







经过隐语多次课程学习之后,有一种很强烈的感觉,就是“可证安全”的特质是隐语团队对于隐私计算技术诸多特性中最为看重的要点。在数据可信流通、联合建模算法等多场景都提到了“可证安全”。隐语体系中非常关键的诸多机器学习算法(SS-XGB、SS-GLM、SS-大模型推理)以及隐私SCQL等都实现了可证安全,而作为这些算法实现的强有力支撑的就是密态引擎SPU。
本笔记会从SPU是什么、为什么要用、怎么实现、怎么用、用在哪五个方面进行介绍。隐语的课程主要是围绕SPU论文进行分享的,可以参考下SecretFlow-SPU: A Performant and User-Friendly Framework for Privacy-Preserving Machine Learning
一、SPU是什么
隐语SPU是一个用于隐私保护机器学习(PPML)的高效且用户友好的框架。SPU的全称是SecretFlow-SPU,它旨在通过结合安全多方计算(MPC)技术,为多个实体之间的协同机器学习提供隐私保护。SPU由前端编译器和后端运行时组成,允许用户在不泄露各自私有数据的情况下,共同计算和训练机器学习模型。
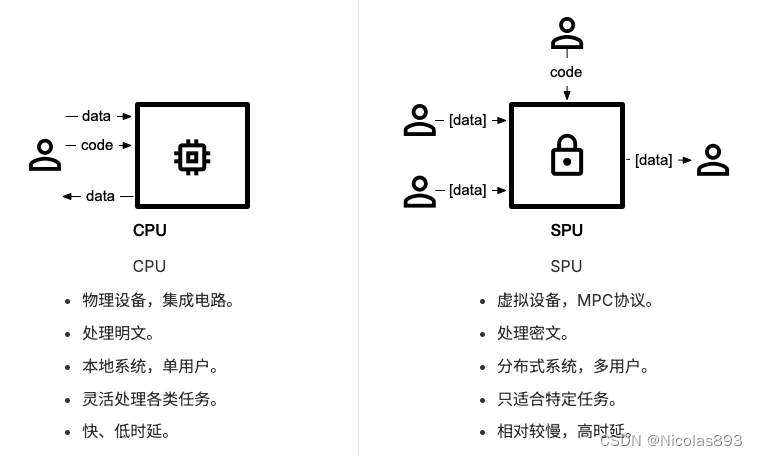
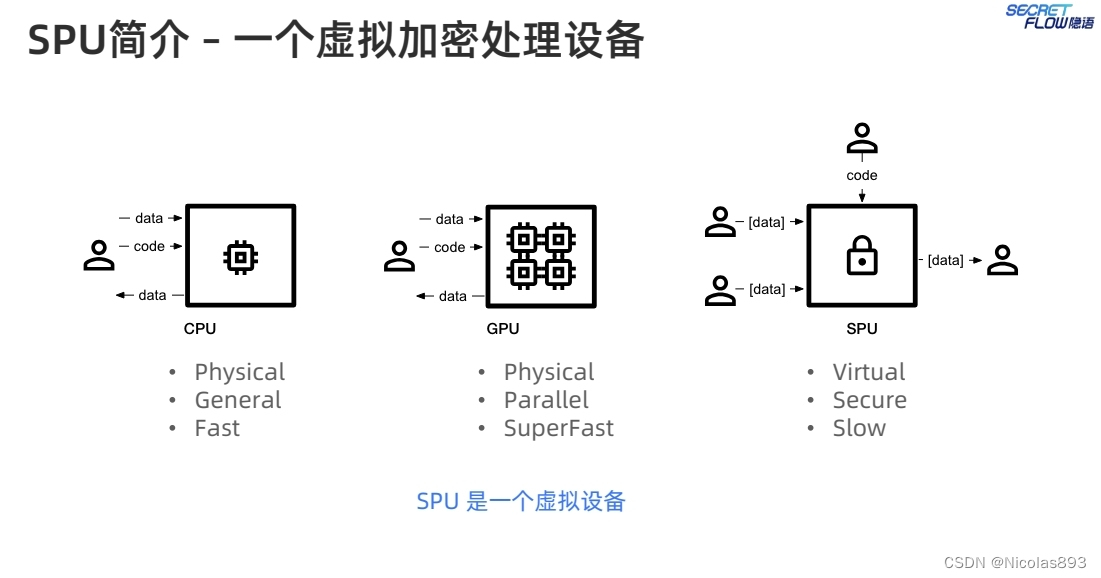
SPU,就像其他处理器(processing unit)一样接受代码和输入数据,并且得到输出数据。但是和其他处理器不同的是,SPU可以保护用户的隐私。尽管SPU和CPU不能直接比较,但是从编程者的视角来说,可以做一个类比。
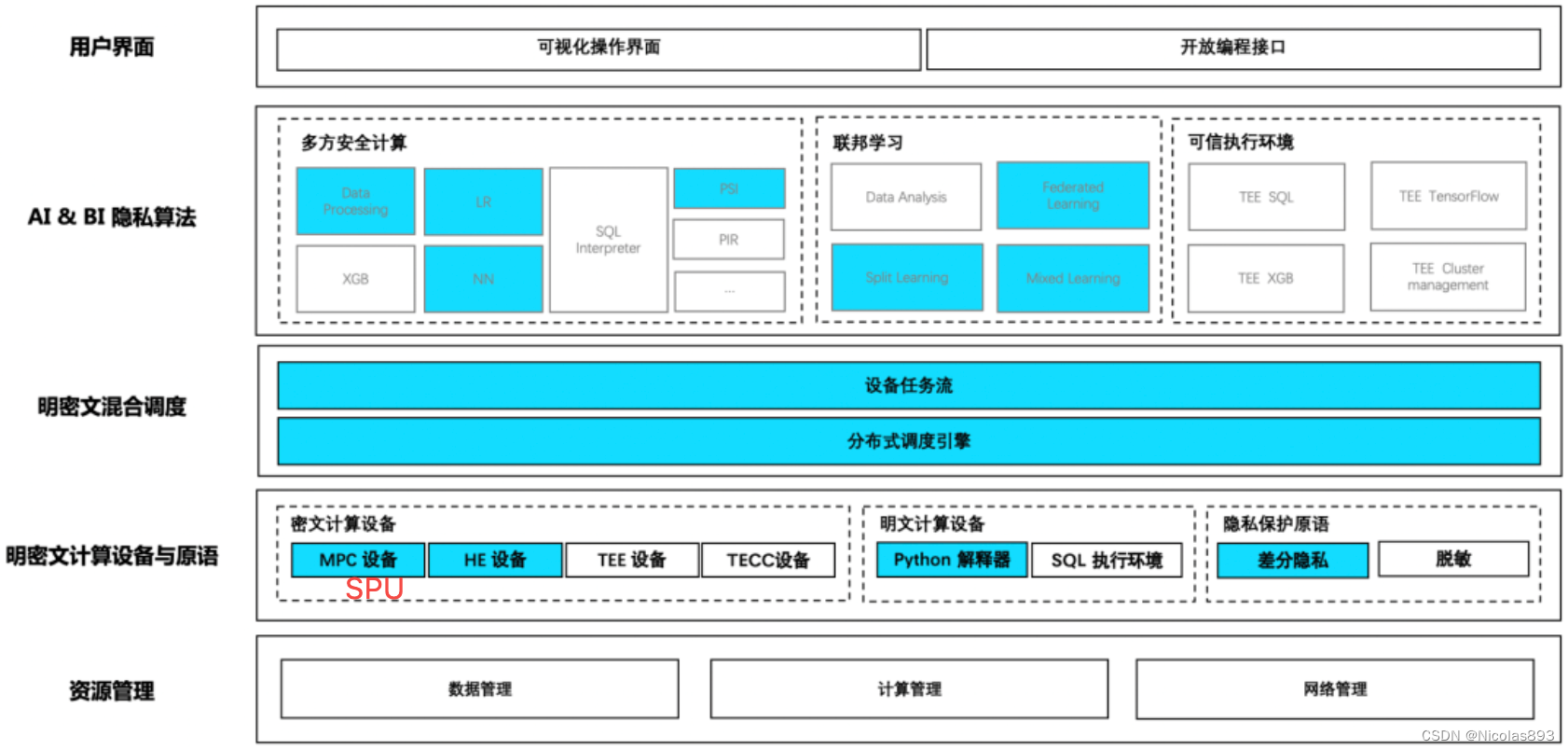
