









首先要准备一些东西
1.虚拟机

2.Xshell

3.Xftp

4.Ubuntu的镜像文件
![]()
5.jdk的包(Linux版)
![]()
6.Hadoop的镜像文件(Hadoop的包)
![]()
7.eclipse(linux版)
![]()
首先下载虚拟机
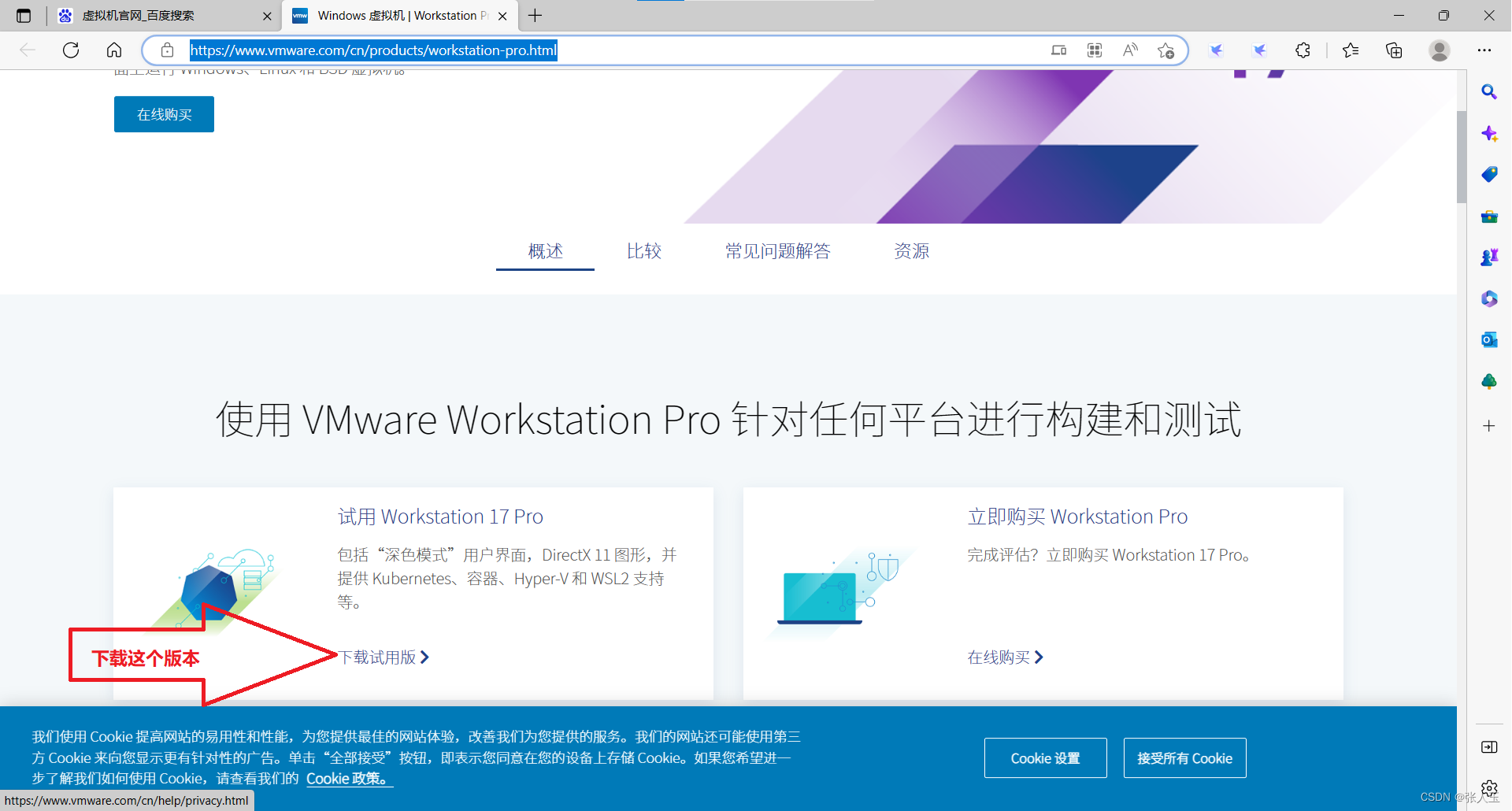
进入虚拟机官网下载:
https://www.vmware.com/cn/products/workstation-pro.html
Xshell
进入官网下载
Xftp
进入官网下载
XFTP - NetSarang Website (xshell.com)
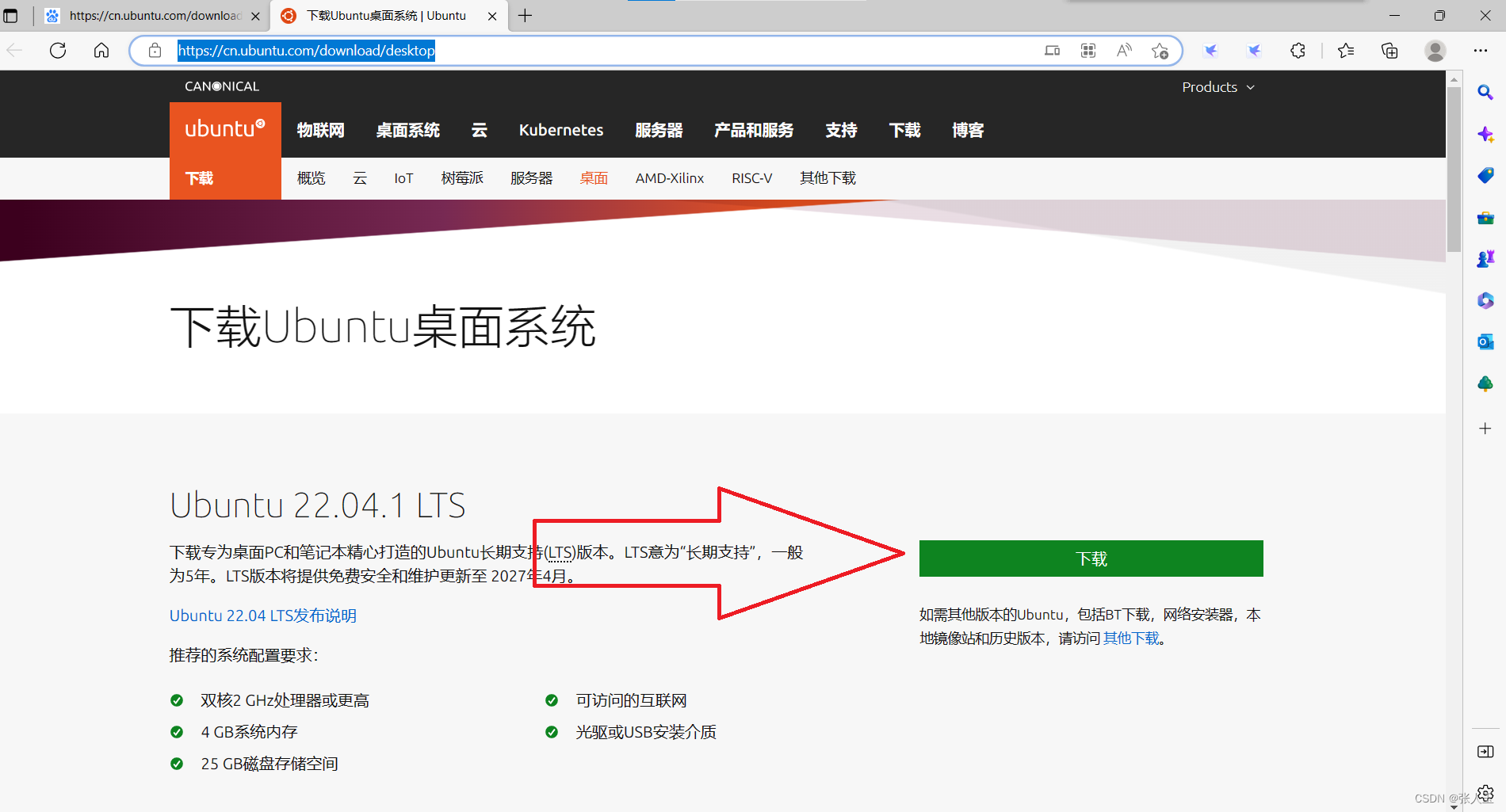
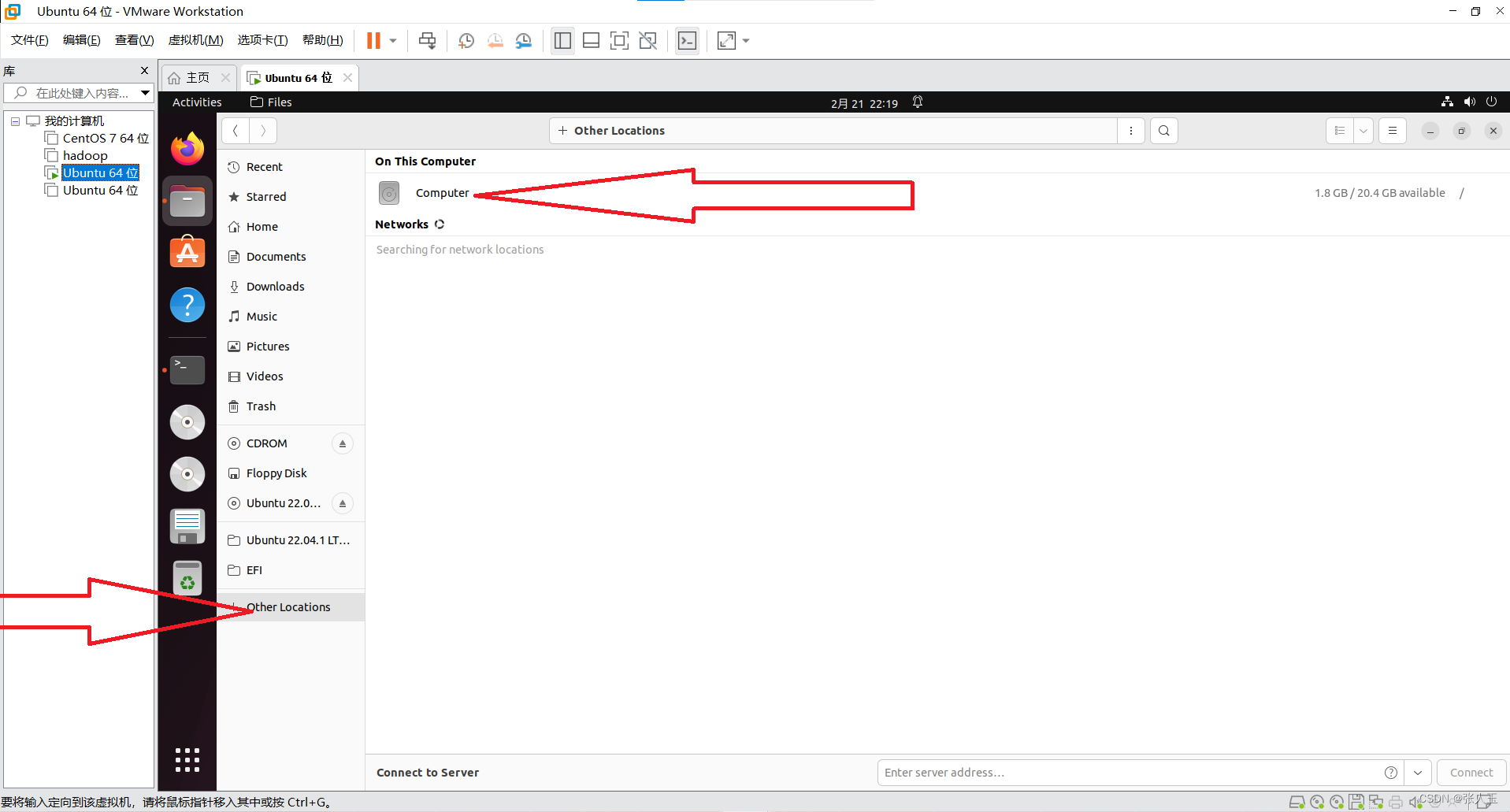
Ubuntu
进入官网下载
https://cn.ubuntu.com/download/desktop
jdk的包
进入官网
https://www.oracle.com/java/technologies/downloads/#java8-linux
Hadoop镜像文件
清华大学管网:
https://mirrors.tuna.tsinghua.edu.cn/apac he/hadoop/common/
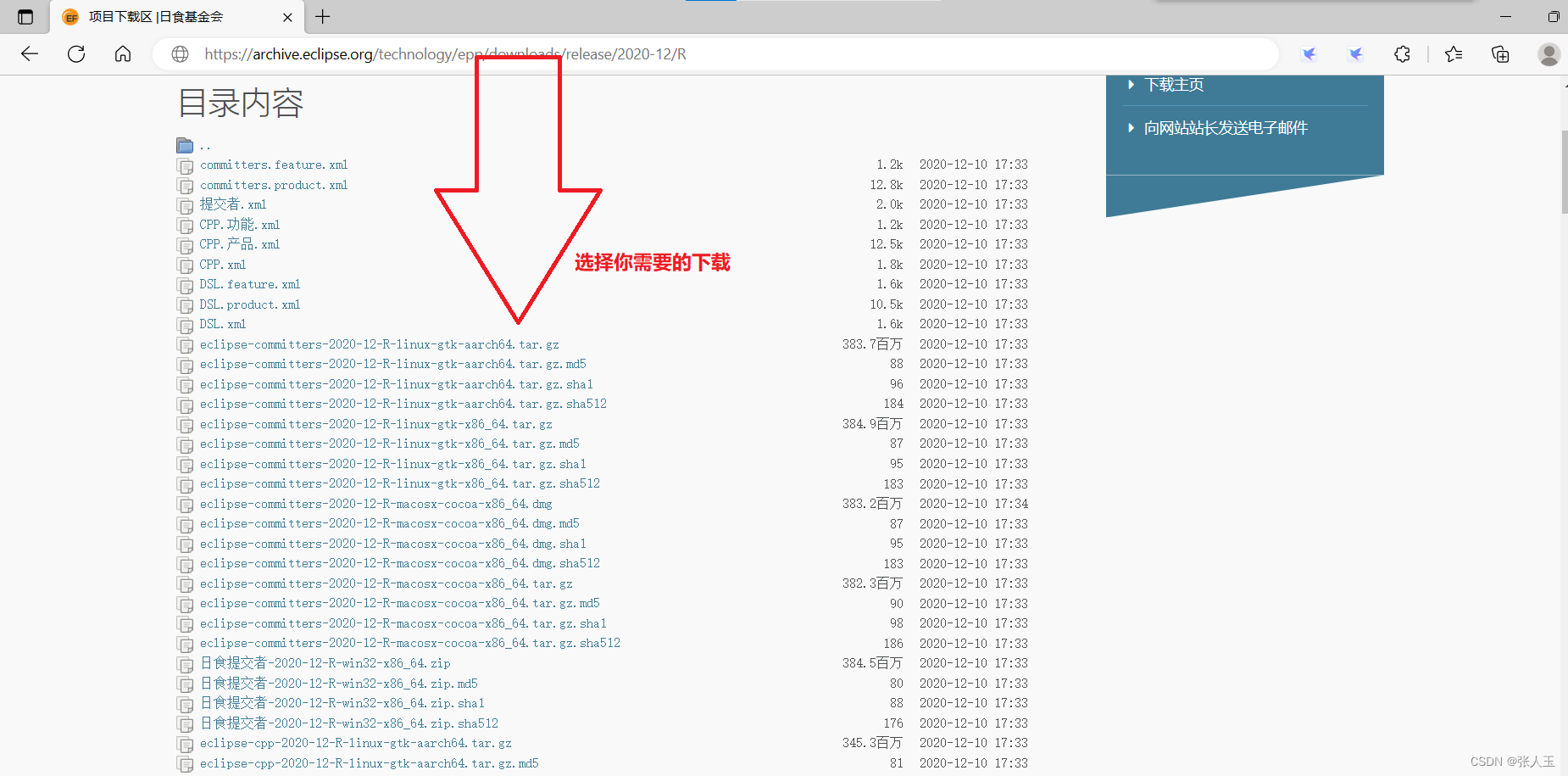
