






数据规范化是数据分析中的一个重要步骤,其目的在于确保数据的一致性和可比性,提高数据质量和分析结果的准确性。以下是一些数据规范化的常见方法和技术:
- 数据清洗:此步骤主要清除数据中的重复项、空格、格式错误等,确保数据的准确性和完整性。
- 数据转换:数据转换涉及将不同格式或单位的数据统一化,如转换日期格式、货币单位或度量单位,以便进行更有效的比较和分析。
- 数据规范化:这一步主要是将文本数据转换为统一的术语和格式。例如,设定规则、使用词典或将数据转换为特定的数据格式,以确保数据的一致性和可读性。
- 数据映射:当处理来自不同数据源的数据时,数据映射特别有用。它将不同数据源的数据映射到一个标准化的模板中,确保数据的一致性和可比性。
- 数据匹配:这一步骤主要是将同一实体的不同表述进行匹配。例如,在处理个人信息时,可能会将“小李”和“李小”这样的不同姓名表述匹配为同一实体。
- 数据验证:验证数据是否符合预设的规则或标准,确保数据的准确性和有效性。
在实际应用中,数据规范化有多种方法,例如Min-max规范化、Z-Score规范化以及小数定标规范化等。Min-max规范化是将原始数据投射到指定的空间[min,max],通过公式新数值 = (原数值-极小值)/ (极大值 - 极小值) 进行计算。Z-Score规范化则是将原始数据转换为正态分布的形式,使得结果更易于比较,其公式为新数值 = (原数值 - 均值)/ 标准差。而小数定标规范化则是通过移动小数点的位置来进行规范化,具体移动位数取决于数据取值的最大绝对值。
除了提高数据质量和一致性,数据规范化还有助于提高数据的准确性和有效性,使得不同来源的数据可以进行更好的比较和分析。同时,它也有助于确保数据的安全和隐私保护,降低数据泄露和滥用的风险。此外,数据规范化还是数据治理和管理的基础,为组织提供了更可靠的数据支持,有助于做出更明智的决策。
在数据库设计中,规范化同样是一个关键步骤。它通过消除冗余数据、降低数据的插入、更新和删除异常,使得数据库中的数据具有最小冗余、最高一致性和完整性。这有助于优化数据库的性能和安全性,提高数据的响应速度和吞吐量。
总的来说,数据规范化是确保数据质量、提高数据分析效率、保障数据安全以及优化数据库设计的重要手段。对于任何组织来说,实施数据规范化都是提升数据管理水平和竞争力的重要途径。
极大值极小值规划
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
# 假设你的数据保存在一个名为 '各站点各时刻进出站客流数据.xlsx' 的 Excel 文件中
data = pd.read_excel('各站点各时刻进出站客流数据.xlsx')
# 取前几行数据,如果只需要一部分数据进行分析的话
data = data.head(20)
# 将'日期'和'时刻'列合并为一个时间戳
data['时间戳'] = pd.to_datetime(data['日期']) + pd.to_timedelta(data['时刻'], unit='H')
# 设置 '时间戳' 列为 DataFrame 的索引,方便后续绘图
data.set_index('时间戳', inplace=True)
# 删除原始的'日期'和'时刻'列
data.drop(['日期', '时刻'], axis=1, inplace=True)
# 数据规范化 - 使用极大值和极小值进行规范化
def min_max_scaler(data_series):
min_val = data_series.min()
max_val = data_series.max()
return (data_series - min_val) / (max_val - min_val)
# 应用规范化函数到'进站人数'和'出站人数'列
data['进站人数'] = min_max_scaler(data['进站人数'])
