






- SVM和KNN分类对比
- KNN——邻近算法,画圆圈,取K个邻近的点
- KNN是什么,用来解决什么问题
- 定义:KNN (K-Nearest Neighbor)算法,意思是K个最近的邻居,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
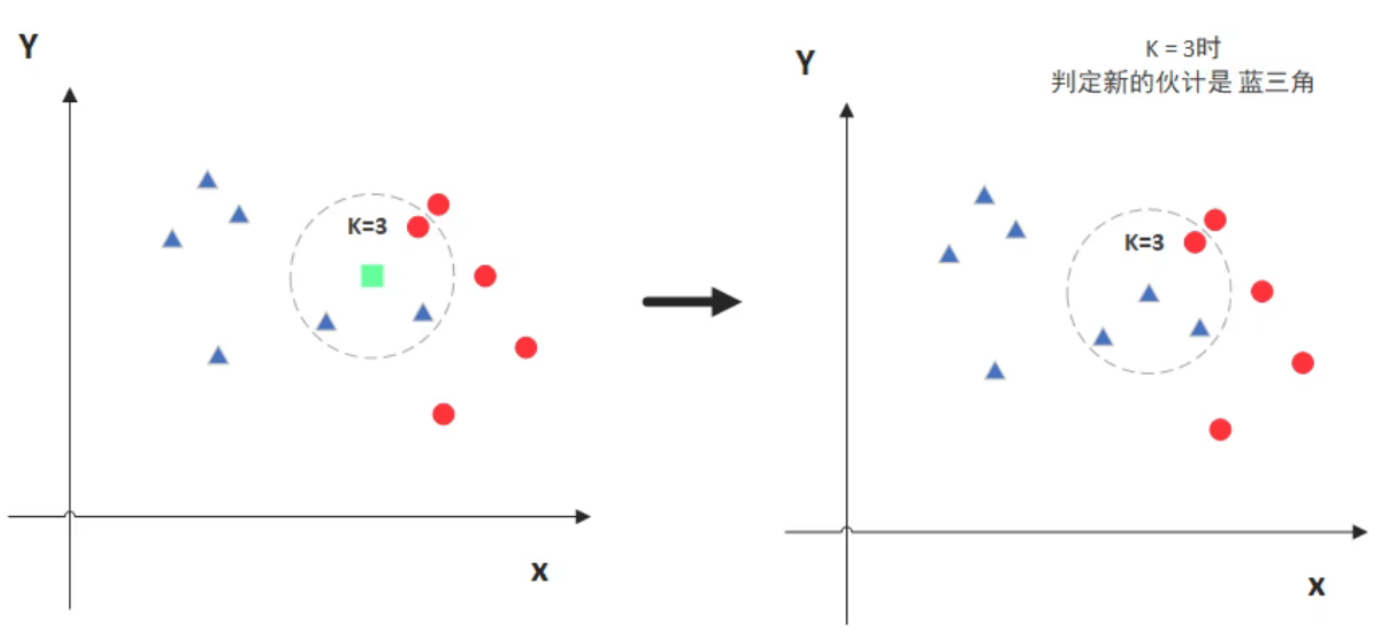
- 图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
- 但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
- KNN的决策边界一般不是线性的,也就是说KNN是一种非线性分类器,如下图。
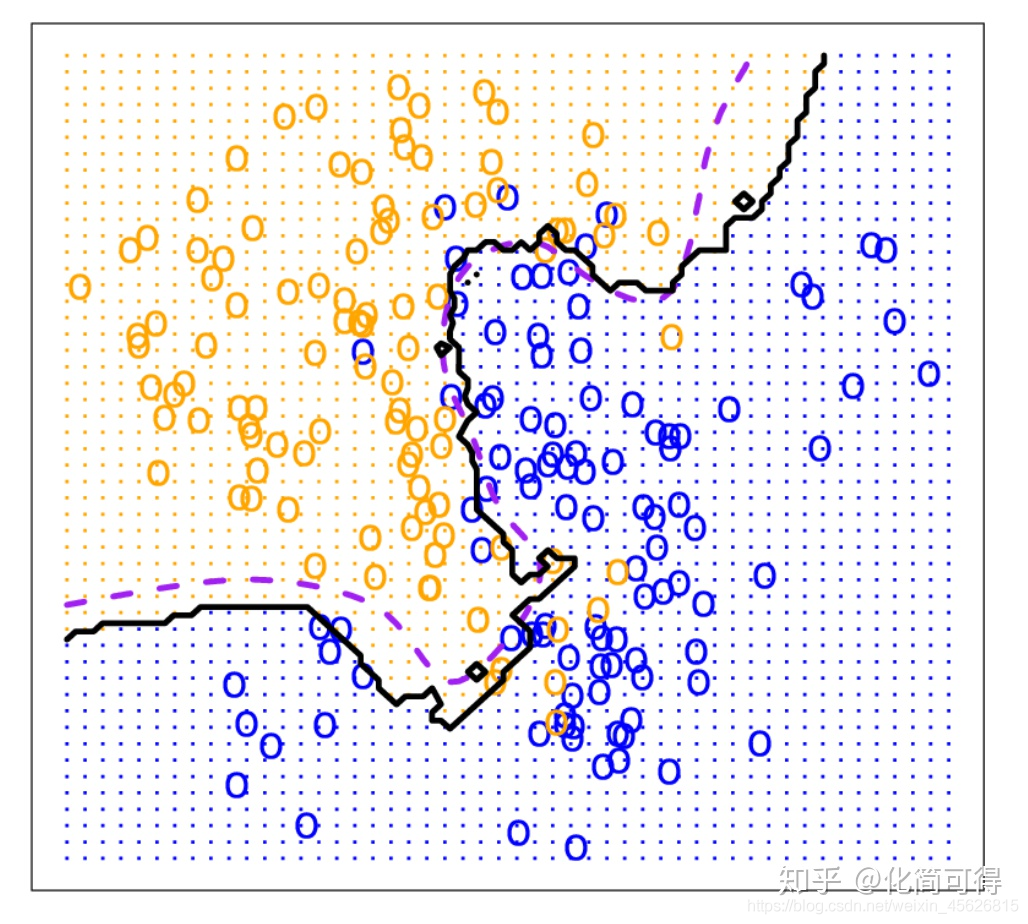
- 如何决定K大小:
- 1. K越小越容易过拟合,当K=1时,这时只根据单个近邻进行预测,如果离目标点最近的一个点是噪声,就会出错,此时模型复杂度高,稳健性低,决策边界崎岖。
- 2. 但是如果K取的过大,这时与目标点较远的样本点也会对预测起作用,就会导致欠拟合,此时模型变得简单,决策边界变平滑。
- 3. 如果K=N的时候,那么就是取全部的样本点,这样预测新点时,最终结果都是取所有样本点中某分类下最多的点,分类模型就完全失效了。
- 4. k值的选取,既不能太大,也不能太小,何值为最好,需要实验调整参数确定,一般根据经验或者均方根误差确认
- KNN是什么,用来解决什么问题
- SVM——找决策分界线,把数据划分开
- 支持向量:两边的红圈
- 分类间隔是由距离分类决策边界最近的那些少量样本决定的,而比这些样本距离分类决策边界更远的大量样本,其实都不会影响到最优权向量的求取,这些作用十分特殊的样本,就被称为“支持向量(Support Vector)”,表示是他们支撑起了线性分类器在最大分类间隔意义下的最优解。这也是为什么这种算法被称为“支持向量机(Support Vector Machine,SVM)”的原因。
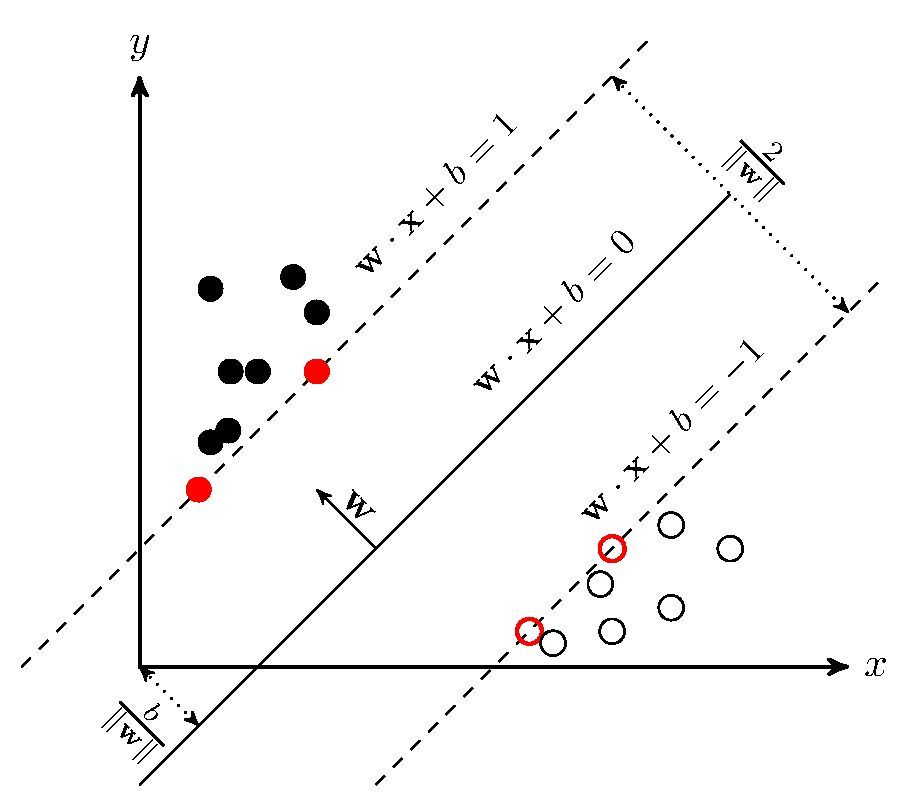
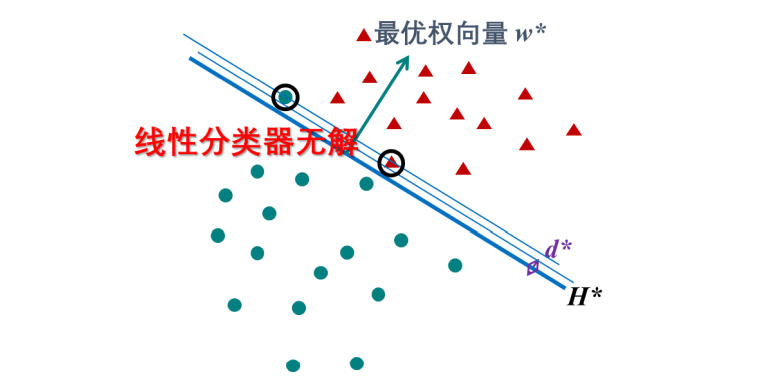
- SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, w⋅x+b=0 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
- 对于线性可分的两类问题,其分类决策边界为一 n维特征空间中的超平面 H,一般情况下会有无穷多个解。当我们确定了一个解对应的权向量 w,超平面的斜率和朝向就是确定的了,可以在一定的范围内平移超平面 H,只要不达到或者越过两类中距离 H最近的样本,分类决策边界都可以正确地实现线性分类。所以,任何一个求解得到的权向量 w,都会带来一系列平行的分类决策边界,其可平移的范围具有一定的宽度,称为分类间隔 d(Margin of Classification)。
