







一、 什么是缓存
缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。
从性能分析:
CPU缓存>内存>磁盘>数据库
从性能来看内存是介于CPU和磁盘,在实际中内存是CPU和磁盘的桥梁。buffer和cache是内存的不同的 体现,接下来简单分析对buffer和cache的理解。
1.1 buffer和cache
Buffer和Cache都是一种缓存技术,但它们的具体含义和应用场景有所不同。
1.1.1 buffer:
A buffer is something that has yet to be “written” to disk.
buffer是为了提高内存和硬盘(或其他I/O设备)之间的数据交换的速度而设计的。buffer将数据缓冲下 来,解决速度慢和快的交接问题;速度快的需要通过缓冲区将数据一点一点传给速度慢的区域。例如: 从内存中将数据往硬盘中写入,并不是直接写入,而是缓冲到一定大小之后刷入硬盘中。
Buffer通常指的是缓冲区,主要用于在两个设备之间进行数据传输时,将待传输的数据暂存到缓冲区中,并从中读取数据进行传输,以避免由于传输速度不匹配而导致的数据丢失或者错误。在编程中,Buffer也常被用于临时存储字符串或二进制数据,以减少频繁的读写操作,提高程序的效率和性能。
1.1.2 cache:
A cache is something that has been “read” from the disk and stored for later use.
cache就是从磁盘读取数据然后存起来方便以后使用。cache实现数据的重复使用,速度慢的设备需要通 过缓存将经常要用到的数据缓存起来,缓存下来的数据可以提供高速的传输速度给速度快的设备。例 如:将硬盘中的数据读取出来放在内存的缓存区中,这样以后再次访问同一个资源,速度会快很多。
Cache通常指高速缓存,用于存储系统中频繁访问的数据或指令等,以提高系统性能和效率。Cache通常位于CPU和内存之间,可以快速地存取数据和指令,避免了频繁从主存中读取数据所带来的延迟。
Cache的主要作用是加速CPU对内存的访问,提高计算机系统的运行速度和响应速度。在实际应用中,Cache常被用于优化计算机的访问速度,比如将经常使用的数据、指令或者程序代码等存储到Cache中,以便后续访问时可以更快地获取数据。
比如,在浏览网页时,当用户第一次打开一个网站时,浏览器会将网页的HTML、CSS、JS等文件从服务器上下载下来,并存储到本地的缓存(即浏览器的Cache)中。下次用户再次访问同一个网站时,浏览器就可以直接从本地Cache中读取数据,避免了重新下载文件所带来的延迟,提高了网页的加载速度。
总之,Cache是一种高速缓存技术,主要用于存储系统中频繁访问的数据或指令等,以提高系统性能和效率。Cache的作用是加速CPU对内存的访问,减少因为访问速度慢而产生的延迟。在实际应用中,Cache可以用于缓存各种类型的数据,方便后续取用。
1.1.3 buffer和cache的特点
Buffer通常用于缓存正在传输的数据,由于需要频繁地写入和清空,因此缓存容量较小,且生命周期比较短;而Cache则用于缓存系统中经常访问的数据,由于数据较为稳定,因此缓存容量较大,且生命周期比较长。
- 共性: 都属于内存,数据都是临时的,一旦关机数据都会丢失。
