







 本文详细介绍了在Stata中进行描述性统计分析的方法,包括中心位置度量(均值、中位数、众数)、波动情况度量(极差、方差、标准差)、定性和定量变量处理,以及如何使用tabstat和summarize函数获取和可视化数据。
本文详细介绍了在Stata中进行描述性统计分析的方法,包括中心位置度量(均值、中位数、众数)、波动情况度量(极差、方差、标准差)、定性和定量变量处理,以及如何使用tabstat和summarize函数获取和可视化数据。
今天之后将要开启stata的进阶部分,即利用stata分析,需在掌握理论的基础上熟练应用

描述性统计的基本原理及核心参数
量化研究所收集的数据十分庞大,描述性统计分析致力于以简单明白的统计量来描述庞大的数据
分三类
描述中心位置的度量→ 算术平均,中位数,众数
描述波动情况的度量→极差、方差和标准差
描述数据集中一个观测位置的度量→百分位数,z得分
定性变量
定性观测值,用两个参数来反映:频数,频率
频数:落入某一类数中的特定观测值的个数
频率:落入某一类数中的特定观测值的个数占总数的比例
定量变量
定量观测值
描述中心位置的度量
描述波动情况的度量
描述数据集中一个观测位置的度量
集中趋势的度量
均值,算术平均
特点
信息利用充分
易受极端值影响
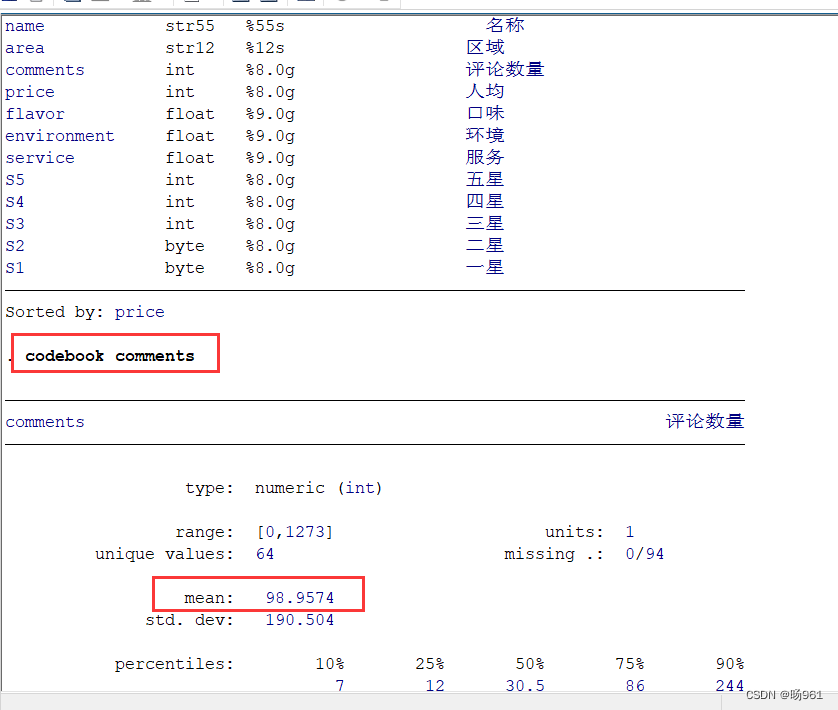
eg. codebook comments
众数
特点
不受极端值的影响
可能没有众数或很多众数
函数内容

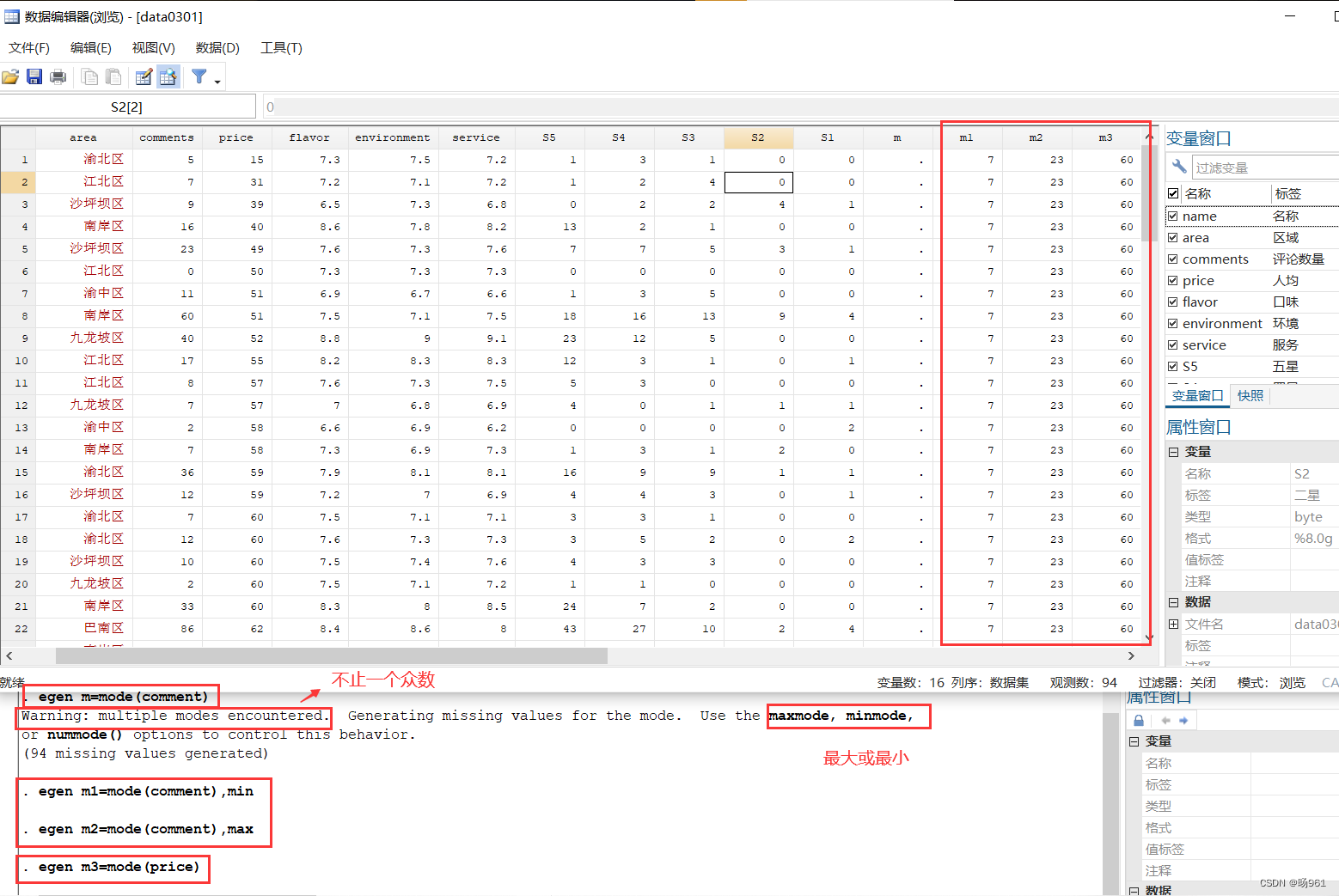
eg. egen m=mode(comment)
中位数
特点
不受极端
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6491
6491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