- 优势:SVM 的性能是十分优越的,这使它自提出以来,得到了非常广泛的应用。它的显著优点,首先是不需要大量的样本(因为最终的解仅由少数支持向量决定),另外就是有很强的泛化能力。
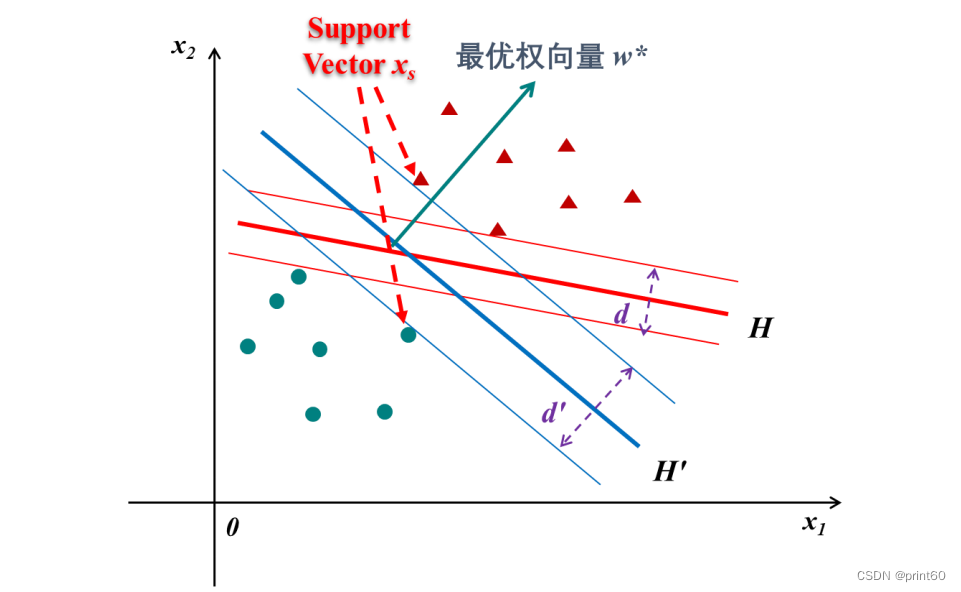
- 支持向量:两边的红圈
- KNN——邻近算法,画圆圈,取K个邻近的点

- SVM原理
- 简介
- 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机(只是划线区分);SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
- 在感知机的基础上进行优化,划线的方式很多,距离两边最远的线为最优解
- 原因:因为分类间隔越大,两类样本做分类决策时的裕量也就越大,由于样本采集所带来的特征值误差所造成的分类错误也就越少