从整体分层架构看,SPU处于明密文计算设备与原语层,支撑密文计算设备中的MPC设备能力。
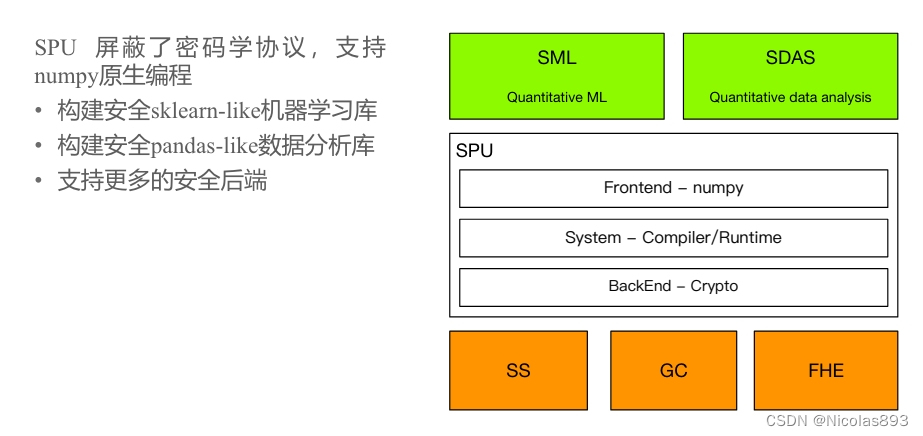
SPU屏蔽了底层复杂的加密协议,可以直接使用熟悉的numpy进行编程,无需关心加密实现细节。基于SPU的能力,未来可以提供类似sklearn的安全机器学习库以及构建类pandas的安全数据分析库,这个也是自己一直想做的,还是蛮期待的。
二、为什么要用SPU
要回答这个问题,需要从业务以及环境背景、技术路线选择等角度出发。
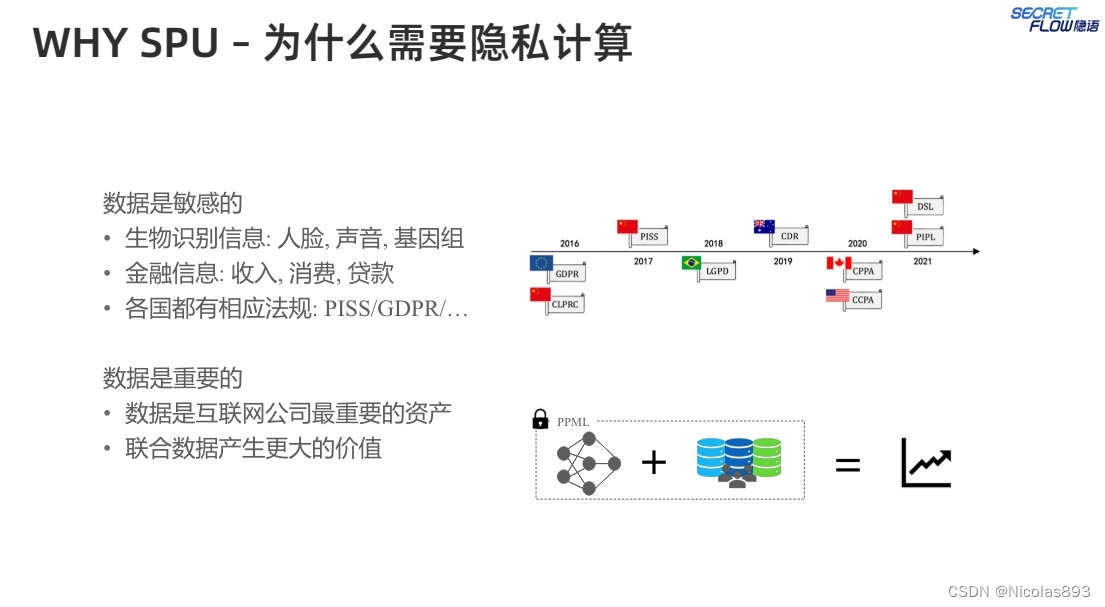
随着公众对数据安全和隐私保护的关注不断增加,隐私保护机器学习(PPML)近年来成为研究热点。安全多方计算(MPC)允许多方在不泄露敏感数据的情况下共同计算函数,为PPML提供了一种可行的解决方案。然而,对于没有密码学背景的用户来说,使用MPC技术开发高效的PPML程序是一个巨大的挑战。
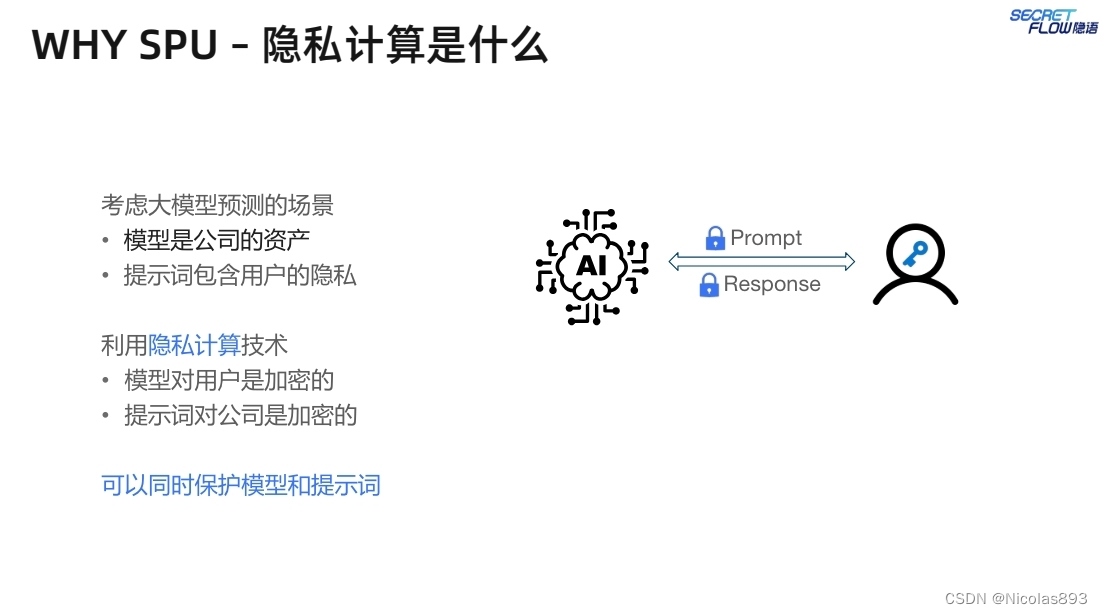
这里以大模型的推理场景为例,提示词往往会包含敏感的用户隐私信息,因此对于用户而言,希望能够将提示词进行加密,不对大模型服务提供者暴露明文信息。同样的,大模型在训练过程中会使用超大量的数据,大模型本身就是一种重要的资源,模型提供方也希望保护其模型的参数不被用户获取,确保用户无法直接访问或理解模型的内部细节。
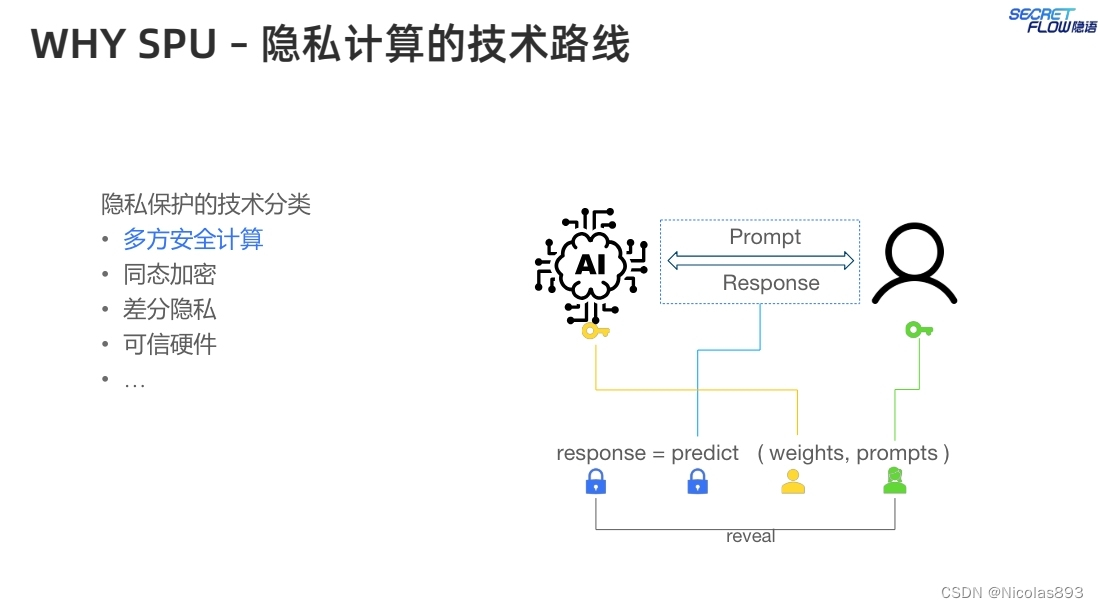
可以采用的技术路线有多种,目前从计算性能、可证安全保证等方面,相对比来说,多方安全计算(MPC)会更加突出。这里描述一下大概的计算流程:
1. 输入数据处理
1.1 数据加密