data['出站人数'] = min_max_scaler(data['出站人数'])
# 绘制进站人数的折线图
plt.figure(figsize=(12, 6))
plt.plot(data.index, data['进站人数'], label='进站人数', marker='o')
# 绘制出站人数的折线图
plt.plot(data.index, data['出站人数'], label='出站人数', marker='o')
# 设置图表标题和轴标签
plt.title('站点编号155随时间变化的进出站人数折线图')
plt.xlabel('时间')
plt.ylabel('规范化后的进出站人数')
# 显示图例
plt.legend()
# 格式化x轴时间戳显示
plt.gca().xaxis.set_major_formatter(DateFormatter('%Y-%m-%d %H:%M'))
# 设置 Matplotlib 的参数,以使用支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 显示图表
plt.show() 
零一规划
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.dates import DateFormatter
# 假设你的数据保存在一个名为 '各站点各时刻进出站客流数据.xlsx' 的 Excel 文件中
data = pd.read_excel('各站点各时刻进出站客流数据.xlsx')
# 取前几行数据,如果只需要一部分数据进行分析的话
data = data.head(20)
# 将'日期'和'时刻'列合并为一个时间戳
data['时间戳'] = pd.to_datetime(data['日期']) + pd.to_timedelta(data['时刻'], unit='H')
# 设置 '时间戳' 列为 DataFrame 的索引
data.set_index('时间戳', inplace=True)
# 删除原始的'日期'和'时刻'列
data.drop(['日期', '时刻'], axis=1, inplace=True)
# 零一归化函数
def normalize(data_series):
min_val = data_series.min()
range_val = data_series.max() - min_val
return (data_series - min_val) / range_val
# 应用零一归化到'进站人数'和'出站人数'列
data['进站人数'] = normalize(data['进站人数'])
data['出站人数'] = normalize(data['出站人数'])
# 绘制进站人数的折线图
plt.figure(figsize=(12, 6))
plt.plot(data.index, data['进站人数'], label='进站人数', marker='o')
# 绘制出站人数的折线图
plt.plot(data.index, data['出站人数'], label='出站人数', marker='o')
# 设置图表标题和轴标签
plt.title('站点编号155随时间变化的进出站人数折线图(零一归化)')
plt.xlabel('时间')
plt.ylabel('零一归化后的进出站人数')
# 显示图例
plt.legend()
# 格式化x轴时间戳显示
plt.gca().xaxis.set_major_formatter(DateFormatter('%Y-%m-%d %H:%M'))
