







1. 朴素贝叶斯分类器
- 数据
Universal Bank 是一家业绩快速增长的银行。为了增加贷款业务,该银行探索将储蓄客户转变成个人贷款客户的方式。银行收集了5000条客户数据,包括客户特征(age、experience、income、family、 CCAvg、education、Zip Code)、客户对上一次贷款营销活动的响应( Personal Loan )、客户和银行的关系( mortgage,securities account.online.CD account、credit card)共13个特征,目标值是 Personal Loan,即客户是否接受了个人贷款。
| ID | Age | Experience | Income | ZIP Code |
| 账户 | 年龄 | 经验 | 收入 | 邮政编码 |
| Family | CCAvg | Education | Mortgage | Securities Account |
| 家庭成员人数 | 信用卡月平均消费 | 教育水平 | 按揭贷款数目 | 证券账户 |
| CD Account | Online | CreditCard | Personal Loan | |
| 定期存款 | 在线 | 信用卡 | 个人贷款 (目标值) |
在5000个客户中,仅480个客户接受了提供给他们的个人贷款。
ID,Age,Experience,Income,ZIP Code,Family,CCAvg,Education,Mortgage,Personal Loan,Securities Account,CD Account,Online,CreditCard 1,25,1,49,91107,4,1.6,1,0,0,1,0,0,0 2,45,19,34,90089,3,1.5,1,0,0,1,0,0,0 3,39,15,11,94720,1,1,1,0,0,0,0,0,0 4,35,9,100,94112,1,2.7,2,0,0,0,0,0,0 5,35,8,45,91330,4,1,2,0,0,0,0,0,1 6,37,13,29,92121,4,0.4,2,155,0,0,0,1,0 7,53,27,72,91711,2,1.5,2,0,0,0,0,1,0 8,50,24,22,93943,1,0.3,3,0,0,0,0,0,1 9,35,10,81,90089,3,0.6,2,104,0,0,0,1,0 10,34,9,180,93023,1,8.9,3,0,1,0,0,0,0 11,65,39,105,94710,4,2.4,3,0,0,0,0,0,0 12,29,5,45,90277,3,0.1,2,0,0,0,0,1,0 13,48,23,114,93106,2,3.8,3,0,0,1,0,0,0 14,59,32,40,94920,4,2.5,2,0,0,0,0,1,0 15,67,41,112,91741,1,2,1,0,0,1,0,0,0 16,60,30,22,95054,1,1.5,3,0,0,0,0,1,1 17,38,14,130,95010,4,4.7,3,134,1,0,0,0,0 18,42,18,81,94305,4,2.4,1,0,0,0,0,0,0 19,46,21,193,91604,2,8.1,3,0,1,0,0,0,0 20,55,28,21,94720,1,0.5,2,0,0,1,0,0,1 21,56,31,25,94015,4,0.9,2,111,0,0,0,1,0 22,57,27,63,90095,3,2,3,0,0,0,0,1,0 23,29,5,62,90277,1,1.2,1,260,0,0,0,1,0 24,44,18,43,91320,2,0.7,1,163,0,1,0,0,0 25,36,11,152,95521,2,3.9,1,159,0,0,0,0,1 26,43,19,29,94305,3,0.5,1,97,0,0,0,1,0 27,40,16,83,95064,4,0.2,3,0,0,0,0,0,0 28,46,20,158,90064,1,2.4,1,0,0,0,0,1,1 29,56,30,48,94539,1,2.2,3,0,0,0,0,1,1 30,38,13,119,94104,1,3.3,2,0,1,0,1,1,1 31,59,35,35,93106,1,1.2,3,122,0,0,0,1,0 