






4、hive其他join操作
在Hive中除了cross join left outer join等这些以外,还有left semi join(左半连接)、full outer join(全外连接) 全外连接: 左表 full outer join 右表 on 关联条件 左半开连接: 左表 left semi join 右表 on 关联条件
示例:
-- 全外连接:full outer join on 大白话解释:左外和右外结果合并 select * from users u full outer join orders o on u.userId = o.userid; -- 左半连接:left semi join on select * from users u left semi join orders o on u.userId = o.userid;
hive中所有join的演示:
use day07; create table tb_1( id int, name string )row format delimited fields terminated by ','; create table tb_2( id int, name string )row format delimited fields terminated by ','; select * from tb_1; select * from tb_2; -- cross join:产生笛卡尔积,tb_1 * tb_2。写SQL的时候,尽可能避免 select * from tb_1 cross join tb_2; -- left outer join:以左表为主,将左表中所有的数据都展示,只展示右表中关联上的内容 select * from tb_1 left outer join tb_2 on tb_1.id=tb_2.id; -- right outer join:以右表为主,将右表中所有的数据都展示,只展示左表中关联上的内容 select * from tb_1 right outer join tb_2 on tb_1.id=tb_2.id; -- full outer join:实际是左右join的结果合并。也就是现在没有哪个是主表,地位都是一样的 select * from tb_1 full outer join tb_2 on tb_1.id=tb_2.id; -- left semi join:左半连接,左右表关联,关联上了以后,只展示左表的数据,右表数据不展示。