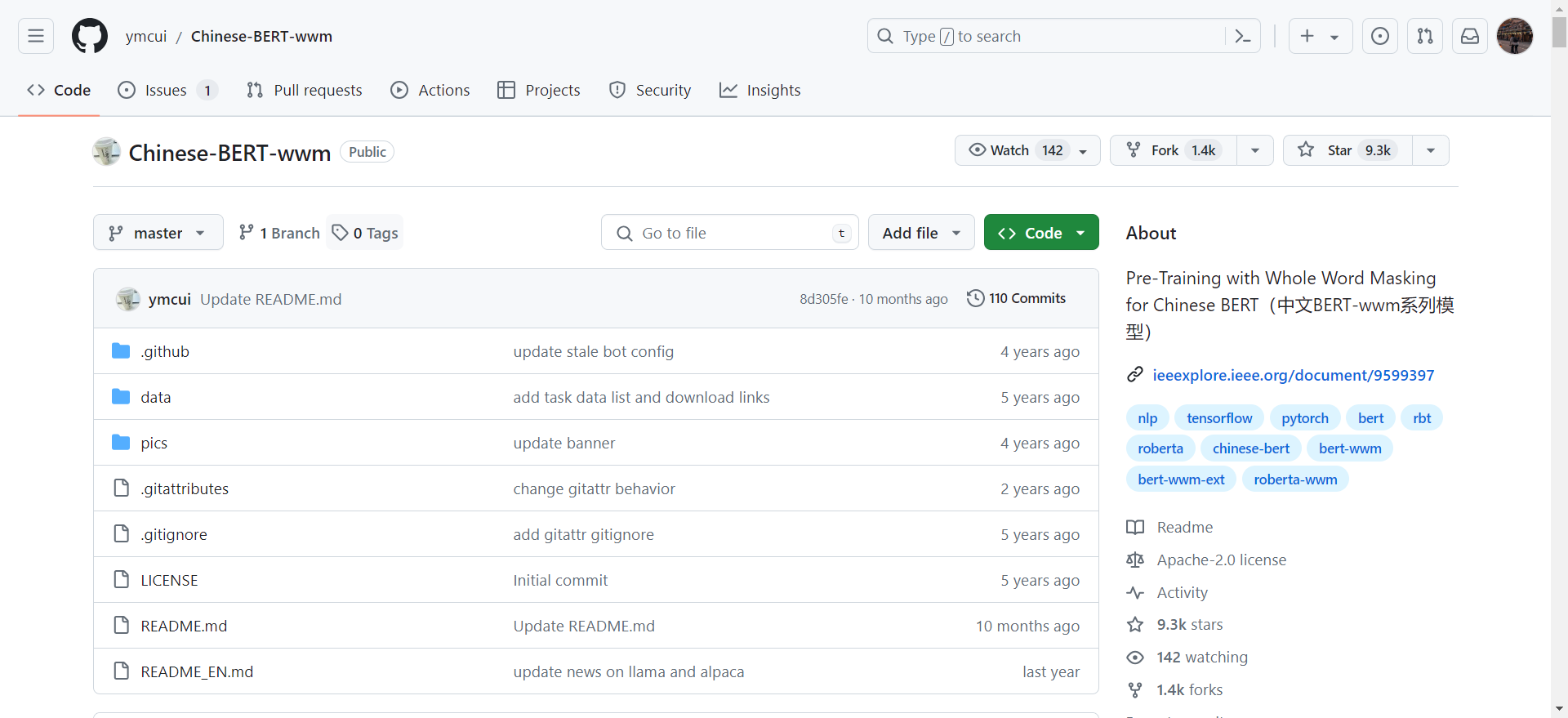
注意:开源版本不包含MLM任务的权重;如需做MLM任务,请使用额外数据进行二次预训练(和其他下游任务一样)。
| 模型简称 | 语料 | Google下载 | 百度网盘下载 |
|---|---|---|---|
RBT6, Chinese | EXT数据[1] | - | TensorFlow(密码hniy) |
RBT4, Chinese | EXT数据[1] | - | TensorFlow(密码sjpt) |
RBTL3, Chinese | EXT数据[1] | TensorFlow PyTorch | TensorFlow(密码s6cu) |
RBT3, Chinese | EXT数据[1] | TensorFlow PyTorch | TensorFlow(密码5a57) |
RoBERTa-wwm-ext-large, Chinese | EXT数据[1] | TensorFlow PyTorch | TensorFlow(密码dqqe) |
RoBERTa-wwm-ext, Chinese | EXT数据[1] | TensorFlow PyTorch | TensorFlow(密码vybq) |
BERT-wwm-ext, Chinese | EXT数据[1] | TensorFlow PyTorch | TensorFlow(密码wgnt) |
BERT-wwm, Chinese | 中文维基 | TensorFlow PyTorch | TensorFlow(密码qfh8) |
BERT-base, ChineseGoogle | 中文维基 | Google Cloud | - |
BERT-base, Multilingual CasedGoogle | 多语种维基 | Google Cloud | - |
BERT-base, Multilingual UncasedGoogle | 多语种维基 | Google Cloud | - |
[1] EXT数据包括:中文维基百科,其他百科、新闻、问答等数据,总词数达5.4B。
Code in Transformer
- 构造函数 (
__init__):embeddings:负责将输入的 token 转换为嵌入向量。encoder:由多层自注意力(self-attention)模块组成,将输入嵌入进行编码处理。pooler:负责提取整个句子的向量表示,可以通过add_pooling_layer参数控制是否使用。
- 输入和输出嵌入 (
get_input_embeddings/set_input_embeddings):- 这些方法用于获取和设置输入嵌入参数。
- 剪枝 (
_prune_heads):- 用于剪掉多头注意力机制中指定的注意力头以减少模型复杂性。
- 前向传播 (
forward):- 接受多种输入参数,包括 token 编号、注意力掩码、输入嵌入等。
- 通过对输入嵌入、编码器和池化层的应用,生成模型的输出。
- 支持输出最后的隐藏状态、池化后的句子向量、隐藏状态序列、注意力权重等。
- 解码器模式:
- 如果模型配置为解码器,将增加一个跨注意力机制层,用于在编码器和解码器之间实现交互。
encoder_hidden_states和encoder_attention_mask参数会在前向传播中被用于跨注意力机制。
class BertModel(BertPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well
as a decoder, in which case a layer of cross-attention is added between
the self-attention layers, following the architecture described in `Attention is all you need
<https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones,
Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the
:obj:`is_decoder` argument of the configuration set to :obj:`True`.
To be used in a Seq2Seq model, the model needs to initialized with both :obj:`is_decoder`
argument and :obj:`add_cross_attention` set to :obj:`True`; an
:obj:`encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = BertEmbeddings(config)
self.encoder = BertEncoder(config)
self.pooler = BertPooler(config) if add_pooling_layer else None
self.init_weights()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""Prunes heads of the model.
heads_to_prune: dict of {layer_num: list of heads to prune in this layer}
See base class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_callable(BERT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@add_code_sample_docstrings(
tokenizer_class=_TOKENIZER_FOR_DOC,
checkpoint="bert-base-uncased",
output_type=BaseModelOutputWithPooling,
config_class=_CONFIG_FOR_DOC,
)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
r"""
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention
if the model is configured as a decoder.
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask
is used in the cross-attention if the model is configured as a decoder.