- 差异:(先理解前两点,后两点有兴趣可以了解)
- A.Buffer通常用于暂存将要写入外部设备的数据,而Cache则是缓存已经读取的数据。
- B.buffer数据丢失会影响数据完整性,源数据不受影响;cache数据丢失不会影响数据完整性,但会影响 性能。
- C.一般来说cache越大,性能越好,超过一定程度,导致命中率太低之后才会越大性能越低。buffer来 说,空间越大性能影响不大,够用就行。cache过小,或者没有cache,不影响程序逻辑(高并发cache 过小或者丢失导致系统忙死除外)。buffer过小有时候会影响程序逻辑,如导致网络丢包。
- D.cache可以做到应用透明,编写应用的可以不用管是否有cache,可以在应用做好之后再上cache。当 然开发者显式使用cache也行。buffer需要编写应用的人设计,是程序的一部分。
1.2 linux系统如何查看内存的缓存
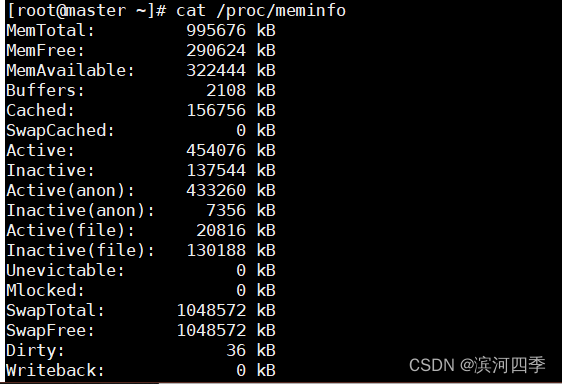
1.2.1 cat /proc/meminfo
查看动态更新的虚拟文件。内容比较全面,可以查看到许多关于内存的信息。
1.2.2 free 快速查看内存的方法
也是经常使用的命令。-h 更人性化的显示内存的单位 -m 以M的形式显示
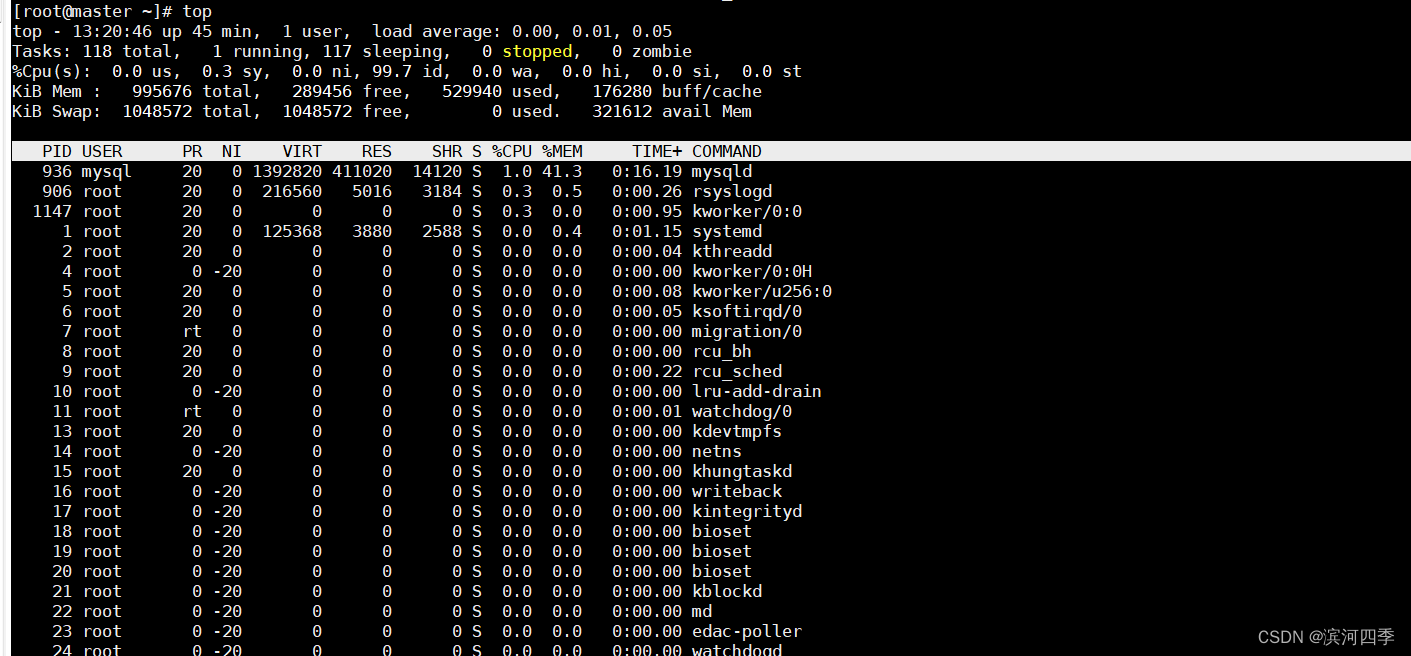
1.2.3 top
top命令提供了实时的运行中的程序的资源使用统计。可以根据内存的使用和大小来进行排序。
退出top命令直接Ctrl+C
快捷键:shift+m 按内存利用率排序 shift+p 按cpu利用率排序
1.2.3 sar
Linux统计/监控工具sar详细介绍:要判断一个系统瓶颈问题,有时需要几个 sar 命令选项结合起来使用:
例如:
- 怀疑CPU存在瓶颈,可用 sar -u 和 sar -q deng 等来查看
- 怀疑内存存在瓶颈,可用 sar -B、 sar -r 和 sar -W 等来查看
- 怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看

二、memcached简介
Memcached 目前这款软件流行于全球各地,经常被用来建立缓存项目,并以此分担来自传统数据库的并发负载压力。
Memcached 可以轻松应对大量同时出现的数据请求,而且它拥有独特的网络结构,在工作机制方面, 它还可以在内存中单独开辟新的空间,建立 HashTable,并对 HashTable 进行有效的管理。
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过 在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可 以用任何语言来编写,并通过memcached协议与守护进程通信。
官方网站地址:https://memcached.org/
官方介绍: memcached is a high-performance, distributed memory object caching system, generic in nature, but originally intended for use in speeding up dynamic web applications by alleviating database load.