数据提供方(用户)将其输入数据进行加密,通常采用**秘密分享(Secret Sharing)**方法:数据X被分割成n个分享(shares),X1, X2, ..., Xn,每个分享由一个参与方持有。
这些分享的集合能够重构原始数据,但单个分享不能泄露原始数据。
1.2 秘密分享
用户将这些分享分别发送给各个计算方(可能包括云服务提供商和其他独立的第三方)。2. 加密模型分发
2.1 模型加密
模型拥有方将模型参数进行加密处理,同样采用秘密分享的方式,将模型参数W分割成n个分享W1, W2, ..., Wn,每个分享由一个计算方持有。2.2 秘密分享
模型拥有方将这些模型参数分享分别发送给各个计算方。3. 密态推理过程
3.1 分布式计算
各计算方根据收到的输入数据分享和模型参数分享,独立进行局部计算。例如,如果模型是一个简单的线性模型Y = WX:各计算方计算Yi = Wi * Xi(这里的乘法和加法操作是在秘密分享下进行的,通常涉及到一些加密计算协议)
3.2 中间结果通信
各计算方之间通过加密通信渠道,交换中间计算结果,以进行必要的合并和进一步计算。3.3 合并结果
计算方将中间结果进行合并,得到加密的推理结果。这个结果通常还是分布在多个计算方之间的部分数据。4. 结果重构
4.1 结果分享
各计算方将其持有的推理结果分享发送给结果接收方(通常是数据提供方)。4.2 结果解密
数据提供方接收所有的推理结果分享,通过秘密分享的重构算法,将这些分享合并,解密得到最终的推理结果Y。
安全多方计算(MPC)是一种密码技术,使多个方可以在不泄露各自私有输入的情况下共同计算函数,为有强隐私关注的机器学习用户提供了一个可证明且实用的解决方案。然而将MPC技术应用于机器学习应用程序具有很大的挑战,因为这两个领域本质上存在差异。MPC专家主要关注为低级计算原语设计高效的密码协议。而机器学习从业者则更习惯于使用封装常用的机器学习模块构建高级模型。因此,对于没有密码学专业知识的机器学习用户来说,在现实场景中高效地实现复杂的PPML任务构成了巨大的障碍。
