







今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
前言
在Java的集合框架中,Map是一个非常重要的接口,用于存储键值对。在开发过程中,我们通常会使用HashMap、TreeMap、LinkedHashMap等常见的Map实现类。但是,在某些场景下,我们可能需要使用一种特殊的Map实现类——IdentityHashMap。
IdentityHashMap和其他Map实现类的区别在于,IdentityHashMap是一个非常特殊的Map实现,它使用的是恒等比较(而不是equals方法)来判断两个键是否相等。这意味着,对于同一个对象的不同引用,IdentityHashMap会将它们视为不同的键,而其他Map实现类则会将它们视为相同的键。
本文将对IdentityHashMap进行深入的源代码解析、应用场景案例分析、优缺点分析等,以帮助读者更好地理解和使用这个特殊的Map实现。
摘要
本文将主要介绍Java中的IdentityHashMap,包括其源代码解析、应用场景案例、优缺点分析等。通过本文的阅读,读者将能够更加清晰地了解IdentityHashMap的特点和使用方法,为其在实际开发中的应用提供帮助。
IdentityHashMap
简介
IdentityHashMap是Java集合框架中的一个特殊的Map实现,它使用恒等比较来判断两个键是否相等。与其他Map实现类使用equals方法不同,IdentityHashMap会将同一对象的不同引用视为不同的键。
IdentityHashMap是一个线程不安全的Map实现,与HashMap一样,它的实现方式也是基于散列表(哈希表)。与HashMap的实现方式不同的是,IdentityHashMap使用的是Object类的hashCode方法和==运算符来计算键的哈希值和比较键的相等性。这使得IdentityHashMap在某些特殊的场景下更加适合使用。
另外值得注意的是,IdentityHashMap实现了java.io.Serializable接口,因此它可以被序列化和反序列化。
源代码解析
类的继承结构
在IdentityHashMap类的源代码中,我们可以看到它是继承自AbstractMap类的。AbstractMap是Map接口的抽象实现,它实现了Map接口中的大部分方法,而留下了一些方法供子类自行实现。
public class IdentityHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, java.io.Serializable, Cloneable
在这里插入图片描述
内部类Entry
IdentityHashMap内部有一个Entry类,它用来表示键值对。Entry类定义如下:
private static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
final int hash;
V value;
Entry<K,V> next;
Entry(K key, int hash, V value, Entry<K,V> next) {
this.key = key;
this.hash = hash;
this.value = value;
this.next = next;
}
可以看到,Entry类实现了Map.Entry接口,它有四个成员变量:key、hash、value、next。
其中,key表示键;hash表示键的哈希值;value表示值;next表示链表中的下一个Entry对象。
构造方法
IdentityHashMap类有三个构造方法,分别如下:
