







本人小白,看过多个博文,不断踩坑+重配,从其他博主的经验中总结适合服务器配置的环境,记录为方便自己后续使用,如有错误,欢迎指正!(服务器用RTX2080TI、或者2060。使用30系列总出错弃了)
一、solo/solov2环境配置
参考:环境配置经过无数踩坑,最后用这位博主方法顺利完成,亲测有用【SOLO】环境配置(mmdetection=1.0.0+mmcv = 0.2.15)_mmdetection1.0_摇曳的树的博客-CSDN博客solo环境配置最难的是版本问题,一定严格按照文中版本配置(mmdetection v1.0.0,mmcv 0.2.16或0.2.15)
1、创建虚拟环境
conda create -n solo python==3.7.3
conda activate solo2、安装指定版本的pytorch及torchvision
pip install torch==1.4.0 torchvision==0.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple3、下载V1.0.0 的mmdetection
git clone -b v1.0.0 https://github.com/open-mmlab/mmdetection.git
#下载后进入mmdetection文件中
cd mmdetection4、安装需要的模块
conda install opencv
pip install cython numpy albumentations==0.3.2 imagecorruptions matplotlib pytest-runner mmcv==0.2.15 numpy Pillow==6.2.2 six terminaltables asynctest codecov flake8 isort pytest pytest-cov pytest-runner xdoctest==0.10.0 yapf kwarray pycocotools -i https://pypi.tuna.tsinghua.edu.cn/simple
如果不行就单独安装
pip install XX -i https://pypi.tuna.tsinghua.edu.cn/simple
cython
numpy