如果有数据重复,不会去重 select * from tb_1 left semi join tb_2 on tb_1.id=tb_2.id; -- 没有right semi join。可以交换表的位置然后通过left semi join来实现 -- select * from tb_1 right semi join tb_2 on tb_1.id=tb_2.id; select * from tb_2 left semi join tb_1 on tb_1.id=tb_2.id;
5、hive其他排序操作
cluster by: 先对数据在处理的时候进行分桶,分完桶以后,再对桶内的数据进行局部排序。分桶和排序的字段是同一个 distribute by: 只对数据在处理的时候进行分桶,不排序 sort by: 只对数据进行局部的排序 order by: 对数据进行全局排序 distribute by + sort by: 先对数据在处理的时候进行分桶,分完桶以后,再对桶内的数据进行局部排序。分桶和排序的字段可以单独指定
示例:
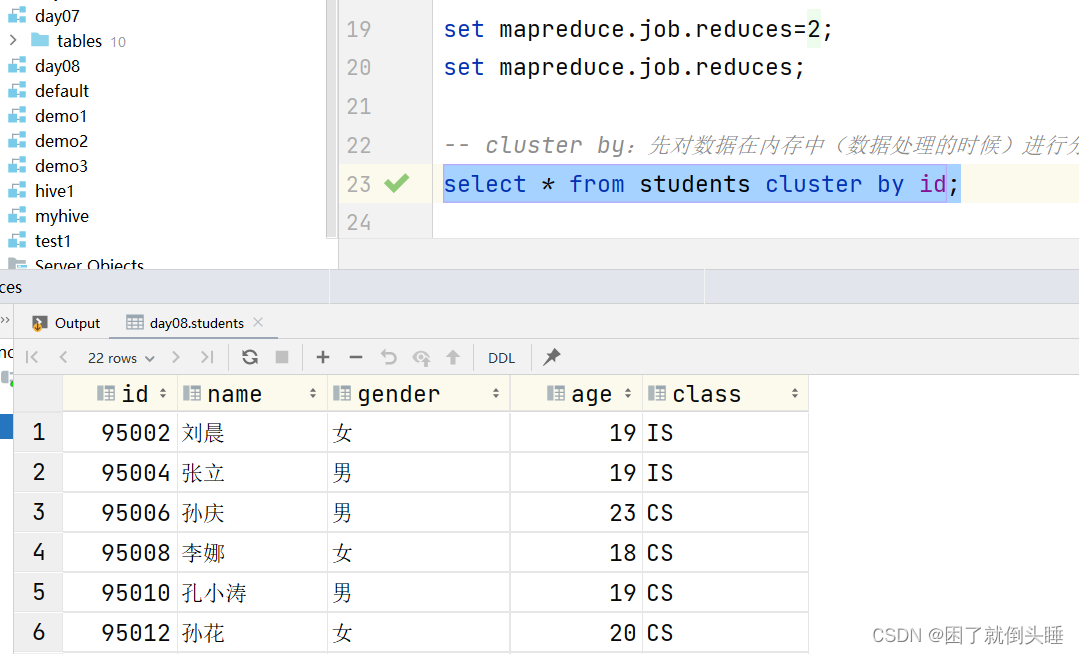
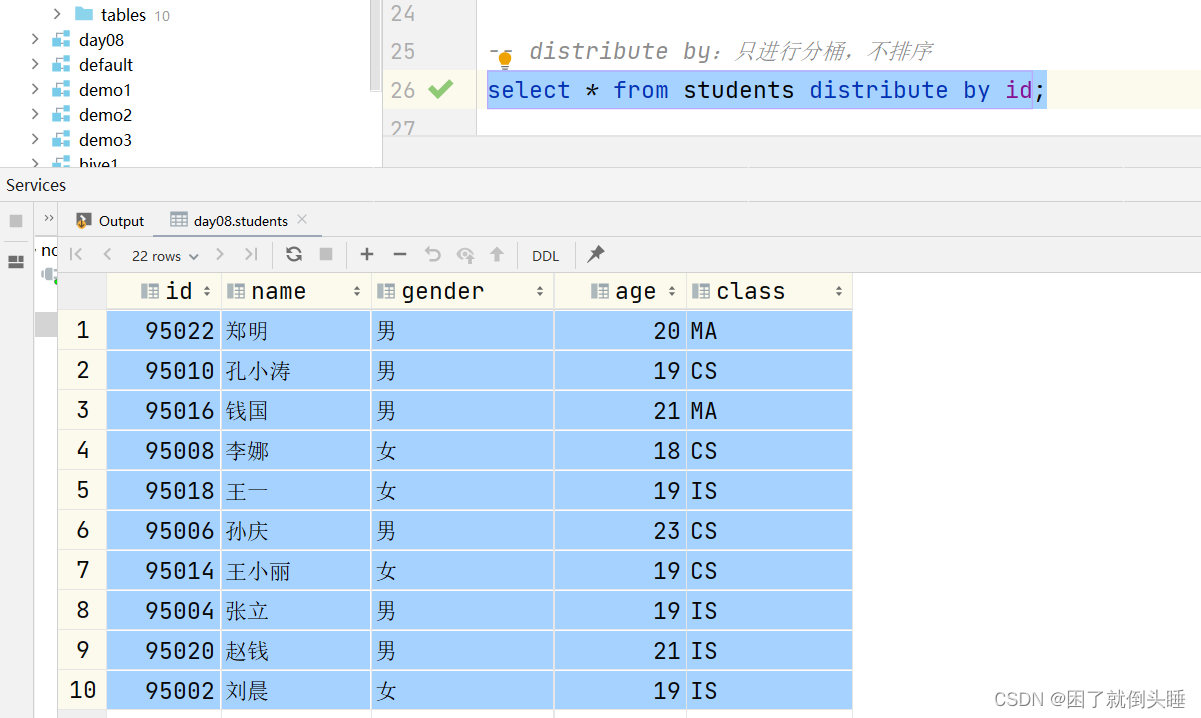
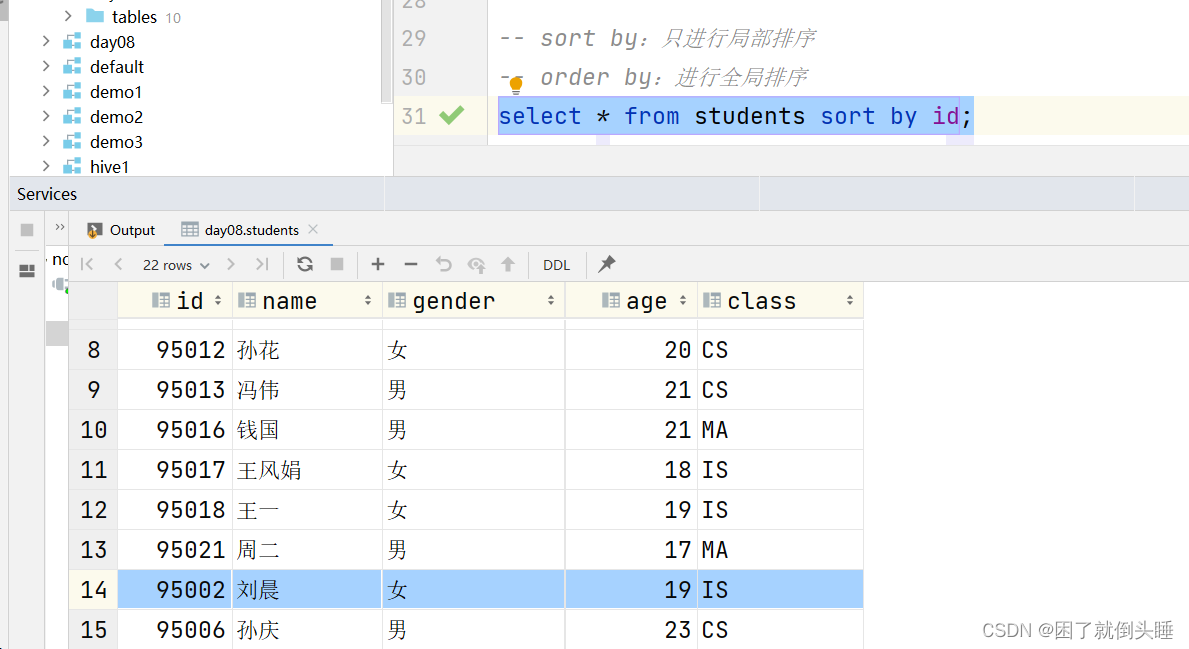
create database day08 comment "第8天的数据库"; use day08; create table students ( id int, name string, gender string, age int, class string ) row format delimited fields terminated by ','; load data inpath '/dir/students.txt' into table students; -- 通过Hive参数设置桶的个数 set mapreduce.job.reduces=2; set mapreduce.job.reduces; -- cluster by:先对数据在内存中(数据处理的时候)进行分桶,再对桶内的数据进行排序 select * from students cluster by id; -- distribute by:只进行分桶,不排序 select * from students distribute