# 设置 Matplotlib 的参数,以使用支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 显示图表
plt.show()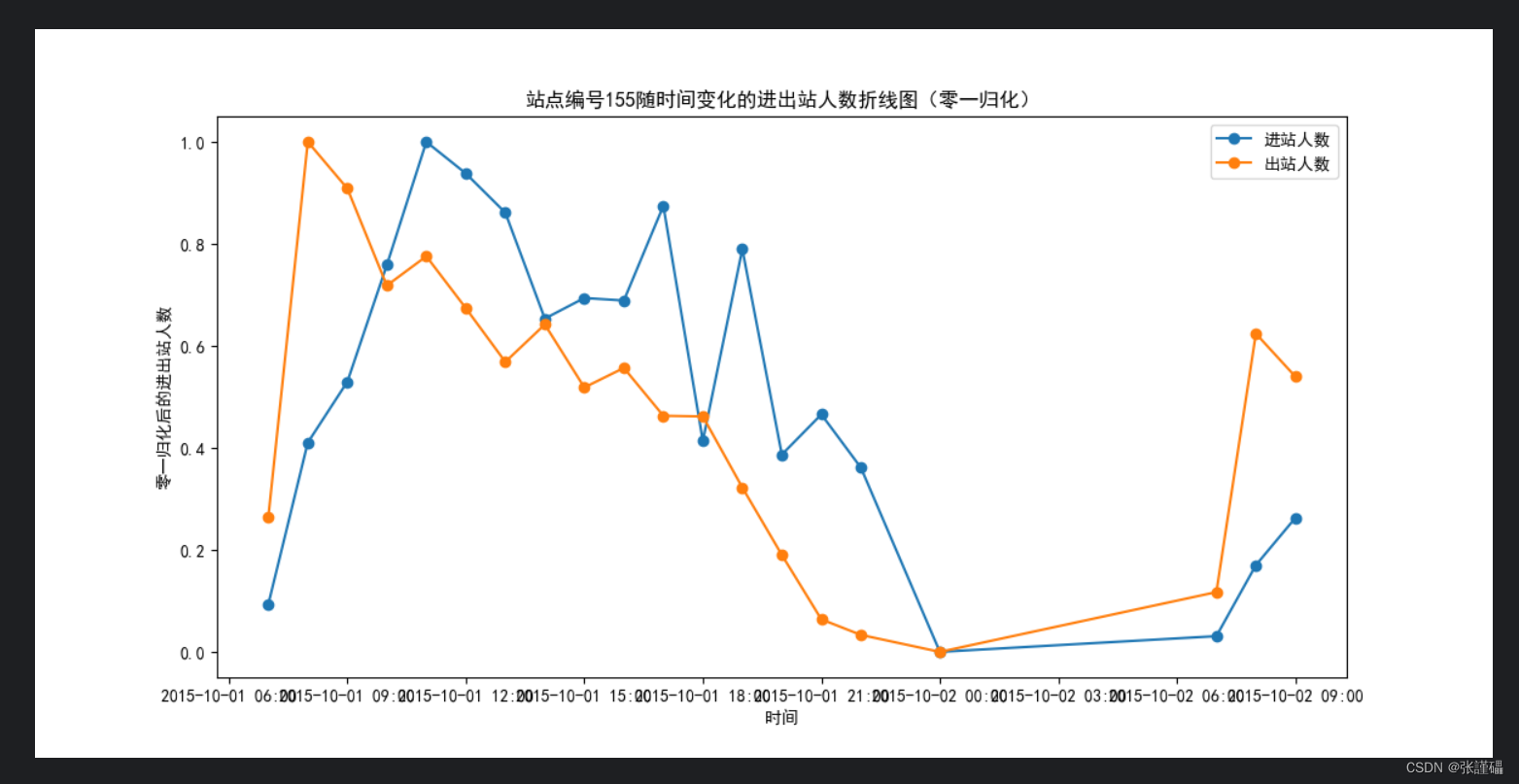
不规划
import pandas as pd
import matplotlib.pyplot as plt
# 假设您的数据保存在一个名为 '各站点各时刻进出站客流数据.xlsx' 的 Excel 文件中
data = pd.read_excel('各站点各时刻进出站客流数据.xlsx')
data = data.head(20)
# 选择需要进行归一化的列
columns_to_normalize = ['进站人数', '出站人数']
# 绘制归一化后的进站人数和出站人数的折线图
plt.figure(figsize=(12, 6))
# 绘制进站人数的折线图
plt.plot(data['时刻'], data['进站人数'], label='进站人数 (归一化后)', marker='o')
# 绘制出站人数的折线图
plt.plot(data['时刻'], data['出站人数'], label='出站人数 (归一化后)', marker='o')
# 设置图表标题和轴标签
plt.title('站点随时间变化的进出站人数折线图(归一化后)')
plt.xlabel('时间')
plt.ylabel('归一化后的进出站人数')
# 显示图例
plt.legend()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 正确显示负号
# 显示图表
plt.show()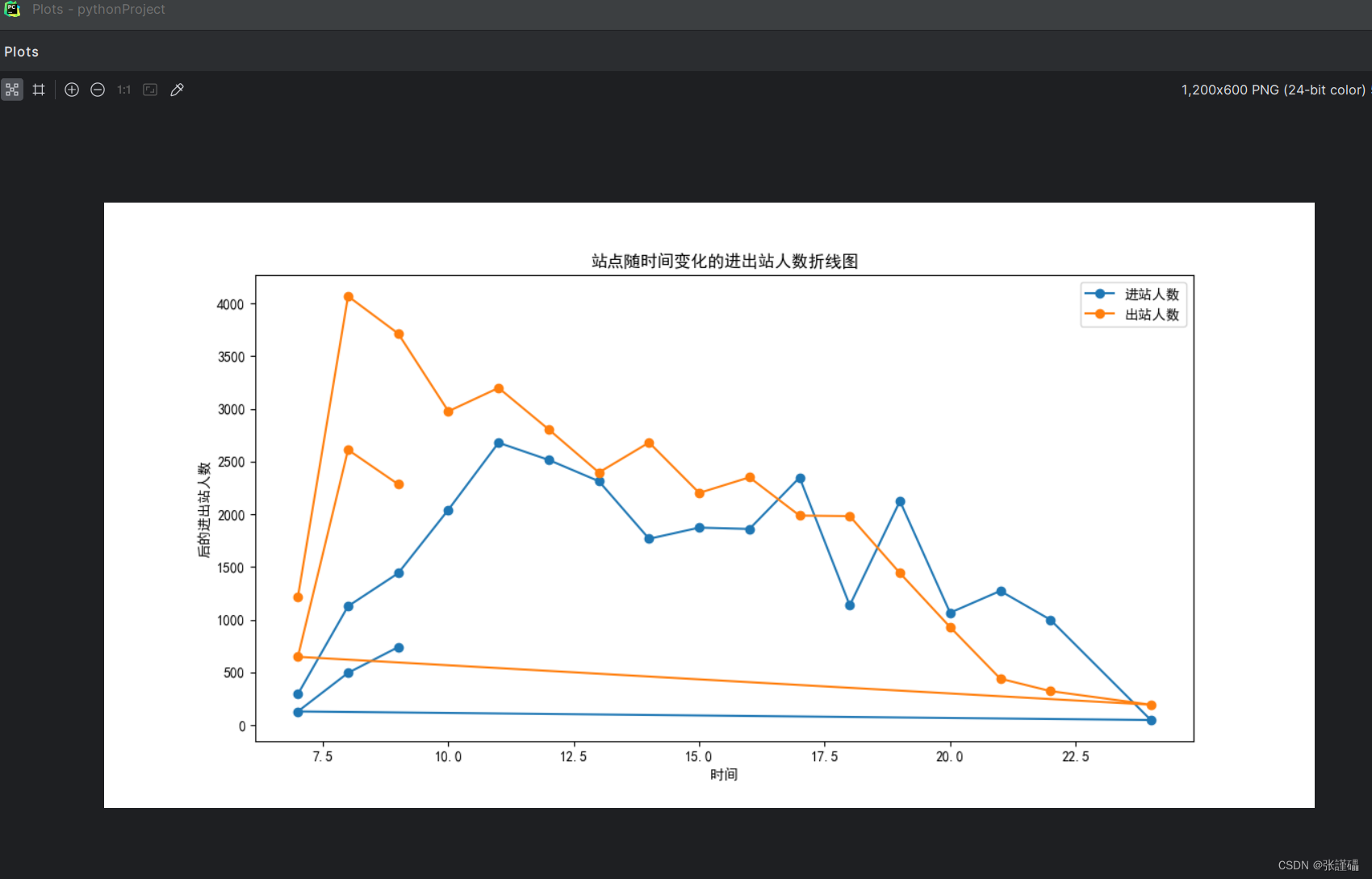
数据集
| 站点编号 | 日期 | 时刻 | 进站人数 | 出站人数 |
| 155 | 2015-10-01 | 7 | 294 | 1215 |
| 155 | 2015-10-01 | 8 | 1128 | 4067 |
| 155 | 2015-10-01 | 9 | 1441 | 3713 |
| 155 | 2015-10-01 | 10 | 2043 | 2976 |
| 155 | 2015-10-01 | 11 | 2678 | 3198 |
| 155 | 2015-10-01 | 12 | 2515 | 2804 |
| 155 | 2015-10-01 | 13 | 2313 | 2396 |
| 155 | 2015-10-01 | 14 | 1767 | 2680 |
| 155 | 2015-10-01 | 15 | 1873 | 2202 |
| 155 | 2015-10-01 | 16 | 1860 | 2350 |
| 155 | 2015-10-01 | 17 | 2348 | 1987 |
| 155 | 2015-10-01 | 18 | 1136 | 1982 |
| 155 | 2015-10-01 | 19 | 2125 | 1442 |
| 155 | 2015-10-01 | 20 | 1066 | 930 |
| 155 | 2015-10-01 | 21 | 1273 | 441 |
| 155 | 2015-10-01 | 22 | 999 | 323 |
| 155 | 2015-10-01 | 24 | 49 | 194 |
| 155 | 2015-10-02 | 7 | 130 | 648 |
| 155 | 2015-10-02 | 8 | 496 | 2611 |
| 155 | 2015-10-02 | 9 | 740 | 2284 |
| 155 | 2015-10-02 | 10 | 1537 | 1893 |
| 155 | 2015-10-02 | 11 | 1942 | 2232 |
| 155 | 2015-10-02 | 12 | 2483 | 1866 |
