






👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
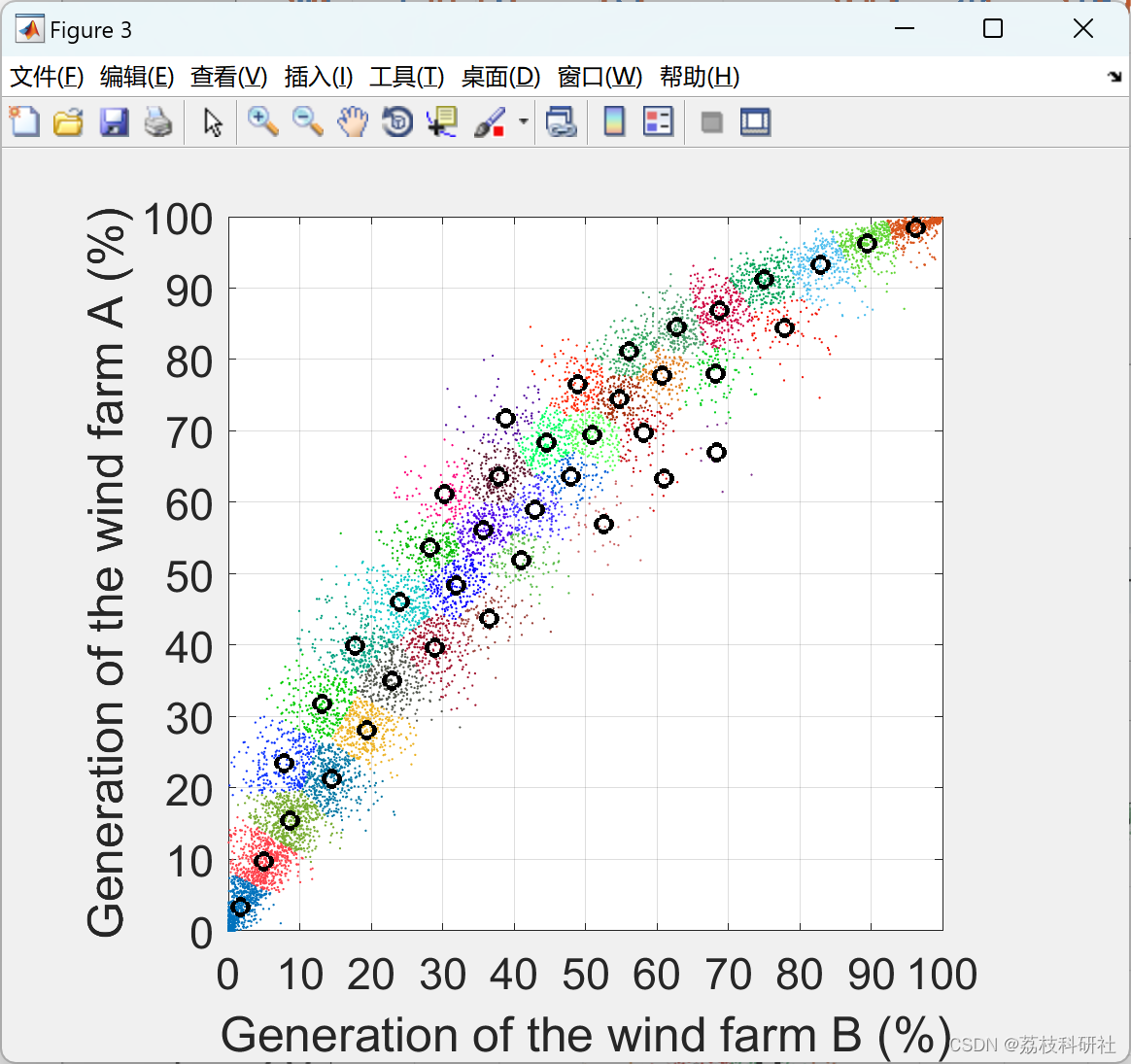
本文介绍了改进的迭代自组织数据分析技术算法(m-ISODATA),这是一种无监督聚类算法,用于捕获电力系统中的代表性场景。有两个应用示例可用:考虑风和负载可变性的概率最优潮流;以及发电扩展规划问题,考虑具有11维数据集的风能 - 太阳能 - 热力系统,用于表示风能,太阳能和负载的变化。
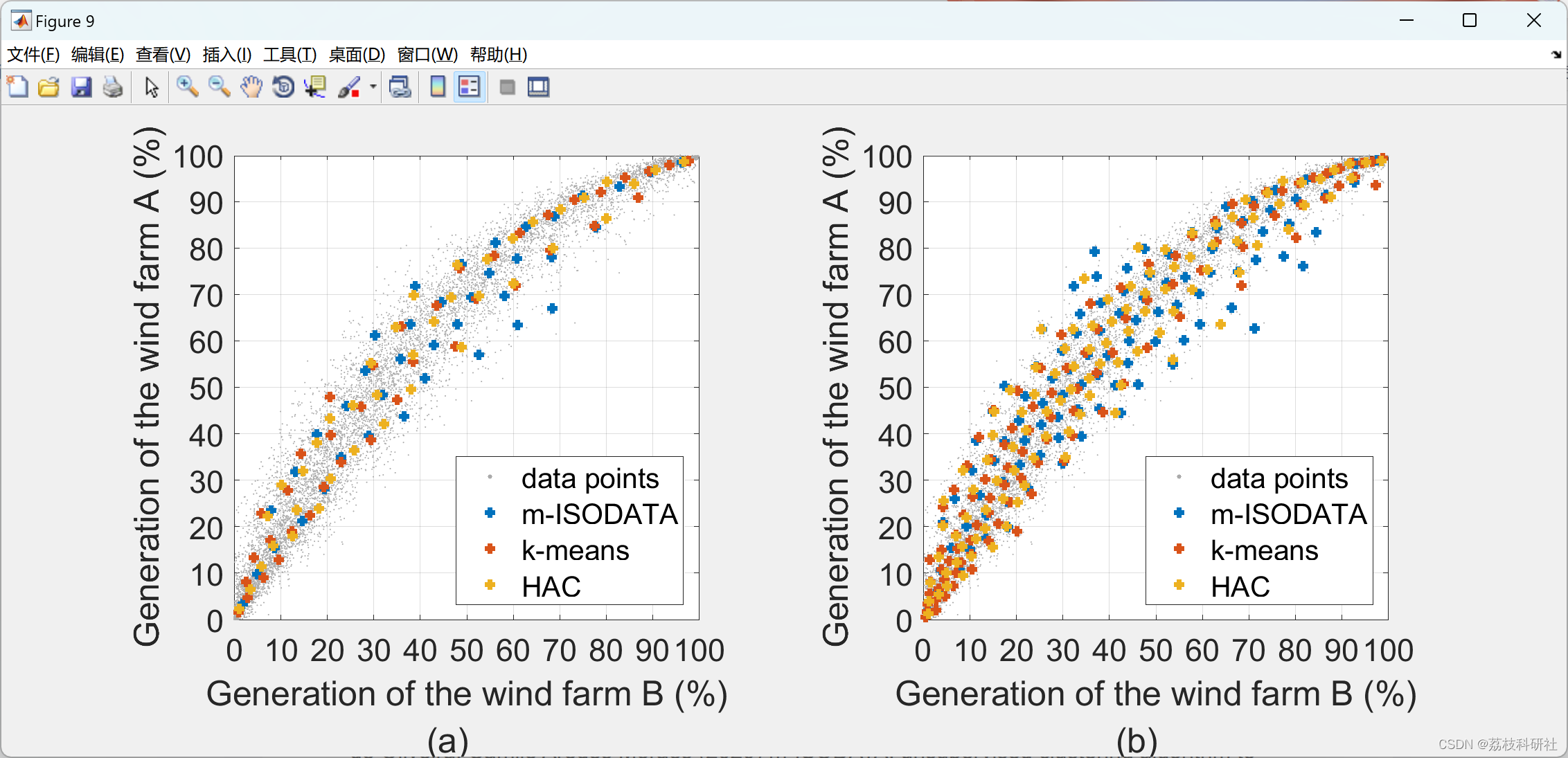
在电力系统的研究中,尤其是针对风电的生成与削减分析,无监督聚类算法扮演着重要角色,它们能够帮助研究人员从大量的风速、风向等气象数据中识别出不同的风能场景,进而分析这些场景对电力系统运行稳定性、调度策略及能源优化的影响。以下是三种常用的无监督聚类算法——m-ISODATA、k-means、层次聚类(Hierarchical Agglomerative Clustering, HAC)——在风场景生成与削减研究中的应用概述。