32,40,16,29,94117,1,2,2,0,0,0,0,1,0 33,53,28,41,94801,2,0.6,3,193,0,0,0,0,0 34,30,6,18,91330,3,0.9,3,0,0,0,0,0,0 35,31,5,50,94035,4,1.8,3,0,0,0,0,1,0 36,48,24,81,92647,3,0.7,1,0,0,0,0,0,0 37,59,35,121,94720,1,2.9,1,0,0,0,0,0,1 38,51,25,71,95814,1,1.4,3,198,0,0,0,0,0 39,42,18,141,94114,3,5,3,0,1,1,1,1,0 40,38,13,80,94115,4,0.7,3,285,0,0,0,1,0 41,57,32,84,92672,3,1.6,3,0,0,1,0,0,0 42,34,9,60,94122,3,2.3,1,0,0,0,0,0,0 43,32,7,132,90019,4,1.1,2,412,1,0,0,1,0 44,39,15,45,95616,1,0.7,1,0,0,0,0,1,0 45,46,20,104,94065,1,5.7,1,0,0,0,0,1,1 46,57,31,52,94720,4,2.5,1,0,0,0,0,0,1 47,39,14,43,95014,3,0.7,2,153,0,0,0,1,0 48,37,12,194,91380,4,0.2,3,211,1,1,1,1,1 49,56,26,81,95747,2,4.5,3,0,0,0,0,0,1 50,40,16,49,92373,1,1.8,1,0,0,0,0,0,1 51,32,8,8,92093,4,0.7,2,0,0,1,0,1,0 52,61,37,131,94720,1,2.9,1,0,0,0,0,1,0 53,30,6,72,94005,1,0.1,1,207,0,0,0,0,0 54,50,26,190,90245,3,2.1,3,240,1,0,0,1,0 55,29,5,44,95819,1,0.2,3,0,0,0,0,1,0 56,41,17,139,94022,2,8,1,0,0,0,0,1,0 57,55,30,29,94005,3,0.1,2,0,0,1,1,1,0 58,56,31,131,95616,2,1.2,3,0,1,0,0,0,0 59,28,2,93,94065,2,0.2,1,0,0,0,0,0,0 60,31,5,188,91320,2,4.5,1,455,0,0,0,0,0 61,49,24,39,90404,3,1.7,2,0,0,1,0,1,0 62,47,21,125,93407,1,5.7,1,112,0,1,0,0,0 63,42,18,22,90089,1,1,1,0,0,0,0,0,0 64,42,17,32,94523,4,0,2,0,0,0,0,1,0 65,47,23,105,90024,2,3.3,1,0,0,0,0,0,0 66,59,35,131,91360,1,3.8,1,0,0,0,0,1,1 67,62,36,105,95670,2,2.8,1,336,0,0,0,0,0 68,53,23,45,95123,4,2,3,132,0,1,0,0,0 69,47,21,60,93407,3,2.1,1,0,0,0,0,1,1 70,53,29,20,90045,4,0.2,1,0,0,0,0,1,0 71,42,18,115,91335,1,3.5,1,0,0,0,0,0,1 72,53,29,69,93907,4,1,2,0,0,0,0,1,0 73,44,20,130,92007,1,5,1,0,0,0,0,0,1 74,41,16,85,94606,1,4,3,0,0,0,0,1,1 75,28,3,135,94611,2,3.3,1,0,0,0,0,0,1 76,31,7,135,94901,4,3.8,2,0,1,0,1,1,1 77,58,32,12,91320,3,0.3,3,0,0,0,0,0,0 78,46,20,29,92220,3,0.5,2,0,0,0,0,0,0 79,54,30,133,93305,2,2.6,3,0,1,0,0,0,0 80,50,26,19,94720,2,0.4,1,118,0,0,0,1,0 