-
- 步骤
- 找支持向量(近的)
- 计算两边所有点和假定面的距离
- 目标函数
- 目的:找到一条线,使得离该线最近的点能够最远
- 放缩变换和优化函数
- 目标函数能够体现SVM的基本定义
- 软间隔优化
- 如果一个模式识别问题,其本质上是线性可分的,但是由于模式采集的过程中各种噪声干扰和采样误差,造成了一些异常点。这些异常点会带来最优解求取的偏差,甚至有可能使线性可分的问题变成了线性不可分的问题,从而无法用线性支持向量机求解。
- 引入松弛因子
- 引入参数C,体现容错能力
- 使它们的和能够取得最小值。松弛变量和值之前的这个 C ,称为惩罚因子,表示我们对分类器中存在异常点的容忍程度。
- 即在原来的最短权向量的二次优化目标基础上,再加上一项 C\sum_{i=1} ξ ^1^{i}
- 当 C 趋近于很大时 : 意味着分类严格不能有错误
- 当 C 趋近于很小时 : 意味着可以有更大的错误容忍
- 如果一个模式识别问题,其本质上是线性可分的,但是由于模式采集的过程中各种噪声干扰和采样误差,造成了一些异常点。这些异常点会带来最优解求取的偏差,甚至有可能使线性可分的问题变成了线性不可分的问题,从而无法用线性支持向量机求解。
- 核函数
- 升维
- 目标:找到一种变换的方法,也就是 f (X)
- 升维
- 找决策分界线(宽的)
- 利用拉格朗日乘子法
- 找支持向量(近的)
- 简介
- 学习参考文章:(5条消息) 【线性分类器】(四)万字长文解释拉格朗日乘子与支持向量机_二进制人工智能的博客-CSDN博客
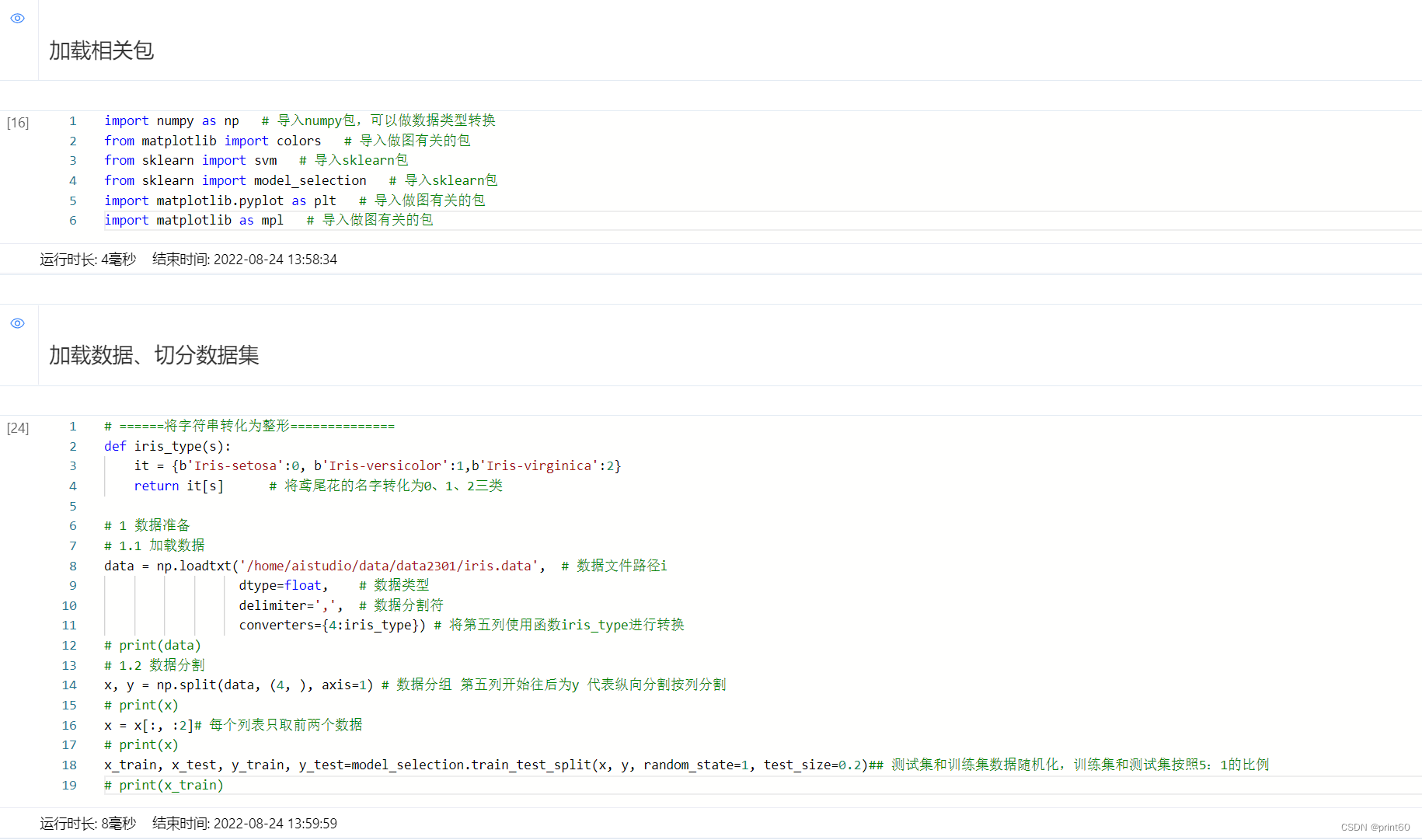
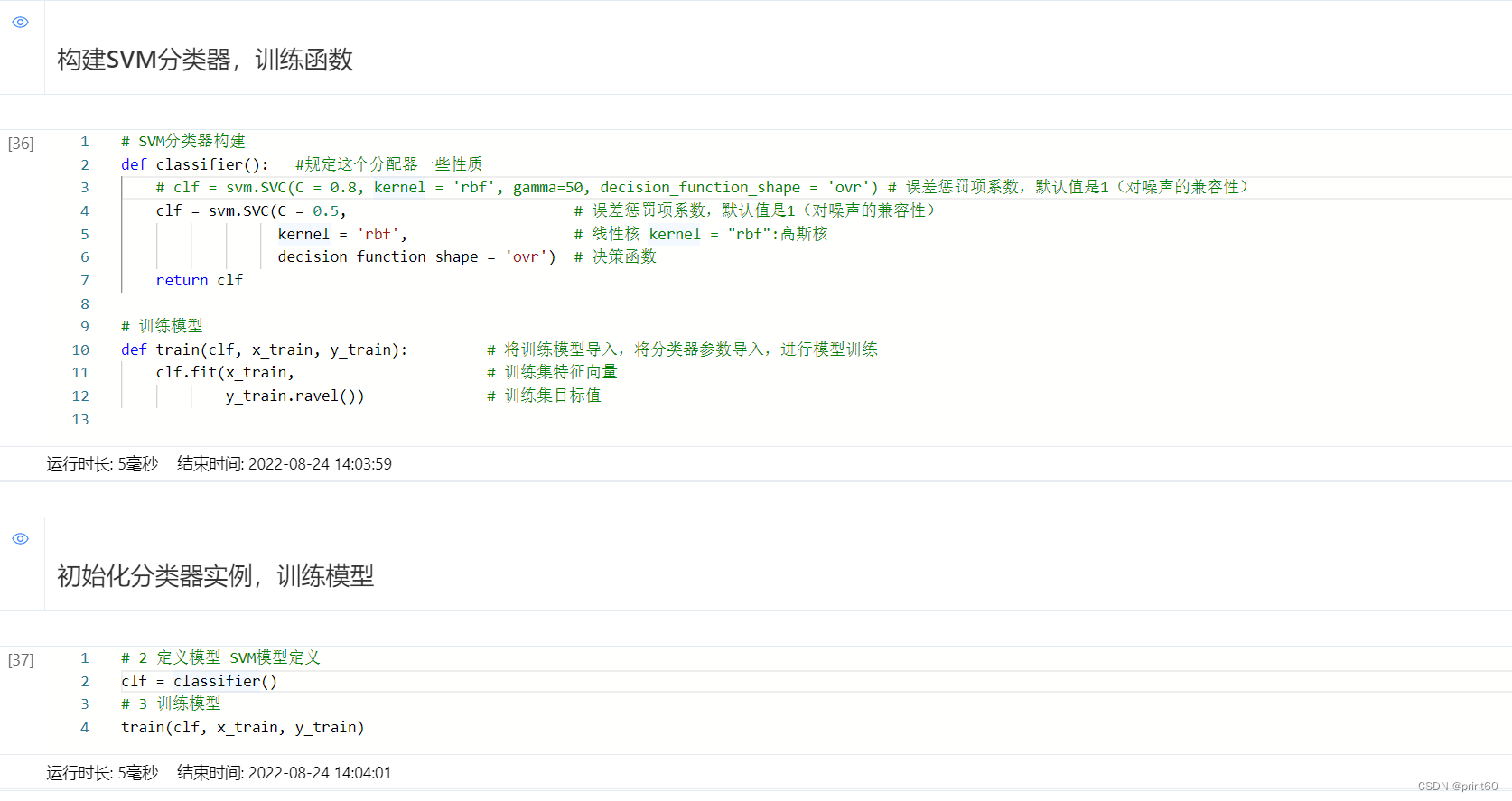
- 百度飞桨的svm鸢尾花分类项目运行















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