1. m-ISODATA (改进型ISODATA)
m-ISODATA是对传统ISODATA(迭代自组织数据分析算法)的一种改进,它结合了K-means和分裂合并技术的优点,能够在聚类过程中自动调整类别数量。在风电数据分析中,m-ISODATA可以有效处理风速、风向等多维数据,自动发现并适应不同风况模式。通过迭代过程,算法不仅能够生成代表性的风场景类别,还能根据数据分布动态调整类别数量,从而更准确地反映风电输出的复杂变化,为风电预测和调度提供依据。
2. k-means
k-means是最基础且广泛使用的无监督聚类算法之一,其目标是将数据集划分为k个簇,使得同一簇内的数据尽可能相似,而不同簇间的数据尽可能不同。在风能研究中,k-means可用于识别风速、风向分布的典型模式,每个簇代表一种特定的风场景。通过预先设定的簇数(例如,根据历史数据确定的几种常见风况),k-means可以快速分类风速记录,为风电功率预测、发电计划制定提供支持。然而,k-means要求事先确定簇的数量,并且对初始中心点的选择敏感,可能需要多次运行以获得最优解。
3. 层次聚类(HAC)
层次聚类方法通过构建一棵树状的聚类结构(又称树状图或 dendrogram),来展示数据点之间的聚合关系。HAC可以是自底向上(凝聚法)或自顶向下(分裂法)进行。在风电场景生成与削减研究中,HAC特别适用于探索风能数据的层次结构特征,比如从细粒度到粗粒度逐步合并相似风速-风向模式,形成不同的风场景类别。这种方法不需要预先指定聚类数量,而是通过剪切树状图在某个合适的高度来得到最终的聚类结果,为风电资源评估、风电场布局规划等提供了灵活的分析手段。
总结
在风电场景的生成与削减研究中,m-ISODATA、k-means和HAC各有优势:m-ISODATA能够自适应调整类别数量,适合处理复杂多变的风电数据;k-means简单高效,但需要预设类别数;HAC则提供了一种探索数据自然层次结构的手段。选择哪种算法应基于具体研究目的、数据特性和对结果解释的需求。实践中,也可能需要综合运用多种算法或进行算法的参数优化,以达到最佳的分析效果。
📚2 运行结果
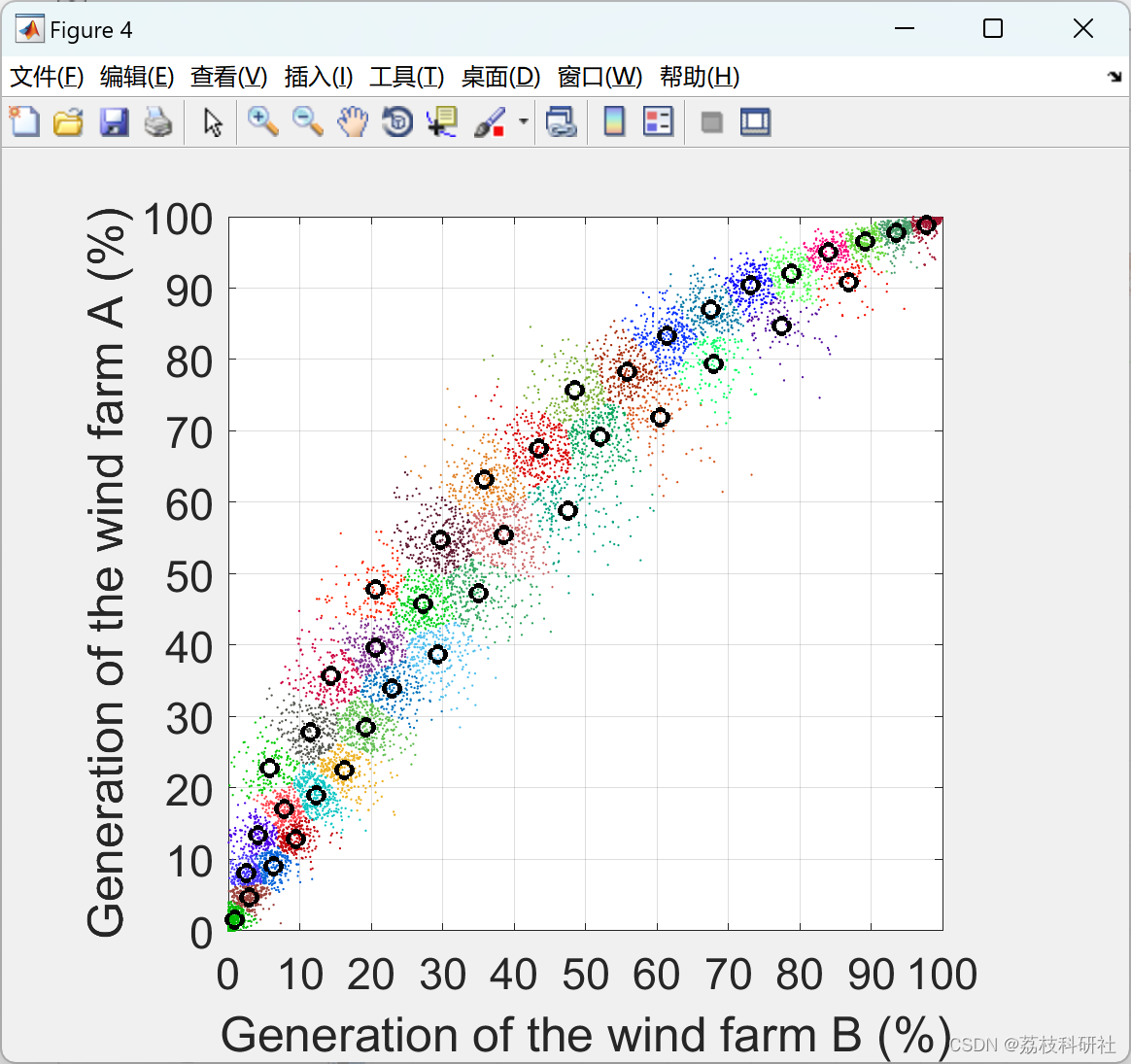