81,60,36,41,95134,4,1.3,1,174,0,0,0,1,1 82,47,22,40,94612,3,2.7,2,0,0,0,0,1,0 83,41,16,82,92507,1,4,3,0,0,0,0,1,0 84,33,9,50,94305,1,2.4,2,0,0,0,0,0,0 85,46,22,18,91730,1,0.9,3,0,0,0,0,1,0 86,27,2,109,94005,4,1.8,3,0,0,0,0,0,0 87,40,16,42,94501,4,2.2,2,126,0,0,0,0,0 88,48,22,78,94305,3,1.1,1,0,0,0,0,1,0 89,65,41,51,94117,2,1.1,1,0,0,0,0,1,0
注意:数据集中的编号(ID)和邮政编码(ZIP CODE)特征因为在分类模型中无意义,所以在数据预处理阶段将它们删除。
- 使用高斯朴素贝叶斯分类器(特征为连续型变量)对数据进行分类
- 使用留出法划分数据集,训练集:测试集为7:3。
- 使用高斯朴素贝叶斯分类器对训练集进行训练
- 使用训练好的模型对测试数据集进行预测并输出预测结果和模型准确度
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
#1. 读入数据
df = pd.read_csv('universalbank.csv')
y = df['Personal Loan']
X = df.drop(['ID', 'ZIP Code', 'Personal Loan'], axis = 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 0)
#2. 训练高斯朴素贝叶斯模型
gnb = GaussianNB()
gnb.fit(X_train, y_train)
# 3. 评估模型
y_pred = gnb.predict(X_test)
print('测试数据的预测结果:', y_pred)
acc = gnb.score(X_test, y_test)
print('GaussianNB模型的准确度:',acc) 
- 使用多项式朴素贝叶斯(特征为离散型变量)对数据进行分类
- 筛选出数据中的离散型特征
- 使用留出法划分数据集,训练集:测试集为7:3。
- 使用多项式朴素贝叶斯分类器对训练集进行训练
- 使用训练好的模型对测试数据集进行预测并输出预测结果和模型准确度
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
#1. 读入数据
df = pd.read_csv('universalbank.csv')
# 1. 读入数据
y = df['Personal Loan']
X = df[['Family', 'Education', 'Securities Account',
'CD Account', 'Online', 'CreditCard']] #只选用6个特征
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
#2. 训练多项式朴素贝叶斯模型
mnb = MultinomialNB()
mnb.fit(X_train, y_train)
y_pred = mnb.predict(X_test)
print('测试数据的预测结果:', y_pred)
acc = mnb.score(X_test, y_test)
print('MultinomialNB模型的准确度:',acc)

2. K近邻分类器(KNN)(4-2)
- 数据
使用第1题中的Universal Bank数据集。
注意:数据集中的编号(ID)和邮政编码(ZIP CODE)特征因为在分类模型中无意义,所以在数据预处理阶段将它们删除。
- 使用KNN对数据进行分类
- 使用留出法划分数据集,训练集:测试集为7:3。
- 使用KNN对训练集进行训练
最近邻的数量K设置为5。
- 使用训练好的模型对测试集进行预测并输出预测结果和模型准确度
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pprint
# 禁用输出省略
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', None)