| 155 | 2015-10-02 | 13 | 1554 | 1607 |
| 155 | 2015-10-02 | 14 | 1517 | 1826 |
| 155 | 2015-10-02 | 15 | 1526 | 1784 |
| 155 | 2015-10-02 | 16 | 1539 | 1883 |
| 155 | 2015-10-02 | 17 | 2044 | 1784 |
| 155 | 2015-10-02 | 18 | 1400 | 1668 |
| 155 | 2015-10-02 | 19 | 2080 | 1292 |
| 155 | 2015-10-02 | 20 | 949 | 924 |
| 155 | 2015-10-02 | 21 | 1278 | 427 |
| 155 | 2015-10-02 | 22 | 660 | 239 |
| 155 | 2015-10-02 | 23 | 10 | 127 |
| 155 | 2015-10-03 | 7 | 118 | 374 |
| 155 | 2015-10-03 | 8 | 417 | 1363 |
| 155 | 2015-10-03 | 9 | 568 | 1695 |
| 155 | 2015-10-03 | 10 | 1448 | 1781 |
| 155 | 2015-10-03 | 11 | 2259 | 1956 |
| 155 | 2015-10-03 | 12 | 2377 | 1724 |
| 155 | 2015-10-03 | 13 | 1692 | 1196 |
| 155 | 2015-10-03 | 14 | 1582 | 1488 |
| 155 | 2015-10-03 | 15 | 1309 | 1550 |
| 155 | 2015-10-03 | 16 | 1543 | 1685 |
| 155 | 2015-10-03 | 17 | 1948 | 1605 |
| 155 | 2015-10-03 | 18 | 1462 | 1683 |
| 155 | 2015-10-03 | 19 | 2218 | 1339 |
| 155 | 2015-10-03 | 20 | 1409 | 731 |
| 155 | 2015-10-03 | 21 | 1347 | 360 |
| 155 | 2015-10-03 | 22 | 541 | 209 |
| 155 | 2015-10-03 | 24 | 17 | 92 |
| 155 | 2015-10-04 | 7 | 122 | 280 |
| 155 | 2015-10-04 | 8 | 402 | 1286 |
| 155 | 2015-10-04 | 9 | 620 | 1684 |
| 155 | 2015-10-04 | 10 | 1447 | 1598 |
| 155 | 2015-10-04 | 11 | 2148 | 1644 |
| 155 | 2015-10-04 | 12 | 2563 | 1529 |
| 155 | 2015-10-04 | 13 | 1581 | 1171 |
| 155 | 2015-10-04 | 14 | 1629 | 1381 |
| 155 | 2015-10-04 | 15 | 1653 | 1580 |
| 155 | 2015-10-04 | 16 | 1690 | 1713 |
| 155 | 2015-10-04 | 17 | 2323 | 1761 |
| 155 | 2015-10-04 | 18 | 1719 | 1774 |
| 155 | 2015-10-04 | 19 | 3006 | 1412 |
| 155 | 2015-10-04 | 20 | 1687 | 781 |