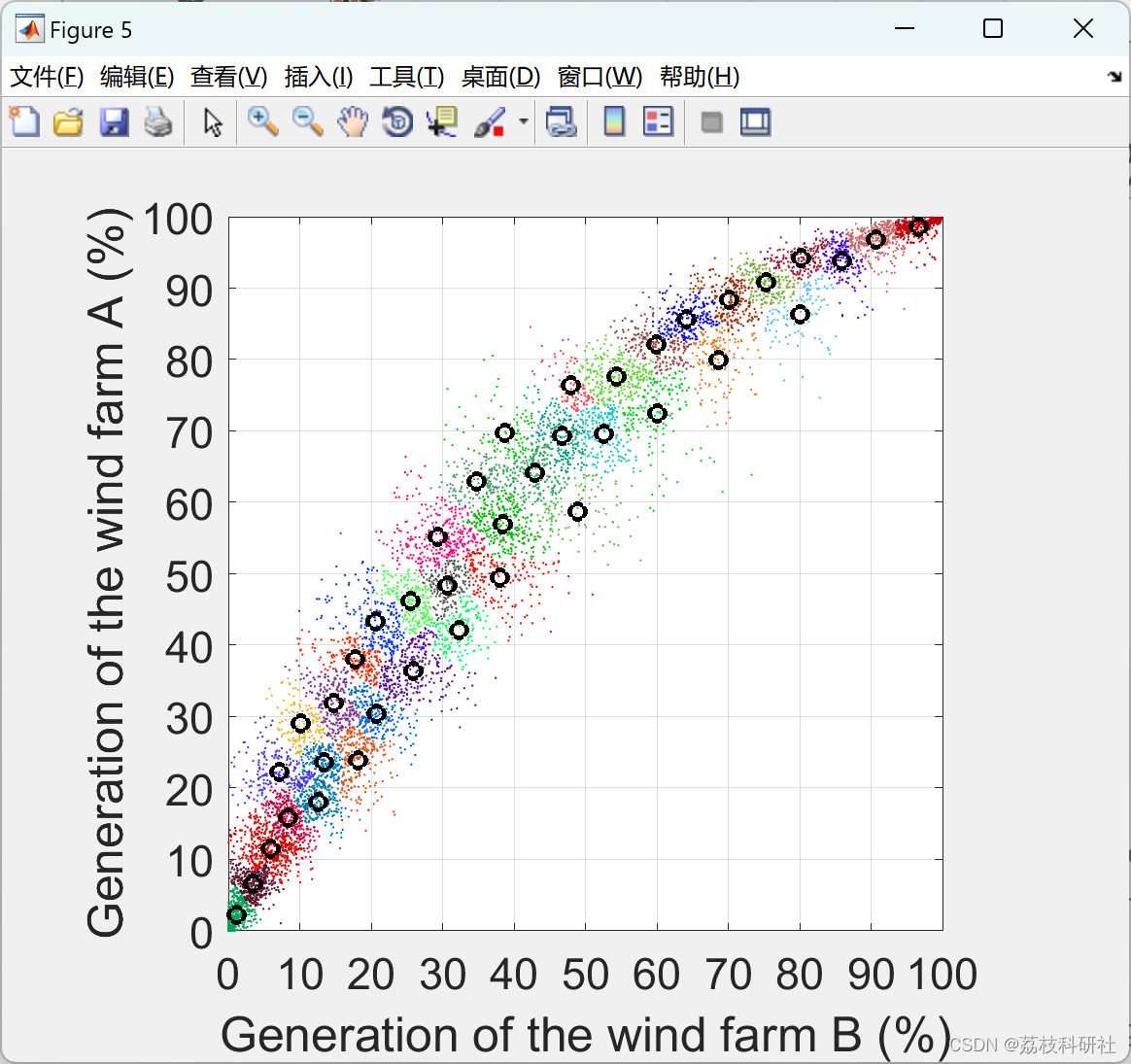
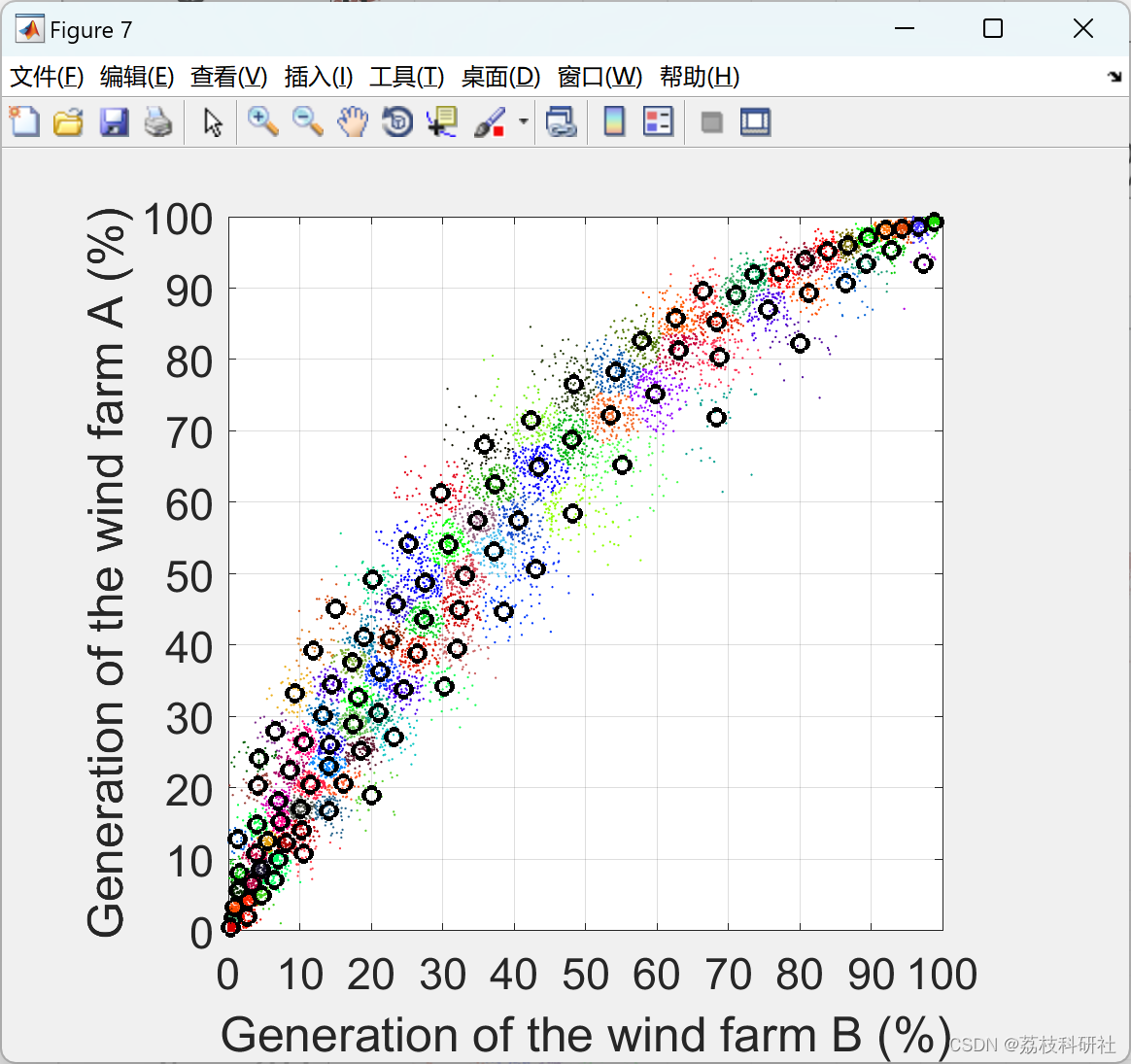
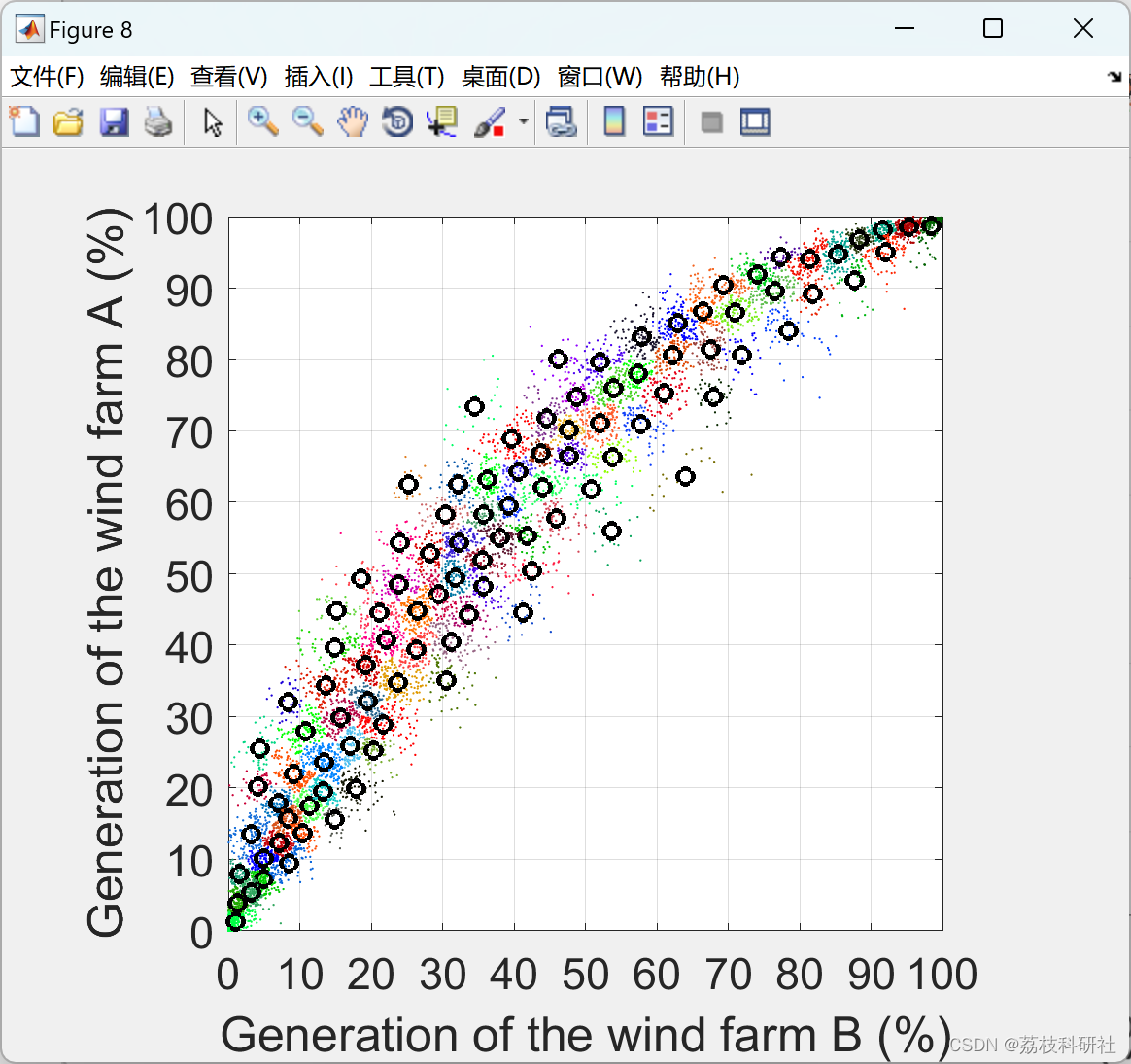
部分代码:
% Operating System
if strcmp(computer, 'PCWIN64')
folder_root = '';
else
folder_root = '/';
end
%
load([folder_root '../data/Series_2WindFarms_mod.mat'],'data'); % Leitura das s锟絩ies na matriz M
[Nobs, nser] = size(data); % N锟絤ero de s锟絩ies
%
%
figure('Position',[339 200 1500 648])
subplot(1,2,1)
color = get(gca,'ColorOrder');