memcached是一种高性能、分布式内存对象缓存系统,本质上是通用的,但最初旨在通过减轻数据库 负载来加速动态web应用程序。
2.1 memcache与memcached
我们有时会见到 Memcache 和 Memcached 两种不同的说法,为什么会有两种名称?
其实 Memcache 是这个项目的名称,而 Memcached 是它服务器端的主程序文件名。一个是项目名 称,另一个是主程序文件名。
memcached是一种缓存技术,将数据放入内存,从而通过内存访问提速,因为内存是最快的, memcached的主要目的是提速。
在memcached中维护了一张大的hashtable表,该表在内存中,表的结构是key和value;
memcached的key一般是字符串,不能重复 memcached的value可以放入(字符串,数值,数组,对象,布尔,二进制数据,图片和视频)
2.2主要解决如下问题
由于网站的高并发读写和对海量数据的处理需求,传统的关系型数据库开始出现瓶颈。
对数据库的高并发读写
关系型数据库本身就是个庞然大物,处理过程非常耗时(如解析 SQL 语句、事务处理等)。如果对关系 型数据库进行高并发读写(每秒上万次的访问),数据库系统是无法承受的。
对海量数据的处理
对于大型的 SNS(Social Network Service) 网站(如 Twitter、新浪微博),每天有上千万条的数据产 生。对关系型数据库而言,如果在一个有上亿条数据的数据表中查找某条记录,效率将非常低。 使用 Memcached 就能很好地解决以上问题
2.3 Memcached数据库特点
memcached作为高速运行的分布式缓存服务器,具有以下的特点。
- 协议简单
- 使用基于文本行的协议,能直接通过telnet在Memcached服务器上存取数据,实现比较简单
- 基于libevent的事件处理
- libevent是基于C开发的程序库,Memcached利用这个库进行异步事件处理
- 内置内存存储方式
- Memcached有一套自己的管理内存方式,而且非常高效,所有数据都保存在Memcached内置的内存 中,当存入的数据占满空间时,会使用LRU算法来清除不使用的缓存数据,从而来重用过期数据的内存 空间,但重启服务器数据将丢失
- memcached不互相通信的分布式
- 各个Memcached服务器之间互不通信,都是独立存取数据,通过客户端的设计让其具有分存式特点, 支持大量缓存和大规模应用
三、Memcached 安装
yum安装(推荐)
Linux系统安装memcached,首先要先安装依赖库。
yum install gcc gcc-c++ libevent-devel
然后使用如下命令安装(仅限Redhat/Fedora/Centos)
yum install memcached -y

四、Memcached 运行
(1)作为前台程序运行:
从终端输入以下命令,启动memcached:
memcached -u root -p 11211 -m 64m -vv这里显示了调试信息。这样就在前台启动了memcached,监听TCP端口11211,最大内存使用量为 64M。调试信息的内容大部分是关于存储的信息。
(2)作为后台服务程序运行:
不指定IP运行:
memcached -p 11211 -m 64m -d -u root指定IP和PID存放位置运行:
memcached -d -m 64M -u root -l 192.168.0.200 -p 11211 -c 256 -P /tmp/memcached.pid
五、Memcached 的特征
Memcached 作为高速运行的分布式缓存服务器,具有以下特点。
- 协议简单
- Memcached 的服务器客户端通信并不使用复杂的.xml等格式,而是使用简单的基于文本行的协议。
- Memcached 连接
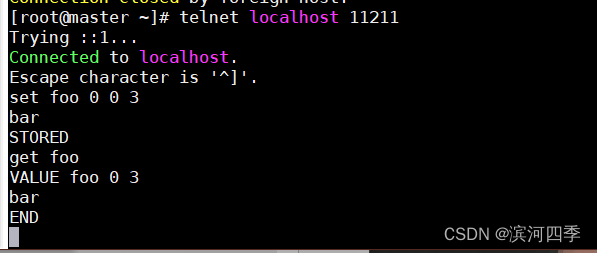
- 因此,通过 telnet 也能在 Memcached 上保存数据、取得数据。以下为示例代码:
telnet localhost 11211 Connected to localhost.localdomain(127.0.0.1). Escape character is '^]'. set foo 0 0 3 (保存命令) bar (数据) STORED (结果) get foo (取得命令) VALUE foo 0 3 (数据) bar (数据)
