







1. “人类对齐(Human Alignment)”背景介绍
本文主要针对大模型训练过程中的PPO(Proximal Policy Optimization)、DPO(Direct Preference Optimization)等概念进行解释和分析,更确切的说是在“人类对齐(Human Alignment)”阶段涉及的技术。尽管大模型在文本生成表现出很强的能力,但这些模型有时会出现错误或具有危害性的行为,比如生成虚假信息、产生有误导性以及带有偏见的结果。在大模型的预训练和有监督微调的过程中,训练目标是根据上下文内容来预测下一个词元。但是,这一过程并未充分考虑人类的价值观或偏好(使用的语料数据在价值观层面参差不齐),可能导致大模型从数据中学习到不符合人类期望的生成模式。其实这种问题,在大模型盛行之前,都会考虑到,特别是商用系统中的对话机器人,产生的结果不能是让人厌恶的。为了规避这些潜在风险,相关组织提出了“人类对齐”这一关键概念,预期是保证大模型的行为与人类期望和价值观相一致。
2. 强化学习基础概念以及与NLP的结合思考
2.1 强化学习基础
在谈具体的技术之前,首先需要了解一下关于强化学习的基本概念和应用,强化学习的分类体系【1】:

另外也可以看下我们之前的文章《强化学习RL与大模型智能体》、《基于Multi-Armed Bandits的个性化push文案自动优选算法实践》,形成初步的概念。强化学习离不开Environment、State、Policy、Action、Reward这五个关键因素。从Policy层面,强化学习可以分为Online-policy以及Offline-policy。Online Policy在强化学习中是指模型在与环境进行实时交互的过程中,根据当前所处的状态直接生成和调整其动作的策略,通俗一点讲就是模型边参与边学习(同一个模型)。而Off-policy在强化学习中是指在模型与环境交互之前,通过事先收集的大量经验或数据来进行策略学习和优化的过程,简单来说,就是模型边看边学(实际交互的模型与学习的模型不是同一个),因此与在线策略不同,离线策略的训练过程并不依赖于与环境的实时交互,而是基于固定的历史数据集。
2.2 强化学习与NLP的结合思考
让我们来看几个关于NLP与RL的问答【2】,思考一下,强化学习与NLP的结合原因、方式以及挑战。
问:在NLP中,RL代表什么?
答:RL(强化学习)在NLP中的应用是指将RL方法应用于NLP模型的训练和优化,以生成或理解自然语言。对于NLP,强化学习可以被视为一种监督学习类型,其中奖励函数评估输出质量,而不是依赖预先定义的标签来提供反馈。例如,在对话系统中,奖励系统可以评估用户满意度、系统响应,以及对话的连贯性和相关性。
问:为什么在NLP中使用RL?
答:在NLP中,RL在许多方面比基于规则或统计的方法更具优势。它可以通过试验不同的行为和结果,并从错误中学习,来处理歧义和不完整的信息。它还能通过从在线反馈和自我改进中学习,适应变化的环境和用户偏好。此外,RL在NLP中可以通过在利用现有知识与探索新方法之间取得平衡,生成更多创新性结果,避免重复,并通过考虑行动的长期影响来优化长期目标,而不仅仅是短期收益。
问:RL在NLP中面临哪些挑战?
答:在NLP中构建基于RL的模型存在一些挑战和限制。需要设计一个合适的奖励函数,该函数应具有可扩展性、信息性,并且能够一致地捕捉预期的行为和目标。此外,由于奖励有限且延迟,学习过程可能会变得缓慢和不稳定,因此需要有效的探索技术。离散且高维的动作空间可能会带来高昂的计算成本,影响策略优化和动作选择。
现在,让我们继续分析下强化学习在NLP(大模型)中的作用:
1. NLP任务中的目标是生成符合人类喜好的反馈。在人类反馈强化学习(RLHF)中,我们希望模型能够根据人类的偏好,生成高质量的响应。具体来说,给模型一个prompt,期望它生成的文本符合人类的价值观,例如,确保回复有礼貌、逻辑合理、符合上下文等。
2. GPT模型的生成过程是自回归的,每次只生成一个token,并且每个token的生成依赖于之前生成的tokens,也就是模型先根据prompt生成第一个token,再根据prompt加上第一个token生成第二个token,依次类推。
3. 结合强化学习的框架,NLP任务可以理解为一个逐步决策过程,强化学习中的基本概念(如状态、动作、奖励等)可以映射到NLP任务的具体操作中:
动作(Action):在强化学习中,动作是智能体(大模型)在某个状态下做出的选择。在NLP任务中,动作空间对应于词表(Vocabulary),即模型在每个时刻从词表中选择一个token输出。每次模型生成一个token,相当于执行了一个动作。
状态(State):强化学习中的状态描述了环境的当前情况。在NLP语境中,状态可以被理解为模型已经生成的token序列,或者说是当前上下文。每生成一个新的token,状态就从“之前的上下文”转变为“更新后的上下文”(即上文 + 新生成的token)。
即时收益(Reward):当模型生成一个新的token时,可以得到即时收益。即时收益反映了模型的输出与人类偏好的匹配程度。例如,一个token是否让生成的句子更符合语义或语法要求。通常,这个即时奖励可以通过一个打分函数来量化,如人类反馈打分、或通过一个辅助模型来评估。
总收益(Cumulative Reward):在强化学习中,总收益是对未来所有可能收益的折现和。对于NLP任务来说,总收益不仅包括当前生成token的收益,还包括后续token的收益,反映了当前选择(token生成)对未来生成序列的潜在影响。模型需要考虑不仅当前的生成质量,还要预测生成未来整个句子的质量。
3. 基于人类反馈的强化学习
3.1 RLHF的标准及流程
奖励模型的主要功能是为强化学习过程提供反馈信号,反映人类对语言模型生成文本的偏好,通常以标量形式呈现。该模型可以通过人类偏好数据微调已有的语言模型,也可以基于这些数据重新训练一个全新的模型。目前的研究普遍认为,使用与待对齐模型规模相当或更大的奖励模型可以获得更好的对齐效果。这是因为更大规模的奖励模型能够更好地理解待对齐模型的知识和能力范围,从而提供更合适的反馈信号。例如,LLaMA-2 使用相同的检查点来初始化待对齐模型和奖励模型。
在训练过程中,RLHF通过奖励模型提供的反馈信号,使用强化学习算法对大模型进行优化。目前,PPO(Proximal Policy Optimization)算法 【5】是常用的人类对齐任务强化学习算法。

监督微调: 为了使待对齐的语言模型具备良好的指令遵循能力,首先需要收集高质量的指令数据进行监督微调,关于指令微调可以参考《大模型微调之指令微调》。指令数据通常包括任务描述及相应的示例输出,可以由人类标注员为特定任务编写,或者由大模型自动生成。
奖励模型训练: 第二步是通过人类反馈数据来训练奖励模型。具体过程如下:首先,语言模型根据任务指令生成若干候选输出,接着标注员对这些输出进行偏好标注。常用的方法是对候选输出进行排序,这可以减少标注员之间的偏好不一致性。然后,利用这些人类偏好数据来训练奖励模型,使其能够有效建模人类偏好。
强化学习训练: 最后一步是将语言模型的对齐问题转化为强化学习问题。待对齐的语言模型作为策略模型,负责接收提示并生成输出文本。模型的动作空间为词汇表中的所有词元,状态则是已生成的词元序列。奖励模型基于当前的语言模型状态提供奖励分数,用于指导策略模型的优化。为了防止训练过程中语言模型偏离其初始状态,通常会在优化目标中加入惩罚项(如 KL 散度)。例如,在 InstructGPT 中,PPO 算法被用于优化语言模型,以最大化奖励模型的评分【6】。每个提示的生成结果都会通过计算当前模型与初始模型之间的 KL 散度来确定惩罚力度,KL 散度越大,表示当前模型偏离初始模型越远。这个对齐过程反复迭代,从而逐步优化模型的对齐效果。
3.2 强化学习PPO( Proximal Policy Optimization)
有了前述内容的铺垫,我们终于进入到PPO算法的介绍。在强化学习过程中,大模型(智能体)根据外部环境的反馈来决定下一步的行动,因此被称为策略模型。在第 t 次大模型(智能体)与环境的交互中,根据当前的环境状态 选择策略并决定下一步的行动
。当大模型(智能体)采取了行动后,环境状态从
转变为新的状态
,同时环境会给出相应的奖励
。大模型(智能体)的目标是在整个交互过程中最大化所有决策路径
的累计奖励总和:
形式化来说,假设参数为 的策略模型生成的决策轨迹
的概率为
,该轨迹能获得的累计奖励为
。强化学习的目标是通过优化策略模型来最大化获得的总奖励,即:
在文本生成任务中,策略模型即大模型。它根据用户的输入和已经生成的内容(即当前状态)来生成下一个词元(即做出下一步决策)。当大模型生成完整的回复(即形成整个决策轨迹)后,标注人员或奖励模型会根据其生成的回复对其进行偏好打分(即奖励分数)。大模型需要通过学习来优化其生成策略,以便使得生成的内容尽可能符合人类的价值观和偏好,从而获得更高的奖励。
在自然语言处理场景中,生成候选词元的决策空间非常庞大,因此难以准确计算所有决策轨迹的期望奖励(即 )。为了解决这一问题,通常采用采样算法,选择多条决策轨迹,并通过计算这些轨迹的平均奖励来近似所有轨迹的期望奖励。在决策空间 T 进行采样时,目标函数会进行如下变换:
其中,代表所有可能的策略集合,𝑁 则是从策略空间
中采样得到的策略轨迹的数量。
在策略梯度算法中,策略模型与外部环境进行交互,并利用这些交互产生的数据来优化模型参数,这种方法被称为在线策略训练(On-policy)。为了确保采样得到的策略轨迹能够有效近似策略模型的决策期望,每次调整模型参数后都需要重新进行采样。因此,策略梯度算法在数据利用率和鲁棒性方面相对较低。与此不同,近端策略优化采用了离线策略训练(Off-policy),即在训练过程中,负责交互的策略模型与负责学习的策略模型是不同的。具体而言,负责学习的模型是通过另一个模型与环境进行交互后获得的轨迹进行优化的。由于使用离线策略训练时采样模型是固定的,允许同一批数据对学习模型进行多次优化,从而提高数据利用效率,使得训练过程更加稳定。这里可以参考下李宏毅老师的视频讲解【7】。

优势函数(Advantage Function)用于衡量某个动作相对于其他可能动作的相对价值。优势函数的定义通常为:
其中:
是在状态
下采取动作
的优势值。
是在状态
是在状态
在这里Q和V是价值函数,在PPO中,价值函数主要用于评估状态或状态-动作对的价值。
V值(状态价值函数/ Critic):
- V(s):表示在状态 s 下,大模型(智能体)按照某一策略执行时的预期累积奖励。反映了大模型(智能体)从某个状态开始,在未来能够获得的期望回报。
Q值(动作价值函数 / Actor) :
- Q(s, a):表示在状态 s 下采取动作 a 后,大模型(智能体)按照某一策略继续执行的预期累积奖励。它反映了在执行某个动作后,大模型(智能体)能够获得的期望回报。
通过使用优势函数,PPO可以更准确地评估动作的价值,减少策略更新的方差。通过将Q值和V值的差异计算为优势函数,PPO能够提供更具信息量的学习信号,帮助策略更快地收敛到最佳解。通过将决策的奖励与期望奖励做差,产生较低奖励的决策将会得到一个负的优势值,而产生较高奖励的决策会得到一个正的优势值。这些相对较差的决策就会被抑制,同时鼓励策略模型产生收益更高的决策。
关于优势函数的参考代码:
def compute_advantages(
self,
values: torch.FloatTensor,
rewards: torch.FloatTensor,
mask: torch.FloatTensor,
):
lastgaelam = 0
advantages_reversed = []
gen_len = rewards.shape[-1]
values = values * mask
rewards = rewards * mask
if self.config.whiten_rewards:
rewards = masked_whiten(rewards, mask, shift_mean=False)
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
returns = advantages + values
advantages = masked_whiten(advantages, mask)
advantages = advantages.detach()
return values, advantages, returns在PPO的策略更新中,会涉及到一个核心概念“重要性采样(Importance Sampling)”。在PPO中,策略的更新依赖于从当前策略(新策略)和旧策略(基线策略)收集的数据。重要性采样允许我们根据新策略的概率与旧策略的概率的比值来调整更新的权重,从而纠正由于策略变化带来的偏差。
具体而言,重要性采样是用于通过在一个分布 p 上的样本来近似另一个分布 q 的期望。特别适用于 q 难以直接计算或采样的情况。这一点让我想起变分自编码的训练过程,可以参考《生成式模型与判别式模型对比(涉及VAE、CRF的数学原理详述)》。两者都涉及通过一个易于采样的分布 p 来近似一个复杂的分布 q。在变分自编码器中,使用变分推断来优化一个简单的分布(通常是高斯分布)来近似目标后验分布,从而计算似然。具体来说,VAE使用了一个变分分布来估计潜在变量的后验,通过最大化下界来优化模型。而在重要性采样中,我们利用一个分布 p 来对目标分布 q 进行采样,以近似计算期望值。这两种方法的核心都是通过将复杂的分布转化为易于处理的形式,从而实现有效的推断和学习。这么看,它们在处理难以直接采样的情况时具有相似的策略和目的。
假设我们要计算变量 x 在分布 q 上函数 f(x) 的期望 ,可以通过将期望转化为积分形式,并建立 p 和 q 之间的关系来推导,如下所示:
可以重写为:
进一步变形为:
其中 p(x) 和 q(x) 分别是 x 在这两个分布中的概率。通过这一推导,看到在分布 q 上的期望可以通过在分布 p 上采样并乘以比例 来估计。在离线强化学习中,策略模型
与环境交互并采样决策轨迹,然后使用这些轨迹近似估算策略模型
的期望奖励。因此,可以将重要性采样应用于此情境。
根据上述推导,我们可以得出以下形式,推导的过程可以参考【7】:
这为 PPO 算法的目标函数的离线策略训练提供了基础:
需要注意的是,虽然重要性采样保证了 p 和 q 上的期望一致,但无法保证它们的方差一致。因此,为确保重要性采样的稳定性,两个分布 p 和 q 应尽可能相似,以减少方差的差异,可以根据下述的公式展开来理解方差这个事情。 
此外,PPO 算法在策略更新中引入了裁剪机制,以限制策略比率的变化,从而避免过于激进的更新。这种裁剪保证了新策略与旧策略之间的决策分布差异不会过大(即 和
之间的差异有限),增强了重要性采样的稳定性。具体定义如下:
策略损失计算参考代码:
pg_loss1 = -advantages * ratio
pg_loss2 = -advantages * torch.clamp(ratio, 1.0 - self.cliprange, 1.0 + self.cliprange)
pg_loss = torch.sum(torch.max(pg_loss1, pg_loss2) * mask) / n 在优化时,PPO选择裁剪前后的优势值中的最小值。当优势值大于 0 时,表示当前决策较优,需要提高该决策的概率(即增加
。如果比率
保持在限制范围内,目标函数中的
会促使策略增强该决策的概率。相反,当
超出限制时,为了防止新旧策略间的显著差异导致不稳定的训练,裁剪机制会控制
的更新幅度。
当优势值 小于 0 时,
保证在概率较高时,策略会学习减少该决策的概率,而裁剪后的项则确保在概率较低时不会参与优化,从而进一步保障算法的稳定性。

进一步,PPO 通过引入 KL 散度作为惩罚项来控制策略模型的更新幅度,利用KL来限制 (特指行为上的距离)的差异,两者越像越好。

具体的目标函数定义如下:
在这个公式中, 是一个超参数,能够根据训练情况进行动态调整。当 KL 散度值较小时,可以适当降低
,使策略模型更积极地更新参数,从而改善策略;反之,当 KL 散度值较大时,应增加
,以减小策略更新的幅度,确保训练过程的稳定性。通过这种方式,PPO 能够灵活地平衡探索与稳定性。
参考代码示例:
def compute_rewards(
self,
scores: torch.FloatTensor,
logprobs: torch.FloatTensor,
ref_logprobs: torch.FloatTensor,
masks: torch.LongTensor,
):
"""
从得分和KL惩罚计算每个标记的奖励。
参数:
scores (`torch.FloatTensor`):
来自奖励模型的得分,形状为 (`batch_size`)
logprobs (`torch.FloatTensor`):
模型的对数概率,形状为 (`batch_size`, `response_length`)
ref_logprobs (`torch.FloatTensor`):
参考模型的对数概率,形状为 (`batch_size`, `response_length`)
返回:
