







1. 背景介绍
表格识别,在RAG中文档解析一环是非常关键的,RAG要发挥作用,其实涉及到三个关键:内容、检索、生成。 高质量的内容是前提。
表格的检测之前有很多工作,比如【1】展示了表格识别的一种方法:
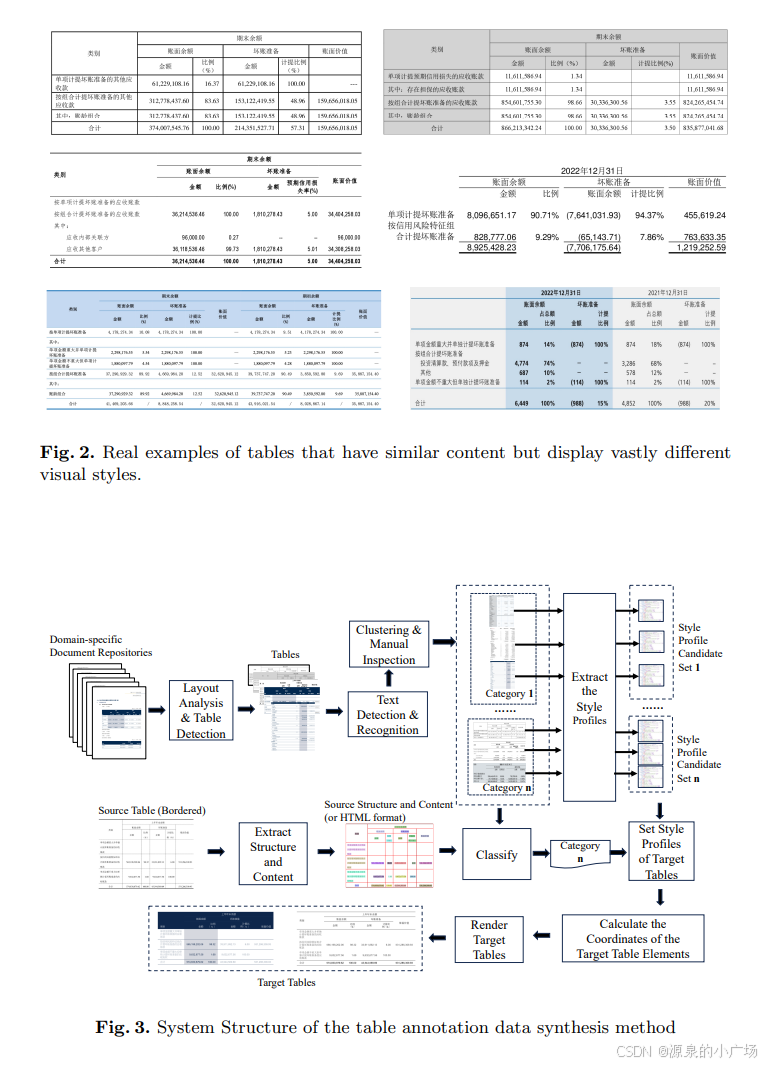
但对于特殊表格,上述方法可能就会遇到一些问题。今天偶然看到有一篇讨论特殊表格检测的方法【2】,对于文档解析有一些启发。
将纸质文档或图片转换成可编辑的电子文档。但是,当图片中包含表格时,常常将完整的表格拆解成零散的部分,给后续操作带来很多不便。今天介绍的方案,是希望开发一种通用算法,能够准确地识别图片中表格的位置,并对其进行合理的标注。表格检测可以看作是一种任意形状目标检测问题。虽然目前很多目标检测方法采用旋转框来捕捉目标,但在实际数据中,表格可能会存在严重的角度畸变,这就造成旋转矩形框很难准确定位表格四个关键点。另外,表格的四个标注点(左上、左下、右上、右下)不仅仅是几何位置,需要精确定位这四个点,还必须判断出表格的正确朝向。
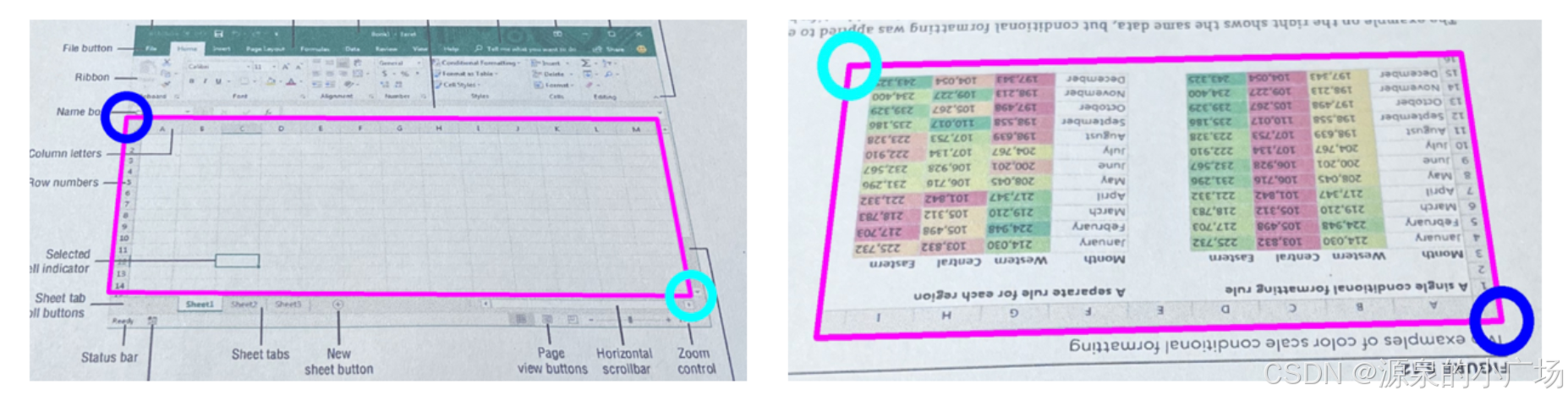
上图展示了标注可视化结果:深蓝色代表左上角关键点,浅蓝色代表右下角关键点,粉色边界框显示出表格的实际形状。从图中可以看出,随着表格的旋转,其左上角标注点也会随之旋转。
使用到的数据集中训练集共10000张图片:
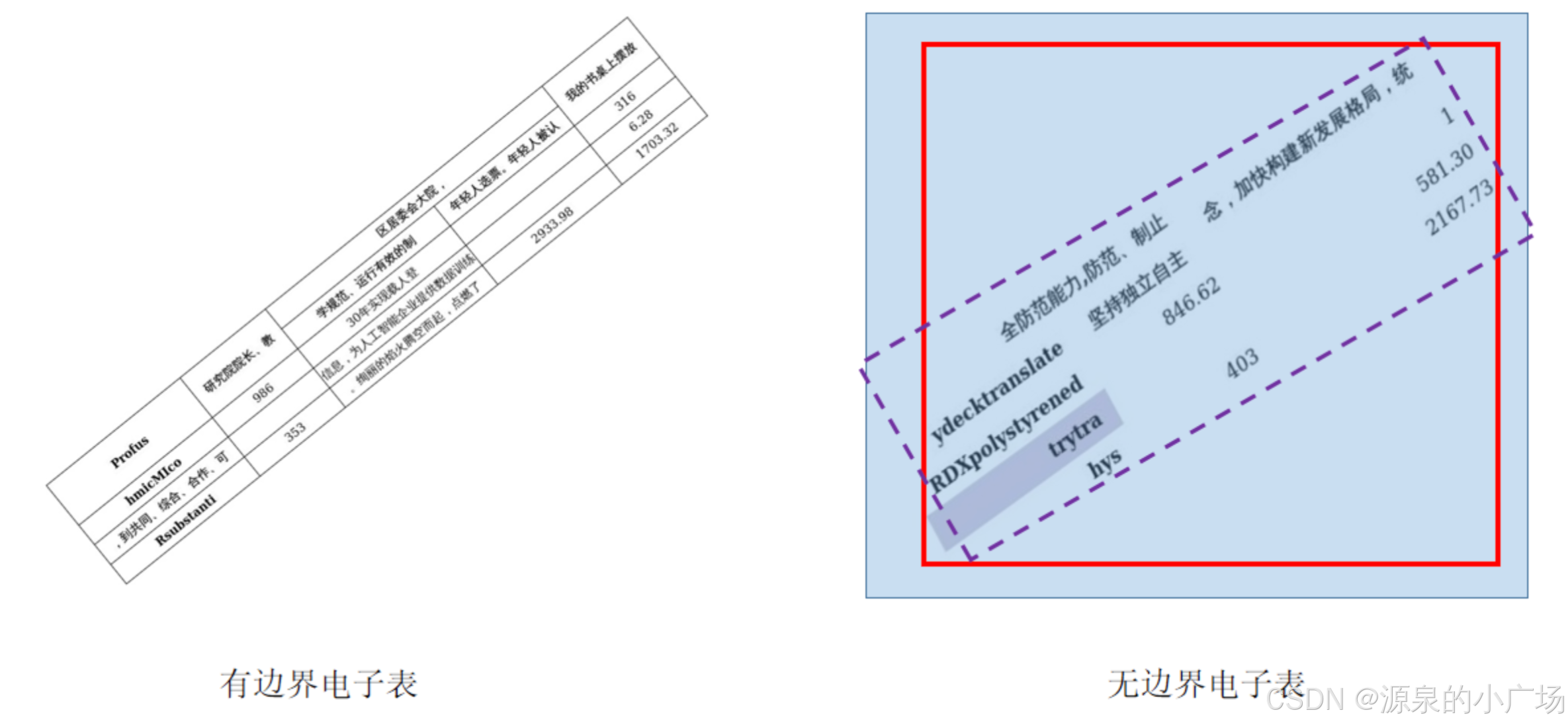