# 读取数据集
data = pd.read_csv("universalbank.csv")
# 数据预处理:删除无意义特征
data = data.drop(columns=['ID', 'ZIP Code'])
# 划分特征和标签
X = data.drop(columns=['Personal Loan'])
y = data['Personal Loan']
# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用KNN算法对训练集进行训练,最近邻的数量K设置为5
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)
# 输出预测结果
for item in y_pred:
print(item, end='\n') # 每项后面都换行,这样就不会合并在一起
print("预测结果:")
print(y_pred)
# 输出模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)

2. CART决策树(4-2)
- 数据
使用第1题中的Universal Bank数据集。
注意:数据集中的编号(ID)和邮政编码(ZIP CODE)特征因为在分类模型中无意义,所以在数据预处理阶段将它们删除。
- 使用CART决策树对数据进行分类
- 使用留出法划分数据集,训练集:测试集为7:3。
- 使用CART决策树对训练集进行训练
决策树的深度限制为10层,max_depth=10。
- 使用训练好的模型对测试集进行预测并输出预测结果和模型准确度
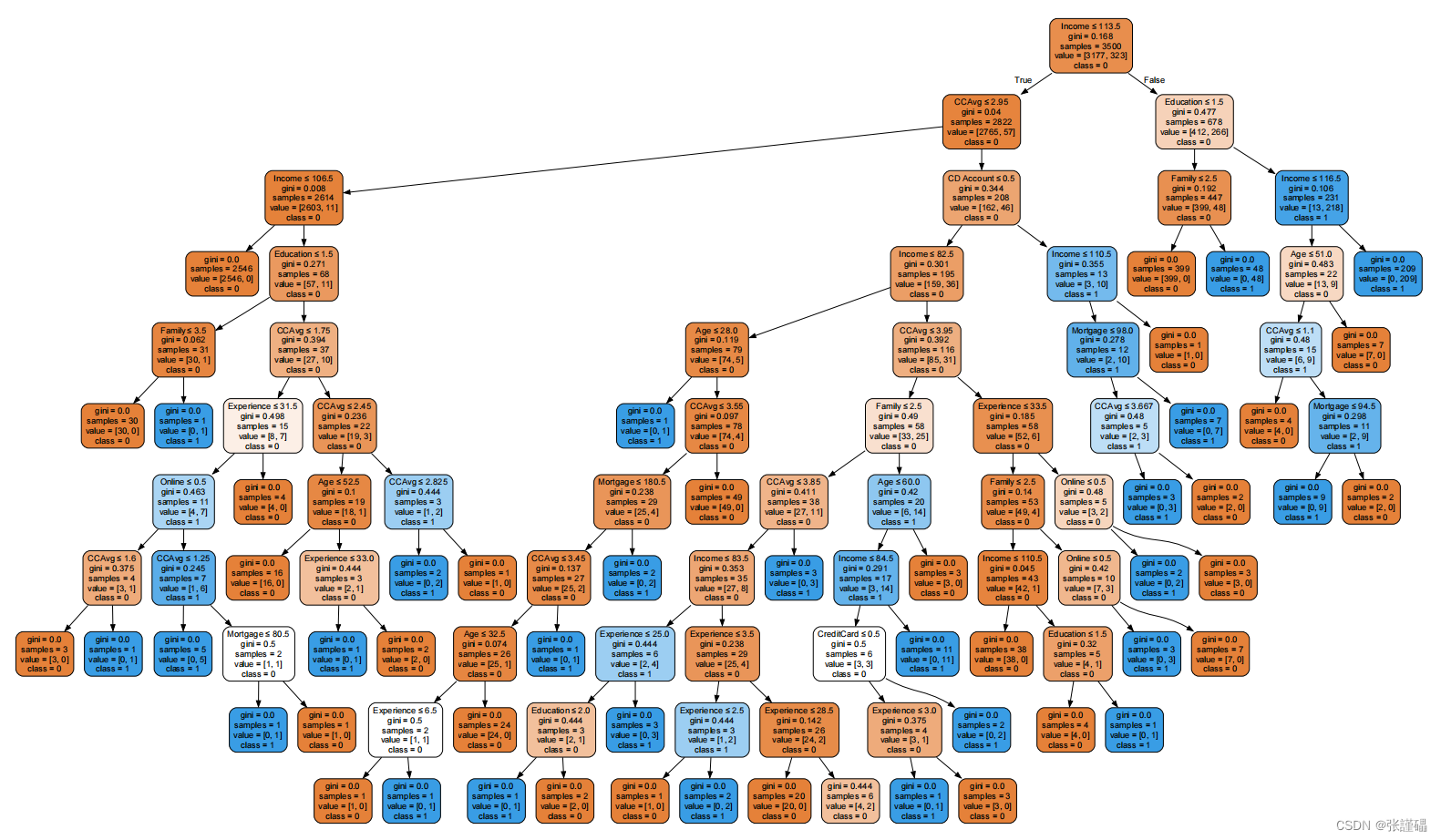
- 可视化训练好的CART决策树模型
- 安装graphviz模块
首先在windows系统中安装graphviz模块
32位系统使用windows_10_cmake_Release_graphviz-install-10.0.1-win32.exe
64位系统使用windows_10_cmake_Release_graphviz-install-10.0.1-win64.exe
注意:安装时使用下图中圈出的选项
安装完成后使用pip install graphviz指令在python环境中安装graphviz库。
- 使用graphviz模块可视化模型
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import export_graphviz
import graphviz
# 读取数据集
data = pd.read_csv("universalbank.csv")
# 数据预处理:删除无意义特征
data = data.drop(columns=['ID', 'ZIP Code'])
# 划分特征和标签
X = data.drop(columns=['Personal Loan'])
y = data['Personal Loan']
# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用CART决策树对训练集进行训练,深度限制为10层
model = DecisionTreeClassifier(max_depth=10)
model.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)
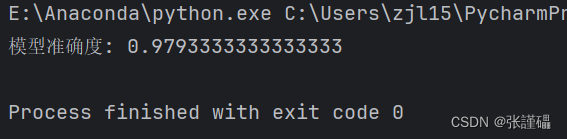
# 输出预测结果和模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)
# 可视化训练好的CART决策树模型
dot_data = export_graphviz(model, out_file=None,
feature_names=X.columns,
class_names=['0', '1'],
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("Universal_Bank_CART6") # 保存为PDF文件
4.神经网络回归任务(4-3)
- 数据
- 使用留出法划分数据集,训练集:测试集为7:3。
- 使用多层感知机回归模型对训练集进行训练
- 使用训练好的模型对测试集进行预测并输出预测结果和模型的MSE和MAE。