`torch.FloatTensor`: 每个标记的奖励,形状为 (`batch_size`, `response_length`)
`torch.FloatTensor`: 非得分奖励,形状为 (`batch_size`, `response_length`)
`torch.FloatTensor`: KL惩罚,形状为 (`batch_size`, `response_length`)
"""
rewards, non_score_rewards, kls = [], [], []
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
# 计算KL惩罚(基于对数概率的差异)
kl = self._kl_penalty(logprob, ref_logprob)
kls.append(kl)
non_score_reward = -self.kl_ctl.value * kl # 非得分奖励为负的KL惩罚
non_score_rewards.append(non_score_reward)
reward = non_score_reward.clone()
last_non_masked_index = mask.nonzero()[-1] # 获取最后一个未掩盖的索引
# 奖励是偏好模型得分 + KL惩罚
reward[last_non_masked_index] += score
rewards.append(reward)
return torch.stack(rewards), torch.stack(non_score_rewards), torch.stack(kls)
def _kl_penalty(self, logprob: torch.FloatTensor, ref_logprob: torch.FloatTensor) -> torch.FloatTensor:
# 根据配置计算KL惩罚
if self.config.kl_penalty == "kl":
return logprob - ref_logprob
if self.config.kl_penalty == "abs":
return (logprob - ref_logprob).abs()
if self.config.kl_penalty == "mse":
return 0.5 * (logprob - ref_logprob).square()
if self.config.kl_penalty == "full":
# 由于此问题需要翻转: https://github.com/pytorch/pytorch/issues/57459
return F.kl_div(ref_logprob, logprob, log_target=True, reduction="none").sum(-1)
raise NotImplementedError
接下来,我们来看下PPO的整个处理流程【6,8,11】:

huggingface也给了一个high level的图【9】以及PPO过程【10】:

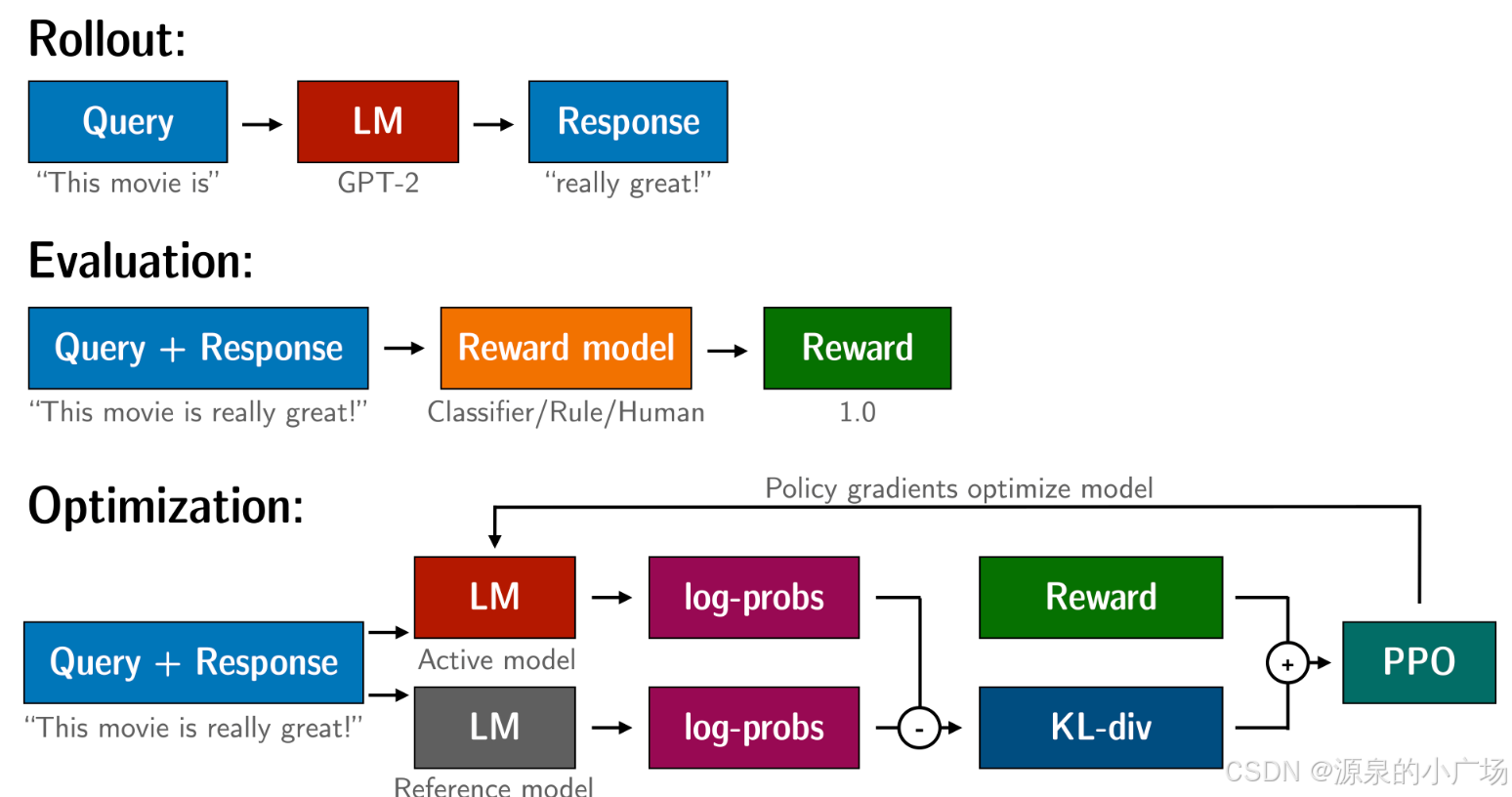
PPO总的损失函数计算参考代码:
def loss(
self,
old_logprobs: torch.FloatTensor,
values: torch.FloatTensor,
logits: torch.FloatTensor,
vpreds: torch.FloatTensor,
logprobs: torch.FloatTensor,
mask: torch.LongTensor,
advantages: torch.FloatTensor,
returns: torch.FloatTensor,
):
"""
计算策略损失和价值损失。
参数:
old_logprobs (`torch.FloatTensor`):
模型的对数概率,形状为 (`batch_size`, `response_length`)
values (`torch.FloatTensor`):
价值头的值,形状为 (`batch_size`, `response_length`)
logits (`torch.FloatTensor`):
模型的logits,形状为 (`batch_size`, `response_length`, `vocab_size`)
vpreds (`torch.FloatTensor`):
价值头的预测值,形状为 (`batch_size`, `response_length`)
logprobs (`torch.FloatTensor`):
模型的对数概率,形状为 (`batch_size`, `response_length`)
"""
# 对预测值进行裁剪
vpredclipped = clip_by_value(
vpreds,
values - self.config.cliprange_value,
values + self.config.cliprange_value,
)
# 计算价值损失
vf_losses1 = (vpreds - returns) ** 2
vf_losses2 = (vpredclipped - returns) ** 2
vf_loss = 0.5 * masked_mean(torch.max(vf_losses1, vf_losses2), mask)
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), mask)
# 计算比率
ratio = torch.exp(logprobs - old_logprobs)
# 计算策略损失
pg_losses = -advantages * ratio
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - self.config.cliprange, 1.0 + self.config.cliprange)
pg_loss = masked_mean(torch.max(pg_losses, pg_losses2), mask)
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).float(), mask)
# 总损失
loss = pg_loss + self.config.vf_coef * vf_loss
# 检查比率是否超过阈值
avg_ratio = masked_mean(ratio, mask).item()
if avg_ratio > self.config.ratio_threshold:
warnings.warn(
f"批次的平均比率 ({avg_ratio:.2f}) 超过阈值 {self.config.ratio_threshold:.2f}。跳过该批次。"
)
pg_loss = pg_loss * 0.0
vf_loss = vf_loss * 0.0
loss = loss * 0.0
# 计算熵和KL散度
entropy = masked_mean(entropy_from_logits(logits), mask)
approxkl = 0.5 * masked_mean((logprobs - old_logprobs) ** 2, mask)
policykl = masked_mean(old_logprobs - logprobs, mask)
# 计算返回值的均值和方差
return_mean, return_var = masked_mean(returns, mask), masked_var(returns, mask)
value_mean, value_var = masked_mean(values, mask), masked_var(values, mask)
# 收集统计信息
stats = dict(
loss=dict(policy=pg_loss.detach(), value=vf_loss.detach(), total=loss.detach()),
policy=dict(
entropy=entropy.detach(),
approxkl=approxkl.detach(),
policykl=policykl.detach(),
clipfrac=pg_clipfrac.detach(),
advantages=advantages.detach(),
advantages_mean=masked_mean(advantages, mask).detach(),
