







实验|Vachel
算力支持|幻方AIHPC

PyTorch分布式训练
2018年,将近3亿参数的Bert模型横空出世,将NLP领域推向了新的高度。近年来人工智能领域的发展愈来愈趋向于对大模型的研究,各大AI巨头都纷纷发布了其拥有数千亿参数的大模型,诞生出了很多新的AI应用场景。
另一方面,多种因素继续推动大模型的长足发展:1) 社会正经历着深度的数字化转型,大量的数据逐渐融合,催生出许多人工智能的应用场景和需求;2) 硬件技术不断进步:英伟达 A100 GPU,Google的 TPU,阿里的含光800等,推动着AI算力的不断提升。可以这么说,“大数据+大模型+大算力”的组合,是迈入 AI 2.0 的基石。
然而,对于大多数AI从业者们来说,受限于一些因素,平常很难接触到大数据或者大算力,很多高校研究生们往往都习惯于用一张显卡(个人PC)来加速训练,这不仅训练缓慢,甚至会因此限制住了想象,禁锢了创造力。
幻方AI团队自研了智能分时调度系统、高效存储系统与网络通信系统,可以将集群当成一台普通计算机来使用,根据任务需求弹性扩展GPU算力;自研了hfai数据仓库、模型仓库,优化AI框架与算子,集成落地了许多前沿的应用场景;通过Client接口或者Jupyter就可以轻松接入,加速训练起AI大模型。幻方AI旨在打造一个大规模AI计算服务,助力数据科学家与AI开发者们打破禁锢,推动AI新发展。
本期文章分享的,是如何使用起多张显卡,来加速你的AI模型。分布式训练技术逐渐成为AI从业者必备技能之一,这是从“小模型”走向“大模型”的必由之路。我们以 PyTorch 编写的ResNet训练为例,为大家展示不同的分布式训练方法及其效果。
训练任务:ResNet + ImageNet
训练框架:PyTorch 1.8.0
训练平台:幻方AI HPC
训练代码:https://github.com/HFAiLab/pytorch_distributed
训练准备
萤火二号当前一共有625个节点,每个节点8张A100,完整支持了PyTorch的并行训练环境。笔者先使用1个节点8张卡,测试不同的分布式训练方法所需要的时间、显卡利用效率;之后采用多个节点,来验证并行加速的效果。测试的采用三种方法:
1 nn.DataParallel
2 torch.distributed + torch.multiprocessing
3 apex
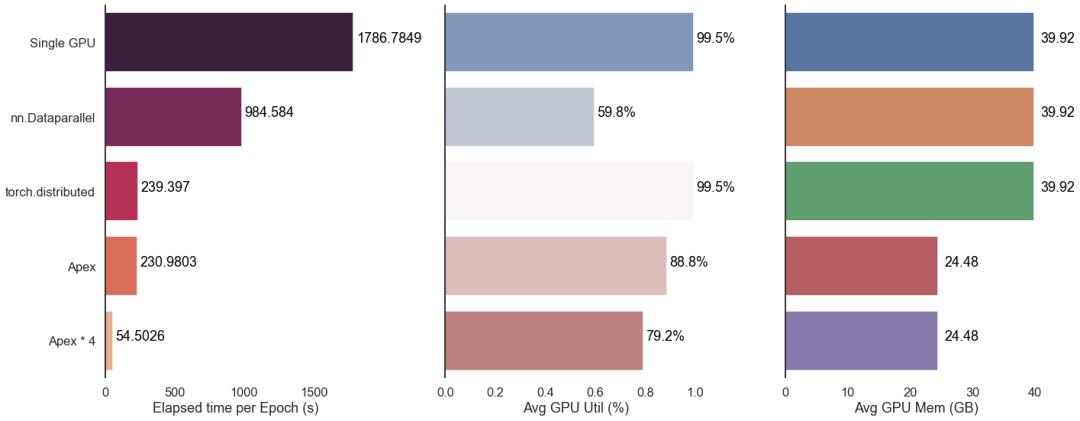
为充分利用显存,这里 batch_size 设为400,记录每Epoch的耗时来进行对比。我们先采用单机单卡测试作为baseline,每Epoch耗时1786秒上下。
测试结果发现,有apex加持的并行加速效果最好;DataParallel较慢,且显卡资源利用度不高,不推荐使用;多机多卡带来的加速效果非常显著。整体结果如下:
nn.DataParallel
DataParallel 是PyTor
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











