









首先要进行准备工作
需要准备虚拟机
进入官网下载
Windows 虚拟机 | Workstation Pro | VMware | CN

准备镜像源文件

准备jdk和Hadoop包
jdk的包
进入官网
https://www.oracle.com/java/technologies/downloads/#java8-linux
Hadoop镜像文件
清华大学管网:
https://mirrors.tuna.tsinghua.edu.cn/apac he/hadoop/common/
Xshell
进入官网下载
Xftp
进入官网下载
XFTP - NetSarang Website (xshell.com)
这里要连接Xshell去传输文件
连接Xshell
说明:需要提前先安装好 Xshell 和 Xftp

输入之后,可能中间会中断一次,不要担心,按enter继续就可以了








将
jdk的包(Linux版)
![]()
Hadoop的镜像文件(Hadoop的包)
![]()
传输过去
这里我以 Ubuntu的连接为例,
需要下载的资源在我的博客的资源包里面也有,可以直接下载
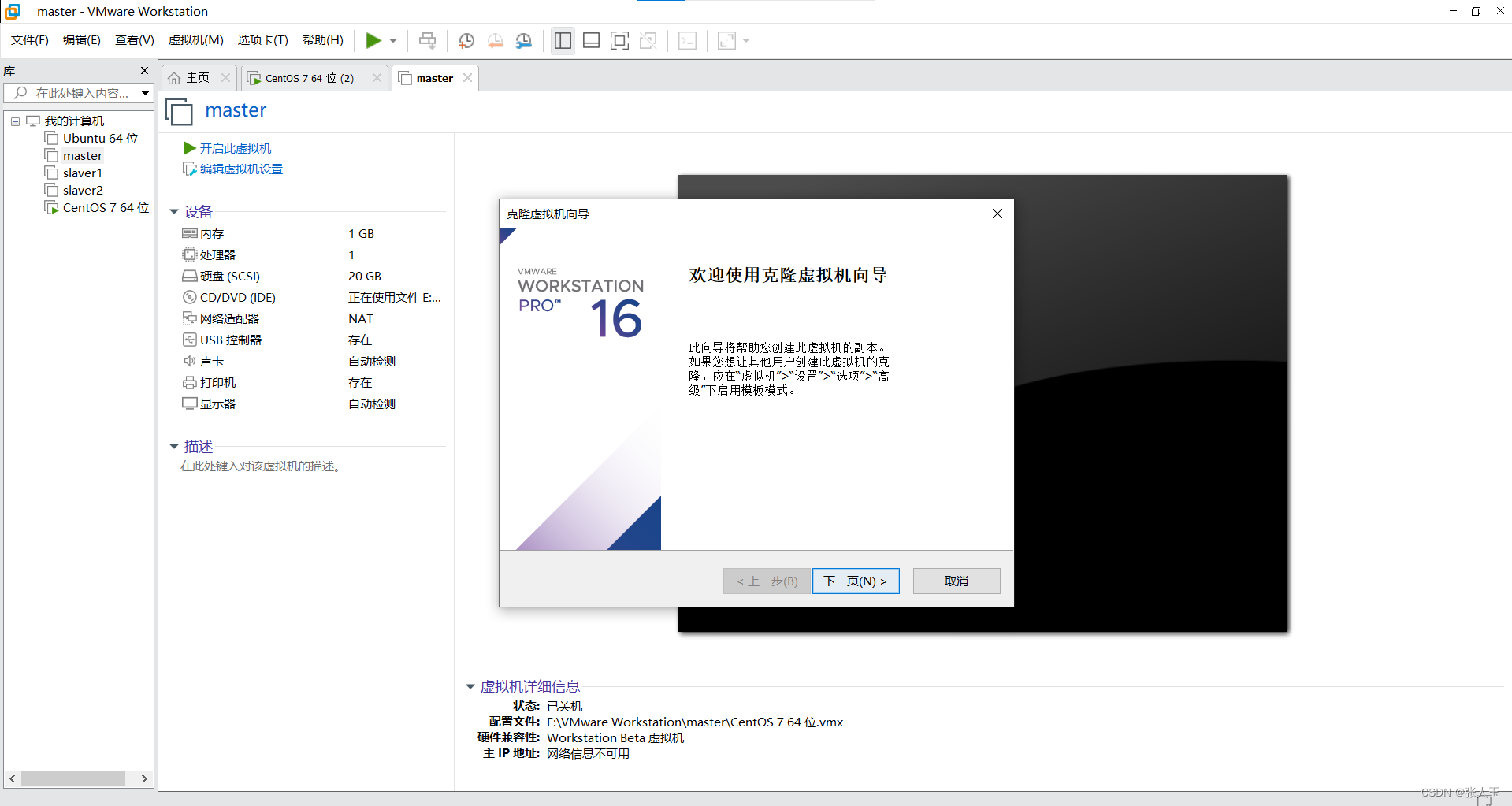
准备工作之后创建虚拟机