Mask values selected in ``[0, 1]``:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **maked**.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, device)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
Code WIth Me
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler(sys.stdout))
class Instructor:
def __init__(self, opt):
self.opt = opt
if 'bert' in opt.model_name:
tokenizer = Tokenizer4Bert(opt.max_seq_len, opt.pretrained_bert_name)
bert = BertModel.from_pretrained(opt.pretrained_bert_name)
self.model = opt.model_class(bert, opt).to(opt.device)
else:
tokenizer = build_tokenizer(
fnames=[opt.dataset_file['train'], opt.dataset_file['test']],
max_seq_len=opt.max_seq_len,
dat_fname='{0}_tokenizer.dat'.format(opt.dataset))
embedding_matrix = build_embedding_matrix(
word2idx=tokenizer.word2idx,
embed_dim=opt.embed_dim,
dat_fname='{0}_{1}_embedding_matrix.dat'.format(str(opt.embed_dim), opt.dataset))
self.model = opt.model_class(embedding_matrix, opt).to(opt.device)
self.trainset = ABSADataset(opt.dataset_file['train'], tokenizer)
self.testset = ABSADataset(opt.dataset_file['test'], tokenizer)
assert 0 <= opt.valset_ratio < 1
if opt.valset_ratio > 0:
valset_len = int(len(self.trainset) * opt.valset_ratio)
self.trainset, self.valset = random_split(self.trainset, (len(self.trainset) - valset_len, valset_len))
else:
self.valset = self.testset
if opt.device.type == 'cuda':
logger.info('cuda memory allocated: {}'.format(torch.cuda.memory_allocated(device=opt.device.index)))
self._print_args()
def _print_args(self):
n_trainable_params, n_nontrainable_params = 0, 0
for p in self.model.parameters():
n_params = torch.prod(torch.tensor(p.shape))
if p.requires_grad:
n_trainable_params += n_params
else:
n_nontrainable_params += n_params
logger.info(
'n_trainable_params: {0}, n_nontrainable_params: {1}'.format(n_trainable_params, n_nontrainable_params))
logger.info('> training arguments:')
for arg in vars(self.opt):
logger.info('>>> {0}: {1}'.format(arg, getattr(self.opt, arg)))
def _reset_params(self):
for child in self.model.children():
if type(child) != BertModel: # skip bert params
for p in child.parameters():
if p.requires_grad:
if len(p.shape) > 1:
self.opt.initializer(p)
else:
stdv = 1. / math.sqrt(p.shape[0])
torch.nn.init.uniform_(p, a=-stdv, b=stdv)
def _train(self, criterion, optimizer, train_data_loader, val_data_loader):
max_val_acc = 0
max_val_f1 = 0
global_step = 0
path = None
for epoch in range(self.opt.num_epoch):
logger.info('>' * 100)
logger.info('epoch: {}'.format(epoch))
n_correct, n_total, loss_total = 0, 0, 0
# switch model to training mode
self.model.train()
for i_batch, sample_batched in enumerate(train_data_loader):
global_step += 1
# clear gradient accumulators
optimizer.zero_grad()
inputs = [sample_batched[col].to(self.opt.device) for col in self.opt.inputs_cols]
outputs = self.model(inputs)
targets = sample_batched['polarity'].to(self.opt.device)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
n_correct += (torch.argmax(outputs, -1) == targets).sum().item()
n_total += len(outputs)
loss_total += loss.item() * len(outputs)
if global_step % self.opt.log_step == 0:
train_acc = n_correct / n_total
train_loss = loss_total / n_total
logger.info('loss: {:.4f}, acc: {:.4f}'.format(train_loss, train_acc))
val_acc, val_f1 = self._evaluate_acc_f1(val_data_loader)
logger.info('> val_acc: {:.4f}, val_f1: {:.4f}'.format(val_acc, val_f1))
if val_acc > max_val_acc:
max_val_acc = val_acc
if not os.path.exists('state_dict'):
os.mkdir('state_dict')
path = 'state_dict/{0}_{1}_val_acc{2}'.format(self.opt.model_name, self.opt.dataset, round(val_acc, 4))
torch.save(self.model.state_dict(), path)
logger.info('>> saved: {}'.format(path))
if val_f1 > max_val_f1:
max_val_f1 = val_f1
return path
def _evaluate_acc_f1(self, data_loader):
