






16、JVM 重用
此操作, 在hive2.x已经不需要配置了, 默认支持
jvm重用: 默认情况下, container资源容器 只能使用一次,不能重复使用, 开启JVM重用, 运行container容器可以被重复使用,在hive2.x已经默认支持了
17、推测执行
调优举例: 大数据小组,假设张三有离职苗头,大数据主管会将张三负责的项目和功能分配给到其他同事来负责。
Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。 hadoop中默认两个阶段(map和reduce)都开启了推测执行机制。 hive本身也提供了配置项来控制reduce-side的推测执行: set hive.mapred.reduce.tasks.speculative.execution=true; 关于调优推测执行机制,还很难给一个具体的建议。如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大。 什么时候需要开启? 如果提交的SQL语句,运行的耗时的远超你的预期。你就可以开启推测执行 什么时候不需要开启? 如果对SQL的运行耗时没有特别严格的要求,那么可以不开启。不开启同时能够节约Yarn集群资源。
18、执行计划explain
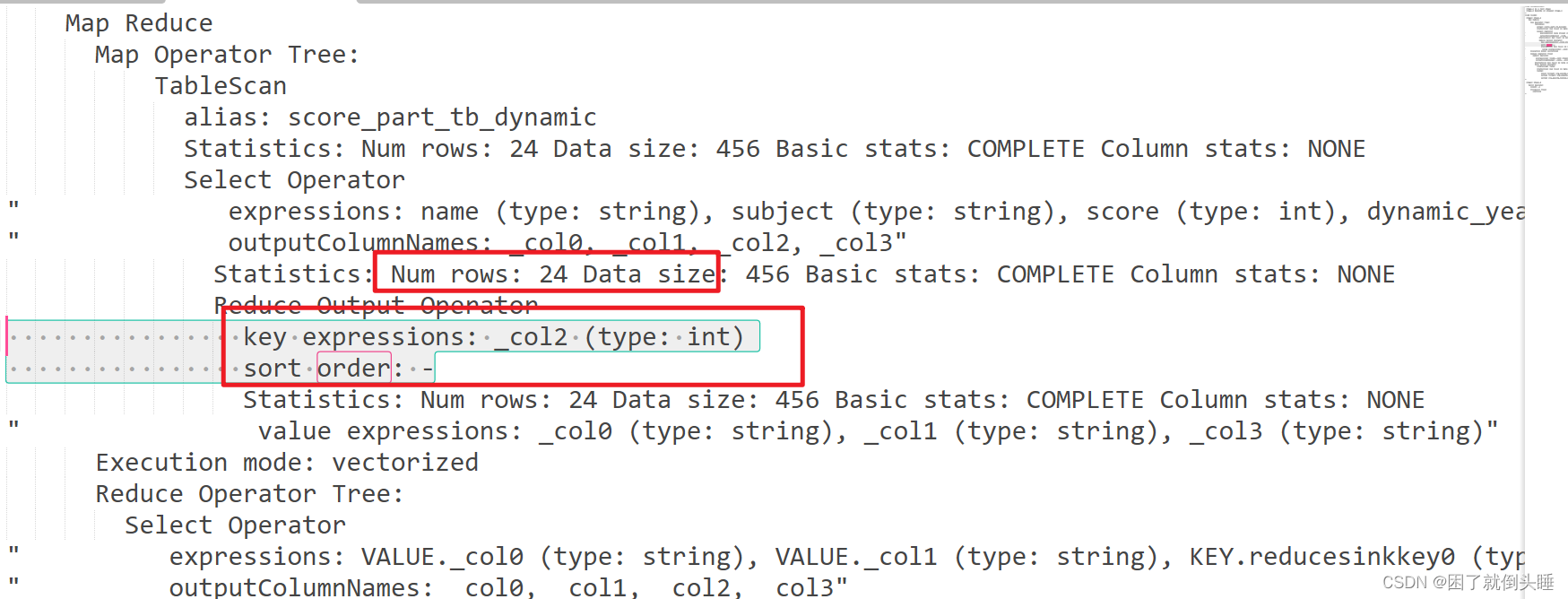
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道Hive是如何处理你的SQL语句的。帮助我们了解底层原理,hive调优,排查数据倾斜等有很有帮助 使用示例:explain [...] sql查询语句; explain sql语句: 查看执行计划的基本信息

(1)stage dependencies:各个stage之间的依赖性
包含多个stage阶段,例如 Stage-1和Stage-0,Stage-1 是根stage,Stage-0 依赖 Stage-1,
(2)stage plan:各个stage的执行计划
包含两部分: map端执行计划树和reduce端执行计划树

explain select * from score_part_tb_dynamic order by score desc;
19 、Hive调优总结
1- 在实际工作中一般不需要针对所有参数去做调整。因为Hive官方已经是提供性能很好的参数配置 2- 理解这些调优手段带来的好处。 3- 参数调优也不是说一下子就能调的很好,需要反复多次的进行参数调整测试
















 1965
1965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