然后就是等待,进程完成,需要等一会,不要着急

完成之后重新启动
安装Hadoop需要设置三个节点,这里我们把这三个节点命名为master,slave1,slave2
启动之后输入刚才的用户名

如果刚才的的用户名是hadoop就不用在建一个了,不然的话还要在建立一个用户名
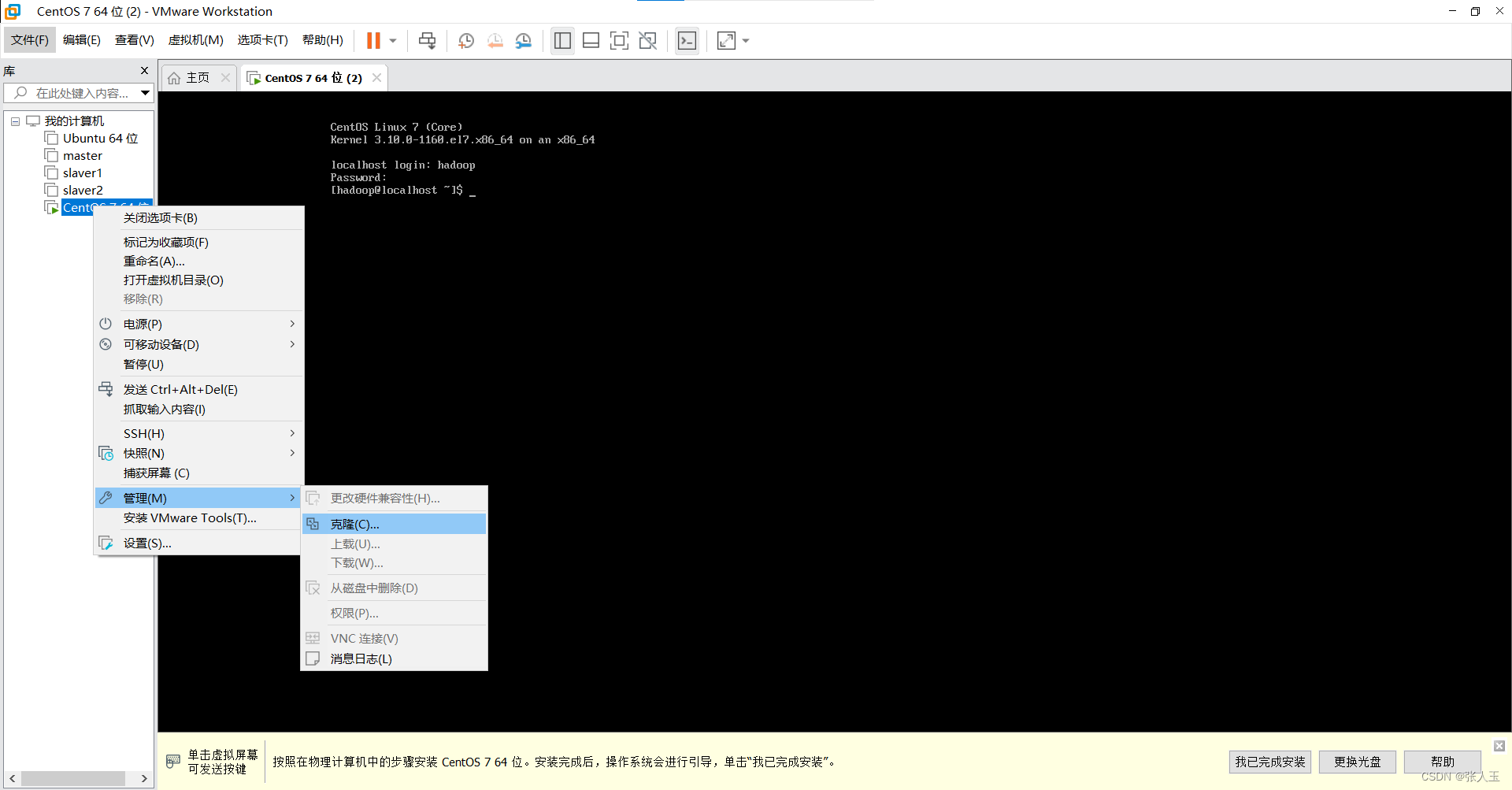



su - //切换root用户vi /etc/hostname
创建一个新用户
adduser hadooppasswd hadoopusermod -a -G hadoop hadoop
查看是否成功
cat /etc/group
切换到hadoop用户
su hadoop
作为开头输入指令,会出现如下提示,告知当前用户不在允许使用超级权限的文件内。
su -
vi /etc/sudoers
exit

4. 关闭防火墙(3个虚拟机都设置)
sudo firewall-cmd --state 
sudo systemctl stop firewalld需要禁止防火墙自动启动(永久关闭)
sudo systemctl disable firewalld 
