






1、Hive和MapReduce的关系
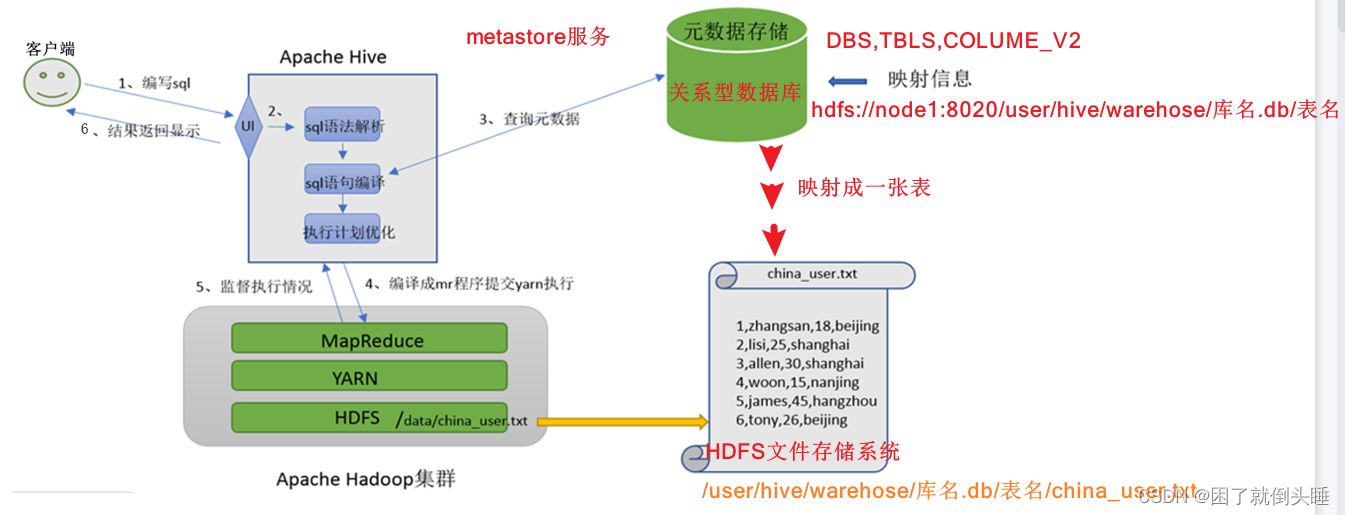
 1- 用户在Hive上编写数据分析的SQL语句,然后再通过Hive将SQL语句翻译成MapReduce程序代码,最后提交到Yarn集群上进行运行
1- 用户在Hive上编写数据分析的SQL语句,然后再通过Hive将SQL语句翻译成MapReduce程序代码,最后提交到Yarn集群上进行运行
2- 大家可以将Hive理解成有道词典,帮助你翻译英文
2、Hive架构
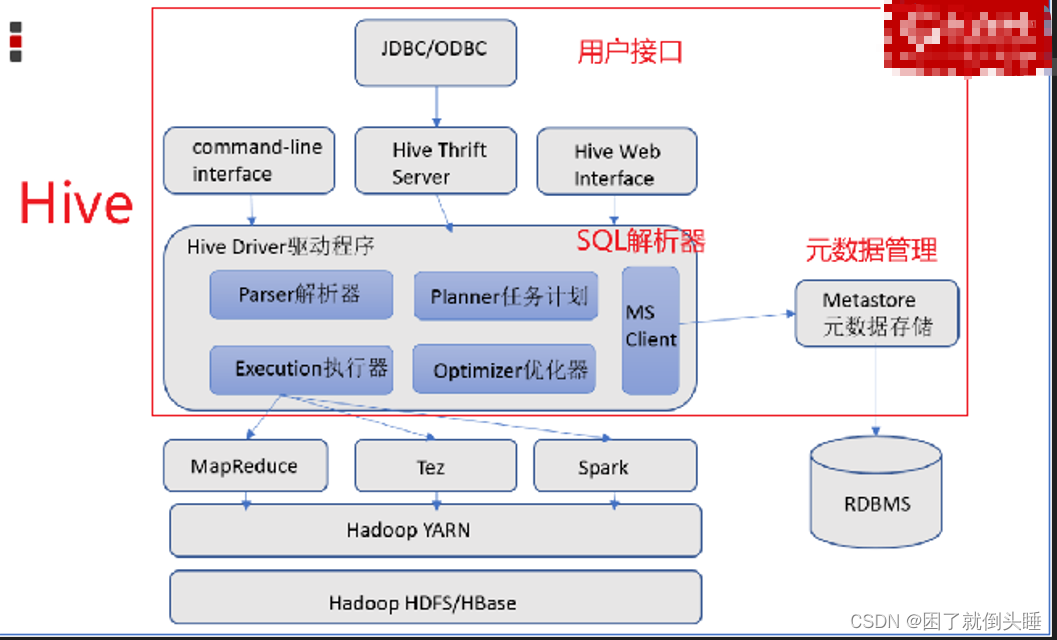
用户接口: 包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。Hive提供了 Hive Shell、 ThriftServer等服务进程向用户提供操作接口
Hiveserver2(Driver): 包括了语法、词法检查、计划编译器、优化器、执行器。核心作用是完成对HiveSQL(HQL)语句从词法、语法检查,并且进行编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce进行执行。
注意: 这部分内容不是具体的进程,而是封装在Hive所依赖的jar中通过Java代码实现。
元数据信息: 包含用Hive创建的Database、table,以及表里面的字段等详细信息
元数据存储: 存储在关系型数据库(RDBMS relation database manager system)中。例如:Hive中有一个默认的关系型数据库是Derby,但是一般会改成MySQL。
Metastore: 是一个进程(服务),用来管理元数据信息。
作用: 客户端连接到Metastore中,Metastore再去关系型数据库中查找具体的元数据信息,然后将结果返回给客户端。
特点: 有了Metastore服务以后,就可以有多个客户端(工作中一般使用的就是DataGrip)同时连接。而且这些客户端都不需要知道元数据存储在什么地方,你只需要连接到Metastore服务里面就行。