eclipse(linux)
https://archive.eclipse.org/technology/epp/downloads/release/2020-12/R
以上网站大部分都需要花钱,也可以选择我的资源包
关注我的博客号
搜索:在Ubuntu上安装hadoop
下载资源包(ubuntu镜像文件需要自己下载其它的都有)
准备工作已经做好了
我们现在可以开始安装了
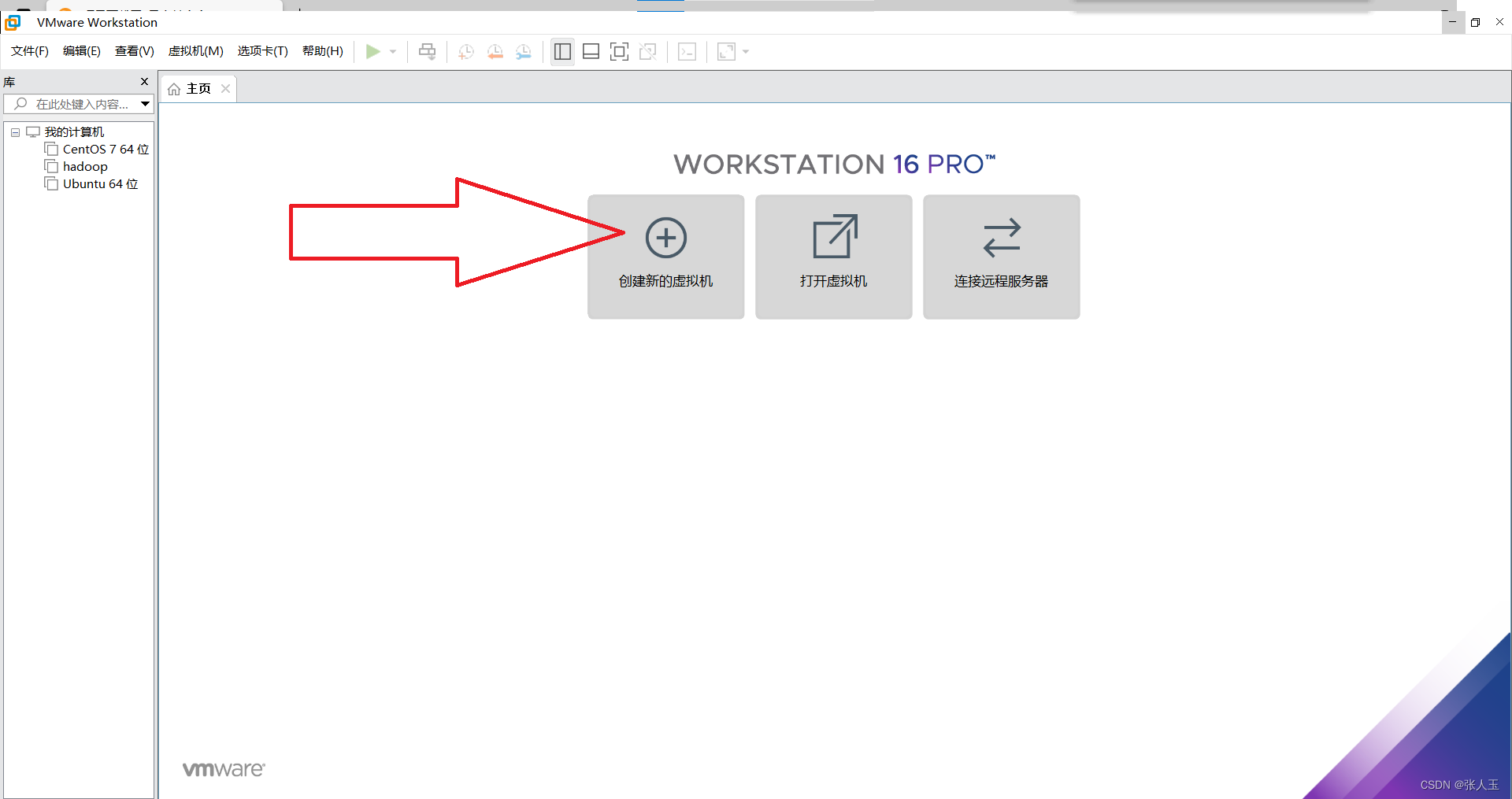
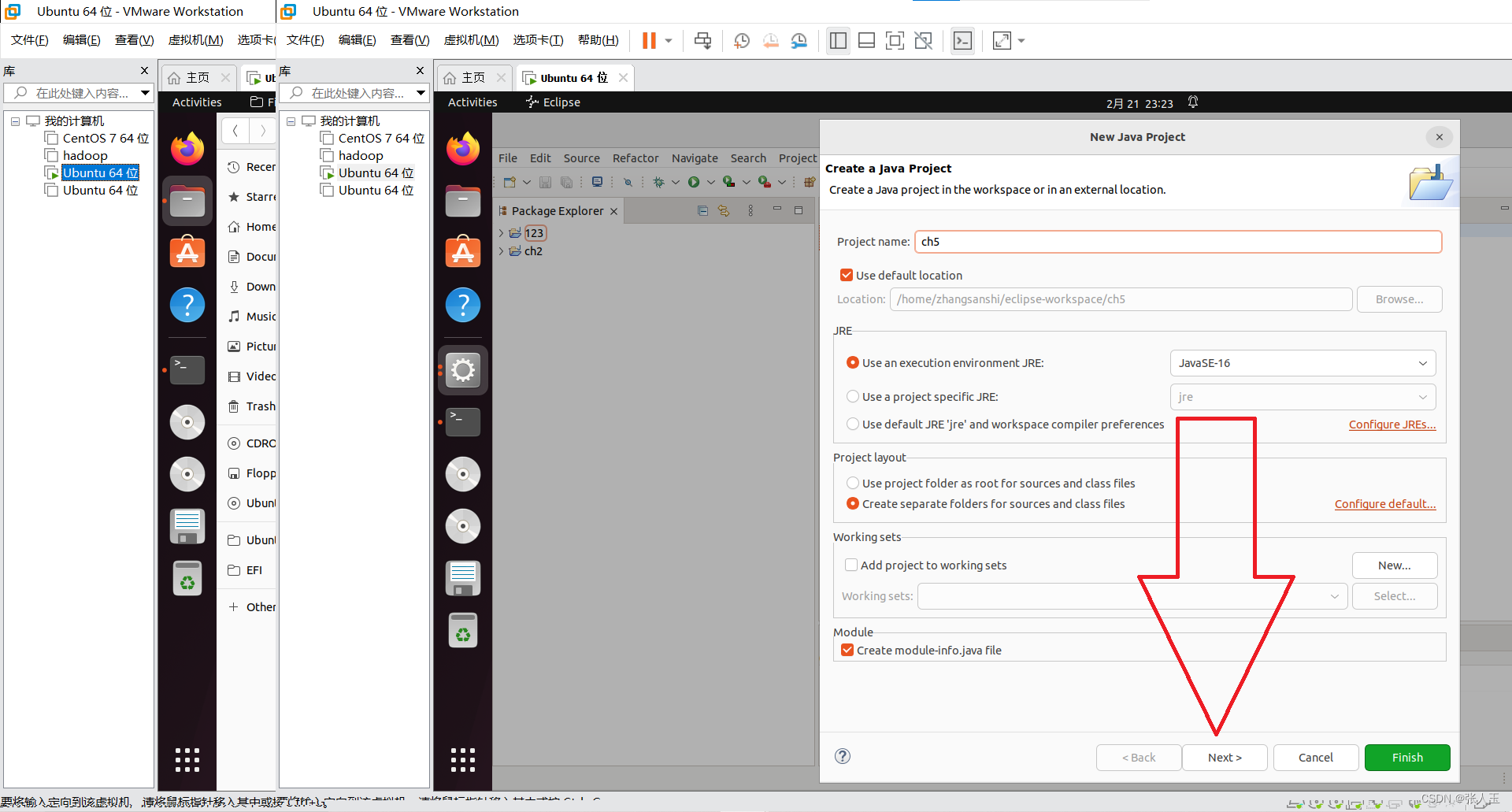
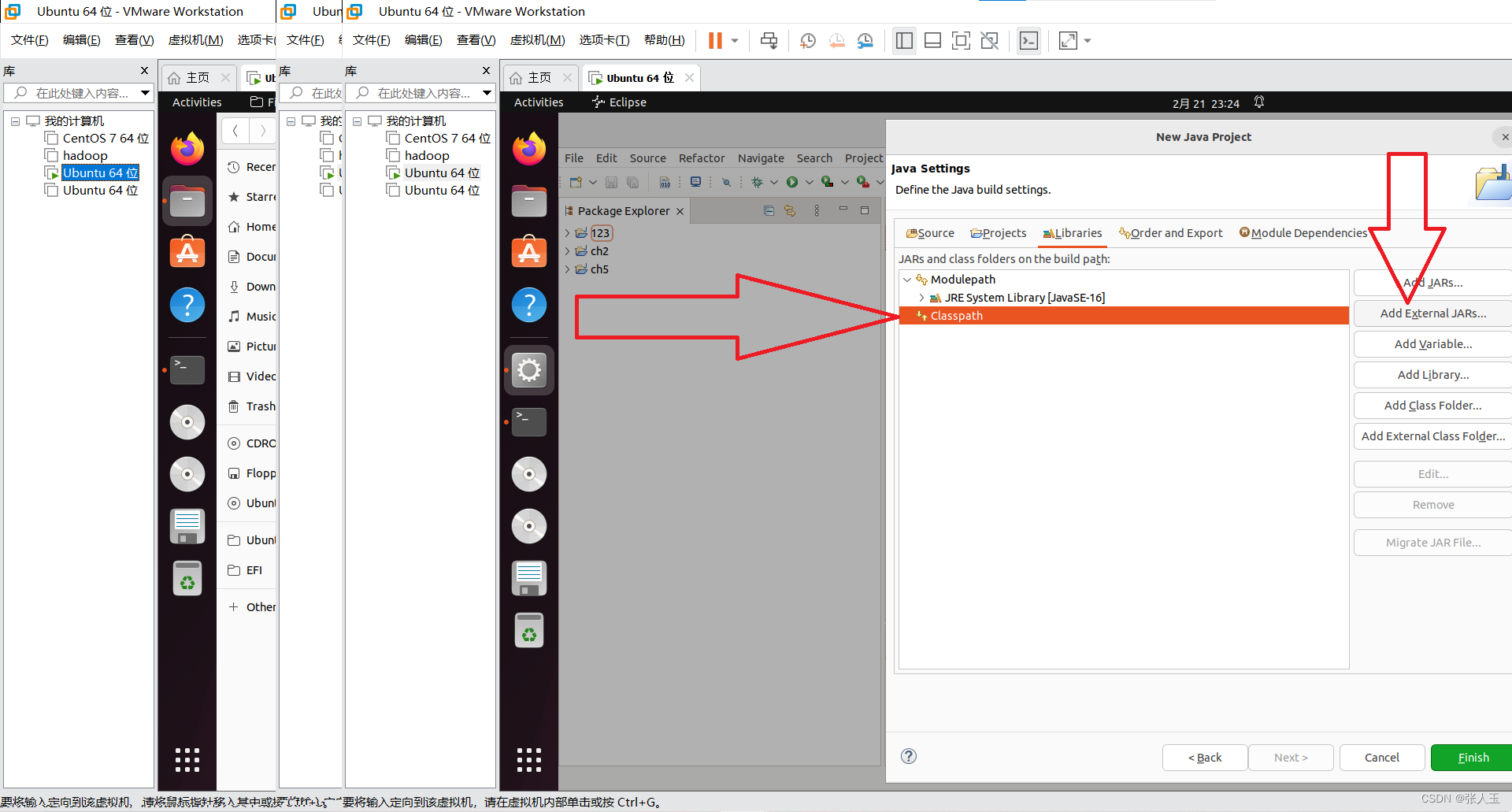
1.创建一个虚拟机
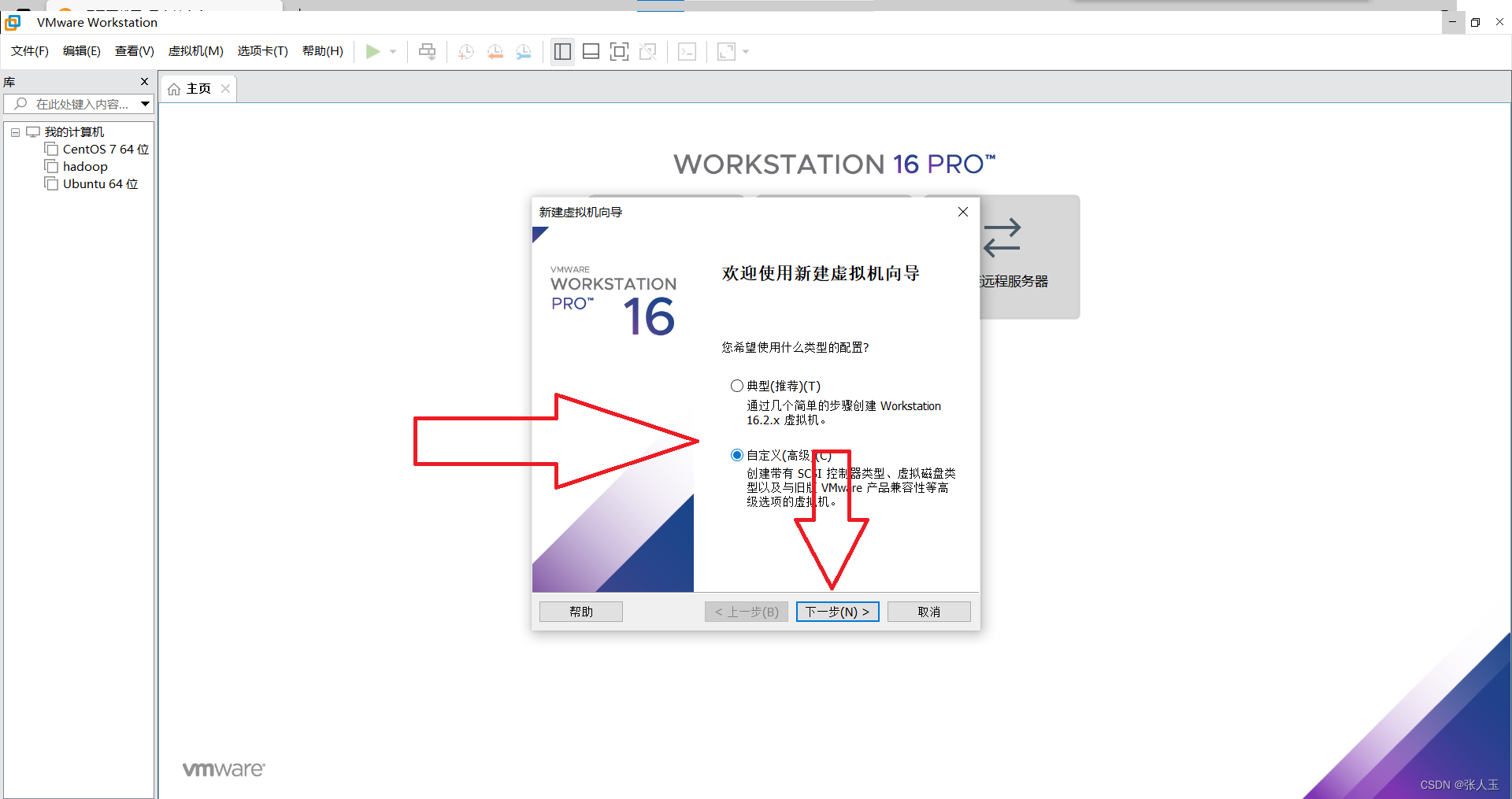
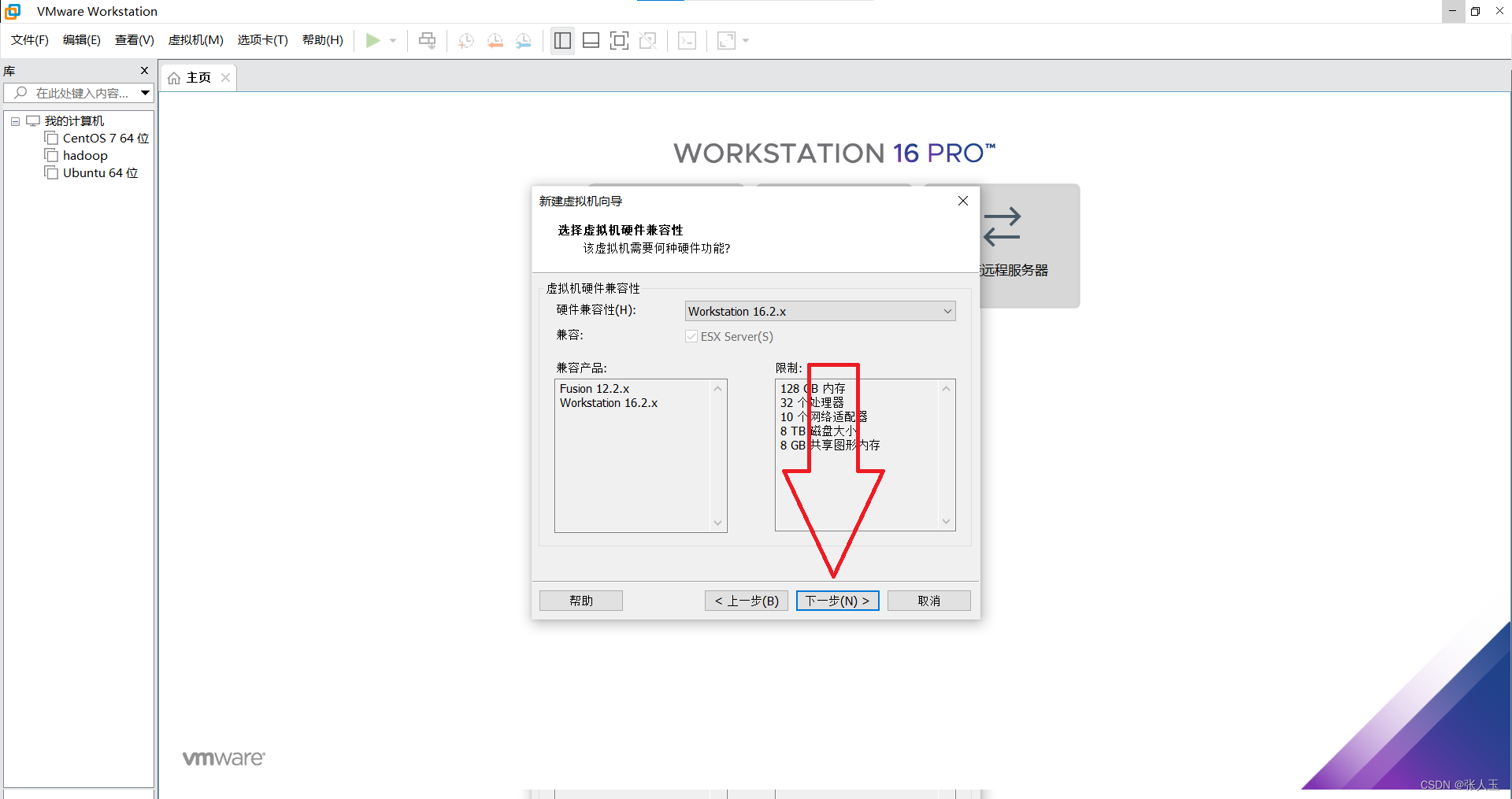
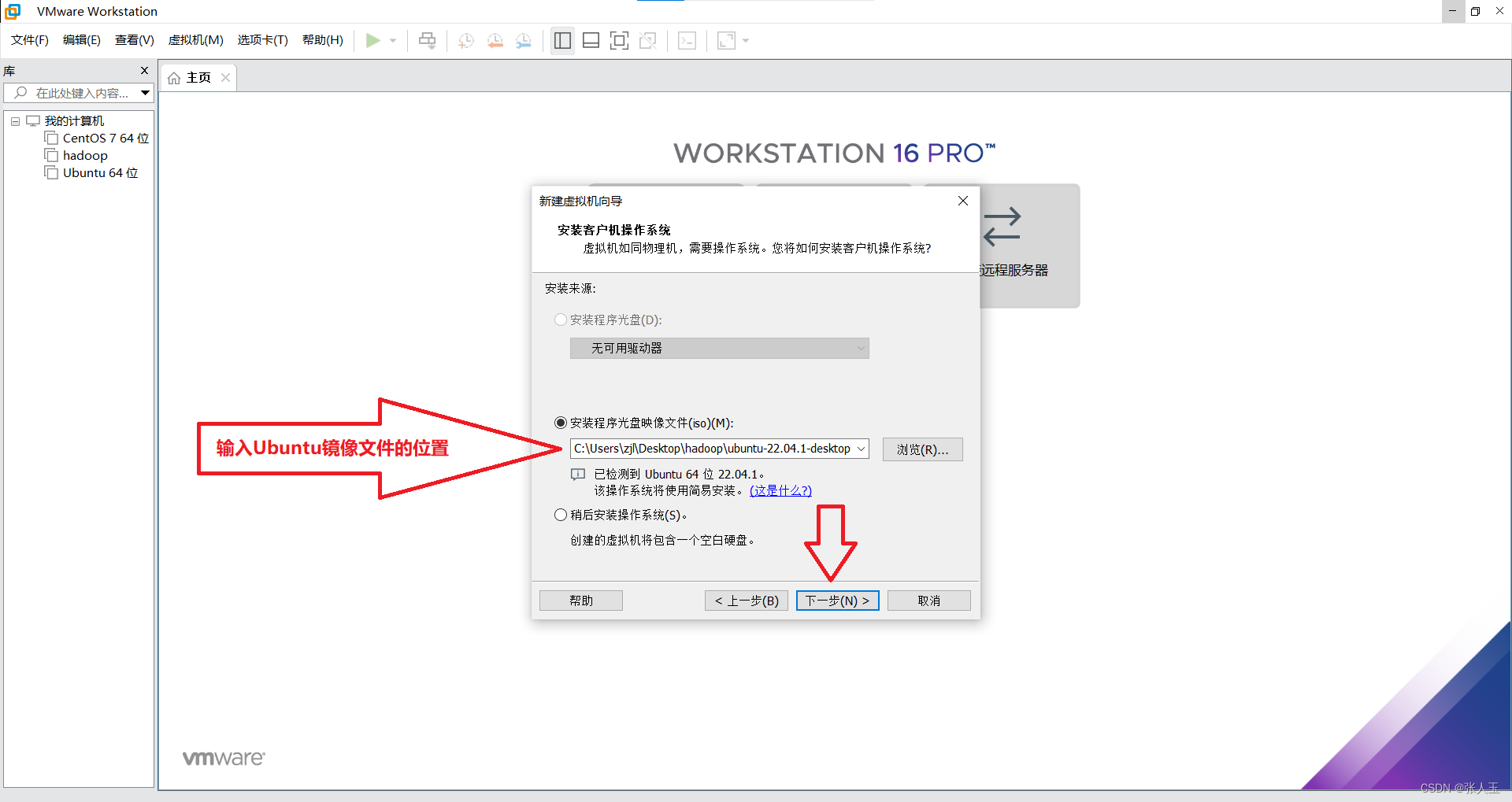
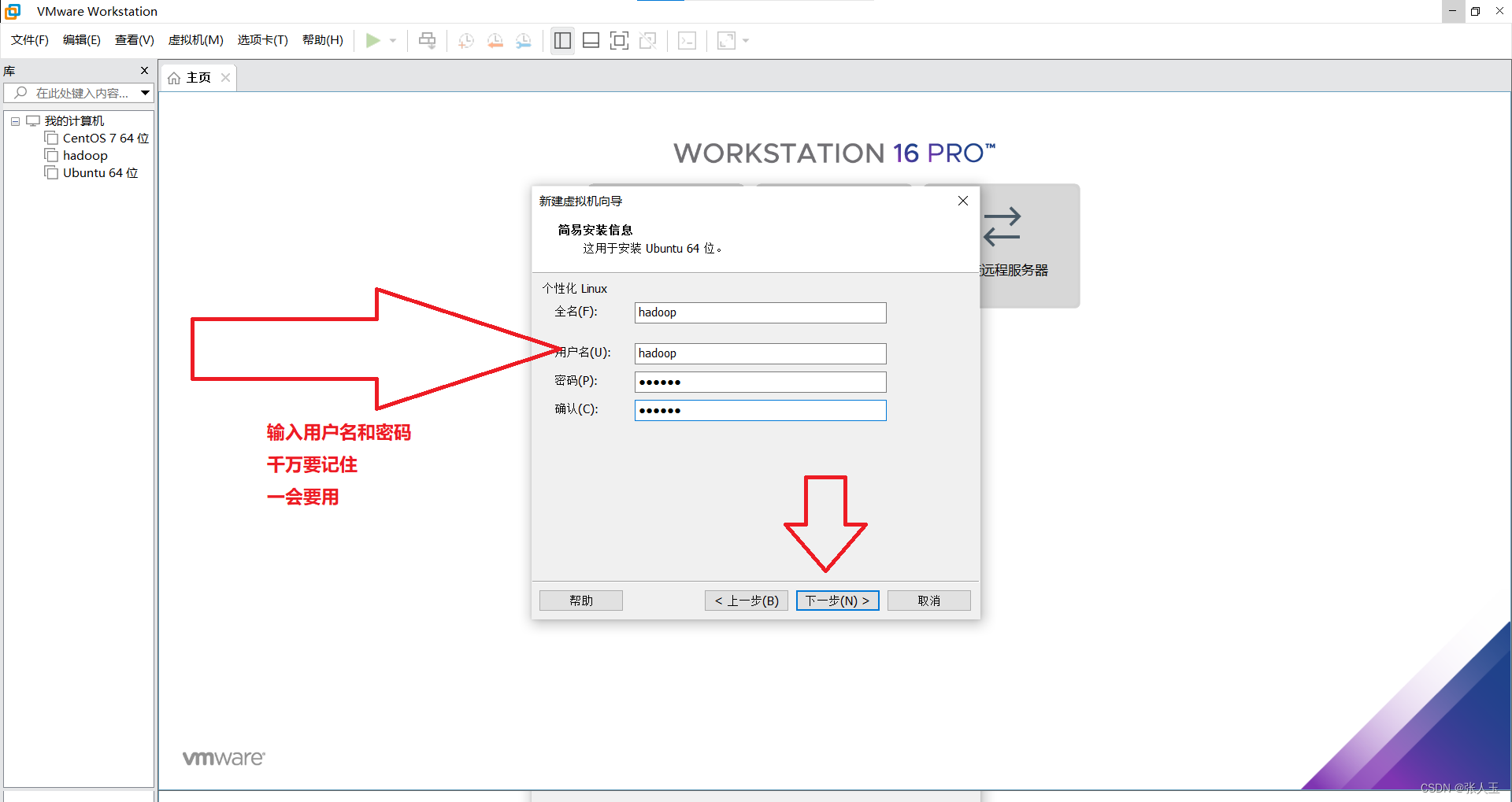
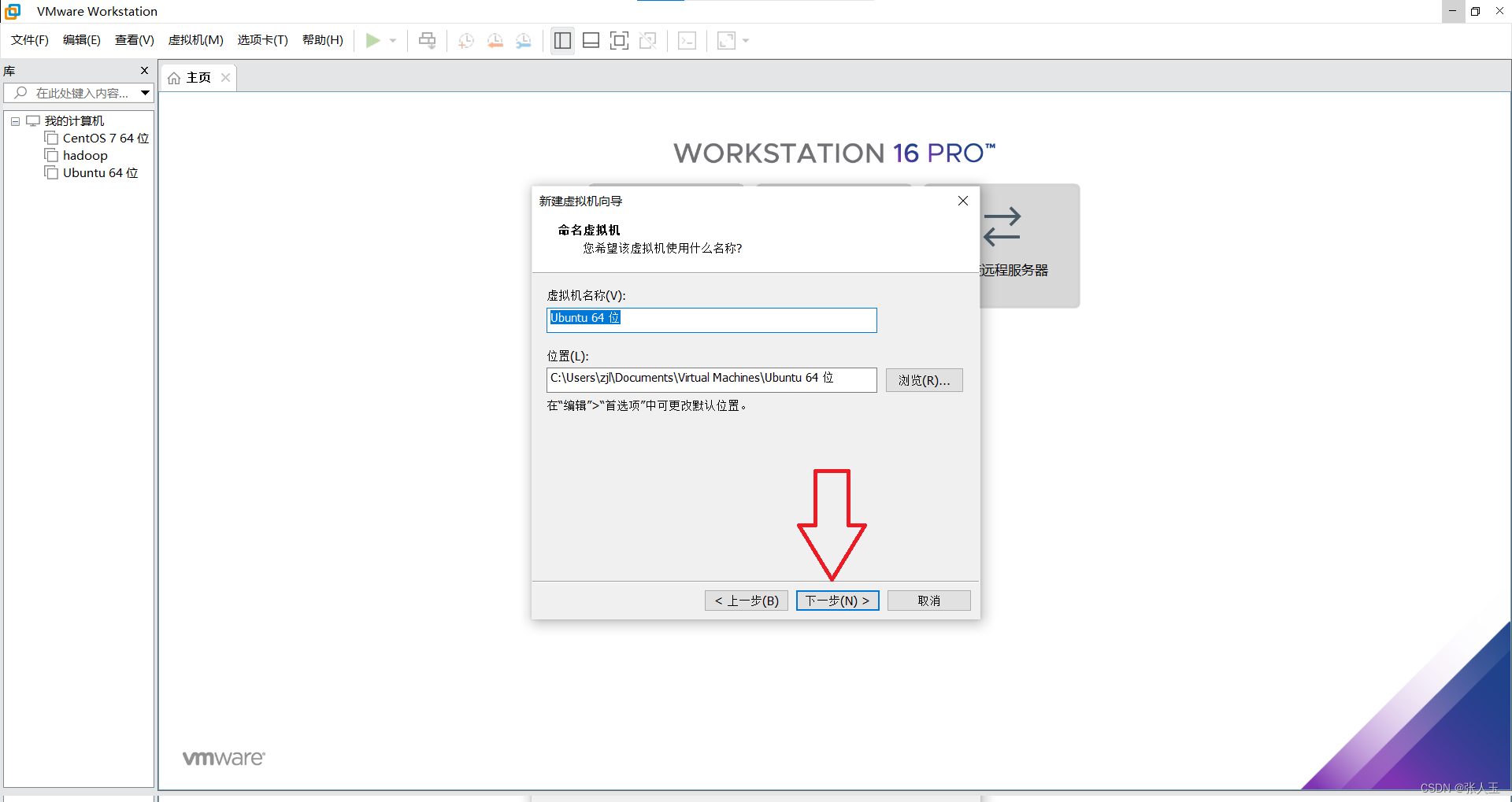
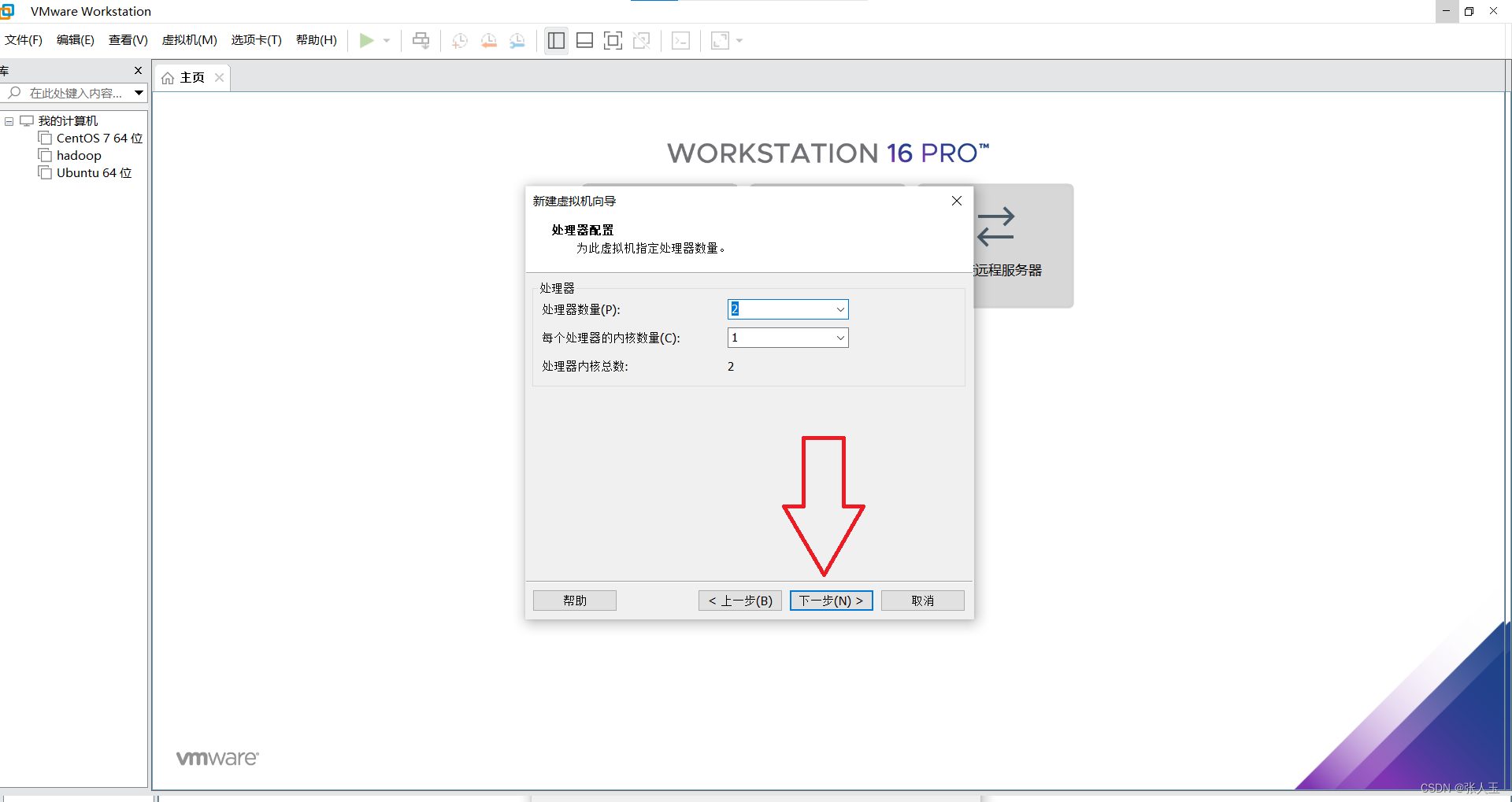
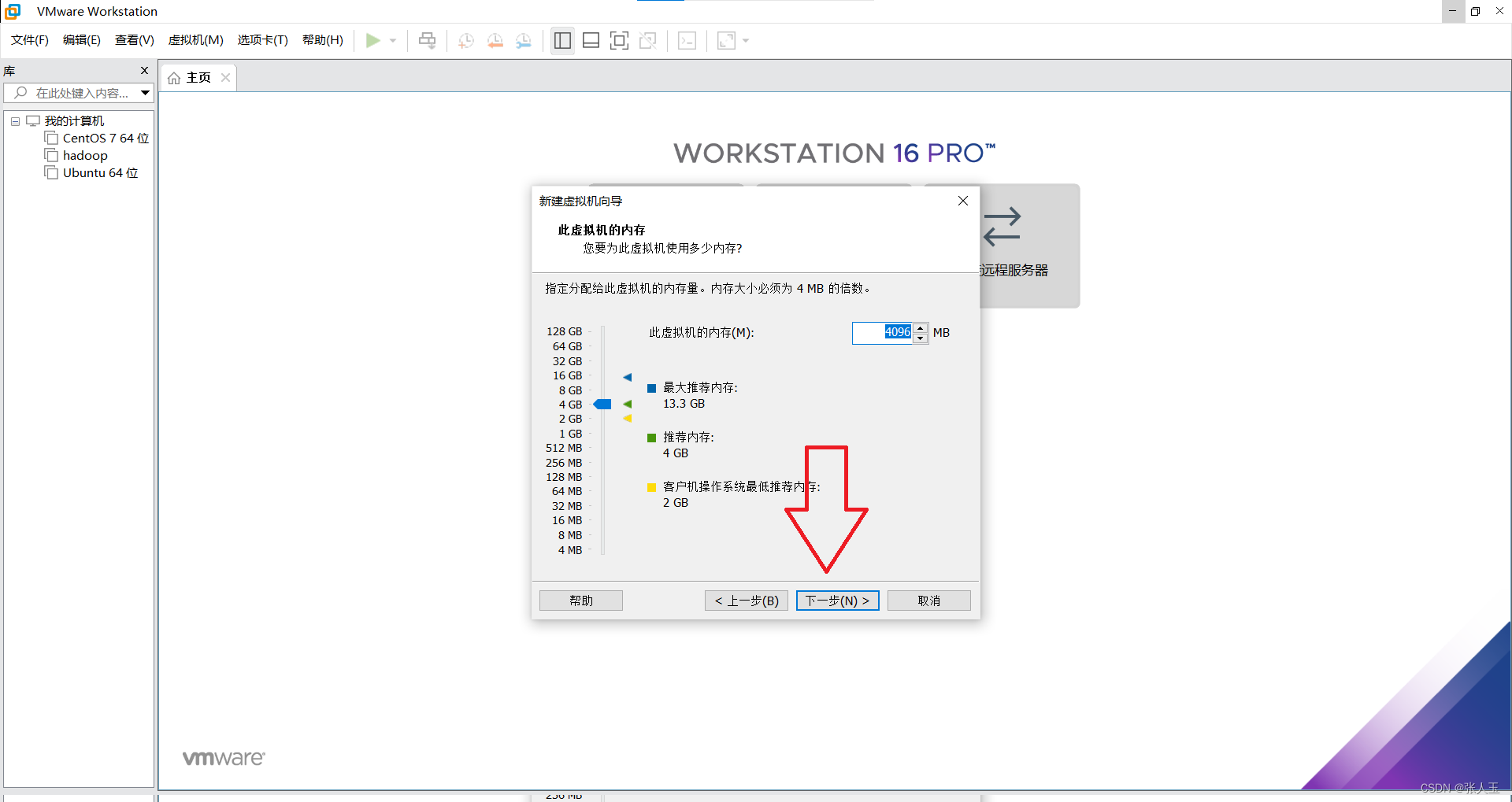
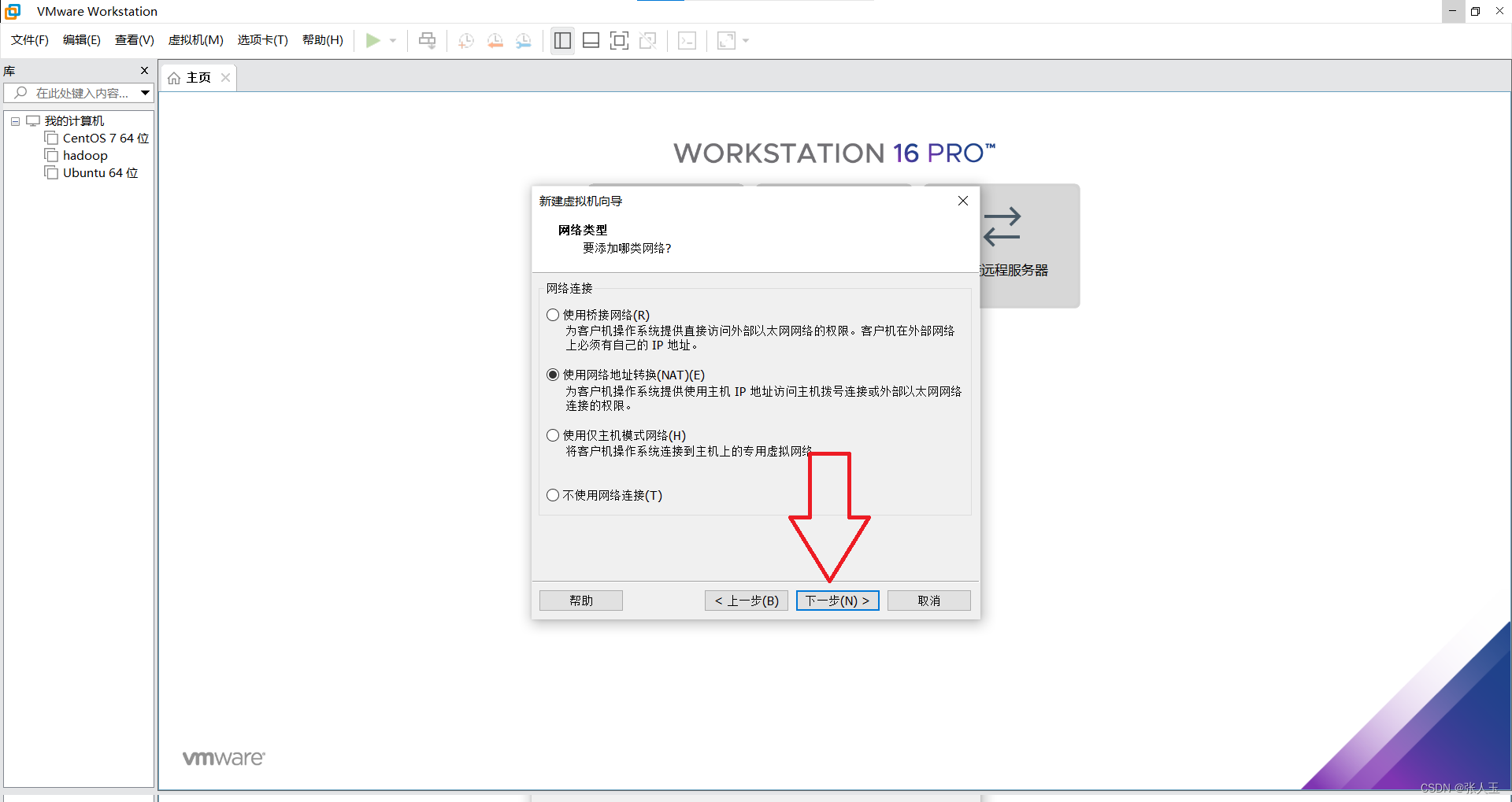