albumentations==0.3.2
imagecorruptions
matplotlib # 5
pytest-runner # 必须在mmcv之前安装(依赖库),否则会报错!!!!!!!!!
mmcv==0.2.15 # 0.2.16版本也可以
numpy
Pillow==6.2.2
six # 10
terminaltables
asynctest
codecov
flake8
isort # 15
pytest
pytest-cov
pytest-runner
xdoctest==0.10.0
yapf # 20
kwarray
pycocotools
5、第一次编译,编译mmdetection
python setup.py develop
# 此时在mmdetection文件夹下6、 在当前mmdetection路径,下载SOLO源码
git clone https://github.com/WXinlong/SOLO.git
# 进入SOLO文件夹内
cd SOLO7、安装所需spicy模块,第二次编译,编译SOLO环境
pip install scipy
# 第二次编译环境
python setup.py develop到此,solo所需环境已配置完成,下一章对环境进行测试,看是否正确配置
二、测试配置环境
1、下载测试环境所需参数文件:选择哪个model进行测试都可以
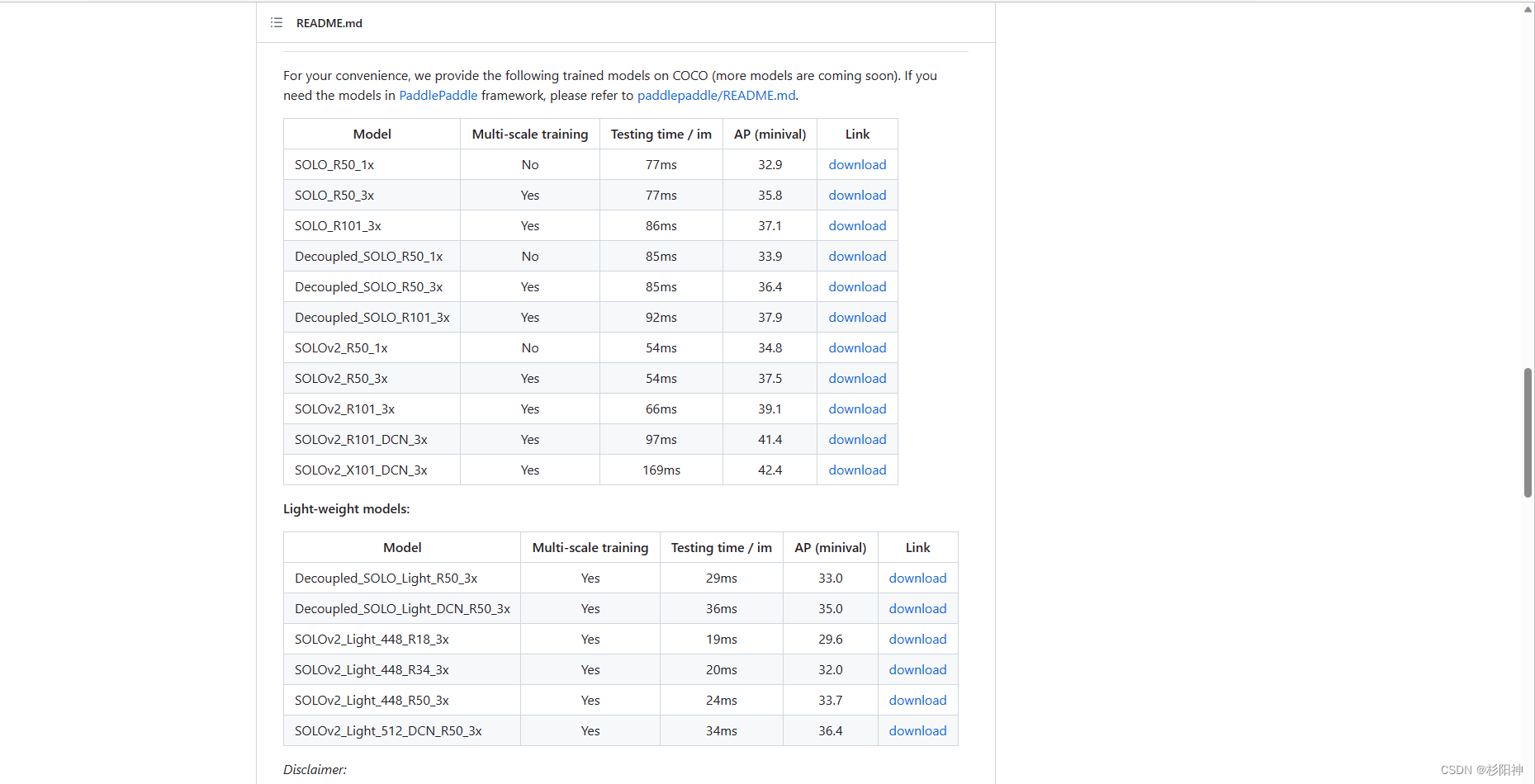
GitHub - WXinlong/SOLO: SOLO and SOLOv2 for instance segmentation, ECCV 2020 & NeurIPS 2020.
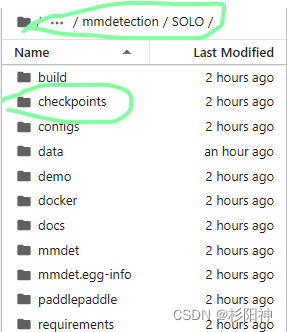
2、SOLO目录下创建名为 checkpoints的文件夹,并把demo所需model存入此文件夹
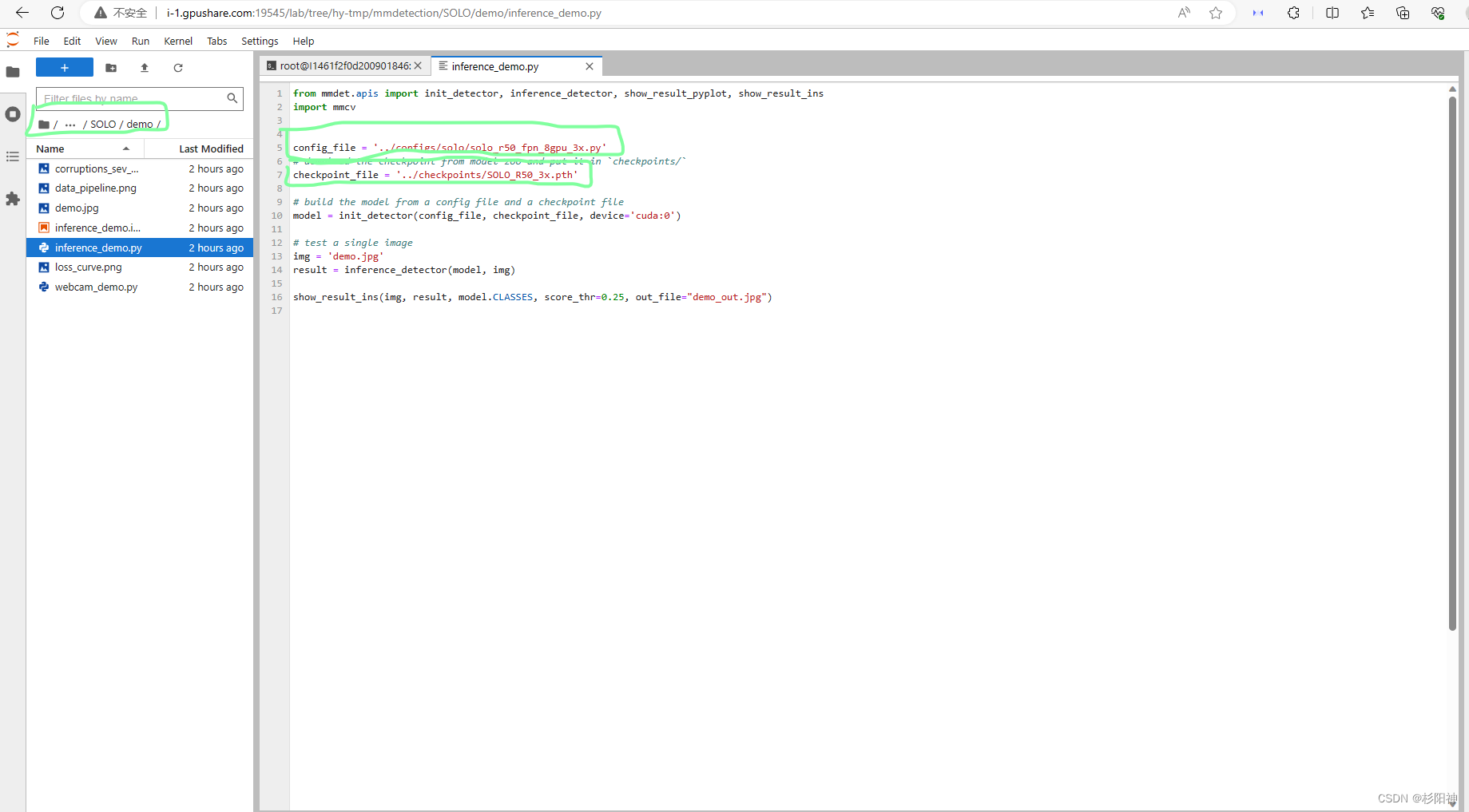
3、修改参数
按照步骤一下载的参数文件名称对应修改demo文件夹下inference_demo.py文件中的第七行代码
第五行代码按照下载的参数文件对应的算法及主干网络选择适配的文件,在第五行正确修改文件名称 。
4、运行测试指令
cd demo