3、MetaStore元数据管理服务
metastore服务配置有3种模式: 内嵌模式、本地模式、远程模式
推荐使用: 远程模式
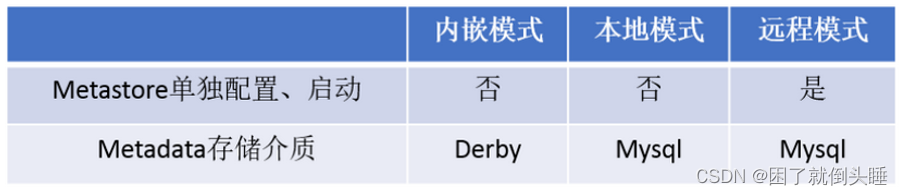
内嵌模式:
优点: 解压hive安装包 bin/hive 启动即可使用
缺点: 不适用于生产环境,derby和Metastore服务都嵌入在主Hive Server进程中,一个服务只能被一个客户端连接(如果用两个客户端以上就非常浪费资源),且元数据不能共享
本地模式:
优点: 可以单独使用外部数据库(一般是MySQL)进行元数据的管理
缺点: 相对浪费资源。指的是Metastore每次启动一次的时候都需要对应的启动Hiveserver2服务。也就是本地模式他们两个是成对出现的。这3个服务的启动顺序,MySQL->metastore->Hiveserver2
远程模式:
优点: 可以单独使用外部数据库(一般是MySQL)进行元数据的管理。Hiveserver2、metastore、MySQL这3个可以单独配置、启动、运行
缺点:
1- 这3个服务的启动顺序,MySQL->metastore->Hiveserver2
2- 这3个服务可能是分布在不同机器上运行的,可能会导致不同服务间进行数据交换速度比较慢
4、数据仓库和数据库
4.1 数据仓库和数据库的区别
数据库与数据仓库的区别:实际讲的是OLTP与OLAP的区别
OLTP(On-Line Transaction Processin): 联机事务处理。数据库中可以进行数据的【增删改查】操作
OLAP(On-Line Analytical Processing): 联机分析处理。数据仓库中主要是对数据进行【查询】操作
数据仓库主要特征:
数据仓库的出现,并不是要取代数据库,主要区别如下:
1- 数据库是面向事务的设计,数据仓库是面向主题设计的。
2- 数据库是为捕获(指的是能够对数据进行增删改操作)数据而设计,数据仓库是为分析数据而设计