public IdentityHashMap() {
init(DEFAULT_CAPACITY);
}
public IdentityHashMap(int expectedMaxSize) {
if (expectedMaxSize < 0)
throw new IllegalArgumentException("expectedMaxSize is negative: "
+ expectedMaxSize);
init(capacity(expectedMaxSize));
}
public IdentityHashMap(Map<? extends K, ? extends V> m) {
this((int) ((1 + m.size()) * DEFAULT_LOAD_FACTOR));
putAll(m);
}
其中,第一个构造方法默认构造一个容量为21的IdentityHashMap对象,第二个构造方法指定了一个期望的最大容量,而第三个构造方法则是将一个已有的Map对象转化为IdentityHashMap对象。
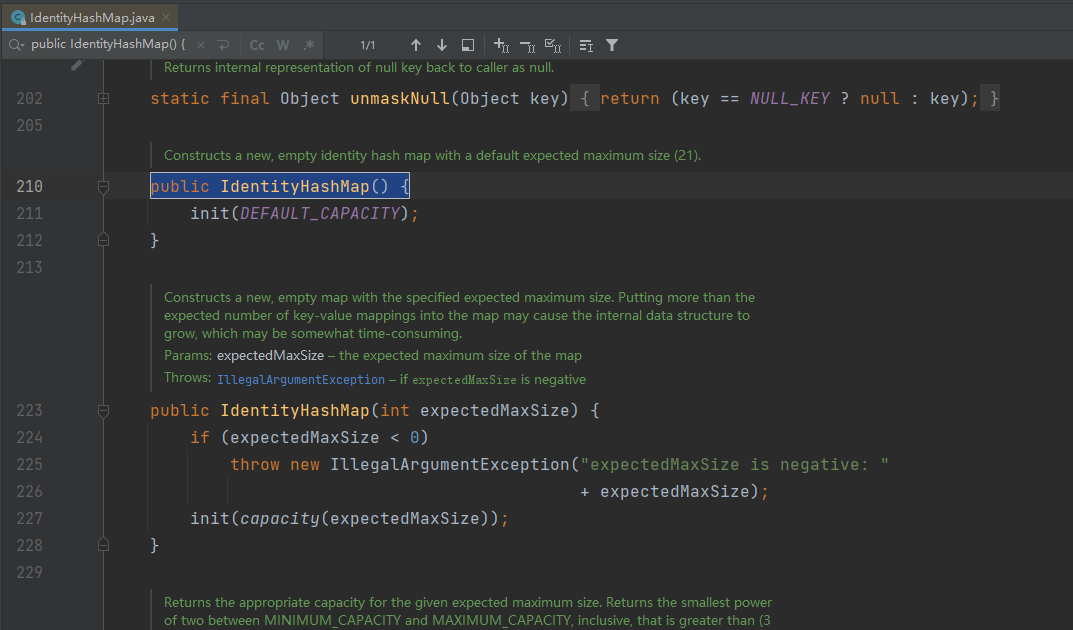
put方法
IdentityHashMap的put方法用于将一个键值对放入Map中。它的实现方式与HashMap的put方法类似,但是它使用的是恒等比较而不是equals方法来判断键的相等性。具体实现如下:
public V put(K key, V value) {
Object k = maskNull(key);
int hash = System.identityHashCode(k);
Entry<K,V>[] tab = getTable();
int index = hash & (tab.length - 1);
for (Entry<K,V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && k == e.key) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
addEntry(k, value, hash, index);
return null;
}
void addEntry(K key, V value, int hash, int index) {
Entry<K,V>[] tab = getTable();
Entry<K,V> e = tab[index];
tab[index] = new Entry<>(key, hash, value, e);
if (size++ >= threshold)
resize(2 * tab.length);
}
可以看到,put方法首先调用了maskNull方法,该方法用于将null值转化为一个非null值进行处理。接着,它调用了System.identityHashCode方法来计算键的哈希值。然后,它遍历链表中的Entry对象,如果找到了值相等的键,就将其对应的值替换为新的值,并返回旧的值。如果没找到相等的键,就调用addEntry方法将新的键值对添加到Map中。
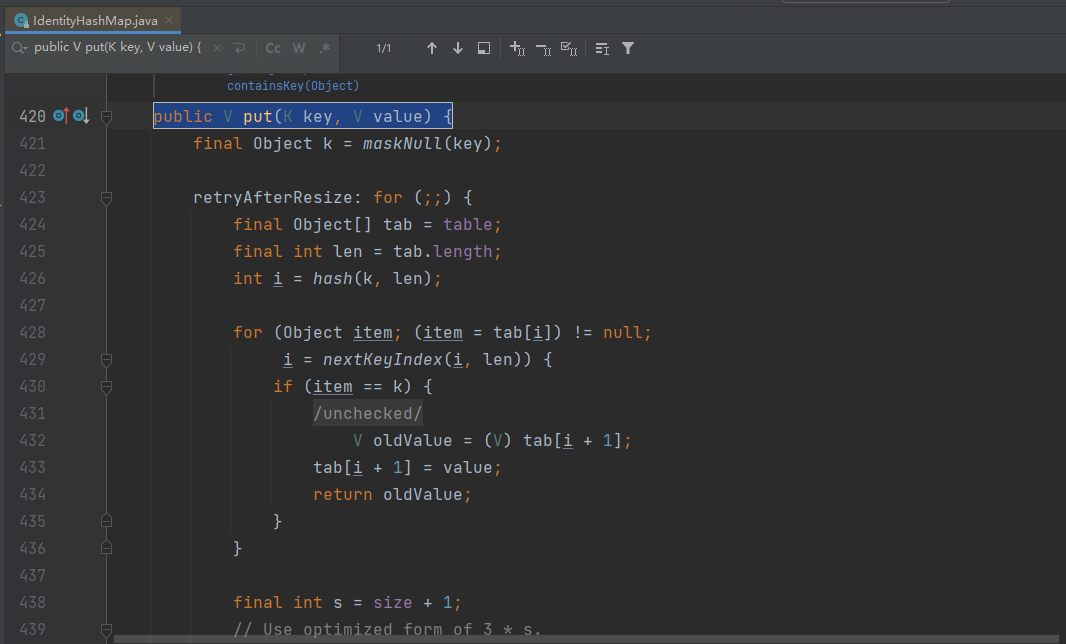
get方法
IdentityHashMap的get方法用于根据键查找值。它的实现方式与HashMap的get方法类似,但是也是使用的恒等比较来判断键的相等性。具体实现如下:
public V get(Object key) {
Object k = maskNull(key);
int hash = System.identityHashCode(k);