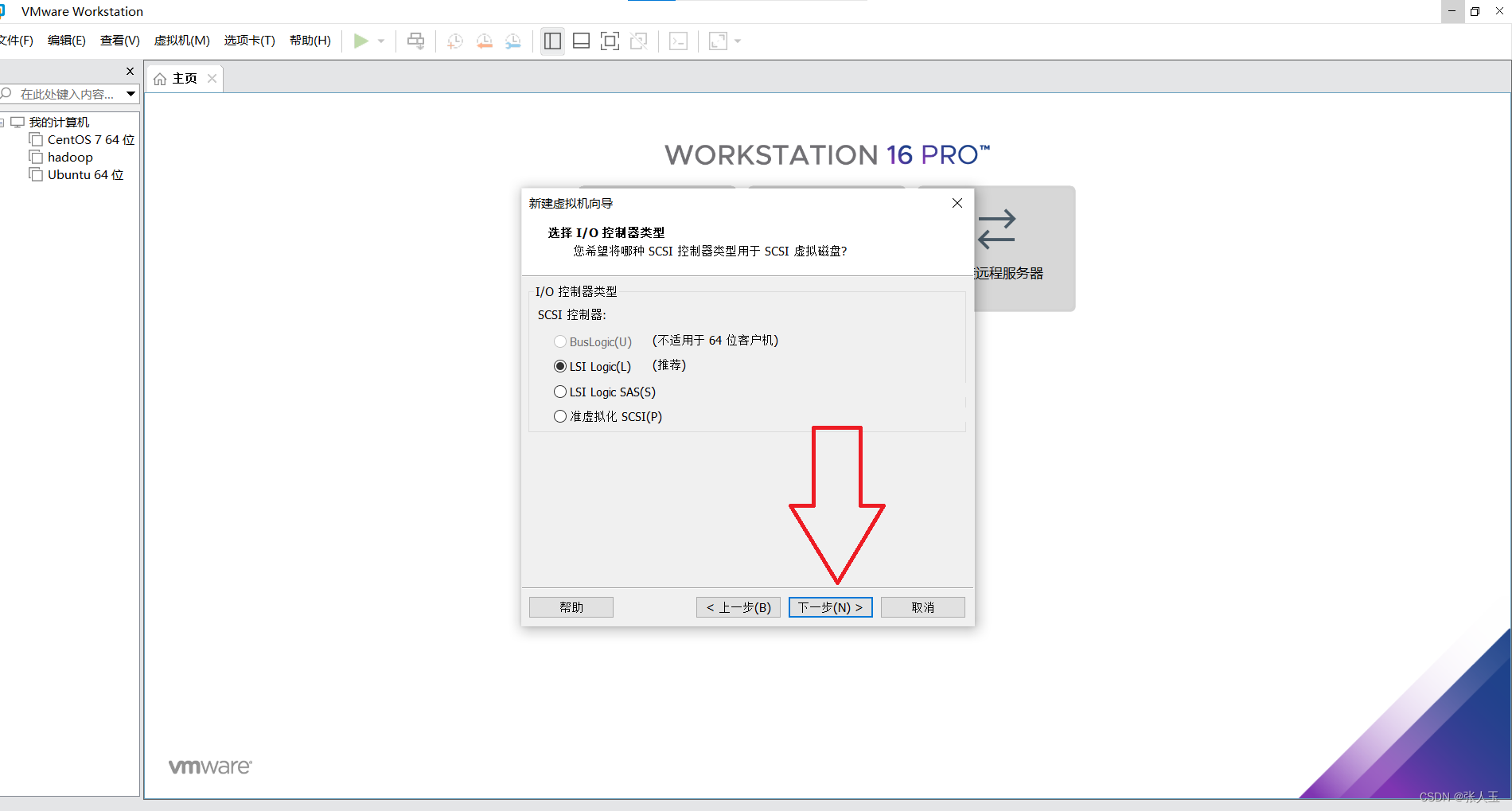
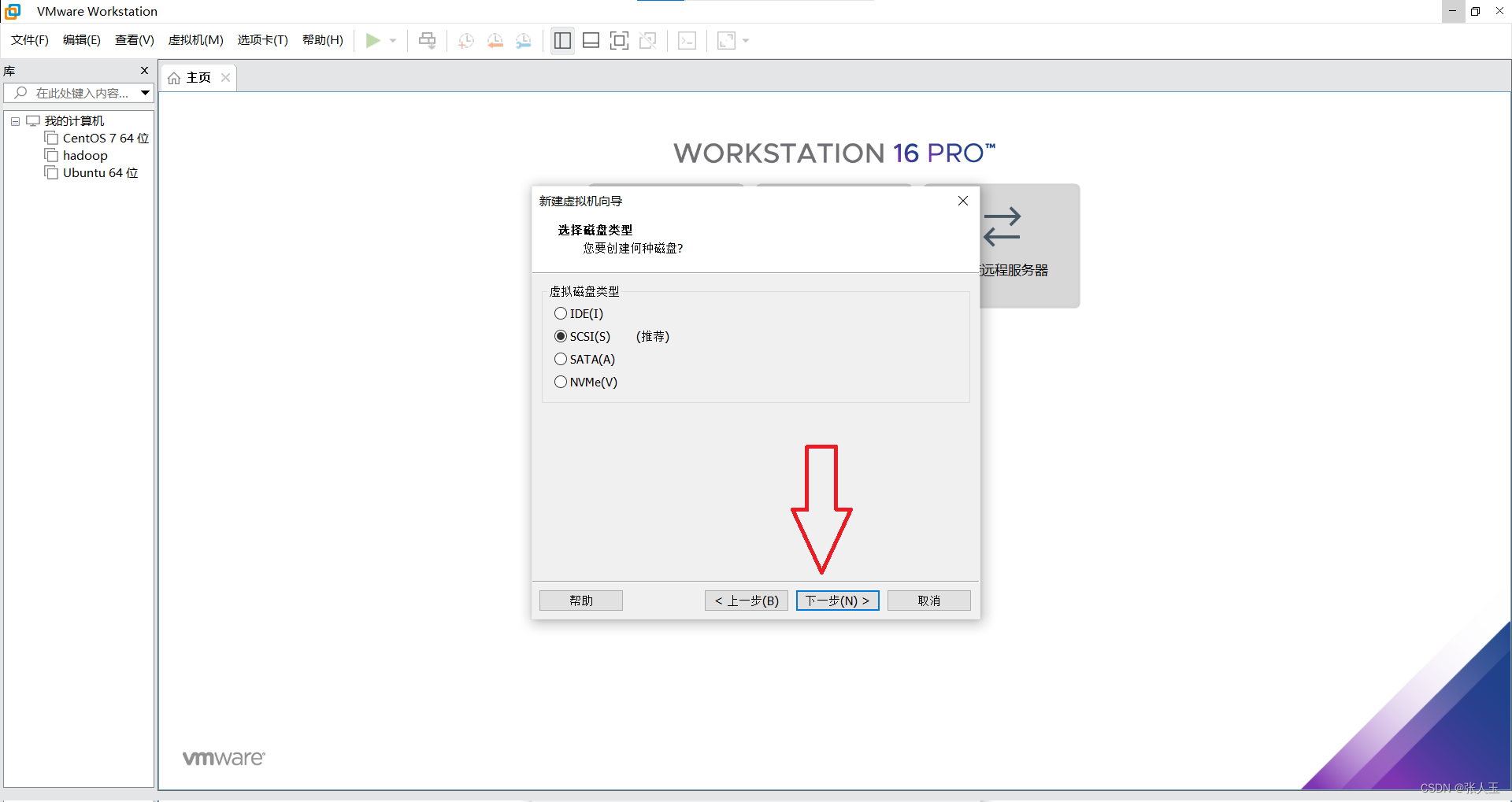
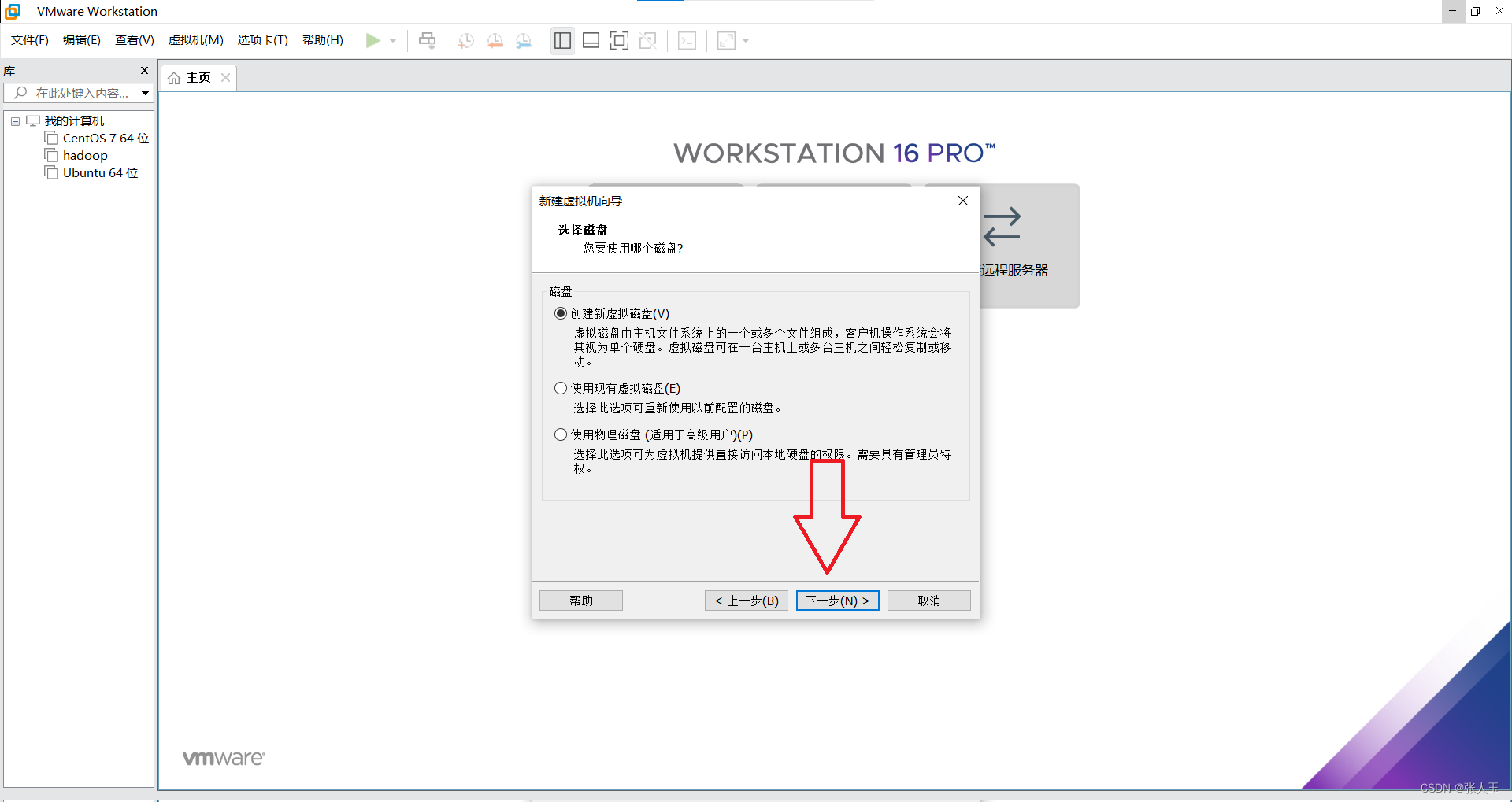
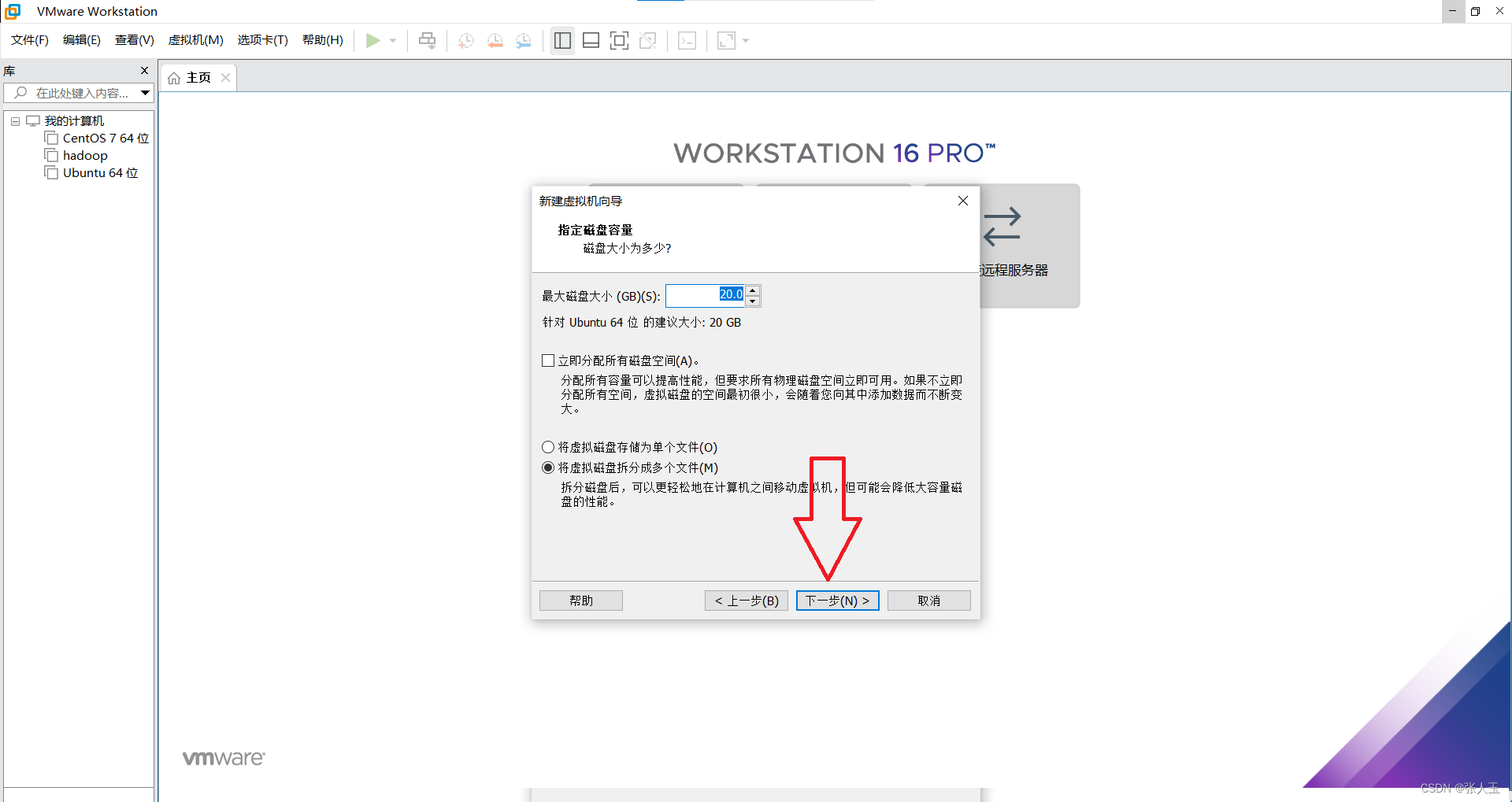
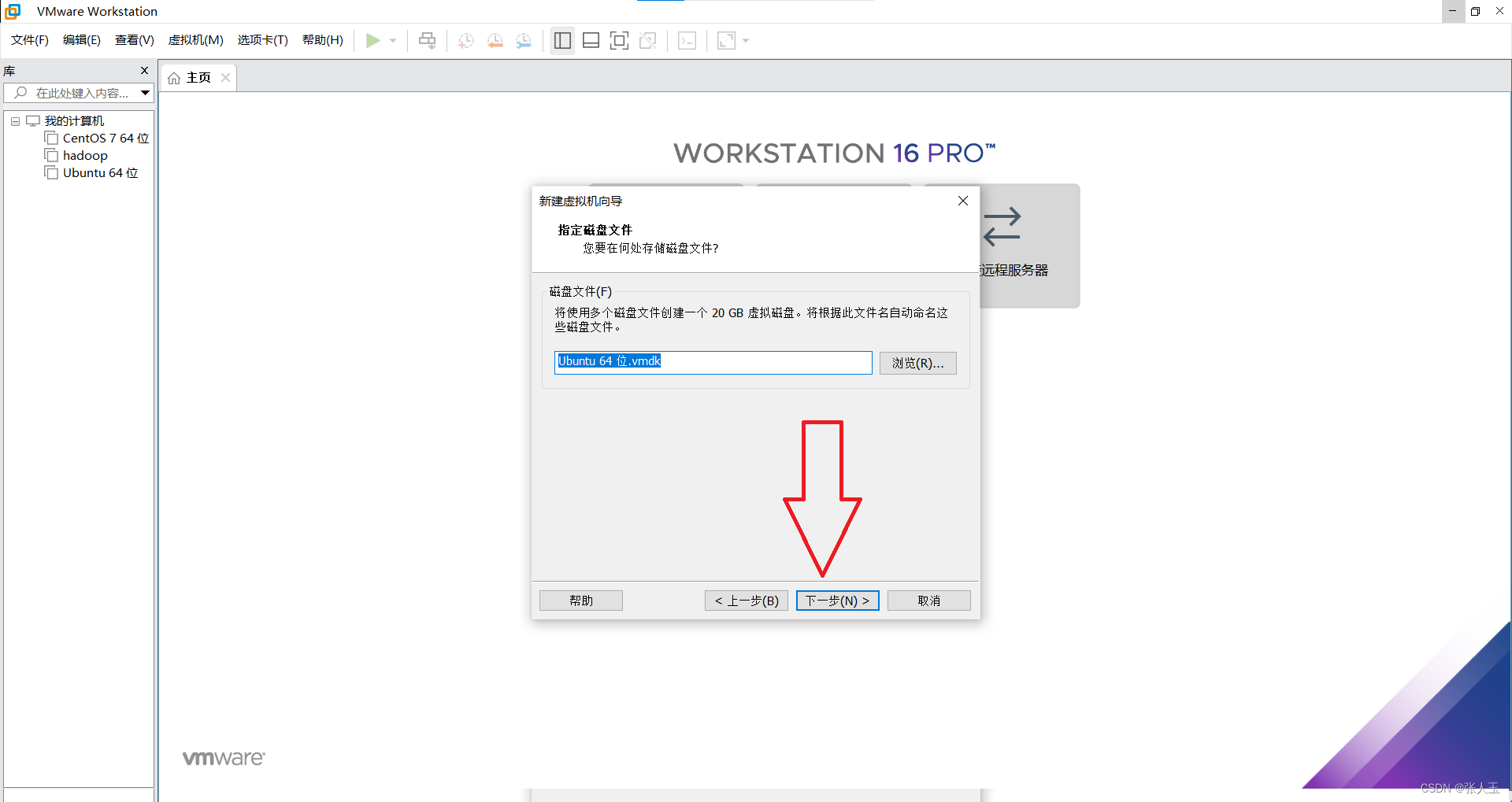
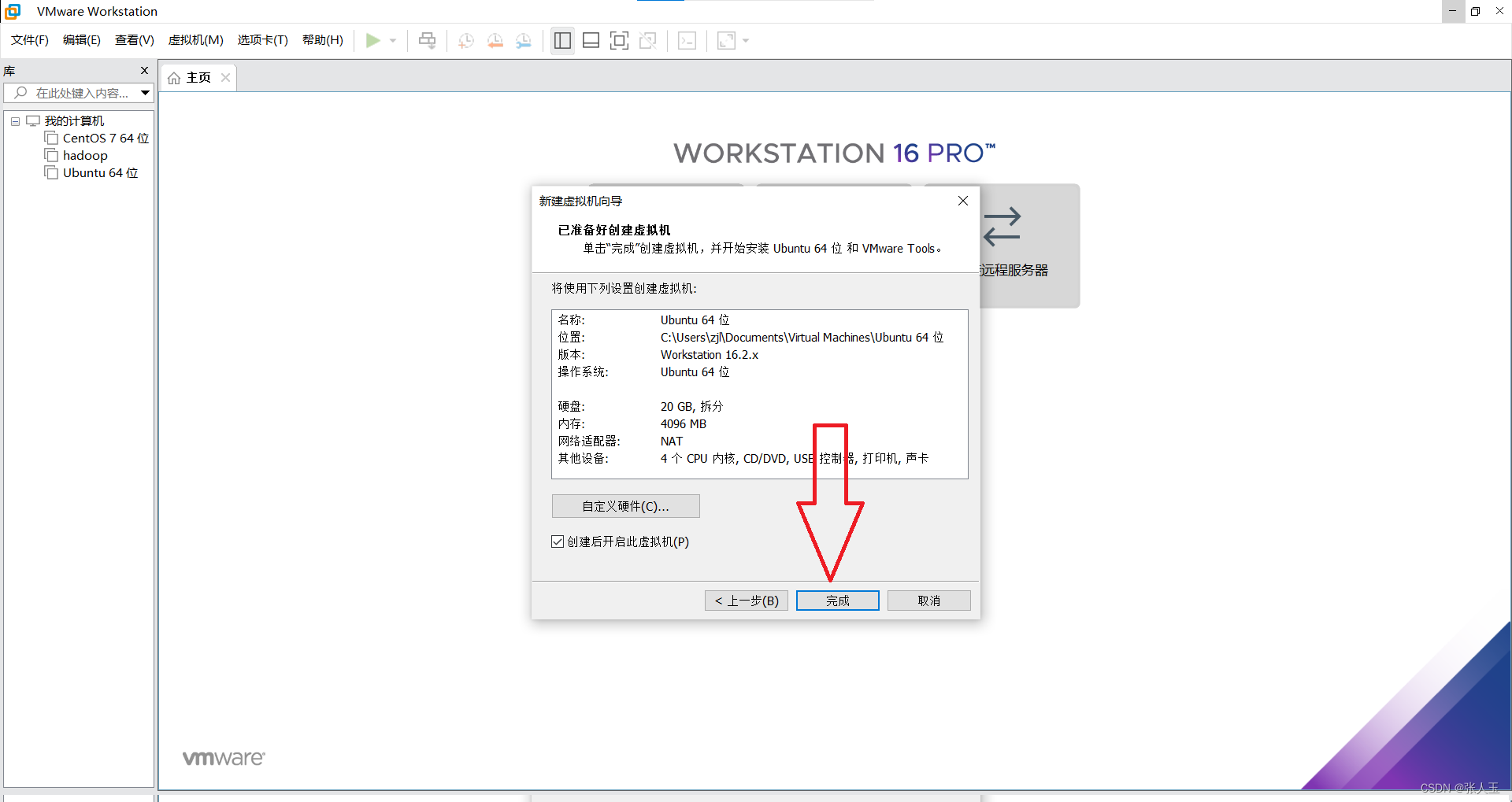
2.启动系统
进入之后
按
ctrl+alt可以将鼠标推出虚拟机的界面
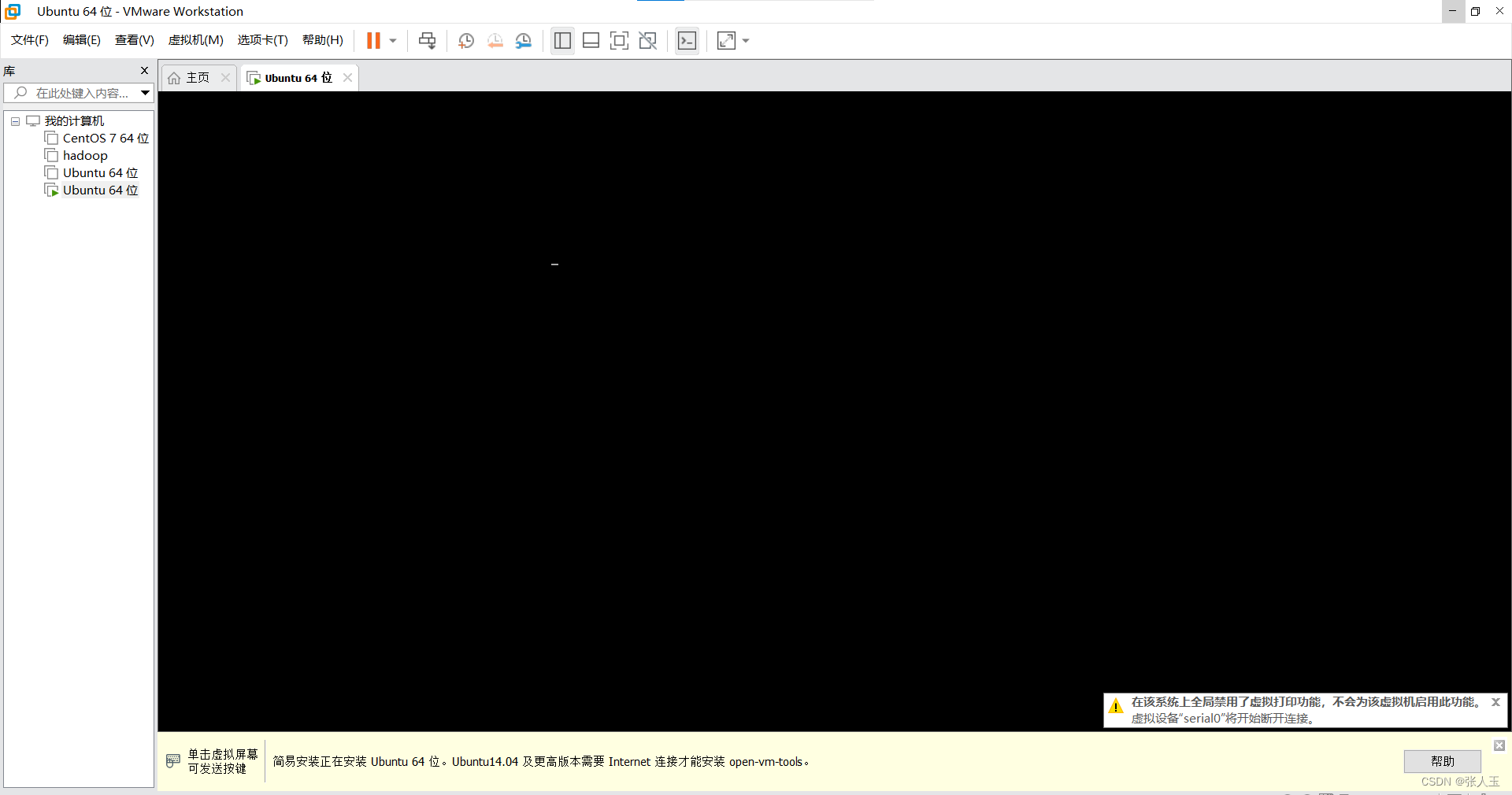
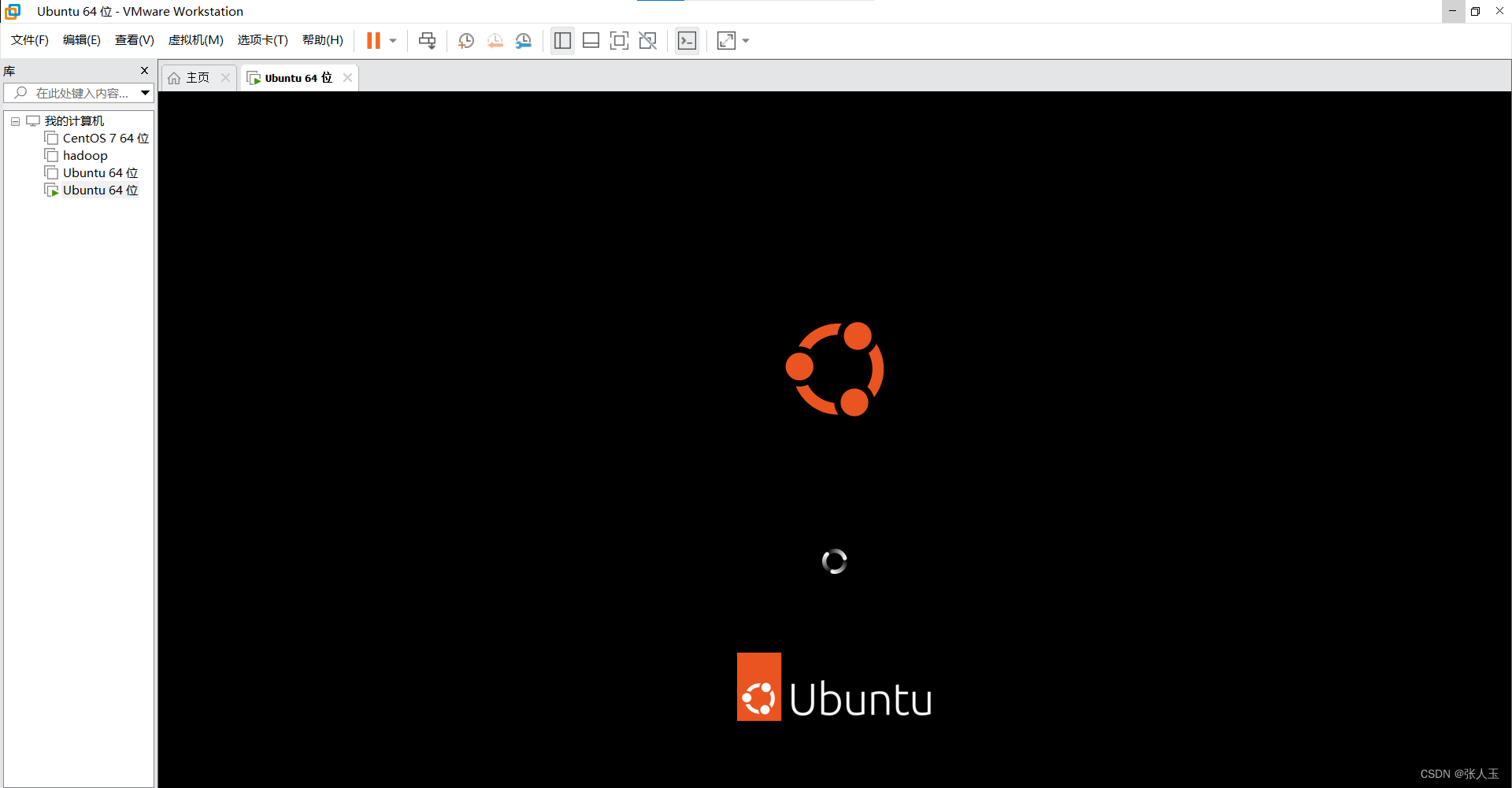
会有一段时间黑屏,这是正常现象请耐心等待,第一次的过程比较缓慢
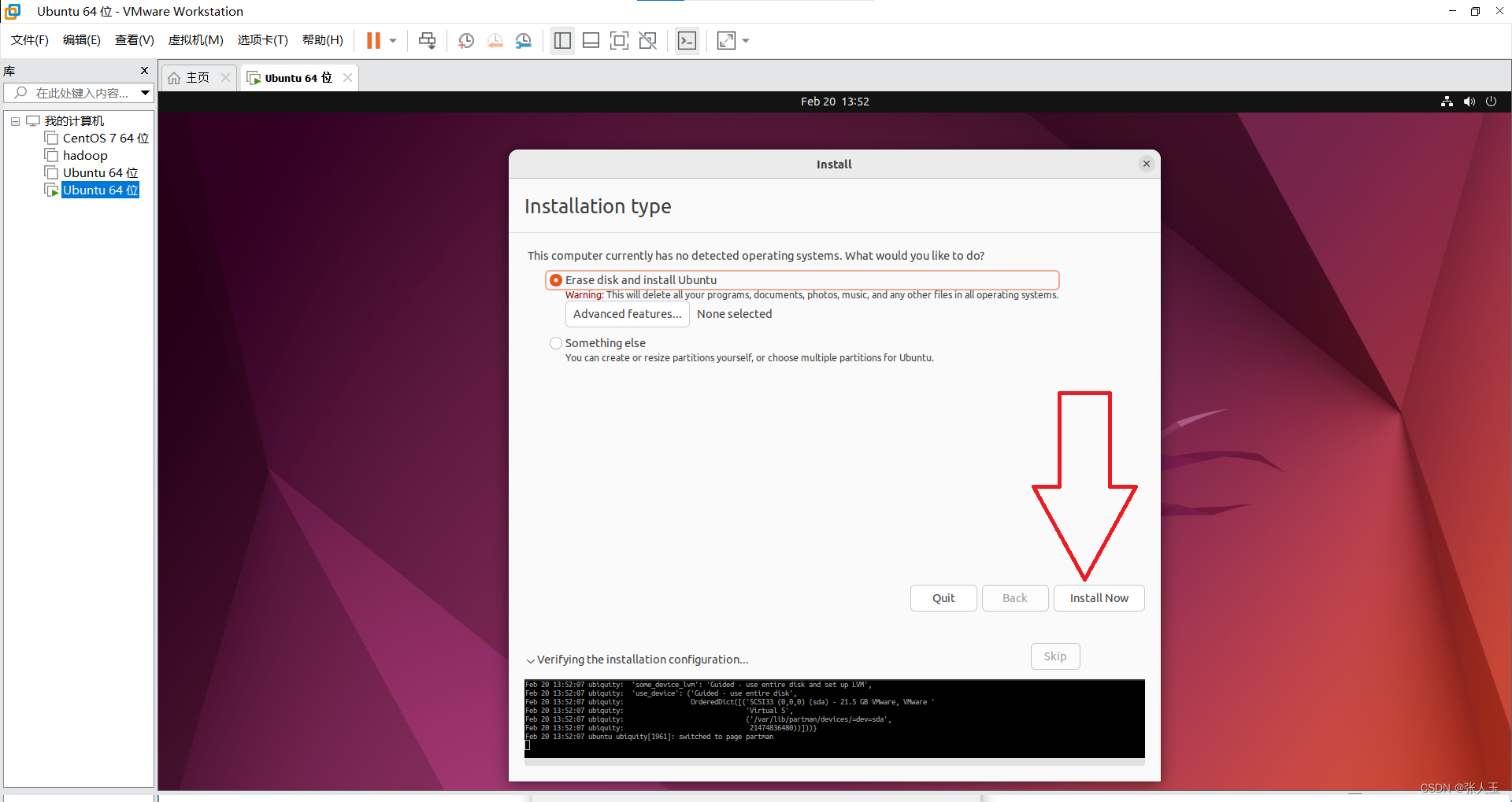
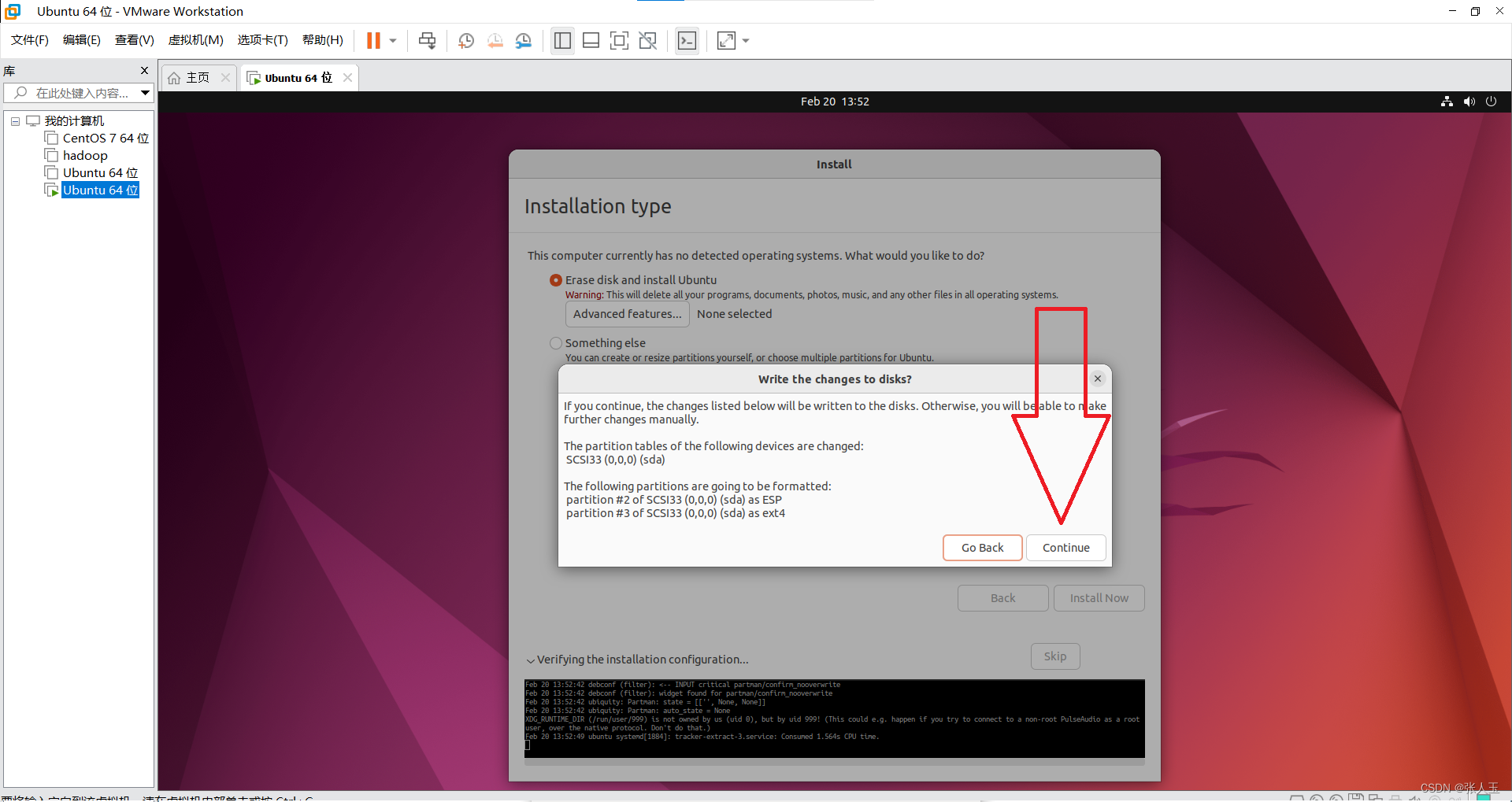
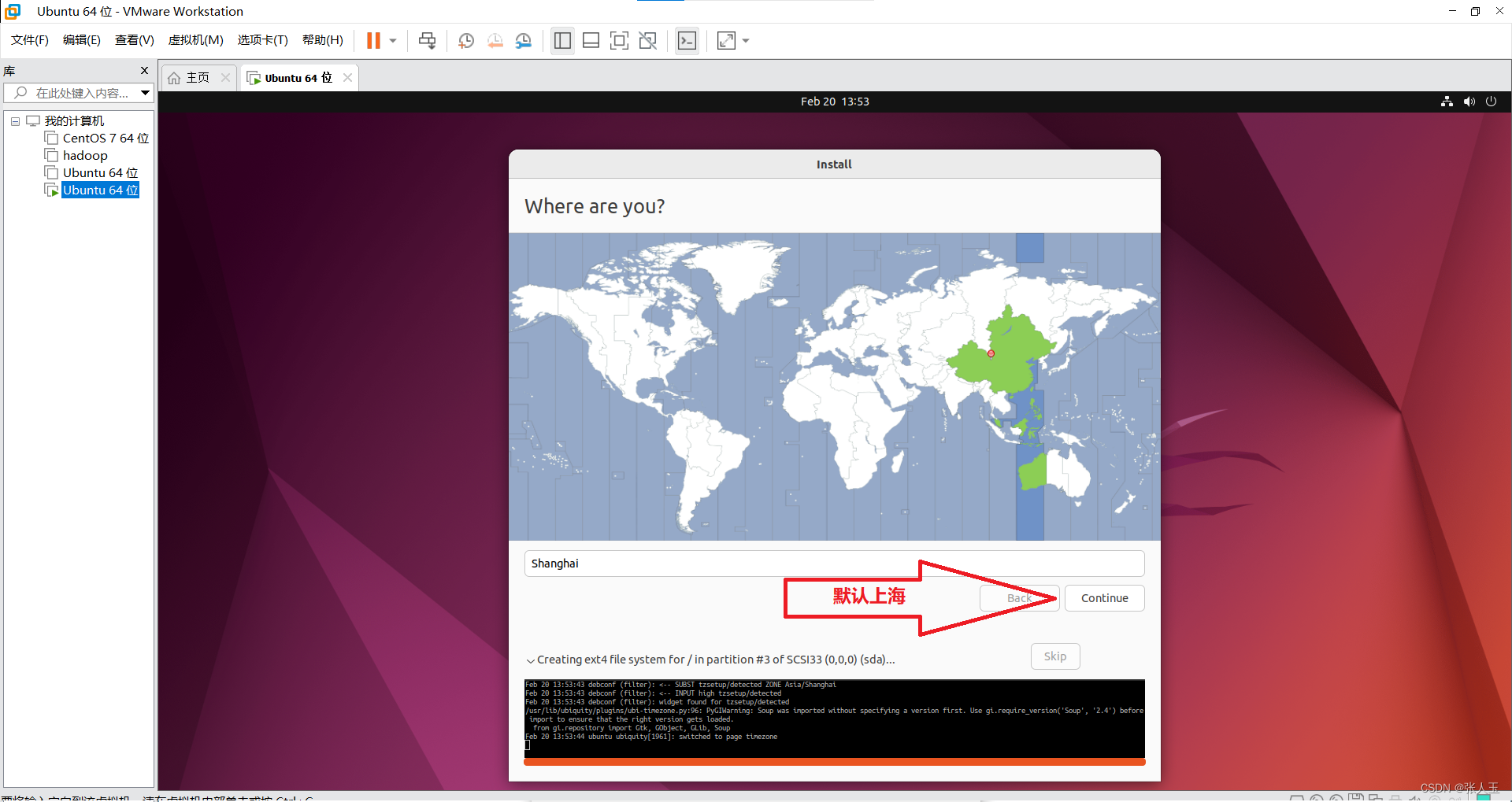
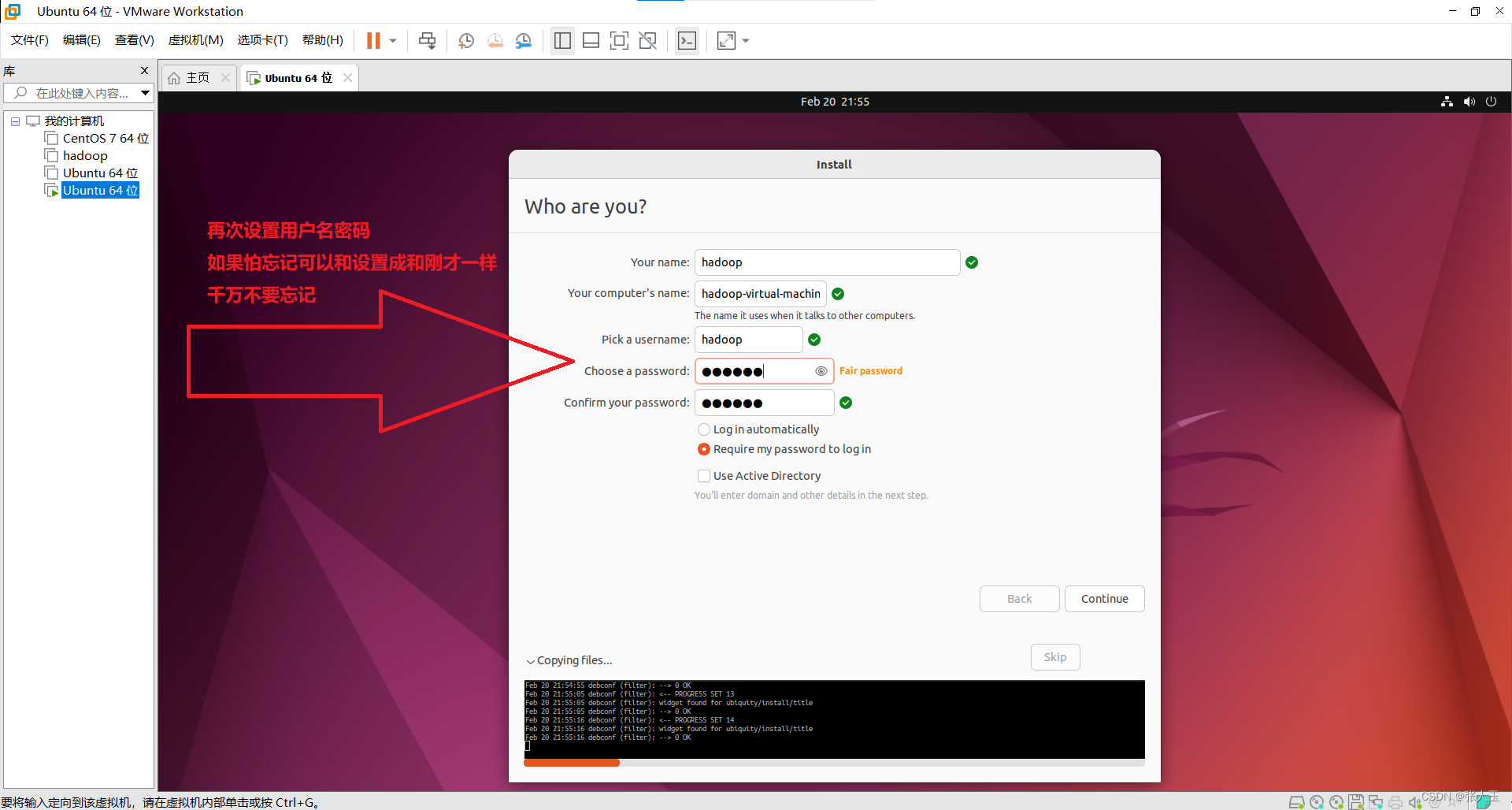
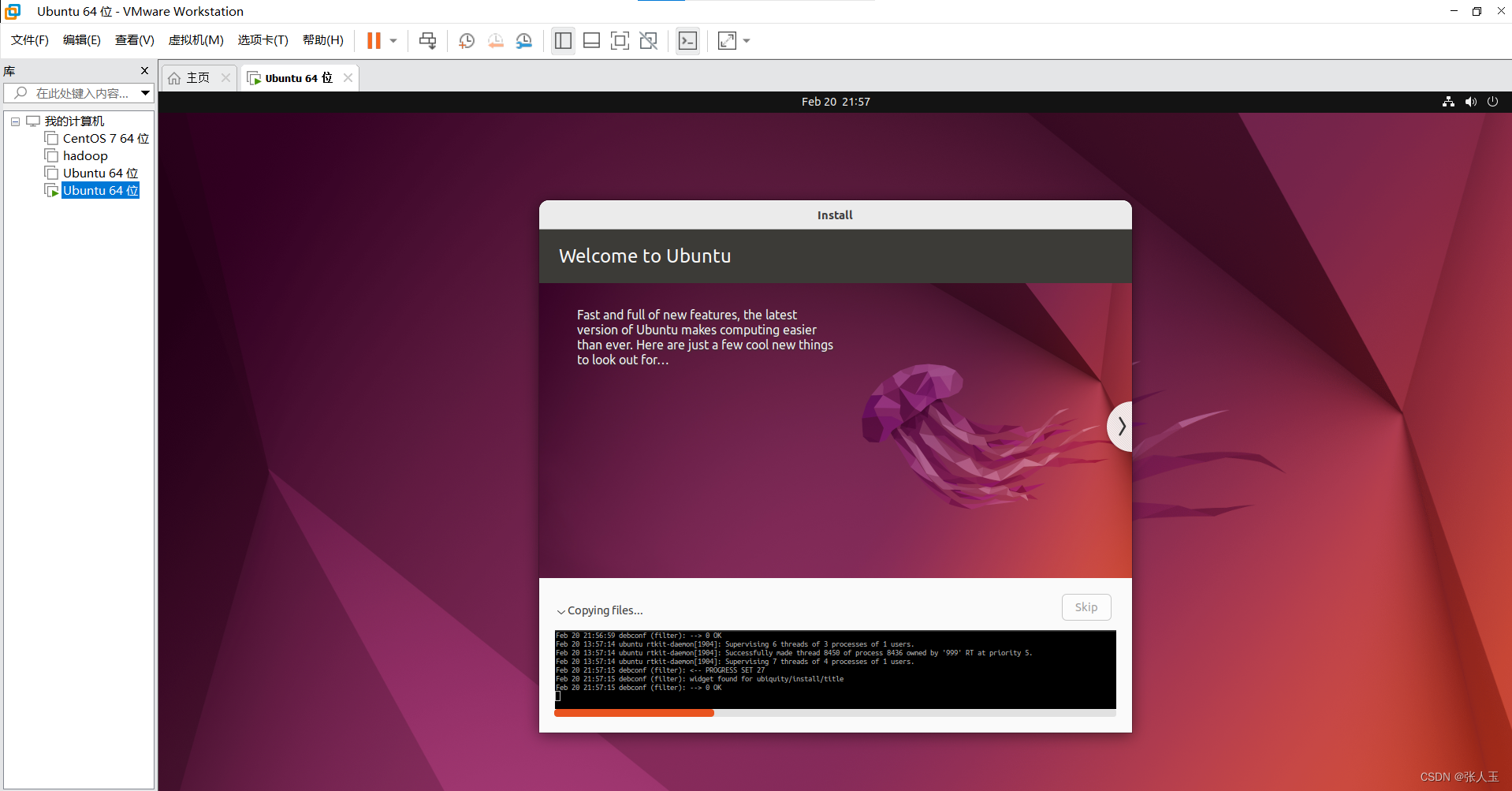
然后需要等待一会,程序自动完成之后,会重新启动


