引言
基本原理
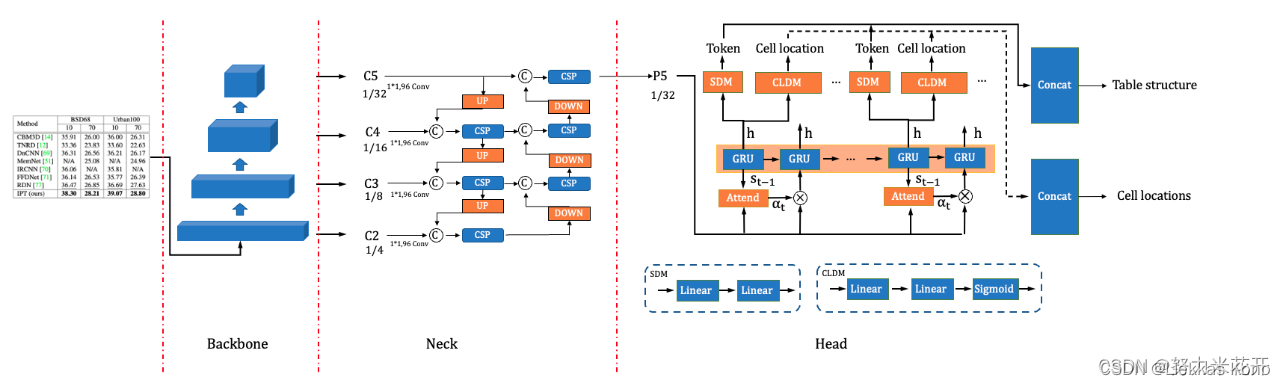
- SLANet主要是结合PP-LCNet + CSP-PAN + Attention来完成的。
- 模型预测两个值,一是
structure_pobs,表格结构的html代码,二是loc_preds,回归单元格四个点坐标。 - 预测表格结构部分损失函数采用的是交叉熵损失,预测单元格坐标损失函数采用的是smooth-l1-loss。
整体框架
核心代码
- 可直接复制运行,该代码主要用来查看算法核心部分的实现细节
- 所用数据皆为randn得来,请侧重查看各个阶段数据的shape,来知晓其中做法。
- 每个算法的核心部分并不神秘,只是大部分情况都被包裹的太深了而已。
import torch
from torch import nn
from torch.nn import functional as F
class SLAHead(nn.Module):
def __init__(self, in_channels=96, is_train=False) -> None:
super().__init__()
self.max_text_length = 500
self.hidden_size = 256
self.loc_reg_num = 4
self.out_channels = 30
self.num_embeddings = self.out_channels
self.is_train = is_train
self.structure_attention_cell = AttentionGRUCell(in_channels,
self.hidden_size,
self.num_embeddings)
self.structure_generator = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size),
nn.Linear(self.hidden_size, self.out_channels)
)
self.loc_generator = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size),
nn.Linear(self.hidden_size, self.loc_reg_num)
)
def forward(self, fea):
batch_size = fea.shape[0]
fea = torch.reshape(fea, [fea.shape[0], fea.shape[1], -1])
fea = fea.permute(0, 2, 1)
structure_preds = torch.zeros(batch_size, self.max_text_length + 1,
self.num_embeddings)
loc_preds = torch.zeros(batch_size, self.max_text_length + 1,
self.loc_reg_num)
hidden = torch.zeros(batch_size, self.hidden_size)
pre_chars = torch.zeros(batch_size, dtype=torch.int64)
loc_step, structure_step = None, None
for i in range(self.max_text_length + 1):
hidden, structure_step, loc_step = self._decode(pre_chars,
fea, hidden)
pre_chars = structure_step.argmax(dim=1)
structure_preds[:, i, :] = structure_step
loc_preds[:, i, :] = loc_step
if not self.is_train:
structure_preds = F.softmax(structure_preds, dim=-1)
return structure_preds, loc_preds
def _decode(self, pre_chars, features, hidden):
emb_features = F.one_hot(pre_chars, num_classes=self.num_embeddings)
(output, hidden), alpha = self.structure_attention_cell(hidden,
features,
emb_features)
structure_step = self.structure_generator(output)
loc_step = self.loc_generator(output)
return hidden, structure_step, loc_step
class AttentionGRUCell(nn.Module):
def __init__(self, input_size, hidden_size, num_embedding) -> None:
super().__init__()
self.i2h = nn.Linear(input_size, hidden_size, bias=False)
self.h2h = nn.Linear(hidden_size, hidden_size)
self.score = nn.Linear(hidden_size, 1, bias=False)
self.gru = nn.GRU(input_size=input_size + num_embedding,
hidden_size=hidden_size,)
self.hidden_size = hidden_size
def forward(self, prev_hidden, batch_H, char_onehots):
batch_H_proj = self.i2h(batch_H)
prev_hidden_proj = torch.unsqueeze(self.h2h(prev_hidden), dim=1)
res = torch.add(batch_H_proj, prev_hidden_proj)
res = F.tanh(res)
e = self.score(res)
alpha = F.softmax(e, dim=1)
alpha = alpha.permute(0, 2, 1)
context = torch.squeeze(torch.matmul(alpha, batch_H), dim=1)
concat_context = torch.concat([context, char_onehots], 1)
cur_hidden = self.gru(concat_context, prev_hidden)
return cur_hidden, alpha
class SLALoss(nn.Module):
def __init__(self) -> None:
super().__init__()
self.loss_func = nn.CrossEntropyLoss()
self.structure_weight = 1.0
self.loc_weight = 2.0
self.eps = 1e-12
def forward(self, pred):
structure_probs = pred[0]
structure_probs = structure_probs.permute(0, 2, 1)
structure_target = torch.empty(1, 501, dtype=torch.long).random_(30)
structure_loss = self.loss_func(structure_probs, structure_target)
structure_loss = structure_loss * self.structure_weight
loc_preds = pred[1]
loc_targets = torch.randn(1, 501, 4)
loc_target_mask = torch.randn(1, 501, 1)
loc_loss = F.smooth_l1_loss(loc_preds * loc_target_mask,
loc_targets * loc_target_mask,
reduction='mean')
loc_loss *= self.loc_weight
loc_loss = loc_loss / (loc_target_mask.sum() + self.eps)
total_loss = structure_loss + loc_loss
return total_loss
if __name__ == '__main__':
x = torch.randn(1, 96, 16, 16)
model = SLAHead()
loss_func = SLALoss()
y = model(x)
loss = loss_func(y)
print(y[0].shape)
print(y[1].shape)



























 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