ratio=ratio.detach(),
),
returns=dict(mean=return_mean.detach(), var=return_var.detach()),
val=dict(
vpred=masked_mean(vpreds, mask).detach(),
error=masked_mean((vpreds - returns) ** 2, mask).detach(),
clipfrac=vf_clipfrac.detach(),
mean=value_mean.detach(),
var=value_var.detach(),
),
)
return pg_loss, self.config.vf_coef * vf_loss, flatten_dict(stats)
def step(
self,
queries: List[torch.LongTensor],
responses: List[torch.LongTensor],
scores: List[torch.FloatTensor],
response_masks: Optional[List[torch.LongTensor]] = None,
):
"""
根据查询列表、模型响应和奖励执行 PPO 优化步骤。
参数:
queries (List[`torch.LongTensor`]):
包含编码查询的张量列表,形状为 (`query_length`)
responses (List[`torch.LongTensor`]):
包含编码响应的张量列表,形状为 (`response_length`)
scores (List[`torch.FloatTensor`]):
包含分数的张量列表。
response_masks (List[`torch.FloatTensor`], *可选*):
包含响应令牌的掩码张量列表。
返回:
`dict[str, Any]`: 训练统计信息摘要
"""
bs = self.config.batch_size
queries, responses, scores, response_masks = self._step_safety_checker(
bs, queries, responses, scores, response_masks
)
scores = torch.tensor(scores, device=self.current_device)
if self.config.use_score_scaling:
# 分数缩放
scores_mean, scores_std = self.running.update(scores)
tensor_to_kwargs = dict(dtype=scores.dtype, device=scores.device)
score_scaling_factor = self.running.std.to(**tensor_to_kwargs) + torch.finfo(scores.dtype).eps
if self.config.use_score_norm:
scores = (scores - self.running.mean.to(**tensor_to_kwargs)) / score_scaling_factor
else:
scores /= score_scaling_factor
if self.config.score_clip is not None:
# 分数裁剪
scores_dtype = scores.dtype
scores = torch.clip(scores.float(), -self.config.score_clip, self.config.score_clip).to(dtype=scores_dtype)
# 如果我们想把最好的模型推送到中心
if hasattr(self, "highest_reward"):
if self.compare_step % self.config.compare_steps == 0:
curr_mean_reward = scores.mean()
# 如果是有史以来最好的奖励
if curr_mean_reward > self.highest_reward:
self.highest_reward = curr_mean_reward
# 将模型推送到中心
self.push_to_hub(**self.push_to_hub_kwargs)
self.compare_step += 1
timing = dict()
t0 = time.time()
t = time.time()
model_inputs = self.prepare_model_inputs(queries, responses)
if self.is_distributed:
pad_first = self.tokenizer.padding_side == "left"
model_inputs["input_ids"] = self.accelerator.pad_across_processes(
model_inputs["input_ids"],
dim=1,
pad_index=self.tokenizer.pad_token_id,
pad_first=pad_first,
)
model_inputs["attention_mask"] = self.accelerator.pad_across_processes(
model_inputs["attention_mask"], dim=1, pad_index=0, pad_first=pad_first
)
if self.is_encoder_decoder:
model_inputs["decoder_input_ids"] = self.accelerator.pad_across_processes(
model_inputs["decoder_input_ids"],
dim=1,
pad_index=self.tokenizer.pad_token_id,
pad_first=pad_first,
)
model_inputs["decoder_attention_mask"] = self.accelerator.pad_across_processes(
model_inputs["decoder_attention_mask"],
dim=1,
pad_index=0,
pad_first=pad_first,
)
model_inputs_names = list(model_inputs.keys())
full_kl_penalty = self.config.kl_penalty == "full"
with torch.no_grad():
all_logprobs, logits_or_none, values, masks = self.batched_forward_pass(
self.model,
queries,
responses,
model_inputs,
response_masks=response_masks,
return_logits=full_kl_penalty,
)
with self.optional_peft_ctx():
ref_logprobs, ref_logits_or_none, _, _ = self.batched_forward_pass(
self.model if self.is_peft_model else self.ref_model,
queries,
responses,
model_inputs,
return_logits=full_kl_penalty,
)
timing["time/ppo/forward_pass"] = time.time() - t
with torch.no_grad():
t = time.time()
if full_kl_penalty:
active_full_logprobs = logprobs_from_logits(logits_or_none, None, gather=False)
ref_full_logprobs = logprobs_from_logits(ref_logits_or_none, None, gather=False)
rewards, non_score_reward, kls = self.compute_rewards(