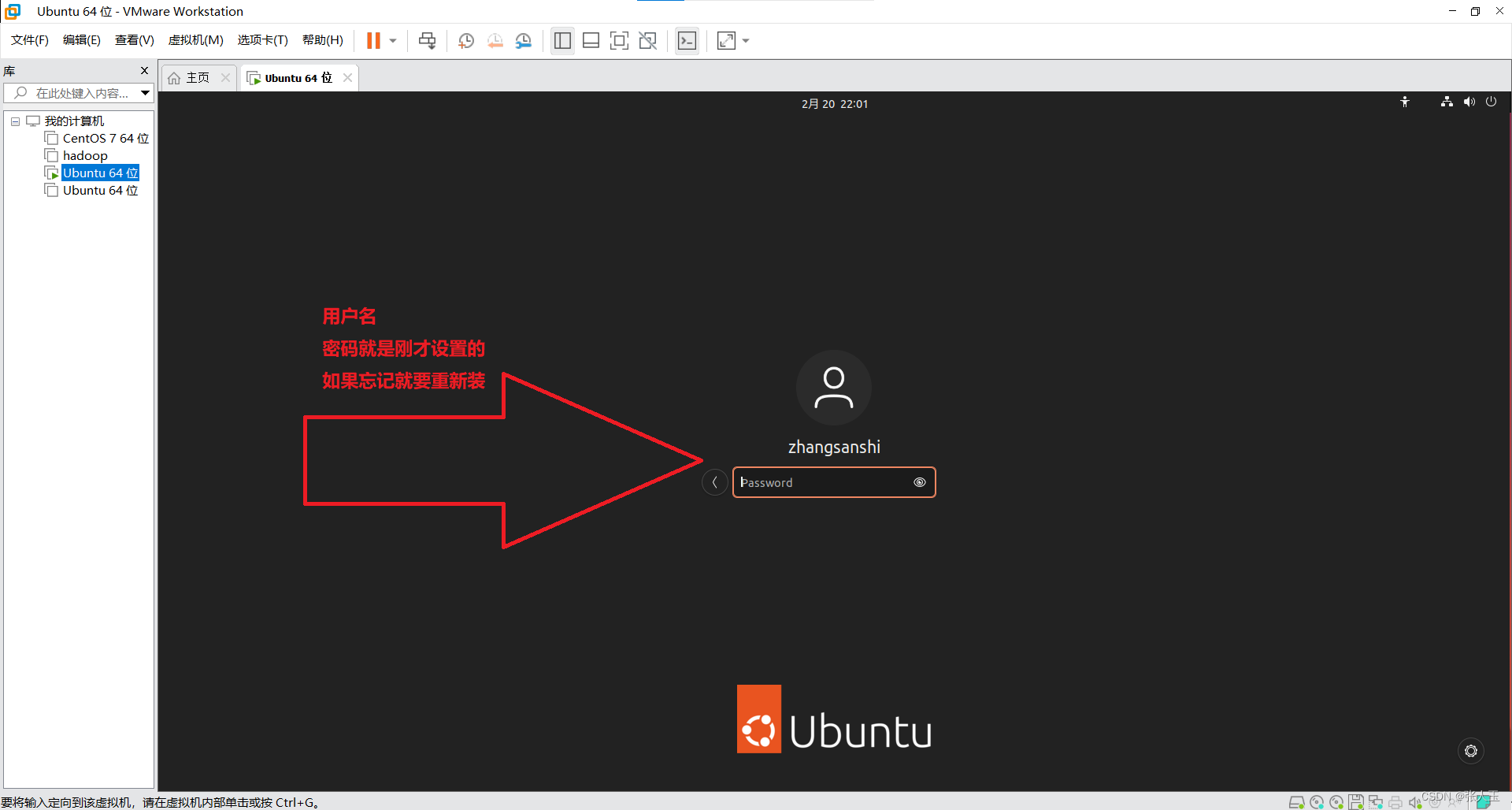
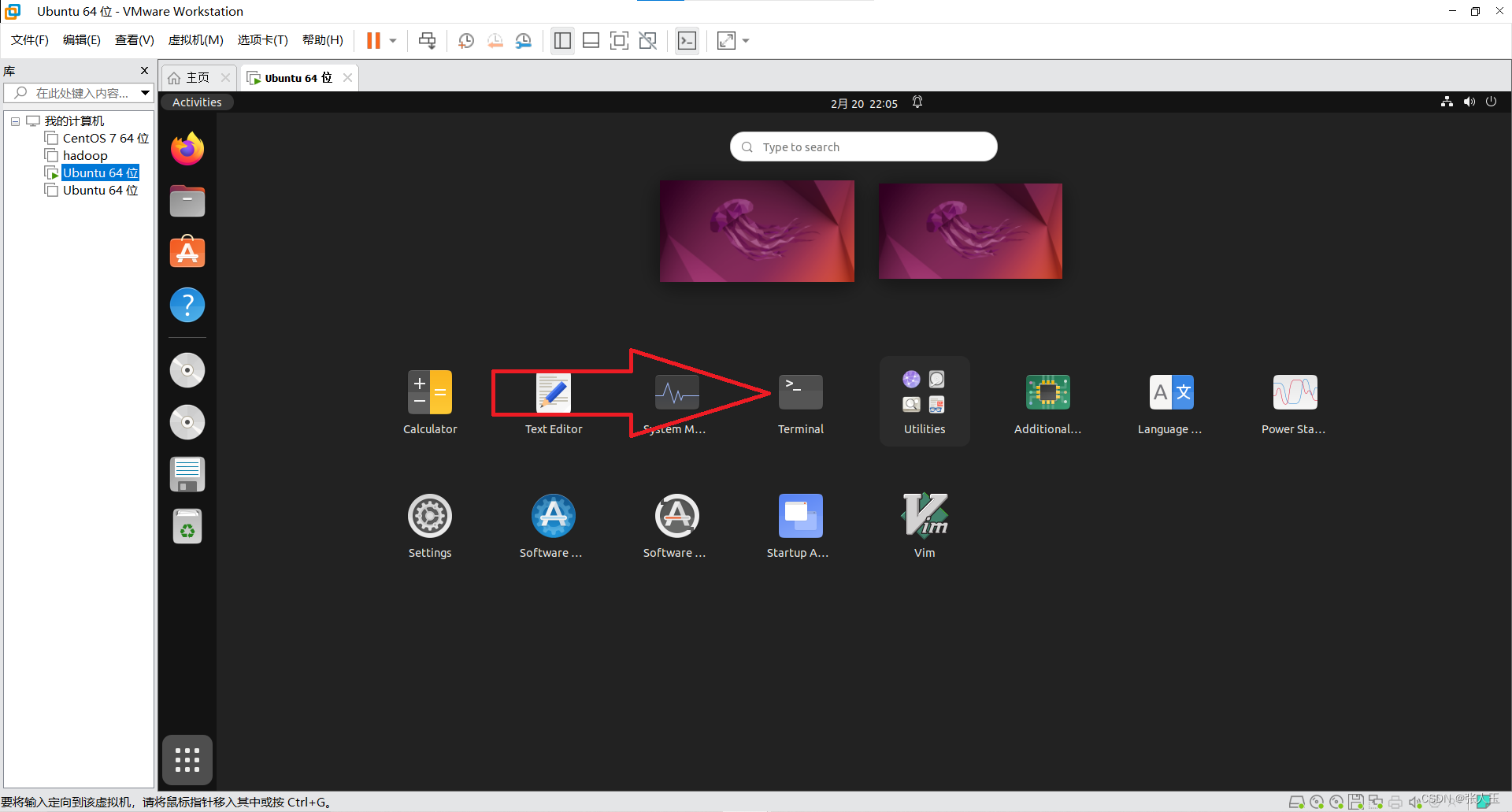
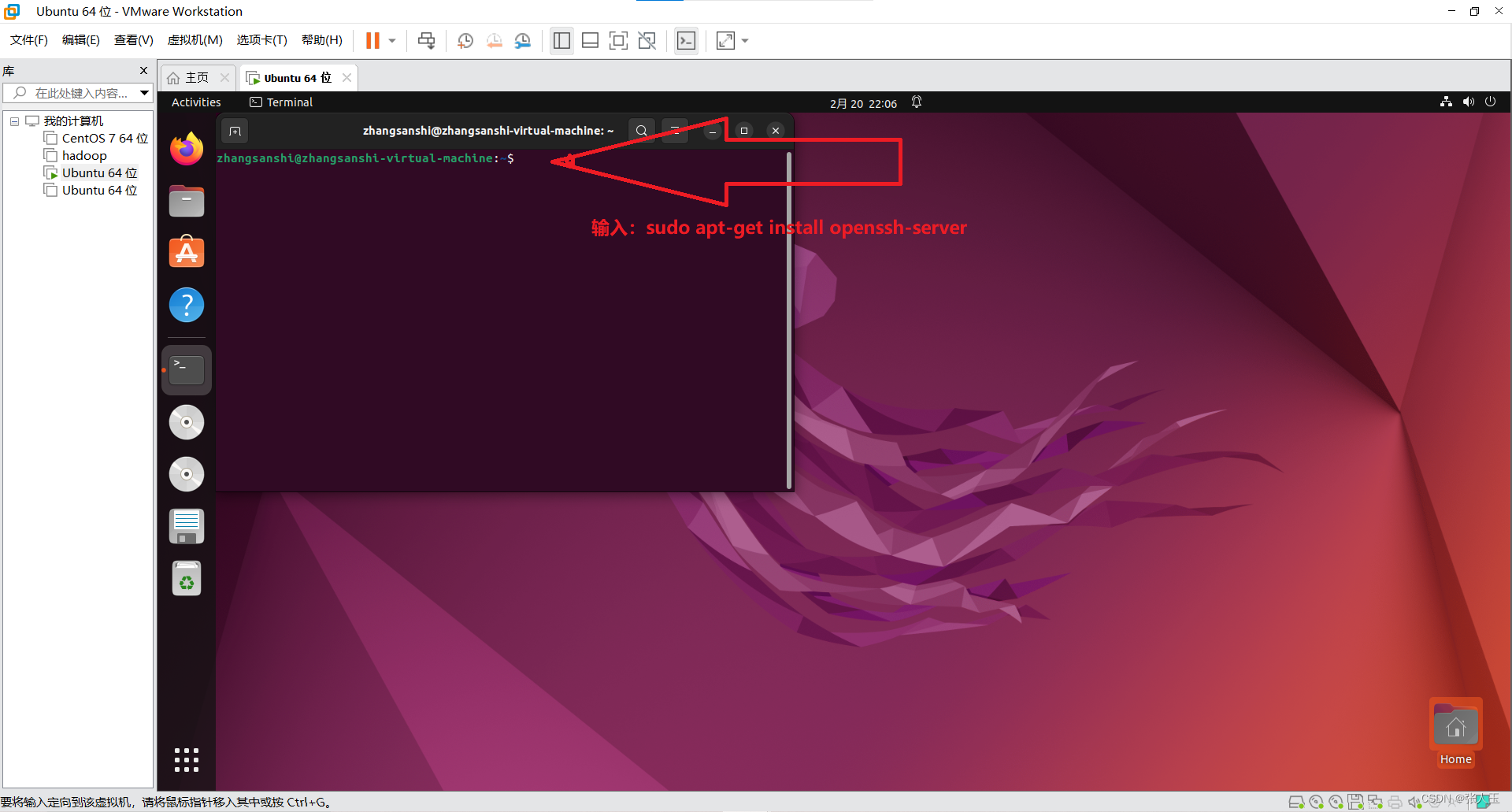
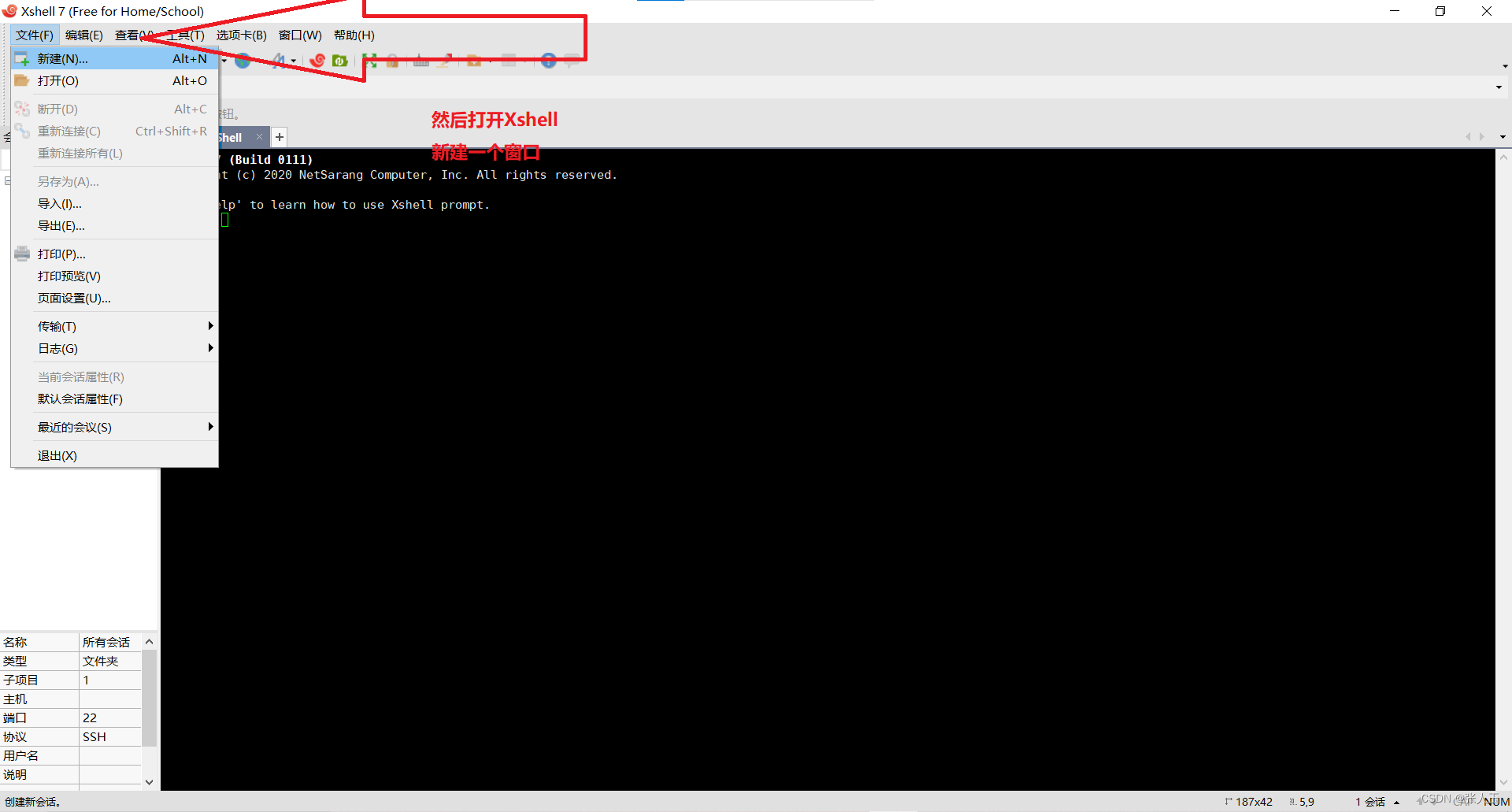
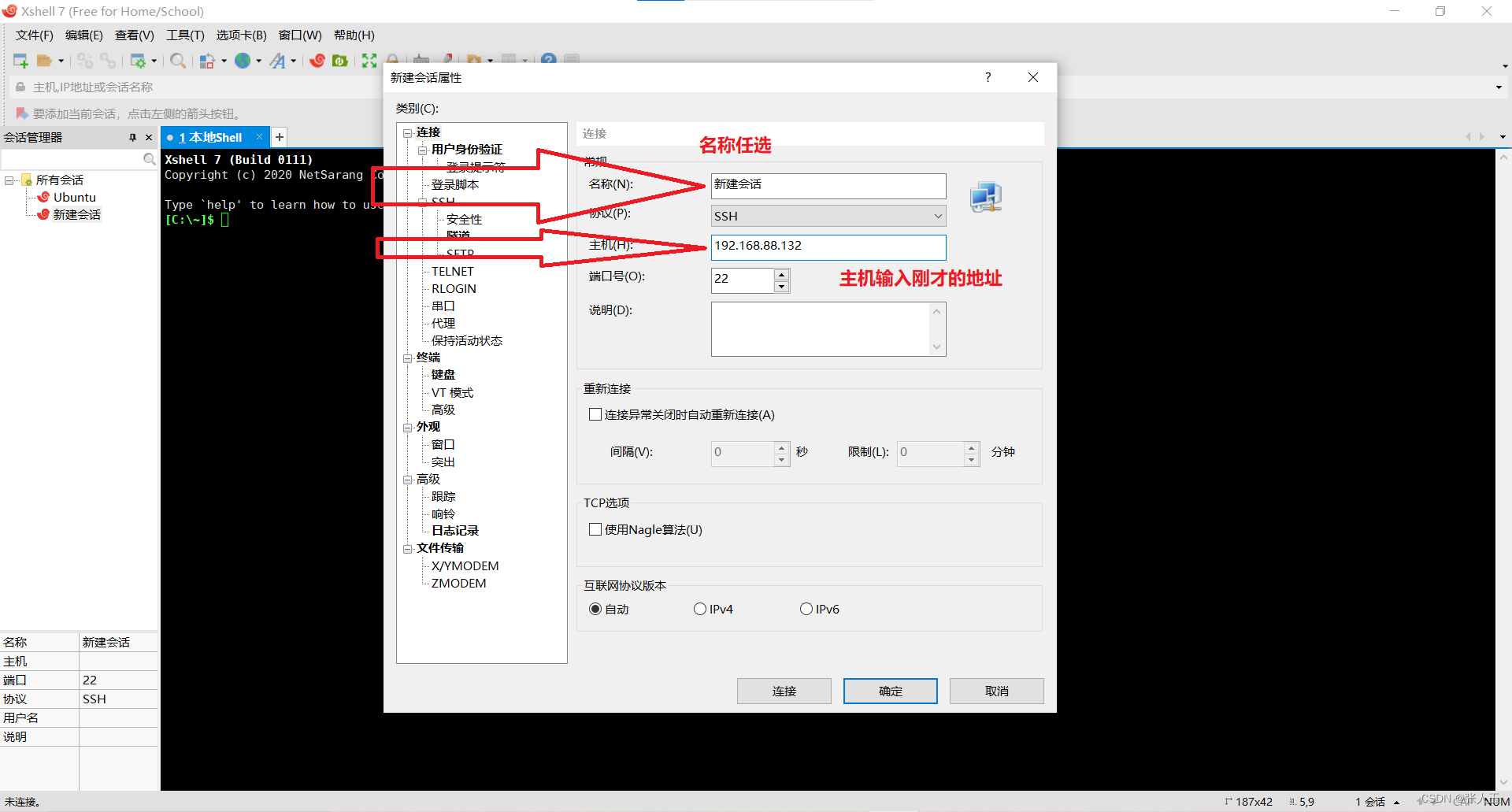
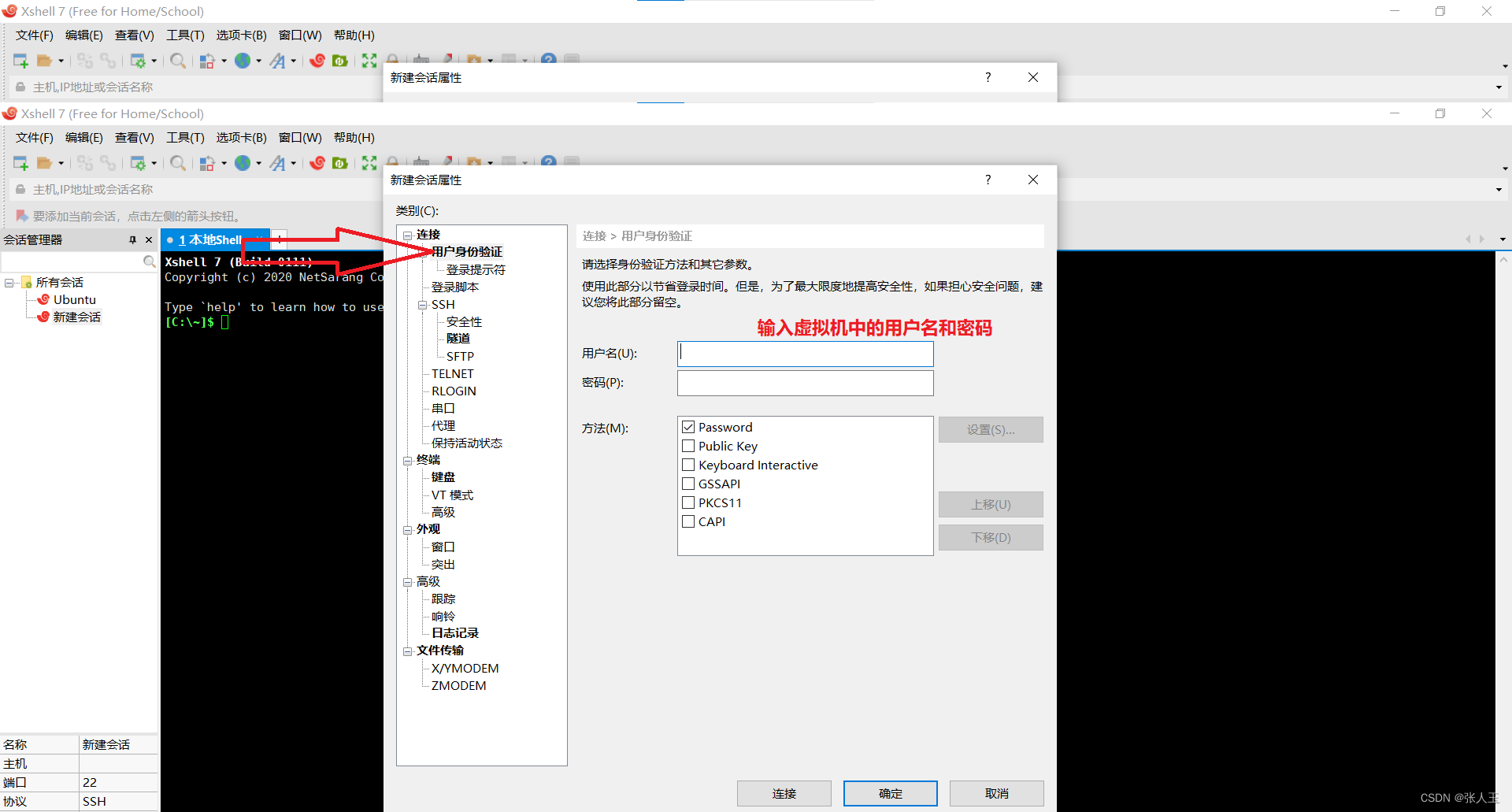
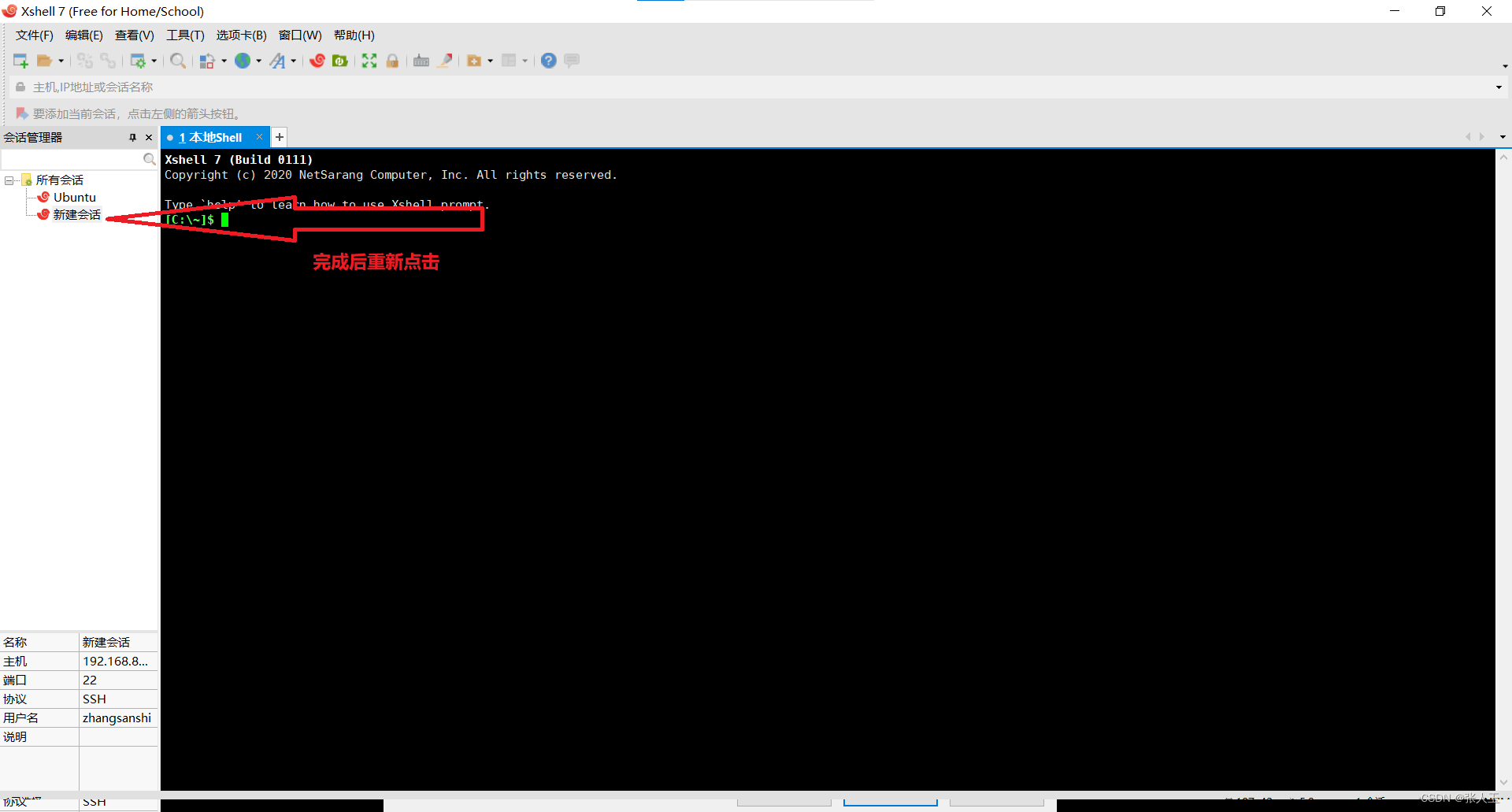
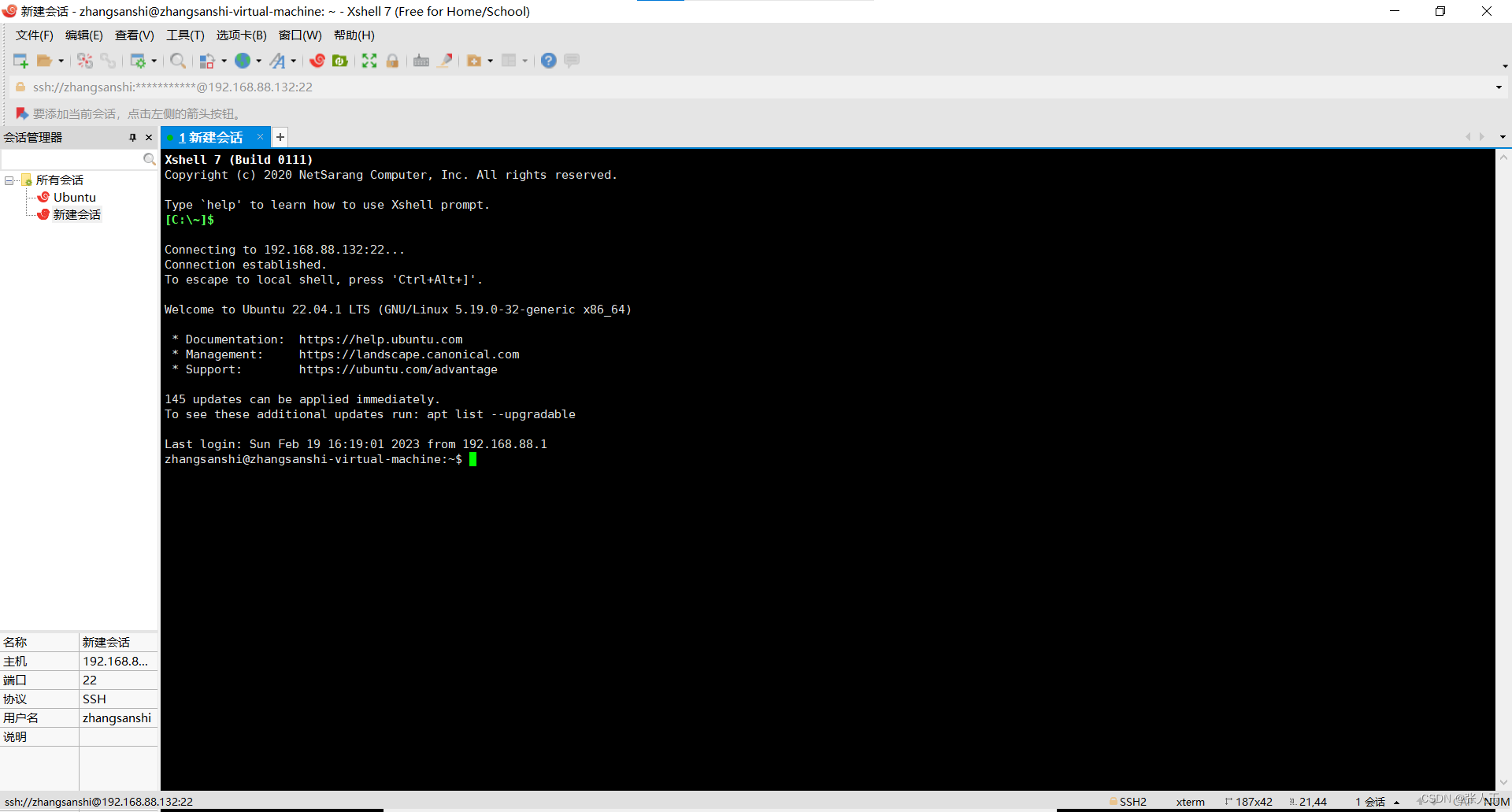
连接Xshell
说明:需要提前先安装好 Xshell 和 Xftp
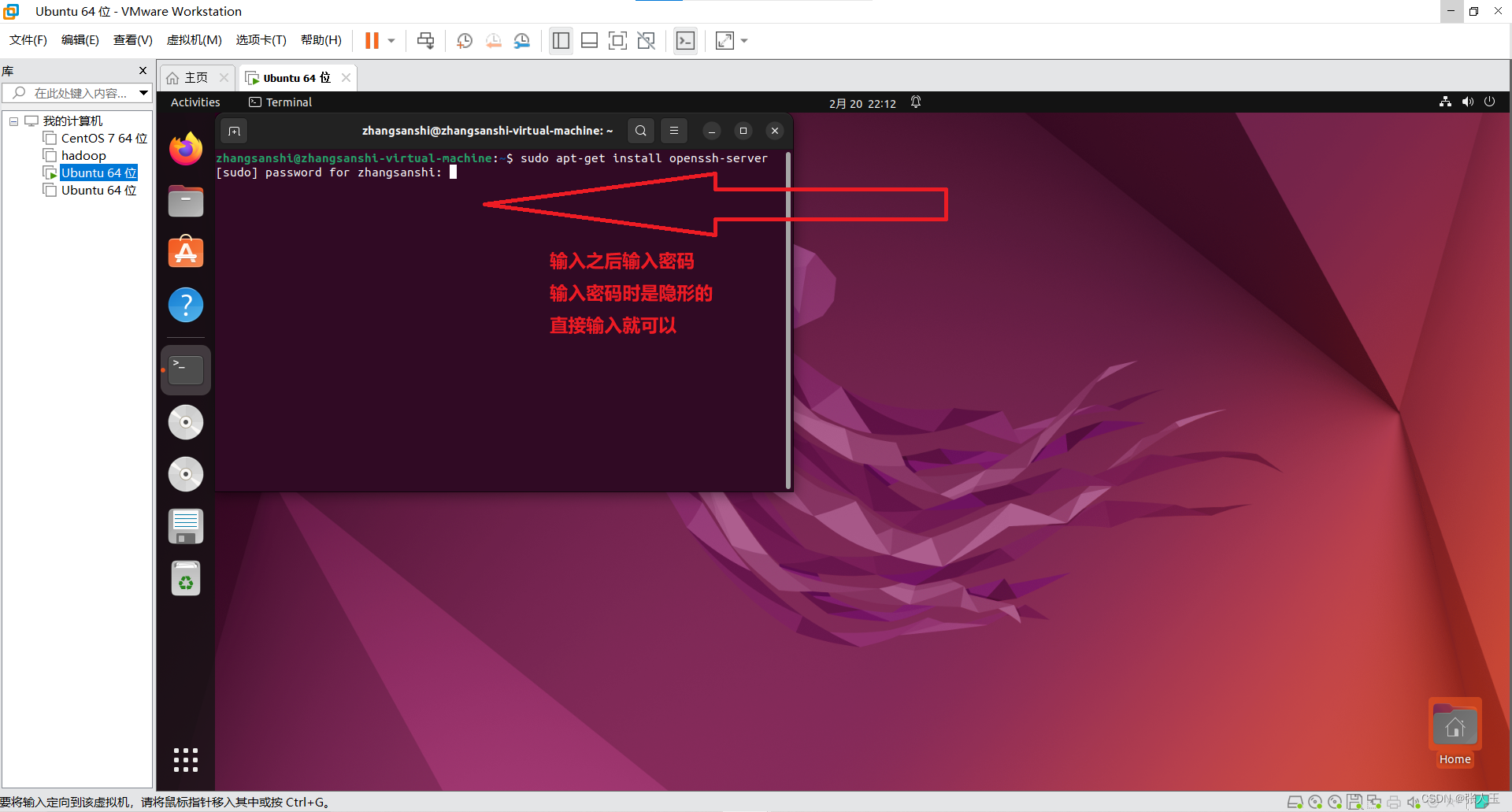
输入之后,可能中间会中断一次,不要担心,按enter继续就可以了

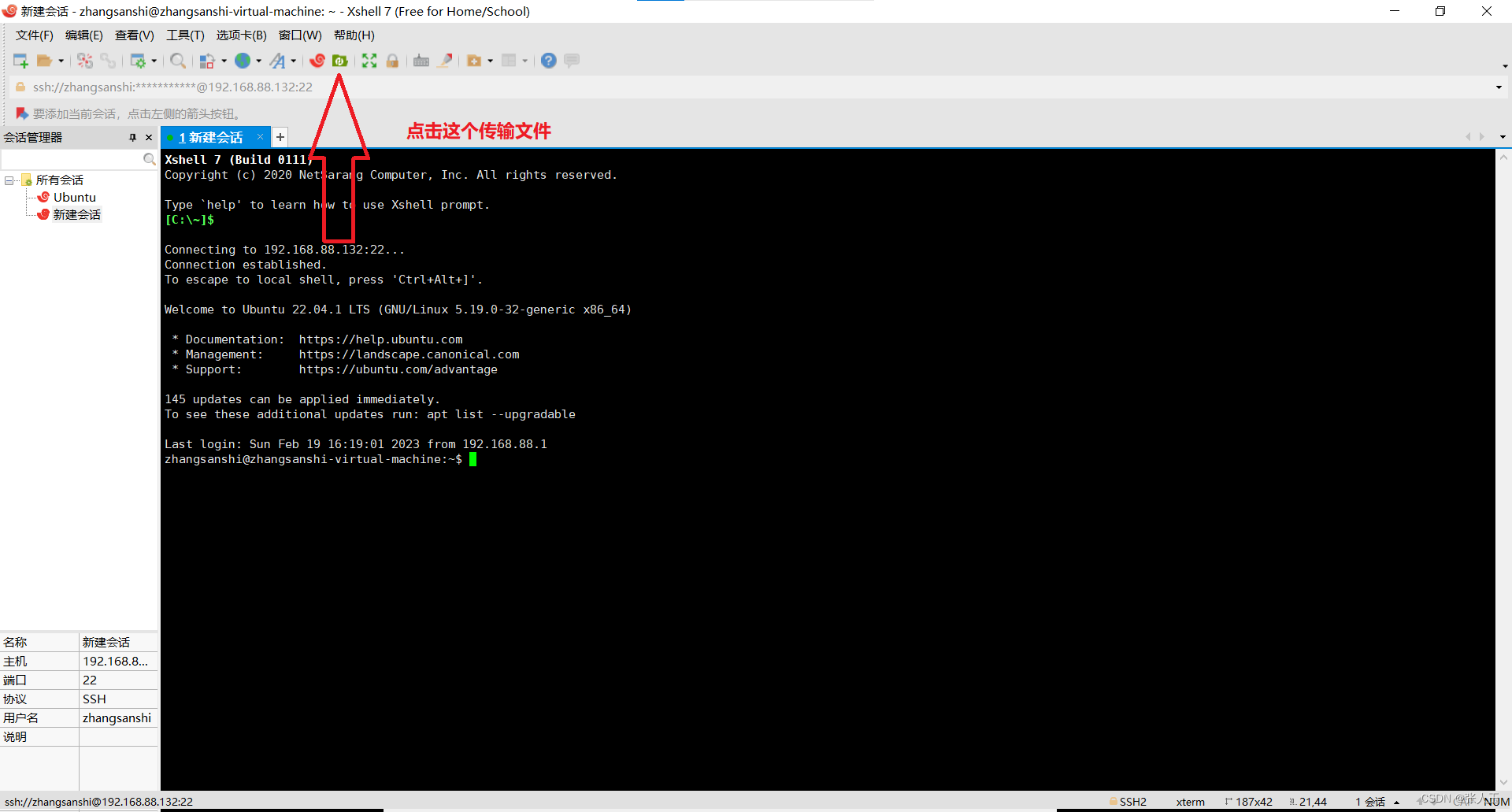
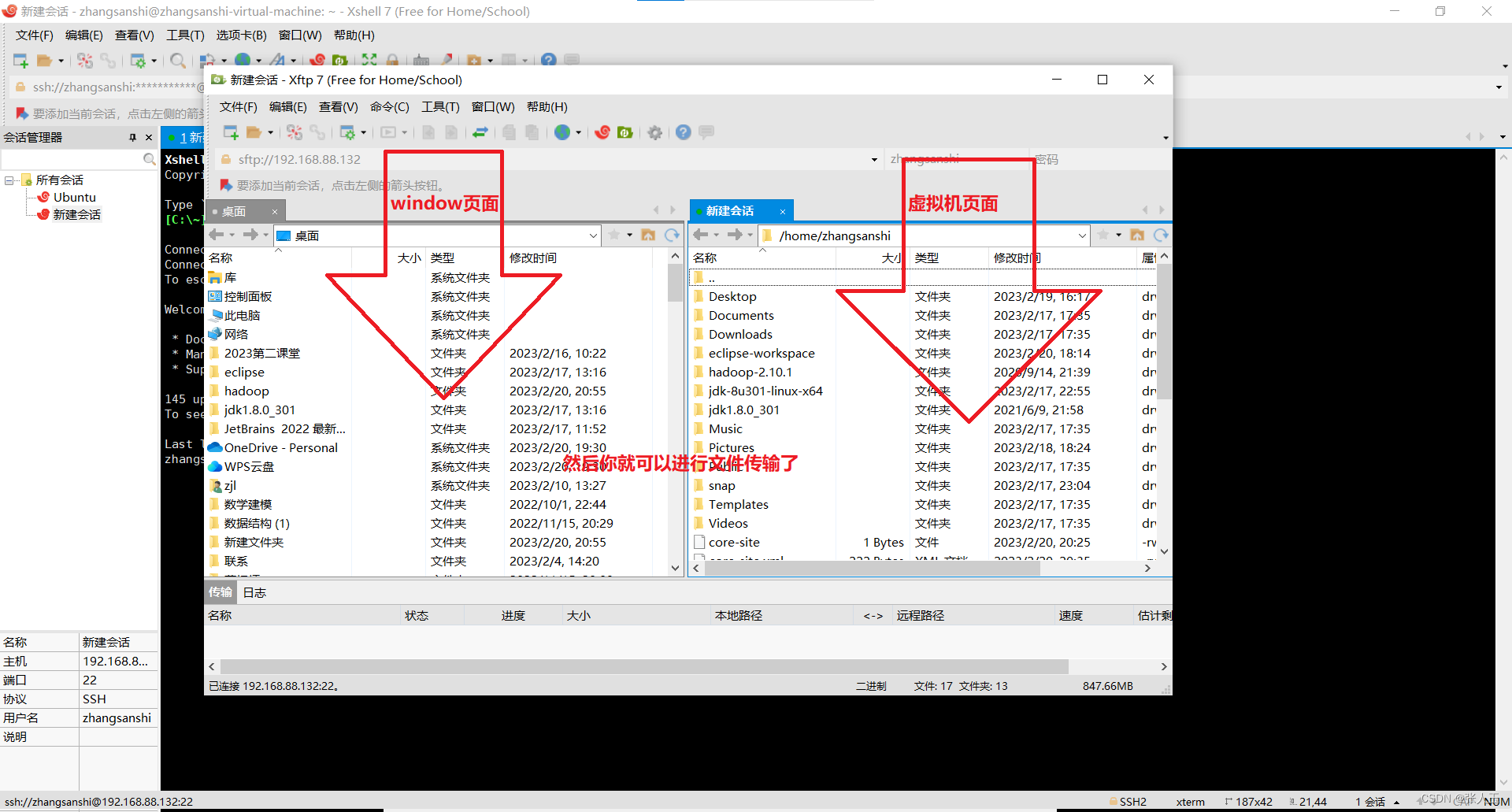
将
jdk的包(Linux版)
![]()
Hadoop的镜像文件(Hadoop的包)
![]()
eclipse(linux版)
![]()
这几个包从winws转到虚拟机中
开始下一步操作
(1)安装jdk和hadoop
先解压文件
输入代码