在SPU推出之前,业内、学术界提出了一系列工作。EzPc、ABY、MP-SPDZ等设计了领域特定语言(或使用高级语言)提供通用的MPC编译器,并支持MPC上的任意计算。这些工作显著降低了开发MPC程序的难度,并允许进行MPC特定的编译优化。然而,这些工作在API设计上与主流机器学习框架仍有显著差距,因此在开发复杂机器学习程序的用户友好性方面存在不足。
TF Encrypted和CrypTen在这方面更进一步,提供了具有MPC实现的通用机器学习接口。这些工作模仿现有机器学习框架的API设计(如TensorFlow和PyTorch)以隐藏底层的MPC密码细节,获得了更高的用户友好性。不过使用起来依然还是不够友好。以CrypTen为例:给定一个预定义的PyTorch模型,用户必须手动重写模型训练/预测程序,通过将PyTorch张量、损失函数和优化器替换为CrypTen对应部分。此外,这些框架依赖TensorFlow或PyTorch作为其底层运行时,缺乏MPC领域特定知识进行编译优化。
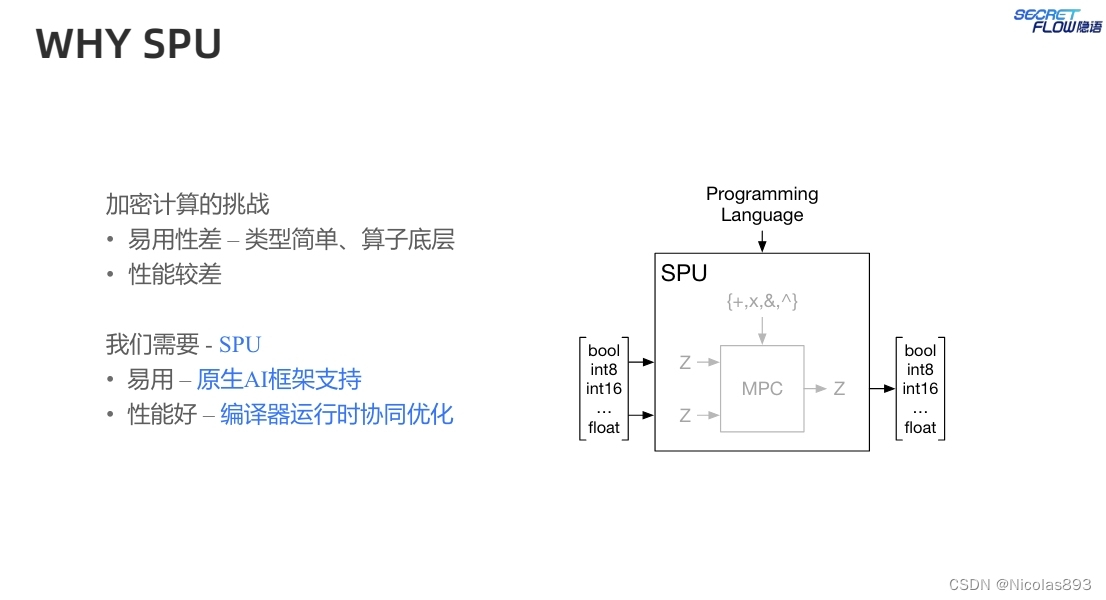
基于上述背景,隐语推出了SPU。SPU主要用于跨不同实体之间协同训练机器学习模型,当然也可以用于联合的数据分析,这些实体对彼此不完全信任并且有隐私保护需求。假设参与方遵循半诚实模型,即他们会按照协议执行但试图从中获取额外信息。此外,还假设参与方的通信通道是安全的,可以防止被动窃听和篡改。SPU的高效性和易用性通过一系列实验得到了验证,支持不同主流ML框架的MPC启用的PPML框架,大大加速了PPML应用程序的开发、测试、调试和部署。