scores, active_full_logprobs, ref_full_logprobs, masks
)
else:
rewards, non_score_reward, kls = self.compute_rewards(scores, all_logprobs, ref_logprobs, masks)
timing["time/ppo/compute_rewards"] = time.time() - t
t = time.time()
values, advantages, returns = self.compute_advantages(values, rewards, masks)
timing["time/ppo/compute_advantages"] = time.time() - t
# 升级为 float32 以避免数据集问题
batch_dict = {
"queries": queries,
"responses": responses,
"logprobs": all_logprobs.to(torch.float32),
"values": values.to(torch.float32),
"masks": masks,
"advantages": advantages,
"returns": returns,
}
batch_dict.update(model_inputs)
t = time.time()
all_stats = []
early_stop = False
for _ in range(self.config.ppo_epochs):
if early_stop:
break
b_inds = np.random.permutation(bs)
for backward_batch_start in range(0, bs, self.config.backward_batch_size):
backward_batch_end = backward_batch_start + self.config.backward_batch_size
backward_batch_inds = b_inds[backward_batch_start:backward_batch_end]
for mini_batch_start in range(0, self.config.backward_batch_size, self.config.mini_batch_size):
mini_batch_end = mini_batch_start + self.config.mini_batch_size
mini_batch_inds = backward_batch_inds[mini_batch_start:mini_batch_end]
mini_batch_dict = {
"logprobs": batch_dict["logprobs"][mini_batch_inds],
"values": batch_dict["values"][mini_batch_inds],
"masks": batch_dict["masks"][mini_batch_inds],
# hacks: queries 和 responses 是不规则的。
"queries": [batch_dict["queries"][i] for i in mini_batch_inds],
"responses": [batch_dict["responses"][i] for i in mini_batch_inds],
"advantages": batch_dict["advantages"][mini_batch_inds],
"returns": batch_dict["returns"][mini_batch_inds],
}
for k in model_inputs_names:
mini_batch_dict[k] = batch_dict[k][mini_batch_inds]
with self.accelerator.accumulate(self.model):
model_inputs = {k: mini_batch_dict[k] for k in model_inputs_names}
logprobs, logits, vpreds, _ = self.batched_forward_pass(
self.model,
mini_batch_dict["queries"],
mini_batch_dict["responses"],
model_inputs,
return_logits=True,
)
train_stats = self.train_minibatch(
mini_batch_dict["logprobs"],
mini_batch_dict["values"],
logprobs,
logits,
vpreds,
mini_batch_dict["masks"],
mini_batch_dict["advantages"],
mini_batch_dict["returns"],
)
all_stats.append(train_stats)
# 通常,提前停止在 epoch 级别进行
if self.config.early_stopping:
policykl = train_stats["policy/policykl"]
early_stop = self._early_stop(policykl)
if early_stop:
break
timing["time/ppo/optimize_step"] = time.time() - t
t = time.time()
train_stats = stack_dicts(all_stats)
# 重新调整 advantages/ratios 的形状,以便不进行平均。
train_stats["policy/advantages"] = torch.flatten(train_stats["policy/advantages"]).unsqueeze(0)
train_stats["policy/advantages"] = torch.nan_to_num(train_stats["policy/advantages"], WANDB_PADDING)
train_stats["policy/ratio"] = torch.flatten(train_stats["policy/ratio"]).unsqueeze(0)
stats = self.record_step_stats(
scores=scores,
logprobs=all_logprobs,
ref_logprobs=ref_logprobs,
non_score_reward=non_score_reward,
train_stats=train_stats,
kl_coef=self.kl_ctl.value,
masks=masks,
queries=queries,
responses=responses,
kls=kls,
)
# 从所有进程收集/减少统计数据
if self.is_distributed:
stats = self.gather_stats(stats)
stats = stats_to_np(stats)
timing["time/ppo/calc_stats"] = time.time() - t
stats["ppo/learning_rate"] = self.optimizer.param_groups[0]["lr"]
# 更新 KL 控制 - 将 batch_size 乘以进程数量
self.kl_ctl.update(
stats["objective/kl"],
self.config.batch_size * self.accelerator.num_processes,
)
def batched_forward_pass(
self,
model: PreTrainedModelWrapper,
queries: torch.Tensor,
responses: torch.Tensor,
model_inputs: dict,
return_logits: bool = False,
response_masks: Optional[torch.Tensor] = None,
):
"""
计算模型在多个批次上的输出。
参数:
queries (`torch.LongTensor`):
编码查询的张量列表,形状为 (`batch_size`, `query_length`)