| 155 | 2015-10-04 | 21 | 1410 | 421 |
| 155 | 2015-10-04 | 22 | 868 | 297 |
| 155 | 2015-10-04 | 24 | 62 | 240 |
| 155 | 2015-10-05 | 7 | 123 | 326 |
| 155 | 2015-10-05 | 8 | 420 | 1192 |
| 155 | 2015-10-05 | 9 | 690 | 1750 |
| 155 | 2015-10-05 | 10 | 1182 | 1455 |
| 155 | 2015-10-05 | 11 | 2179 | 1482 |
| 155 | 2015-10-05 | 12 | 2453 | 1491 |
| 155 | 2015-10-05 | 13 | 1635 | 1409 |
| 155 | 2015-10-05 | 14 | 1690 | 1579 |
| 155 | 2015-10-05 | 15 | 1680 | 1652 |
| 155 | 2015-10-05 | 16 | 1758 | 1908 |
| 155 | 2015-10-05 | 17 | 2510 | 1717 |
| 155 | 2015-10-05 | 18 | 1500 | 1856 |
| 155 | 2015-10-05 | 19 | 2754 | 1440 |
| 155 | 2015-10-05 | 20 | 1359 | 761 |
| 155 | 2015-10-05 | 21 | 1437 | 407 |
| 155 | 2015-10-05 | 22 | 947 | 315 |
| 155 | 2015-10-05 | 24 | 111 | 211 |
| 155 | 2015-10-06 | 7 | 97 | 279 |
| 155 | 2015-10-06 | 8 | 467 | 1196 |
| 155 | 2015-10-06 | 9 | 670 | 1763 |
| 155 | 2015-10-06 | 10 | 1307 | 1314 |
| 155 | 2015-10-06 | 11 | 2463 | 1537 |
| 155 | 2015-10-06 | 12 | 2858 | 1568 |
| 155 | 2015-10-06 | 13 | 2110 | 1395 |
| 155 | 2015-10-06 | 14 | 2344 | 1559 |
| 155 | 2015-10-06 | 15 | 2081 | 1634 |
| 155 | 2015-10-06 | 16 | 1917 | 1648 |
| 155 | 2015-10-06 | 17 | 2935 | 1481 |
| 155 | 2015-10-06 | 18 | 1665 | 1469 |
| 155 | 2015-10-06 | 19 | 2862 | 1354 |
| 155 | 2015-10-06 | 20 | 1383 | 920 |
| 155 | 2015-10-06 | 21 | 2423 | 464 |
| 155 | 2015-10-06 | 22 | 1533 | 300 |
| 155 | 2015-10-06 | 24 | 104 | 175 |
| 155 | 2015-10-07 | 7 | 112 | 311 |
| 155 | 2015-10-07 | 8 | 465 | 1296 |
| 155 | 2015-10-07 | 9 | 790 | 1725 |
| 155 | 2015-10-07 | 10 | 1557 | 1385 |
| 155 | 2015-10-07 | 11 | 3121 | 1498 |
| 155 | 2015-10-07 | 12 | 3302 | 1723 |