jdk-8u301-linux-x64.tar.gz 是文件名,要改成自己的文件名
hadoop-2.10.1.tar.gz 是文件名,要改成自己的文件名
$ tar -zxvf jdk-8u301-linux-x64.tar.gz
$ tar -zxvf hadoop-2.10.1.tar.gz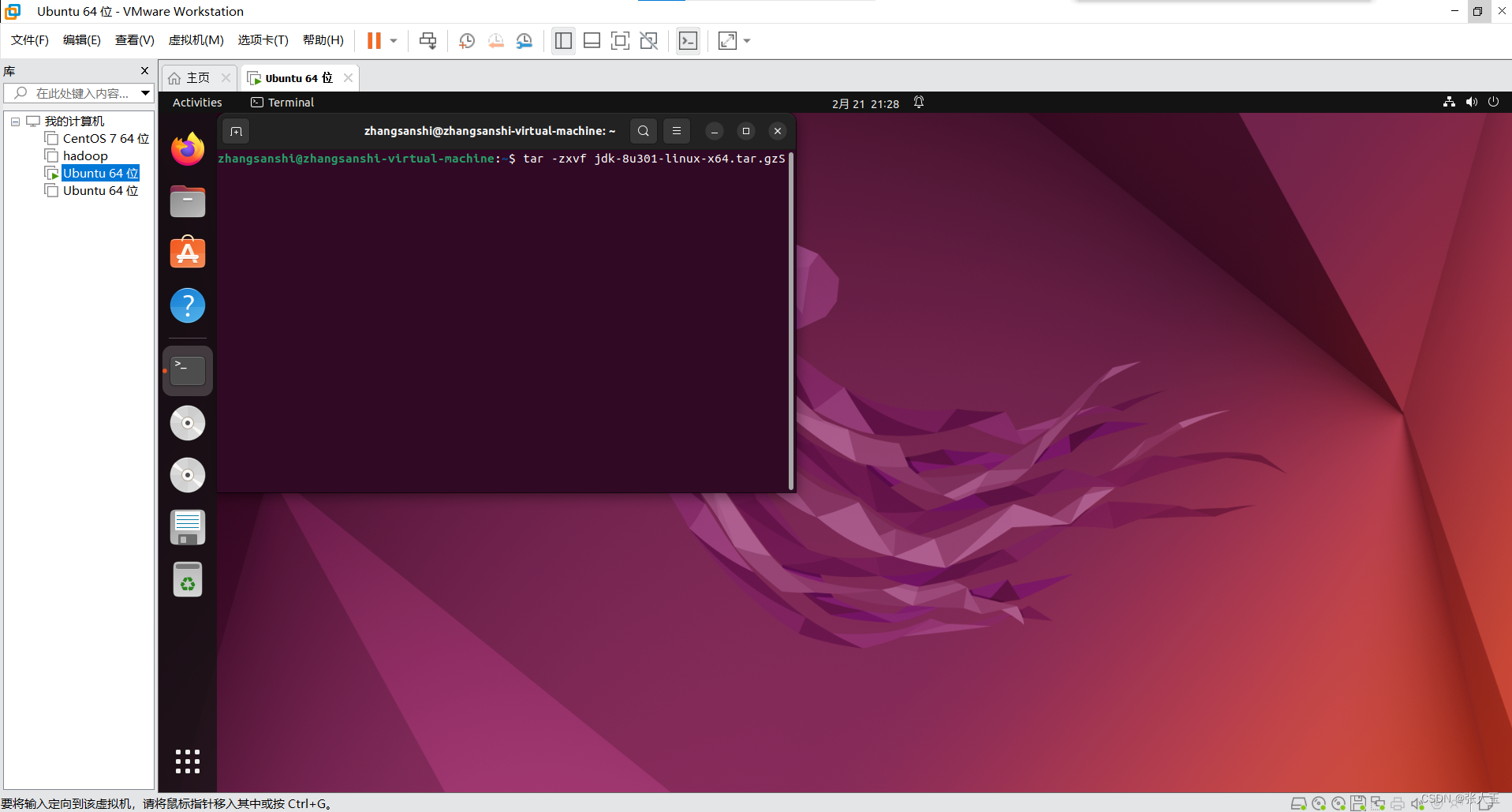
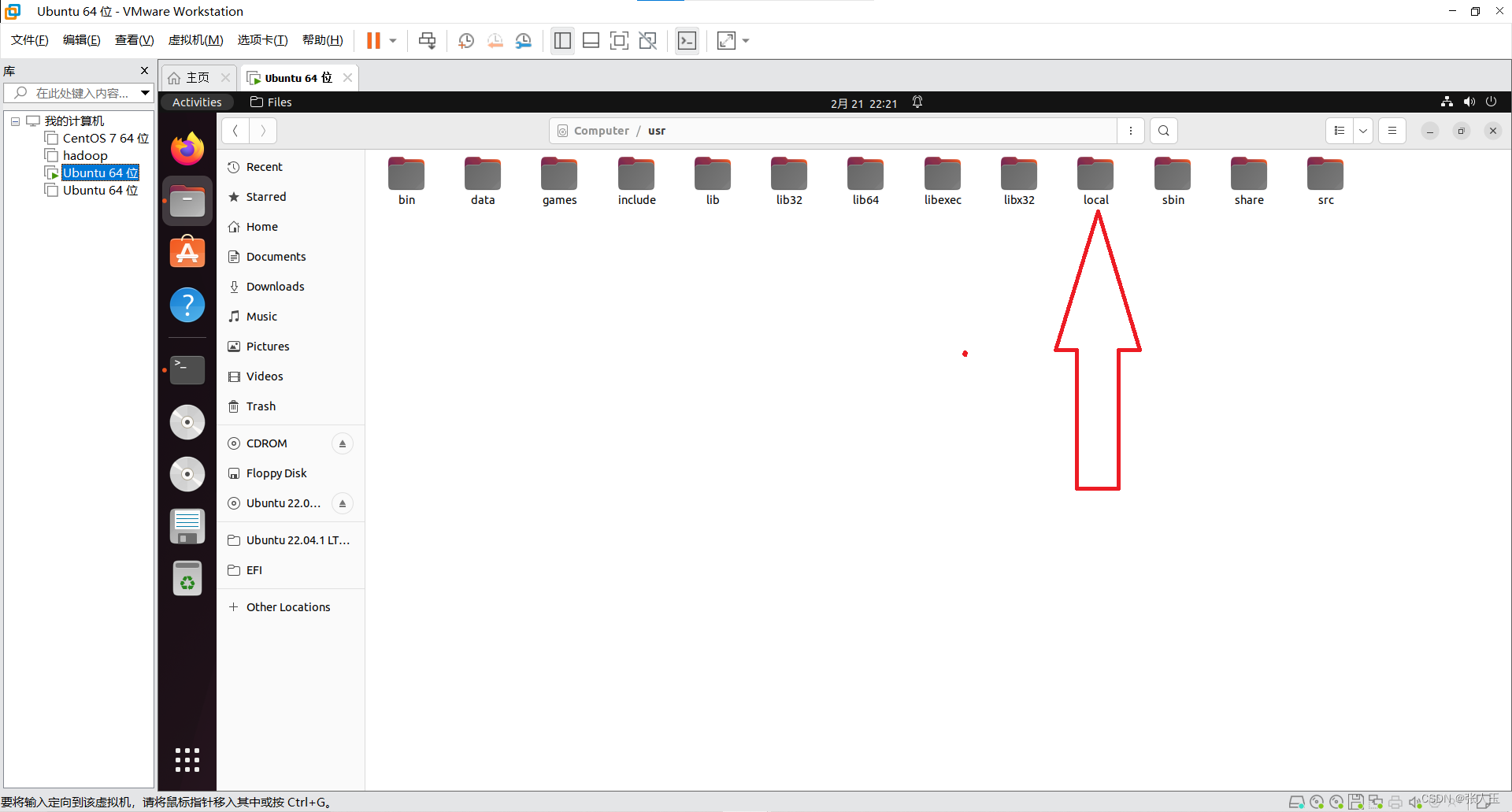
移动jdk
$ sudo mv jdk1.8.0_301 /usr/local/jdk1.8.0
移动hadoop
$ sudo mv hadoop-2.10.1 /usr/local/$ sudo apt install vim$ sudo vim /etc/profileexport JAVA_HOME=/usr/local/jdk1.8.0
export HADOOP_HOME=/usr/local/hadoop-2.10.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin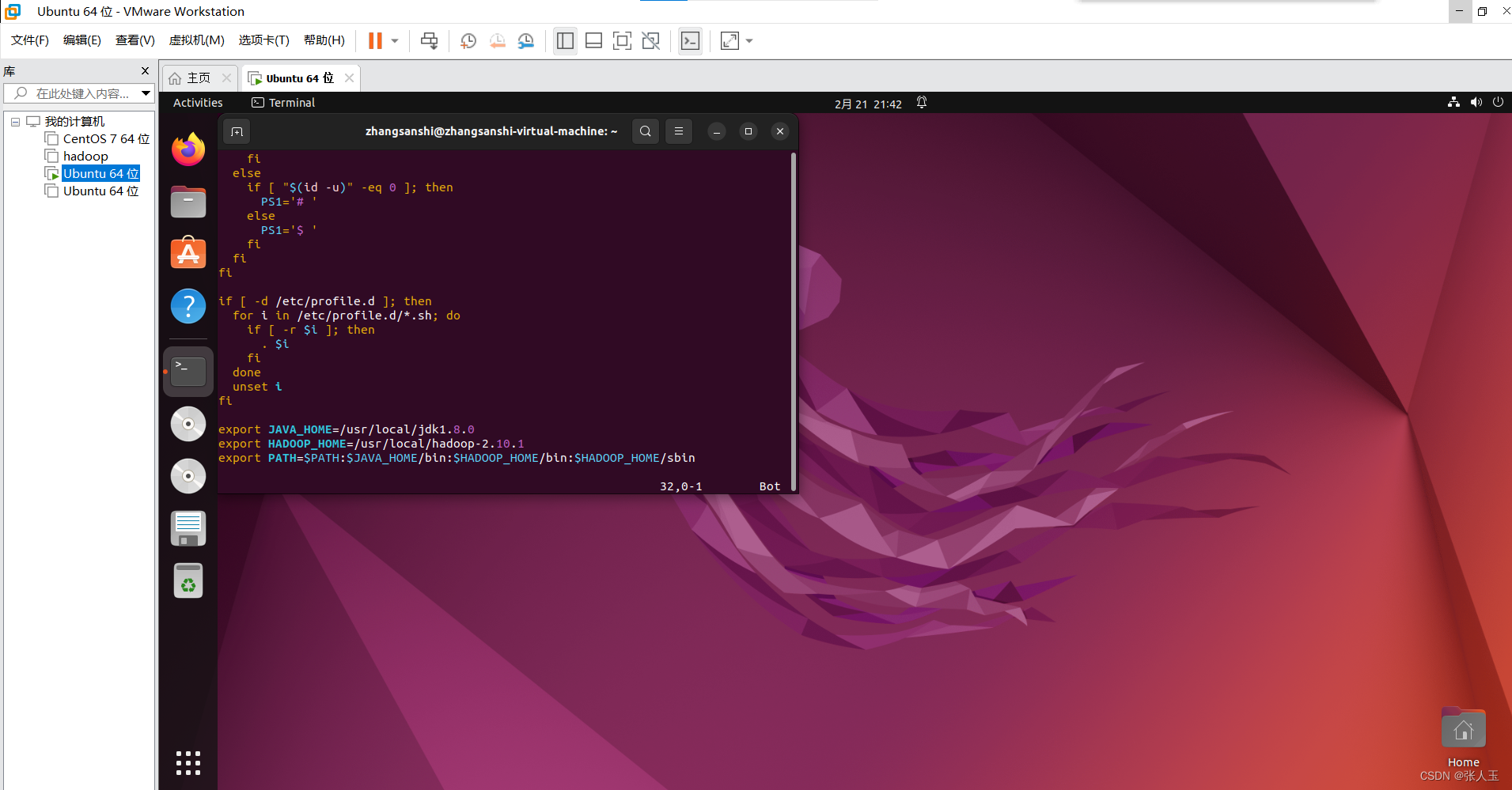
按Esc
然后输入
:wq
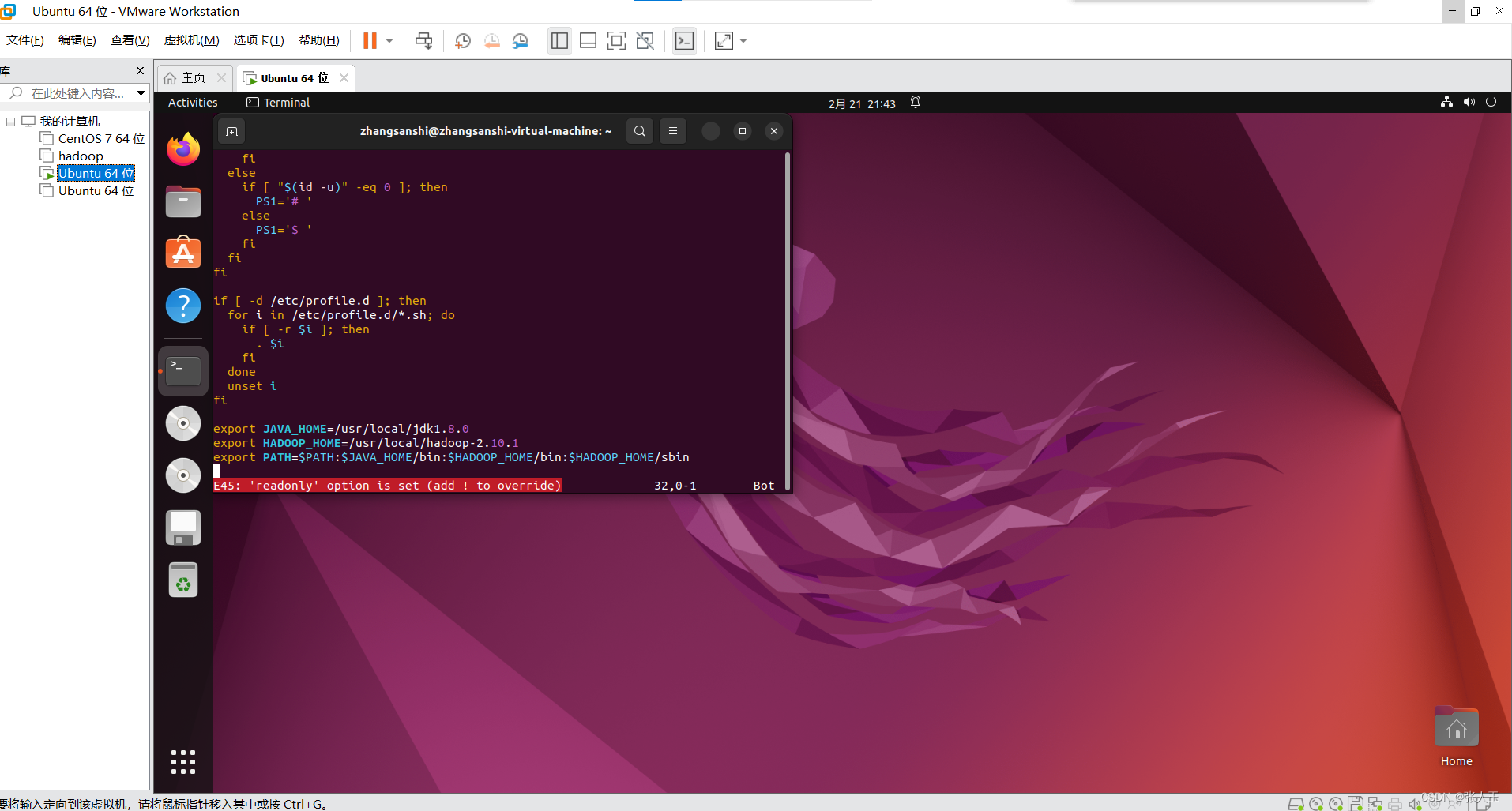
如果出现这种情况退出不了
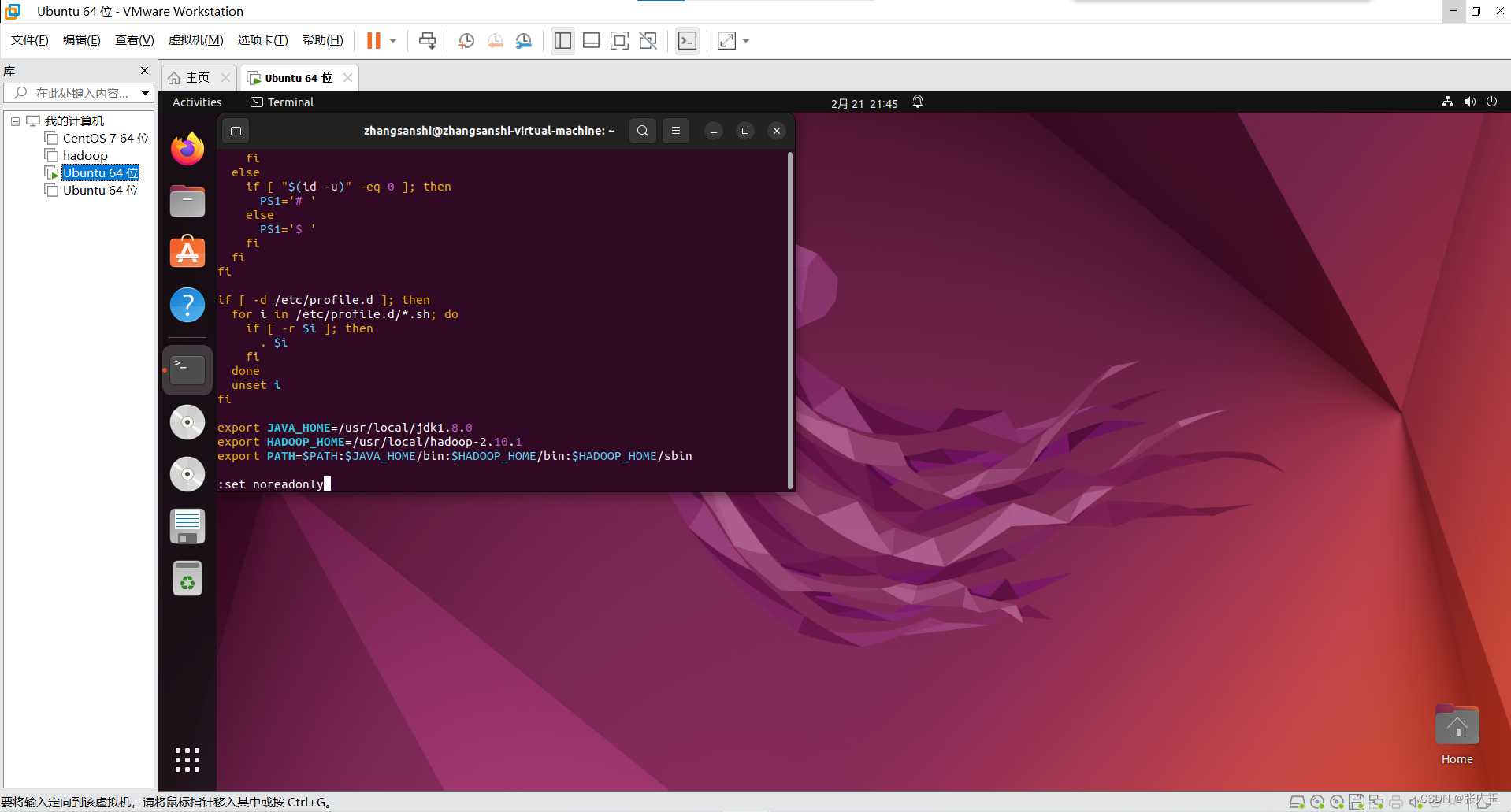