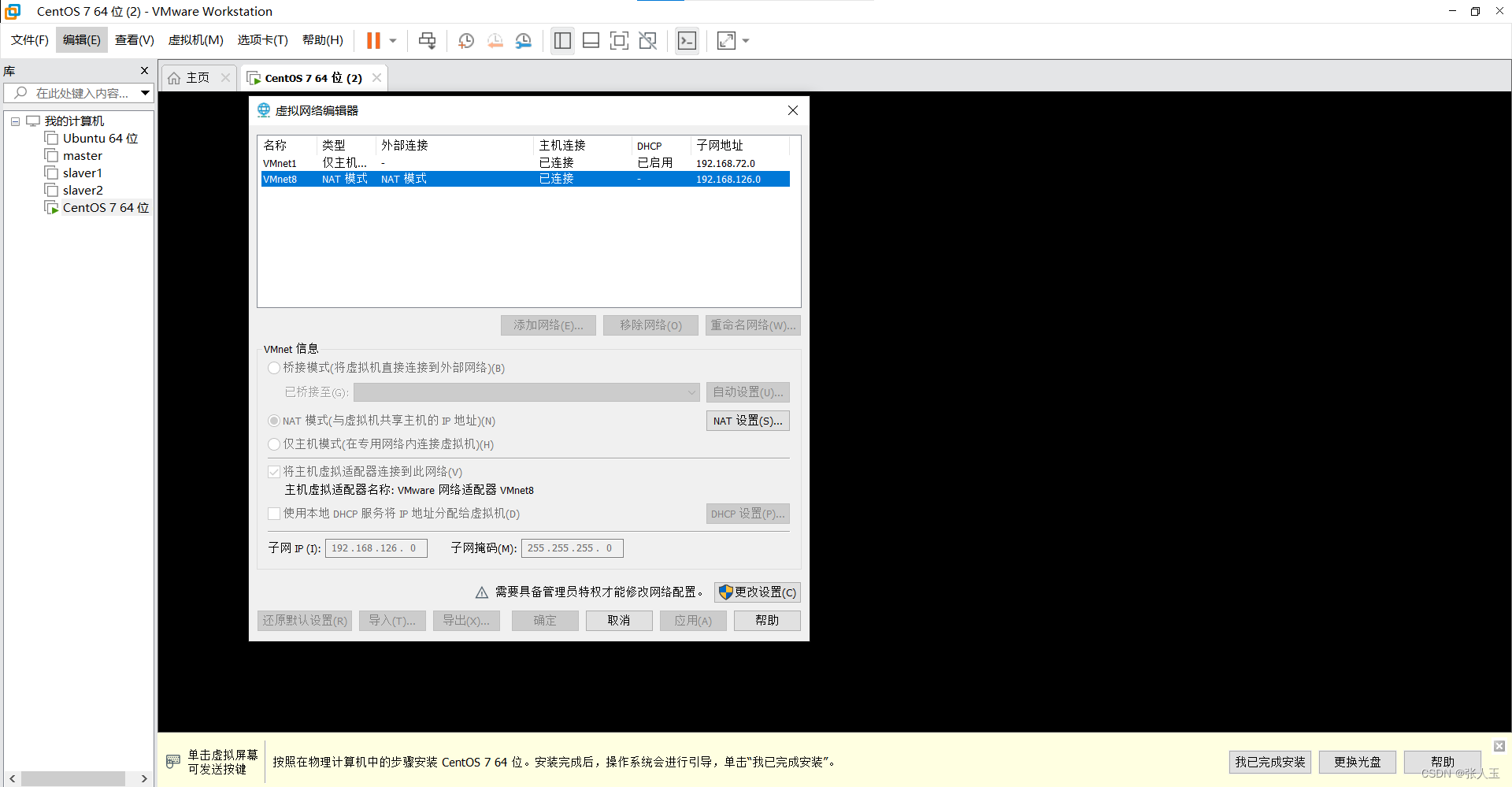
(5)设置IP地址(3个虚拟机都设置)
注意:网段必须与VMnet8子网IP的网段保持一致,网段中xxx.xxx.xxx.1和xxx.xxx.xxx.2(网关(GATEWAY))这两个地址不能使用。例:本机的VMnet8网段为192.168.126.0,则192.168.126.1和192.168.126.2不能使用。可选的IP地址范围为:192.168.126.3-192.168.126.255。
IP地址分配计划
master 192.168.126.3slave1 192.168.126.4slave2 192.168.126.5
修改网络配置文件
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33 
(修改参数:)
BOOTPROTO=static
ONBOOT=yes
追加参数:
IPADDR=192.168.126.3
NETMASK=255.255.255.0
GATEWAY=192.168.126.2 
重启网络服务
sudo systemctl restart network.service 
查看IP地址
ip addr show