三、SPU怎么实现
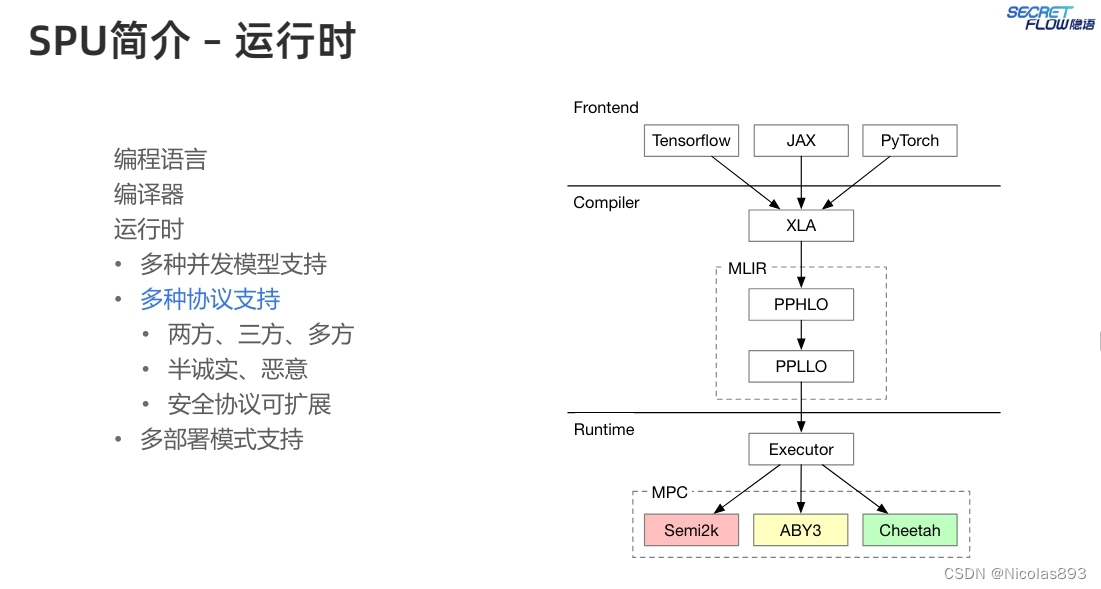
SPU由前端、编译器和后端运行时三部分组成。前端支持多种现有的机器学习框架语言,编译器接受机器学习程序并将其转换为MPC特定的中间表示(IR)PPHLO。经过一系列优化后,IR在后端运行时作为MPC协议执行。其中SPU编译器将Python编码转化为蕴含隐私保护语义的二进制文件。SPU runtime执行这些二进制文件并得到结果。
SPU提供了Python API,开发人员可以使用这些API来编写PPML程序。这些API与主流机器学习框架如JAX的API设计类似,以减少学习成本并提高开发效率。
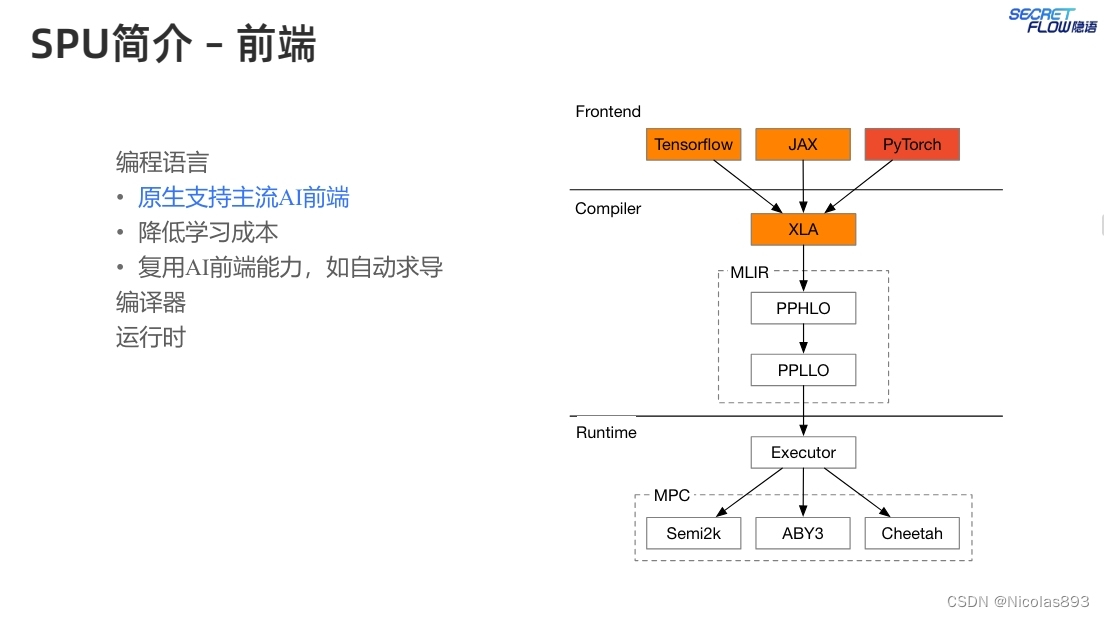
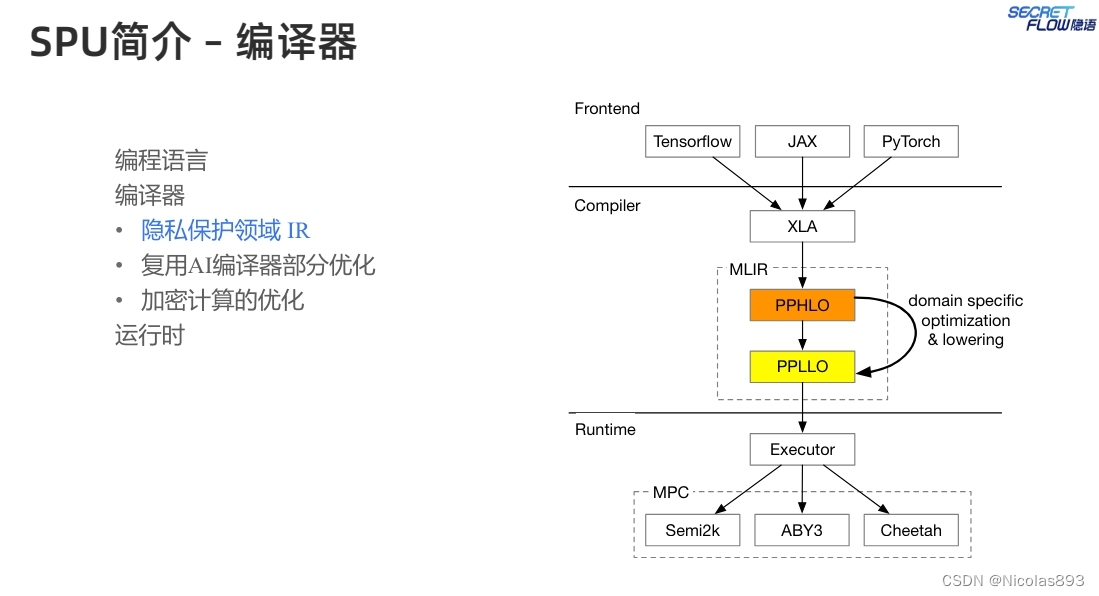
SPU核心之一为编译器,编译器可以将一种编程语言的代码翻译成另一种语言的代码。SPU编译器在设计时考虑了几个要点,包括(1)复用机器学习前端框架,减少用户学习成本,因此选择 XLA 作为SPU编译器的源语言,因为很多AI框架可以将Python代码翻译成XLA IR。利用XLA,可以原生支持这些AI框架。(2)复用机器学习编译器功能,减少重复的工作,选择 MLIR 作为编译器基建。可以复用很多与平台无关的优化和降级或下沉过程。(3)为MPC后端优化,产生适合MPC协议的二进制代码,在类型系统中添加安全相关的类型提示,这些类型提示有助于实现高效率的二进制代码。