responses (`torch.LongTensor`):
编码响应的张量列表,形状为 (`batch_size`, `response_length`)
return_logits (`bool`, *可选*, 默认为 `False`):
是否返回所有logits。如果不需要logits,设置为 `False` 以减少内存消耗。
返回:
(tuple):
- all_logprobs (`torch.FloatTensor`): 响应的对数概率,
形状为 (`batch_size`, `response_length`)
- all_ref_logprobs (`torch.FloatTensor`): 响应的参考对数概率,
形状为 (`batch_size`, `response_length`)
- all_values (`torch.FloatTensor`): 响应的值,形状为 (`batch_size`, `response_length`)
"""
bs = len(queries) # 查询的批次大小
fbs = self.config.mini_batch_size # 最小批次大小
all_logprobs = []
all_logits = []
all_masks = []
all_values = []
model.eval() # 设置模型为评估模式
for i in range(math.ceil(bs / fbs)):
# 构造当前批次的输入参数
input_kwargs = {key: value[i * fbs : (i + 1) * fbs] for key, value in model_inputs.items()}
query_batch = queries[i * fbs : (i + 1) * fbs] # 当前查询批次
response_batch = responses[i * fbs : (i + 1) * fbs] # 当前响应批次
if response_masks is not None:
response_masks_batch = response_masks[i * fbs : (i + 1) * fbs] # 当前响应掩码批次
logits, _, values = model(**input_kwargs) # 获取模型的logits和值
# 根据模型类型获取输入ID和注意力掩码
if self.is_encoder_decoder:
input_ids = input_kwargs["decoder_input_ids"]
attention_mask = input_kwargs["decoder_attention_mask"]
else:
input_ids = input_kwargs["input_ids"]
attention_mask = input_kwargs["attention_mask"]
logprobs = logprobs_from_logits(logits[:, :-1, :], input_ids[:, 1:]) # 从logits计算对数概率
masks = torch.zeros_like(attention_mask) # 创建掩码
masks[:, :-1] = attention_mask[:, 1:] # 处理掩码
for j in range(len(query_batch)):
if self.is_encoder_decoder:
# 解码器句子在Enc-Dec模型中总是从索引1开始
start = 1
end = attention_mask[j, :].sum() - 1
else:
start = len(query_batch[j]) - 1 # 对数概率从第二个查询token开始
if attention_mask[j, 0] == 0: # 处理左侧填充
start += attention_mask[j, :].nonzero()[0]
end = start + len(response_batch[j]) # 结束位置
masks[j, :start] = 0 # 设置起始位置之前的掩码为0
masks[j, end:] = 0 # 设置结束位置之后的掩码为0
if response_masks is not None:
masks[j, start:end] = masks[j, start:end] * response_masks_batch[j] # 更新响应掩码
if return_logits:
all_logits.append(logits) # 保存logits
else:
del logits # 不需要logits时删除以节省内存
all_values.append(values) # 保存值
all_logprobs.append(logprobs) # 保存对数概率
all_masks.append(masks) # 保存掩码
return (
torch.cat(all_logprobs), # 拼接所有对数概率
torch.cat(all_logits)[:, :-1] if return_logits else None, # 拼接所有logits(如果需要)
torch.cat(all_values)[:, :-1], # 拼接所有值
torch.cat(all_masks)[:, :-1], # 拼接所有掩码
)
PPO 训练流程
输入: SFT 模型
,奖励模型
输出: 与人类偏好对齐的大语言模型
- 初始化负责与环境交互的策略模型:
- 初始化负责学习的策略模型:
- 循环 (对于每个步骤 step=1,2,…):
- 从
采样得到若干决策轨迹
- 计算“优势估计”
- 循环 (对于每个 k=1,2,…,K):
- 计算目标函数
- 使用梯度上升优化
- 更新与环境交互的策略模型:
- 结束循环
参考代码示例【10】:
for epoch in tqdm(range(epochs), "epoch: "):
for batch in tqdm(ppo_trainer.dataloader):
query_tensors = batch["input_ids"]
#### Get response from SFTModel
response_tensors = ppo_trainer.generate(query_tensors, **generation_kwargs)
batch["response"] = [tokenizer.decode(r.squeeze()) for r in response_tensors]
#### Compute reward score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = reward_model(texts)
rewards = [torch.tensor(output[1]["score"]) for output in pipe_outputs]
#### Run PPO step
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)4. 非强化学习的对齐方法(DPO)
尽管 RLHF已被证实是一种有效的语言模型对齐技术,但面临一些局限性。首先,在 RLHF 的训练过程中,需要同时维护和更新多个模型,包括策略模型、奖励模型、参考模型和评价模型。这不仅会消耗大量内存资源,还使得整个算法的执行过程变得相对复杂。此外,RLHF 中常用的近端策略优化算法在优化过程中的稳定性较差,并对超参数的选择非常敏感,这进一步增加了模型训练的难度和不确定性。为了解决这些问题,工业界/学界提出了一系列基于监督微调的对齐方法,通过更简单、直接的方式实现大语言模型与人类价值观的对齐,从而避免复杂强化学习算法带来的挑战【3】。
非强化学习的对齐方法利用高质量的对齐数据集,通过特定的监督学习算法对大语言模型进行微调。与传统的指令微调方法不同,这些基于监督微调的对齐方法要求模型在优化过程中能够区分对齐数据与未对齐数据(或对齐质量的高低),从而直接从中学习与人类期望对齐的行为模式。实现非强化学习的有监督对齐方法需要关注两个关键要素:构建高质量的对齐数据集和设计监督微调对齐算法。
本文主要关注监督微调对齐算法的介绍。具体的,是对DPO(Direct Preference Optimization, DPO,即直接偏好优化)的介绍。直接偏好优化是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO 可以通过与有监督微调相似的复杂度实现模型对齐,不再需要在训练过程中针对大语言模型进行采样,同时超参数的选择更加容易。