Entry<K,V>[] tab = getTable();
int index = hash & (tab.length - 1);
for (Entry<K,V> e = tab[index]; e != null; e = e.next)
if (e.hash == hash && k == e.key)
return e.value;
return null;
}
可以看到,get方法首先调用了maskNull方法,然后使用System.identityHashCode方法计算键的哈希值。接着,它遍历链表中的Entry对象,如果找到了值相等的键,就返回对应的值。如果没有找到相等的键,就返回null。
应用场景案例
IdentityHashMap通常被用于需要使用恒等比较的场景中。例如:
- 在某些数据结构中存储对象引用时。
- 在需要使用对象引用作为键的场景中。
IdentityHashMap的使用还需要注意以下几点:
- IdentityHashMap的性能与HashMap相比略逊。
- 在IdentityHashMap中存储大量对象引用可能会导致内存泄漏。
优缺点分析
优点
- 在需要使用恒等比较的场景中,IdentityHashMap更加方便。
- IdentityHashMap使用的是恒等比较,所以在某些特定的场景下比其他Map实现类效率更高。
缺点
- IdentityHashMap的性能相对于其他Map实现类较低。
- 在IdentityHashMap中,存储大量对象引用可能会导致内存泄漏。
类代码方法介绍
put(K key, V value): 向IdentityHashMap中添加一个键值对。get(Object key): 根据键查找对应的值。remove(Object key): 根据键删除对应的键值对。clear(): 清空IdentityHashMap中的所有键值对。clone(): 克隆IdentityHashMap对象。
测试用例
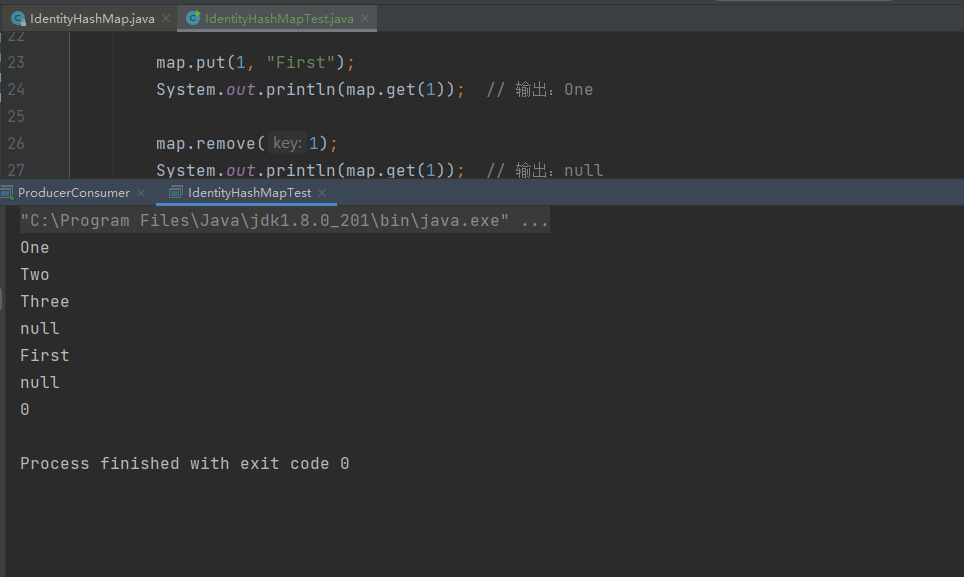
下面是一个简单的测试用例,用于展示IdentityHashMap的基本用法:
package com.example.javase.collection;
import java.util.IdentityHashMap;
/**
* @author ms
* @date 2023/10/25 17:37
*/
public class IdentityHashMapTest {
public static void main(String[] args) {
IdentityHashMap<Integer, String> map = new IdentityHashMap<Integer, String>();
map.put(1, "One");
map.put(2, "Two");
map.put(3, "Three");
System.out.println(map.get(1)); // 输出:One
System.out.println(map.get(2)); // 输出:Two
System.out.println(map.get(3)); // 输出:Three
System.out.println(map.get(4)); // 输出:null
map.put(1, "First");
System.out.println(map.get(1)); // 输出:One
map.remove(1);
System.out.println(map.get(1)); // 输出:null
map.clear();
System.out.println(map.size()); // 输出:0