n_correct, n_total = 0, 0
t_targets_all, t_outputs_all = None, None
# switch model to evaluation mode
self.model.eval()
with torch.no_grad():
for t_batch, t_sample_batched in enumerate(data_loader):
t_inputs = [t_sample_batched[col].to(self.opt.device) for col in self.opt.inputs_cols]
t_targets = t_sample_batched['polarity'].to(self.opt.device)
t_outputs = self.model(t_inputs)
n_correct += (torch.argmax(t_outputs, -1) == t_targets).sum().item()
n_total += len(t_outputs)
if t_targets_all is None:
t_targets_all = t_targets
t_outputs_all = t_outputs
else:
t_targets_all = torch.cat((t_targets_all, t_targets), dim=0)
t_outputs_all = torch.cat((t_outputs_all, t_outputs), dim=0)
acc = n_correct / n_total
f1 = metrics.f1_score(t_targets_all.cpu(), torch.argmax(t_outputs_all, -1).cpu(), labels=[0, 1, 2],
average='macro')
return acc, f1
def run(self):
# Loss and Optimizer
criterion = nn.CrossEntropyLoss()
_params = filter(lambda p: p.requires_grad, self.model.parameters())
optimizer = self.opt.optimizer(_params, lr=self.opt.learning_rate, weight_decay=self.opt.l2reg)
train_data_loader = DataLoader(dataset=self.trainset, batch_size=self.opt.batch_size, shuffle=True)
test_data_loader = DataLoader(dataset=self.testset, batch_size=self.opt.batch_size, shuffle=False)
val_data_loader = DataLoader(dataset=self.valset, batch_size=self.opt.batch_size, shuffle=False)
self._reset_params()
best_model_path = self._train(criterion, optimizer, train_data_loader, val_data_loader)
self.model.load_state_dict(torch.load(best_model_path))
self.model.eval()
test_acc, test_f1 = self._evaluate_acc_f1(test_data_loader)
logger.info('>> test_acc: {:.4f}, test_f1: {:.4f}'.format(test_acc, test_f1))
def main():
# Hyper Parameters
parser = argparse.ArgumentParser()
parser.add_argument('--model_name', default='bert_spc', type=str)
parser.add_argument('--dataset', default='laptop', type=str, help='twitter, restaurant, laptop')
parser.add_argument('--optimizer', default='adam', type=str)
parser.add_argument('--initializer', default='xavier_uniform_', type=str)
parser.add_argument('--learning_rate', default=2e-5, type=float, help='try 5e-5, 2e-5 for BERT, 1e-3 for others')
parser.add_argument('--dropout', default=0.1, type=float)
parser.add_argument('--l2reg', default=0.01, type=float) # L2正则化参数
parser.add_argument('--num_epoch', default=3, type=int, help='try larger number for non-BERT models')
parser.add_argument('--batch_size', default=16, type=int, help='try 16, 32, 64 for BERT models')
parser.add_argument('--log_step', default=5, type=int)
parser.add_argument('--embed_dim', default=300, type=int)
parser.add_argument('--hidden_dim', default=300, type=int)
parser.add_argument('--bert_dim', default=768, type=int)
parser.add_argument('--pretrained_bert_name', default='bert-base-uncased', type=str)
parser.add_argument('--max_seq_len', default=80, type=int)
parser.add_argument('--polarities_dim', default=3, type=int)
parser.add_argument('--hops', default=3, type=int)
parser.add_argument('--device', default=None, type=str, help='e.g. cuda:0')
parser.add_argument('--seed', default=None, type=int, help='set seed for reproducibility')
parser.add_argument('--valset_ratio', default=0, type=float,
help='set ratio between 0 and 1 for validation support')
# The following parameters are only valid for the lcf-bert model
parser.add_argument('--local_context_focus', default='cdm', type=str, help='local context focus mode, cdw or cdm')
parser.add_argument('--SRD', default=3, type=int,
help='semantic-relative-distance, see the paper of LCF-BERT model')
opt = parser.parse_args()
if opt.seed is not None:
random.seed(opt.seed)
numpy.random.seed(opt.seed)
torch.manual_seed(opt.seed)
torch.cuda.manual_seed(opt.seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
model_classes = {