用一个图来直观感受下PPO和DPO的区别【12, 13】:


文章【3,13】对DPO的公式做了很详细的推导,有兴趣可以参考下。不过公式过于复杂,为了帮助读者更容易把握关键的模块,这里做一下核心的公式演化主线的描述。DPO 算法概述
DPO算法的核心目标是通过简化奖励建模,优化强化学习中的决策过程。它直接建立决策函数 与奖励函数 r(x, y) 之间的关系,从而避免复杂的奖励建模。
DPO 的目标函数可以表示为:
这里, 是平衡因子,用于调整奖励和 KL 散度之间的权衡。KL 散度用于测量新旧策略之间的差异。
目标函数的推导
-
拆解 KL 散度: KL 散度的定义为:
在 DPO 的上下文中,我们可以将 KL 散度拆解为:
-
重写目标函数: 将 KL 散度的拆解结果代入目标函数,得到:
-
引入对数形式: 为了优化这个目标函数,我们使用对数形式,使得优化过程更加平滑:
优化过程
-
定义新的概率分布: 引入配分函数 Z(x) 来规范化模型:
这样,我们可以定义新的概率分布:
-
DPO 最终目标函数: 根据人类偏好数据,我们的最终优化目标函数变为:
这里,
是符合人类偏好的输出,
是不符合的输出。
3. 对 进行求导。
定义中间变量 u:
导数的计算:
对目标函数 L(θ)进行求导,得到:
其中,σ 是 sigmoid 函数。
4. 对求导结果进一步展开
展开梯度:
将 u 的定义代入,得到:
代入公式:
替换梯度表达式,得到:
整理表达式:
得到目标函数的另一种形式:
这个目标函数的表达形式,特别类似于learn to rank的pair对模型。可以看下我们之前关于BPR的文章《ToB的大模型系统非常有必要引入搜索推荐算法能力(回顾BPR)》。
分析
梯度的意义:
公式中的 E_{(x,y^+,y^-)\sim D} 表示对人类偏好的样本进行期望计算。梯度和
分别表示生成符合和不符合偏好的内容的策略更新。
优化的目标:
当策略模型生成符合人类偏好的内容 y^+ 时,目标函数希望增大的值,同时减小
的值,从而使模型更倾向于生成符合偏好的输出。
动态步长控制:
梯度中的系数动态控制着梯度的步长。若
与
之间的差异增大,意味着模型的生成结果更倾向于不符合人类偏好,此时梯度步长增大,进行更激进的参数更新,以避免产生不符合的内容。
训练稳定性:
反之,当策略模型成功生成符合人类偏好的内容时,差异减小,步长减小,这使得更新幅度降低,避免性能波动,增加训练的稳定性。
DPO loss计算参考代码【14】:
def dpo_loss(
self,
policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
reference_chosen_logps: torch.FloatTensor,
reference_rejected_logps: torch.FloatTensor,
) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
"""计算一批策略和参考模型的DPO损失。
参数:
policy_chosen_logps: 策略模型对选定响应的对数概率。形状: (batch_size,)
policy_rejected_logps: 策略模型对被拒绝响应的对数概率。形状: (batch_size,)
reference_chosen_logps: 参考模型对选定响应的对数概率。形状: (batch_size,)
reference_rejected_logps: 参考模型对被拒绝响应的对数概率。形状: (batch_size,)
返回:
一个包含三个张量的元组: (losses, chosen_rewards, rejected_rewards)。
losses张量包含每个示例的DPO损失。
chosen_rewards和rejected_rewards张量分别包含选定和被拒绝响应的奖励。
"""
# 计算选择的对数比率
chosen_logratios = policy_chosen_logps.to(self.accelerator.device) - (
not self.reference_free
) * reference_chosen_logps.to(self.accelerator.device)
# 计算拒绝的对数比率
rejected_logratios = policy_rejected_logps.to(self.accelerator.device) - (
not self.reference_free
) * reference_rejected_logps.to(self.accelerator.device)
if self.f_divergence_type == FDivergenceType.ALPHA_DIVERGENCE.value:
# alpha散度公式: (1 - u^-alpha) / alpha
# 选择样本和拒绝样本之间的散度差为:
# (1 - u[w]^-alpha) / alpha - (1 - u[l]^-alpha) / alpha
# = (u[l]^-alpha - u[w]^-alpha) / alpha
# 其中u[w]和u[l]分别是选定和拒绝样本的策略/参考概率比
alpha_coef = FDivergenceConstants.ALPHA_DIVERGENCE_COEF_DEFAULT
if self.f_divergence_params and FDivergenceConstants.ALPHA_DIVERGENCE_COEF_KEY in self.f_divergence_params:
alpha_coef = float(self.f_divergence_params[FDivergenceConstants.ALPHA_DIVERGENCE_COEF_KEY])
logits = (cap_exp(rejected_logratios * -alpha_coef) - cap_exp(chosen_logratios * -alpha_coef)) / alpha_coef
else:
# 计算策略对数比率
pi_logratios = policy_chosen_logps - policy_rejected_logps
if self.reference_free:
ref_logratios = torch.tensor([0], dtype=pi_logratios.dtype, device=pi_logratios.device)
else:
ref_logratios = reference_chosen_logps - reference_rejected_logps
pi_logratios = pi_logratios.to(self.accelerator.device)
ref_logratios = ref_logratios.to(self.accelerator.device)
logits = pi_logratios - ref_logratios
if self.f_divergence_type == FDivergenceType.JS_DIVERGENCE.value:
# js散度公式: log(2 * u / (1 + u))
# 选择样本和拒绝样本之间的散度差为:
# log(2 * u[w] / (1 + u[w])) - log(2 * u[l] / (1 + u[l]))
# = log(u[w]) - log(u[l]) - (log(1 + u[w]) - log(1 + u[l]))
# 其中u[w]和u[l]分别是选定和拒绝样本的策略/参考概率比
logits -= F.softplus(chosen_logratios) - F.softplus(rejected_logratios)
# beta是DPO损失的温度参数,通常在0.1到0.5之间。
# 当beta趋近于0时,我们忽略参考模型。label_smoothing参数编码了我们对标签的不确定性并计算保守的DPO损失。
if self.loss_type == "sigmoid":
losses = (
-F.logsigmoid(self.beta * logits) * (1 - self.label_smoothing)
- F.logsigmoid(-self.beta * logits) * self.label_smoothing