}
}
在上述测试用例中,我们首先创建了一个IdentityHashMap对象,并向其中添加了三个键值对。接着,我们通过get方法根据键查找对应的值,并使用remove方法删除了一个键值对。最后,我们使用clear方法清空了IdentityHashMap中的所有键值对。
测试结果
根据如上测试用例,本地测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加更多的测试数据或测试方法,进行熟练学习以此加深理解。
测试代码分析
根据如上测试用例,在此我给大家进行深入详细的解读一下测试代码,以便于更多的同学能够理解并加深印象。
如上测试用例是一个使用 IdentityHashMap 类实现的简单示例程序,IdentityHashMap 是 Java 提供的一种基于引用相等性比较的 Map 数据结构,即只有在 key 引用相等时才视为同一键。
首先,在 main 方法中创建了一个 IdentityHashMap 的实例对象 map,并向 map 中添加了三对键值对,分别是 1-“One”、2-“Two”、3-“Three”。然后,使用 get 方法获取了 key 分别为 1、2、3、4 的值,分别输出了对应的 value,输出结果为 One、Two、Three、null。
接着,使用 put 方法将 key 为 1 的 value 修改为 “First”,此时再次使用 get 方法获取 key 为 1 的值,输出结果仍然为 One,说明 IdentityHashMap 没有对引用相等的 key 进行覆盖操作。
接下来,使用 remove 方法移除了 key 为 1 的键值对,再次使用 get 方法获取 key 为 1 的值,输出结果为 null,说明该键值对已被移除。
最后,使用 clear 方法清空了 map 中的所有键值对,并输出 map 的大小,输出结果为 0,证明 map 已被成功清空。
小结
本文介绍了Java中的IdentityHashMap,它是一种特殊的Map实现类,使用恒等比较来判断键是否相等。本文对其源代码进行了解析,并分析了其应用场景、优缺点。IdentityHashMap在需要使用恒等比较的场景中更加方便,但由于其使用的是恒等比较,所以在某些特定场景下比其他Map实现类效率更高,但同时也会导致内存泄漏。在实际开发中,需要根据具体的需求和场景来选择合适的Map实现类,包括HashMap、TreeMap、LinkedHashMap以及IdentityHashMap等。
总结
本文对Java中的IdentityHashMap进行了深入的源代码解析和应用场景案例分析,并分析了其优缺点。IdentityHashMap是一个使用恒等比较来判断键是否相等的Map实现类,对于需要使用恒等比较的场景中更加方便。但是,由于它使用的是恒等比较,所以在某些特定的场景下比其他Map实现类效率更高,但同时也会导致内存泄漏。
在实际开发中,我们可以根据具体的需求和场景来选择不同的Map实现类,包括HashMap、TreeMap、LinkedHashMap以及IdentityHashMap等。对于需要使用恒等比较的场景,IdentityHashMap是一个不错的选择。
… …
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
… …
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。















 2614
2614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