by id; -- sort by:只进行局部排序 -- order by:进行全局排序 select * from students sort by id; select * from students order by id; -- distribute by 配合sort by:可以实现先分桶,再对桶内的数据进行排序。 -- 相对cluster by的好处是,可以指定不同的字段。 -- 字符串的排序规则,依据ASCII码表进行排序。https://www.runoob.com/w3cnote/ascii.html select * from students distribute by id sort by gender desc;
6、正则模糊查询
模糊查询:
1- %: 匹配0到多个
2- _: 匹配仅且一个
正则查询:
1- 使用正则的时候,需要将like改成rlike
2- 正则查询中不支持对数值的查询。需要使用cast进行数据类型转换
示例:
use day07;
select * from orders;
select * from orders where useraddress like 's%';
-- .*是正则的写法,匹配任意的内容。如果用的是正则,需要改成rlike,regex
select * from orders where useraddress rlike 's.*';
select * from orders where userid like '_';
-- ..表示匹配2个字符。rlike中只支持字符串类型,不支持数值类型
select * from orders where cast(userid as string) rlike '..';
-- 正则表达式复杂用法
-- ^1\\d{6}$:匹配字符串中以1开头,并且后面跟上6个其他任意的数值。\d表示的是匹配数值。\\d表示转义
-- ^:匹配开头,必须要以1开头
-- $:匹配结尾,必须以数值结尾
select * from orders where orderno rlike '^1\\d{6}$';
使用正则查询遇到的问题:
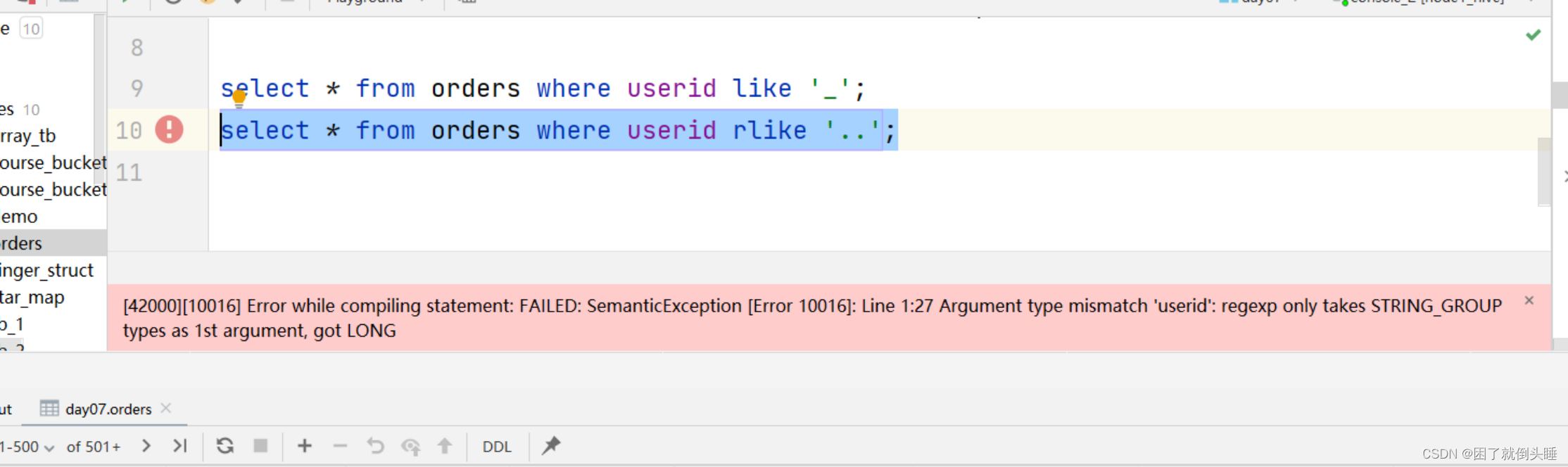
原因: rlike中只支持字符串类型,不支持数值类型
解决办法: 进行类型转换

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