)
elif self.loss_type == "robust":
losses = (
-F.logsigmoid(self.beta * logits) * (1 - self.label_smoothing)
+ F.logsigmoid(-self.beta * logits) * self.label_smoothing
) / (1 - 2 * self.label_smoothing)
elif self.loss_type == "exo_pair":
# EXO论文中的公式(16): https://huggingface.co/papers/2402.00856
import math
if self.label_smoothing == 0:
self.label_smoothing = 1e-3
losses = (self.beta * logits).sigmoid() * (
F.logsigmoid(self.beta * logits) - math.log(1 - self.label_smoothing)
) + (-self.beta * logits).sigmoid() * (F.logsigmoid(-self.beta * logits) - math.log(self.label_smoothing))
elif self.loss_type == "hinge":
losses = torch.relu(1 - self.beta * logits)
elif self.loss_type == "ipo":
# 论文中的公式(17),其中beta是IPO损失的正则化参数,文中用tau表示。
losses = (logits - 1 / (2 * self.beta)) ** 2
elif self.loss_type == "bco_pair":
chosen_logratios = policy_chosen_logps - reference_chosen_logps
rejected_logratios = policy_rejected_logps - reference_rejected_logps
chosen_rewards = self.beta * chosen_logratios
rejected_rewards = self.beta * rejected_logratios
rewards = torch.cat((chosen_rewards, rejected_rewards), 0).mean().detach()
self.running.update(rewards)
delta = self.running.mean
losses = -F.logsigmoid((self.beta * chosen_logratios) - delta) - F.logsigmoid(
-(self.beta * rejected_logratios - delta)
)
elif self.loss_type == "sppo_hard":
# 在论文中(https://huggingface.co/papers/2405.00675),SPPO使用了一种软概率的方法,通过PairRM评分估算。这里描述的版本是硬概率版本,其中算法1的公式(4.7)中赢家的P设为1,输家的P设为0。
a = policy_chosen_logps - reference_chosen_logps
b = policy_rejected_logps - reference_rejected_logps
losses = (a - 0.5 / self.beta) ** 2 + (b + 0.5 / self.beta) ** 2
elif self.loss_type == "nca_pair":
chosen_rewards = (policy_chosen_logps - reference_chosen_logps) * self.beta
rejected_rewards = (policy_rejected_logps - reference_rejected_logps) * self.beta
losses = (
-F.logsigmoid(chosen_rewards)
- 0.5 * F.logsigmoid(-chosen_rewards)
- 0.5 * F.logsigmoid(-rejected_rewards)
)
elif self.loss_type == "aot_pair":
chosen_logratios = policy_chosen_logps - reference_chosen_logps
rejected_logratios = policy_rejected_logps - reference_rejected_logps
chosen_logratios_sorted, _ = torch.sort(chosen_logratios, dim=0)
rejected_logratios_sorted, _ = torch.sort(rejected_logratios, dim=0)
delta = chosen_logratios_sorted - rejected_logratios_sorted
losses = (
-F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
- F.logsigmoid(-self.beta * delta) * self.label_smoothing
)
elif self.loss_type == "aot":
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
pi_logratios_sorted, _ = torch.sort(pi_logratios, dim=0)
ref_logratios_sorted, _ = torch.sort(ref_logratios, dim=0)
delta = pi_logratios_sorted - ref_logratios_sorted
losses = (
-F.logsigmoid(self.beta * delta) * (1 - self.label_smoothing)
- F.logsigmoid(-self.beta * delta) * self.label_smoothing
)
elif self.loss_type == "apo_zero":
# APO论文中的公式(7): https://huggingface.co/papers/2408.06266
# 当你相信选定的输出优于模型的默认输出时使用此损失
losses_chosen = 1 - F
DPO是一种简单的训练范式,可以在没有强化学习的情况下从偏好中训练语言模型。DPO 通过识别语言模型策略与奖励函数之间的映射,使得可以使用简单的交叉熵损失直接训练语言模型以满足人类偏好,而无需将偏好学习问题强行转变为标准的强化学习设置。
5. 参考材料
【1】A Taxonomy of RL Algorithms
【2】The Role of Reinforcement Learning in NLP
【4】A Survey of Large Language Models
【5】Proximal Policy Optimization
【6】Training language models to follow instructions with human feedback
【8】Secrets of RLHF in Large Language Models Part I: PPO
【9】Illustrating Reinforcement Learning from Human Feedback (RLHF)
【10】PPO Trainer
【11】RLHF(PPO) vs DPO
【12】Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback
【13】Direct Preference Optimization: Your Language Model is Secretly a Reward Model
【14】dpo_trainer



















 1487
1487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











