







目录
一、什么是spark?
Spark是一个分布式计算平台,用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎,它能够高效地处理大规模数据,并支持多种数据处理模式,如批处理、交互式查询、流处理和机器学习等。在大数据领域得到了广泛的应用,在云计算、企业数据分析、实时数据处理和机器学习等方面发挥了重要作用,它的出现极大地简化了大数据处理的复杂性,提高了数据处理的效率和准确性。
二、什么是Scala?
Spark是一个分布式计算平台,用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎,它能够高效地处理大规模数据,并支持多种数据处理模式,如批处理、交互式查询、流处理和机器学习等。在大数据领域得到了广泛的应用,在云计算、企业数据分析、实时数据处理和机器学习等方面发挥了重要作用,它的出现极大地简化了大数据处理的复杂性,提高了数据处理的效率和准确性
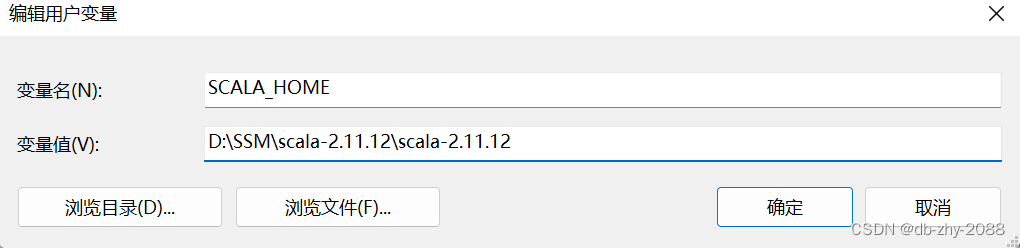
三、配置Scala
解压scala-2.11.12(windows配置环境变量SCALA_HOME,PATH添加:%SCALA_HOME%\bin、%SCALA_HOME%\lib,然后重启idea

四、项目实现过程
1.公司福利总数要求分析
根据工作岗位查询该岗位的福利统计
注意传入参数问题:
第一个是要查询的表名,第二个是表对应的岗位名称,第三个是运行模式。第四个是本地电脑的IP地址
- 使用
SparkSession构建了一个Spark应用程序,并与指定的master节点进行了通信。master地址由命令行参数提供。定义了一个数据库连接的属性,包括用户名和密码。 代码显示如下:
public static void main(String[] args) throws AnalysisException {
SparkSession ss = SparkSession.builder().appName("gm1").master(args[2]).getOrCreate();
Properties properties = new P 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1214
1214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