数据集分为四种类型:有边界电子表、无边界电子表、IMG_纸质表以及paper_纸质表。对于有边界电子表,由于其边缘清晰且没有段落文字干扰,检测相对简单,模型的置信度通常可以在0.98到1之间;而无边界电子表则因缺乏明确的边缘而增加了检测难度。红色实线框代表模型预测的边界框,紫色虚线框显示了标注的四边形真实形状,蓝色透明区域则为真实边界框。可以看出,由于模型不会主动推断出隐藏的边界,预测出的边界框往往略小于真实边界框,但仍可满足IoU匹配要求;同时,由于分割方案对目标形状已有一定的感知能力,表格轮廓点的预测难度并不高。相比之下,IMG和paper类纸质表的检测更加困难。一方面,纸质表格常常受到周围段落文字和复杂环境的干扰;另一方面,这类表格在整张图片中所占比例较低,较小的输入尺寸可能会影响表格的正确分类。此外,与电子表格只是在平面内进行随机旋转不同,纸质表的拍摄角度更加随意,形状畸变严重,甚至有的表格根本没有明显边界,这将导致检测和分割的难度大幅增加。
2. 算法评价指标及算法思路
评价指标为:precision 和 recall。根据评价指标,box 的检测相对简单,其中关键点的检测较为困难,在图像尺寸在 1K-2K 且部分表格没有明确边界的情况下,20像素的容错率较低,因此需要不断强化分割网络的形状感知能力,使其可以根据已有边界或单元格文字推断出表格的隐藏边界。此外,采用轮廓点回归方法虽然速度更快,但是由于感知不到形状信息,在 20 像素的容错率下对关键点的检测精度较低;采用语义分割类方法推理时间较长、显存占有率高。
分享方案提出了表格检测与语义分割相分离的串行实例分割方案。采用 ppyoloe-plus-x 作为表格检测模型,并取得了0.425的检测分数。考虑到表格形状对表格边界的提示作用,采用 DBNet 作为语义分割网络,并采用 Dice Loss 分别对 loss_shrink_maps 和 loss_binary_maps 进行优化,从而强化网络对形状的感知能力。