python inference_demo.py 运行后会在demo文件夹下生成demo_out.jpg文件,即为测试成功

如果按照上述方式遇到问题可参考以下链接中的问题,看是否有相同:
实例分割SOLO & SOLOv2环境配置(ubuntu20.04 + miniconda)_Pertance的博客-CSDN博客
三、 solo训练自己的数据集
本文采用coco2017数据集格式,可以用labelme标注工具,用python脚本将数据集做成coco2017数据集格式。(具体数据集制作可在CSDN中搜索)
参考:solo/solov2 训练自己的数据集并且测试_solo训练自己的数据集_DuanFa95613的博客-CSDN博客
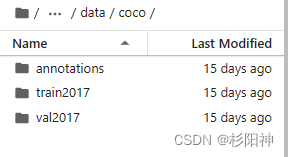
1、数据制作,将数据集放置在指定文件夹下
数据集放置在SOLO/data/coco文件夹下,具体形式如下图
2、修改对应文件的参数
a、在SOLO/mmdet/datasets文件夹下面创建的是our_data.py文件:
from .coco import CocoDataset
from .registry import DATASETS
@DATASETS.register_module
class our_data(CocoDataset):
CLASSES = ['BJX','GDX'] #lableme标注的的类的名字b、修改SOLO/mmdet/datasets/init.py文件
from .builder import build_dataset
from .cityscapes import CityscapesDataset
from .coco import CocoDataset
from .custom import CustomDataset
from .dataset_wrappers import ConcatDataset, RepeatDataset
from .loader import DistributedGroupSampler, GroupSampler, build_dataloader
from .registry import DATASETS
from .voc import VOCDataset
from .wider_face import WIDERFaceDataset