plot(-1,-1, '.', 'LineWidth', 2,'MarkerSize', 8, 'color', [170 170 170]/255)
hold on
plot(data(:, 1)*100, data(:,2)*100,'.','MarkerSize', 3.5, 'Color', 120*[1 1 1]/255, 'HandleVisibility', 'off')
xlabel(['Generation of the wind farm B (%)\newline' ...
' (a)'])
ylabel('Generation of the wind farm A (%)')
%
ninterval = 24;
mx = zeros(ninterval, 1);
my = zeros(ninterval, 1);
passo = 1/ninterval;
i0 = -passo;
for interval = 1:ninterval
sx = 0;
sy = 0;
c = 0;
i0 = i0+passo;
iF = i0+passo;
if interval < ninterval
for iobs = 1:Nobs
if data(iobs, 2)>=i0 && data(iobs, 2)<=iF
sx = sx+data(iobs, 1);
sy = sy+data(iobs, 2);
c = c+1;
end
end
else
for iobs = 1:Nobs
if data(iobs, 2)>=0.99 && data(iobs, 2)<=1
sx = sx+data(iobs, 1);
sy = sy+data(iobs, 2);
c = c+1;
end
end
end
if c>0
mx(interval) = sx/c;
my(interval) = sy/c;
else
mx(interval) = NaN;
my(interval) = NaN;
end
end
plot(mx*100, my*100, '--', 'LineWidth', 3, 'Color', color(4,:))
legend('data points', 'data average')