| 155 | 2015-10-07 | 13 | 3068 | 1739 |
| 155 | 2015-10-07 | 14 | 2810 | 1852 |
| 155 | 2015-10-07 | 15 | 2560 | 1895 |
| 155 | 2015-10-07 | 16 | 2442 | 2063 |
| 155 | 2015-10-07 | 17 | 3932 | 1910 |
| 155 | 2015-10-07 | 18 | 2118 | 1907 |
| 155 | 2015-10-07 | 19 | 3308 | 1583 |
| 155 | 2015-10-07 | 20 | 1530 | 1060 |
| 155 | 2015-10-07 | 21 | 2897 | 602 |
| 155 | 2015-10-07 | 22 | 1389 | 319 |
| 155 | 2015-10-07 | 24 | 144 | 219 |
| 155 | 2015-10-08 | 7 | 169 | 314 |
| 155 | 2015-10-08 | 8 | 600 | 1573 |
| 155 | 2015-10-08 | 9 | 582 | 2452 |
| 155 | 2015-10-08 | 10 | 962 | 1468 |
| 155 | 2015-10-08 | 11 | 1825 | 1201 |
| 155 | 2015-10-08 | 12 | 1305 | 1207 |
| 155 | 2015-10-08 | 13 | 1422 | 1196 |
| 155 | 2015-10-08 | 14 | 1470 | 1532 |
| 155 | 2015-10-08 | 15 | 1424 | 1343 |
| 155 | 2015-10-08 | 16 | 1342 | 1242 |
| 155 | 2015-10-08 | 17 | 2186 | 1096 |
| 155 | 2015-10-08 | 18 | 1298 | 1297 |
| 155 | 2015-10-08 | 19 | 1902 | 1090 |
| 155 | 2015-10-08 | 20 | 1192 | 608 |
| 155 | 2015-10-08 | 21 | 1128 | 362 |
| 155 | 2015-10-08 | 22 | 333 | 274 |
| 155 | 2015-10-08 | 24 | 21 | 197 |
| 155 | 2015-10-09 | 7 | 122 | 222 |
| 155 | 2015-10-09 | 8 | 494 | 1219 |
| 155 | 2015-10-09 | 9 | 534 | 2236 |
| 155 | 2015-10-09 | 10 | 922 | 1394 |
| 155 | 2015-10-09 | 11 | 1814 | 1206 |
| 155 | 2015-10-09 | 12 | 1202 | 1246 |
| 155 | 2015-10-09 | 13 | 1235 | 1071 |
| 155 | 2015-10-09 | 14 | 1281 | 1431 |
| 155 | 2015-10-09 | 15 | 1357 | 1323 |
| 155 | 2015-10-09 | 16 | 1186 | 1340 |
| 155 | 2015-10-09 | 17 | 1750 | 1392 |
| 155 | 2015-10-09 | 18 | 1380 | 1550 |
| 155 | 2015-10-09 | 19 | 2039 | 1307 |
| 155 | 2015-10-09 | 20 | 1080 | 673 |