from .xml_style import XMLDataset
from .our_data import our_data #把我们的数据集加进去
__all__ = [
'CustomDataset', 'XMLDataset', 'CocoDataset', 'VOCDataset',
'CityscapesDataset', 'GroupSampler', 'DistributedGroupSampler',
'build_dataloader', 'ConcatDataset', 'RepeatDataset', 'WIDERFaceDataset',
'DATASETS', 'build_dataset','our_data'
]3、选择使用主干网络,修改对应文件
模型训练文件在SOLO/configs/solo文件夹下,选择要训练的对应修改
修改:num_classes:分类+1(背景)
数据集地址、数据集名字、json文件存放地址、模型存储的地址
total_epochs = 36,可以根据需求选择训练次数
# model settings
model = dict(
type='SOLO',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3), # C2, C3, C4, C5
frozen_stages=1,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=0,
num_outs=5),
bbox_head=dict(
type='SOLOHead',
num_classes=6, #修改 你的类个数+1
in_channels=256,
stacked_convs=7,
seg_feat_channels=256,
strides=[8, 8, 16, 32, 32],
scale_ranges=((1, 96), (48, 192), (96, 384), (192, 768), (384, 2048)),
sigma=0.2,
num_grids=[40, 36, 24, 16, 12],
cate_down_pos=0,
with_deform=False,
loss_ins=dict(
type='DiceLoss',