通过采用上述的串行实例分割结构,不仅表格检测与表格分割不再相互约束。网络可以检测到更多的边界框,而且网络不再需要同时分割表格中的多个表格实例,显存和耗时大大减小,模型的单张图片耗时从 Solov2 的 0.42s 降到 0.37s。
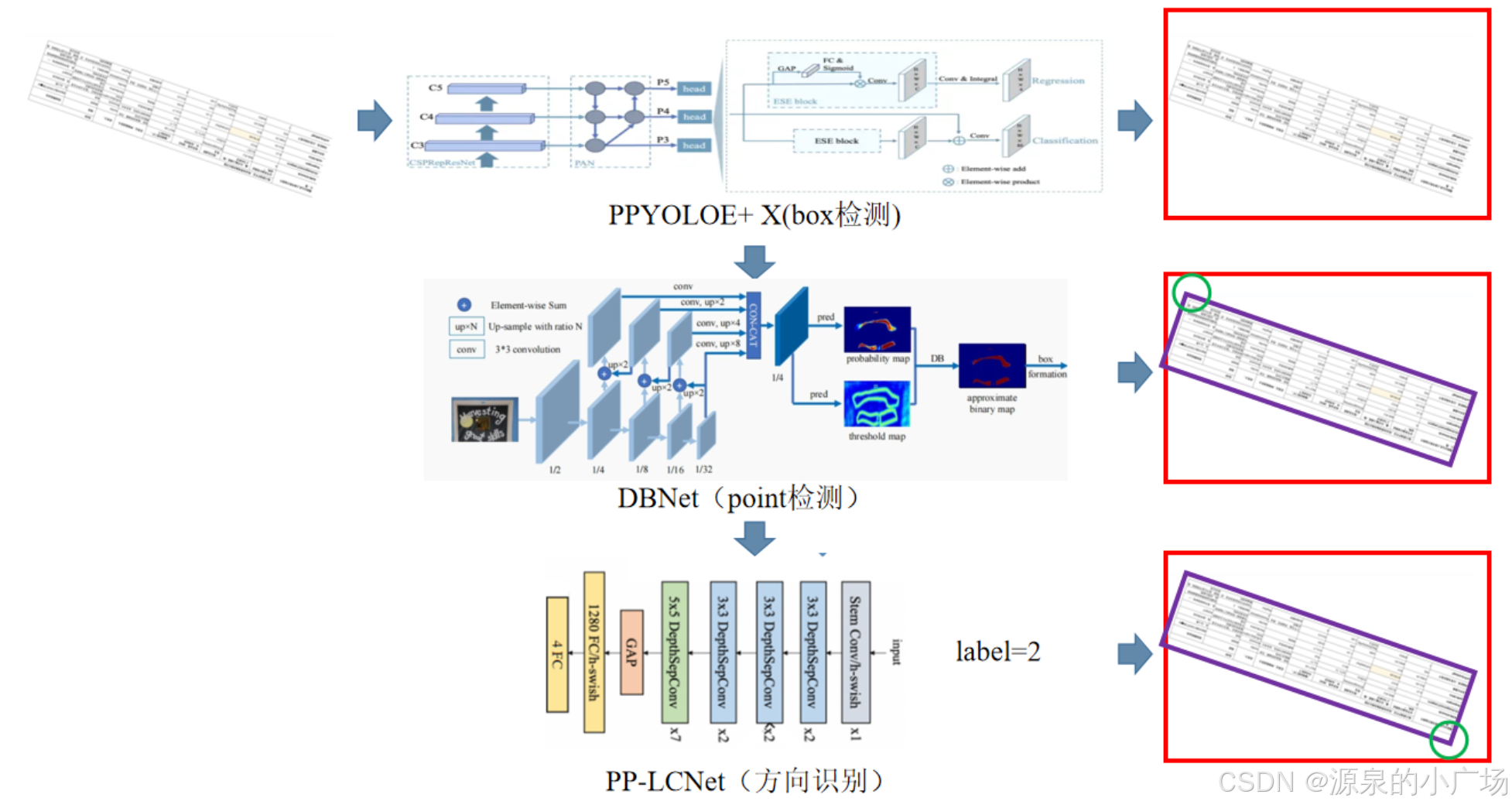
在使用DBNet进行表格语义分割的过程中,考虑到语义分割网络检测结果存在一定噪音,检测出来的多边形边数可能大于4(如:分割结果缺角或某一边凸出),利用最小包络四边形算法寻找凸多边形的最小包围四边形。
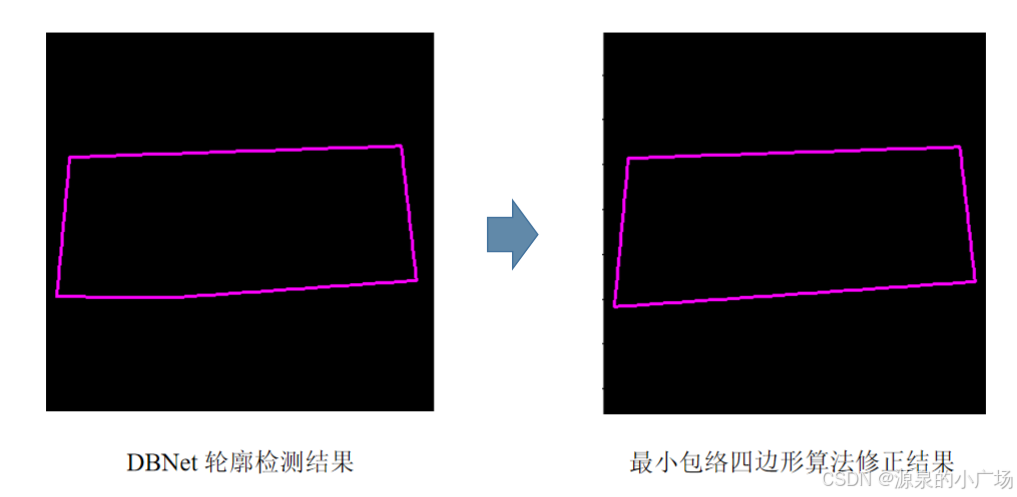
此外采用 PP-LCNet 建模几何轮廓点与语义轮廓点的相对关系。
具体实现流程分为两大技术模块:
一、几何特征点计算模块
基于真实标签的语义轮廓点坐标,通过双阶段空间推理机制构建几何轮廓点体系:
横向坐标排序:依据x轴坐标值对四个关键点进行升序排列,将前两位标记为左侧坐标集,后两位归为右侧坐标集
纵向坐标分析:在左侧坐标集内部,选取y轴坐标较小者为几何左上角特征点,较大者对应左下角;右侧坐标集则取y轴坐标较小者为右上角,较大者定义为右下角
二、方向类别判定模块
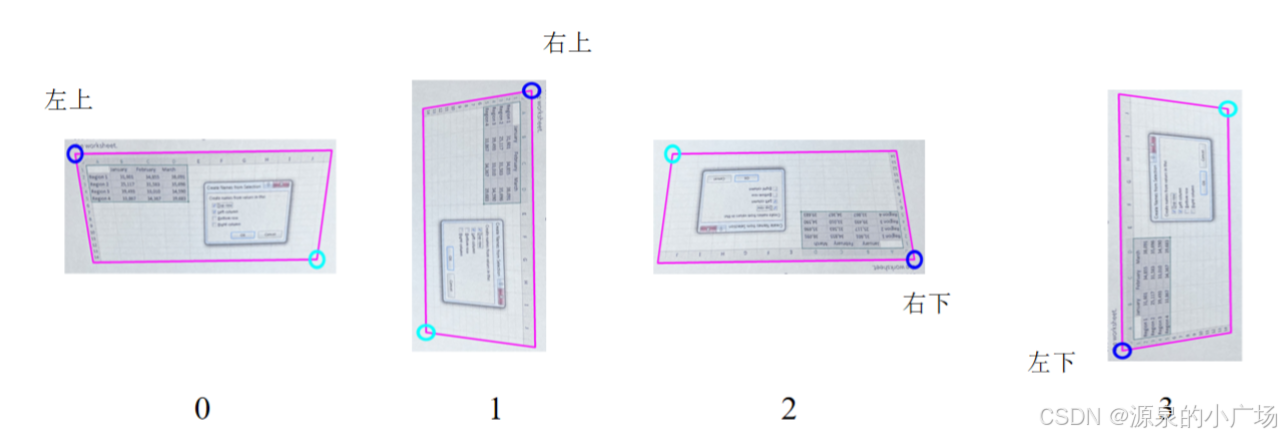
通过建立几何-语义特征点的空间映射关系,构建四元方向分类体系:
类别0:语义左上角与几何左上角空间重合
类别1:语义左上角位于几何右上角区域
类别2:语义左上角分布于几何右下象限
类别3:语义左上角定位在几何左下方位
该方法通过建立几何特征与语义特征的空间对应关系,能够有效提升复杂场景下的轮廓点检测精度。
针对表格方向识别,通过多阶段协同优化,具体实施策略与系统架构如下:
一、数据增强与误差分析优化
全向旋转增强策略
在训练阶段对表格图像施加0-360°无约束随机旋转变换,同步执行动态方向标签计算机制,有效提升模型对任意旋转角度的泛化能力。测试阶段创新性地引入对抗性旋转策略:基于测试集方向分布直方图分析(约90%样本为0类方向),针对性实施随机旋转扰动,打破数据分布偏差带来的模型偏好。误差溯源与先验增强
实验发现:尽管旋转增强使方向识别准确率达96.7%,但极端样本仍存在误判。深入分析表明,方向标签依赖的几何轮廓在检测阶段存在信息缺失风险。为此引入DBNet多模态检测机制,通过精准提取表格关键点构建轮廓先验信息,该设计具备双重优势:
建立抗干扰机制:消除外部文字噪声对方向判定的干扰
消解临界歧义:解决方向类别切换点的模糊判定问题
经此优化,方向识别准确率显著提升至99.6%
二、三阶式系统架构
算法采用级联式处理流水线:
表格定位模块
采用PP-YOLOE-Plus-X检测器进行表格边界框预测,基于置信度阈值筛选高质量检测结果,执行精细化实例裁剪结构解析模块
将裁剪后的表格实例输入DBNet网络进行语义分割,通过OpenCV轮廓分析算法提取精确表格关键点坐标,构建几何拓扑结构方向判别模块
PP-LCNet网络创新性地融合双重特征:
原始图像表观特征
轮廓先验的几何约束特征
通过预定义的几何-语义轮廓点映射规则,实现方向类别预测与语义轮廓坐标的联合输出
该架构通过检测-解析-判别的递进式处理,将传统单阶段识别任务解耦为特征明确的子任务,既保证各模块的专业化处理能力,又通过特征级联实现全局优化。实验表明,轮廓先验的引入使模型在保持高精度的同时,推理耗时仅增加8.3ms,达到精度与效率的优化平衡。
3. 训练细节
3.1 PP-YOLOE-Plus-X 目标检测模型