先输入
:set noreadonly
在按Esc 在输入
:wq更新环境变量
$ source /etc/profile测试是否配置成功
测试Hadoop是否安装完成
$ hadoop version
测试Java是否安装完成
$ java -version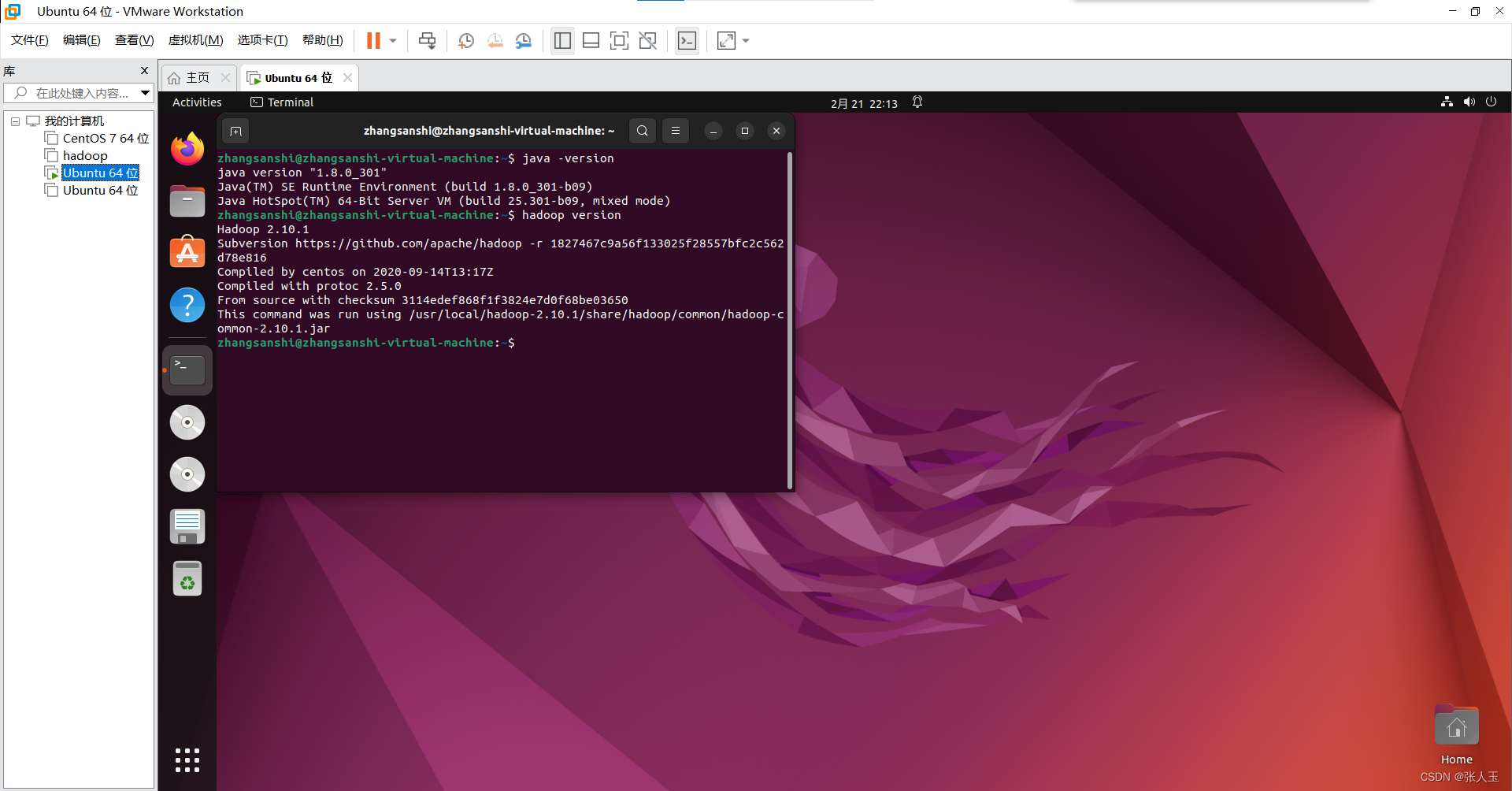
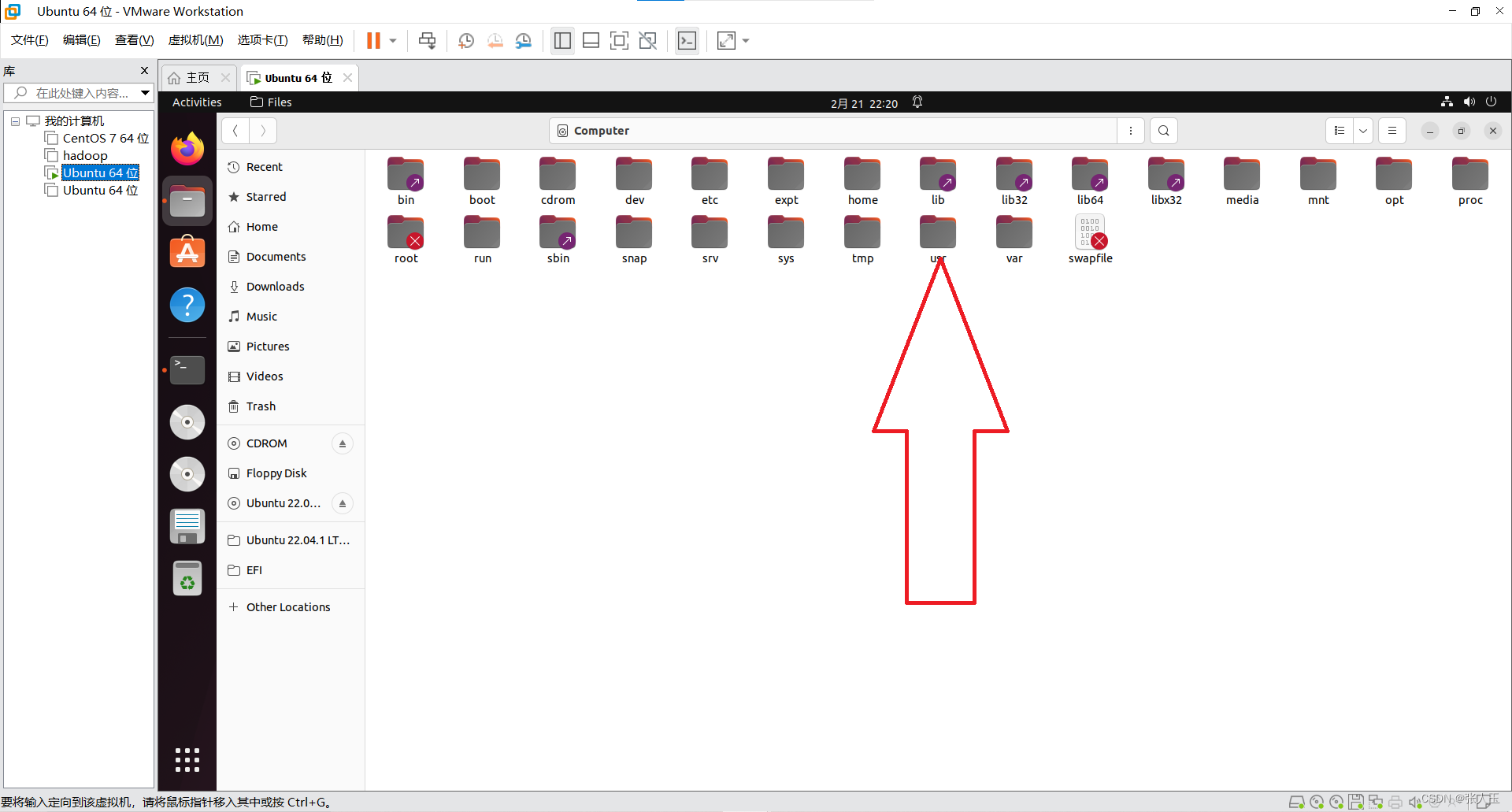
配置Hadoop
$ sudo mkdir -p /usr/data/hadoop/tmpHadoop 默认启动的时候使用的是系统下的 /temp 目录下,但 是在每一次重启的时候系统都会将其自动清空 ,如果没有临 时的储存目录有可能会在下一次启动 Hadoop 的时候出现 问题。
$ sudo chown sillin:silin -R /usr/data
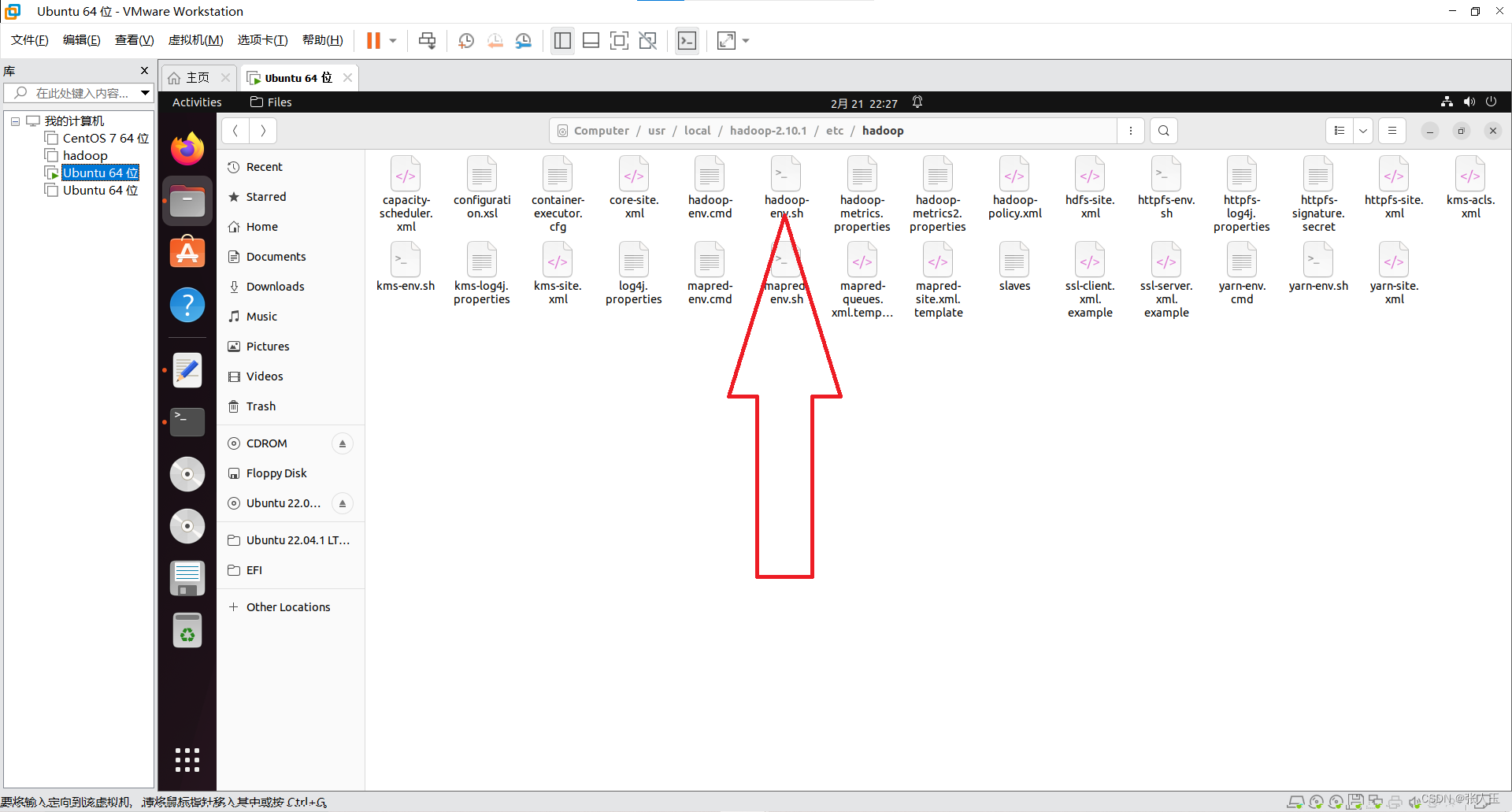
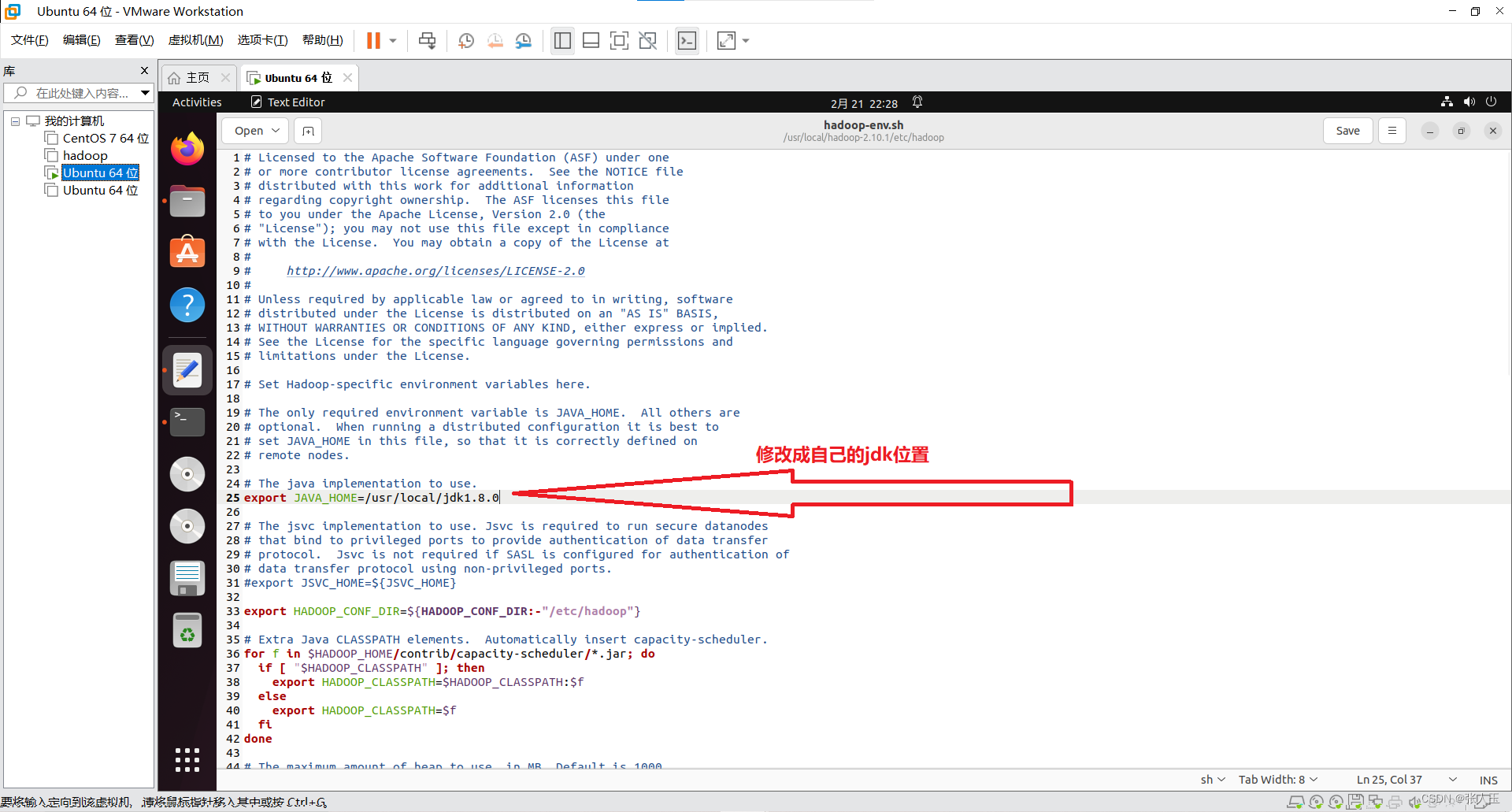
(这里以本机用户名 silin 为例。) 进入 hadoop 安装文件下的/etc/hadoop/文件夹中 编辑 hadoop-env.sh 脚本文件
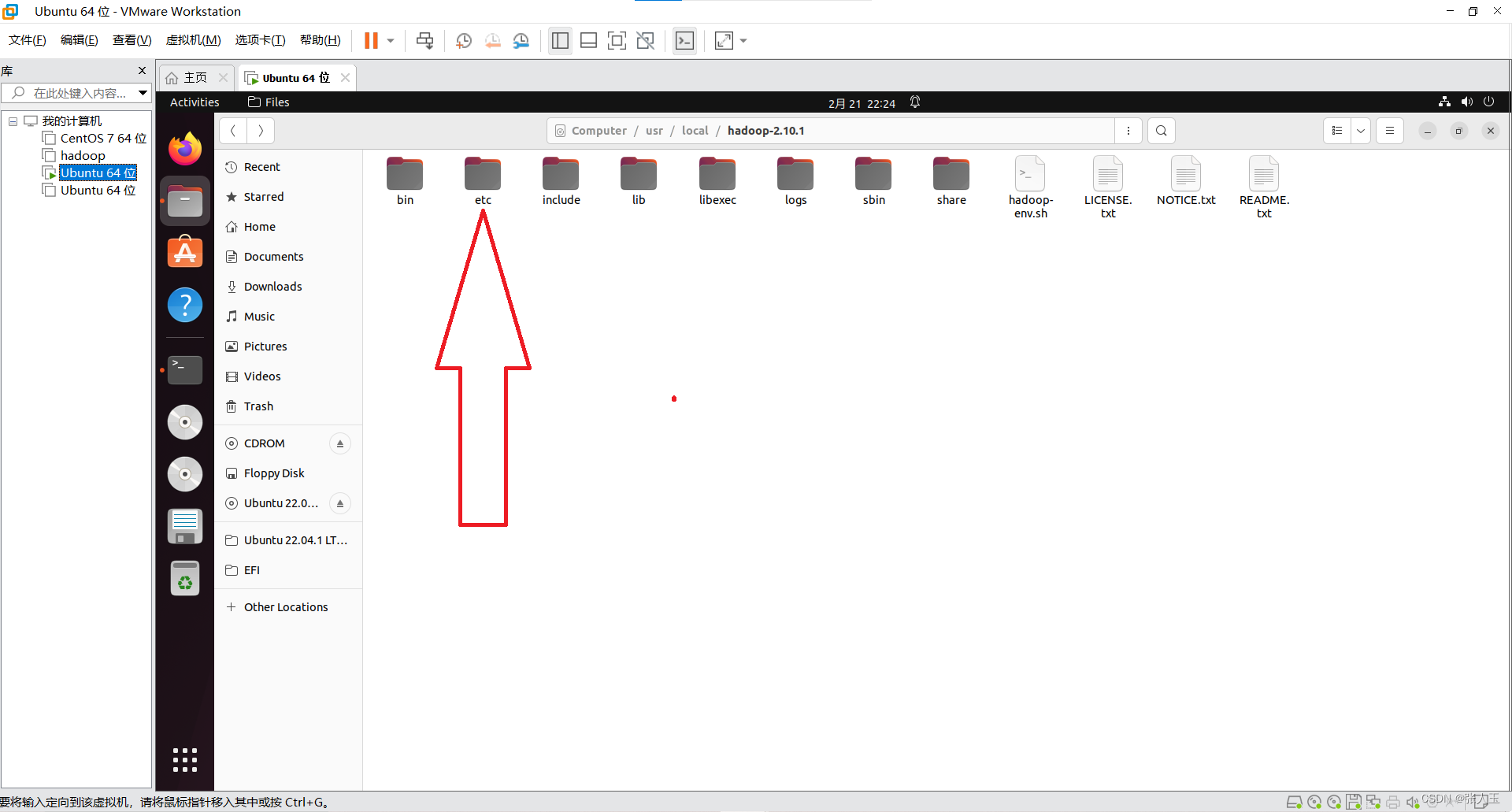
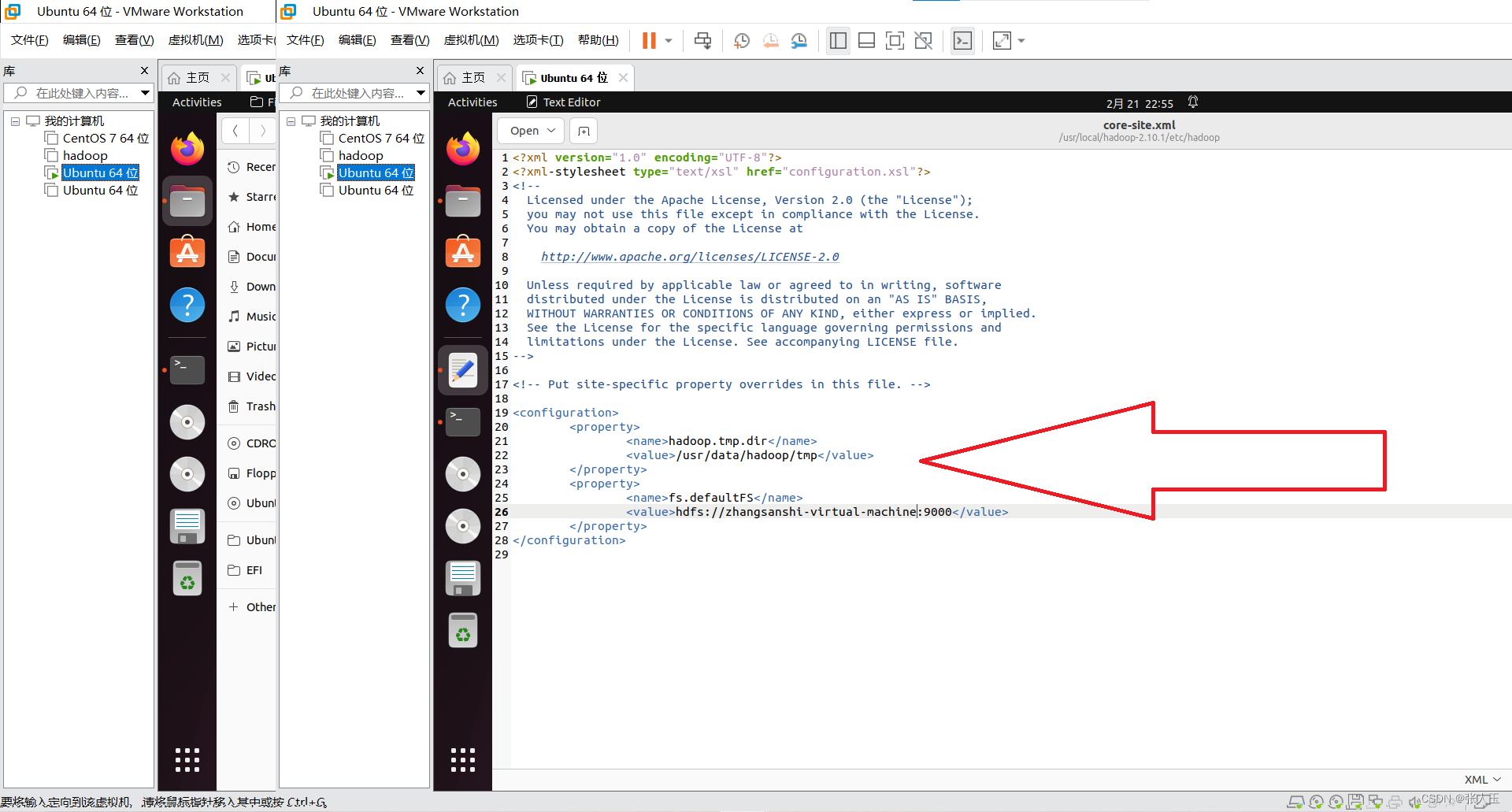