use_sigmoid=True,
loss_weight=3.0),
loss_cate=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
))
# training and testing settings
train_cfg = dict()
test_cfg = dict(
nms_pre=500,
score_thr=0.1,
mask_thr=0.5,
update_thr=0.05,
kernel='gaussian', # gaussian/linear
sigma=2.0,
max_per_img=100)
# dataset settings
dataset_type = 'our_data' #这里是你的数据集的名字
data_root = '/home/uc/SOLO/configs/solo/data/coco/' #这是你数据集所在文件夹
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
dict(type='Resize',
img_scale=[(1333, 800), (1333, 768), (1333, 736), #这里可以修改图片的大小。
(1333, 704), (1333, 672), (1333, 640)],
multiscale_mode='value',
keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
imgs_per_gpu=1,
workers_per_gpu=1,
train=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_train2017.json', #读取训练数据集
img_prefix=data_root + 'train2017/',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json', #读取测试数据集
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'val2017/',
pipeline=test_pipeline))
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
step=[27, 33])
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook'),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
# runtime settings
total_epochs = 36
device_ids = range(8)
dist_params = dict(backend='nccl')
log_level = 'INFO'
work_dir = './work_dirs/solo_release_r50_fpn_8gpu_3x' #存储模型路径
load_from = None
resume_from = None
workflow = [('train', 1)]4、训练网络
python tools/train.py configs/solo/solo_r50_fpn_8gpu_3x.py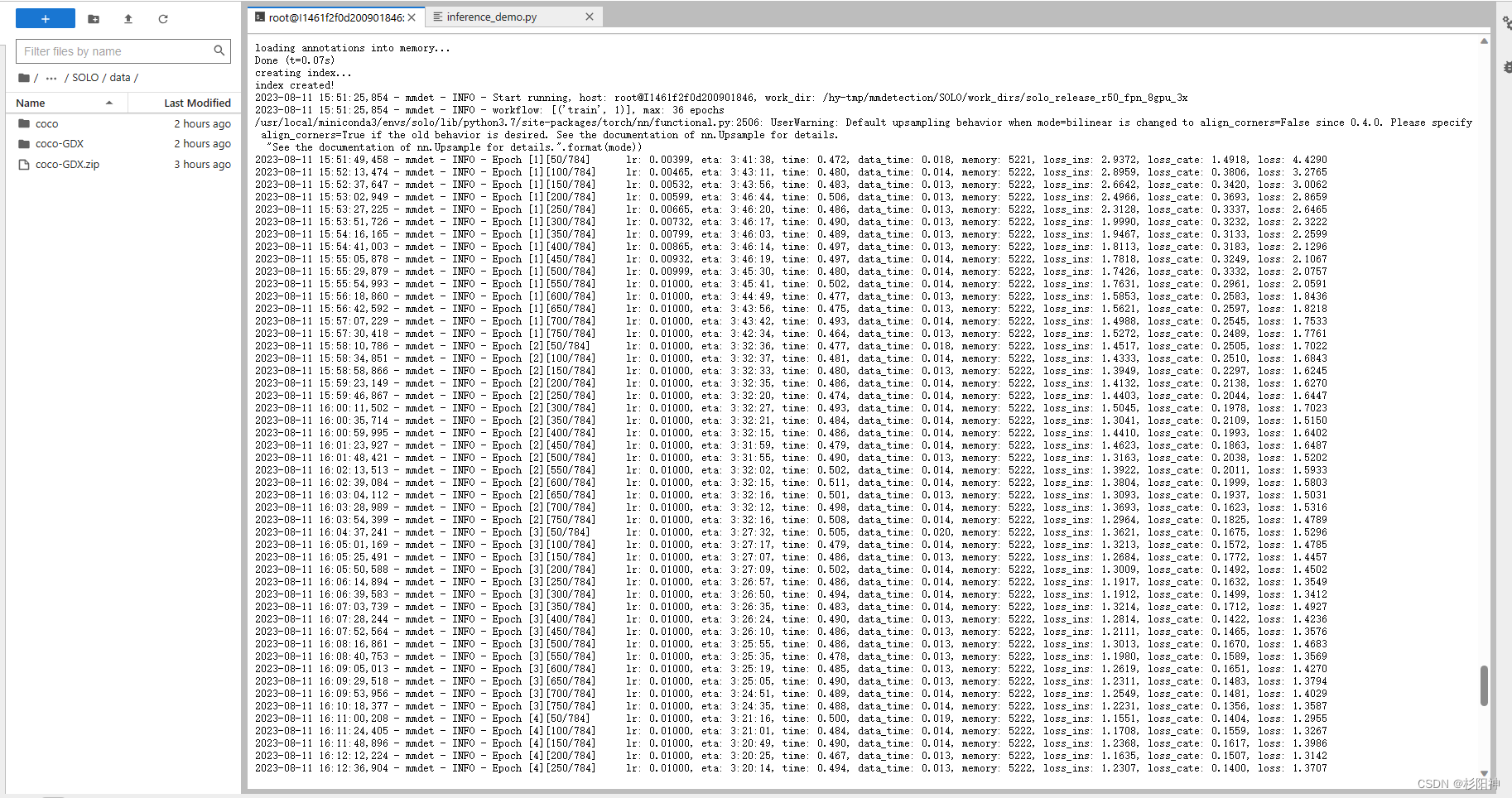
四、生成coco评价指标
训练好的参数文件 (一般保存在work_dirs文件夹中)选择要评价的参数文件,将其放在weights文件夹下(也可选择修改代码中文件地址)
python tools/test_ins.py configs/solo/solo_r50_fpn_8gpu_3x.py weights/epoch_36.pth --show --out results_solo.pkl --eval segm
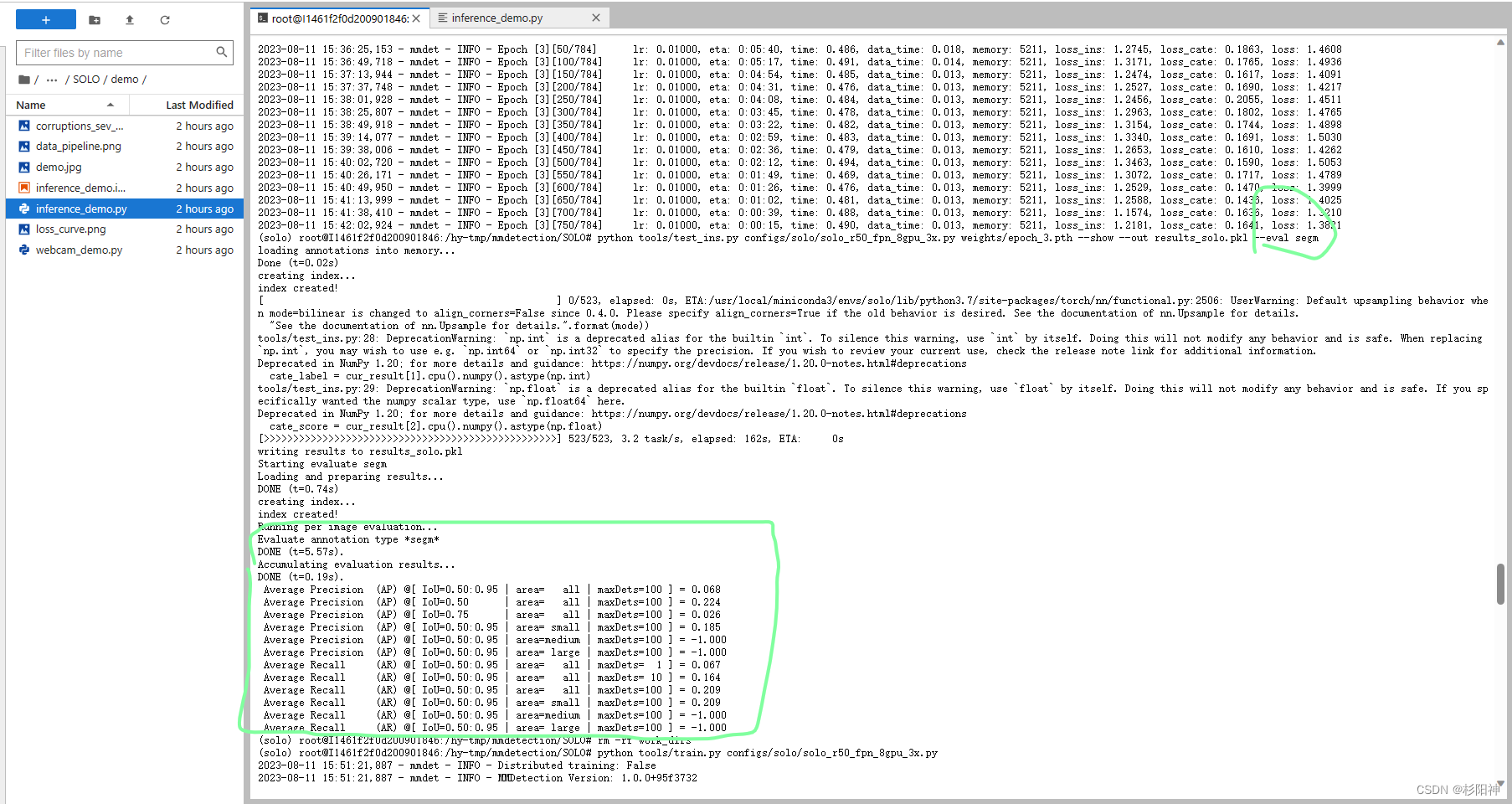
其他评价指标,参考下方链接:
SOLOV2训练教学_solov2训练自己的数据集_求则得之,舍则失之的博客-CSDN博客
总结
solo环境配置最重要的就是各个版本要求十分严格,亲测按照文中步骤可以运行,每个设备情况不同,可能配置中会遇见各种问题。小白本人经过多次、多天不断崩溃尝试,根据有经验的博文最终试出这个我行得通的方法。希望看见此文的朋友有信心,不断尝试,最终成功配置出环境!















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