- 使用训练好的模型对如下数据的房价进行预测并输出结果
数据:[3.0,2.5,1490,8102,2.0,0,0,4,1490,0,1990,0]
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
# 读取数据
df = pd.read_csv('house-price.csv')
df = df.drop(columns=['date', 'street', 'city', 'statezip', 'country'])
# 设置特征名称
feature_names = ['bedrooms', 'bathrooms', 'sqft_living', 'sqft_lot', 'floors', 'waterfront', 'view', 'condition', 'sqft_above', 'sqft_basement', 'yr_built', 'yr_renovated']
X = df[feature_names]
y = df['price']
# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化多层感知机回归模型,并设置参数
model = MLPRegressor(max_iter=1000, random_state=42, hidden_layer_sizes=(100,))
# 对训练集进行训练
model.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)
# 计算模型的均方误差(MSE)和平均绝对误差(MAE)
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
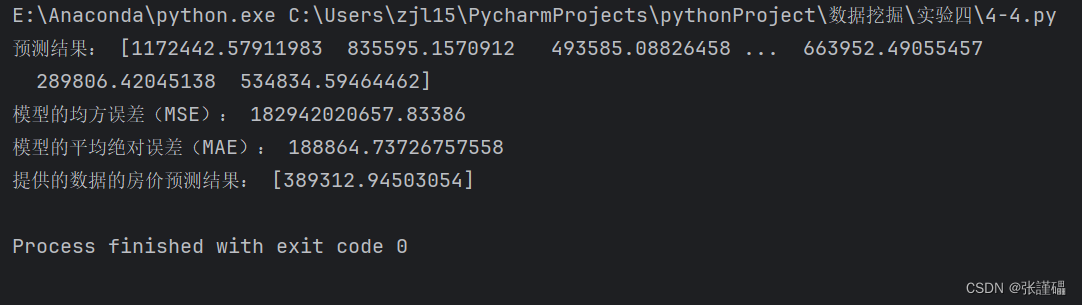
# 输出预测结果和模型的MSE和MAE
print("预测结果:", y_pred)
print("模型的均方误差(MSE):", mse)
print("模型的平均绝对误差(MAE):", mae)
# 创建新数据
new_data = pd.DataFrame([[3.0, 2.5, 1490, 8102, 2.0, 0, 0, 4, 1490, 0, 1990, 0]], columns=feature_names)
# 使用训练好的模型对提供的数据进行预测
predicted_price = model.predict(new_data)
print("提供的数据的房价预测结果:", predicted_price)
5.神经网络分类任务(4-3)
- 数据
- 用1-10行数据作为训练集,用11-20行数据作为测试集。
- 使用多层感知机分类模型对训练集进行训练
- 使用训练好的模型对测试集进行预测并输出预测结果和模型准确度。
- 使用模型对21-25行数据的贷款申请进行评估,输出评估结果(1为同意,0为拒绝)。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 加载数据
df = pd.read_excel('企业贷款审批数据表.xlsx') # 请替换成你的数据文件路径
# 划分训练集和测试集
train_data = df.iloc[0:17] # 使用1-17行数据作为训练集
test_data = df.iloc[17:20] # 使用18-20行数据作为测试集
# 特征和标签
X_train = train_data.drop(columns=['Y']) # 特征
y_train = train_data['Y'] # 标签
X_test = test_data.drop(columns=['Y']) # 特征
y_test = test_data['Y'] # 标签
# 初始化多层感知机分类模型
model = MLPClassifier(max_iter=1000, random_state=42)
# 训练模型并记录损失值
history = model.fit(X_train, y_train)
# 对测试集进行预测
y_pred = model.predict(X_test)
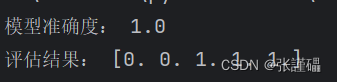