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/data/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://zhangjinlei:9000</value>
</property>
</configuration>

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
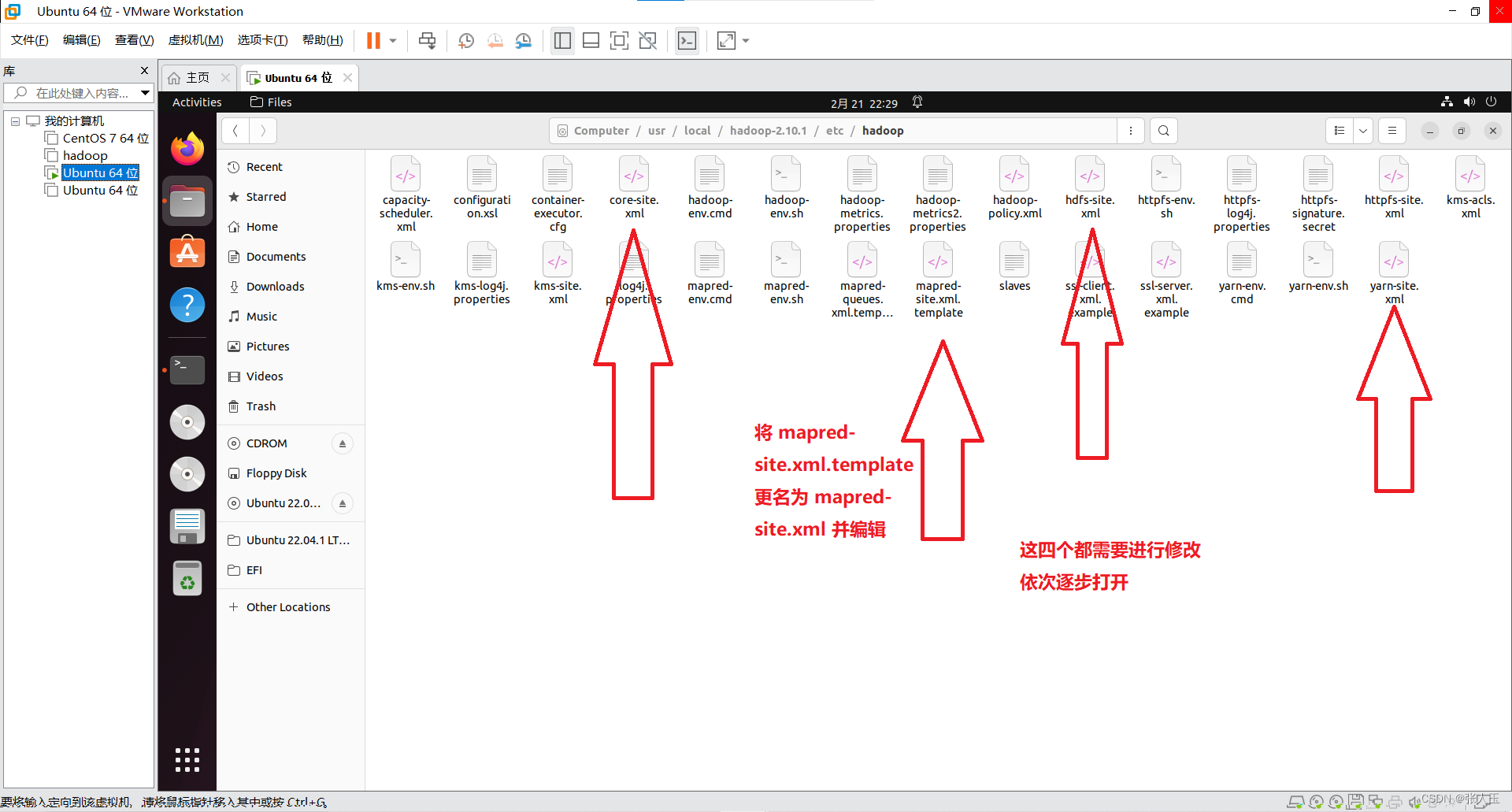
</configuration>将 mapred-site.xml.template 更名为 mapred-site.xml 并编辑
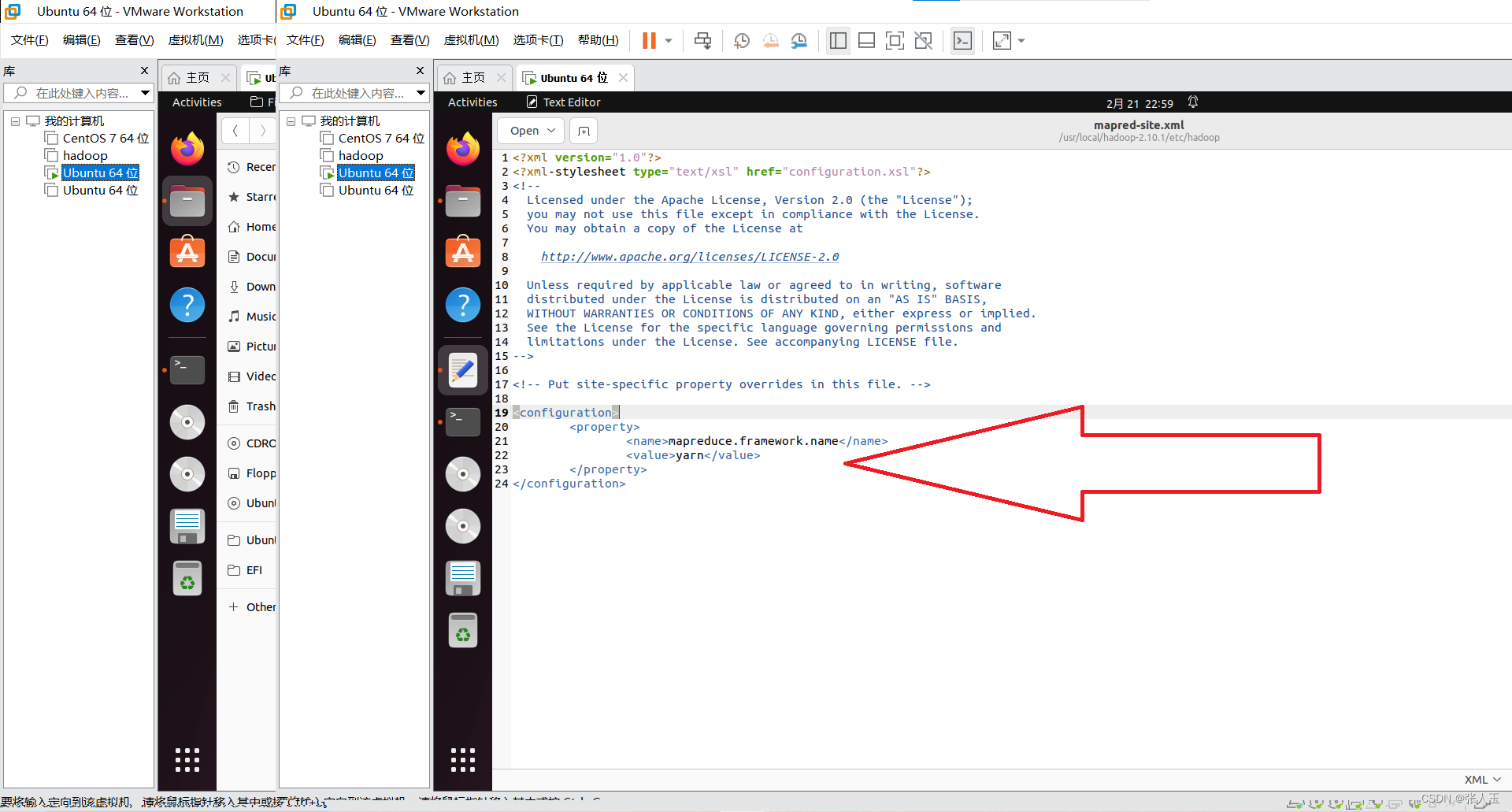
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>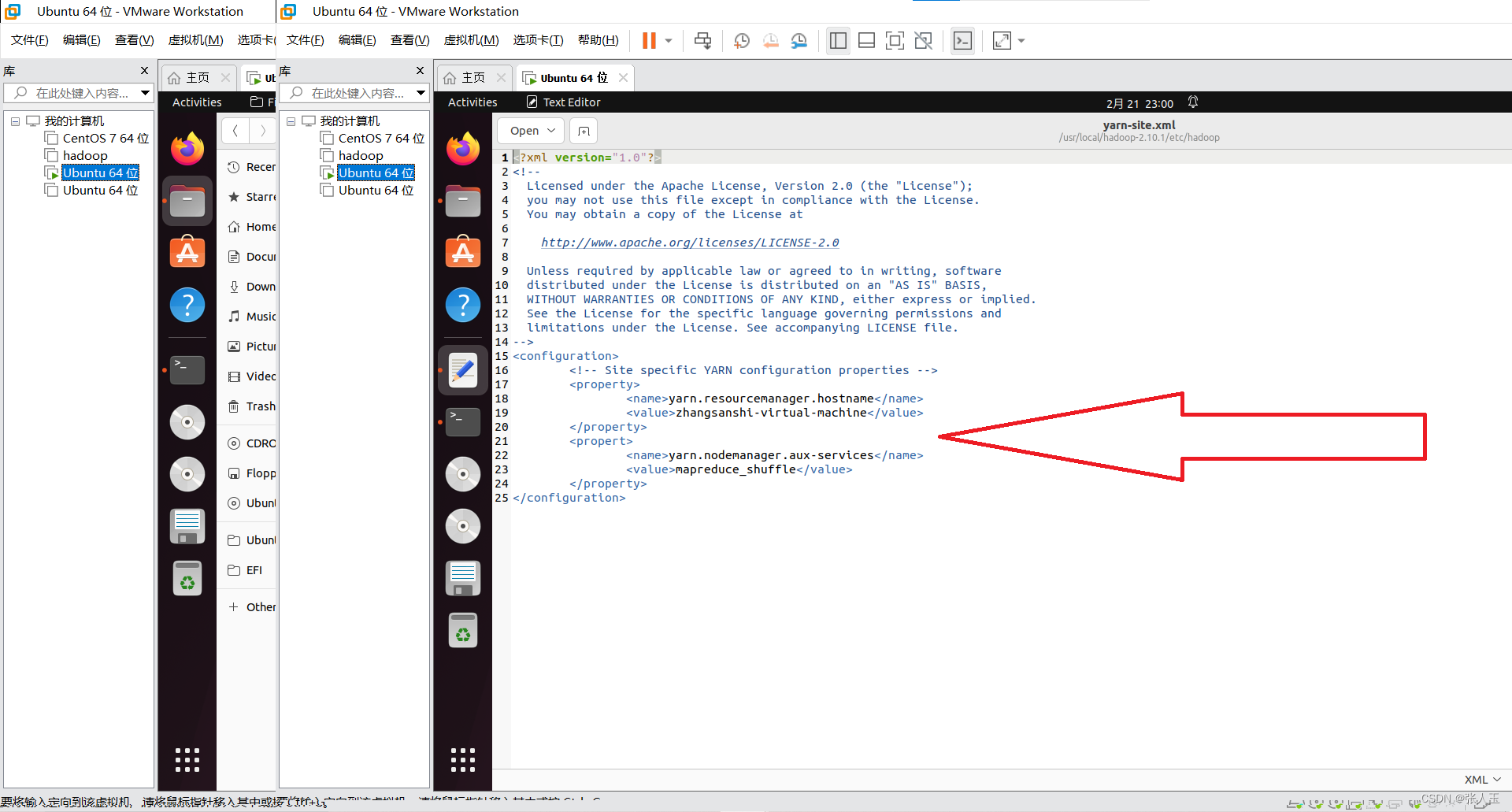
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zhangsanshi-virtual-machine</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>设置ssh免密登录
$ sudo apt-get install openssh-server$ systemctl enable ssh.service