| 155 | 2015-10-09 | 21 | 829 | 284 |
| 155 | 2015-10-09 | 22 | 323 | 177 |
| 155 | 2015-10-09 | 24 | 13 | 89 |
| 155 | 2015-10-10 | 7 | 106 | 234 |
| 155 | 2015-10-10 | 8 | 463 | 964 |
| 155 | 2015-10-10 | 9 | 519 | 1942 |
| 155 | 2015-10-10 | 10 | 1064 | 1394 |
| 155 | 2015-10-10 | 11 | 1797 | 1256 |
| 155 | 2015-10-10 | 12 | 1413 | 1079 |
| 155 | 2015-10-10 | 13 | 1336 | 1132 |
| 155 | 2015-10-10 | 14 | 1344 | 1320 |
| 155 | 2015-10-10 | 15 | 1312 | 1371 |
| 155 | 2015-10-10 | 16 | 1292 | 1484 |
| 155 | 2015-10-10 | 17 | 1779 | 1466 |
| 155 | 2015-10-10 | 18 | 1325 | 1621 |
| 155 | 2015-10-10 | 19 | 2196 | 1838 |
| 155 | 2015-10-10 | 20 | 1411 | 971 |
| 155 | 2015-10-10 | 21 | 1004 | 379 |
| 155 | 2015-10-10 | 22 | 379 | 239 |
| 155 | 2015-10-10 | 24 | 24 | 133 |
| 155 | 2015-10-11 | 7 | 124 | 210 |
| 155 | 2015-10-11 | 8 | 417 | 869 |
| 155 | 2015-10-11 | 9 | 637 | 1350 |
| 155 | 2015-10-11 | 10 | 1445 | 1316 |
| 155 | 2015-10-11 | 11 | 2185 | 1168 |
| 155 | 2015-10-11 | 12 | 1931 | 1118 |
| 155 | 2015-10-11 | 13 | 1468 | 1195 |
| 155 | 2015-10-11 | 14 | 1261 | 1338 |
| 155 | 2015-10-11 | 15 | 1243 | 1539 |
| 155 | 2015-10-11 | 16 | 1485 | 1875 |
| 155 | 2015-10-11 | 17 | 2052 | 1975 |
| 155 | 2015-10-11 | 18 | 1310 | 2127 |
| 155 | 2015-10-11 | 19 | 1991 | 1865 |
| 155 | 2015-10-11 | 20 | 1346 | 1071 |
| 155 | 2015-10-11 | 21 | 1132 | 434 |
| 155 | 2015-10-11 | 22 | 434 | 252 |
| 155 | 2015-10-11 | 24 | 21 | 165 |
| 155 | 2015-10-12 | 7 | 154 | 274 |
| 155 | 2015-10-12 | 8 | 596 | 1200 |
| 155 | 2015-10-12 | 9 | 521 | 2288 |
| 155 | 2015-10-12 | 10 | 1150 | 1578 |
| 155 | 2015-10-12 | 11 | 1848 | 1340 |
| 155 | 2015-10-12 | 12 | 1397 | 1193 |
