






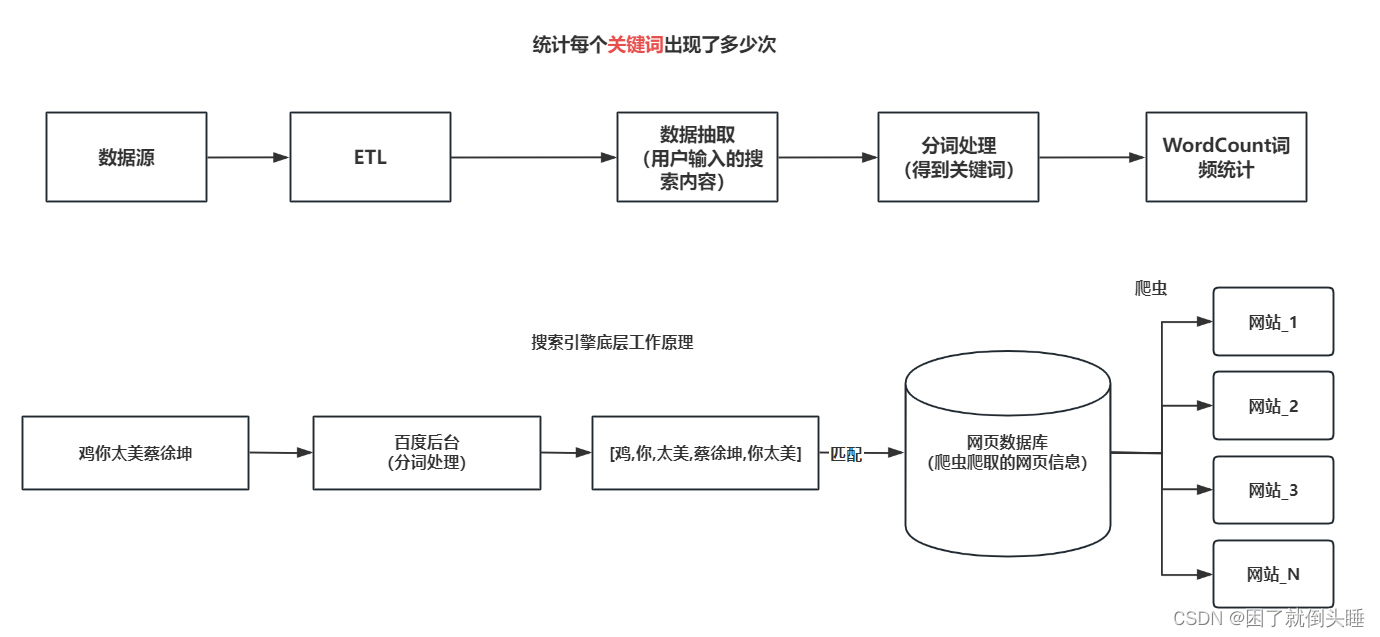
2.1 数据源介绍
访问时间 用户id []里面是用户输入搜索内容 url结果排名 用户点击页面排序 用户点击URL