# 计算模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)
# 准备新数据
new_data = df.iloc[20:25].drop(columns=['Y'])
# 使用训练好的模型进行评估
evaluation_result = model.predict(new_data)
print("评估结果:", evaluation_result)
# 创建一个图形对象
fig, ax = plt.subplots(2, 1, figsize=(10, 10))
# 绘制训练过程中的损失值变化
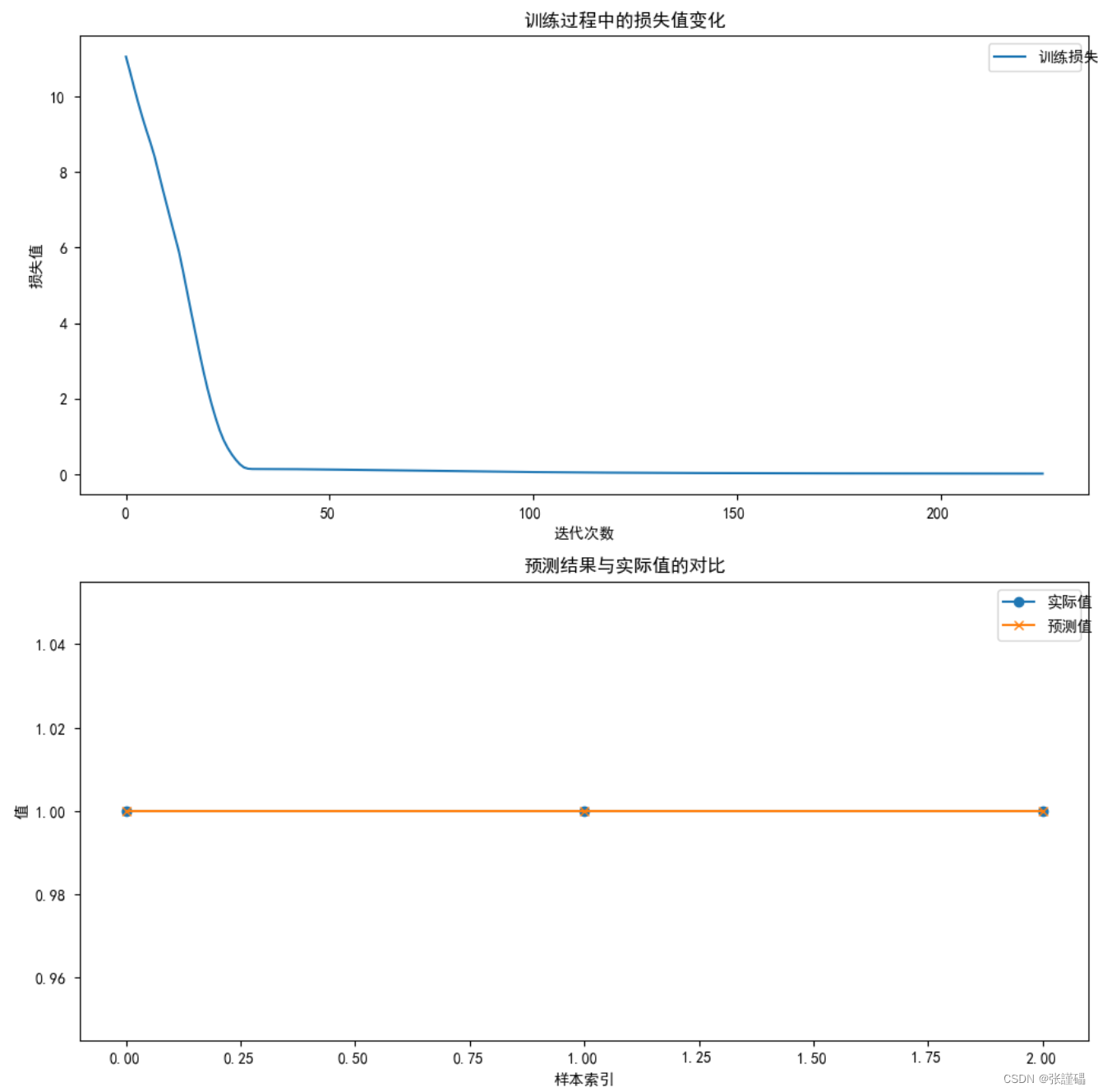
ax[0].plot(model.loss_curve_, label='训练损失')
ax[0].set_title('训练过程中的损失值变化')
ax[0].set_xlabel('迭代次数')
ax[0].set_ylabel('损失值')
ax[0].legend()
# 绘制预测结果与实际值的对比折线图
ax[1].plot(y_test.values, label='实际值', marker='o')
ax[1].plot(y_pred, label='预测值', marker='x')
ax[1].set_title('预测结果与实际值的对比')
ax[1].set_xlabel('样本索引')
ax[1].set_ylabel('值')
ax[1].legend()
# 显示图形
plt.tight_layout()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.show()
6.关联规则分析(4-4)
- 安装mlxtend库
pip install mlxtend
- 数据读取与预处理
- 使用TransactionEncoder将上图中列表转换为下图中所示DataFrame
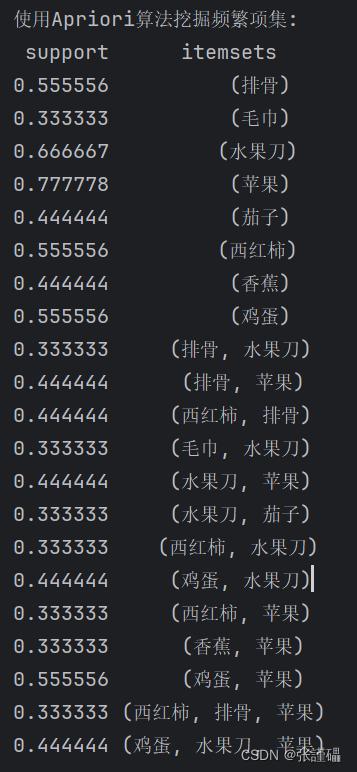
- 使用apriori算法挖掘频繁项集(最小支持度为0.3),并输出结果
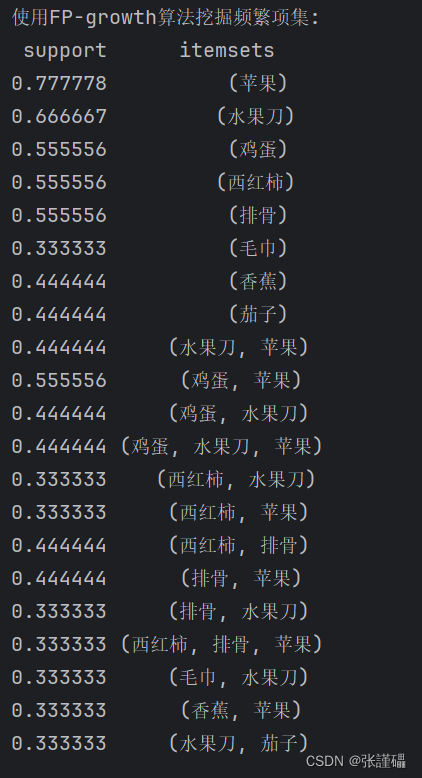
(4)使用FP-growth算法挖掘频繁项集(最小支持度为0.3),并输出结果,与上一问结果进行对比
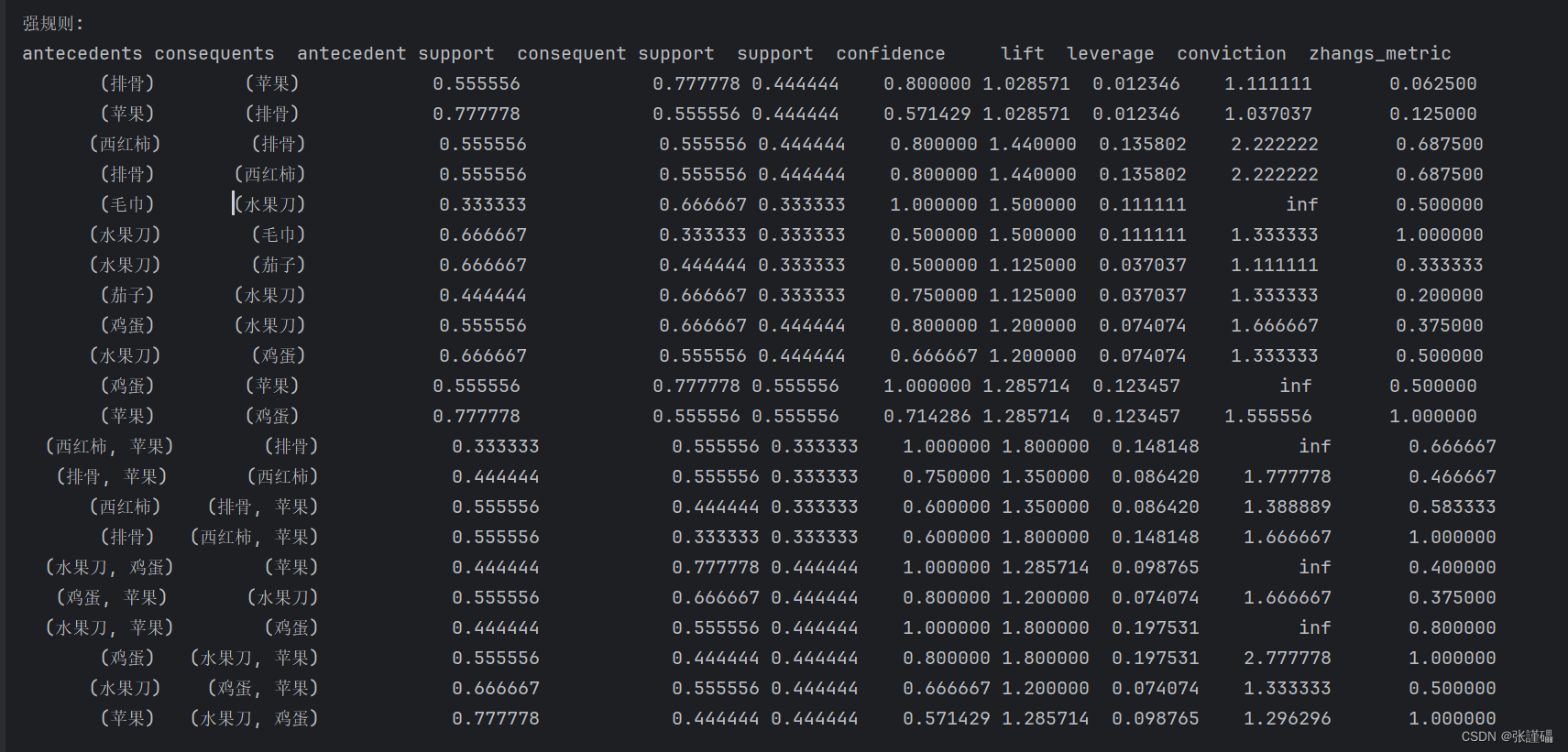
(5)生成强规则(最小置信度为0.5, 提升度>1),并输出结果
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, fpgrowth, association_rules
# 步骤2:数据读取与预处理
data = {
'I1': ['西红柿', '排骨', '鸡蛋', '毛巾', '水果刀', '苹果'],
'I2': ['西红柿', '茄子', '水果刀', '香蕉'],
'I3': ['鸡蛋', '袜子', '毛巾', '肥皂', '苹果', '水果刀'],
'I4': ['西红柿', '排骨', '茄子', '毛巾', '水果刀'],
'I5': ['西红柿', '排骨', '酸奶', '苹果'],
'I6': ['鸡蛋', '茄子', '酸奶', '肥皂', '苹果', '香蕉'],
'I7': ['排骨', '鸡蛋', '茄子', '水果刀', '苹果'],
'I8': ['土豆', '鸡蛋', '袜子', '香蕉', '苹果', '水果刀'],
'I9': ['西红柿', '排骨', '鞋子', '土豆', '香蕉', '苹果']
}
transactions = list(data.values())
# 步骤3:使用TransactionEncoder将列表转换为DataFrame
te = TransactionEncoder()
te_ary = te.fit(transactions).transform(transactions)
print(te_ary)
df = pd.DataFrame(te_ary, columns=te.columns_)
# 步骤4:使用apriori算法挖掘频繁项集(最小支持度为0.3),并输出结果
frequent_itemsets_apriori = apriori(df, min_support=0.3, use_colnames=True)
print("使用Apriori算法挖掘频繁项集:")