数据策略
-
采用全量数据训练模式,不进行常规训练集/验证集划分
数据增强方案
-
像素级增强:
-
色彩空间变换:亮度(±32%)、对比度(±32%)、饱和度(±32%)、色相(±18°)随机调整
-
通道顺序随机置换
-
-
空间几何变换:
-
随机扩展填充(填充值:[123.675, 116.28, 103.53])
-
随机裁剪(比例范围0.5-1.0)
-
随机水平/垂直翻转
-
-
多尺度训练:
-
动态分辨率调整:[640, 1216]区间内19级尺度,步长32像素
-
标准化:μ=[0,0,0], σ=[1,1,1]
-
训练配置
-
预训练模型:ppyoloe-plus-x 在 Object365 数据集上的预训练模型
-
训练周期:90 epochs
-
学习率策略:
-
0-5 epochs:LinearWarmup
-
5-90 epochs:CosineDecay(lr=1e-3)
-
-
优化器:Momentum(β=0.9)
-
复合损失函数:
-
分类:Focal Loss
-
回归:GIoU Loss + L1 Loss
-
分布匹配:DF Loss
-
总损失:加权求和
-
3.2 DBNet 表格检测模型
数据生成
-
Base阶段:从原图裁剪表格实例
-
Refine阶段:实时从标签文件生成
训练策略
| Base阶段 | Refine阶段 | |
|---|---|---|
| 数据划分 | 全量训练 | 全量训练 |
| 数据增强 | 随机旋转/翻转 色彩抖动 缩放填充 标准化(ImageNet参数) | 增加随机扩张 归一化(/255) |
| 训练配置 | ||
| 预训练模型 | ResNet50 | Base阶段最佳模型 |
| 训练周期 | 100 epochs | 100 epochs |
| 最优模型 | epoch64 | epoch33 |
| 损失函数 | Dice Loss ×2 | Dice Loss ×2 |
| 优化器 | Adam(lr=1e-4) | Adam(lr=1e-4) |
| 学习率策略 | Step Decay | Step Decay |
3.3 PP-LCNet 方向分类模型
数据生成
-
Base阶段:实时裁剪表格实例
-
Refine阶段:基于裁剪结果绘制边界框
训练策略
| Base阶段 | Refine阶段 | |
|---|---|---|
| 数据划分 | 9:1训练/测试集 | - |
| 数据增强 | CutOut 随机裁剪 ImageNet标准化 | 增加随机扩张 归一化(/255) |
| 训练配置 | ||
| 训练周期 | 80 epochs | 80 epochs |
| 最优模型 | epoch80 | epoch64 |
| 损失函数 | Cross Entropy | Cross Entropy |
| 优化器 | Adam(lr=5e-3) | Adam(lr=5e-3) |
| 学习率策略 | MultiStepDecay (milestones=[10,20,...,70]) | MultiStepDecay |
4. 参考材料
【1】Synthesizing Realistic Data for Table Recognition



















 1806
1806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