3- 数据库一般存储业务数据(由于用户的各种操作行为产生的数据,例如:下单、商品浏览等),数据仓库存储的一般是历史数据。
4- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。
5- 数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。

4.2 数据仓库基础三层架构
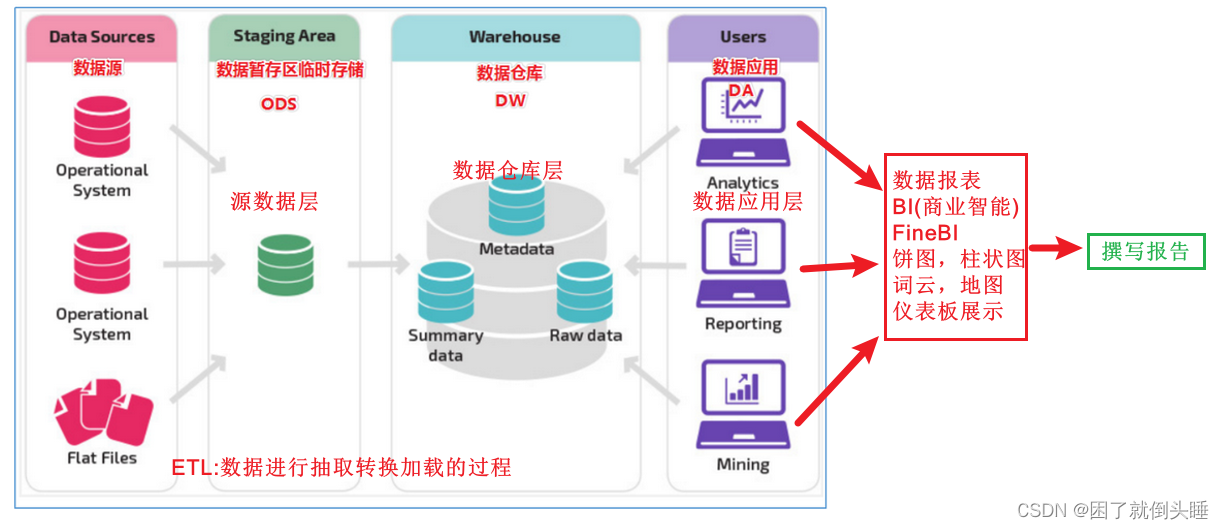
源数据层(ODS): 该层数据几乎不做任何处理操作。直接使用外部系统中的数据结构(数据库名称、表名称、表结构)。为大数据数仓中后续的其他处理提供数据支撑
数据仓库层(DW): 也称之为细节层。DW层的数据应该做到一致、准确、干净。也就是对ODS层中的数据进行ETL以及数据指标分析
数据应用层(DA或APP): 前端页面直接读取该层的数据,进行前端可视化(以看得见的图表、曲线图、柱状图、饼图)的展示
大数据前端产品示例:https://tongji.baidu.com/main/overview/demo/overview/index
4.3 ETL和ELT
广义上ETL:数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extract, 转化Transform , 装载Load)的过程。 但是在实际操作中将数据加载到仓库却产生了两种不同做法:ETL和ELT。 狭义上ETL: 先将数据从业务系统(可以理解为例如京东的订单数据)中抽取到数据仓库的ODS层中,然后执行转换操作,将数据结构化并且转换层适合后续容易处理的表结构 ELT: 将数据从业务系统中抽取并且直接加载到数据仓库的DW层的表里面。加载完以后,再根据业务需求对数据进行清洗以及指标的计算分析
















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