print(frequent_itemsets_apriori.to_string(index=False))
# 步骤5:使用FP-growth算法挖掘频繁项集(最小支持度为0.3),并输出结果,与上一问结果进行对比
frequent_itemsets_fpgrowth = fpgrowth(df, min_support=0.3, use_colnames=True)
print("\n使用FP-growth算法挖掘频繁项集:")
print(frequent_itemsets_fpgrowth.to_string(index=False))
# 步骤6:生成强规则(最小置信度为0.5, 提升度>1),并输出结果
rules = association_rules(frequent_itemsets_apriori, metric="confidence", min_threshold=0.5)
rules = rules[rules['lift'] > 1]
print("\n强规则:")
print(rules.to_string(index=False))

7.时间序列分析(4-5)
- 安装statsmodels库
pip install statsmodels
- 数据读取与预处理
使用pd.read_csv()读取并对日期数据进行转换
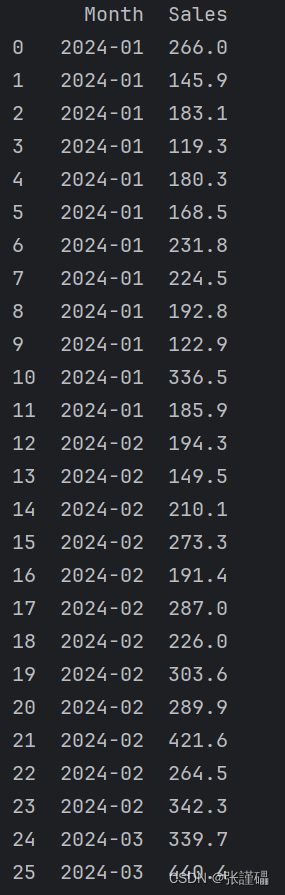
- 检测序列的平稳性
- 时序图判断法
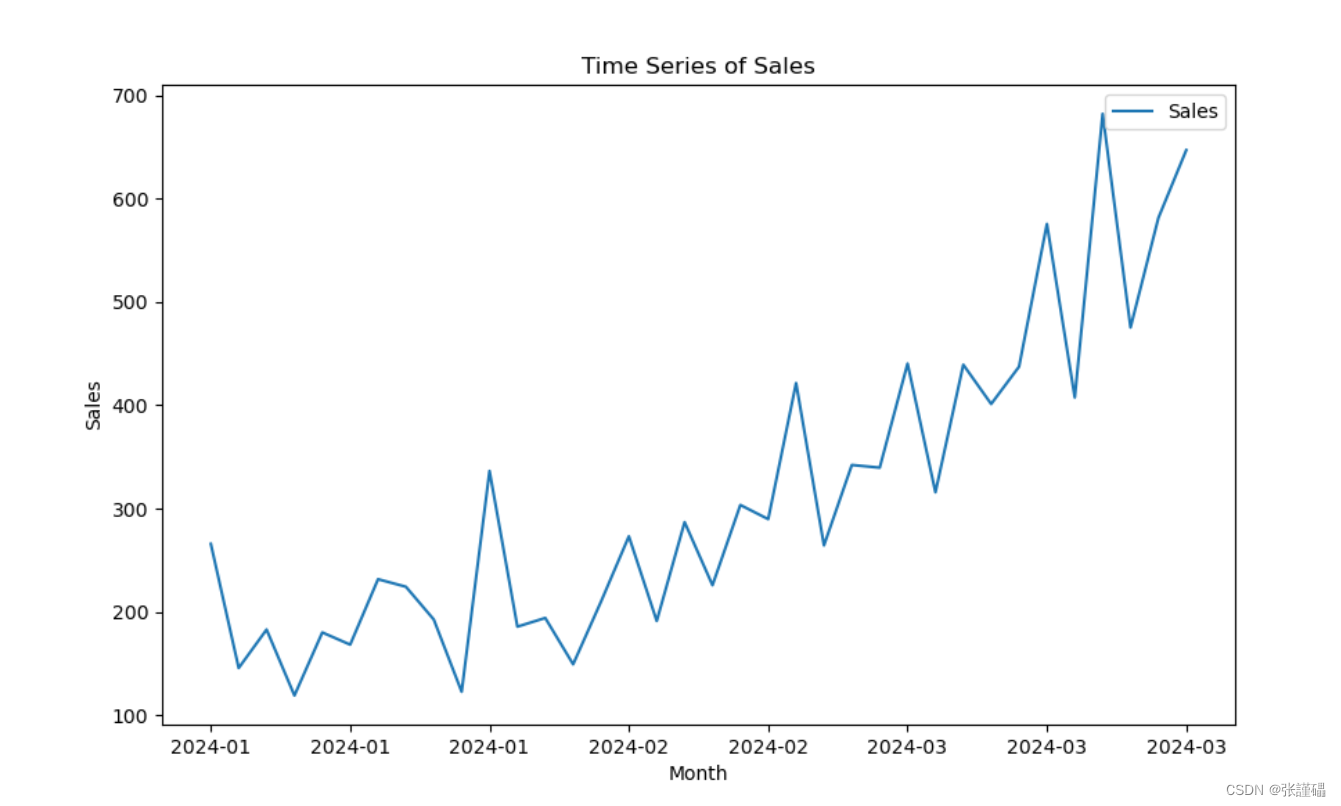
-
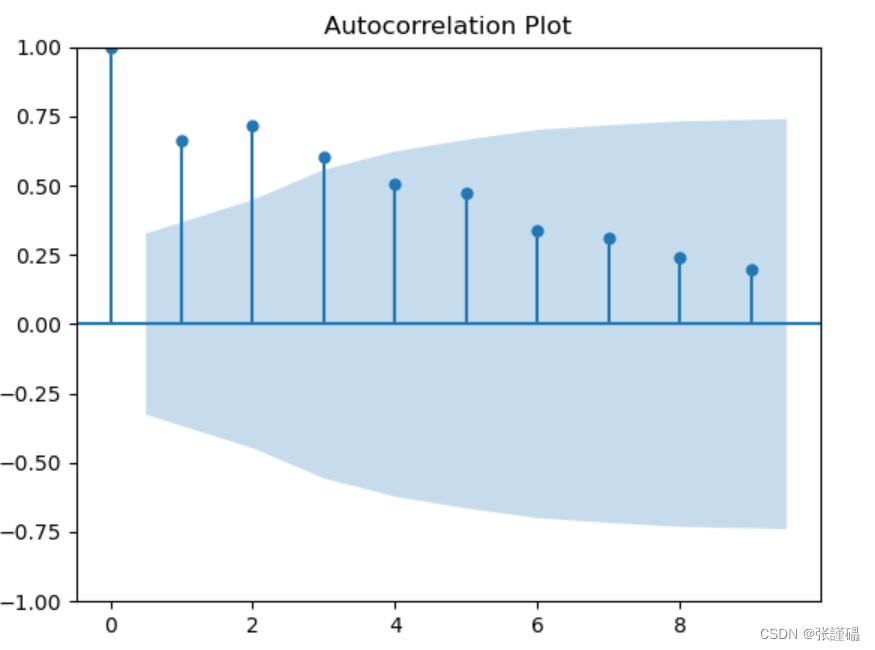
- 制自相关图判断法
- 使用ADF单位根检测法
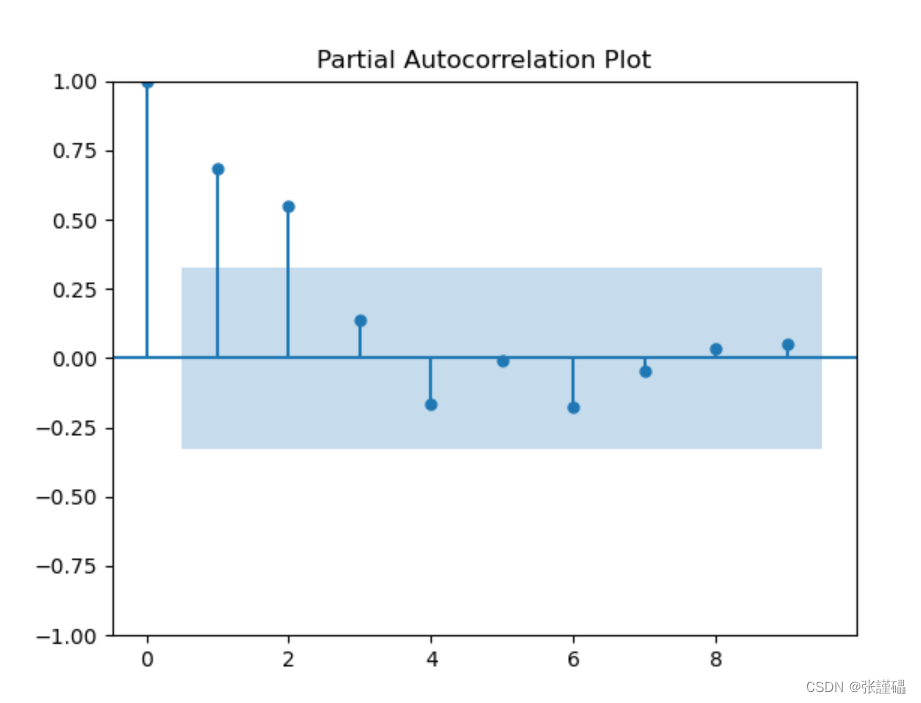

注意:p>0.05即为非平稳序列
- 差分处理
# 差分处理
diff_data = data.diff().dropna() 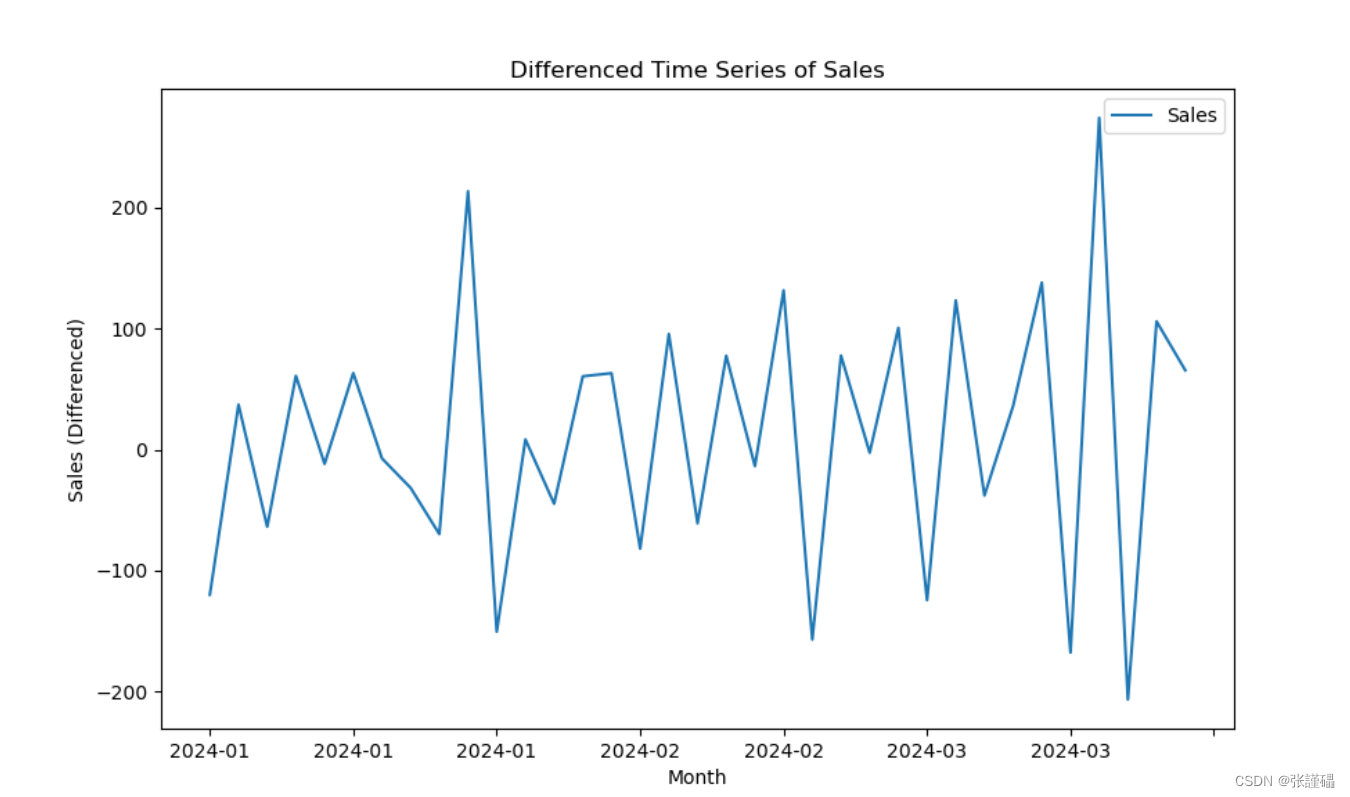
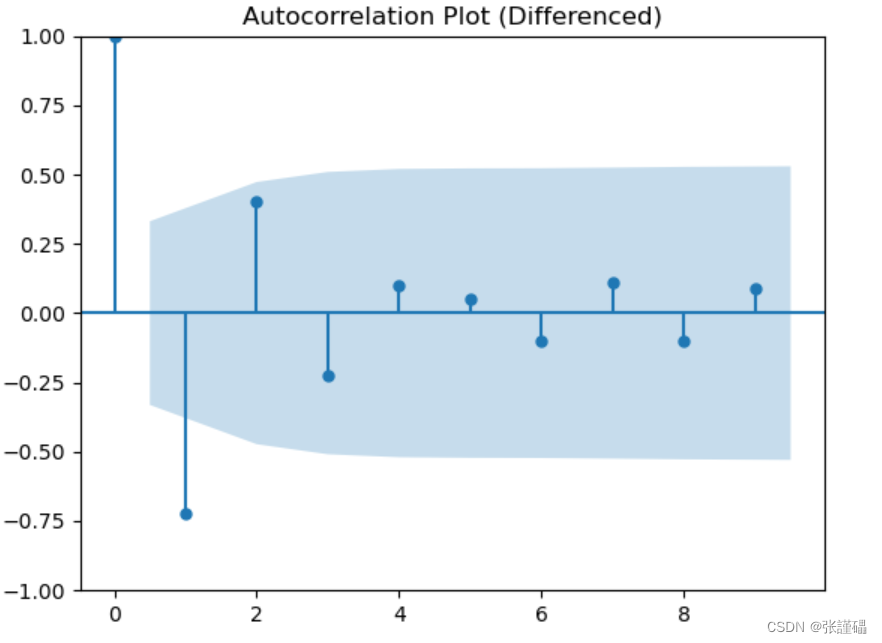
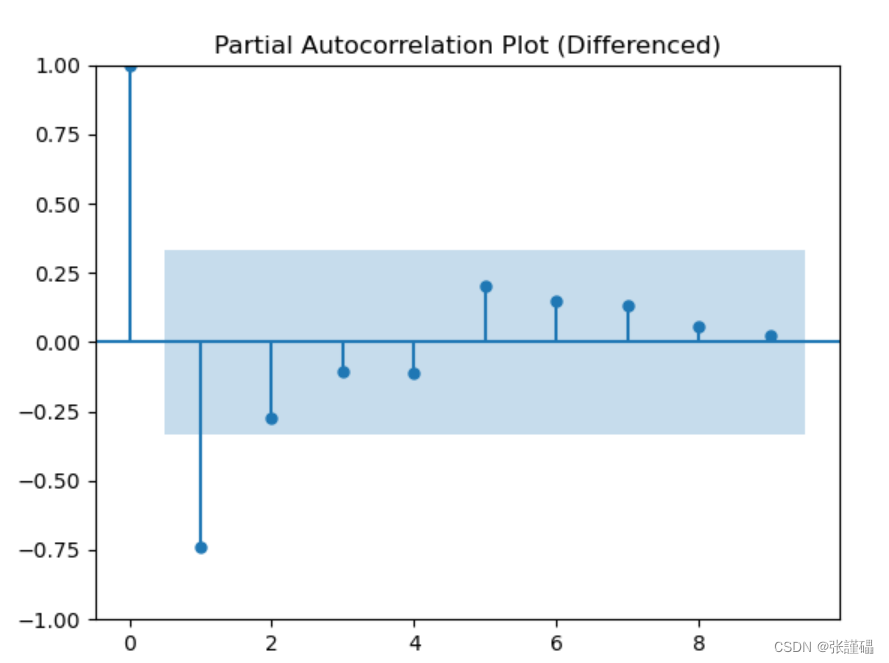

注意:根据上一步结果判断数据序列为非平稳序列,如想使用模型对数据进行建模,则需将数据转换为平稳序列。所以在这一步使用差分处理对序列进行处理。
对处理后的序列进行平稳性检测(自相关图法、偏相关图法、ADF检测法)
- 使用ARIMA模型对差分处理后的序列进行建模
- 使用模型预测未来5个月的销售额
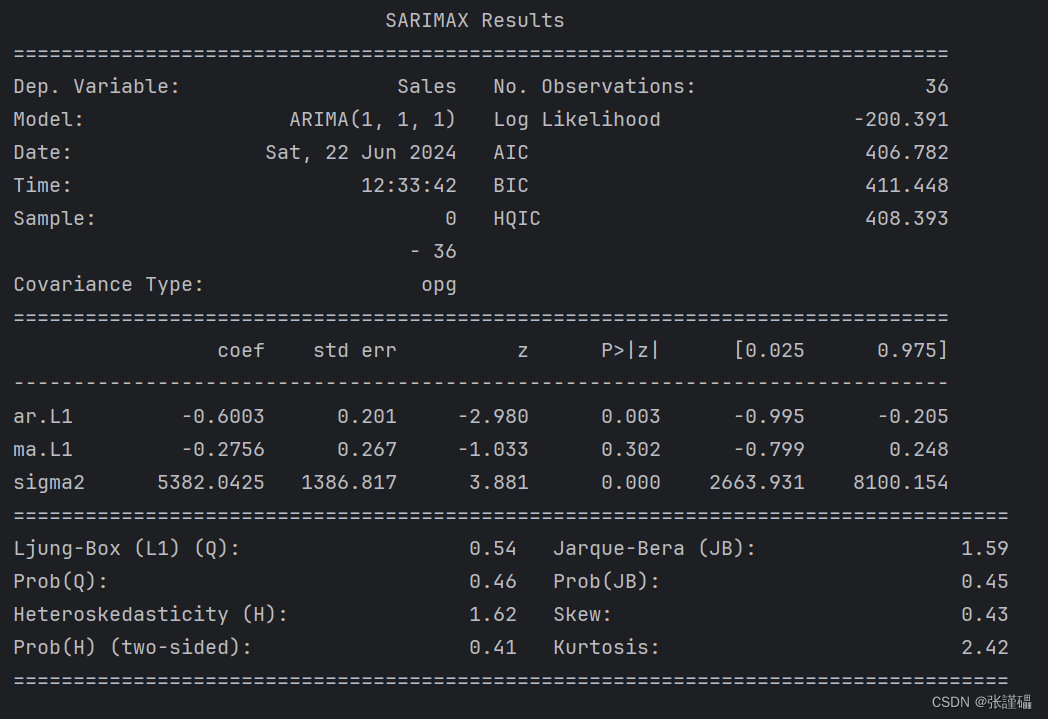
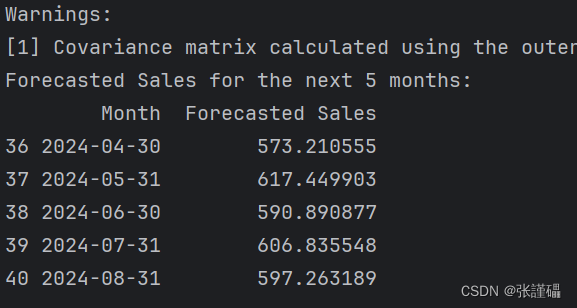
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima.model import ARIMA
import io
# 读取数据并进行预处理
data = """
"Month","Sales"
"1-01",266.0
"1-02",145.9
"1-03",183.1
"1-04",119.3
"1-05",180.3
"1-06",168.5
"1-07",231.8
"1-08",224.5
"1-09",192.8
"1-10",122.9
"1-11",336.5
"1-12",185.9
"2-01",194.3
"2-02",149.5
"2-03",210.1
"2-04",273.3
"2-05",191.4
"2-06",287.0
"2-07",226.0
"2-08",303.6
"2-09",289.9
"2-10",421.6
"2-11",264.5
"2-12",342.3
"3-01",339.7
"3-02",440.4
"3-03",315.9
"3-04",439.3
"3-05",401.3
"3-06",437.4
"3-07",575.5
"3-08",407.6
"3-09",682.0
"3-10",475.3
"3-11",581.3
"3-12",646.9
"""
# 将字符串转换为DataFrame
data = pd.read_csv(io.StringIO(data))