基于HLO设计PPHLO,作为SPU的定制IR,因为HLO缺乏MPC相关的语义,无法进行优化和高效执行。一般来说,PPHLO表示一个由一系列操作组成的计算图。每个操作的输入和输出都是张量。张量类型系统是PPHLO与其他机器学习对比中最显著的差异。在PPHLO中,一个张量的类型可以通过一个三元组<Shape, Data Type, Visibility>来表示。Shape是张量的维度。至于数据类型,PPHLO目前支持布尔值、整数和定点数。可见性是PPHLO中独特的张量属性。它可以是秘密的或公开的。秘密意味着张量需要被保护,其真实值对SPU后端节点是不可见的。相反,公开意味着张量不需要被保护,任何后端节点都可以获取其值。对于PPHLO中的每个操作,使用以下规则根据输入类型确定输出类型(这里不考虑形状,因为它由操作语义决定)。1) 数据类型提升:如果操作数之一是定点数,结果也是定点数;2) 可见性缩小:如果操作数之一是秘密,结果也是秘密。根据这两条规则,可以推导出PPHLO中所有张量的类型。
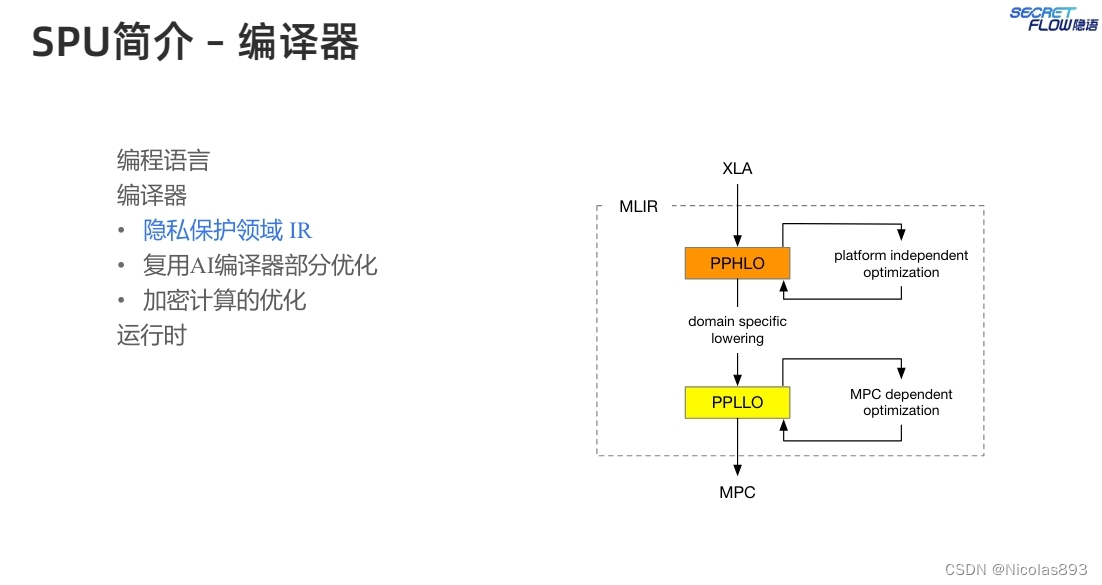
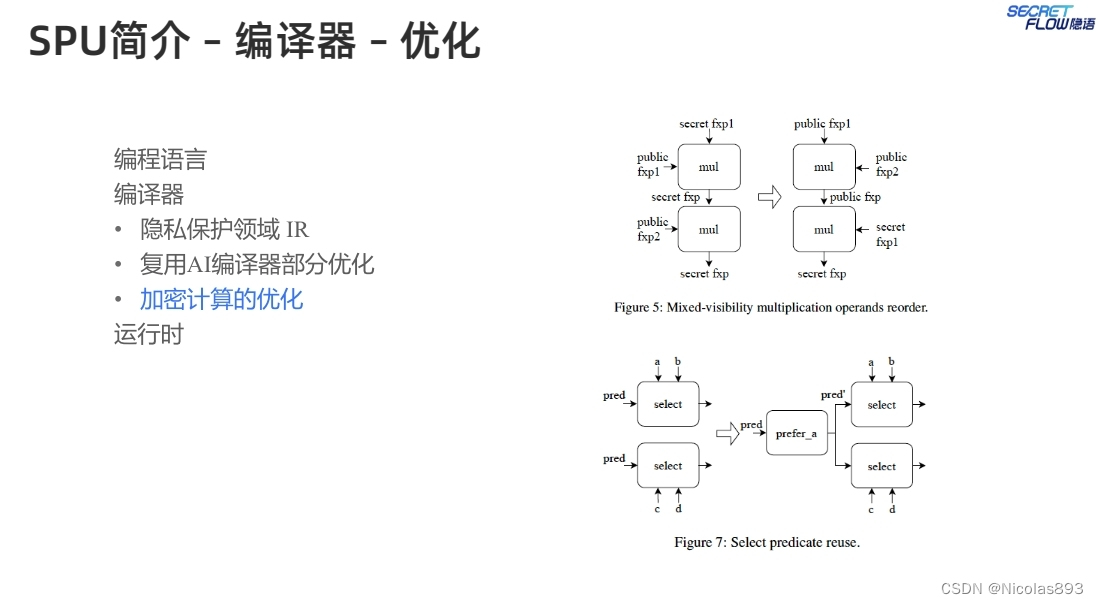
编译器能够对加密计算流程进行优化,比如归并一些明文计算,使得密文计算次数减少。举两个例子进行说明:(1)混合数据类型乘法融合,在常规机器学习计算中,当将一个整数与一个小数相乘时,会首先调用一个转换操作,将该整数转换为浮点数。然后,乘法操作可以分派给浮点乘法内核。而在SPU中直接使用该图,整数将首先被转换为定点数,然后进行定点乘法,这需要截断操作以保持小数位。然而,整数可以直接与定点数相乘。因此,可以将这两个操作融合为一个乘法操作,以减少冗余的截断和转换。这种优化也适用于其他类似操作,例如点积运算。