| 155 | 2015-10-12 | 13 | 1411 | 1146 |
| 155 | 2015-10-12 | 14 | 1271 | 1318 |
| 155 | 2015-10-12 | 15 | 1161 | 1363 |
| 155 | 2015-10-12 | 16 | 1142 | 1316 |
| 155 | 2015-10-12 | 17 | 1522 | 1228 |
| 155 | 2015-10-12 | 18 | 1295 | 1186 |
| 155 | 2015-10-12 | 19 | 1886 | 1080 |
| 155 | 2015-10-12 | 20 | 1084 | 600 |
| 155 | 2015-10-12 | 21 | 813 | 264 |
| 155 | 2015-10-12 | 22 | 320 | 166 |
| 155 | 2015-10-12 | 24 | 23 | 120 |
| 155 | 2015-10-13 | 7 | 122 | 218 |
| 155 | 2015-10-13 | 8 | 467 | 1055 |
| 155 | 2015-10-13 | 9 | 423 | 2008 |
| 155 | 2015-10-13 | 10 | 1065 | 1342 |
| 155 | 2015-10-13 | 11 | 1547 | 1203 |
| 155 | 2015-10-13 | 12 | 1339 | 998 |
| 155 | 2015-10-13 | 13 | 1255 | 1003 |
| 155 | 2015-10-13 | 14 | 1164 | 1161 |
| 155 | 2015-10-13 | 15 | 1075 | 1281 |
| 155 | 2015-10-13 | 16 | 1106 | 1289 |
| 155 | 2015-10-13 | 17 | 1589 | 1217 |
| 155 | 2015-10-13 | 18 | 1303 | 1211 |
| 155 | 2015-10-13 | 19 | 1935 | 1102 |
| 155 | 2015-10-13 | 20 | 1173 | 640 |
| 155 | 2015-10-13 | 21 | 802 | 276 |
| 155 | 2015-10-13 | 22 | 320 | 181 |
| 155 | 2015-10-13 | 24 | 23 | 69 |
| 155 | 2015-10-14 | 7 | 113 | 211 |
| 155 | 2015-10-14 | 8 | 427 | 987 |
| 155 | 2015-10-14 | 9 | 475 | 1999 |
| 155 | 2015-10-14 | 10 | 1019 | 1437 |
| 155 | 2015-10-14 | 11 | 1651 | 1197 |
| 155 | 2015-10-14 | 12 | 1349 | 1106 |
| 155 | 2015-10-14 | 13 | 1331 | 1022 |
| 155 | 2015-10-14 | 14 | 1285 | 1171 |
| 155 | 2015-10-14 | 15 | 1099 | 1206 |
| 155 | 2015-10-14 | 16 | 1149 | 1249 |
| 155 | 2015-10-14 | 17 | 1583 | 1077 |
| 155 | 2015-10-14 | 18 | 1385 | 1147 |
















 4900
4900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