# 将'Month'列转换为日期类型
data['Month'] = pd.to_datetime(data['Month'], format='%m-%d')
# 将'Month'列转换为日期类型,并设置年份为2024年
data['Month'] = pd.to_datetime(data['Month'], format='%y-%m', yearfirst=True).dt.strftime('2024-%m')
print(data)
# 将日期列设置为索引
data.set_index('Month', inplace=True)
# 绘制时序图
data.plot(figsize=(10, 6))
plt.xlabel('Month')
plt.ylabel('Sales')
plt.title('Time Series of Sales')
plt.show()
# 检测序列的平稳性
# 自相关图
plot_acf(data, lags=9)
plt.title('Autocorrelation Plot')
plt.show()
# 偏相关图
plot_pacf(data, lags=9)
plt.title('Partial Autocorrelation Plot')
plt.show()
# ADF检验
adf_result = adfuller(data['Sales'])
print('ADF Statistic:', adf_result[0])
print('p-value:', adf_result[1])
print('Critical Values:', adf_result[4])
# 差分处理
diff_data = data.diff().dropna()
# 绘制差分后的时序图
diff_data.plot(figsize=(10, 6))
plt.xlabel('Month')
plt.ylabel('Sales (Differenced)')
plt.title('Differenced Time Series of Sales')
plt.show()
# 差分后的序列平稳性检测
# 自相关图
plot_acf(diff_data, lags=9)
plt.title('Autocorrelation Plot (Differenced)')
plt.show()
# 偏相关图
plot_pacf(diff_data, lags=9)
plt.title('Partial Autocorrelation Plot (Differenced)')
plt.show()
# ADF检验
adf_result_diff = adfuller(diff_data['Sales'])
print('ADF Statistic (Differenced):', adf_result_diff[0])
print('p-value (Differenced):', adf_result_diff[1])
print('Critical Values (Differenced):', adf_result_diff[4])
# 使用ARIMA模型建模
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit()
# 打印模型的概要信息
print(model_fit.summary())
# 预测未来5个月的销售额
forecast_steps = 5
forecast = model_fit.forecast(steps=5)
# 生成未来几个月的日期
last_month = data.index[-1]
future_months = pd.date_range(start=last_month, periods=forecast_steps + 1, freq='M')[1:]
# 创建包含日期和预测销售额的DataFrame
forecast_df = pd.DataFrame({'Month': future_months, 'Forecasted Sales': forecast})
# 输出预测结果
print('Forecasted Sales for the next 5 months:')
print(forecast_df)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