'lstm': LSTM,
'td_lstm': TD_LSTM,
'tc_lstm': TC_LSTM,
'atae_lstm': ATAE_LSTM,
'memnet': MemNet,
'bert_spc': BERT_SPC,
# default hyper-parameters for LCF-BERT model is as follws:
# lr: 2e-5
# l2: 1e-5
# batch size: 16
# num epochs: 5
}
dataset_files = {
'twitter': {
'train': './datasets/acl-14-short-data/train.raw',
'test': './datasets/acl-14-short-data/test.raw'
},
'restaurant': {
'train': './datasets/semeval14/Restaurants_Train.xml.seg',
'test': './datasets/semeval14/Restaurants_Test_Gold.xml.seg'
},
'laptop': {
'train': './datasets/semeval14/Laptops_Train.xml.seg',
'test': './datasets/semeval14/Laptops_Test_Gold.xml.seg'
}
}
input_colses = {
'lstm': ['text_raw_indices'],
'td_lstm': ['text_left_with_aspect_indices', 'text_right_with_aspect_indices'],
'tc_lstm': ['text_left_with_aspect_indices', 'text_right_with_aspect_indices', 'aspect_indices'],
'atae_lstm': ['text_raw_indices', 'aspect_indices'],
'memnet': ['text_raw_without_aspect_indices', 'aspect_indices'],
'bert_spc': ['text_bert_indices', 'bert_segments_ids'],
}
initializers = {
'xavier_uniform_': torch.nn.init.xavier_uniform_,
'xavier_normal_': torch.nn.init.xavier_normal,
'orthogonal_': torch.nn.init.orthogonal_,
}
optimizers = {
'adadelta': torch.optim.Adadelta, # default lr=1.0
'adagrad': torch.optim.Adagrad, # default lr=0.01
'adam': torch.optim.Adam, # default lr=0.001
'adamax': torch.optim.Adamax, # default lr=0.002
'asgd': torch.optim.ASGD, # default lr=0.01
'rmsprop': torch.optim.RMSprop, # default lr=0.01
'sgd': torch.optim.SGD,
}
opt.model_class = model_classes[opt.model_name]
opt.dataset_file = dataset_files[opt.dataset]
opt.inputs_cols = input_colses[opt.model_name]
opt.initializer = initializers[opt.initializer]
opt.optimizer = optimizers[opt.optimizer]
opt.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') \
if opt.device is None else torch.device(opt.device)
log_file = '{}-{}-{}.log'.format(opt.model_name, opt.dataset, strftime("%y%m%d-%H%M", localtime()))
logger.addHandler(logging.FileHandler(log_file))
ins = Instructor(opt)
ins.run()
if __name__ == '__main__':
main()
参数list
model Config :
“attention_probs_dropout_prob”: 0.1,
“finetuning_task”: null,
“hidden_act”: “gelu”,
“hidden_dropout_prob”: 0.1,
“hidden_size”: 768,
“initializer_range”: 0.02,
“intermediate_size”: 3072,
“layer_norm_eps”: 1e-12,
“max_position_embeddings”: 512,
“model_type”: “bert”,
“num_attention_heads”: 12,
“num_hidden_layers”: 12,
“num_labels”: 2,
“output_attentions”: false,
“output_hidden_states”: false,
“output_past”: true,
“pad_token_id”: 0,
“pruned_heads”: {},
“torchscript”: false,
“type_vocab_size”: 2,
“use_bfloat16”: false,
“vocab_size”: 30522
Parameters in True:
loading weights file https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-pytorch_model.bin from cache at C:\Users\Administrator\.cache\torch\transformers\aa1ef1aede4482d0dbcd4d52baad8ae300e60902e88fcb0bebdec09afd232066.36ca03ab34a1a5d5fa7bc3d03d55c4fa650fed07220e2eeebc06ce58d0e9a157
cuda memory allocated: 439071232
n_trainable_params: 109484547, n_nontrainable_params: 0
> training arguments:
>>> model_name: bert_spc
>>> dataset: restaurant
>>> optimizer: <class 'torch.optim.adam.Adam'>
>>> initializer: <function xavier_uniform_ at 0x000002B8894F90D0>
>>> learning_rate: 2e-05
>>> dropout: 0.1
>>> l2reg: 0.01
>>> num_epoch: 3
>>> batch_size: 16
>>> log_step: 5
>>> embed_dim: 300
>>> hidden_dim: 300
>>> bert_dim: 768
>>> pretrained_bert_name: bert-base-uncased
>>> max_seq_len: 80
>>> polarities_dim: 3
>>> hops: 3
>>> device: cuda
>>> seed: None
>>> valset_ratio: 0
>>> local_context_focus: cdm
>>> SRD: 3
>>> model_class: <class 'models.bert_spc.BERT_SPC'>
>>> dataset_file: {'train': './datasets/semeval14/Restaurants_Train.xml.seg', 'test': './datasets/semeval14/Restaurants_Test_Gold.xml.seg'}
>>>
把这个cuda 给它利用起来!