6)设置每台主机的hostname到IP的映射关系3个虚拟机都设置)
sudo vi /etc/hosts(在配置文件中追加3行
192.168.126.3 master
192.168.126.4 slave1
192.168.126.5 slave2 
测试hostname是否可用
ping master终止按钮
ctrl c 
ssh-keygen -t rsa 
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@master
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave1
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave2


3)测试免密登录
ssh master输入代码
jdk-8u301-linux-x64.tar.gz 是文件名,要改成自己的文件名
tar -zxvf jdk-8u301-linux-x64.tar.gz
sudo mv jdk1.8.0_301/ /usr/local/jdk1.8.0
sudo vi /etc/profile.d/java.sh 
JAVA_HOME=/usr/local/jdk1.8.0
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH更新环境变量
source /etc/profile
测试是否配置成功
java -version 
输入代码
hadoop-2.10.1.tar.gz 是文件名,要改成自己的文件名
tar -zxvf hadoop-2.10.1.tar.gz
sudo mv hadoop-2.10.1 /usr/local/sudo vi /etc/profile.d/hadoop.shHADOOP_HOME=/usr/local/hadoop-2.10.1
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_HOME PATH
更新环境变量
source /etc/profile测试是否配置成功
hadoop version

sudo mkdir -p /usr/data/hadoop/tmpHadoop默认将运行时的临时文件存储在根目录下的/tmp 文件中,而此文件夹在重启后会被自动清空,这会导致一些问题的出现。因此,新建一个专门用来存放hadoop临时文件的目录。
sudo chown hadoop:hadoop -R /usr/data
cd /usr/local/hadoop-2.10.1/etc/hadoopvi hadoop-env.sh将${JAVA_HOME}改为jdk的实际安装路径

配置core-site.xml配置文件
vi core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/data/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostname:9000</value>
</property>
</configuration>
配置hdfs-site.xml的配置文件
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>将mapred-site.xml.template更名为mapred-site.xml并编辑
cp mapred-site.xml.template mapred-site.xmlvi mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>配置yarn-site.xml
vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hostname</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>配置slaves文件(指定从节点)
vi slaves (5)格式化namenode
hdfs namenode -formatstart-dfs.sh
start-yarn.shjpsmaster

slave1

slave2

最后
致谢
王老师
没有老师的帮助
我无法安装成功
参考链接:

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