字段与字段之间的分隔符号为 \t和空格 (制表符号)
2.2 需求分析
需求一: 统计每个 关键词 出现了多少次,最终展示top10数据
关键词示例: ['.','+','的',360', '安全卫士', '哄抢', '救灾物资', '75810', '部队' ...]
注意:'.','+','的'都需要过滤
需求二: 统计每个用户每个 搜索内容 点击的次数,最终展示top5数据
需求三: 统计每个分钟页面点击次数,最终展示top5数据(课后作业)
2.3jieba分词器
说明:
发现在数据中,并没有直接的关键词,关键词数据是包含在搜索词中,而且一个搜索词中包含了多个关键词,所有如何想基于关键词进行统计, 首先需求先拆分搜索词,获取关键词,思考:如何做呢?
借助第三方的分词工具实现中文分词
Java语言:IK分词器
Python语言:jieba(结巴)分词器
如何使用jieba分词器呢?
1- 需要在系统中安装jieba分词库: local模式只需要安装在node1即可 如果集群模式运行 需要各个节点都要安装
安装命令: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
安装成功的截图:
测试
# 导包
import jieba
# main程序的入口
if __name__ == '__main__':
# 精确模式
r1 = list(jieba.cut('我要去黑马找斌哥学习大数据技术'))
print(r1)
# 全模式
r2 = list(jieba.cut('我要去黑马找斌哥学习大数据技术',cut_all=True))
print(r2)
# 搜索引擎模式
r3 = list(jieba.cut_for_search('我要去黑马找斌哥学习大数据技术'))
print(r3)
2.4 代码实现
2.3.1 数据准备
-
1- 将数据文件拷贝到data目录下:
-
2- 数据清洗_分析
# 导包
import os
import jieba
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
def get_topN_keyword(etlRDD, n):
r1 = etlRDD.flatMap(lambda line_list: list(jieba.cut(line_list[2]))) \
.filter(lambda word: word not in ('.', '+', '的')) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda agg, curr: agg + curr) \
.top(n, lambda t: t[1])
print(r1)
def get_topN_search(etlRDD,n):
r2 = etlRDD.map(lambda line_list: ((line_list[1], line_list[2]),1) ) \
.reduceByKey(lambda agg, curr: agg + curr) \
.top(n, lambda t: t[1])
print(r2)
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
conf = SparkConf().setAppName('pyspark_demo').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2.数据输入
textRDD = sc.textFile('file:///export/data/spark_project/spark_core/data/SogouQ.sample')
print(textRDD.count()) # 测试原始数据量10000
# 3.数据处理(切分,转换,分组聚合)
etlRDD = textRDD.filter(lambda line: line.strip() != '').map(lambda line: line.split()).filter(
lambda line_list: len(line_list) >= 6)
# 去除搜索内容两端的 [ ]
etlRDD = etlRDD.map(lambda line_list:
[
line_list[0],
line_list[1],
line_list[2][1:-1],
line_list[3],
line_list[4],
line_list[5]
])
# 4.数据输出
# 需求一: 统计每个 关键词 出现了多少次, 最终展示top10数据 注意:'.', '+', '的' 都需要过滤
# 伪SQL:select 关键词 ,count(*) from 搜狗表 group by 关键词
get_topN_keyword(etlRDD, 10)
# 需求二: 统计每个用户 每个 搜索内容 点击的次数, 最终展示top5数据
# 伪SQL:select 用户,搜索内容,count(*) from 搜狗表 group by 用户,搜索内容
get_topN_search(etlRDD,5)
# 5.关闭资源
sc.stop()
可能遇到的错误:
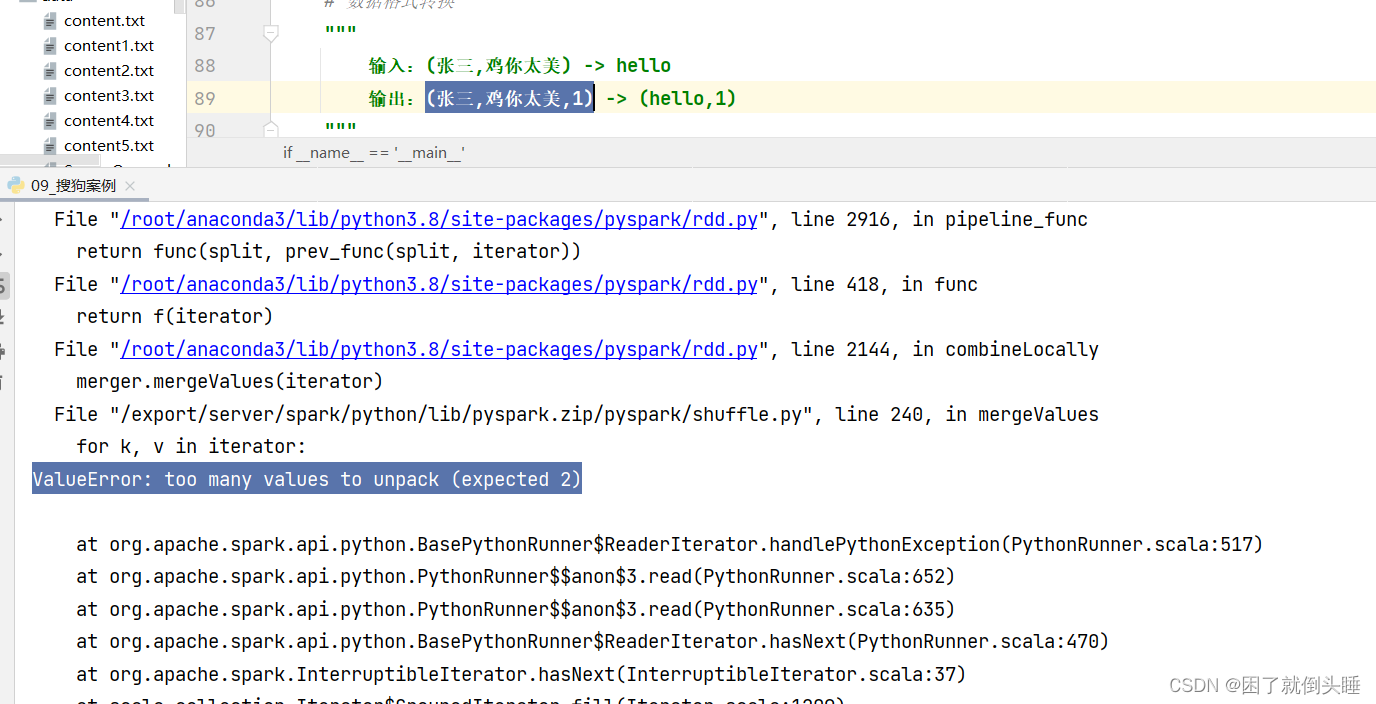
原因: reduceByKey只能接收元组中有2个元素的情况
3、数据核对
大数据开发人员/数据分析人员,必须要对自己统计的指标结果负责!!!
结果数据的核对方式:
1- (不常用)在离线文件中直接ctrl+F搜索关键内容核对
2- (常用)一般原始数据会存放在MySQL/Hive中一份,可以编写和代码逻辑完全一样的SQL来进行核对。可以通过如下方式来提高核对效率:
2.1- 如果是分区表,挑选几个分区进行核对即可
2.2- 如果是分桶表, 可以抽样查询几个桶核对
2.3- 也可以使用tablesample函数对抽样查询
2.4- 可以在SQL的where语句中,添加数据过滤条件,例如:时间范围过滤条件、用户编号过滤条件等,将核对的数据量缩小,提高核对效率
3- (不常用,难度比较大)可以对重点指标的同比、环比进行监控。还可以结合算法的方式对指标统计结果进行检测。
4- 个人经验或者同事互相帮忙查看测试
















 1010
1010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