axis([0 100 0 100])
axis('square')
grid on
xticks(0:10:100)
set(gca,'FontSize',14)
%
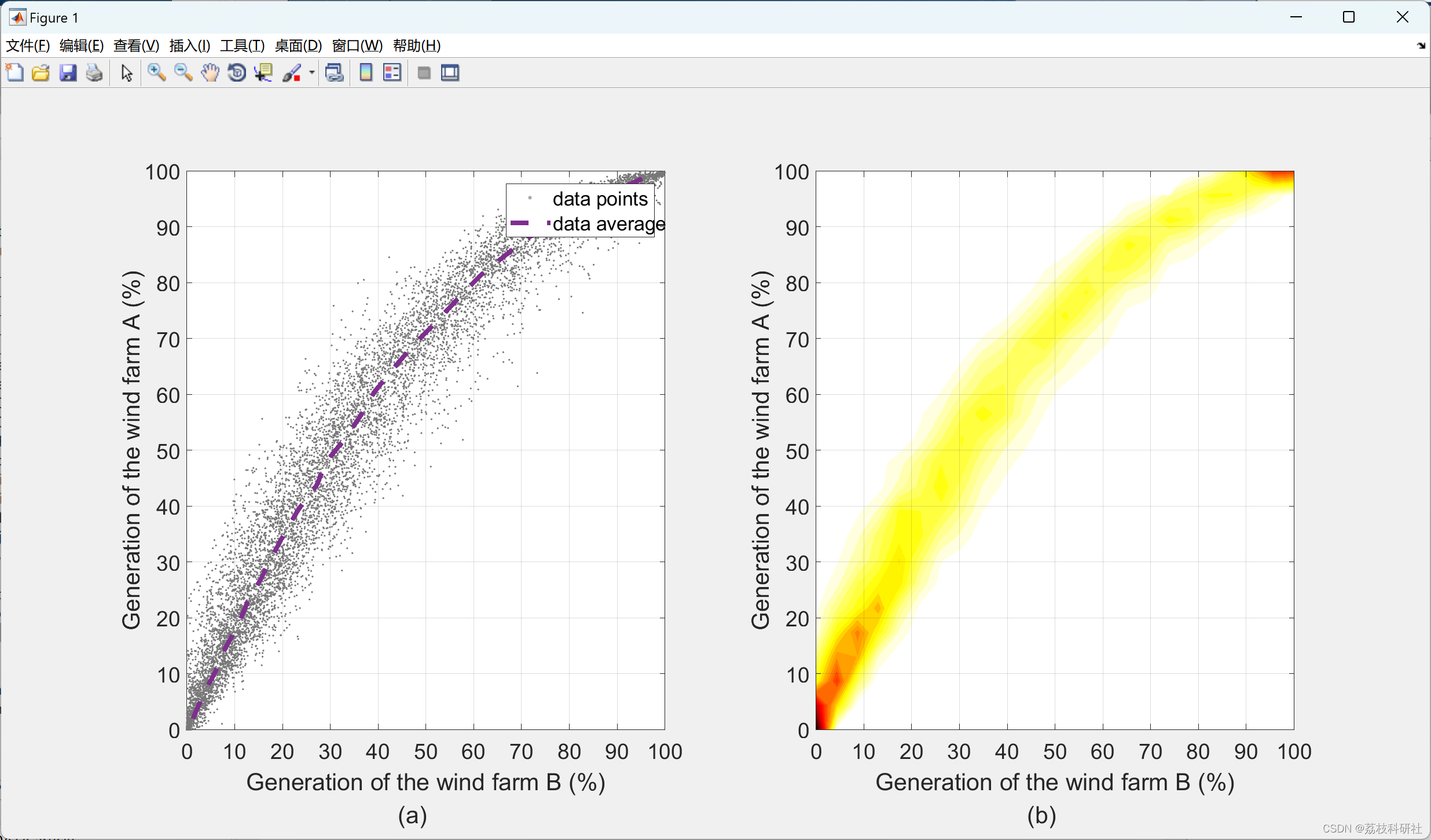
%% Density plot
[N, c] = hist3(data,[24 24],'CdataMode','auto','LineStyle','none');
[Nsize, ~] = size(N);
xy = linspace(0, 1, Nsize);
N=N/sum(sum(N));
N(N==0)=NaN;
%
subplot(1,2,2)
% contourf(xy*100,xy*100,N',25,':')
contourf(xy*100,xy*100,N',25,'LineStyle','none')
colormap(flipud(hot))
xlabel(['Generation of the wind farm B (%)\newline' ...