六、Memcached之应用实例配置
1、应用实例配置
1)基础环境配置,三台服务器最好都做
①关闭防火墙:
systemctl stop firewalld systemctl disable firewalld sed -i 's/enforcing/disabled/' /etc/selinux/config setenforce 0②同步时间:
yum -y install ntp ntpdate
ntpdate cn.pool.ntp.org
hwclock --systohc
③环境规划:
IP地址 环境 192.168.198.142 memcache 192.168.198.147 web 192.168.198.148 mysql
2)web服务器配置
在web服务器192.168.198.147 上安装软件,启动服务
卸载系统默认的mysql版本
rpm -e mariadb-libs postfix
安装数据库软件,如果是克隆过来的因为已经安装过了则不需要安装;
过程略,如果没有安装参考之前的mysql博客进行安装;
安装lnmp环境
yum install httpd php php-gb php-mysql php-memcache
启动apache服务
systemctl restart httpd sysstemctl enable httpd
3)mysql数据库服务器配置
在mysql服务端创建用户(192.168.198.148)
mysql8.0中默认的身份认证插件是caching_sha2_password,替代了之前的
mysql_navtive_password,并且设置用户的host范围为%,使所有主机都可以连接create user 'memcache'@'%' identified by 'Nebula@123'; ALTER USER'memcache'@'%' IDENTIFIED WITH mysql_native_password BY 'Nebula@123'; flush privileges;
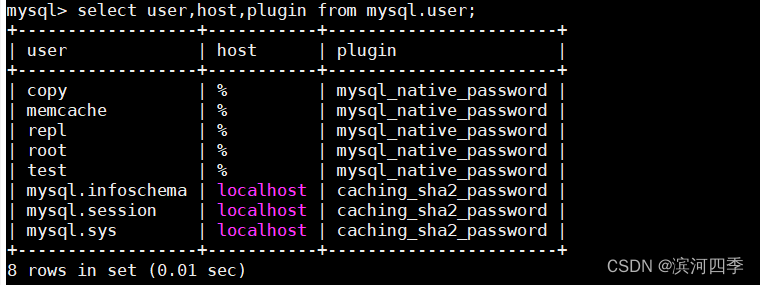
检查mysql用户表中有刚才创建的用户信息
select user,host,plugin from mysql.user;
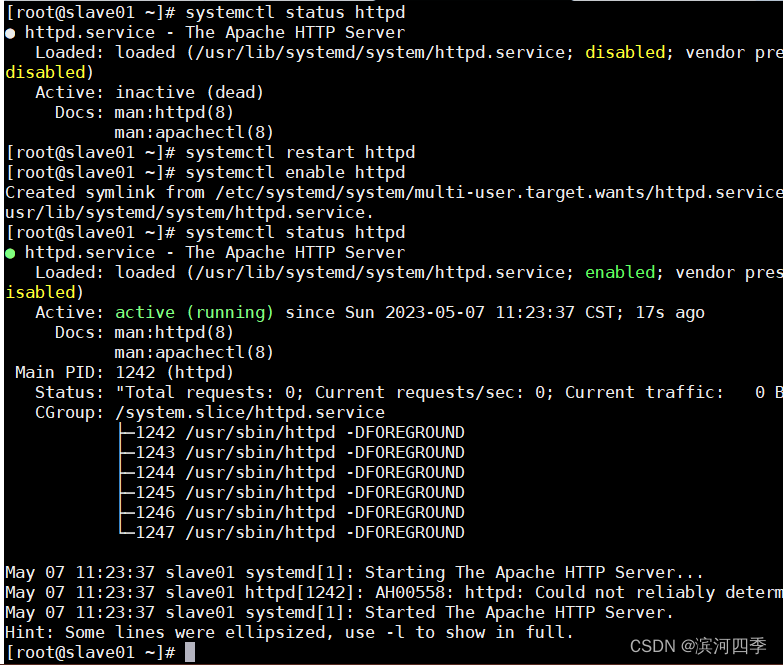
4) web服务器测试
(web服务器上)测试http功能,如下图则正常
vim /var/www/html/index.html
测试PHP测试功能
vim /var/www/html/index.php<?php phpinfo(); ?>
5) 在web服务器上测试mysql服务器是否连接成功
在web服务器(192.168.198.147)上编写下面的文件:
vim /var/www/html/mysql.php<?php $link=mysql_connect('192.168.198.148','memcache','Nebula@123'); if($link) echo "Success!!"; else echo "Fail!!"; mysql_close(); ?>
写完之后保存退出;
然后浏览器上连接你的web服务器IP;显示Success!!成功连接mysql服务器。
6)memcache 服务配置及测试
安装启动略(未安装参考之前的安装方法) 测试略,只要保证服务正常启动并能正常访问就可
7)实例功能测试
①测试web和memcache的连通性
如果你是使用后台开启的memcache服务,就不用杀死
②Web服务器(192.168.42.30)做代码测试
这里的IP地址为memcached端,和他的端口号
<?php $memcache = new Memcache; $memcache->connect('192.168.198.142', 11211) or die ("Could not connect"); $version = $memcache->getVersion(); echo "Server's version: ".$version." "; $tmp_object = new stdClass; $tmp_object->str_attr = 'test'; $tmp_object->int_attr = 123; $memcache->set('key', $tmp_object, false, 10) or die ("Failed to save data at the server"); echo "Store data in the cache (data will expire in 10 seconds) "; $get_result = $memcache->get('key'); echo "Data from the cache: "; var_dump($get_result); ?>