下载命令行见官网:
https://pytorch.org/
Some Q in coding part :
对于各个参数的理解:
embed_dim: 嵌入层的维度,默认为 300 , howhidden_dim: 隐藏层的维度,默认为 300, howSRD: 语义相对距离(Semantic-Relative-Distance),LCF-BERT 模型的一个参数,默认为 3。
Result in Restarunt
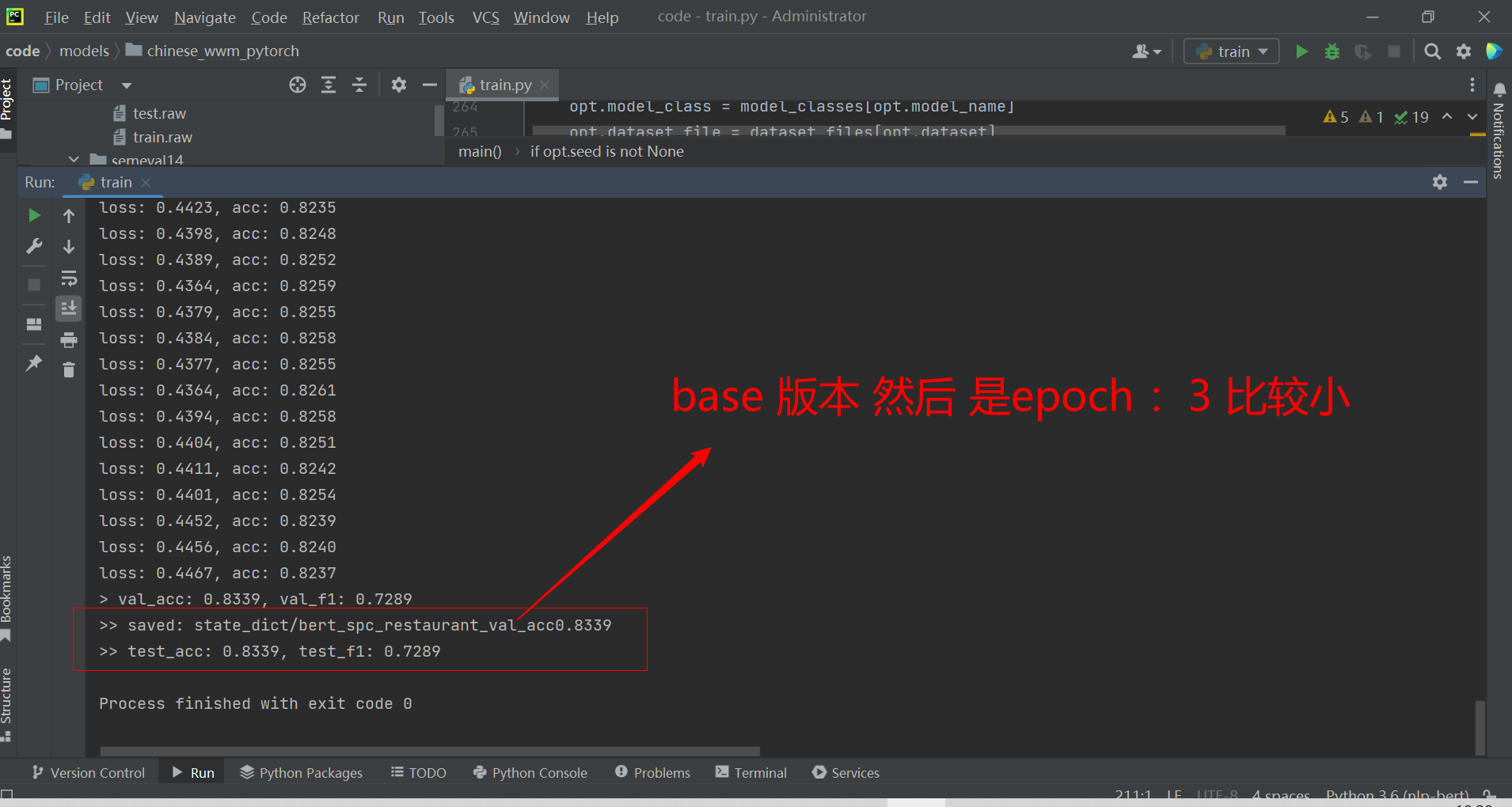
More Thinking
接下来有时间可以考虑做一个中文的情感细粒度分类,和数据的可视化展示; 以及分析一下最新的Bert 的改进论文 and 修改一下前馈(Fine Turing)
预期的难点和挑战:
- 分词
- 中文的好一点的数据(这个好像Hugging Face 的官网上也有)
- 论文part 的工作
相关论文:
链接:https://pan.baidu.com/s/1eeHn0hVB8HHyrHzWLZc-EQ?pwd=qooh
提取码:qooh
–来自百度网盘超级会员V5的分享














 2132
2132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