' (b)'])
ylabel('Generation of the wind farm A (%)')
%colorbar('Ticks',[0.005,0.036],'TickLabels',{'Low','High'})
axis('square')
grid on
xticks(0:10:100)
set(gca,'FontSize',14)
print(gcf,[folder_root 'fig_DataDensity.jpg'],'-djpeg','-r200');
savefig([folder_root 'fig_DataDensity.fig'])
%
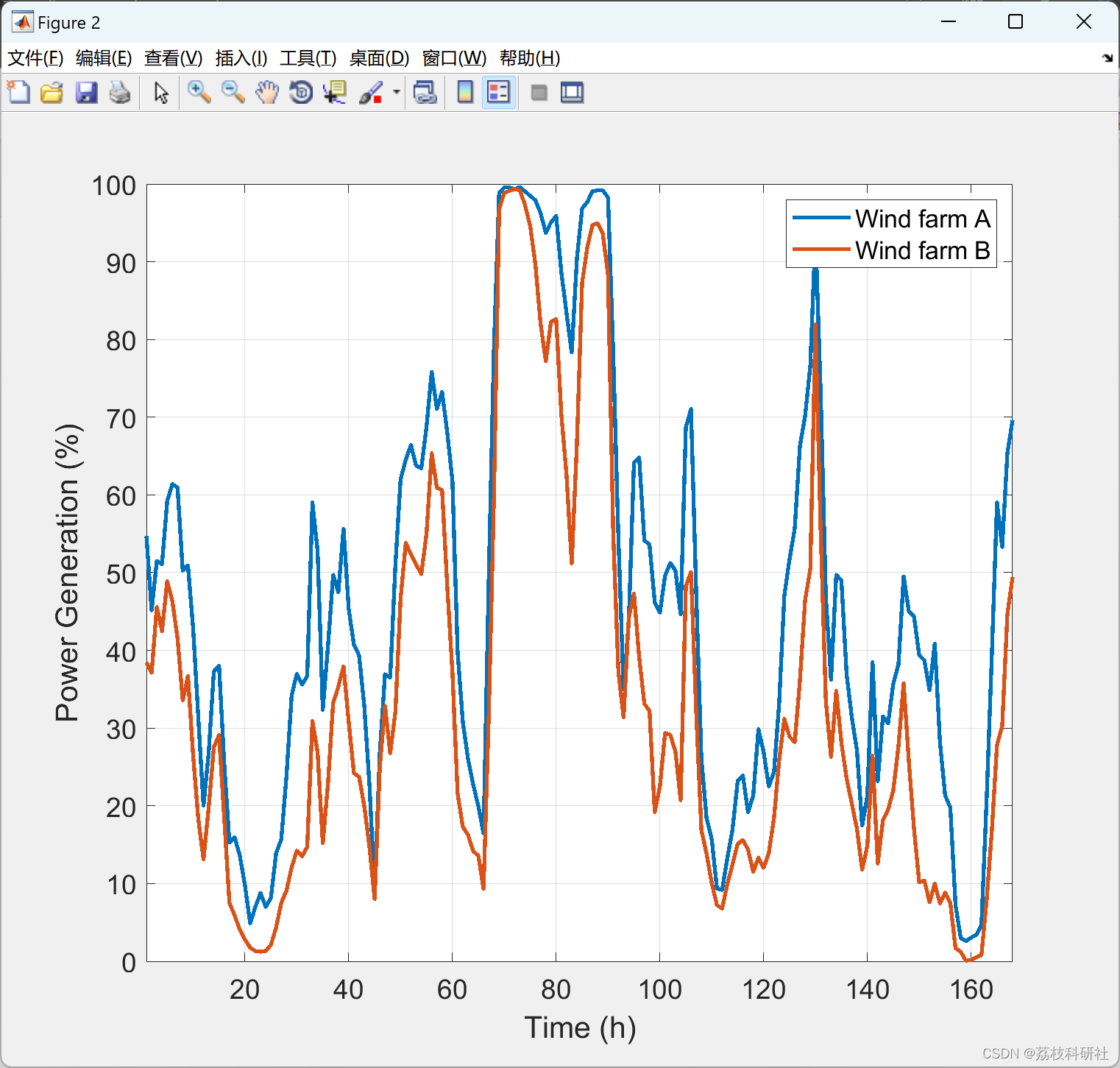
%% Historical series
figure('Position',[339 120 759 648])
%plot(1:8760, movmean(data(:,2)*100,24*7), 1:8760, movmean(data(:,1)*100,24*7), 'LineWidth', 2)
plot(1:24*7, data(1:24*7,2)*100, 1:24*7, data(1:24*7,1)*100, 'LineWidth', 2)
legend('Wind farm A', 'Wind farm B')
xlabel('Time (h)')
ylabel('Power Generation (%)')
axis([1 24*7 0 100])
grid on
set(gca,'FontSize',14)
print(gcf,[folder_root 'fig_hist_2WF.jpg'],'-djpeg','-r200');
savefig([folder_root 'fig_hist_2WF.fig'])
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]Arthur Neves de Paula, Edimar José de Oliveira, Leonardo de Mello Honório , Leonardo Willer de Oliveira, Camile Arêdes Moraes (2020) m-ISODATA: unsupervised clustering algorithm to capture representative scenarios in power systems
[2]李仲恒,刘蓉晖.基于ISODATA的电力负荷曲线分类[J].上海电力学院学报,2019,35(04):327-332.
[3]王燕妮,李军,田思敏.模糊ISODATA聚类结合直方图熵值算法的异常行为检测[J].现代电子技术,2017,40(12):120-123+127.DOI:10.16652/j.issn.1004-373x.2017.12.033.















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