③ 在web服务器下配置session(web端192.168.198.147):
vim /etc/php.inisession.save_handler = memcache session.save_path ="tcp://192.168.42.29:11211? persistent=1&weight=1&timeout=1&retry_interval=15"
④ 测试memcached的可用性:
vim /var/www/html/memcache1.php<?php session_start(); if (!isset($_SESSION['session_time'])) { $_SESSION['session_time'] = time(); } echo "session_time:".$_SESSION['session_time']." "; echo "now_time:".time()." "; echo "session_id:".session_id()." "; ?>
⑤ 在mysql服务器(192.168.198.148)上创建测试数据库:
create database testab1; use testab1; create table test1(id int not null auto_increment,name varchar(20) default null,primary key(id)) engine=innodb auto_increment=1 default charset=utf8; insert into test1(name) values ('tom1'),('tom2'),('tom3'),('tom4'),('tom5');
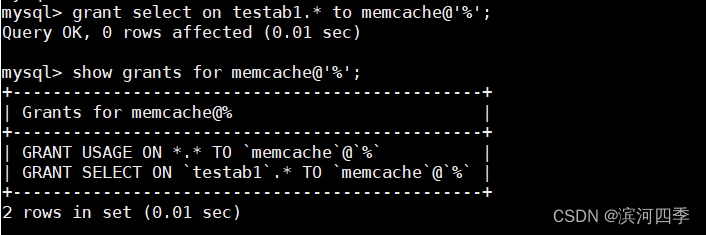
⑥ 对memcache用户赋予库testab1的查看权限
grant select on testab1.* to memcache@'%'; show grants for memcache@'%';
⑦ 在web服务器上创建下面的文件:
vim /var/www/html/memcache2.php$key=md5($query); if(!$memcache->get($key)) { $conn=mysql_connect("192.168.198.148","memcache","Nebula@123"); //数据库节点,地址,用户,密码 mysql_select_db(testab1); $result=mysql_query($query); while ($row=mysql_fetch_assoc($result)) { $arr[]=$row; } $f = 'mysql'; $memcache->add($key,serialize($arr),0,30); $data = $arr ; } else{ $f = 'memcache'; $data_mem=$memcache->get($key); $data = unserialize($data_mem); } echo $f; echo ""; echo "$key"; echo ""; //print_r($data); foreach($data as $a) { echo "number is $a[id]"; echo ""; echo "name is $a[name]"; echo ""; } ?>
注意:memcached有个缓存时间默认是1分钟,过了一分钟后,memcached需要重新从数据库中取得数据
















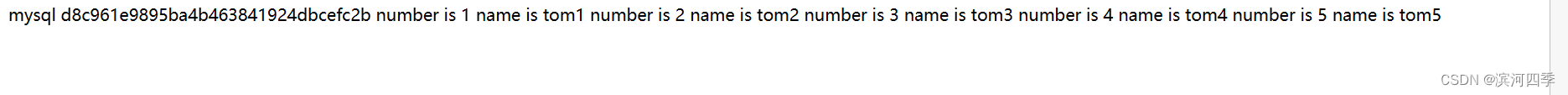

















 2847
2847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











