






4.1 深层神经网络
表示神经网络的层数;
表示第
层上的单元数量,
,
;
表示第
层中的激活函数值,也是第
层输出的函数值,
,而第
层输入的函数值是
,神经网络最后的输出
;
是计算
值的权重;
有些函数只有用非常深层的神经网络才能学习,实际中难以判断,一般最开始可以试试logistic回归,再试试单隐层、双隐层,再将隐层数当作超参数,然后再开发集上评估;
4.2 深层网络中的前向传播
单样本中,普遍规则是:
而对于m个样本的向量化,普遍规则也长得很像:
这种情况下,必须用for loop去将神经网络的每一层进行计算,无法省略:
4.3 校对矩阵的维数

一些普适性的维度检查标准:
的维度必须是
;
的维度必须是
,即使是多样本下对
之类也一样;
的维度必须是
,且
的维度就是
;
与
维度保持一致,
与
维度保持一致,其他都类似;
与
维度保持一致,
与
维度保持一致,其他都类似;
凡是向量化中横向堆排m个样本的那些矩阵,比如等,列数一定等于样本数m;
做矩阵乘法必须满足左矩阵列数等于右矩阵行数;
4.4 为什么使用深层显示?
不一定要很大的神经网络,但往往要有足够深的神经网络,即隐藏层得足够多;
例子1:人脸识别
输入一张人脸照片,深度神经网络第一层是一个边缘探测器,也叫特征探测器,值得注意的是,由于要使用卷积神经网络,隐藏单元将不再像之前那样排列,而是像像素一样堆叠成一个矩形:

每一个小方块就是一个隐藏单元,有些试图找水平方向的边缘,有些试图找垂直方向的边缘……第二层将边缘拼在一起,就可以开始检测一些部位,比如眼睛、鼻子、嘴巴……第三层再组合起来就可以开始检测人脸;
边缘检测器针对的都是照片中很小快的面积,面部探测器就要大一些,所以一般会从比较小的细节入手,再一步步扩大到更大更复杂的区域;可以把这种方法称为从简单到复杂的金字塔状表示方法或组成方法;
其他例子:如语音识别中,先从低层次的音调、波形特征入手,再到音位(如cat的发音“CA-”就是一个音位),再到单词,再到词组,再到完整句子;
例子2:电路理论
一些较复杂的函数可以用较小的隐藏单元数但较深的神经网络计算,但如果用较浅的神经网络计算它们,需要成指数级别增长的单元数量才能达到相同的效果;
例如:要计算
如果采用深层神经网络:

这种树图对应的神经网络深度为,因此节点数量或门数量并不会太大;
但如果只能采用单隐层神经网络:

那么这一层的隐藏单元数量也要指数级上升到,这是难以承受的;
4.5 搭建深层神经网络块
对第层的前向传播而言,参数是
,输入
,经过
以及
的计算后输出
;一个细节是,会将计算好的
缓存起来,后面在反向传播时直接拿来用;
对第层的反向传播而言,则是输入
,输出
;
然后对每一层都更新,比如,对第
层:
至此就完成了一个梯度下降循环。

4.6 前向和反向传播
第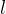 层的前向传播:输入
层的前向传播:输入![a^{[l-1]}](https://latex.csdn.net/eq?a%5E%7B%5Bl-1%5D%7D) ,输出
,输出![a^{[l]}](https://latex.csdn.net/eq?a%5E%7B%5Bl%5D%7D) ,缓存
,缓存![z^{[l]},w^{[l]},b^{[l]}](https://latex.csdn.net/eq?z%5E%7B%5Bl%5D%7D%2Cw%5E%7B%5Bl%5D%7D%2Cb%5E%7B%5Bl%5D%7D)
单样本公式:
m个样本公式:
第层的反向传播:输入![da^{[l]}](https://latex.csdn.net/eq?da%5E%7B%5Bl%5D%7D) ,输出
,输出![da^{[l-1]},dw^{[l]},db^{[l]}](https://latex.csdn.net/eq?da%5E%7B%5Bl-1%5D%7D%2Cdw%5E%7B%5Bl%5D%7D%2Cdb%5E%7B%5Bl%5D%7D)
单样本公式:
第二个式子老吴在课里甚至写错了,漏了个转置,后面讲维度也有出错过……
m个样本公式:

值得注意的是每一层的权重参数都要更新;
反向传播中最开始的输入是,并且如果在做二元分类,那么输出层只有一个单元并采用
函数激活,有:
4.7 参数VS超参数
超参数有:学习率,梯度下降法的循环次数
,隐层数
,隐藏单元数
,激活函数的选择;超参数最终控制了参数
,
还有一些超参数后面会学到:momentum,mini batch size,正则化参数……
超参数调优仍然是经验为主,比如调整、尝试不同的学习率看看损失函数有没有下降、发散、收敛,开发新应用必须要有耐心地试、试、试!知道找到最优的超参数,培养自己的直觉。

4.8 这和大脑有什么关系?
过时的类比而已,现在生物学上对神经元依然在进行研究,但目前仍是一个谜,世上没人能说清楚神经元的原理,而神经网络则是学习函数的映射,学从到
的映射;感兴趣可以听老吴采访其他大神的视频,有一个人在做这方面的研究。















 1127
1127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