(2)混合可见性乘法操作数重排,可以优化截断的场景是混合可见性连续定点数的相乘。一个秘密定点数与两个公开定点数相乘涉及两个乘法操作。每个操作都会生成一个需要截断的秘密乘积,而在某些MPC协议下,这种截断具有很高的通信开销。然而可以在不影响正确性的情况下重排操作数。首先计算两个公开定点数的乘积,该乘积也是公开的,因此可以通过本地移位来截断结果。然后使用该结果与秘密定点数相乘。通过重排乘法操作数,可以节省一次昂贵的截断操作。
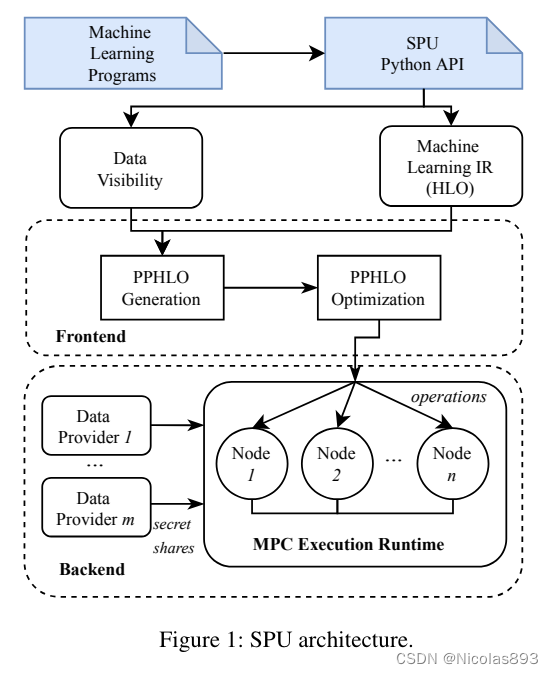
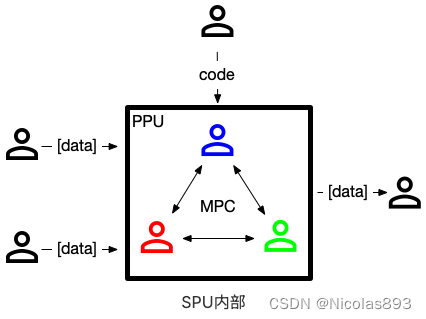
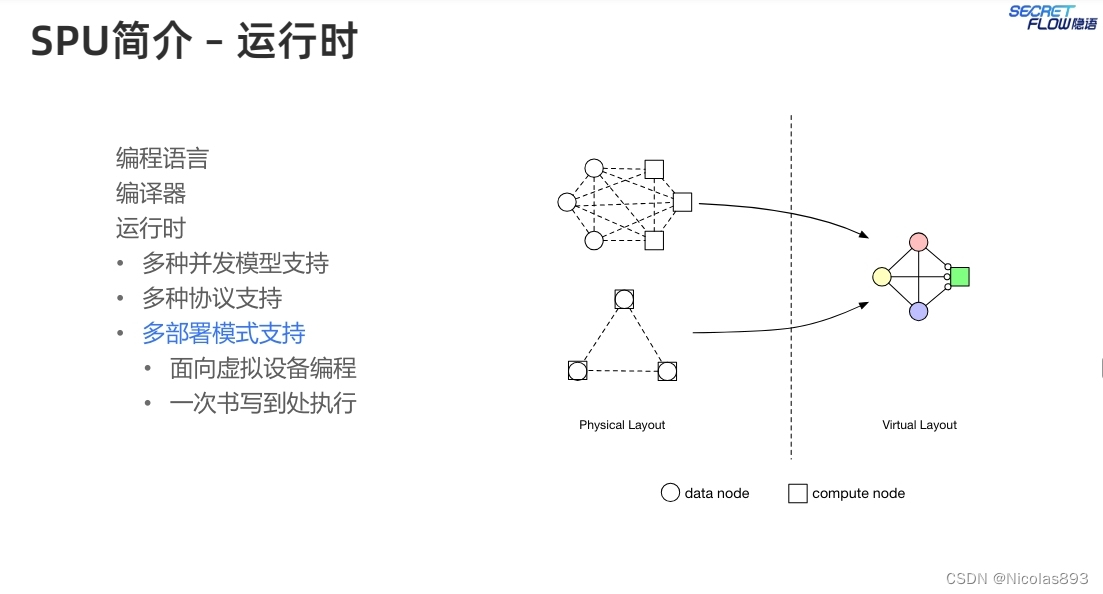
SPU另一核心为运行时。运行时是一个用多个不相互信任的物理节点组成的虚拟设备。在SPU中,多个物理设备同时执行一个MPC协议,在完成特定计算任务的同时保护数据隐私。从外面看,多个物理设备形成了一个虚拟设备并且提供了通用计算服务。
模型示意图如下
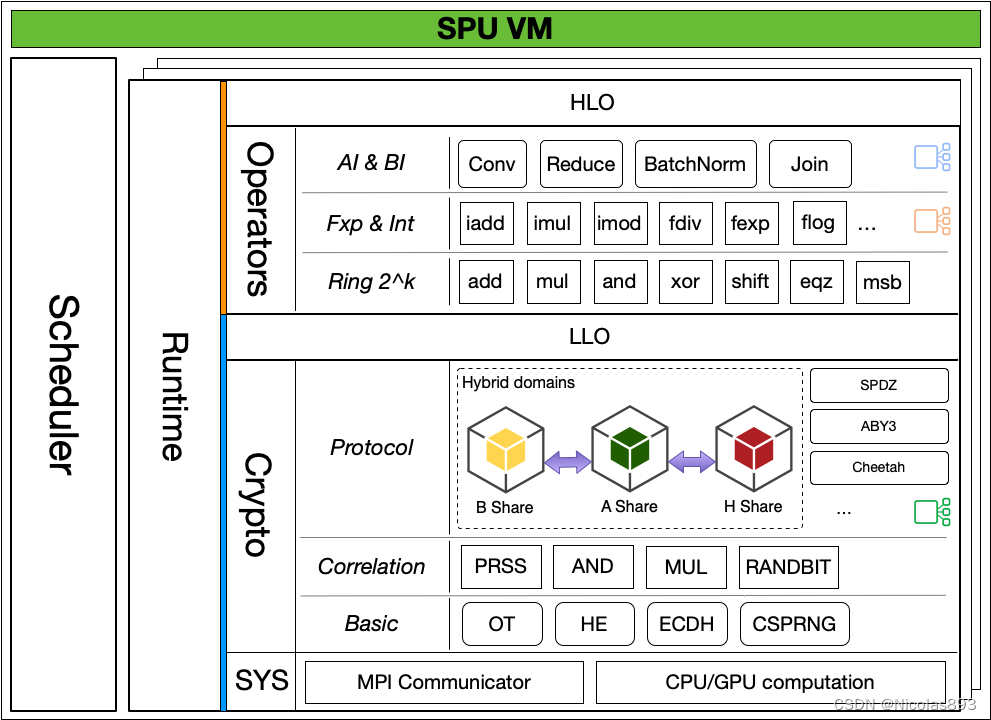
作为一个虚拟机,SPU运行时是一个多层的结果,将SPU二进制程序逐层分解至最底层的密码学原语,并且提供了并行和调度能力。
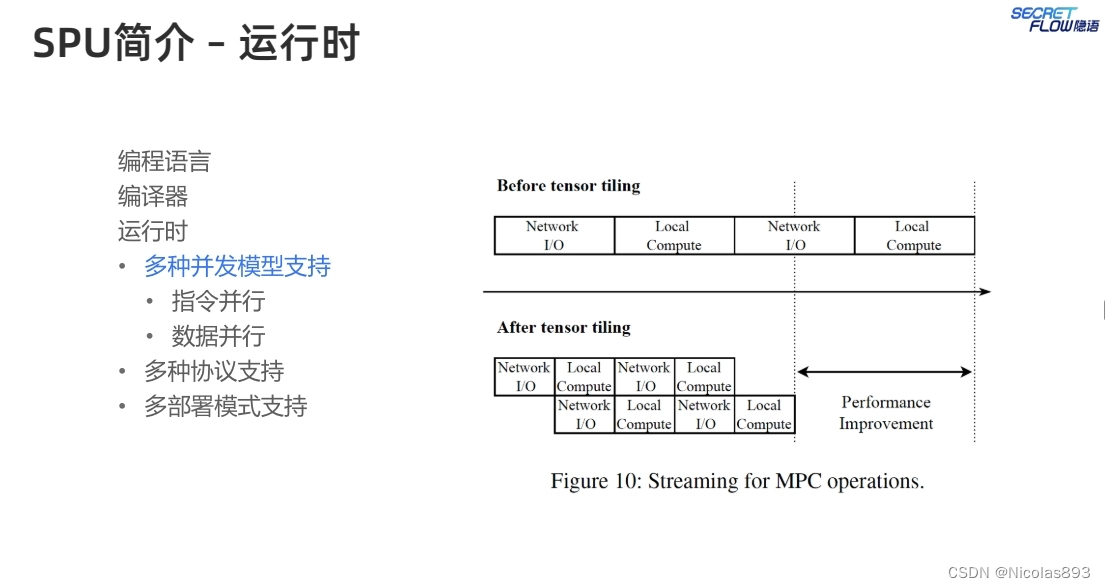
运行时支持多种并发模型,提升处理性能。SPU通过对数据列表执行一个操作来减少执行操作的数量,从而实现了类似的向量化机制。例如,有两个操作mul(a,b)和mul(c,d),其中mul表示逐元素乘法操作,a、b、c、d是张量。SPU会将a、b和c、d一起打包,对这些张量执行一个mul操作。由于MPC(多方计算)乘法需要通信,SPU可以通过向量化减少通信轮次的数量。