$ service sshd start
$ ssh-keygen -t rsa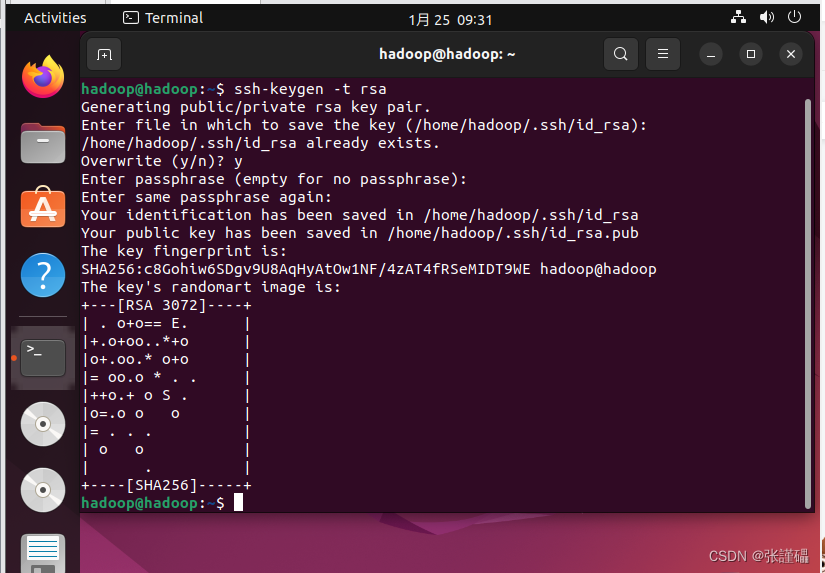
$ ssh-copy-id -i ~/.ssh/id_rsa.pub zhangsanshi
$ ssh-copy-id -i ~/.ssh/id_rsa.pub 自己的用户名
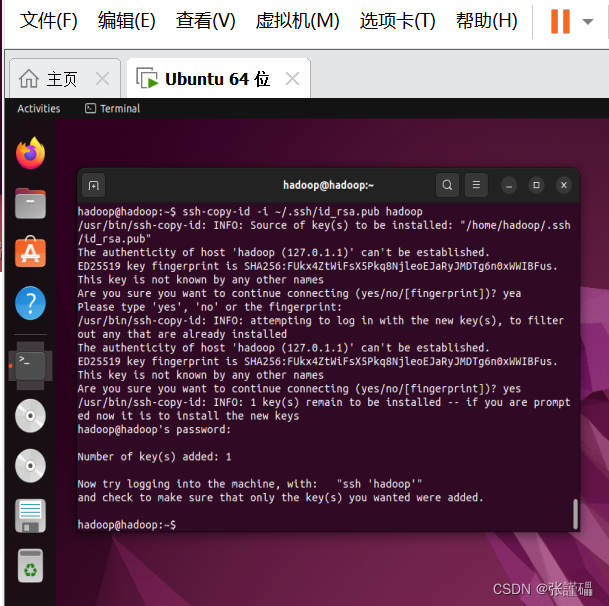
$ ssh zhangsanshi$ hdfs namenode -format
启动
$ start-dfs.sh
$ start-yarn.sh
检验
$ jps
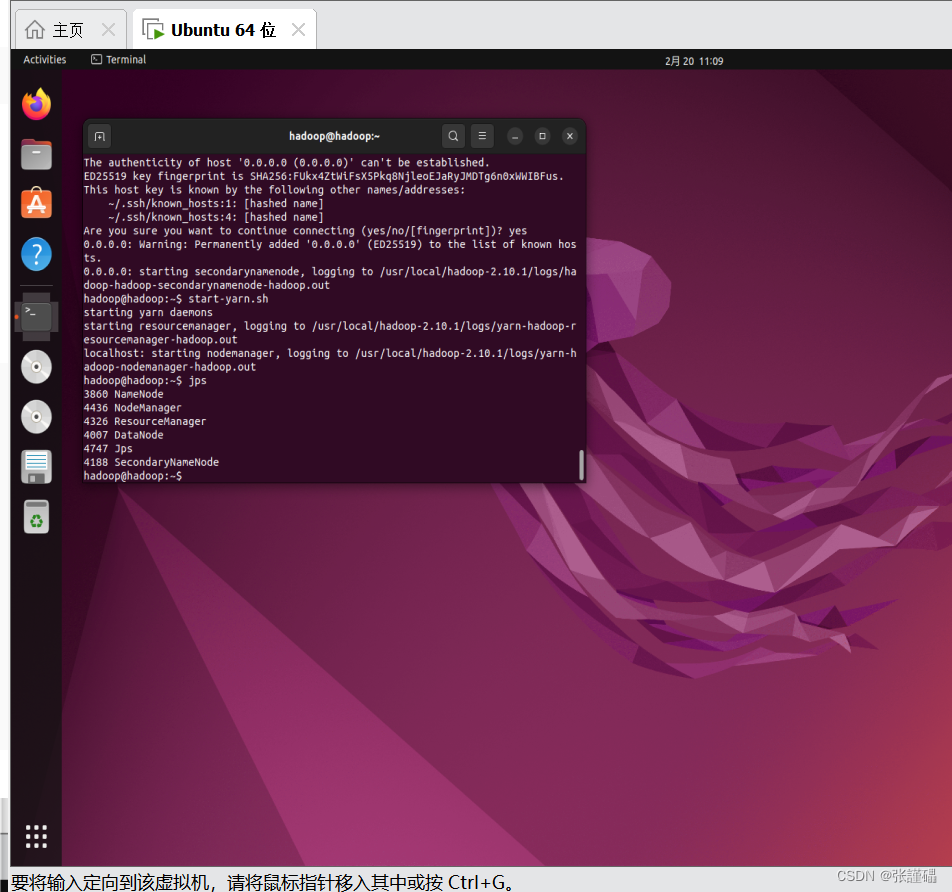
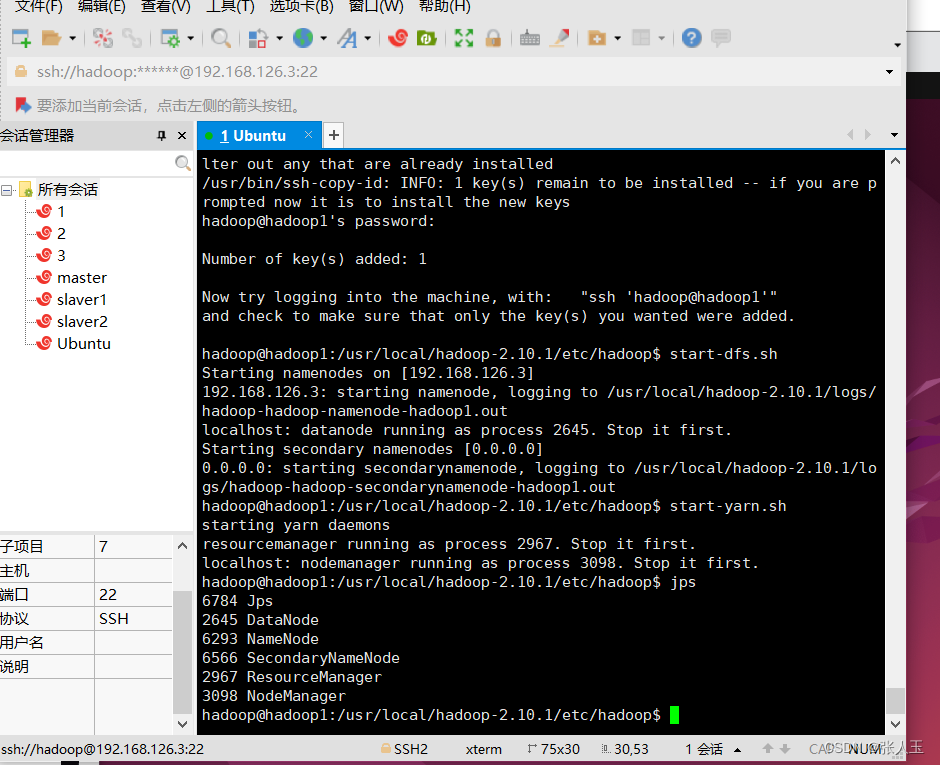
$ tar -zxvf eclipse-java-2021-09-R-linux-gtk-x86_64.tar.gz
安装
$ sudo mv eclipse/ /usr/local/
启动
先输入
$ cd /usr/local/eclipse/
在输入
$ ./eclipse

















 3568
3568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