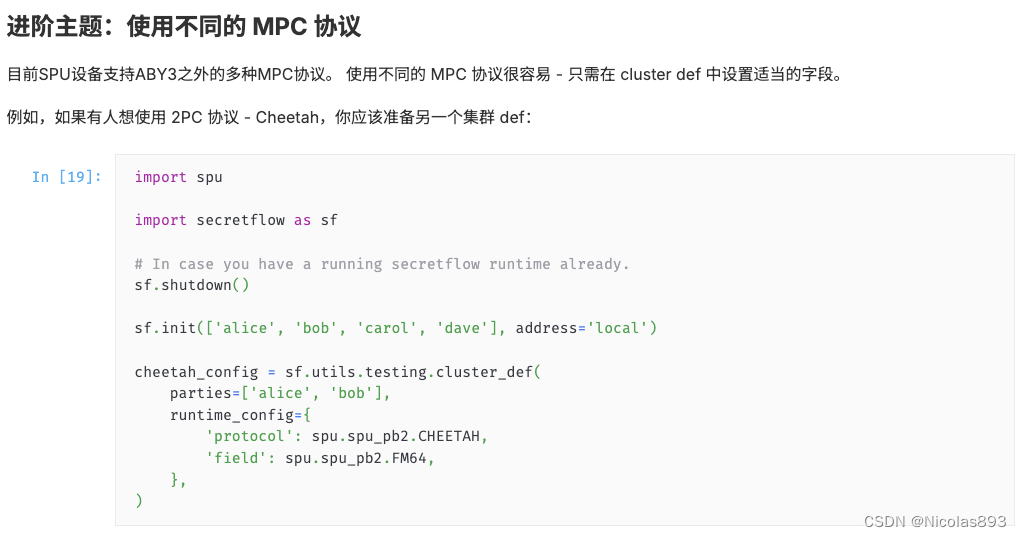
此外SPU支持两方协议(Cheetah)、三方协议(ABY3)、多方协议(Semi2k),可以根据具体场景选择最合适的协议。
SPU支持多种部署方案,比如数据节点同时也作为计算节点的模式,也可以支持算力外包的mpc模式。
四、SPU怎么用
这里展示了密态比较场景的编程界面,要比较x与y的大小,解决百万富翁问题。整体操作是简单的。初始化后端的SPU节点和数据提供者(即P0和P1分别代表Alice和Bob)。指定数据来自P0和P1,这意味着这两个函数只能在P0和P1上本地执行。派生结果是需要在SPU上保护的私有数据。指定函数compare是私有的,并应在SPU上执行。比较Alice和Bob的数据。变量x和y将被SPU自动获取为秘密共享,并且比较结果z也是秘密共享。为了获得z的明文结果,开发人员应使用ppd.get()来重建z。

支持清晰的日志流程进行debug排查错误。

修改配置信息即可切换协议等,这里列出了aby3和cheetah协议的配置信息。

更多的使用细节可以参考:SecretFlow
五、SPU用在哪里
这里列出了一些应用案例,特别是在大模型场景中有成功的应用探索,但性能还无法满足商用,值得继续探索。MPC因其通信代价较大,因此在应用的时候,可以根据实际情况,采用最小化MPC的模式,比如采用明密文混合计算、多种隐私计算技术混合使用等方式。MPC作为一种通用的计算协议,应用前景还是很广的,期待未来更多优秀的应用案例。






















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











